↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep learning models often exhibit strong generalization despite nearly memorizing training data—a phenomenon poorly understood. This paper focuses on the generalizability of memorization neural networks, a crucial aspect of this complex problem. Existing studies primarily focus on the number of parameters needed for memorization; however, they lack theoretical analysis of the memorization networks’ generalizability, leaving a significant knowledge gap. The central issue addressed is the need to bridge the gap between memorization and generalization, particularly in the context of over-parameterized models.
This research addresses this gap by providing a formal theoretical framework for studying the generalizability of memorization neural networks. The authors introduce the concepts of memorization parameter complexity and efficient memorization sample complexity to analyze the structural conditions and sample size needed for generalizability. They develop algorithms for constructing memorization networks with the smallest number of parameters and provide lower and upper bounds for sample complexity. Crucially, they demonstrate that commonly used memorization network structures may lack generalizability. This paper’s findings provide valuable guidance to researchers in designing efficient and generalizable memorization algorithms and understanding the implications of over-parameterization in deep learning.
Key Takeaways#
Why does it matter?#
This paper is crucial because it provides the first theoretical analysis of memorization neural networks’ generalizability, a critical aspect of deep learning’s success. It addresses a significant gap in understanding the relationship between memorization and generalization, offering insights relevant to current over-parameterization trends. The work opens new avenues for research into efficient and generalizable memorization algorithms and sample complexity.
Visual Insights#

This table presents the accuracy of a memorization algorithm (Theorem 7.3) on MNIST for all possible binary classification tasks. Each cell (i,j) represents the accuracy of classifying images from class i versus class j.
In-depth insights#
Mem. Nets Limits#
The heading ‘Mem. Nets Limits’ suggests an exploration of the boundaries and constraints of memorization neural networks. A thoughtful analysis would delve into the capacity limits of these networks, investigating how the number of parameters, network architecture (depth and width), and the nature of the training data impact their ability to memorize information perfectly. Generalization limitations would be a crucial aspect, examining whether perfect memorization hinders the network’s capacity to generalize to unseen data. The analysis should consider different types of memorization algorithms and their respective strengths and weaknesses in terms of both capacity and generalization. Furthermore, computational constraints should be discussed, analyzing the time and resource requirements for training and deploying extremely large memorization networks. Finally, it would be valuable to consider potential theoretical limits, discussing if fundamental mathematical or computational constraints restrict the ultimate expressive power of these networks, irrespective of their size and structure.
Optimal Mem. Size#
Determining the optimal memorization size in neural networks is crucial for balancing model capacity and generalization. A smaller network might underfit, failing to capture the data’s underlying patterns, while an excessively large network risks overfitting, memorizing noise rather than meaningful information. The optimal size isn’t solely determined by the training dataset’s size (N). Factors like data dimensionality (n), data distribution characteristics (e.g., separation bound, density), and desired generalization performance significantly influence the ideal parameter count. Theoretical lower bounds often highlight the minimal parameter requirements for memorization, but these are usually insufficient for good generalization. Efficient algorithms strive to construct networks achieving memorization with the fewest parameters, frequently employing techniques like data compression and projection to reduce dimensionality. However, optimality doesn’t guarantee generalizability; even an optimally sized network might not generalize well if the data distribution is unfavorable. Research into this area often explores trade-offs, seeking practical methods that balance memorization capacity with robust generalization. This pursuit continues to be a core challenge in deep learning theory and practice.
Gen. & Width#
The heading ‘Gen. & Width’ likely refers to the interplay between generalization ability and network width in neural networks, particularly within the context of memorization. A key insight would be whether wider networks are inherently better at generalizing beyond the training data, even when perfectly memorizing it. The analysis might explore if a minimum width is necessary for generalization, considering that memorization itself doesn’t guarantee good generalization. Overly narrow networks might be prone to overfitting, even with a perfect fit to training data. Conversely, sufficient width might allow the network to learn more robust and generalizable features, despite the memorization focus. The findings could quantify a minimum width requirement for effective generalization in memorization-focused models, or show if this relationship is more nuanced and dependent on factors like dataset properties or architecture choices. The research might also consider the trade-off between generalization, width, and computational cost. A wider network is generally more computationally expensive to train and might not be practical. Investigating this trade-off is crucial for practical application.
Sample Complexity#
The concept of sample complexity is crucial in machine learning, particularly when dealing with the generalizability of memorization neural networks. The paper investigates the minimum number of training samples needed to ensure a memorization algorithm generalizes well to unseen data. It establishes both lower and upper bounds for this sample complexity, demonstrating a critical relationship between the complexity of the data distribution and the required sample size. The lower bound highlights the inherent difficulty of achieving generalization in high-dimensional spaces, showing that an exponential number of samples might be necessary in the worst-case scenario. Conversely, the upper bound offers a more optimistic perspective, suggesting polynomial sample complexity under certain conditions. A key insight is that the optimal number of parameters for memorization does not guarantee generalization; additional samples are needed to ensure robust performance on unseen data. The efficient memorization sample complexity is also introduced, considering the computational cost of the algorithm. This nuanced analysis of sample complexity provides a valuable theoretical framework for understanding the practical challenges and limits of generalizing memorization networks.
Efficient Mem. Algo#
The heading ‘Efficient Mem. Algo.’ likely refers to a section detailing efficient memorization algorithms within a machine learning context. The core idea revolves around creating neural networks that can perfectly memorize training data while maintaining good generalization capabilities on unseen data. Efficiency is key, focusing on minimizing computational costs and the number of parameters used. The algorithm’s design would prioritize speed and resource-friendliness without sacrificing accuracy. Generalization is crucial, as the algorithm must prevent overfitting to the training data and provide robust performance on new, unrelated data. The algorithm likely involves innovative techniques in network architecture, training methods, or regularization strategies to achieve this balance of efficiency and generalization. Theoretical analysis of sample complexity and computational cost would likely accompany the description of the proposed algorithm to justify its efficiency claims. The discussion might include comparisons with existing memorization algorithms to highlight the advantages of the ’efficient’ approach. The section likely concludes with experimental results demonstrating the algorithm’s efficiency and generalization performance on benchmark datasets.
More visual insights#
More on tables

