↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) often struggle with complex reasoning, especially when context is crucial. Existing methods mostly focus on refining the reasoning process itself, neglecting the importance of first understanding the logical structure within the context. This can lead to superficial understanding and unreliable results.
The paper proposes InfoRE, a novel method that re-organizes contextual information before the reasoning process. InfoRE first extracts logical relationships (parallelism, causality, etc.) and then prunes irrelevant information to reduce noise. Experiments show that InfoRE significantly improves LLMs’ performance on various context-aware, multi-hop reasoning tasks, achieving an average 4% improvement in accuracy using a zero-shot setting across all tasks. This demonstrates the effectiveness of InfoRE in improving reasoning accuracy and reliability.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation of large language models (LLMs): their struggles with complex reasoning tasks, particularly those requiring contextual awareness. By introducing the InfoRE method, the research offers a novel approach that enhances LLMs’ ability to extract logical relationships from context, leading to improved reasoning accuracy and reliability. This has significant implications for various NLP applications, opening new avenues for research on enhancing LLM reasoning capabilities and improving the quality of contextually aware systems.
Visual Insights#
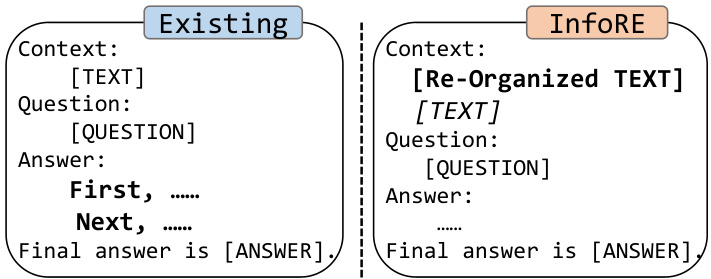
This figure compares the proposed InfoRE method with existing methods for large language model reasoning. Existing methods focus solely on improving the reasoning process itself. In contrast, InfoRE emphasizes reorganizing the input context information to explicitly highlight logical relationships before the reasoning process begins, which is believed to improve the accuracy and reliability of the results. The optional text within square brackets highlights that the original text may be used in conjunction with the re-organized information.
