↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current graph reasoning methods often lack generalizability and user-friendliness. While large language models (LLMs) can process graph data, they neglect the valuable visual modality crucial for human understanding. This paper aims to bridge this gap by incorporating visual graph representations.
The proposed GITA framework integrates visual graphs and textual descriptions into a unified graph reasoning system using a vision-language model (VLM). Furthermore, it introduces a new vision-language dataset, GVLQA, to facilitate the evaluation and training of such models. Experiments demonstrate that GITA outperforms existing LLMs on general graph reasoning tasks, highlighting the effectiveness of integrating visual information.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the limitations of existing graph reasoning methods by integrating visual information, a novel approach with significant implications for various fields. The introduction of the GVLQA dataset further enhances the impact by providing a benchmark for future research and promoting advancements in vision-language graph reasoning.
Visual Insights#
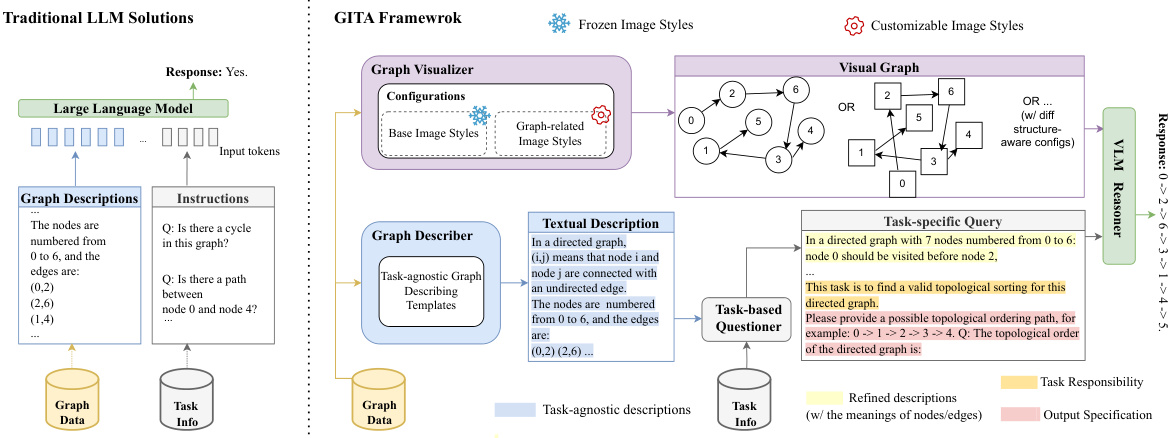
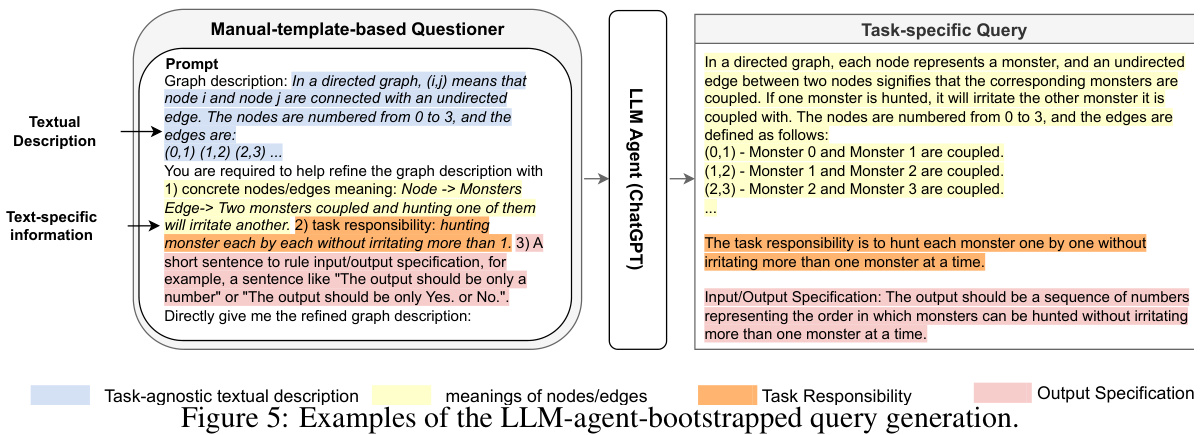
This figure illustrates the architecture of the Graph to visual and Textual Integration (GITA) framework. It compares GITA with traditional Large Language Model (LLM) solutions for graph reasoning. GITA integrates visual graph representations with textual descriptions for more effective reasoning. The figure highlights the four components of GITA: a graph visualizer, a graph describer, a task-based questioner, and a Vision-Language Model (VLM) reasoner. It shows how these components work together to process graph data and generate answers to questions.
