↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large diffusion models are powerful but computationally expensive, limiting their use. Traditional pruning methods require extensive retraining, which is inefficient. This paper introduces DiP-GO, a new pruning method that tackles this issue.
DiP-GO frames model pruning as a subnet search within a ‘SuperNet’ constructed by adding backup connections to a standard diffusion model. It uses a plugin pruner network and optimization losses to identify and remove redundant computations efficiently via a few-step gradient optimization. Experiments show significant speedups (4.4x on Stable Diffusion 1.5) without losing accuracy, outperforming existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel method for efficiently pruning diffusion models, significantly improving inference speed without sacrificing accuracy. This addresses a critical limitation of diffusion models, making them more practical for real-world applications and opening new avenues for research in model compression.
Visual Insights#
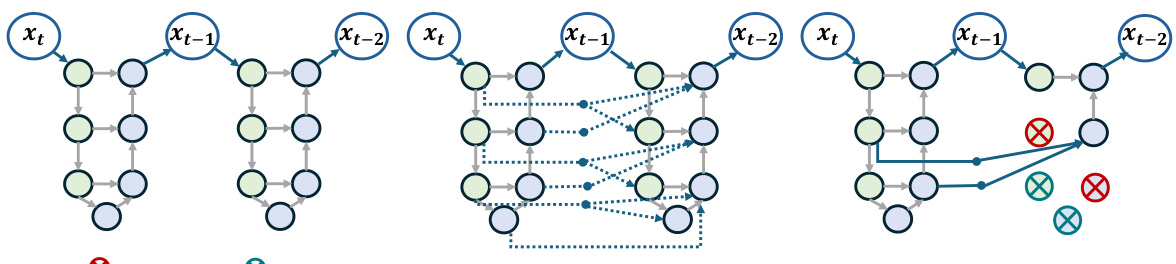
This figure illustrates the core idea of the DiP-GO method. It shows how a standard diffusion model (a) is transformed into a SuperNet (b) by adding backup connections between blocks in adjacent timesteps. This SuperNet allows for the identification of an optimal SubNet (c) by selectively removing less important blocks during inference, leading to significant computational savings. The backup connections ensure that the inference process can continue even after blocks are removed.
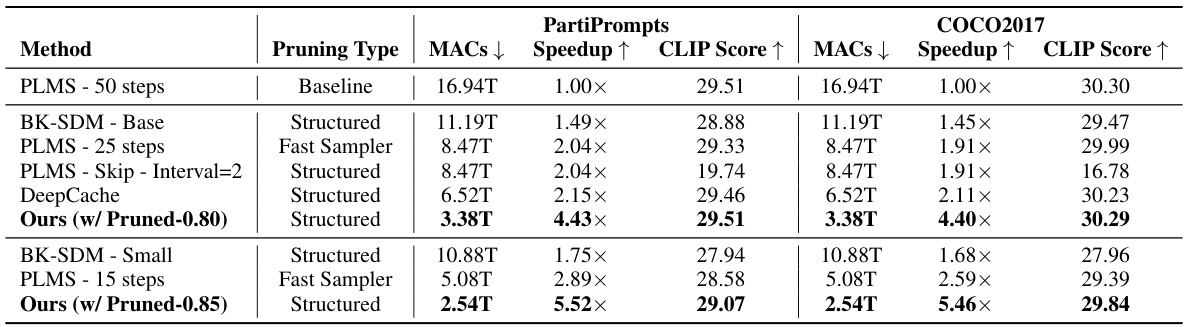
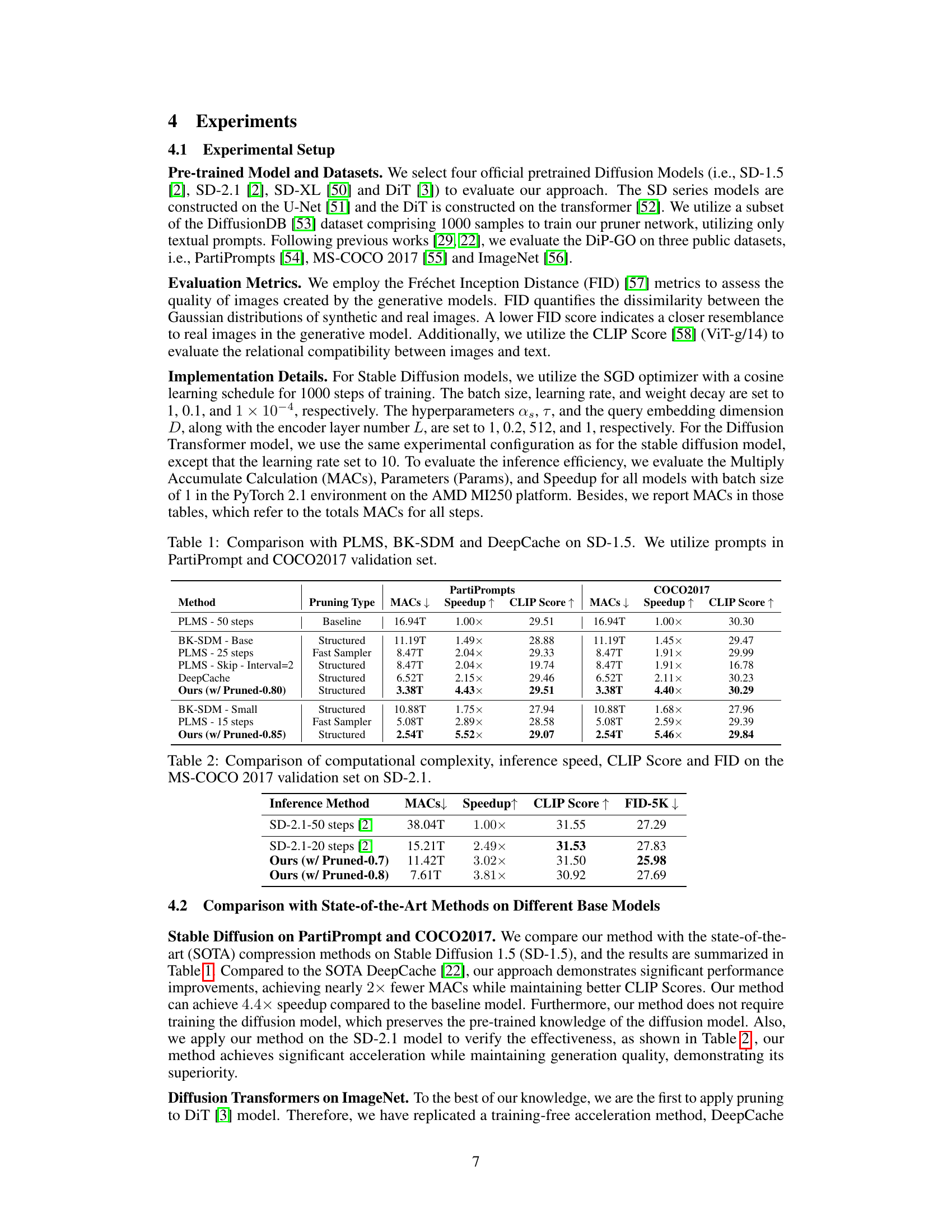
This table compares the performance of the proposed DiP-GO method with three other state-of-the-art methods (PLMS, BK-SDM, and DeepCache) on the Stable Diffusion 1.5 model. The comparison is done using two different datasets (PartiPrompts and COCO2017) and focuses on metrics such as Multiply-Accumulate operations (MACs), speedup achieved, CLIP score, and FID. The table helps to illustrate the efficiency gains of DiP-GO in terms of computational cost while maintaining comparable or even improved image quality.
In-depth insights#
Few-Step Pruning#
The concept of ‘Few-Step Pruning’ in the context of diffusion models presents a compelling approach to enhance efficiency. It directly addresses the computational burden associated with the multi-step denoising process inherent in these models. By focusing on pruning within a limited number of steps, it potentially avoids the substantial retraining costs typically required by traditional pruning methods. This is especially significant given the vast datasets and computational resources needed for retraining large diffusion models. A key advantage lies in its potential to strike a balance between model accuracy and inference speed. Instead of aggressively pruning to an extreme degree, a few-step approach allows for a more controlled reduction in complexity, potentially mitigating the risk of significant performance degradation. The differentiability of the pruning process, possibly achieved through techniques like gradient optimization, is crucial for effective SubNet search and precise identification of less critical computational blocks. This technique could lead to more intelligent, adaptive pruning strategies that dynamically adjust based on the specific characteristics of the input data, further optimizing the balance between speed and accuracy. However, the success of this approach hinges upon the ability to accurately identify and remove only truly redundant computations without sacrificing the model’s generative capabilities. Careful design of the optimization loss function is crucial for this, as is the choice of an appropriate SuperNet architecture upon which the pruning is performed. Overall, few-step pruning offers a promising pathway towards faster and more efficient diffusion models.
