↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many 3D perception systems use multi-modal data (like LiDAR and cameras) to improve accuracy. However, this adds complexity and slows down processing. Cross-modal knowledge distillation (KD) offers a solution by training simpler single-modal models using insights from complex multi-modal ones. Existing KD methods, however, often have limited versatility and struggle to bridge the gap between different sensor types.
VeXKD solves this by introducing a modality-general fusion module and a novel mask generation network. This module effectively transfers knowledge to single-modal students without extra processing time, significantly improving accuracy in various 3D tasks (object detection and map segmentation). The data-driven spatial masks focus the knowledge transfer on the most important features, maximizing efficiency and making the framework suitable for diverse 3D perception tasks and future advancements.
Key Takeaways#
Why does it matter?#
This paper is important because it presents VeXKD, a novel and versatile framework that effectively integrates cross-modal fusion and knowledge distillation for 3D perception. This addresses the limitations of existing methods by improving the accuracy of single-modal student models without increasing inference time and by enhancing the versatility of KD algorithms. It opens new avenues for research in improving the efficiency and accuracy of 3D perception systems, particularly for autonomous driving applications.
Visual Insights#
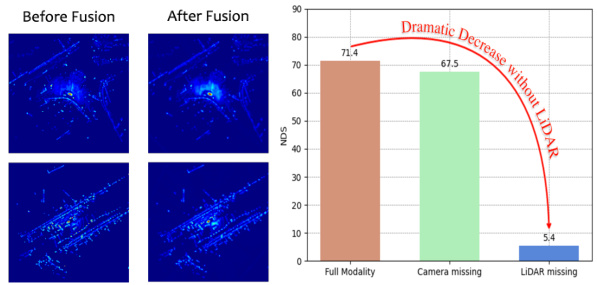
This figure shows a visualization of BEVFusion’s feature maps before and after fusion, illustrating minimal information gain from the fusion process. The bar chart highlights a significant drop in performance (NDS score) when LiDAR data is missing, emphasizing the model’s heavy reliance on LiDAR-specific information rather than general multi-modal features.
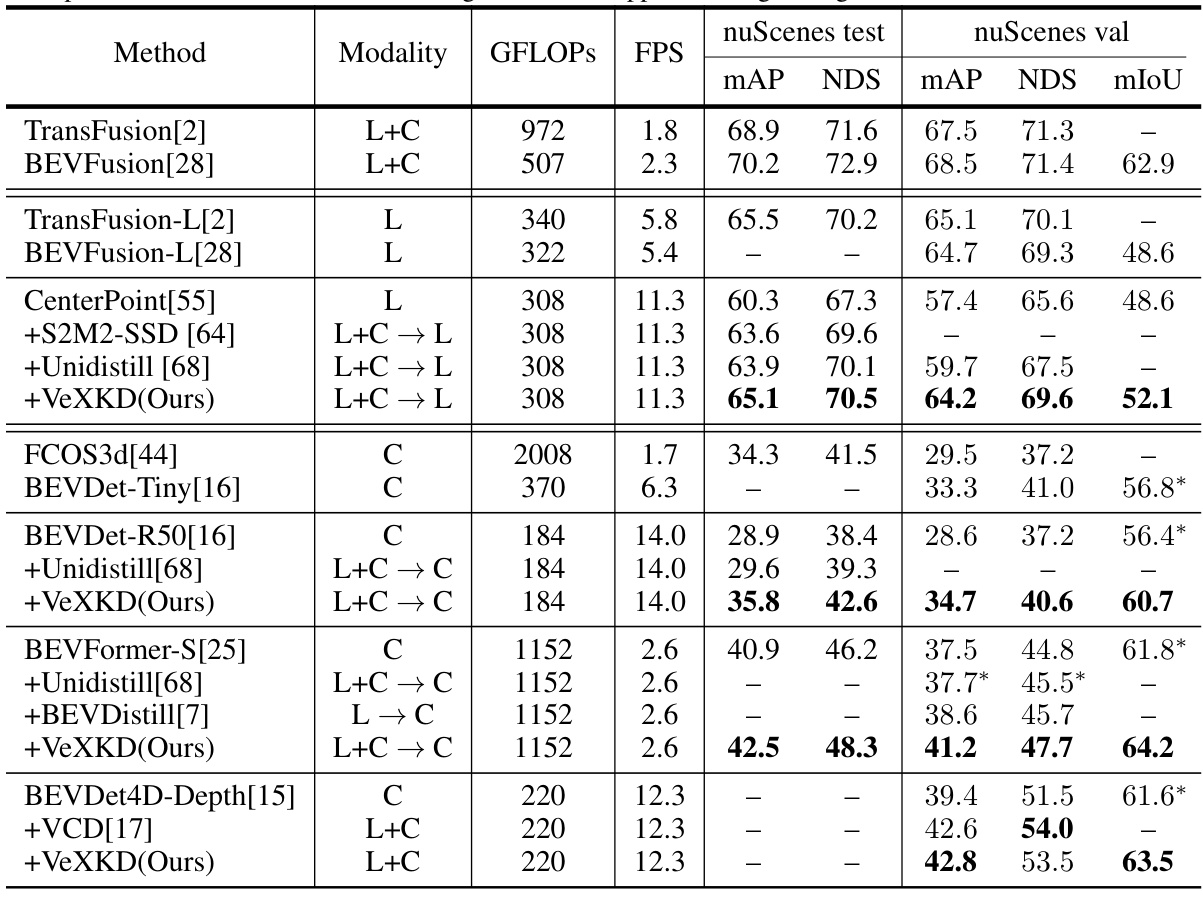
This table presents a comparison of the performance of VeXKD against several state-of-the-art methods on the nuScenes dataset for 3D object detection and BEV map segmentation tasks. It shows various metrics (mAP, NDS, mIoU, FPS, GFLOPS) for different model configurations, including single-modal (LiDAR or Camera only), multi-modal, and models using knowledge distillation with VeXKD. The results illustrate the effectiveness of VeXKD in improving performance and closing the gap between single-modal and multi-modal models. Note that the FPS (Frames Per Second) numbers are specific to the hardware (GTX 4090 GPU) and batch size used.
In-depth insights#
Cross-Modal Fusion#
