↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Retrieval-Augmented Generation (RAG) uses LLMs with retrievers to answer questions using relevant documents. However, current RAG pipelines have limitations: LLMs struggle with many contexts, retrievers may miss relevant information, and separate ranking models lack generalization.
RankRAG addresses these by instruction-tuning a single LLM for both context ranking and answer generation. This unified approach significantly improves performance across various benchmarks, outperforming existing expert ranking models and showing excellent generalization to new domains, even without specific domain training. It uses a small fraction of ranking data during training and exhibits superior data efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in natural language processing and information retrieval because it introduces RankRAG, a novel framework that significantly improves retrieval-augmented generation. Its data-efficient instruction-tuning method is highly relevant to current research trends focused on improving LLM efficiency and generalization. The results demonstrate superior performance on multiple benchmarks opening new avenues for research in instruction tuning and RAG.
Visual Insights#

This figure shows the performance of the ChatQA-1.5 model (a strong RAG model) on four different datasets (NQ, TriviaQA, PopQA, FEVER) when varying the number of top-k contexts used for answer generation. The results illustrate a trade-off. Using a small number of top contexts (e.g., k=5) results in lower recall (fewer relevant documents retrieved), while using a large number of contexts (e.g., k=20) introduces noisy or irrelevant information that negatively impacts the model’s ability to generate accurate answers. The optimal k value appears to be around 10 for the various datasets shown.

This table presents the instruction template used in Stage-II of the RankRAG framework. It shows how different tasks (context-rich QA, retrieval-augmented QA, context ranking, and retrieval-augmented ranking) are formatted for the instruction tuning process in a unified (x, c, y) structure. This structure allows for effective knowledge transfer across the different task types. Each row represents a task type, showing the input question (x), the context provided (c), and the expected output answer (y).
In-depth insights#
RankRAG Framework#
The RankRAG framework presents a novel approach to Retrieval-Augmented Generation (RAG) by unifying context ranking and answer generation within a single large language model (LLM). This is achieved through instruction-tuning, a technique that significantly improves the LLM’s ability to follow instructions and generalize to new tasks. Unlike traditional RAG pipelines that rely on separate retriever and ranking models, RankRAG’s integrated design offers enhanced efficiency and improved performance. By incorporating ranking data into the instruction-tuning process, RankRAG enables the LLM to effectively filter out irrelevant contexts, leading to more accurate and relevant answers, especially in challenging scenarios such as multi-hop questions or those requiring factual verification. The framework’s strength lies in its data efficiency; achieving superior results with minimal ranking data compared to existing expert models. This also demonstrates an impressive generalization capability to new domains. The retrieve-rerank-generate pipeline further refines the process by leveraging the LLM’s improved ranking capabilities for a more effective context selection.
Instruction Tuning#
Instruction tuning, a crucial technique in training large language models (LLMs), involves fine-tuning the model on a dataset of instructions and corresponding desired outputs. This process goes beyond traditional supervised learning by explicitly teaching the model to follow diverse instructions, improving its ability to generalize to new, unseen tasks. RankRAG leverages instruction tuning to achieve a unified framework for both context ranking and answer generation within the RAG pipeline. This approach is particularly powerful as it allows the LLM to learn the complex interplay between information retrieval and response generation, leading to superior performance. A key advantage is the enhanced generalization capabilities of the instruction-tuned LLM, enabling it to adapt effectively to new domains without extensive fine-tuning. Furthermore, instruction tuning addresses the limitations of using separate ranking models in RAG by allowing the LLM to directly learn optimal ranking strategies within the generation process. The success of RankRAG highlights the potential of instruction tuning for building highly adaptable and versatile LLMs for various knowledge-intensive tasks.
RAG Limitations#
Retrieval Augmented Generation (RAG) systems, while powerful, face limitations. Retrievers often struggle with long-tail knowledge, relying on limited embedding space to capture complex semantic relationships between queries and documents. This leads to a recall-precision tradeoff: retrieving too many contexts burdens the LLM, while retrieving too few misses crucial information. Current RAG pipelines are typically a two-stage process which causes problems. Further, LLMs show limitations in effectively processing large numbers of retrieved contexts, impacting the accuracy of answer generation. Finally, expert ranking models, though improving retrieval, lack the versatile generalization capacity of LLMs and often struggle with zero-shot performance on new domains. These issues significantly affect RAG’s overall effectiveness and highlight a critical need for more sophisticated techniques that address these limitations.
Benchmark Results#
A thorough analysis of benchmark results is crucial for evaluating the effectiveness of RankRAG. It’s important to examine the specific benchmarks used, ensuring they are relevant and representative of the target tasks. The choice of baselines is equally vital, as they provide a context for understanding RankRAG’s performance. A detailed comparison of performance metrics (e.g., Exact Match, F1-score) across different benchmarks and baselines will highlight the strengths and weaknesses of RankRAG, revealing its capabilities and limitations. Analyzing the results will provide insights into RankRAG’s generalization ability and efficiency, uncovering areas where it excels and where further improvements are needed. Careful consideration of factors such as dataset size and model parameters will provide a comprehensive evaluation. Finally, discussing any unexpected or noteworthy findings further enhances the overall understanding of RankRAG’s performance.
Future Directions#
Future research could explore several promising avenues. Improving RankRAG’s efficiency is crucial; while adding a reranking step enhances accuracy, it increases processing time. Investigating more efficient ranking methods or optimizing the retriever to reduce the initial candidate pool would significantly benefit the pipeline’s practicality. Furthermore, extending RankRAG’s capabilities beyond question answering is warranted. Adapting it to diverse tasks like summarization, translation, or code generation could unlock its full potential. Incorporating diverse data sources into the training is a key area for improvement. Exploring multi-modal data or integrating knowledge graphs could lead to more robust and nuanced understanding. Finally, a comprehensive investigation into RankRAG’s generalizability and robustness is essential. This would involve testing on a wider array of tasks and domains, evaluating performance under adversarial conditions, and analyzing its sensitivity to noise or biases in data. Addressing these areas would solidify RankRAG’s position as a leading framework for retrieval-augmented generation.
More visual insights#
More on figures