SuperNet Design#
The concept of a SuperNet in the context of diffusion model pruning is a crucial innovation. It addresses the challenge of intelligently pruning the model without sacrificing performance. By creating a SuperNet with redundant connections based on the similarity of features across different denoising steps, the authors introduce flexibility. This approach transforms the pruning problem into a SubNet search, allowing for a more dynamic and adaptive pruning process. The additional connections act as safety nets, ensuring that even when some computational blocks are removed, the network remains functional. This differentiable pruner network learns to identify and remove redundant computation, leading to significant efficiency gains. The SuperNet design is key to the success of the few-step gradient optimization, enabling the identification of an optimal SubNet without the need for extensive retraining. The intelligent and differentiable nature of the pruning process is a major advancement compared to traditional static pruning methods.
DiP-GO Approach#
The DiP-GO approach presents a novel solution to the computational cost of diffusion models by framing model pruning as a differentiable SubNet search within a SuperNet. DiP-GO leverages the inherent similarity of features across adjacent denoising steps in diffusion models, creating a SuperNet with redundant connections. A plugin pruner network, trained with sparsity and consistency loss functions, intelligently identifies and removes these redundant computations, yielding an optimal SubNet. The method avoids the computationally expensive retraining required by traditional pruning methods, achieving significant speed improvements, such as a 4.4x speedup on Stable Diffusion 1.5 without sacrificing accuracy. The use of gradient checkpointing and a post-processing algorithm further enhances efficiency and ensures the pruned model meets specified requirements. This innovative approach not only enhances efficiency but also showcases the potential of casting model pruning as a SubNet search problem, paving the way for more intelligent and efficient pruning techniques in diffusion models and potentially other deep learning architectures.
Pruning Analysis#
A thorough pruning analysis in a deep learning research paper would go beyond simply reporting compression ratios. It should delve into the impact of pruning on model accuracy, ideally across various metrics (e.g., precision, recall, F1-score, AUC) and different datasets. The analysis needs to explore the trade-off between model size and performance. Examining the effects of pruning on different layers or network components (e.g., convolutional layers vs. fully connected layers) is crucial. Visualization techniques, such as heatmaps showing the distribution of pruned weights, can offer valuable insights into the pruning strategy’s effectiveness. Furthermore, a robust analysis would involve comparing different pruning methods, and discussing the computational cost of the pruning process itself, including the time needed for training and inference. Finally, generalizability of the pruned model should be discussed, demonstrating how well it performs on unseen data.
Future Works#
Future work could explore several promising directions. Improving the efficiency of the SuperNet search process is crucial; current methods face challenges with high-dimensional search spaces. Investigating alternative optimization losses or search algorithms could significantly enhance efficiency and identify even more optimal SubNets. The effectiveness of DiP-GO across diverse model architectures and data modalities should be further validated, specifically assessing its performance on larger, more complex datasets. Additionally, combining DiP-GO with other compression techniques (e.g., quantization, low-rank approximations) might yield additional performance gains. A thorough investigation into the interplay between different pruning strategies and their impact on the overall generative quality and stability would be highly valuable. Finally, exploring the theoretical underpinnings of the SuperNet approach would provide a deeper understanding of its efficacy and guide future enhancements.
