↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Spiking cameras offer high-speed, high-dynamic-range imaging but reconstructing clear images from their asynchronous spike data is challenging. Existing methods often use complex, step-by-step network architectures which overlook the intrinsic collaboration between spatio-temporal information. This limits the quality and efficiency of image reconstruction.
This paper introduces STIR, an efficient network that jointly performs inter-frame alignment and intra-frame filtering. STIR utilizes a hybrid spike embedding representation and a symmetric interactive attention block, improving interaction between spatio-temporal features. Experiments show that STIR outperforms existing methods in terms of accuracy and efficiency while maintaining low model complexity, paving the way for real-world high-speed imaging applications.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents STIR, a novel and efficient spatio-temporal interactive reconstruction network for spiking cameras. This addresses a key challenge in neuromorphic vision, improving image quality and efficiency, and opening avenues for high-speed imaging applications. Its innovative approach of jointly optimizing motion estimation and intensity reconstruction surpasses existing methods and has potential impact across autonomous driving and robotics.
Visual Insights#
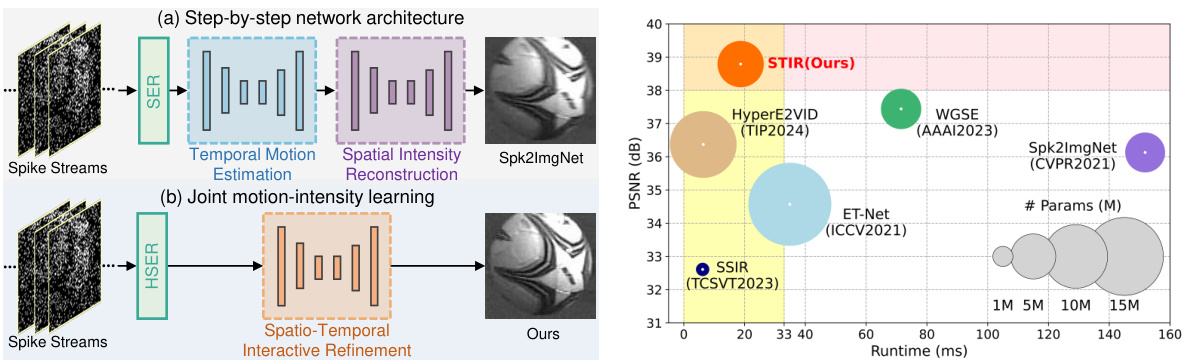
This figure compares two different approaches for spike-to-image reconstruction. (a) shows the traditional step-by-step method, which consists of separate modules for spike embedding, temporal motion estimation, and spatial intensity reconstruction. (b) illustrates the proposed method, which uses a joint motion-intensity learning framework. The proposed method uses a novel hybrid spike embedding representation (HSER) to efficiently link the binary spikes from the camera to the deep learning model.
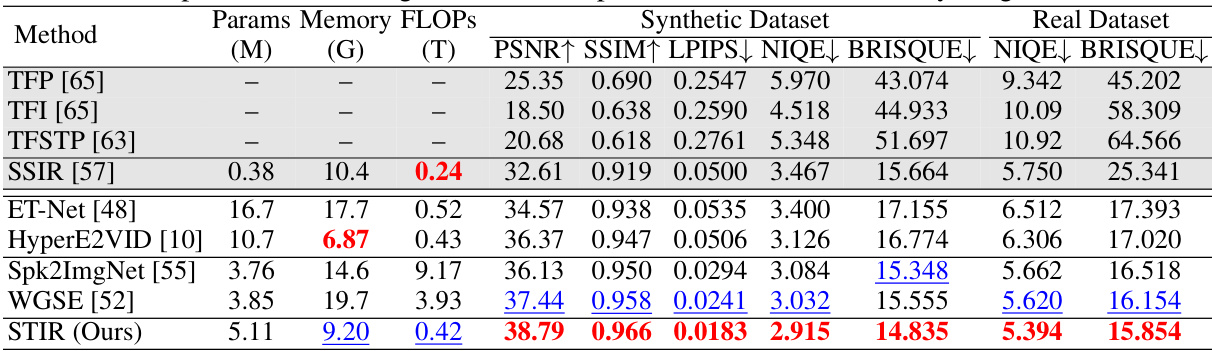
This table presents a quantitative comparison of the proposed STIR method against state-of-the-art (SOTA) methods for spiking camera image reconstruction. It evaluates performance on both synthetic (SREDS) and real-captured datasets using metrics such as PSNR, SSIM, LPIPS, NIQE, and BRISQUE. The table highlights STIR’s superior performance in terms of reconstruction accuracy and efficiency (parameter size, memory usage, and FLOPs).
