↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current open-source code Large Language Models (LLMs) often underperform due to training on limited, single-source data. This data often lacks diversity and may not fully leverage the potential of pre-trained models. Additionally, simply combining diverse data sources can negatively impact model performance.
The researchers introduce AlchemistCoder, a series of enhanced Code LLMs trained on multi-source data. They address the limitations of existing methods by introducing AlchemistPrompts to harmonize the conflicting styles and qualities present in different datasets, and by incorporating the data construction process as additional fine-tuning tasks. These techniques lead to substantial improvements in code generation and generalization, with AlchemistCoder models outperforming other open-source models of similar size and even rivaling larger, closed-source models.
Key Takeaways#
Why does it matter?#
This paper is crucial because it demonstrates a novel approach to fine-tuning code LLMs using multi-source data, overcoming limitations of single-source datasets. It introduces AlchemistPrompts, a technique to harmonize conflicting styles in multi-source data, leading to significant performance improvements. This opens new avenues for research in code intelligence and LLM fine-tuning.
Visual Insights#
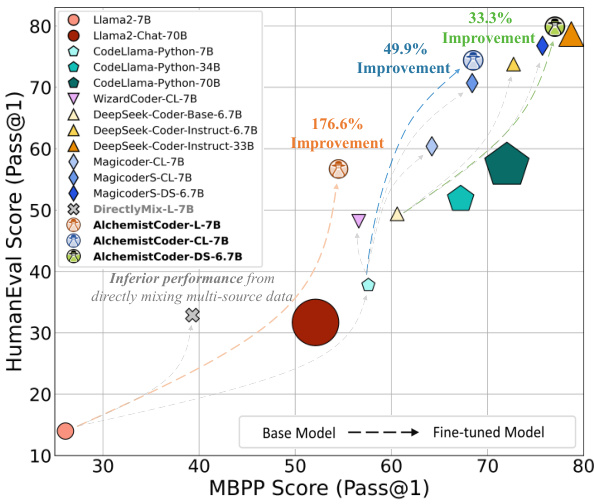
This figure shows the performance of various open-source code LLMs on two popular benchmarks: HumanEval and MBPP. The x-axis represents the MBPP (Mostly Basic Python Programming) score, indicating the model’s ability to solve basic Python programming problems. The y-axis shows the HumanEval score, measuring the model’s capacity to pass more complex human-written coding challenges. Each point represents a different model, with its position determined by its performance on both benchmarks. The AlchemistCoder series (various models) is highlighted, showcasing significantly better performance compared to other open-source LLMs of similar sizes and even surpassing some significantly larger models.

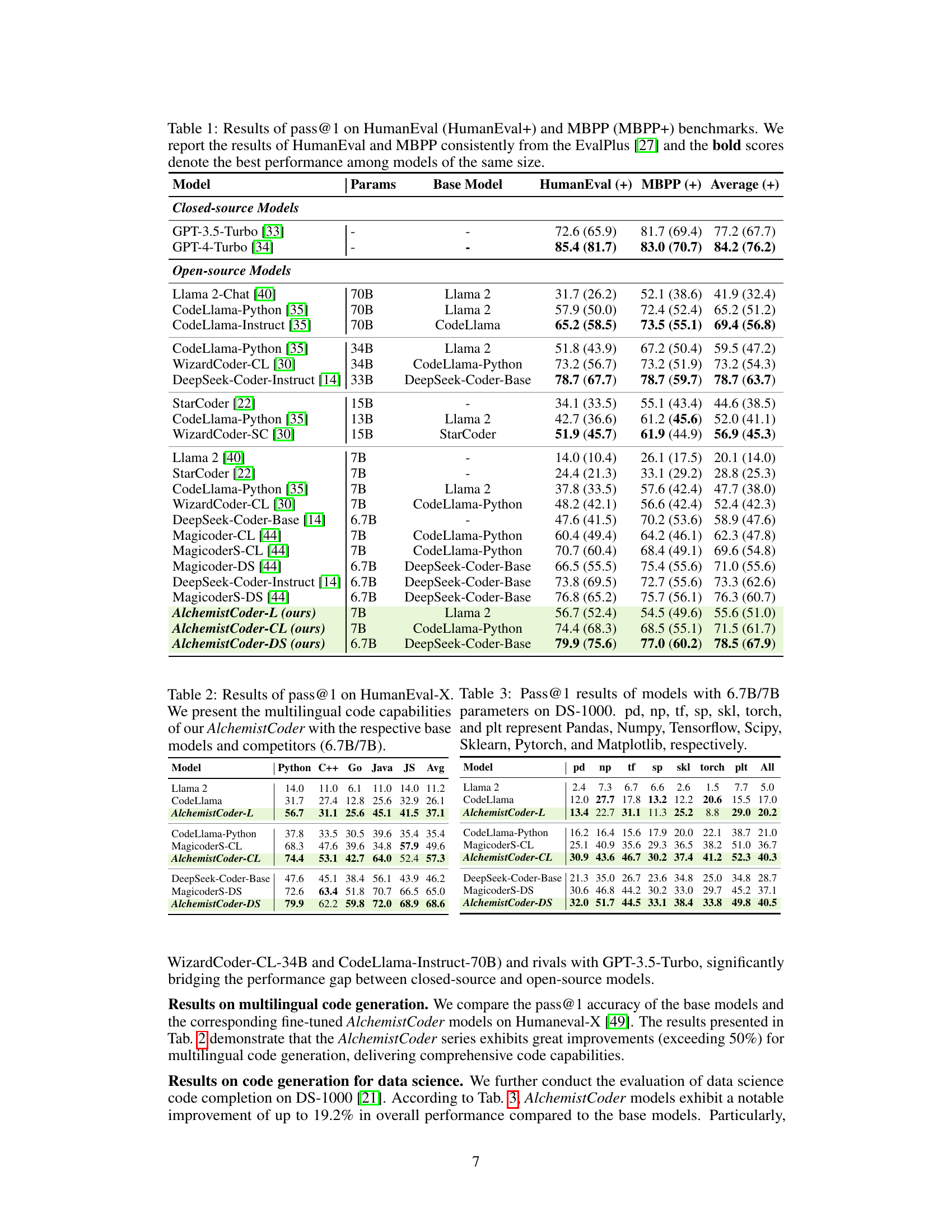