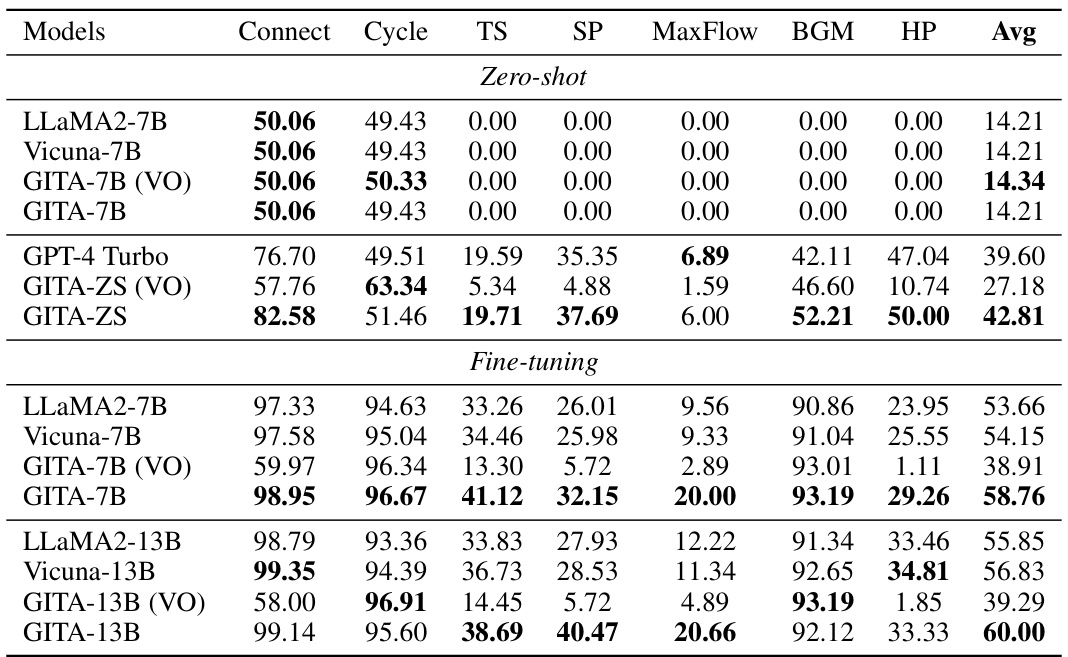
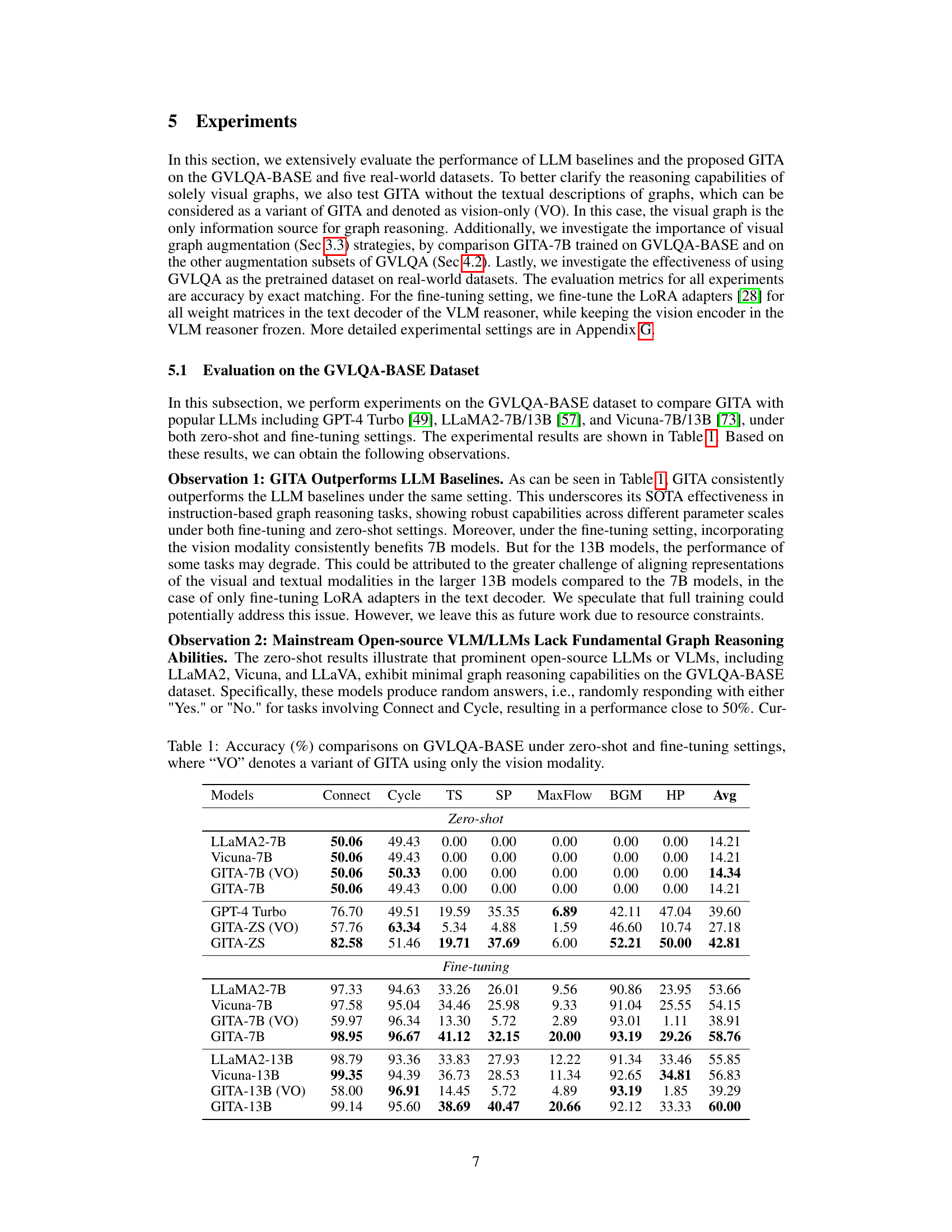
This table compares the performance of the proposed GITA framework with several popular LLMs (LLaMA2, Vicuna, GPT-4 Turbo) on the GVLQA-BASE dataset. It shows the accuracy of each model on seven different graph reasoning tasks, under both zero-shot and fine-tuning settings. The results demonstrate GITA’s superior performance, highlighting the benefits of integrating visual information into graph reasoning.