In-depth insights#
Spatio-temporal fusion#
Spatio-temporal fusion in the context of image reconstruction from spiking cameras aims to effectively combine spatial and temporal information present in the asynchronous spike streams generated by these sensors. A key challenge is the inherent sparsity and irregularity of spike data, making direct application of traditional image processing techniques difficult. Successful spatio-temporal fusion strategies often involve sophisticated deep learning architectures that learn complex relationships between spatially neighboring pixels and temporally adjacent spike events. Effective fusion methods typically employ attention mechanisms or recurrent neural networks to model long-range dependencies within the spatio-temporal domain. The aim is to generate high-quality, temporally consistent image sequences from the noisy and incomplete spike data. The performance of spatio-temporal fusion approaches is typically assessed using quantitative metrics such as Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) and qualitative evaluations of visual reconstruction quality. The efficiency of the fusion algorithm, in terms of computational complexity and memory usage, is also an important consideration. Ultimately, research on spatio-temporal fusion seeks to push the boundaries of high-speed, low-power vision systems that can operate in dynamic environments.
Hybrid spike encoding#
The concept of “Hybrid spike encoding” in the context of spiking neural network (SNN) image reconstruction addresses a key challenge: effectively translating asynchronous, binary spike streams from spiking cameras into a format suitable for deep learning. A purely explicit method, relying on readily interpretable statistics like the time elapsed between spikes, can be limited in capturing detailed texture. Conversely, a purely implicit method, using neural networks to directly process spike trains, might lack transparency in feature extraction. A hybrid approach aims to combine the strengths of both. Explicit encoding, perhaps using metrics like inter-spike intervals or spike counts within time windows, provides a robust and interpretable foundation. This is then augmented by implicit encoding utilizing convolutional neural networks (CNNs) to learn complex, high-dimensional representations from the spike data, thereby capturing subtle nuances in texture. The hybrid model benefits from the robustness and interpretability of explicit methods and the power and flexibility of implicit methods for enhanced accuracy and efficiency in reconstructing high-quality images from spiking camera data.
STIR Network#
The Spatio-Temporal Interactive Reconstruction (STIR) network presents a novel approach to image reconstruction from spiking camera data. Instead of the typical sequential processing of spike embedding, motion estimation, and intensity recovery, STIR integrates these steps into a unified, interactive framework. This allows for a more efficient and effective use of spatio-temporal information, leading to improved reconstruction quality. A key innovation is the joint refinement of inter-frame feature alignment and intra-frame feature filtering. The network employs a hybrid spike embedding representation to effectively bridge the gap between raw spike data and deep learning models. Further enhancing its capabilities are the symmetric interactive attention block and multi-motion field estimation block, both designed to strengthen the interplay between temporal and spatial information. STIR demonstrates superior performance and efficiency compared to existing methods, achieving significant gains in PSNR while maintaining low computational complexity. Its architecture exhibits flexibility with adjustable parameters allowing for customization based on hardware constraints and performance goals. The overall approach emphasizes the inherent synergy of spatio-temporal cues in spiking camera data, showcasing a significant advance in efficient and high-quality image reconstruction.
Ablation studies#
Ablation studies systematically assess the contribution of individual components within a machine learning model. In this context, it is likely the authors systematically removed or altered specific parts of their proposed spatio-temporal interactive reconstruction (STIR) network to understand their impact on the overall performance. This could involve removing modules such as the hybrid spike embedding, the symmetric interactive attention block, or the multi-motion field estimation block. By evaluating the effect of each ablation on metrics like PSNR, SSIM, and LPIPS, they gain critical insights into the effectiveness and necessity of each component. The results from these experiments justify design choices and highlight the key elements that contribute significantly to the model’s high accuracy and efficiency. The ablation study helps determine what aspects of the model are most important, leading to more efficient model designs and a deeper understanding of the model’s internal workings. It’s valuable to note that a well-designed ablation study provides a strong basis for demonstrating the model’s robustness and explaining its improved performance over existing methods. It offers a level of transparency about the model’s architecture and functionality that enhances the credibility of the research.