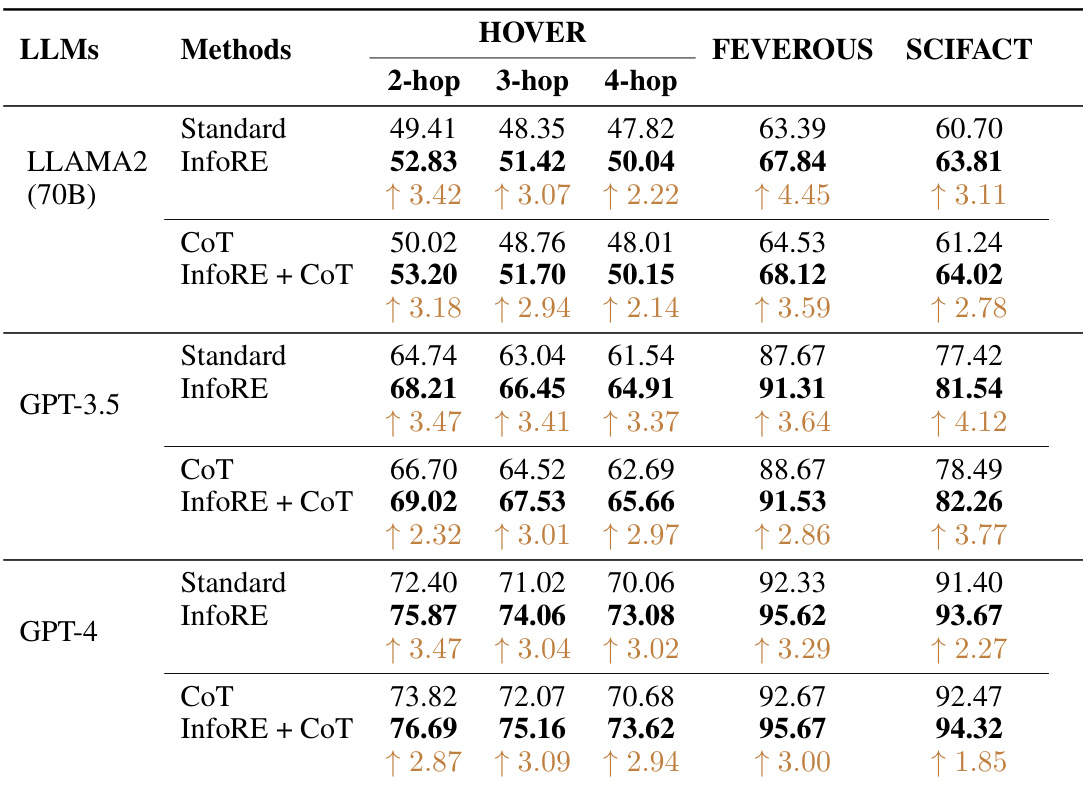
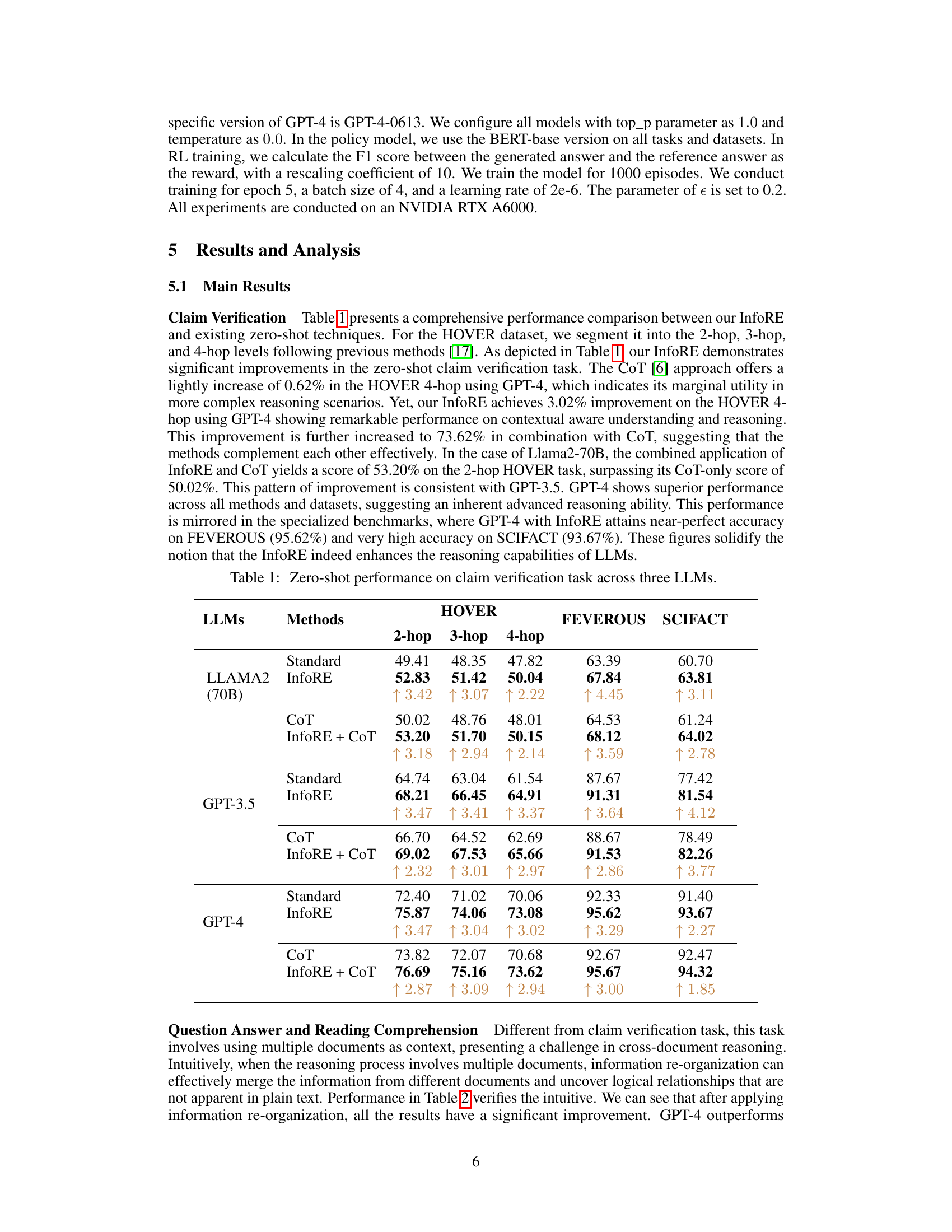
This table presents a comprehensive performance comparison of three different LLMs (Llama2-70B, GPT-3.5, and GPT-4) across various claim verification tasks using a zero-shot setting. The results are broken down by the number of hops required for reasoning (2-hop, 3-hop, 4-hop) and show the performance of four different methods: Standard (baseline), InfoRE (the proposed method), CoT (Chain-of-Thought), and InfoRE + CoT (combination of InfoRE and CoT). The improvements achieved by InfoRE over the baseline are clearly indicated in the table for each task and LLM. This demonstrates the effectiveness of the InfoRE method in enhancing the reasoning capabilities of LLMs.
In-depth insights#
LLM Reasoning Boost#
An LLM Reasoning Boost section in a research paper would likely explore methods for enhancing the reasoning capabilities of large language models. This could involve examining various prompt engineering techniques, such as chain-of-thought prompting or tree-of-thoughts, which guide the LLM through a step-by-step reasoning process. The section might also delve into model architecture modifications, perhaps focusing on incorporating external knowledge bases or integrating specialized reasoning modules to improve performance on complex tasks. A critical aspect would be the evaluation methodology, detailing the benchmarks and metrics used to assess the effectiveness of the proposed boosting strategies. Furthermore, the discussion might cover limitations of the approach, including potential biases or vulnerabilities, along with suggestions for future research directions. The overall goal would be to present a comprehensive and insightful analysis of techniques to improve LLM reasoning, ultimately leading to more reliable and accurate outputs.
InfoRE Methodology#