More visual insights#
More on figures
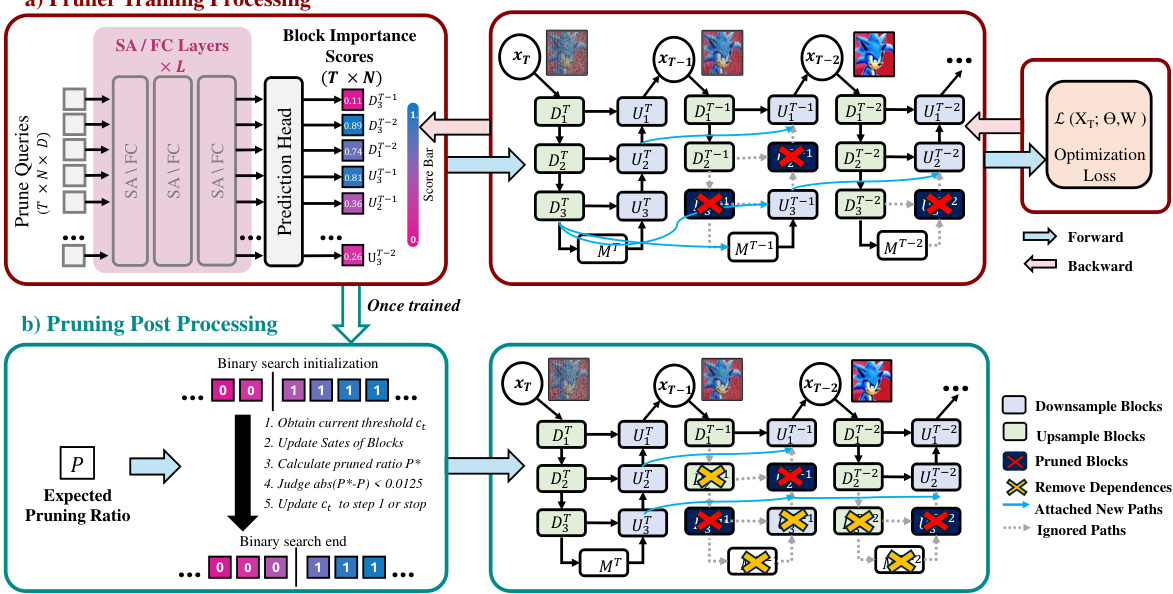
This figure illustrates the architecture and workflow of the proposed diffusion pruner (DiP-GO). Part (a) shows the training process, where a pruner network learns to assign importance scores to blocks in the diffusion model. The network uses self-attention and fully connected layers to process input queries, predicting which blocks are essential. The training is guided by a loss function that balances consistency (maintaining generation quality) and sparsity (reducing computations). Part (b) depicts the post-training inference process. The trained pruner’s importance scores are used in a binary search to determine the optimal subset of blocks to execute, thus creating a pruned model for faster inference.

This figure visualizes the generated images at different pruning ratios (0.3 to 0.8). It shows how the image generation time decreases as the pruning ratio increases (from 5.01s to 1.23s). While some minor image details change with higher pruning ratios, the main subjects in the images remain consistent with the input text prompts, demonstrating that the model maintains good performance even with significant pruning.

This figure illustrates the DiP-GO diffusion pruner. Part (a) shows the training process where a pruner network learns to assign importance scores to blocks in a diffusion model. The network uses queries and self-attention/fully-connected layers to capture block relationships and predict which blocks to keep or remove during inference. The network is trained using consistent and sparse losses. Part (b) demonstrates the post-processing step. After training, the pruner network is discarded. The learned importance scores determine the final pruned model (a subnet of the original model) for efficient inference.

This figure shows a comparison of images generated by the original DiT model and the pruned DiT model using DDIM with 250 steps. The pruned model achieved a 2.4x speedup while maintaining image quality comparable to the original model. The pruning was done to reduce Multiply-Accumulate operations (MACs) by 60%. The figure showcases that the pruned model can still generate high-quality images despite significant computational savings.

This figure compares the image generation quality of three different methods: SD1.5 (baseline), DeepCache, and the proposed DiP-GO method. Three different text prompts were used to generate images, and the resulting images are shown for each method. The comparison highlights the visual similarity of images generated by DiP-GO and the baseline SD1.5 model, suggesting that DiP-GO can achieve significant speedup without compromising image quality.