Future work#
The paper’s lack of a dedicated ‘Future Work’ section is notable. However, based on the content, several promising avenues for future research emerge. Extending the STIR framework to handle extremely low-light conditions is crucial given that current methods struggle with limited accumulated light intensity. Improving robustness to noise and motion blur, especially in challenging scenarios like fast-moving objects and occlusions, is another key area. Exploring more advanced motion estimation techniques, such as incorporating optical flow methods, could enhance the accuracy of inter-frame alignment. Investigating the effectiveness of different architectures, and comparing STIR with other neural network architectures, beyond CNNs, would also be valuable. Finally, the authors’ mention of potential limitations suggests that investigating the model’s behavior in other real-world scenarios and on a wider range of datasets could provide valuable insights into its generalization capabilities and further improve its performance.
More visual insights#
More on figures
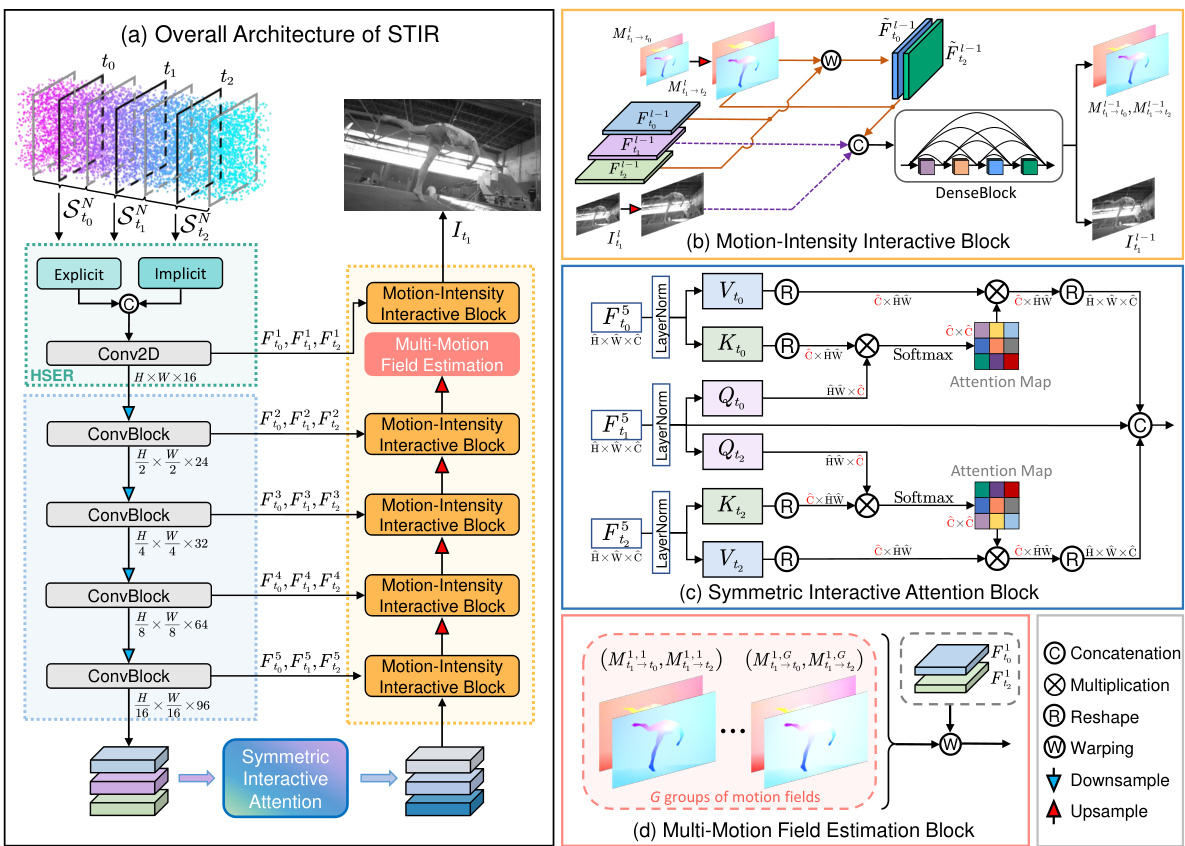
This figure provides a detailed overview of the proposed Spatio-Temporal Interactive Reconstruction (STIR) network architecture. It shows the overall framework, highlighting the key components: the hybrid spike embedding representation (HSER), the hierarchical feature encoder, the spatio-temporal interactive decoder with motion-intensity interactive blocks, the symmetric interactive attention block, and the multi-motion field estimation block. The figure illustrates how the network processes spike streams from a spiking camera to generate high-quality intermediate frames. The color-coded lines indicate feature flow and processing, showcasing the network’s coarse-to-fine refinement strategy.