The InfoRE methodology, designed to enhance Large Language Model (LLM) reasoning, centers on re-organizing contextual information before the reasoning process begins. This contrasts with existing methods that primarily focus on refining the reasoning steps themselves. InfoRE initially extracts logical relationships from the input text using a MindMap structure, which captures both explicit and implicit connections. Then, a pruning step uses a reinforcement learning model (trained with BERT) to remove irrelevant or distracting information, effectively reducing noise. The resultant re-organized context, enriched with clearly defined logical connections and devoid of extraneous details, is then fed into the LLM for reasoning. This approach allows the LLM to develop a deeper, more nuanced understanding of the context, leading to improved accuracy and reliability in the final answer. The efficacy is demonstrated via experiments on various tasks, showing significant improvements over standard and Chain-of-Thought methods.
Multi-Hop QA Tests#
In a hypothetical research paper section on ‘Multi-Hop QA Tests’, a thorough evaluation would demand a multifaceted approach. We’d expect a detailed description of the datasets used, emphasizing their suitability for assessing multi-hop reasoning abilities. Key characteristics, such as the complexity of the reasoning chains (number of hops), the diversity of question types, and the presence of distractors, would need clear articulation. The evaluation methodology should be explicitly defined, specifying the metrics employed (e.g., exact match, F1 score) and the baseline models against which the proposed method is compared. A rigorous statistical analysis of the results is crucial, potentially involving significance tests to ensure reliable conclusions. The discussion section should critically analyze the findings, acknowledging limitations and suggesting avenues for future research. Crucially, the analysis should explore the reasons behind both successes and failures, offering insights into the model’s strengths and weaknesses. The overall presentation should be clear, concise, and well-structured, enabling readers to fully grasp the methodology and appreciate the significance of the results in advancing multi-hop question answering.