Cross-modal fusion, in the context of 3D perception, aims to synergistically combine data from different sensor modalities, such as LiDAR and cameras, to achieve more robust and accurate scene understanding. The core challenge lies in effectively integrating inherently disparate data representations. LiDAR provides sparse 3D point cloud data representing distances and object locations, while cameras capture rich 2D images encoding color, texture, and visual context. Successful fusion strategies must address these differences to leverage the strengths of each modality, compensating for individual limitations. Methods explored often involve transforming data into a shared representation space (such as a bird’s-eye view), followed by feature-level or decision-level fusion. Effective fusion hinges on the alignment of data and the identification of complementary information, reducing redundancy while amplifying perceptual richness. This process is crucial for applications like autonomous driving, where reliable and real-time scene interpretation is paramount. Recent advancements have focused on transformer-based architectures and attention mechanisms, enabling more flexible and context-aware fusion processes.
Masked KD#
Masked Knowledge Distillation (KD) is a technique that selectively transfers knowledge from a teacher model to a student model, focusing on specific, relevant parts of the feature maps. Instead of distilling knowledge from the entire feature map, which can include noise and irrelevant information, masked KD employs a mask to identify and select the most crucial regions, thus improving the effectiveness and efficiency of the distillation process. This masking strategy often involves learning a data-driven mask, adapting to the specific characteristics of both teacher and student models, and different downstream tasks. The mask generation process itself can be learned, becoming an integral part of the KD framework, making it more adaptable and versatile. By focusing only on essential information, masked KD mitigates the challenges associated with capacity discrepancies and information gaps between teacher and student. The outcome is a student model that achieves improved performance with potentially reduced computational costs. In essence, masked KD refines traditional KD by intelligently filtering knowledge transfer, leading to more robust and efficient model training.
BEV Feature Distillation#
The concept of “BEV Feature Distillation” in 3D perception research involves transferring knowledge from a teacher model’s Bird’s Eye View (BEV) feature maps to a student model. This is crucial because multi-modal models (teachers) often achieve high accuracy but lack real-time performance. Distillation focuses on transferring only the most valuable information, reducing computational overhead. A key challenge is bridging the modality gap, where teacher and student models use different sensor inputs (e.g., LiDAR vs. camera). Effective methods address this by using modality-general fusion modules or focusing on BEV features, which are representation-friendly across modalities. The approach also incorporates data-driven spatial masks, dynamically selecting the most relevant parts of the teacher’s BEV maps for knowledge transfer. This adaptive masking further improves efficiency and accuracy. The result is a versatile and effective training strategy that enhances the capabilities of single-modal student models while maintaining computational efficiency.