This figure compares the image reconstruction results of different methods on synthetic and real datasets. The top row shows results for a synthetic dataset, while the bottom row shows results for a real-captured dataset. The results show that the proposed method outperforms the existing methods in terms of accurately reconstructing the boundaries of fast-moving objects.

This figure shows a qualitative comparison of different image reconstruction methods on both synthetic and real-captured datasets. The top row presents results from a synthetic dataset, while the bottom row shows results from real-world data captured by a spiking camera. The figure highlights the superior performance of the proposed STIR method (Ours) in accurately reconstructing the boundaries of fast-moving objects, demonstrating its ability to handle dynamic scenes effectively and with high precision. This contrasts with the results from other methods, which show more blurry or less defined edges, especially for rapidly moving objects.

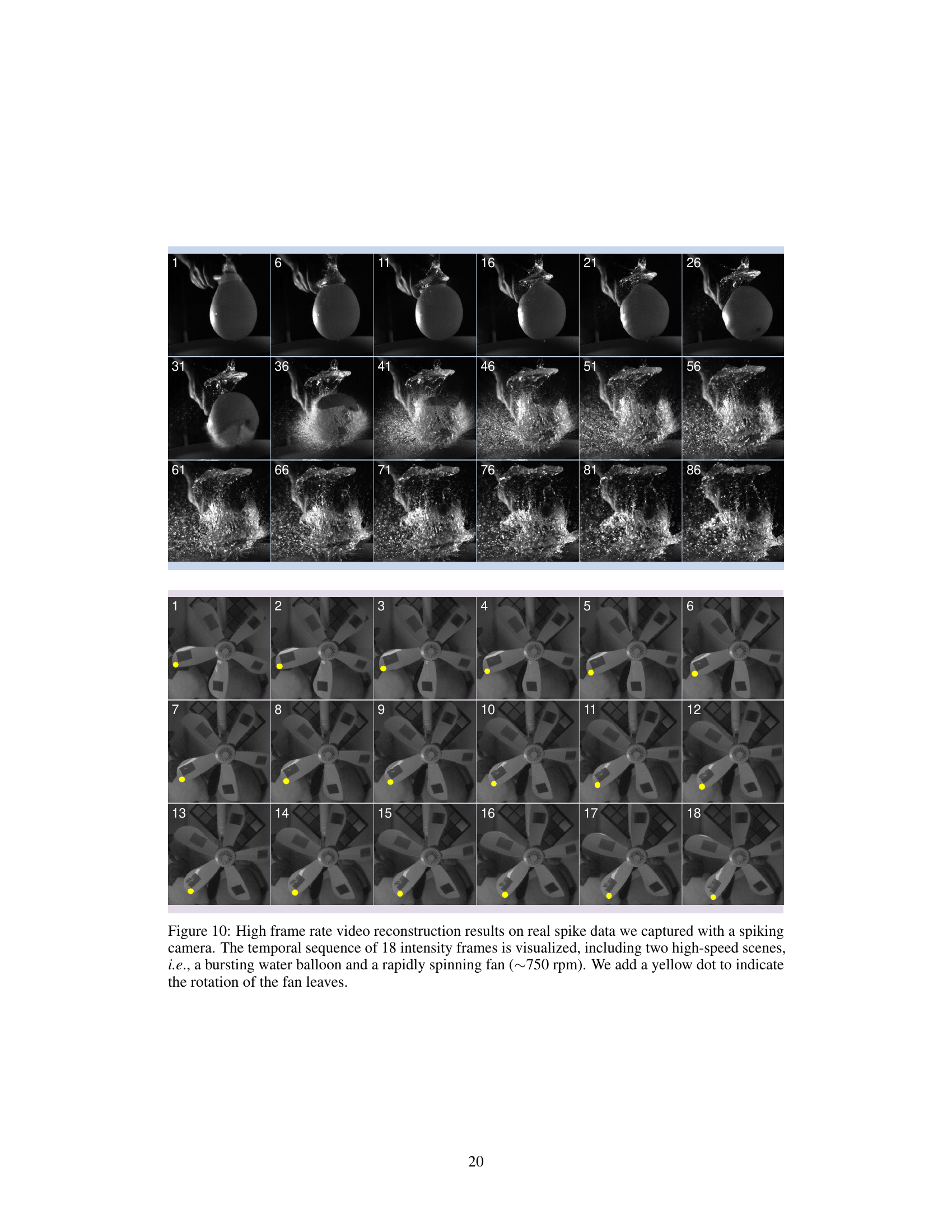
This figure shows a visual comparison of image reconstruction results on synthetic and real datasets using different methods, including the proposed STIR method. The top row presents results from the synthetic dataset, and the bottom row shows results from the real-captured dataset. Each scene contains 24 consecutive frames, and a corresponding spike stream of N=20 is centered around each frame. The figure highlights the superior performance of the STIR method in reconstructing precise boundaries and details of fast-moving objects compared to other methods.

This figure visualizes the ablation study conducted on the recVidarReal2019 dataset. It demonstrates the impact of removing key components of the proposed Spatio-Temporal Interactive Reconstruction (STIR) network on the quality of reconstructed images. The results show that each component (symmetric interactive attention block, reconstruction loss Lrec, warping-based inter-frame feature alignment, and the use of multiple motion fields) contributes to the overall performance. Removing any of these components leads to a noticeable decrease in image quality, highlighting the effectiveness of the STIR model’s full design.

This figure presents a visual comparison of image reconstruction results using different methods on both synthetic and real-world datasets. The top row shows results for a synthetic dataset, while the bottom row displays results for real-captured data. Each image shows a scene with fast-moving objects. The figure highlights the superior performance of the proposed STIR method in accurately reconstructing the details and boundaries of these moving objects, emphasizing its improved fidelity compared to existing state-of-the-art methods. The detailed captions under the images indicate the methods used for reconstruction.

This figure shows a visual comparison of image reconstruction results between the proposed method and several state-of-the-art methods using both synthetic and real datasets. The top row displays results from synthetic data, while the bottom row showcases results obtained from real-world spiking camera data. Yellow boxes highlight the regions of interest, and the results show that the proposed method is superior in reconstructing precise boundaries of fast-moving objects, indicating higher fidelity compared to other methods.

This figure compares two different approaches for spike-to-image reconstruction. (a) shows the traditional step-by-step method, which involves separate modules for spike embedding, motion estimation, and intensity recovery. (b) illustrates the authors’ proposed method, which integrates motion and intensity estimation within a unified framework, using a novel hybrid spike embedding representation (HSER) to bridge the gap between raw spike data and the deep learning model. The new method aims for more efficiency and better performance.
