↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Parameter-efficient finetuning (PEFT) methods are crucial for adapting large language models (LLMs) to various tasks. However, current PEFT methods face challenges in efficiently deploying LLMs with multiple adapters and in interpreting LLM behavior. Existing batching techniques using matrix multiplication introduce overhead, while interpreting billion-parameter models is complex.
RoAd, a novel method employing 2D rotation, elegantly addresses these issues. RoAd achieves optimal performance with minimal trainable parameters (<0.1%), facilitates efficient batching comparable to element-wise multiplication, and enhances interpretability through integration within a distributed interchange intervention framework. Experimental results demonstrate RoAd’s superiority across various benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces RoAd, a novel parameter-efficient finetuning method that addresses key challenges in deploying large language models. RoAd’s efficiency in batching and composability, coupled with its enhanced interpretability, makes it a significant contribution to the field. It opens avenues for research into more efficient and interpretable LLM adaptation.
Visual Insights#

This figure compares the performance of different parameter-efficient fine-tuning (PEFT) methods on three types of tasks: GLUE benchmark, eight commonsense reasoning tasks, and four arithmetic reasoning tasks. The PEFT methods compared are RoAd, Full FT (full finetuning), LoReFT, DORA, LORA, Adapters, and AdapterFFN. The x-axis represents the percentage of trainable parameters, and the y-axis represents the accuracy achieved on each task. The results show that RoAd achieves high accuracy while using significantly fewer trainable parameters compared to other methods, particularly on GLUE and commonsense reasoning tasks.

This table summarizes the three variants of the RoAd model, showing the number of trainable parameters for each variant. RoAd1 uses a single scaling factor for all dimensions, RoAd2 uses two independent scaling factors for each pair of dimensions, and RoAd4 uses four separate scaling factors for each dimension. This results in different numbers of trainable parameters (d2, 2d2, and 4d2, respectively, where d2 is the number of dimensions in the original weight matrix). The table clarifies how the parameter sharing and independence differ across the variants of RoAd, reflecting the varying levels of parameter efficiency.
In-depth insights#
2D Rotation PEFT#
2D Rotation PEFT presents a novel parameter-efficient fine-tuning (PEFT) method that leverages the power of 2D rotations. By focusing on the angular components of the weight matrices, it significantly reduces the number of trainable parameters while achieving comparable or even surpassing the performance of other PEFT methods. This approach is particularly efficient in handling multiple requests within the same batch. The use of element-wise multiplication instead of batch matrix multiplication greatly improves throughput. This is a key advantage over other methods that introduce significant computational overheads. Furthermore, it exhibits promising composability, effectively merging the knowledge from various tasks. However, its inherent limitation lies in its scalability, particularly when increasing the number of trainable parameters. Combining 2D rotation with other PEFT methods could mitigate this limitation. Overall, 2D Rotation PEFT offers a compelling approach for efficient and composable fine-tuning, particularly for resource-constrained environments. Further research should focus on enhancing its scalability and investigating its broader applications.
Efficient Batching#
Parameter-efficient fine-tuning (PEFT) methods significantly reduce the computational cost of adapting large language models (LLMs) to various downstream tasks. However, efficiently deploying LLMs with multiple task-specific adapters, especially when different adapters are needed for distinct requests within the same batch, presents a considerable challenge. The paper addresses this challenge, focusing on efficient batching mechanisms. Traditional approaches using batch matrix multiplication (BMM) incur significant overhead, especially when dealing with many heterogeneous requests. The proposed method leverages a novel strategy that replaces computationally expensive BMM with element-wise operations, thereby drastically improving batch processing speed and reducing latency. This is achieved by employing a 2D rotation that adapts LLMs and allows for efficient parallel processing of requests with different adapters. The reduction in overhead is substantial, making the approach suitable for real-time applications where quick response times are crucial. The paper highlights the effectiveness of this efficient batching strategy through quantitative experiments, demonstrating a significant throughput improvement over existing PEFT methods.
Composability#
The concept of composability in the context of this research paper centers on the ability to merge or combine different task-specific adapters, each trained for unique downstream tasks, without requiring further finetuning. This implies that the adapters are designed to be orthogonal or minimally interactive, allowing seamless integration within the same model. The efficient batching of heterogeneous requests is made possible because element-wise operations are used instead of computationally expensive matrix multiplication, improving throughput. While the paper primarily demonstrates composability qualitatively, it suggests that the underlying principles—orthogonal parameter adaptation and efficient batching—enable the merging of trained parameters trained for different tasks without significant performance loss, making the approach potentially very powerful for complex, multi-task applications.
RoAd Limitations#
The core limitation of RoAd revolves around its scalability. While demonstrating strong performance with minimal parameters, increasing the number of trainable parameters significantly impacts performance. This poses a challenge for applications needing a high degree of adaptability. Composability, though a notable advantage, is also limited; combining weights from different tasks might not always yield seamless integration. The method’s reliance on angular information for adaptation, while insightful, might overlook valuable magnitude adjustments crucial in certain scenarios. The interpretability, though enhanced through integration within a framework, may not offer a fully comprehensive understanding of the internal mechanisms. Finally, the generalizability of RoAd’s success across diverse datasets and LLMs needs further evaluation to confirm consistent performance.
Future of RoAd#
The future of RoAd hinges on addressing its current limitations, primarily its scalability. While demonstrating strong performance with minimal parameters, extending RoAd’s capabilities to larger-scale models and more complex tasks requires further research. Investigating adaptive parameter sharing mechanisms within RoAd’s 2D rotation framework could enhance its efficiency. Exploring integration with other PEFT methods like LoRA to leverage their complementary strengths is also crucial. Furthermore, enhancing RoAd’s interpretability through deeper integration with intervention frameworks will unlock deeper insights into its functionality and allow for more targeted improvements. Finally, thorough exploration of RoAd’s performance across diverse datasets and NLP applications, including focus on multilingual support and resource-constrained settings, will be key to establishing its broader applicability and impact.
More visual insights#
More on figures