In-depth insights#
Visual Graph Augmentation#
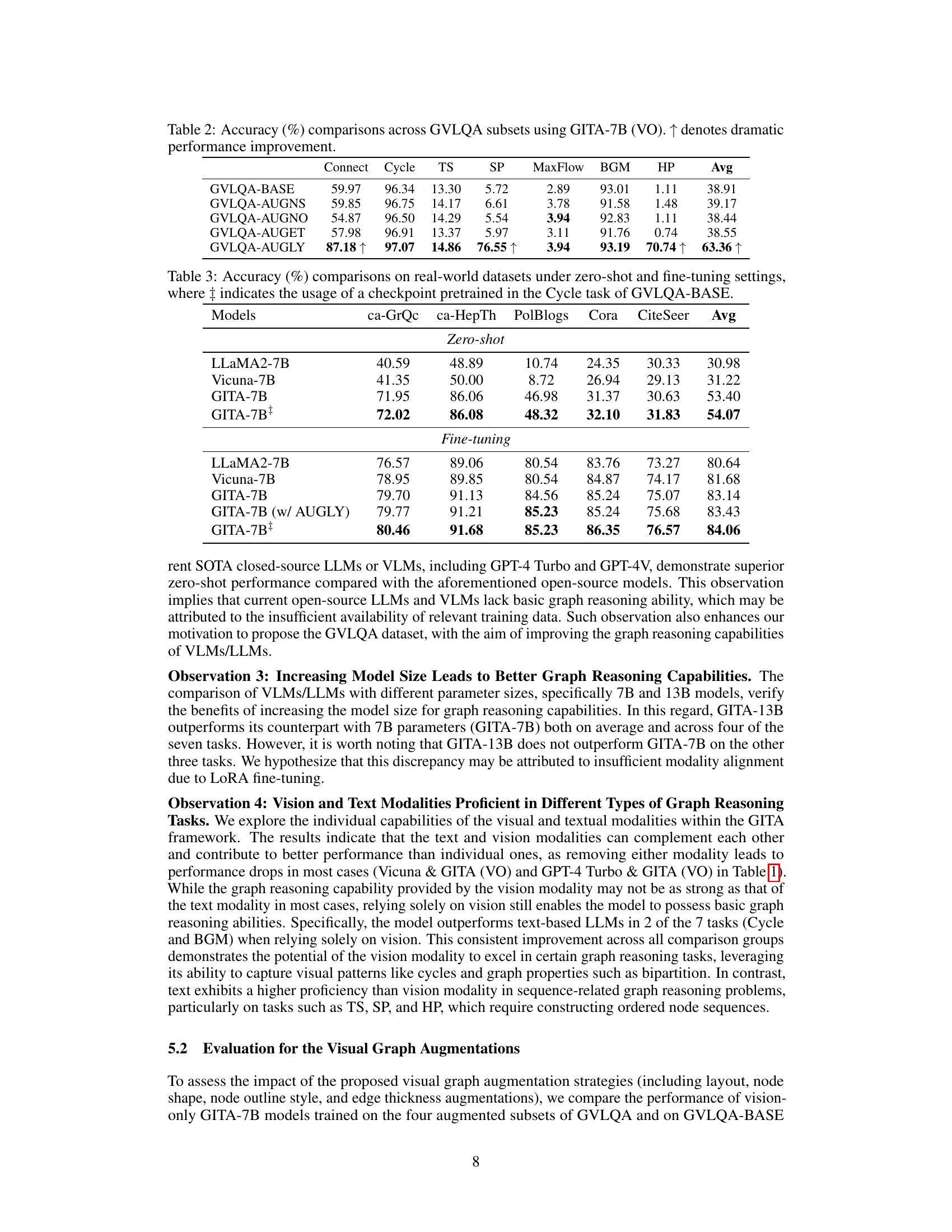
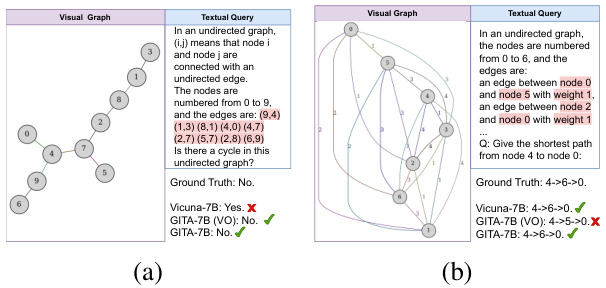
The section on “Visual Graph Augmentation” explores data augmentation strategies to enhance the robustness and performance of visual graph-based reasoning models. Four key augmentation strategies are introduced: layout augmentation (altering graph layouts), node shape augmentation, node outline style augmentation, and edge thickness augmentation. The authors’ hypothesis is that these variations will improve model generalizability and resilience to noise, potentially leading to better downstream task performance. Experiments focusing on these augmentation strategies, particularly layout augmentation, demonstrate that carefully introduced diversity in the visual representations of graphs can significantly boost model performance, underscoring the importance of considering data augmentation for visual graph reasoning. The finding regarding the effectiveness of layout augmentation in particular suggests the potential for further exploration into similar strategies to improve the effectiveness of vision-based graph reasoning models.