This table presents the pass@1 scores achieved by various large language models (LLMs) on the HumanEval and MBPP benchmarks. The models are categorized into closed-source and open-source, with each model’s performance reported along with its size (in parameters). The table highlights the superior performance of AlchemistCoder models compared to other open-source models of similar size and even larger ones in some cases. The scores are presented both with and without the use of EvalPlus enhancements.
In-depth insights#
Multi-Source Harmony#
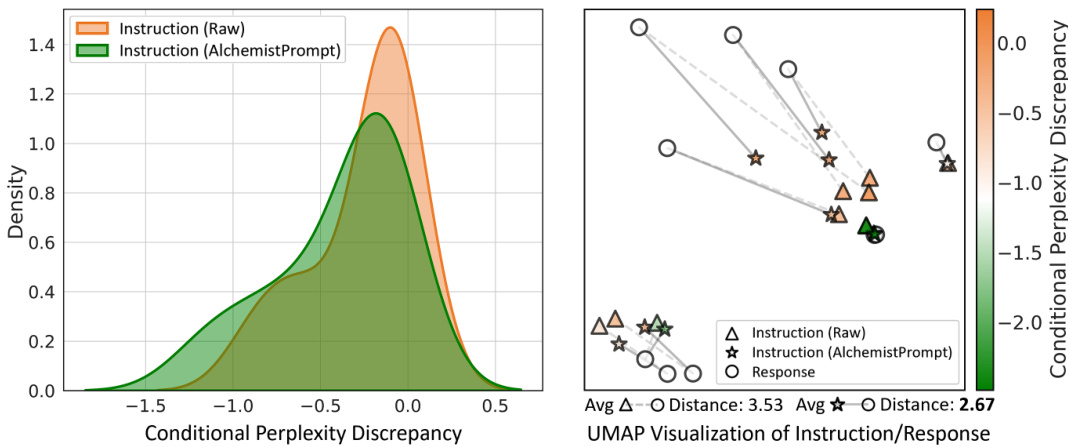
The concept of “Multi-Source Harmony” in a research paper likely revolves around the challenges and solutions involved in integrating data from various sources. It suggests a focus on resolving inherent conflicts arising from differences in data styles, quality, and formats. The core idea is to harmonize diverse datasets to create a unified and enriched training corpus, potentially for a machine learning model. This could involve techniques like data cleaning, normalization, and the development of strategies to mitigate conflicts between different data sources’ inherent biases or inconsistencies. A successful approach might involve novel prompting techniques or data augmentation strategies that bridge these differences, ultimately leading to improved model performance and generalization. Careful consideration of data provenance and quality control is crucial for maintaining data integrity and reliability. The successful implementation of “Multi-Source Harmony” would significantly enhance the robustness and generalizability of the resulting system, showing the advantages of leveraging multiple data sources over relying on single-source data alone. The paper likely demonstrates this improvement through rigorous experimentation and evaluation.
Hindsight Tuning#
Hindsight tuning, in the context of large language models (LLMs), represents a powerful paradigm shift in how we approach model training. It moves away from the traditional reliance on pre-defined, static training data towards a more dynamic and adaptive approach. The core idea is to leverage the model’s own predictions (or ‘hindsight’) to re-evaluate and re-label training data, essentially creating a feedback loop that allows