This figure presents a pilot study on pretrained and finetuned representations to investigate the impact of magnitude and angular displacement on model adaptation. The left and middle panels show the relative change in magnitude (AM) and angular displacement (AD) between pretrained and finetuned representations using full finetuning and LoRA methods, respectively. The right panel demonstrates a disentanglement experiment that separately evaluates the effects of magnitude and angle on the model’s ability to adapt to downstream tasks.
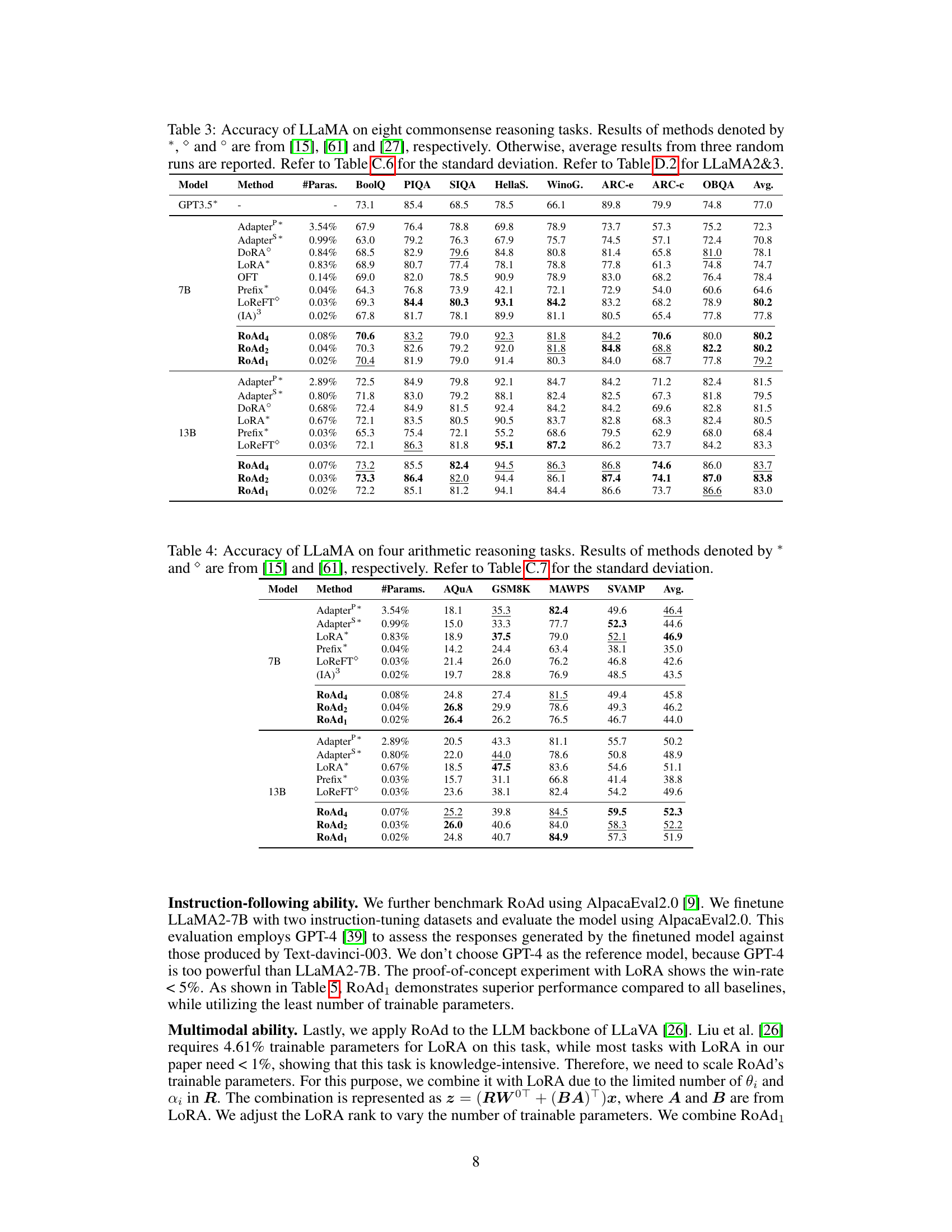
This figure illustrates the architecture of RoAd1, a variant of the proposed 2D rotary adaptation method. It shows how the input vector (h) is processed through a series of 2D rotations, represented by the matrices (R_i), before being combined with the pre-trained weights (W^0) to produce the final output (z). Each (R_i) rotates pairs of adjacent dimensions of (h), and the entire process is designed to be computationally efficient and parameter-sparse.
The figure displays the accuracy achieved by various parameter-efficient fine-tuning (PEFT) methods and full finetuning on three different sets of tasks: GLUE benchmark, eight commonsense reasoning tasks, and four arithmetic reasoning tasks. Two different large language models (LLMs) were used: RoBERTa-large and LLaMA-13B. The x-axis shows the percentage of trainable parameters used for each method, indicating its parameter efficiency. The y-axis displays the achieved accuracy for each task set. RoAd consistently demonstrates high accuracy with significantly fewer trainable parameters compared to other PEFT methods.