Modality-General Fusion#
The concept of ‘Modality-General Fusion’ in the context of multi-modal 3D perception is crucial for robust and accurate scene understanding. It addresses the challenge of effectively combining data from disparate sources like LiDAR and cameras, which have different strengths and weaknesses. A modality-general approach is superior to modality-specific fusion because it avoids over-reliance on a single sensor type. A truly modality-general fusion model would leverage the complementary information from all modalities equally, rather than prioritizing one over others. This leads to improved robustness against sensor failures and enhances the overall performance across various downstream tasks. The core of such an approach likely involves a fusion architecture that is agnostic to the specific sensor type, operating on a common representation (like the Bird’s Eye View). Key design considerations would include techniques that address potential modality misalignment and ensure fair representation of all modalities within the fusion process. Successful implementation could significantly improve the reliability and accuracy of 3D perception systems, making them less susceptible to noise and more capable of handling challenging scenarios in autonomous driving and robotics.
VeXKD Limitations#
VeXKD, while demonstrating strong performance improvements, has inherent limitations. The modality-general fusion module, although designed for versatility, might underperform compared to highly specialized fusion methods tailored for specific sensor combinations. The data-driven mask generation relies on the fusion byproducts; inaccuracies in the fusion process could negatively impact the quality of generated masks, thus affecting feature distillation. The approach’s effectiveness relies on the teacher model’s capability; a suboptimal teacher could hinder the transfer of knowledge, limiting the student model’s improvements. Furthermore, the framework’s evaluation is primarily focused on the nuScenes dataset, restricting the generalizability to other datasets with different characteristics. Finally, extensive computational resources are needed for training, especially when dealing with high-resolution inputs and multiple modalities, potentially hindering wider adoption. Future work should address these limitations to enhance robustness and expand applicability.
More visual insights#
More on figures