for iterative refinement. This is particularly valuable when dealing with noisy, inconsistent, or incomplete datasets, a common problem in real-world applications. Hindsight tuning addresses inherent data conflicts, such as variations in coding style and quality, by using the model’s understanding to identify and resolve discrepancies, thus leading to improved generalization and robustness. This iterative refinement process is key to eliciting the full potential of pre-trained models, enabling them to handle more complex and nuanced tasks than with traditional training methods. The effectiveness of hindsight tuning often depends heavily on the quality of the base model used for generating the revised labels and careful design of the prompt engineering process. The incorporation of code comprehension tasks further strengthens the approach, fostering a deeper understanding of code structure and logic, leading to superior instruction-following capabilities.
AlchemistPrompts#
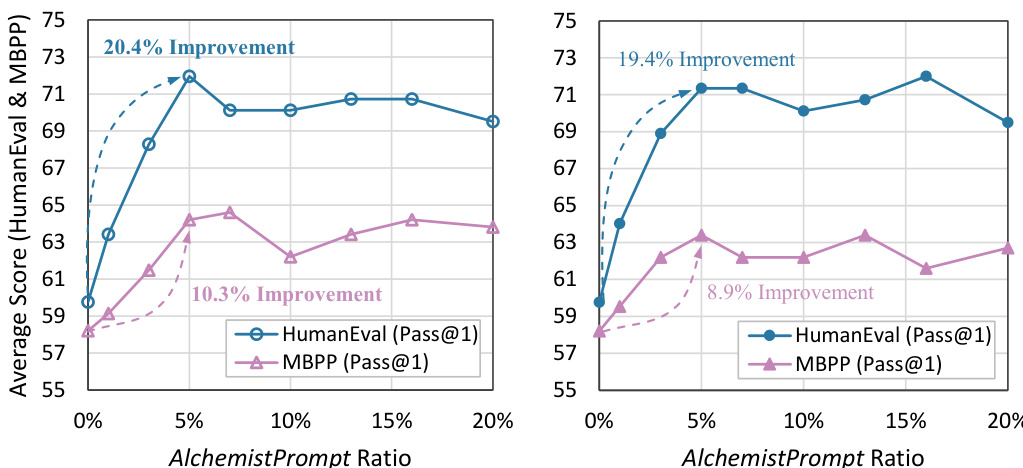
The AlchemistPrompts method is a novel approach to harmonize the inherent conflicts within multi-source code corpora used for fine-tuning large language models (LLMs). It addresses the challenge of directly mixing diverse data, which often leads to suboptimal performance due to conflicting styles and qualities. Instead of naive data integration, AlchemistPrompts employs a hindsight relabeling technique, where a high-quality LLM (like GPT-4) generates customized prompts that are tailored to specific data sources and instruction-response pairs. These prompts clarify ambiguities, bridge style differences, and enhance the alignment between instructions and responses. The key innovation lies in using these data-specific prompts to refine instructions, thus mitigating the negative impacts of conflicting data sources and eliciting better performance from the LLM. This approach achieves both harmonization between and within data sources, leading to improved instruction-following capabilities and generalization in code generation. The effectiveness of AlchemistPrompts is validated empirically, showcasing significant performance gains over baselines that directly mix multi-source data.