This figure presents a pilot study to investigate the impact of magnitude and angular changes on the representations of pretrained and finetuned LLMs. The left and middle panels show how full finetuning and LoRA affect the magnitude and angle changes of representations. The right panel shows a disentanglement experiment evaluating the effect of isolating changes in magnitude vs. angle, and shows that angular adjustments have a more significant impact on finetuning.
More on tables
This table presents the results of different parameter-efficient fine-tuning (PEFT) methods on the GLUE benchmark using RoBERTa as the base model. It compares the performance of RoAd with other PEFT methods like LORA, Adapter, and full finetuning across various tasks within the GLUE benchmark. The table highlights RoAd’s performance and parameter efficiency. It also includes the standard deviation of the results for RoAd.
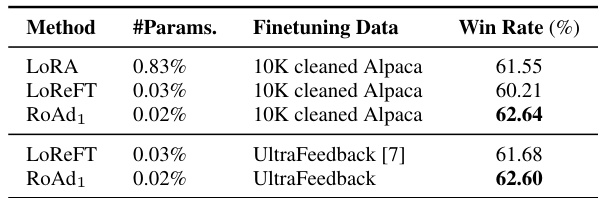
This table presents the results of instruction-following ability experiments on LLaMA2-7B using AlpacaEval2.0. It compares the performance of different parameter-efficient fine-tuning (PEFT) methods, namely LoRA, LoReFT, and RoAd1, using two instruction-tuning datasets: 10K cleaned Alpaca and UltraFeedback. The ‘Win Rate (%)’ indicates the percentage of times the model’s generated responses were judged to be superior to those of Text-davinci-003 by GPT-4. The table highlights the superior performance of RoAd1, achieving the highest win rate with minimal trainable parameters, demonstrating its effectiveness for instruction-following tasks.