This figure illustrates the two-stage instruction tuning framework used for RankRAG. Stage-I involves supervised fine-tuning (SFT) on various instruction-following datasets such as conversational datasets (SODA, Dolly, OpenAssistant), long-form QA datasets (ELI5), and synthetic instruction datasets (Self-Instruct, Unnatural Instructions). This stage enhances the LLM’s instruction-following abilities. Stage-II focuses on RankRAG instruction tuning, where the LLM is trained on multiple tasks such as context-rich QA, retrieval-augmented QA, retrieval-augmented ranking, and context ranking. This is done using datasets like MS MARCO, conversational QA datasets (Synthetic Conversation, Human AnnotatedConvQA), and reading comprehension datasets (NarrativeQA, DROP, Quoref, NewsQA, TAT-QA, ROPES). This stage aims to enhance the LLM’s capability for both context ranking and answer generation. The inference stage is also depicted, showing a retriever extracting top-N documents, which are then reranked by RankRAG to select the top-K documents for answer generation.
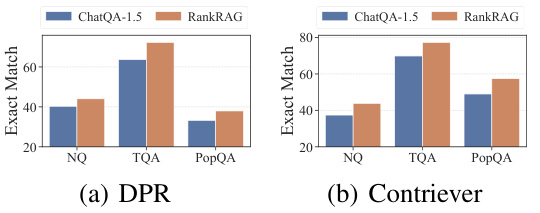
This figure compares the performance of RankRAG and ChatQA-1.5 using two different retrievers: DPR and Contriever, across three question answering datasets (NQ, TriviaQA, and PopQA). The x-axis represents the datasets, and the y-axis shows the Exact Match accuracy. The bars in each group represent the performance of ChatQA-1.5 and RankRAG. The caption indicates that a more detailed breakdown of Recall performance for each model and retrieval method is available in Appendix E.1.