This figure illustrates the overall architecture of the VeXKD framework, which integrates cross-modal fusion and knowledge distillation. It shows how a modality-general fusion module combines LiDAR and camera inputs to create a BEV (Bird’s Eye View) feature map. This BEV feature map then undergoes masked feature distillation, where learned masks guide the knowledge transfer to single-modal student models for different perception tasks (e.g., 3D object detection, BEV map segmentation). The design is intended to be versatile and work across different model architectures.

This figure illustrates the process of BEV query guided mask generation and masked feature distillation. The (a) part shows the transformer-based mask generation block utilizing fusion module byproducts as a query. (b) illustrates the deformable cross-attention mechanism where the query identifies key spatial locations in teacher feature maps. Finally, (c) depicts the masked feature distillation stage, where learned masks are applied to both teacher and student features before calculating the distillation loss.

This figure illustrates the architecture of the Modality-General Fusion Module (MGFM), a key component of the VeXKD framework. The MGFM uses a transformer-based architecture with deformable attention mechanisms to fuse features from LiDAR and camera modalities in the BEV (Bird’s Eye View) space. Panel (a) shows the overall structure. Panel (b) details the deformable cross-modal attention, highlighting how the learnable BEV query interacts symmetrically with LiDAR and camera features to extract modality-general information. Panel (c) illustrates the deformable query self-attention mechanism, which allows the BEV query to interact with itself, integrating correlational relationships among features and improving the accuracy and semantic richness of the fused BEV features.
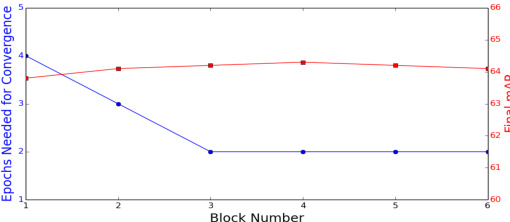
This ablation study examines the impact of varying the number of transformer blocks within the mask generation network on the model’s performance. The graph shows that increasing the number of blocks beyond two does not significantly improve the final mAP (mean Average Precision), while the number of epochs needed to achieve convergence decreases. This suggests that a balance must be struck, and three blocks are chosen as the optimal configuration in the paper. The experiment is conducted on the nuScenes validation set.

This figure visualizes the spatial masks generated by the BEV Query Guided Mask Generation module for different feature levels (low and high) and tasks (object detection and BEV segmentation). The masks are learned in a data-driven manner and highlight specific regions of the feature maps deemed most relevant for downstream tasks. For object detection, the masks emphasize areas around ground truth object locations, especially for low-level features. For BEV segmentation, the masks also highlight background features. This adaptive mask generation is key to the effectiveness of the knowledge distillation process.

This figure compares feature maps from a camera and LiDAR before and after knowledge distillation (KD). The left shows the original feature maps, while the right shows the feature maps after applying KD. The results indicate that KD improves the camera feature maps by making the depth projection more deterministic. Additionally, KD enhances the LiDAR feature maps by highlighting crucial spatial features, which improves the overall accuracy of 3D perception.

This figure illustrates the overall architecture of the VeXKD framework. It shows how a modality-general fusion module combines LiDAR and camera data into a unified BEV representation. This fused representation is then used by a masked feature distillation method to transfer knowledge to single-modal student models. The key innovation is the use of learned masks, generated from the fusion process, that focus the distillation on the most informative parts of the teacher model’s feature maps. The framework is designed to be versatile and adaptable to various student modalities and downstream tasks.

This figure shows a comparison of feature maps before and after knowledge distillation (KD). The left two images show camera feature maps, where the leftmost image is before KD and the other is after KD. Similarly, the rightmost two images display LiDAR feature maps before and after KD. The results demonstrate that KD enhances the quality of camera features by improving the accuracy of the depth projection and enhances the quality of LiDAR features by highlighting their importance and correlating them with textual information from the images.

This figure visualizes the BEV feature maps for both camera and LiDAR modalities before and after applying knowledge distillation (KD). For camera features, KD improves depth estimation, leading to a more organized and accurate feature map compared to the chaotic distribution seen without KD. For LiDAR features, KD enhances the correlation between point cloud distribution and image texture, improving visualization of crucial areas and partially mitigating the sparsity issue at longer distances.
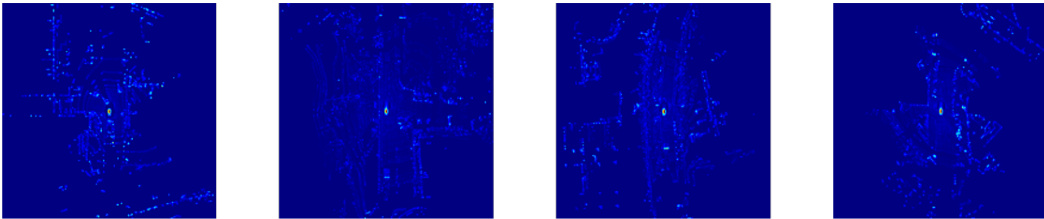
This figure visualizes the BEV feature maps for both camera and LiDAR modalities, comparing the results before and after applying knowledge distillation (KD). The top row shows camera features, demonstrating how KD improves the depth information by creating a more deterministic and less chaotic feature distribution. The bottom row illustrates LiDAR features, showing that KD enhances the key features by highlighting important information that was less clear in the original LiDAR data. The enhanced features are more spatially localized and easier to interpret for perception tasks.