Code Comprehension#
Code comprehension, within the context of large language models (LLMs) for code generation, signifies the model’s ability to understand the meaning, structure, and intent behind code. It’s more than just syntactic analysis; it involves semantic understanding, encompassing the ability to infer functionality, identify relationships between code elements, and reason about code execution. Effective code comprehension is crucial for several LLM tasks like code generation, debugging, and code summarization. A model with strong code comprehension skills is better equipped to generate more accurate, efficient, and contextually appropriate code. Moreover, good code comprehension allows LLMs to handle diverse coding styles, identify potential errors or bugs proactively, and adapt to various programming paradigms. The evaluation of code comprehension often involves tasks that test the model’s ability to interpret and extrapolate code behavior given specific inputs and conditions. The development of advanced code comprehension capabilities in LLMs is an active area of research, with techniques like data augmentation and improved model architectures continuously being explored.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In the context of a research paper, such studies are crucial for understanding the effectiveness of different elements and isolating the impact of specific techniques. A well-designed ablation study should systematically vary a single aspect while holding others constant, allowing researchers to determine the importance of that element. For example, in a code generation model, an ablation study might involve removing different components such as the data filtering process, the AlchemistPrompts, or a specific training task. By observing the resulting performance changes (e.g., in accuracy, efficiency, etc.), researchers can evaluate the unique contribution of each component to the overall system. These studies provide strong evidence that supports claims made in the paper and demonstrate a rigorous approach to experimental design, enhancing the credibility and robustness of the research findings. The results should clearly demonstrate what aspects contribute to the system’s success and inform future development. Failing to conduct proper ablation studies often weakens the overall argument, particularly in machine learning contexts, where complex interactions between model components are commonplace.
More visual insights#
More on figures

This figure presents a scatter plot comparing the performance of various open-source code large language models (Code LLMs) on two popular code benchmarks: HumanEval and MBPP. The x-axis represents the MBPP score (Pass@1), and the y-axis shows the HumanEval score (Pass@1). Each point represents a different Code LLM, with its position indicating its performance on both benchmarks. The plot highlights that the AlchemistCoder series significantly outperforms other open-source Code LLMs of similar sizes, even rivaling or surpassing much larger models.

This figure shows the performance of various open-source code large language models (Code LLMs) on two popular benchmarks: HumanEval and MBPP. The x-axis represents the MBPP score (Pass@1), and the y-axis represents the HumanEval score (Pass@1). Each point represents a different Code LLM, and its position indicates its performance on both benchmarks. The figure highlights the superior performance of the AlchemistCoder series compared to other models of similar size and even larger models.

This figure shows a scatter plot comparing the performance of various open-source code LLMs on two popular benchmarks: HumanEval and MBPP. The x-axis represents the MBPP score (higher is better), and the y-axis represents the HumanEval score (higher is better). Each point represents a different LLM, and the size of the point is proportional to the model size. The plot clearly shows that the AlchemistCoder series significantly outperforms other open-source LLMs of comparable size, and even rivals or surpasses larger models.