This figure shows the performance of the ChatQA-1.5 model on four different question answering datasets (NQ, TriviaQA, PopQA, FEVER) with varying numbers of top-k retrieved contexts. The results illustrate a trade-off; using a small number of contexts (k) reduces the recall of relevant information, while using a larger number of contexts increases the likelihood of including irrelevant or noisy information which negatively impacts the quality of the LLM’s generated answers.

This figure shows the performance of the ChatQA-1.5 model on four different question answering datasets (NQ, TriviaQA, PopQA, FEVER) with varying numbers of top-k retrieved contexts. It demonstrates a clear trade-off: using a small number of contexts (k=5) limits recall (the ability to find relevant information), while using too many contexts (k=20) introduces irrelevant or noisy information that negatively impacts the LLM’s ability to generate accurate answers. The optimal k value appears to be around 10, showing a balance between recall and the ability to filter out irrelevant information.
More on tables
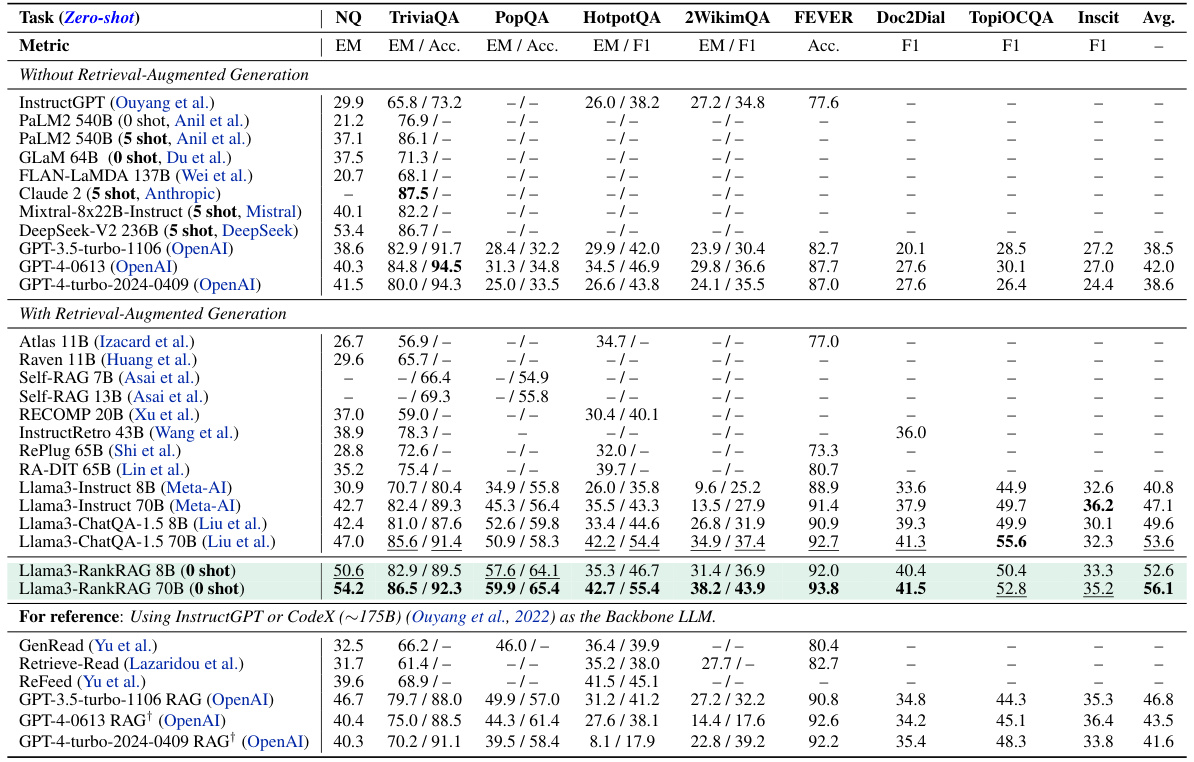
This table presents the performance comparison of RankRAG against various baselines across nine different datasets. The results are categorized into models without retrieval-augmented generation (RAG) and those with RAG. Zero-shot evaluation is used, meaning no additional demonstrations were provided during testing. The table highlights the performance of RankRAG, especially its competitive results against strong LLMs like GPT-4 and GPT-4-turbo, as well as other state-of-the-art RAG models.