This figure visualizes the BEV (Bird’s Eye View) feature maps for both camera and LiDAR modalities before and after knowledge distillation (KD). For camera-based features, the differences highlight the improved depth estimation accuracy and more deterministic depth projection after KD, resulting in less chaotic depth distribution. For LiDAR-based features, the improved correlation between point cloud distribution and camera textural information is shown by the enhanced visibility of key features and reduction in sparsity, especially in areas further away.

This figure shows a comparison of 3D object detection results before and after applying knowledge distillation. The left side displays the results from a camera-based model, and the right side shows the results from a LiDAR-based model. In both cases, the use of knowledge distillation leads to improvements in the accuracy and reliability of the object detection results. Specifically, the camera-based model benefits from increased confidence in depth estimations, while the LiDAR-based model achieves better recognition and classification, especially for objects at longer distances.

This figure shows a comparison of the detection results before and after applying knowledge distillation to both camera and LiDAR-based student models. The left side demonstrates the results obtained using camera images, while the right side displays the results using LiDAR point clouds. In both cases, the improved accuracy and robustness of the models after applying knowledge distillation are apparent, as indicated by the tighter bounding boxes and more accurate positioning of detected objects.

This figure shows a comparison of the 3D object detection results before and after applying knowledge distillation to both camera and LiDAR-based student models. The top two images show a camera view, and the bottom two show a LiDAR view. In each pair, the left image displays the detection result before KD and the right image shows the result after KD. The improvements in detection accuracy and localization are clearly visible after the application of KD. Specifically, the camera-based detection shows improved depth estimation accuracy, and the LiDAR-based detection shows enhanced localization, especially for objects at greater distances.

This figure shows a comparison of 3D object detection results before and after applying knowledge distillation. The top row shows the results for a camera-based model, and the bottom row shows the results for a LiDAR-based model. In both cases, the knowledge distillation improves the accuracy of the detection results, particularly in terms of reducing false positives and enhancing the accuracy of bounding boxes, especially for objects at a distance or partially occluded.

This figure visually compares the segmentation results obtained from camera and LiDAR modalities before and after applying knowledge distillation. The top row shows the ground truth segmentation labels for both camera and LiDAR. The second row displays the segmentation results from the camera modality before applying knowledge distillation, showing inaccuracies and boundary blurring. The third row presents the improved segmentation results from the camera modality after applying knowledge distillation, demonstrating enhanced boundary definition and more precise segmentation. The bottom row shows the segmentation results from the LiDAR modality before and after applying knowledge distillation. The results indicate that knowledge distillation enhances the accuracy of both camera and LiDAR-based segmentation, especially in regions with sparse data points.

This figure visualizes the segmentation results for both camera and LiDAR modalities, comparing the results before and after applying knowledge distillation. The top row shows the ground truth segmentation labels. The middle row shows the camera segmentation results before applying knowledge distillation, illustrating inaccuracies, particularly in boundary delineation. The bottom row demonstrates the improved accuracy and boundary definition in the camera segmentation after knowledge distillation. The LiDAR segmentation results show similar improvements from knowledge distillation, particularly in reducing hallucinations and improving the definition of less prominent features and background areas.

This figure visualizes the segmentation results for both camera and LiDAR modalities before and after applying knowledge distillation. It highlights how knowledge distillation improves the accuracy of depth estimation in camera-based segmentation and enhances background details in LiDAR-based segmentation by correlating camera textural information and point cloud distribution.

This figure visualizes the segmentation results for both camera and LiDAR modalities, comparing the results before and after applying knowledge distillation (KD). It shows the ground truth segmentation labels alongside the model’s predictions before and after KD. The comparison highlights how KD improves the accuracy of segmentation, especially for camera data (reducing boundary blur) and LiDAR data (improving background accuracy and mitigating sparsity issues).