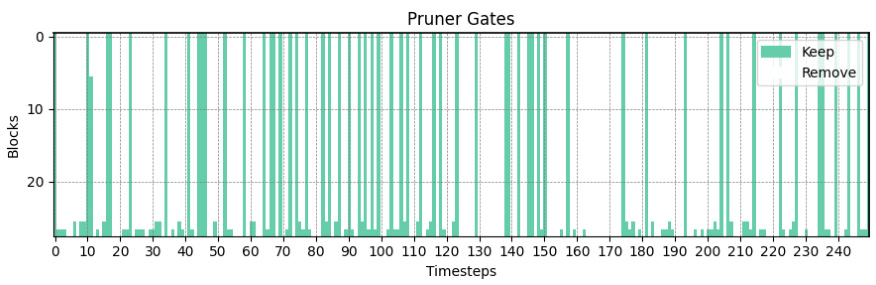
This figure visualizes the decisions made by the pruner network regarding which blocks (computational units) to keep or remove during the inference process of the DiT-XL/2 diffusion model. The x-axis represents the timesteps in the denoising process (250 in total), and the y-axis represents the blocks within the model. Each vertical bar indicates whether a block is kept (green) or removed (no bar) at each timestep. The pattern shows that the model tends to prune fewer blocks in the middle timesteps, where significant image content generation occurs, and prunes more blocks at the beginning and end.
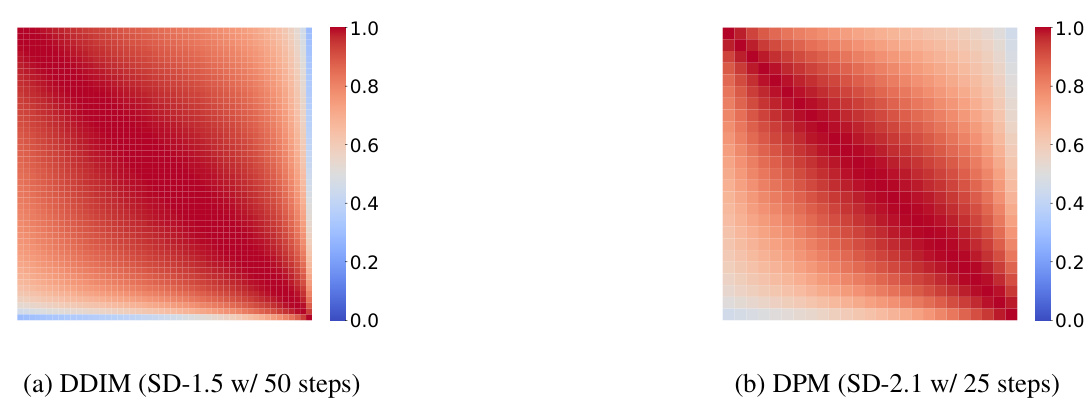
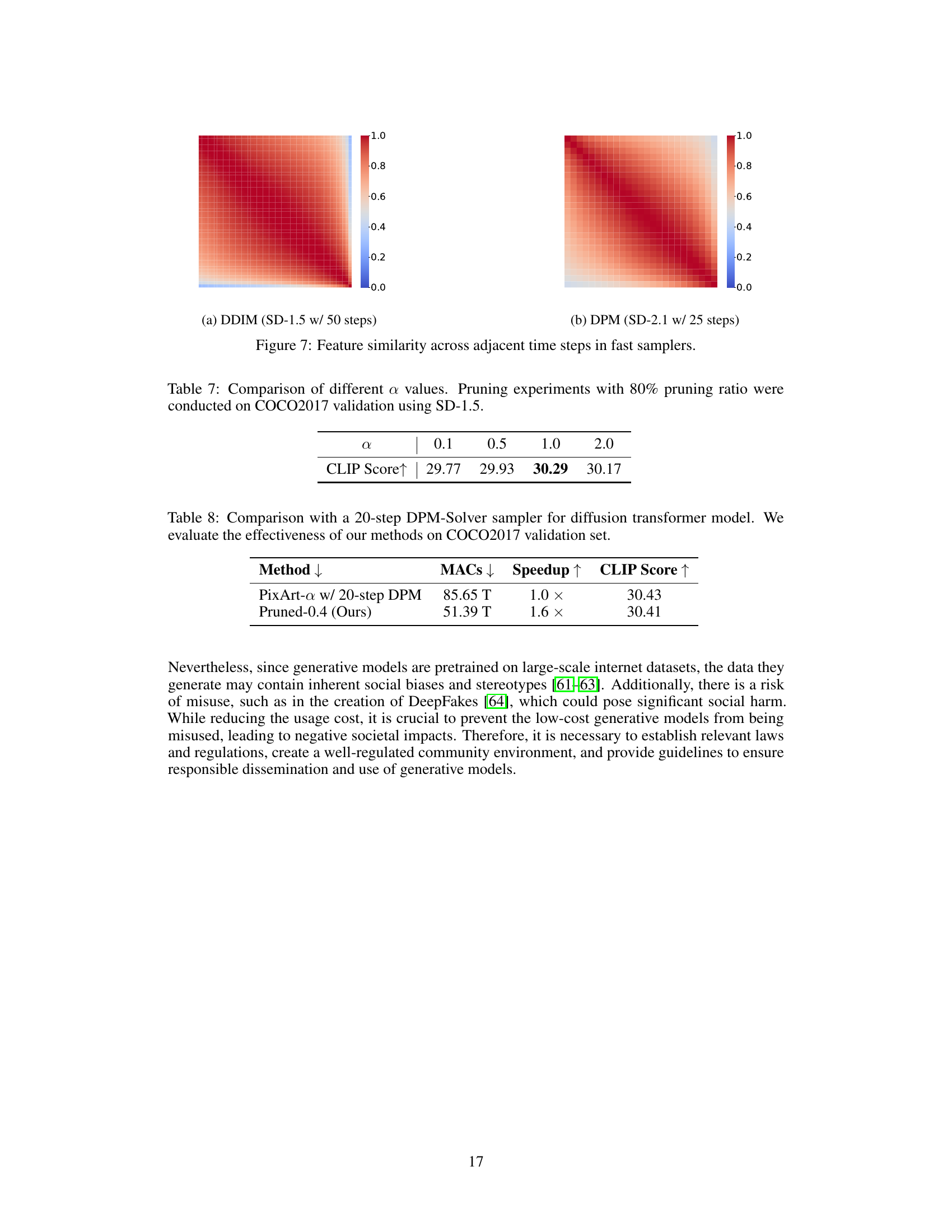
This figure shows heatmaps visualizing the feature similarity across adjacent time steps for two different fast samplers: DDIM (SD-1.5 with 50 steps) and DPM (SD-2.1 with 25 steps). The heatmaps represent the average cosine similarity between features of the penultimate upsampling block across all time steps, calculated