More on tables

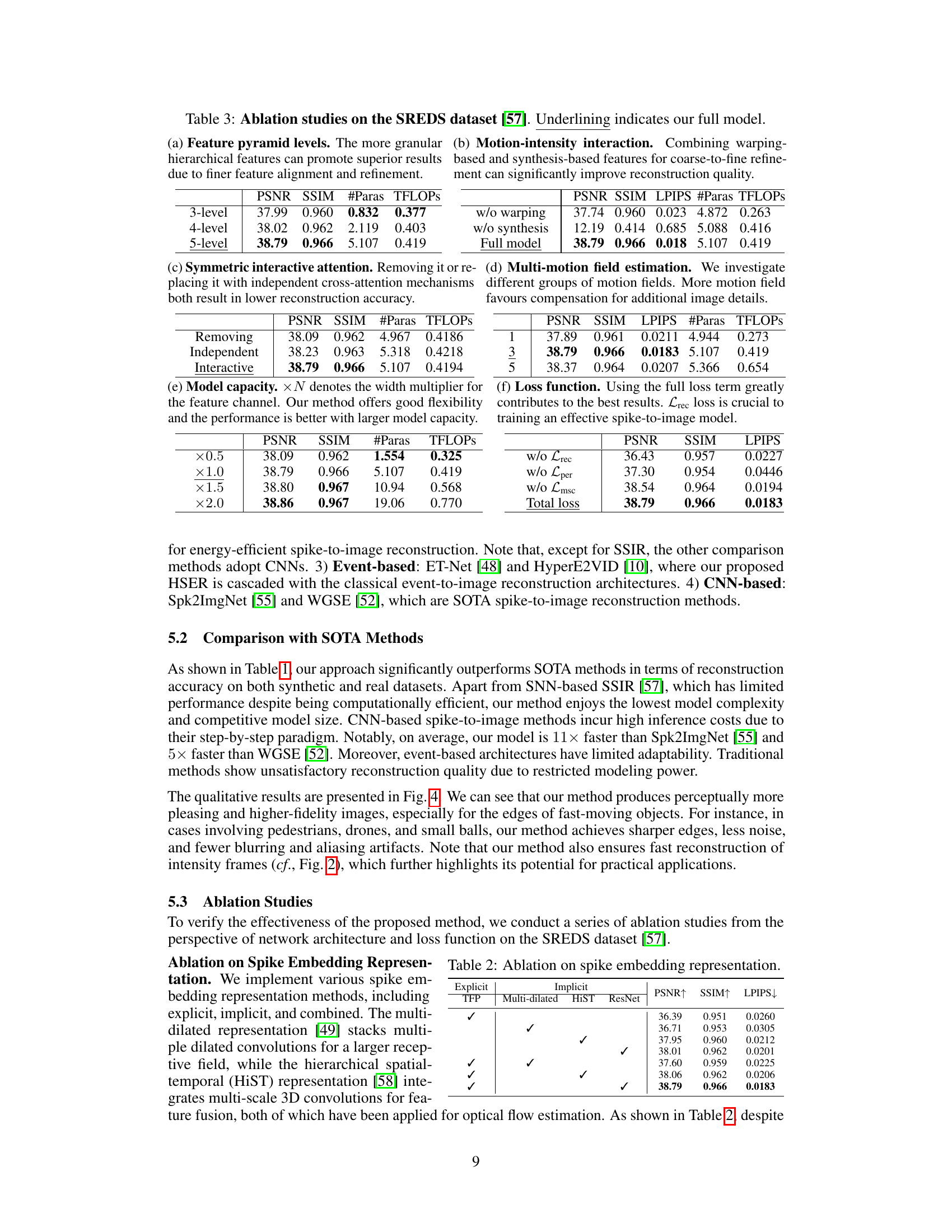
This table presents the ablation study results on the SREDS dataset to analyze the impact of different components of the proposed Spatio-Temporal Interactive Reconstruction (STIR) network. It systematically investigates the effects of varying the number of feature pyramid levels, the interplay of motion and intensity interactions, different attention mechanisms, the number of motion fields, model capacity, and the loss function components. Each row shows the performance (PSNR, SSIM, LPIPS, #Paras, TFLOPS) obtained with a specific configuration.

This table presents the ablation study results on the SREDS dataset to analyze the impact of different components of the proposed STIR model. It shows the effect of varying the number of pyramid levels, the type of motion-intensity interaction, the use of symmetric interactive attention, the number of motion fields, the model capacity, and the loss function on the model’s performance (PSNR, SSIM, #Paras, TFLOPs). The full model is highlighted by underlining.
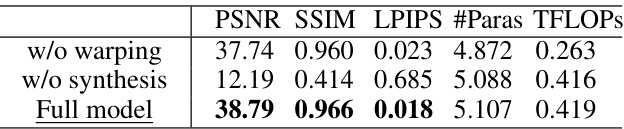
This table presents ablation studies conducted on the SREDS dataset to analyze the impact of different design choices on the performance of the proposed Spatio-Temporal Interactive Reconstruction (STIR) network. Specifically, it examines the effects of varying the number of feature pyramid levels, the interaction between motion and intensity, the use of symmetric interactive attention, the number of multi-motion fields, model capacity, and the loss function components. The results demonstrate the contribution of each component to the overall performance of the STIR network.