This figure visually compares the segmentation results for both camera and LiDAR modalities, before and after applying knowledge distillation. It highlights the improvements in boundary delineation and background representation achieved through the knowledge distillation process. The camera modality benefits from improved depth estimation, while the LiDAR modality shows enhanced background representation and reduced misclassifications. The comparison showcases the effectiveness of the proposed approach in improving the accuracy and quality of BEV map segmentation for both modalities.
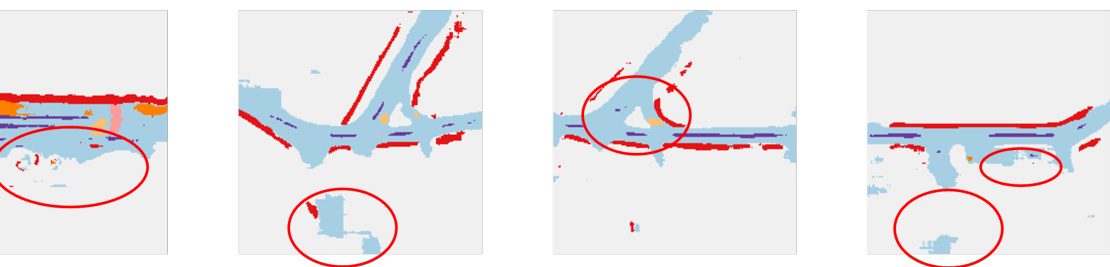
This figure visualizes the segmentation results for both camera and LiDAR modalities, comparing the results before and after applying the proposed knowledge distillation (KD) method. The top row shows the ground truth segmentation labels, providing a basis for comparison. The middle row displays the camera-based segmentation before KD, highlighting areas where the model struggles with boundary delineation and accuracy. The bottom row showcases the LiDAR-based segmentation before KD, demonstrating challenges with sparsity and accurate background representation. The red circles highlight specific regions of interest where the improvements made by the KD method are most evident. The results demonstrate that the KD method enhances both the camera and LiDAR-based segmentation, improving boundary delineation and accuracy, as well as reducing errors in areas with sparse point clouds or a lack of features.