GVLQA Dataset#
The GVLQA dataset represents a significant contribution to the field of vision-language graph reasoning. Its novelty lies in combining visual graph representations with textual queries and answers, creating a richer, more human-understandable dataset than purely textual approaches. The dataset’s size and diversity (526K instances across seven tasks) allow for robust evaluation of different models. Furthermore, its construction from an open-source dataset makes it accessible and reproducible. However, the dataset’s reliance on existing graph data may limit its inherent diversity. The explicit integration of visual graphs opens up exciting new research directions. GVLQA’s design, including augmentation subsets, provides valuable tools for studying the impact of various visual features on model performance. The availability of this dataset is expected to significantly accelerate the progress of vision-language graph reasoning.
GITA Framework#
The GITA framework innovatively integrates visual and textual information for enhanced graph reasoning. It leverages a visual graph representation, moving beyond purely textual approaches. This visual component, coupled with textual descriptions and task-specific queries, allows a Vision-Language Model (VLM) to reason more effectively. The framework’s strength lies in its end-to-end design, which seamlessly combines visual and textual modalities. GITA’s task-agnostic nature makes it adaptable to various graph reasoning tasks without requiring architectural modifications, thus offering greater flexibility and generalizability than traditional methods. The inclusion of a dedicated graph visualizer, describer, and questioner further enhances its performance and usability. However, the reliance on visual representations may present scalability challenges, particularly with extremely large graphs.
LLM Graph Reasoning#
LLM graph reasoning represents a significant advancement in graph-structured data processing. Early methods focused on converting graphs into textual formats for LLM input, overlooking the rich visual information inherent in graph structures. This limitation is addressed by innovative approaches that integrate visual graph representations, significantly improving performance on various graph reasoning tasks. The development of novel datasets, specifically designed for vision-language graph reasoning, is crucial for evaluating and advancing these techniques. The use of large vision-language models (VLMs) further enhances capabilities, allowing for more effective integration of visual and textual information within the reasoning process. Future research should focus on addressing the challenges of scalability and generalizability, particularly for very large graphs, and on exploring more robust methods for integrating multimodal information to better exploit the strengths of both vision and language models. A key challenge remains in balancing consistency and variety in visual graph representations during training and testing to achieve optimal model performance.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending GITA to handle even larger graphs is crucial, potentially through more sophisticated sampling techniques or architectural modifications to better manage computational demands. Investigating the impact of different visual graph generation methods beyond layout augmentation, including node and edge representations, could significantly enhance performance. Developing a more comprehensive benchmark dataset with a wider variety of graph types and tasks would strengthen the evaluation of graph reasoning models. Furthermore, research into the interplay between visual and textual modalities needs further investigation to optimize their combined contribution to accuracy. Lastly, the framework’s generalizability across diverse graph reasoning tasks should be rigorously tested on a broader range of real-world applications to solidify its practical value.