Ablation Study#
An ablation study systematically removes components of a model to determine their individual contributions. In the context of a research paper on improving large language model reasoning, an ablation study might investigate the impact of different stages in a proposed pipeline. For instance, it could evaluate the effect of removing the information re-organization step, the extraction process, or the pruning component. By isolating each part, the researchers could precisely quantify its impact on the overall reasoning accuracy. This helps to validate the necessity of each module, revealing whether they are crucial for improved performance or simply contribute marginally. Such an analysis would also reveal potential redundancies or areas where optimization can be focused, furthering the understanding of the model’s strengths and weaknesses. The results could influence future development, highlighting core components for improved reasoning ability and potentially suggesting simplifications to the architecture if certain components prove dispensable.
Future Enhancements#
Future enhancements for this information re-organization approach could involve exploring diverse information structures beyond MindMaps, such as knowledge graphs or hierarchical tree structures, to better capture complex relationships. The integration of more sophisticated noise reduction techniques, potentially using advanced machine learning models, is crucial. Furthermore, researching methods to automate the extraction process entirely and expanding beyond zero-shot settings to incorporate few-shot or fine-tuned models will significantly boost performance. Addressing scalability for very large contexts and multilingual support is key to broader applicability. Finally, investigating and mitigating potential biases present in the source content and the employed LLMs is essential to ensure the reliability and fairness of the enhanced reasoning process. Thorough evaluation on a wider range of benchmark datasets and tasks is needed to validate generalizability and robustness.
More visual insights#
More on figures

This figure illustrates the InfoRE method’s framework. It shows two main components: 1. Information Re-organization: This stage involves extracting logical relationships from the context (using a MindMap structure) and then pruning irrelevant information using a BERT-based model trained with reinforcement learning. The reward function for the RL training is the F1 score. 2. Reasoning: This stage uses the re-organized context (along with the optional original context) to answer the question using an LLM. The example given in the figure highlights how the re-organized information helps in directly answering the question.
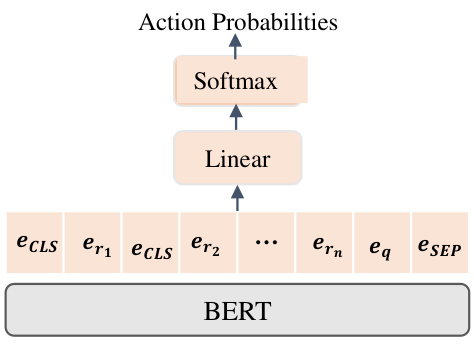
This figure illustrates the architecture of the pruning model used in the InfoRE method. The input consists of concatenated logical relationships and their corresponding attributes from the extracted context, along with the question. A pre-trained BERT model processes this input. The output of the BERT model is then passed through a linear layer and a softmax function to produce action probabilities for each logical relationship (keep or delete). The [CLS] token representation is crucial for the model to determine which relationships are relevant for answering the question and which should be removed to reduce noise.
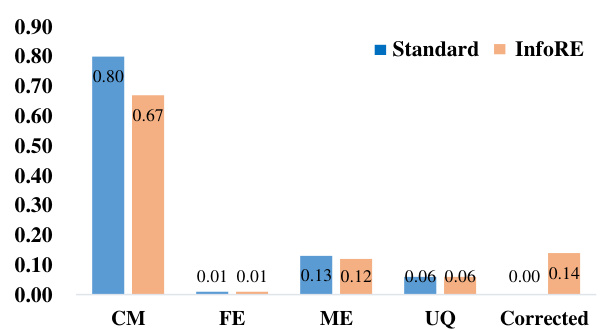
This figure presents a bar chart comparing the error rates of the baseline method (Standard) and the proposed InfoRE method across different error categories in the 2WikiMultiHopQA dataset. The error categories are: Contextual Misunderstanding (CM), Factual Error (FE), Mathematical Error (ME), and Unanswerable Question (UQ). The ‘Corrected’ category shows the percentage of errors from the Standard method that were successfully addressed by InfoRE. It visually demonstrates the effectiveness of InfoRE in reducing contextual misunderstanding errors, which were the most frequent type of error in the baseline method.