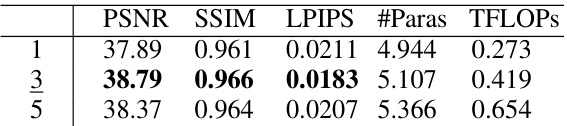
This table presents the ablation study results performed on the SREDS dataset to analyze the impact of different components on the proposed Spatio-Temporal Interactive Reconstruction (STIR) network. It shows the effect of varying the number of feature pyramid levels, using motion-intensity interaction, employing symmetric interactive attention, using multi-motion field estimation, adjusting model capacity, and using different loss functions on the model’s PSNR, SSIM, LPIPS, number of parameters and TFLOPs.
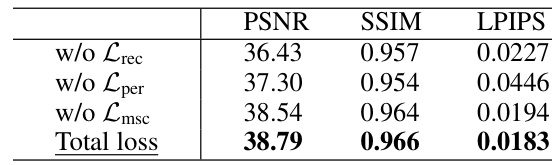
This table presents the ablation study results performed on the SREDS dataset to analyze the impact of different components of the proposed STIR model. It shows the effects of changing the number of feature pyramid levels, the inclusion or exclusion of motion-intensity interaction, symmetric interactive attention, multi-motion field estimation, model capacity, and the loss function components.
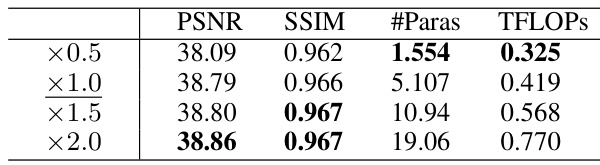
This table presents ablation studies performed on the SREDS dataset to analyze the impact of different components of the proposed STIR model on its performance. It examines the effects of varying the number of feature pyramid levels, the combination of warping-based and synthesis-based features, the use of symmetric interactive attention, the number of motion fields, the model capacity (width multiplier), and the loss function components on PSNR, SSIM, the number of parameters, and TFLOPs.
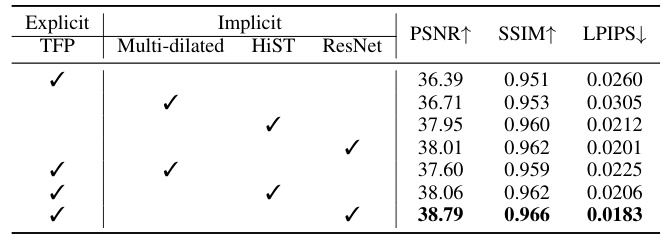
This table presents the ablation study on different spike embedding representation methods. It compares the performance (PSNR, SSIM, LPIPS) of using explicit methods (TFP), implicit methods (Multi-dilated, HiST, ResNet), and combinations of explicit and implicit methods. The results show that combining explicit and implicit methods, specifically using TFP and ResNet, yields the best performance.
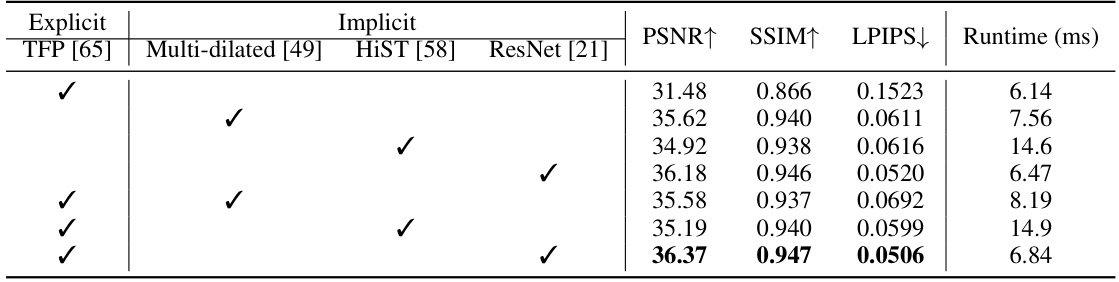
This table compares the proposed STIR method against state-of-the-art (SOTA) image reconstruction methods on both synthetic (SREDS) and real-captured datasets. The comparison includes performance metrics (PSNR, SSIM, LPIPS, NIQE, BRISQUE), model parameters, GPU memory usage, and FLOPs. The results highlight that STIR achieves superior performance while maintaining low model complexity and efficiency.
Full paper#