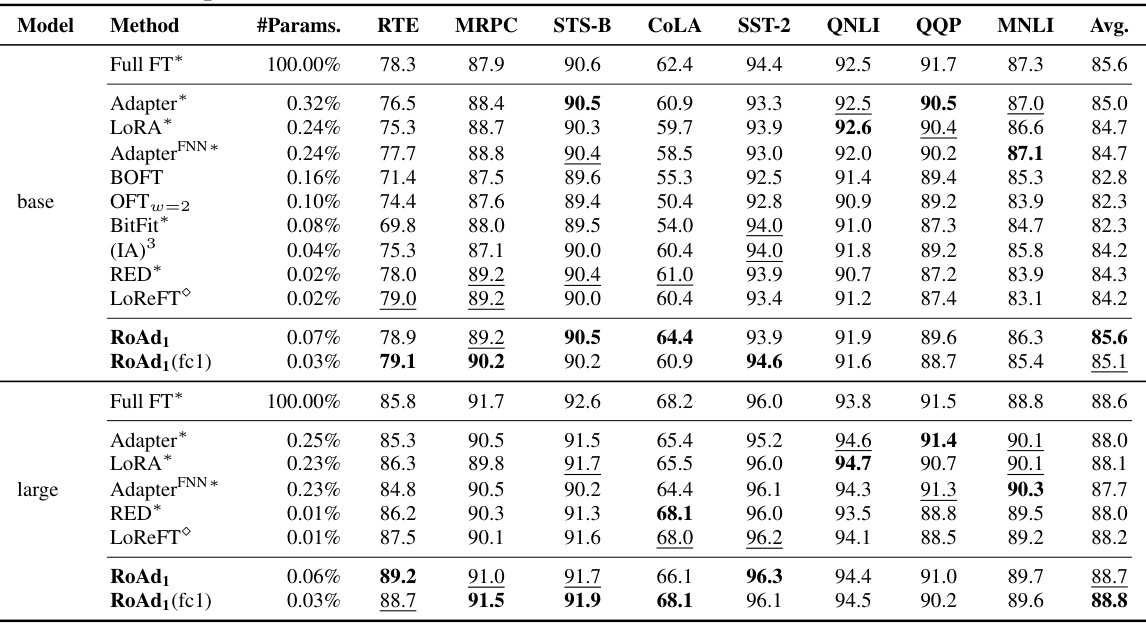
This table presents the results of various parameter-efficient fine-tuning (PEFT) methods and full fine-tuning on the GLUE benchmark using RoBERTa-base and RoBERTa-large language models. It compares the performance (accuracy and correlation scores) of different methods across multiple tasks, highlighting the parameter efficiency of RoAd1 in achieving results comparable to or better than other PEFT methods and even full fine-tuning, using significantly fewer trainable parameters.