This table presents the ablation study results for the RankRAG model using Llama3-8B as the backbone. It shows the impact of removing different components of the RankRAG framework on its performance across nine datasets. Specifically, it analyzes the effects of removing the reranking step, the retrieval-augmented QA data, and the retrieval-augmented ranking data. Additionally, it compares RankRAG’s performance against two baselines: one using only the initial supervised fine-tuning (SFT) stage and another incorporating the RAFT method from the related work. The results demonstrate the importance of each component for RankRAG’s overall performance.

This table presents the zero-shot performance of RankRAG and several baseline models across nine knowledge-intensive NLP datasets. The table compares the exact match (EM), accuracy (Acc.), or F1 scores achieved by each model on each dataset. It highlights RankRAG’s superior performance compared to other RAG models, particularly on challenging datasets such as PopQA and 2WikimQA. The results showcase RankRAG’s ability to generalize well without relying on additional demonstrations or fine-tuning.
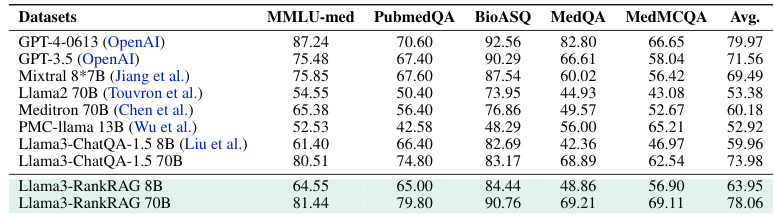
This table presents the zero-shot performance of RankRAG and various baselines across nine knowledge-intensive NLP datasets. The results showcase RankRAG’s performance compared to other models, highlighting its effectiveness, especially when compared to models with significantly more parameters. The table also notes limitations with GPT-4 and GPT-4-turbo in certain datasets, and highlights the use of the KILT benchmark for specific models and datasets.