This table presents the accuracy of a binary classification task on the CIFAR-10 dataset using a memorization algorithm proposed in Theorem 7.3 of the paper. Each cell (i,j) represents the accuracy achieved when using only samples from classes i and j for training and testing on those two classes. Higher values indicate better performance.
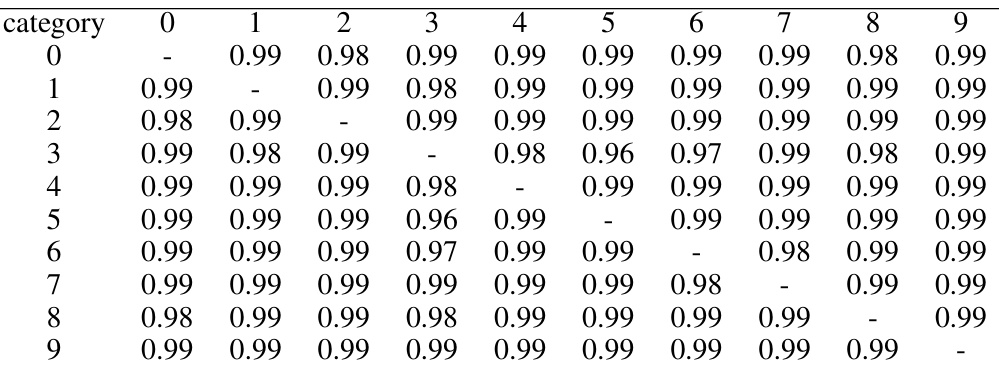
This table presents the accuracy results of a memorization algorithm (Theorem 7.3) applied to binary classification problems on the MNIST dataset. Each cell shows the accuracy of classifying one digit against another. The algorithm’s generalization performance across different pairs of digits is evaluated.

This table compares the performance of three different memorization algorithms (M1, M2, and M3) on five different pairs of MNIST digits. The accuracy of each algorithm is reported for each pair. Algorithm M1 significantly outperforms M2 and M3, suggesting its superior generalization capability.
Full paper#



