This figure shows a scatter plot comparing the performance of various open-source code LLMs on two popular benchmarks: HumanEval and MBPP. The x-axis represents the MBPP score (Pass@1), and the y-axis represents the HumanEval score (Pass@1). Each point represents a different LLM model, with its position determined by its performance on both benchmarks. The plot highlights the superior performance of the AlchemistCoder series, surpassing other open-source models in both benchmarks.

This figure is a scatter plot showing the performance of various open-source code LLMs on two popular code benchmarks: HumanEval and MBPP. The x-axis represents the MBPP score (higher is better), and the y-axis represents the HumanEval score (higher is better). Each point represents a different LLM, with the size of the point possibly indicating the model size. The AlchemistCoder series of models are highlighted, demonstrating significantly better performance than other open-source models of similar size, and even rivaling or surpassing larger models.
This figure shows a scatter plot comparing the performance of various open-source code LLMs on two popular benchmarks: HumanEval and MBPP. The x-axis represents the MBPP score (Pass@1), and the y-axis represents the HumanEval score (Pass@1). Each point represents a different LLM model, with its position indicating its performance on both benchmarks. The AlchemistCoder series (multiple models of varying sizes) is highlighted, demonstrating significantly better performance than other open-source models of comparable size and even rivaling or exceeding much larger models.
This figure shows a scatter plot comparing the performance of various open-source code LLMs on two popular benchmarks: HumanEval and MBPP. The x-axis represents the MBPP score (Pass@1), and the y-axis represents the HumanEval score (Pass@1). Each point represents a different LLM, with its size indicating the model’s parameter count. The plot highlights that AlchemistCoder models significantly outperform other open-source LLMs of comparable size and even rival or surpass larger models.

This figure shows the performance of various open-source code large language models (Code LLMs) on two popular benchmarks: HumanEval and MBPP. The x-axis represents the MBPP score (Pass@1), and the y-axis represents the HumanEval score (Pass@1). Each point represents a different Code LLM, with its position indicating its performance on both benchmarks. The AlchemistCoder series of models significantly outperforms other models, especially those of similar size (6.7B/7B parameters), even rivaling or surpassing much larger models (15B/33B/70B parameters). The figure highlights the superior performance of the AlchemistCoder models achieved through the methods described in the paper.

This figure compares the performance of various open-source code large language models (Code LLMs) on two popular benchmarks: HumanEval and MBPP. The x-axis represents the MBPP score (Pass@1), and the y-axis represents the HumanEval score (Pass@1). Each point represents a different Code LLM, and the size of the point indicates the model’s size. The AlchemistCoder series shows significantly better performance compared to other models of similar size and even surpasses larger models.

This figure shows a scatter plot comparing the performance of various open-source code large language models (Code LLMs) on two popular benchmarks: HumanEval and MBPP. The x-axis represents the MBPP score (Pass@1), and the y-axis represents the HumanEval score (Pass@1). Each point represents a different Code LLM, with its position indicating its performance on both benchmarks. The plot highlights the superior performance of the AlchemistCoder series compared to other models of similar size and even some larger models.

This figure shows the performance of various open-source code large language models (Code LLMs) on two popular benchmarks: HumanEval and MBPP. The x-axis represents the MBPP score (Pass@1), and the y-axis represents the HumanEval score (Pass@1). Each point represents a different Code LLM, with its position indicating its performance on both benchmarks. The AlchemistCoder series of models (various versions indicated by different shapes) significantly outperforms other models of similar size, and even rivals or surpasses much larger models. The figure visually demonstrates the superior performance and effectiveness of the AlchemistCoder approach.

This figure shows the performance of various open-source code large language models (Code LLMs) on two popular benchmarks: HumanEval and MBPP. The x-axis represents the MBPP score (Pass@1), and the y-axis represents the HumanEval score (Pass@1). Each point represents a different Code LLM, with its position indicating its performance on both benchmarks. The AlchemistCoder series of models (represented by different colored points) consistently outperforms all other open-source models, showcasing the effectiveness of the proposed method. The figure highlights a significant improvement in performance compared to models that directly mix data from multiple sources, demonstrating the benefit of the AlchemistCoder’s approach to harmonizing multi-source data.