More on tables
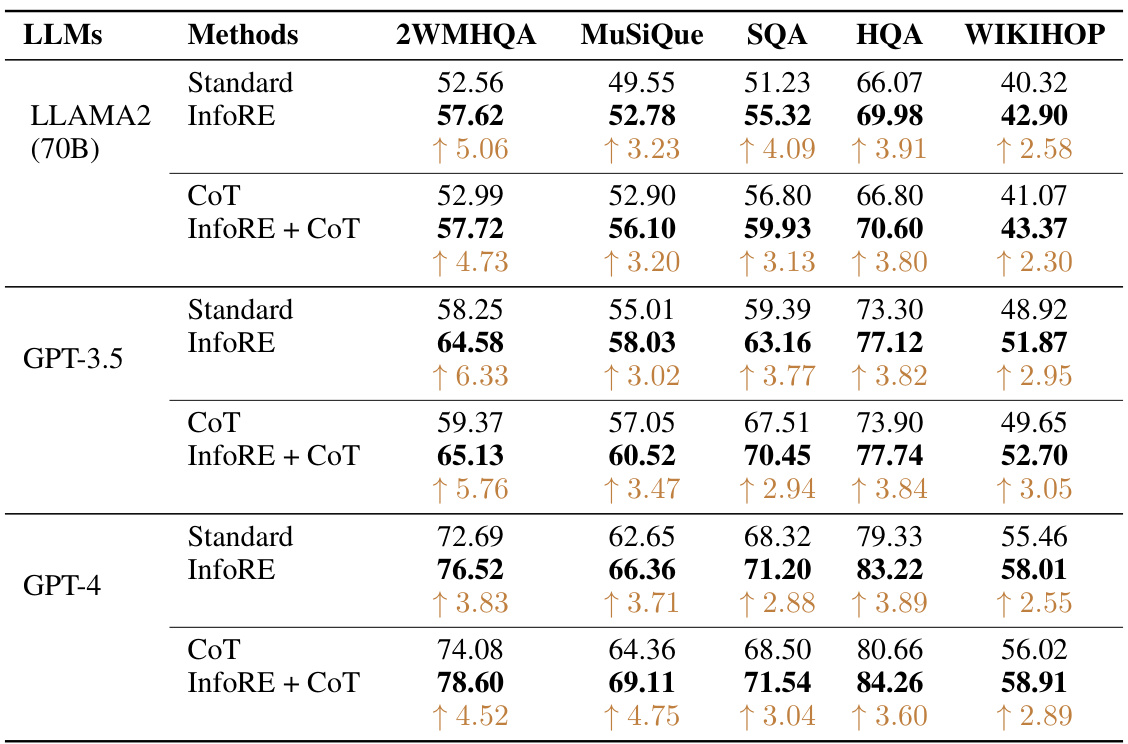
This table presents a comparison of the performance of three different large language models (LLMs) - Llama2-70B, GPT-3.5, and GPT-4 - on claim verification tasks. It shows the zero-shot performance (no training data) of each LLM using four methods: Standard (direct reasoning), InfoRE (information re-organization), CoT (chain of thought), and a combination of InfoRE and CoT. The results are broken down by dataset (HOVER, FEVEROUS, SCIFACT) and, for HOVER, by the number of reasoning hops (2-hop, 3-hop, and 4-hop). The improvement achieved by InfoRE is highlighted.