using 200 samples from the COCO2017 validation set. Warmer colors (red) indicate higher similarity, while cooler colors (blue) represent lower similarity. The figures demonstrate a high degree of similarity between features at consecutive time steps, particularly for DDIM. This supports the paper’s argument that there is potential for computational savings by exploiting redundancy in feature computation across the inference process.
More on tables
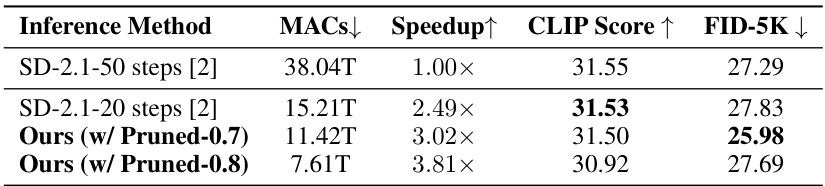
This table compares the performance of different inference methods for the Stable Diffusion 2.1 model on the MS-COCO 2017 validation set. It shows the MACs (Multiply-Accumulate Operations), which is a measure of computational complexity, speedup compared to the baseline (SD-2.1 with 50 steps), CLIP Score (a measure of image-text alignment), and FID (Fréchet Inception Distance, a measure of image quality). The methods compared include the original SD-2.1 with 50 and 20 steps, and the proposed DiP-GO method with two different pruning ratios (0.7 and 0.8).