This table presents the results of several parameter-efficient fine-tuning (PEFT) methods and a full finetuning method on four arithmetic reasoning tasks using the LLaMA language model. The tasks are AQuA, GSM8K, MAWPS, and SVAMP. The table shows the accuracy achieved by each method, along with the percentage of trainable parameters used. The results highlight the performance of RoAd compared to other PEFT methods in this specific task.

This table presents the results of visual instruction tuning on the LLaVA1.5-7B model using different parameter-efficient fine-tuning (PEFT) methods. It shows the performance (accuracy) of each method across four different tasks: GQA, SQA, VQAT, and POPE, as well as the average performance across all four tasks. The methods compared include LoRA, RoAd4 (a novel method proposed in the paper), and a combination of RoAd1 and LoRA. The table highlights the parameter efficiency of RoAd4, which achieves comparable performance to LoRA with significantly fewer parameters.
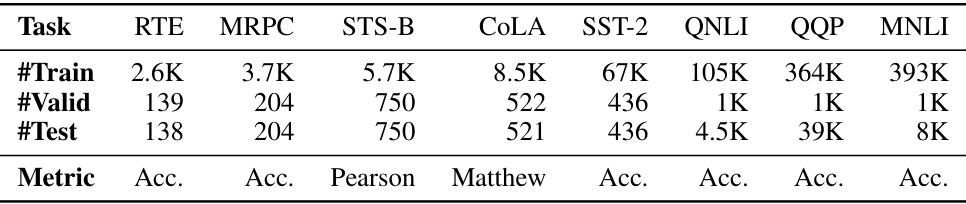
This table presents the details of the GLUE benchmark dataset used in the paper’s experiments. It provides the number of training, validation, and test samples for each of the nine tasks included in the GLUE benchmark. It also specifies the evaluation metric used for each task (Accuracy, Pearson correlation, or Matthew’s correlation). The table notes that the validation and test sets were randomly split from the original development set and that different random seeds resulted in different samples for the validation and test sets.
This table presents the results of different parameter-efficient fine-tuning (PEFT) methods on the GLUE benchmark using RoBERTa as the base model. It compares the performance of RoAd to other PEFT methods (LORA, Adapter, etc.) and full finetuning, showing the accuracy scores on various GLUE tasks. The table also shows the percentage of trainable parameters used by each method.

This table presents the results of different parameter-efficient fine-tuning (PEFT) methods on the GLUE benchmark using RoBERTa as the base model. It compares the performance (accuracy, correlation) of various methods, including RoAd, against full finetuning and other PEFT approaches like LoRA and adapters. The table highlights RoAd’s parameter efficiency, showing it achieves competitive results with significantly fewer trainable parameters.

This table presents the results of different parameter-efficient fine-tuning (PEFT) methods on the GLUE benchmark using RoBERTa as the base model. It compares the performance of RoAd1 to other PEFT methods (e.g., LORA, Adapter, BitFit, RED, LoReFT) and full fine-tuning across various tasks in the GLUE benchmark. The table highlights RoAd1’s performance, particularly its efficiency in terms of trainable parameters while achieving comparable or superior accuracy to other methods.

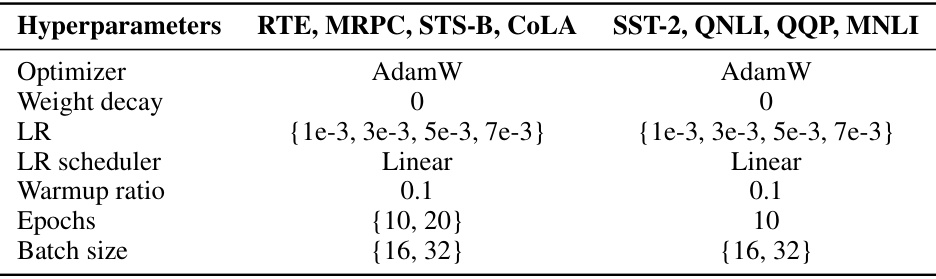
This table presents the hyperparameter settings used for both commonsense and arithmetic reasoning tasks. The settings were chosen without extensive hyperparameter tuning. Note the differences in the number of epochs and the learning rate between the two reasoning tasks. These differences reflect the different characteristics of the two types of tasks and their corresponding datasets.