More on tables
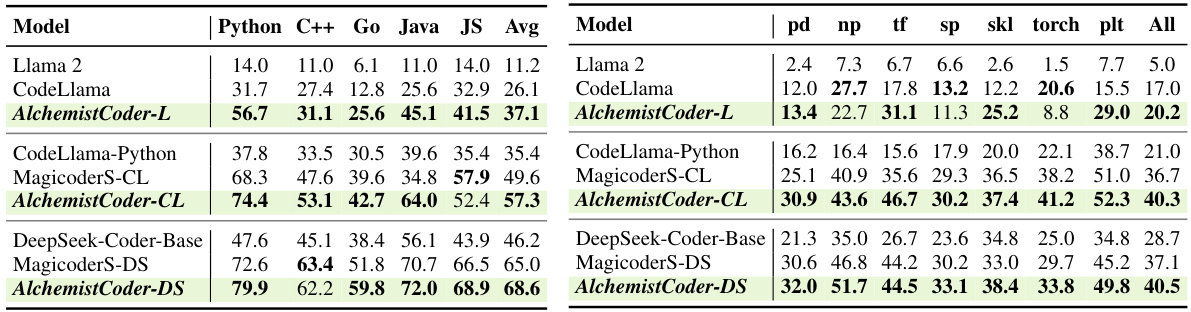
Table 2 presents the pass@1 scores on the HumanEval-X benchmark for various models, showcasing their multilingual code generation capabilities. Table 3 shows pass@1 scores on the DS-1000 benchmark focusing on data science code completion, comparing performance across different models and highlighting the specific libraries (Pandas, NumPy, TensorFlow, SciPy, Scikit-learn, PyTorch, Matplotlib) involved in the tasks.
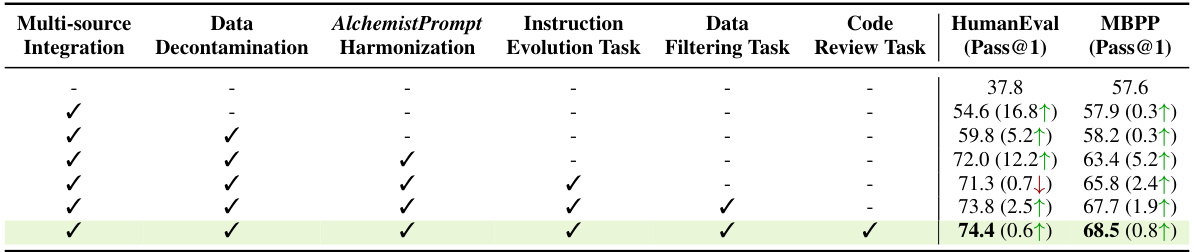
This table presents the ablation study results of the AlchemistCoder-CL-7B model’s performance on HumanEval and MBPP benchmarks. It analyzes the impact of different components of the proposed method: multi-source data integration, data decontamination, AlchemistPrompt harmonization, and three code understanding tasks (instruction evolution, data filtering, and code review). Each row represents a different combination of these components, showing the pass@1 scores on both benchmarks. The final row shows the model’s performance with all components included, demonstrating the overall improvement achieved.

This table presents the performance of AlchemistCoder models (6.7B and 7B parameters), along with several baseline models, across three diverse benchmarks: MMLU (evaluating multitask language understanding), BBH (assessing comprehensive reasoning), and GSM8K (testing mathematical ability). The average score across all three benchmarks is also provided for each model, offering a comparative overview of their general-purpose capabilities. The results highlight AlchemistCoder’s superior performance compared to the base models on these benchmarks, showcasing its improved abilities in various reasoning and comprehension tasks.