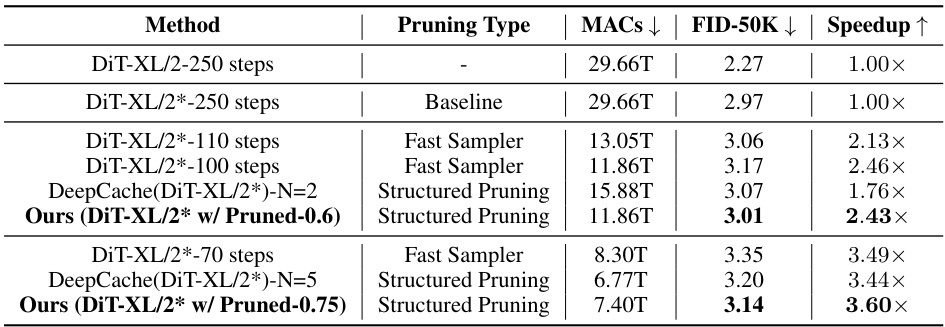
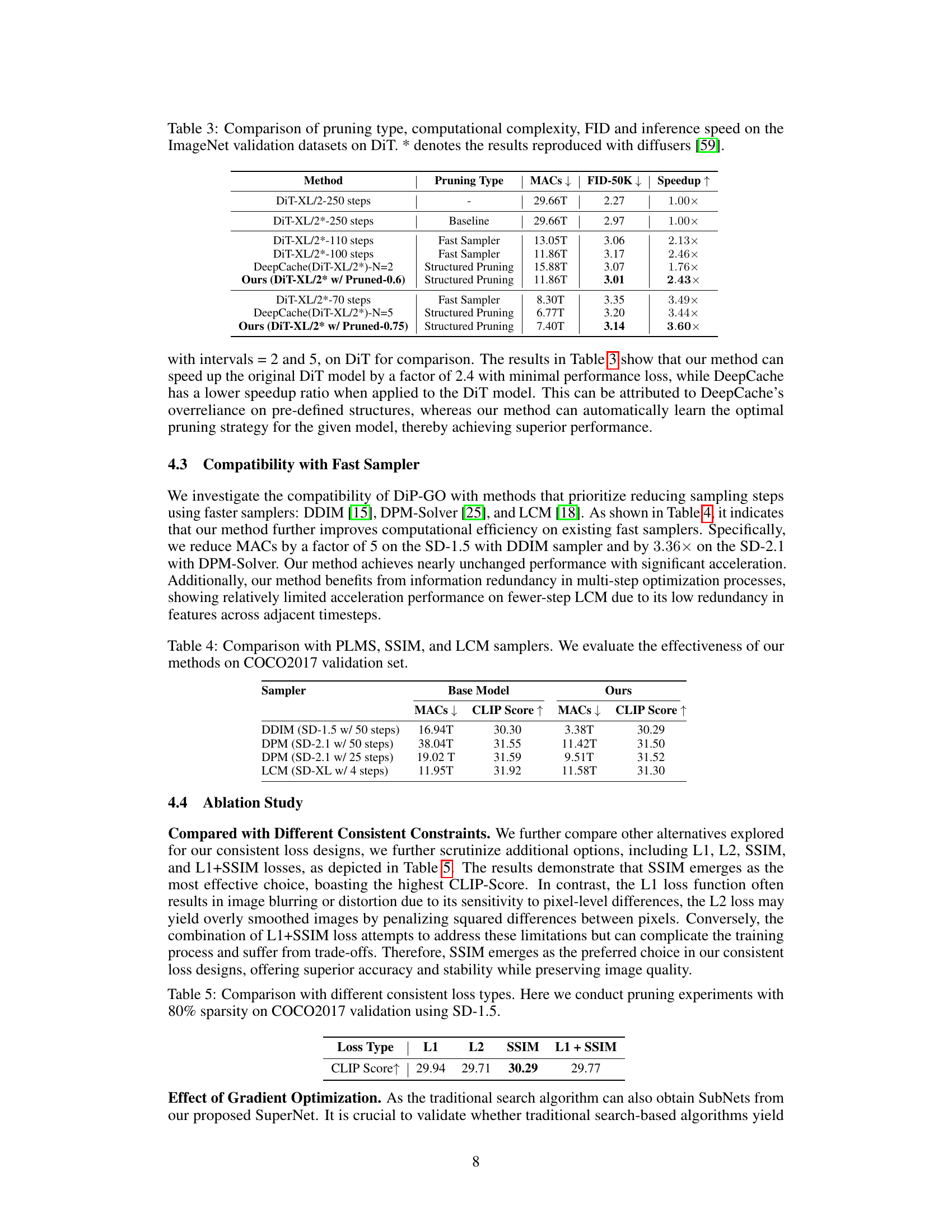
This table compares different methods for pruning the DiT model on the ImageNet validation dataset. It shows the pruning type used (structured pruning, fast sampler), the resulting MACs (multiply-accumulate operations), FID (Fréchet Inception Distance) score, and speedup achieved compared to the baseline DiT model. The results marked with * indicate that they were reproduced using the diffusers library.