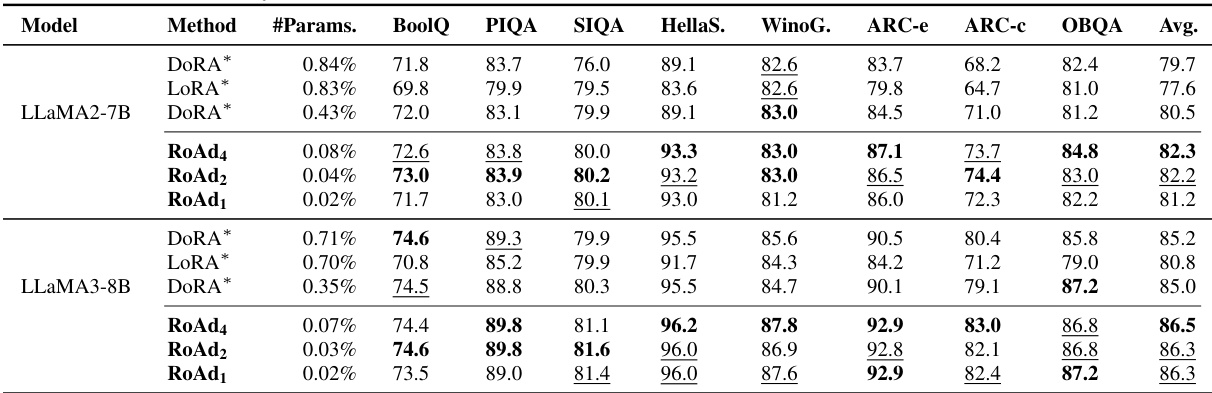
This table presents the results of evaluating various parameter-efficient fine-tuning (PEFT) methods and a full finetuning approach on eight commonsense reasoning tasks using the LLaMA language model. The table shows the average accuracy across three random runs for each method and model size (LLaMA-7B and LLaMA-13B), along with the percentage of trainable parameters used. The results highlight RoAd’s performance compared to other PEFT methods like LoReFT, DORA, and LORA.

This table presents the results of different parameter-efficient fine-tuning (PEFT) methods and full fine-tuning on four arithmetic reasoning tasks using the LLaMA language model. The table shows the accuracy of each method on the AQuA, GSM8K, MAWPS, and SVAMP datasets. The ‘#Params.’ column indicates the percentage of trainable parameters used by each method. The table also includes a comparison with three baselines reported in other studies.

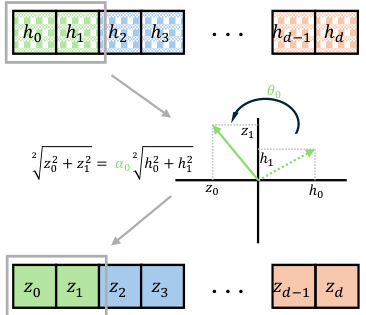
This table presents the hyperparameters used for fine-tuning different models (RoAd1, RoAd2, RoAd4, OFT, and BOFT) on the LLaMA-7B model. It shows the percentage of trainable parameters used (#Params.), the peak GPU memory consumed during training (Peak GPU memory (GB)), and the training time in seconds (Training time (s)). The table highlights the efficiency of RoAd methods compared to OFT and BOFT in terms of memory usage and training time.
This table presents the results of different parameter-efficient fine-tuning (PEFT) methods on the GLUE benchmark using RoBERTa as the base model. It compares the performance of RoAd with other state-of-the-art PEFT techniques, highlighting RoAd’s high accuracy while using significantly fewer trainable parameters. The table includes results for both the RoBERTa-base and RoBERTa-large models.
Full paper#