More visual insights#
More on figures
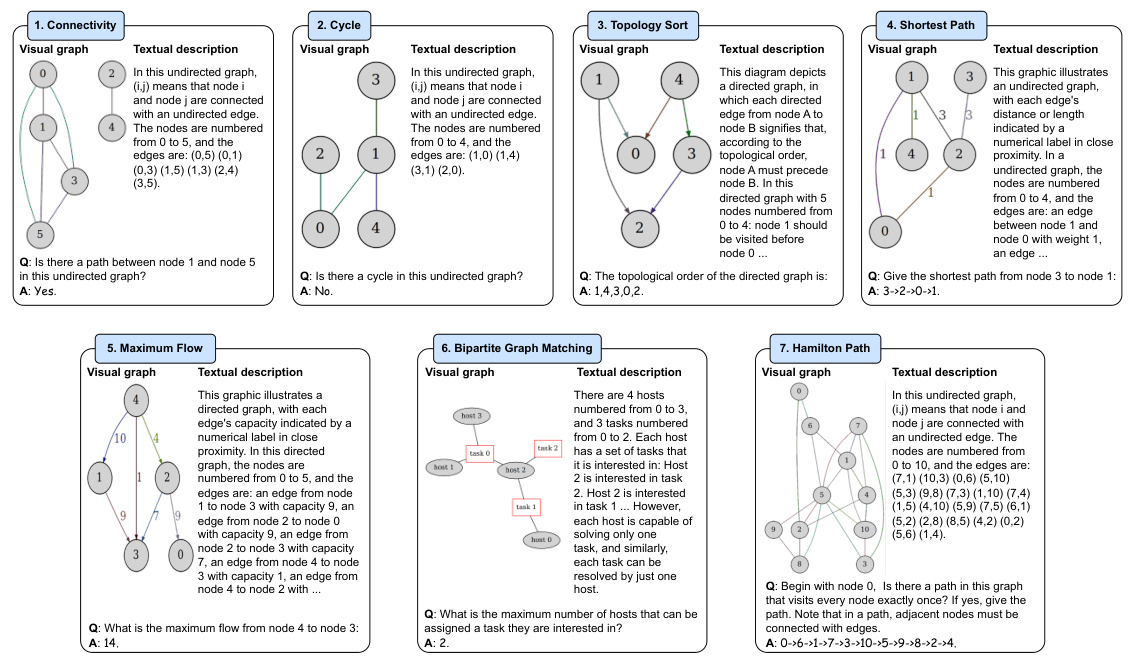
This figure illustrates the architecture of the Graph to visual and Textual Integration (GITA) framework, highlighting its four main components: a graph visualizer, a graph describer, a task-based questioner, and a Vision-Language Model (VLM). It contrasts GITA’s approach of incorporating visual graph information with traditional Large Language Model (LLM) solutions which rely solely on textual representations of the graph. The figure showcases how GITA integrates visual and textual information to perform vision-language graph reasoning tasks more effectively.
The figure illustrates the architecture of the Graph to visual and Textual Integration (GITA) framework, which incorporates visual graphs into general graph reasoning. It shows four key components: a graph visualizer (V), a graph describer (D), a task-based questioner (Q), and a Vision-Language Model (VLM) reasoner (R). The visualizer converts the graph structure into a visual image. The describer generates textual descriptions of the graph. The questioner integrates descriptions and task requirements into prompt instructions. The VLM reasoner processes the visual and textual information to perform the reasoning task. The figure also compares GITA’s architecture to existing LLM solutions, highlighting GITA’s innovative approach of integrating visual information into graph reasoning.

This figure illustrates the architecture of the Graph to visual and Textual Integration (GITA) framework. It shows the four main components: a graph visualizer, a graph describer, a task-based questioner, and a vision-language model (VLM). The figure also compares GITA to traditional LLM solutions, highlighting how GITA uniquely integrates visual graph information into the reasoning process. Data flows through the components, starting with graph structure input, visual graph generation, textual description creation, task query generation, and finally a response from the VLM.
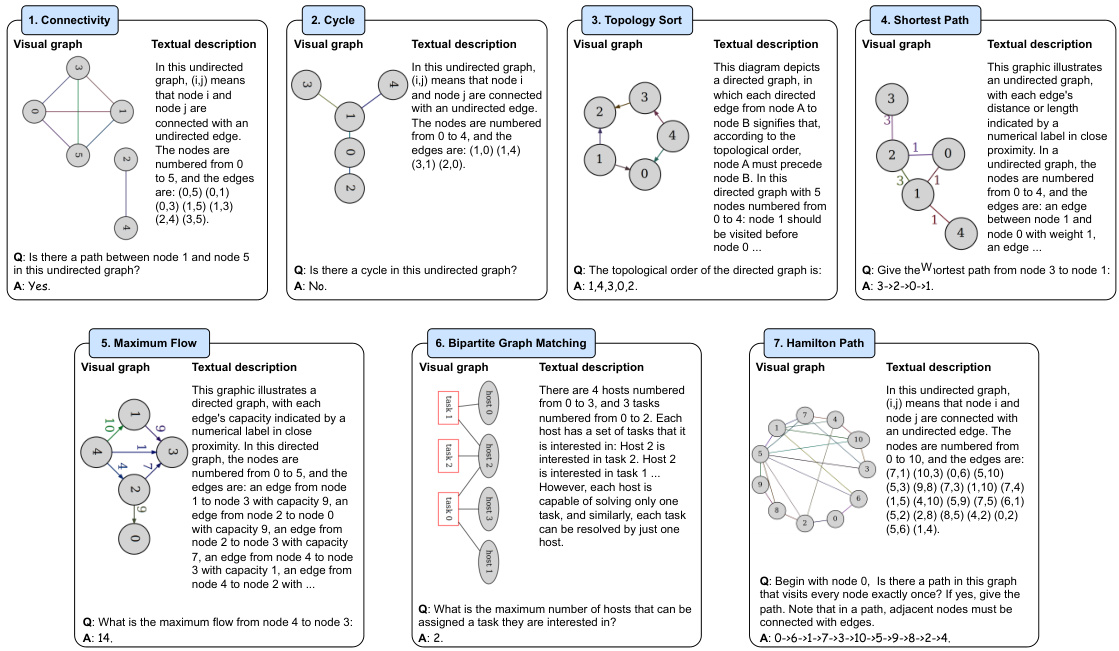
This figure illustrates the architecture of the Graph to visual and Textual Integration (GITA) framework. It shows the four main components of GITA: a graph visualizer (V), a graph describer (D), a task-based questioner (Q), and a Vision-Language Model (VLM) reasoner (R). The figure also compares GITA to traditional LLM solutions, highlighting how GITA incorporates visual graph information into the reasoning process. The visual graph is generated by the visualizer, and a textual description of the graph is produced by the describer. The questioner takes the textual description and the task requirements and forms a query. Finally, the VLM reasoner uses both the visual graph and the textual query to produce an answer.