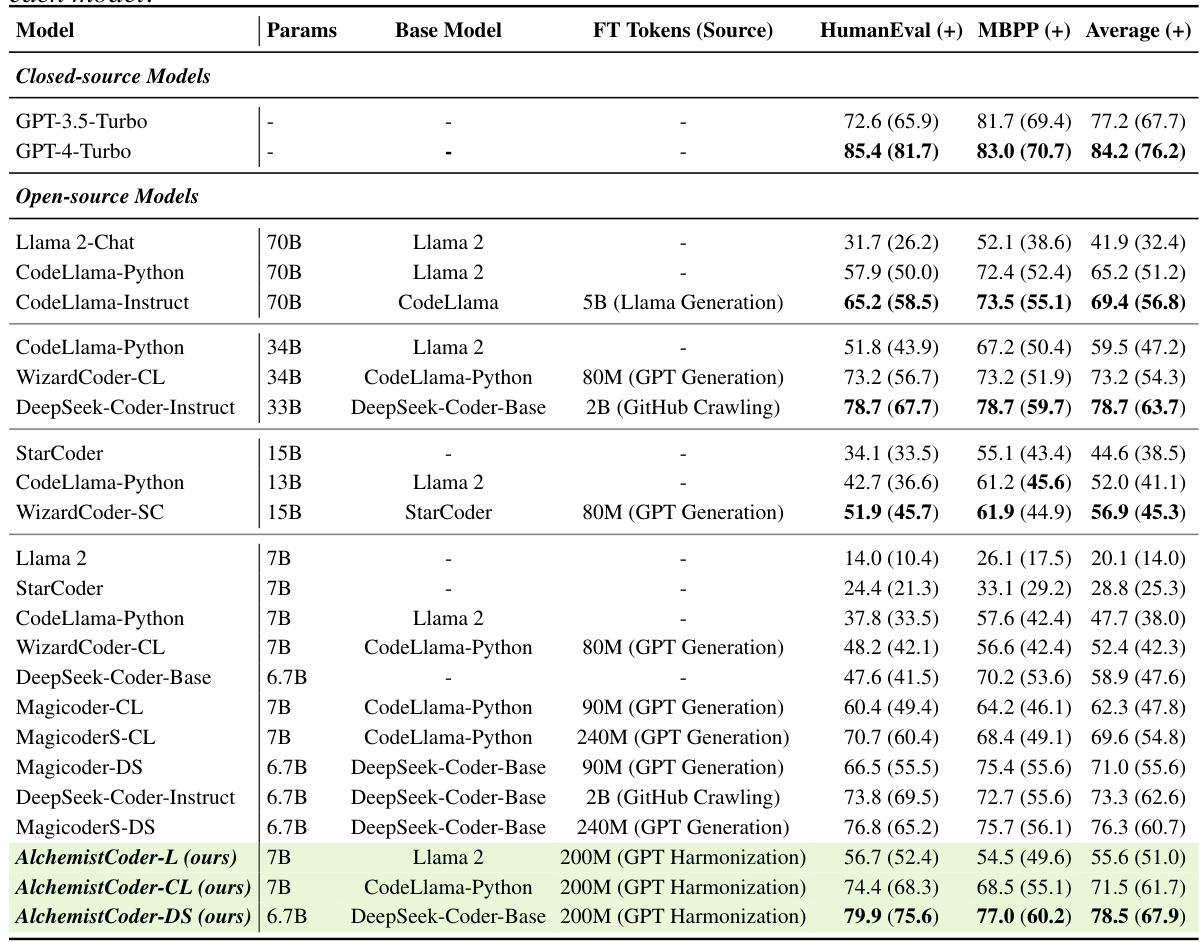
This table presents the pass@1 scores achieved by various large language models (LLMs) on two popular code generation benchmarks: HumanEval and MBPP. It compares the performance of both closed-source models (GPT-3.5-Turbo and GPT-4-Turbo) and various open-source models across different parameter scales, highlighting the relative performance of AlchemistCoder models (AlchemistCoder-L, AlchemistCoder-CL, AlchemistCoder-DS) compared to other models of similar size and larger models.