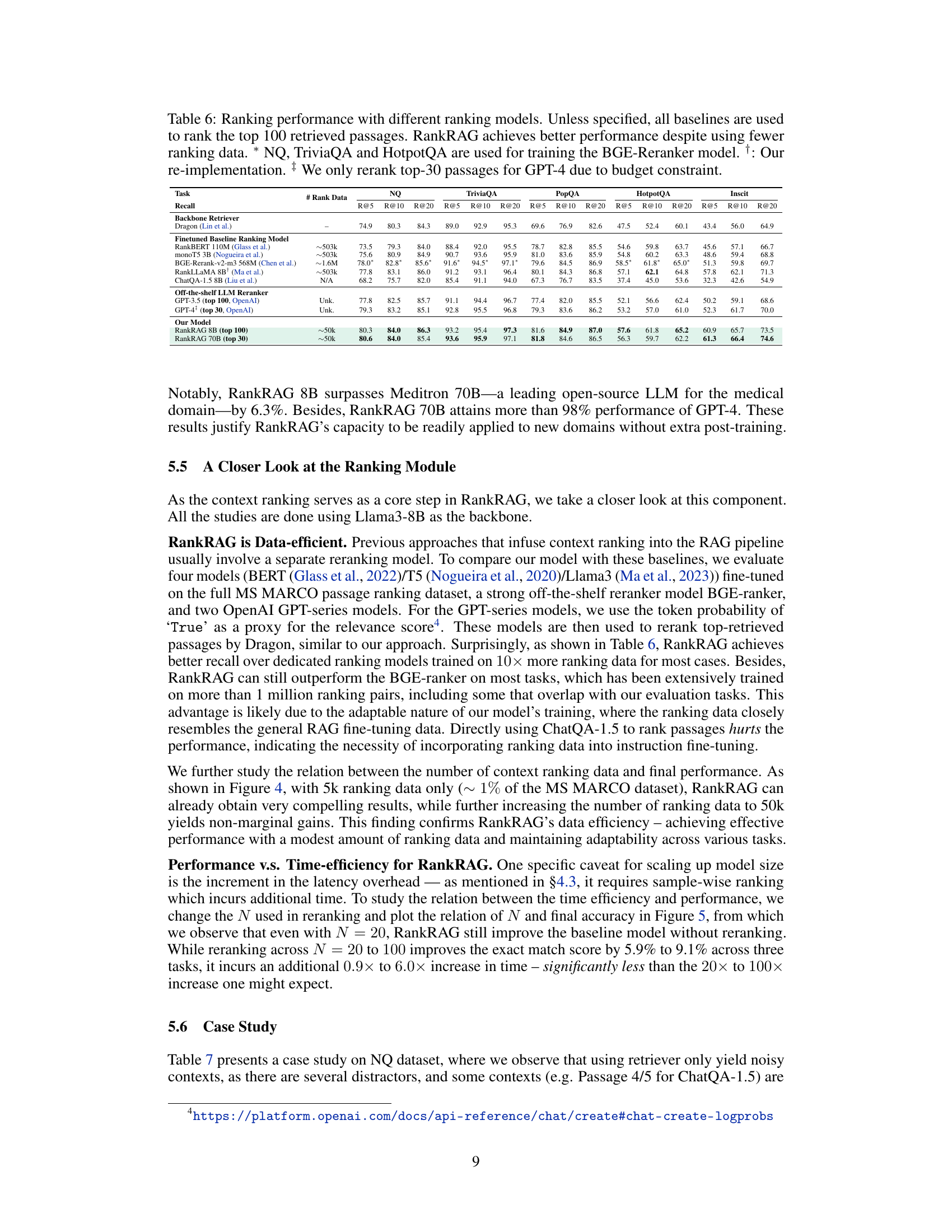
This table compares the recall performance (R@5, R@10, R@20) of different ranking models on five datasets (NQ, TriviaQA, PopQA, HotpotQA, Inscit). The models include various baselines like RankBERT, monoT5, BGE-Reranker, RankLLaMA, and ChatQA-1.5. It also includes OpenAI’s GPT-3.5 and GPT-4 as off-the-shelf LLMs used for reranking. Finally, it presents the performance of RankRAG 8B and 70B, highlighting its data efficiency by achieving better results than models trained on significantly more data.

This table presents the zero-shot performance of RankRAG and various baseline models across nine knowledge-intensive NLP datasets. It compares the Exact Match (EM) or Accuracy scores depending on the specific dataset and includes notes on any limitations or caveats for certain models.

This table presents a comparison of RankRAG’s performance against various baselines across nine different datasets. The evaluation is zero-shot, meaning no additional examples or fine-tuning was used. The table highlights the performance of different models, including those with and without retrieval-augmented generation (RAG), and specifically notes instances where GPT-4 and GPT-4-turbo models refused to answer due to insufficient information in retrieved passages. The average performance across all datasets is also provided.

This table presents a comparison of RankRAG’s performance against various baselines across nine datasets, encompassing zero-shot evaluations without additional demonstrations. The table highlights the performance differences across different models, including those with and without retrieval-augmented generation (RAG), and notes some limitations of GPT-4 and GPT-4-turbo in handling cases where relevant information is absent from retrieved passages.

This table presents a comparison of RankRAG’s performance against various baselines across nine knowledge-intensive NLP datasets. The results are categorized by whether or not a retrieval-augmented generation (RAG) method was used. The table includes metrics like Exact Match (EM), Accuracy (Acc.), and F1 score, showing RankRAG’s superior performance, especially on more challenging datasets. Note that some models may refuse to answer when relevant information is absent, affecting the reported scores.

This table presents a comparison of RankRAG’s performance against various baselines across nine different datasets. The results show RankRAG’s zero-shot performance (without additional demonstrations) and considers different model sizes. The table highlights RankRAG’s improvement over existing methods, especially on more challenging datasets. Note that GPT-4 and GPT-4 turbo models sometimes refuse to answer if relevant information is missing from the retrieved context, affecting their EM/Accuracy scores.
Full paper#