This figure illustrates the architecture of the Graph to visual and Textual Integration (GITA) framework, a novel end-to-end framework that systematically integrates visual information into instruction-based graph reasoning. It compares GITA’s architecture to existing Large Language Model (LLM) solutions. The figure highlights four key components of GITA: (1) a graph visualizer for generating visual graphs, (2) a graph describer for generating textual descriptions, (3) a task-based questioner for generating task-specific queries, and (4) a vision-language model (VLM) for conducting graph reasoning using both visual and textual information. The comparison highlights the integration of visual modality as a key differentiator of GITA from traditional LLM approaches.
This figure illustrates the architecture of the Graph to visual and Textual Integration (GITA) framework, which is proposed in the paper for vision-language graph reasoning. It shows a comparison with traditional Large Language Model (LLM) solutions. GITA consists of four main components: a graph visualizer, a graph describer, a task-based questioner, and a Vision-Language Model (VLM) reasoner. The figure highlights how GITA integrates visual information into the process of graph reasoning, which is not typically considered in traditional LLM solutions. The figure depicts the flow of information through each component, from the input graph to the final answer. It provides a visual representation of the framework’s design and its key differences from traditional LLMs.

This figure illustrates the architecture of the Graph to visual and Textual Integration (GITA) framework. GITA integrates visual graphs into general graph reasoning by using four main components: a graph visualizer (V), a graph describer (D), a task-based questioner (Q), and a Vision-Language Model (VLM) reasoner (R). The figure also shows a comparison with traditional LLM solutions, highlighting GITA’s innovative approach of incorporating visual information.

This figure illustrates the architecture of the Graph to visual and Textual Integration (GITA) framework. GITA integrates visual graphs into general graph reasoning by incorporating four components: a graph visualizer (V), a graph describer (D), a task-based questioner (Q), and a Vision-Language Model (VLM) reasoner (R). The figure contrasts GITA’s approach with traditional LLM solutions, highlighting the unique integration of visual information into the graph reasoning process. The figure shows how the visual graph and textual description are combined to answer a question.
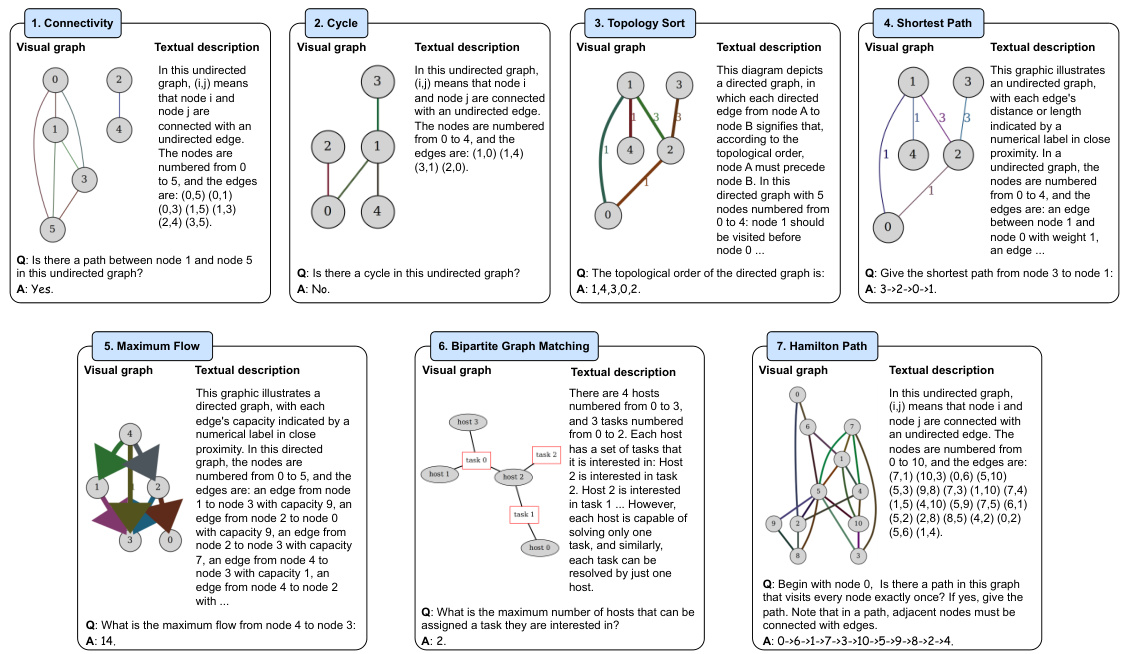
This figure illustrates the architecture of the Graph to visual and Textual Integration (GITA) framework. GITA is a novel framework that integrates visual graphs into general graph reasoning by incorporating four components: 1) a graph visualizer to generate visual graph images, 2) a graph describer to generate textual descriptions of the graph structure, 3) a task-based questioner that organizes the description and task requirements into prompt instructions, and 4) a Vision-Language Model (VLM) to perform vision-language graph reasoning. The figure also compares GITA with traditional LLM solutions, highlighting GITA’s unique ability to incorporate visual information into instruction-based graph reasoning.