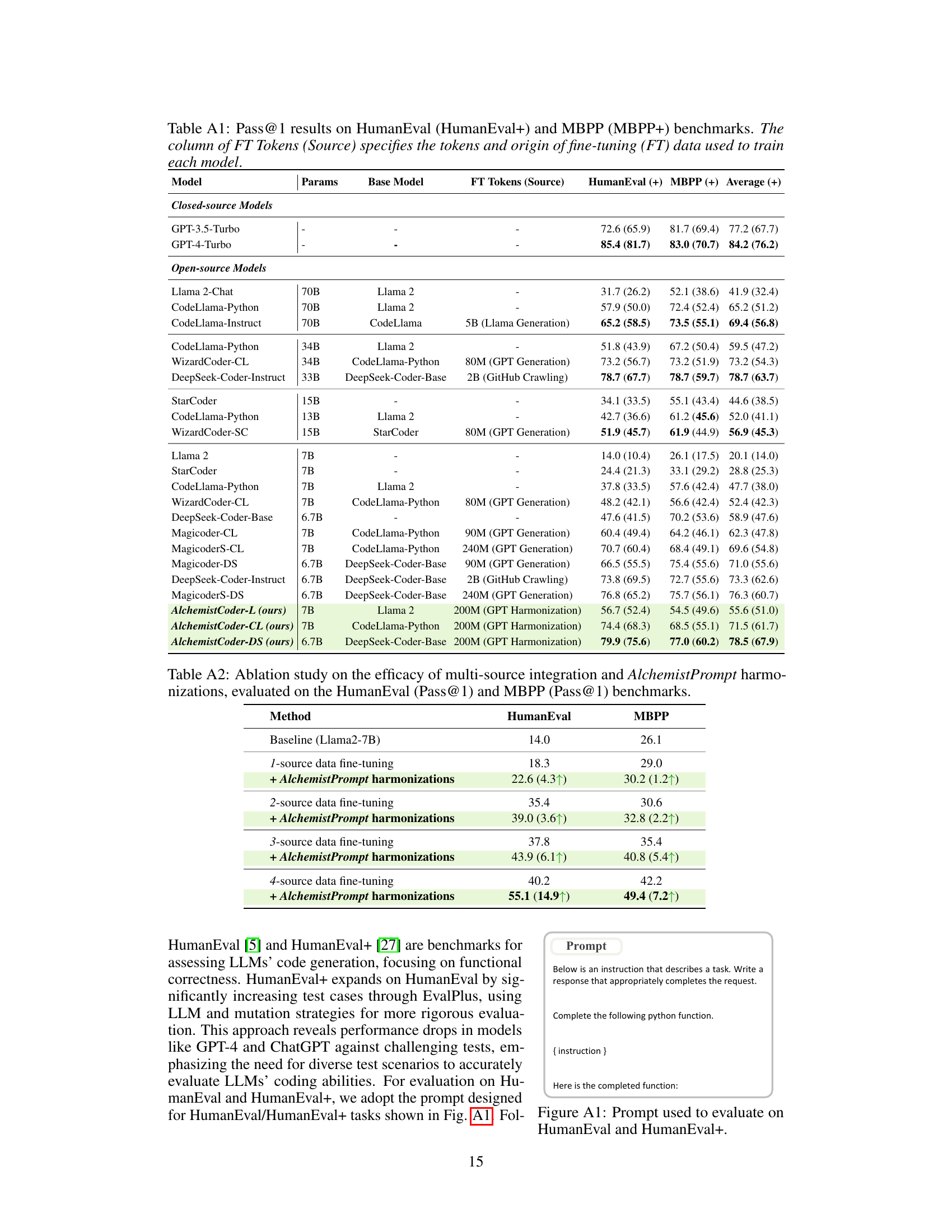
This table presents the results of an ablation study conducted to evaluate the effectiveness of multi-source data integration and AlchemistPrompt harmonizations on the HumanEval and MBPP benchmarks. The study systematically increased the number of data sources used for fine-tuning, while incorporating AlchemistPrompt harmonizations to address inherent conflicts between different data sources. The results demonstrate the impact of each component on the model’s performance, showcasing the effectiveness of the proposed method in enhancing code generation capabilities.
Full paper#