This figure visualizes the results of BEV map segmentation for both camera and LiDAR modalities, comparing the results before and after applying knowledge distillation (KD). The top row shows the ground truth segmentation labels. The middle rows demonstrate the camera-based segmentation results: the first showing the results before applying KD, and the second showing the results after. Similarly, the bottom rows show the LiDAR-based segmentation results, also before and after KD. The red circles highlight areas where the KD significantly improves the segmentation accuracy by enhancing the details and reducing inaccuracies, particularly in areas with sparse data or ambiguous boundaries. The comparison helps illustrate how KD improves the quality and precision of segmentation in various scenarios.
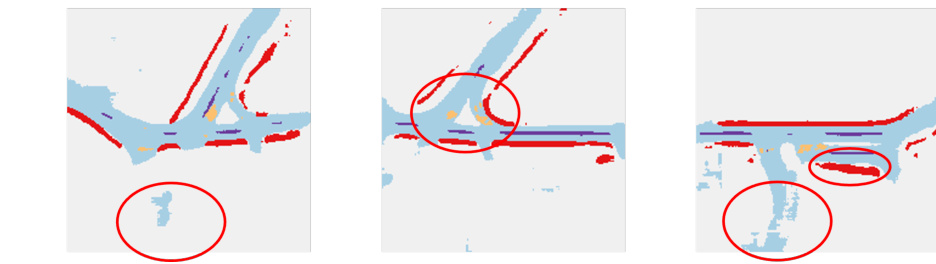
This figure shows a comparison of segmentation results for camera and LiDAR modalities before and after applying knowledge distillation. The top row displays ground truth segmentation labels, followed by the results from camera-only segmentation (before and after KD), and LiDAR-only segmentation (before and after KD). The red circles highlight areas where the knowledge distillation process significantly improves the accuracy of segmentation results.
More on tables
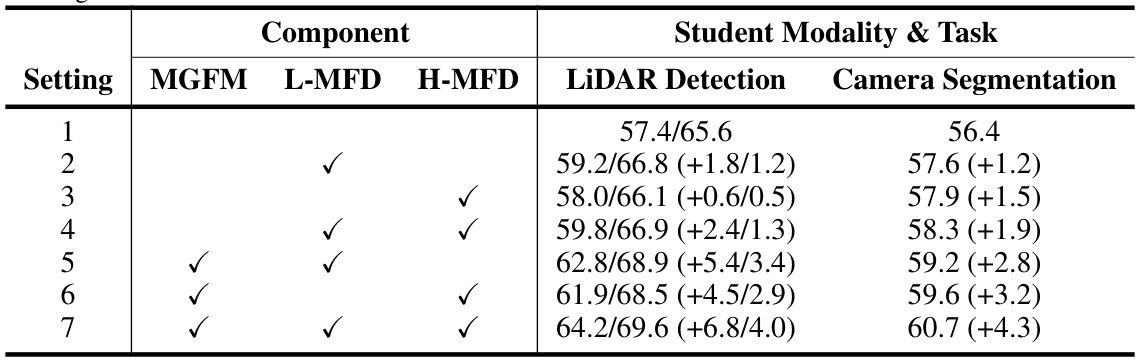
This ablation study shows the individual and combined effects of the Modality-General Fusion Module (MGFM), Low-level Masked Feature Distillation (L-MFD), and High-level Masked Feature Distillation (H-MFD) on the performance of LiDAR detection and Camera Segmentation tasks. The results demonstrate that each component contributes to improved performance, and their combined effect leads to the best overall results. The numbers in parentheses show the improvement over the baseline (Setting 1).
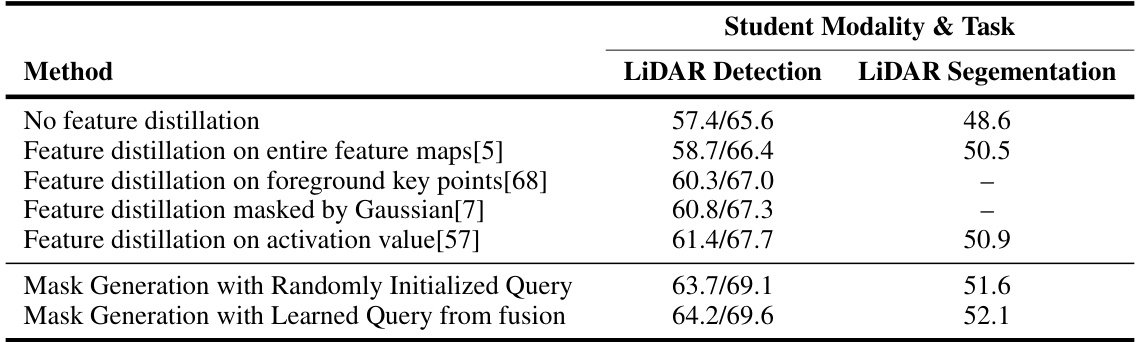
This table presents the results of an ablation study comparing different mask selection methods for feature distillation on the nuScenes validation set. It compares the performance (mAP and NDS for LiDAR detection, mIoU for LiDAR segmentation) of several methods: no feature distillation, feature distillation on the entire feature map, feature distillation on foreground key points, feature distillation masked by Gaussian, and feature distillation based on activation values. Finally, it contrasts these methods with two versions of mask generation using either randomly initialized or learned queries from the fusion module.

This table presents a comparison of the performance of VeXKD and several state-of-the-art methods on the nuScenes dataset for 3D object detection and BEV map segmentation. It shows metrics such as mAP, NDS, and mIoU for different modalities (LiDAR, Camera, and Fusion), highlighting the improvements achieved by VeXKD through cross-modal knowledge distillation. The table also includes GFLOPS and FPS for different models.
Full paper#



