More on tables

This table presents the accuracy of the vision-only GITA-7B model across different subsets of the GVLQA dataset. Each subset represents a different visual augmentation strategy applied to the graphs (layout, node shape, node outline, and edge thickness). The table shows a significant performance improvement when using layout augmentation, highlighting its importance in vision-based graph reasoning. The average accuracy across all tasks is shown for each subset, allowing for comparison of the effectiveness of different augmentation strategies.

This table compares the performance of various LLMs (LLaMA2-7B, Vicuna-7B, and GITA-7B) on five real-world datasets for node classification and link prediction tasks. It shows the accuracy of each model under both zero-shot and fine-tuning settings. The GITA-7B+ row indicates results when using a checkpoint pre-trained on the Cycle task from the GVLQA-BASE dataset. The table highlights the effectiveness of GITA, particularly when fine-tuned, and showcases improvement through visual graph augmentation.

This table compares the performance of the proposed GITA framework with two dedicated Graph Neural Networks (GNNs), namely GCN and SAGE, on the GVLQA-Base dataset. The comparison highlights the performance of GITA-7B and GITA-13B across seven graph reasoning tasks: Connectivity, Cycle, Topological Sort, Shortest Path, Maximum Flow, Bipartite Graph Matching, and Hamilton Path. The results showcase GITA’s competitive performance against specialized GNNs, demonstrating its ability to tackle various graph reasoning tasks effectively.
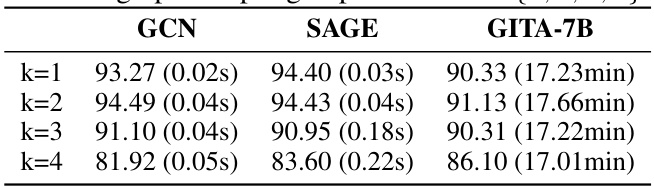
This table presents the accuracy and inference time of GCN, SAGE, and GITA-7B models on the ca-HepTh dataset using different subgraph sampling hop numbers (k). It demonstrates the performance of each model with varying subgraph sizes, showing the trade-off between accuracy and computational cost.
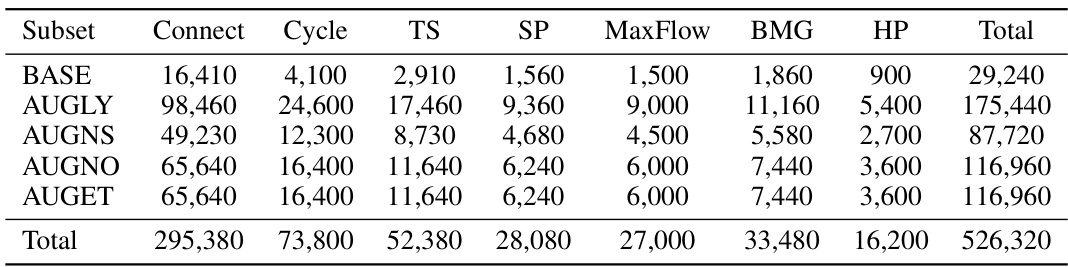
This table presents the statistical distribution of samples across different subsets of the GVLQA dataset. Each subset is named, and the number of samples for each of seven graph reasoning tasks (Connectivity, Cycle, Topological Sort, Shortest Path, Maximum Flow, Bipartite Graph Matching, Hamilton Path) is provided. The ‘Total’ column shows the overall number of samples in each subset. The subsets represent different visual augmentation strategies applied to the base dataset.