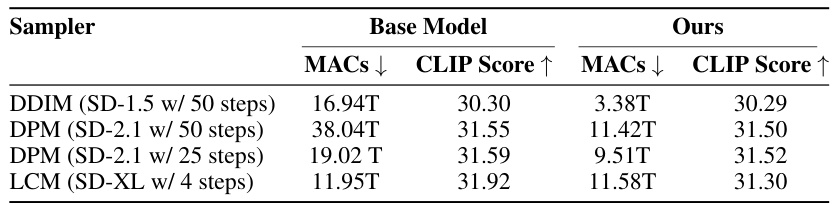
This table compares the computational efficiency (MACs) and image quality (CLIP Score) of the proposed DiP-GO method combined with different sampling methods (PLMS, DDIM, DPM-Solver, and LCM) on the MS-COCO 2017 validation set. It demonstrates the compatibility of DiP-GO with various fast samplers and shows how it further improves efficiency even when used in conjunction with these techniques. The results highlight the effectiveness of DiP-GO in accelerating inference speed without significant loss of image quality across different sampling strategies.

This table presents the results of an ablation study comparing different loss functions used in the DiP-GO model for consistent loss. The goal was to find the loss function that provides the best balance between model accuracy and sparsity. The experiment was performed on the COCO2017 validation set using the Stable Diffusion 1.5 model with an 80% pruning ratio. The results are measured using the CLIP score, a metric that evaluates the quality of generated images. The table shows that the SSIM loss function achieves the highest CLIP score, indicating better performance than L1, L2, or the combined L1 + SSIM loss functions.
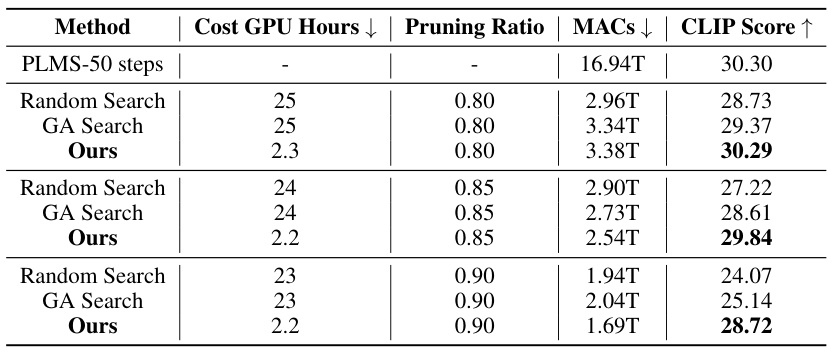
This table compares the GPU hours, pruning ratio, MACs (Multiply-Accumulate operations), and CLIP score achieved by three different methods: Random Search, Genetic Algorithm (GA) Search, and the proposed DiP-GO method, for three different pruning ratios (0.80, 0.85, and 0.90) on Stable Diffusion 1.5. It demonstrates that DiP-GO achieves superior performance in terms of CLIP score while significantly reducing the computational cost (MACs) compared to traditional search-based approaches. The table highlights the efficiency and effectiveness of DiP-GO in finding an optimal SubNet for pruned models.

This table presents the results of ablation studies conducted to determine the optimal value for the hyperparameter α in the DiP-GO model. The experiments involved pruning 80% of the model’s parameters on the COCO2017 validation set using Stable Diffusion 1.5. The table shows the CLIP Score achieved for different values of α (0.1, 0.5, 1.0, and 2.0). The CLIP Score is a metric used to evaluate the quality of generated images based on their alignment with text prompts, with higher scores indicating better quality.

This table compares the performance of the proposed DiP-GO method with a baseline method (PixArt-a with a 20-step DPM solver) on a diffusion transformer model. The comparison focuses on Multiply-Accumulate operations (MACs), speedup achieved, and CLIP score. The results demonstrate the efficiency gains obtained by DiP-GO while maintaining comparable image quality.
Full paper#