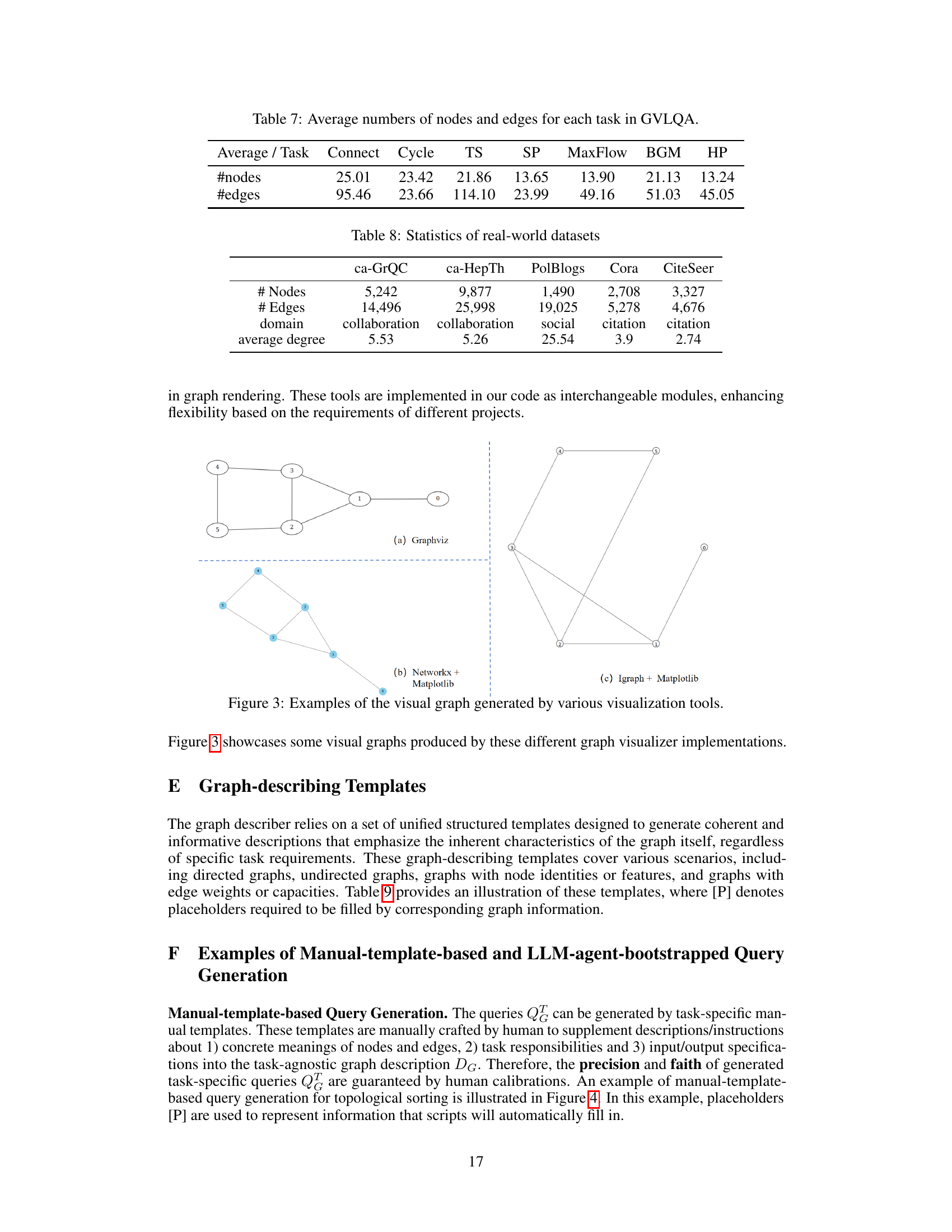
This table presents the average number of nodes and edges for each of the seven graph reasoning tasks included in the GVLQA dataset. The tasks are: Connectivity, Cycle, Topological Sort, Shortest Path, Maximum Flow, Bipartite Graph Matching, and Hamilton Path. The data provides insights into the scale and complexity of the graphs used in the dataset for each task. This is useful context for understanding the difficulty level of the tasks presented to the models.
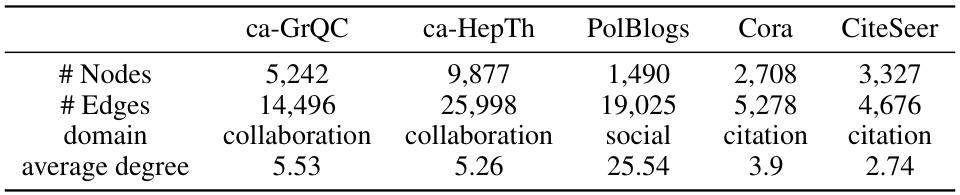
This table presents the statistics of five real-world datasets used in the paper’s experiments, including the number of nodes and edges, the domain of each dataset, and the average degree of the nodes in the graph. These datasets represent various graph types and are used to evaluate the generalizability of the proposed GITA framework.
This table presents the accuracy comparison results of different models (LLMs and GITA) across various graph reasoning tasks in the GVLQA-BASE dataset, under both zero-shot and fine-tuning settings. It highlights GITA’s superior performance compared to baseline LLMs, showing consistent improvement in accuracy across various tasks and model sizes. The observation regarding the performance differences between 7B and 13B models under fine-tuning settings provides insightful discussion regarding the challenges of modality alignment in larger models.
Full paper#