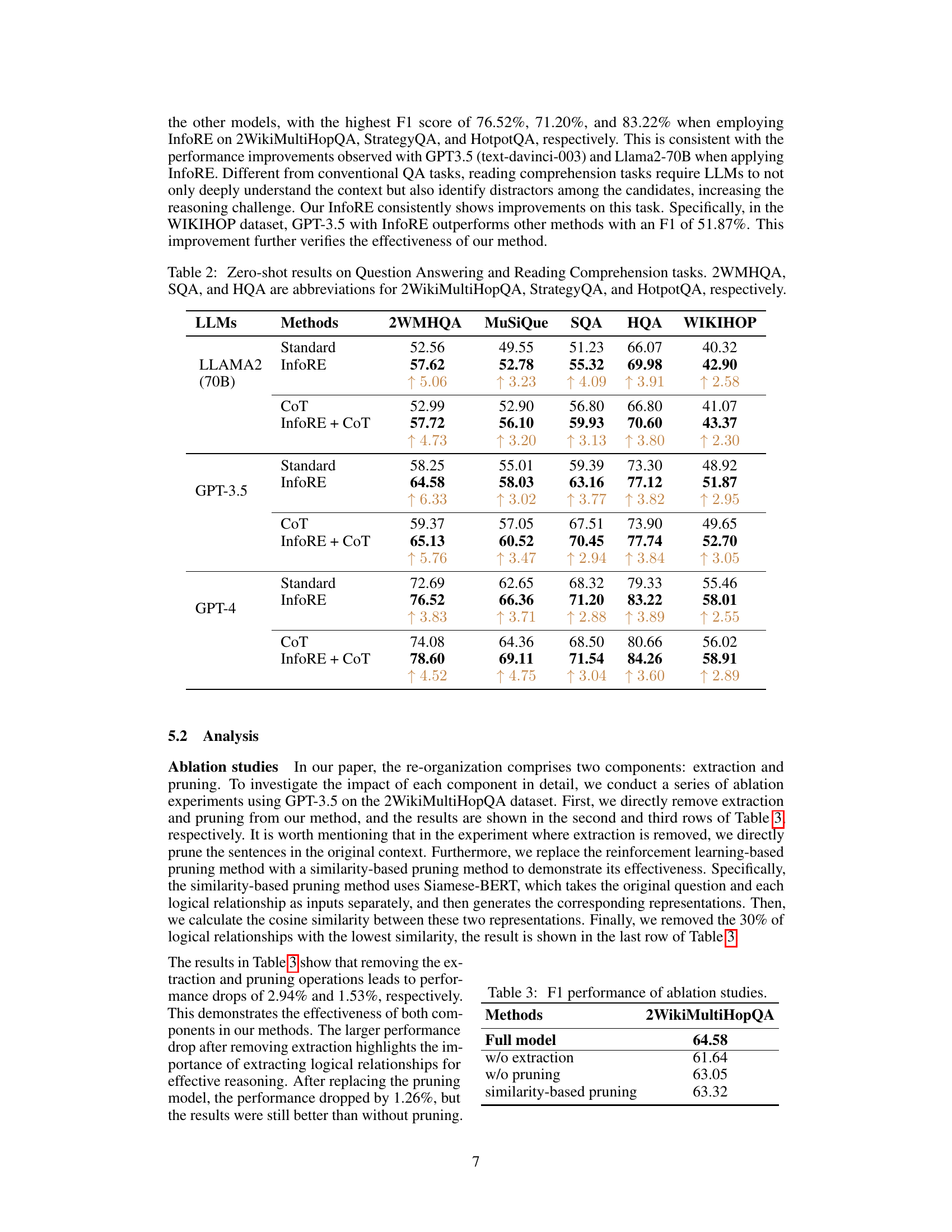
This table presents the results of ablation studies conducted on the 2WikiMultiHopQA dataset using GPT-3.5. The purpose was to evaluate the individual contributions of the extraction and pruning components within the InfoRE method. Rows show the F1 score when either extraction or pruning is removed from the model, and also when a similarity-based method replaces the RL-based pruning. The results demonstrate that both extraction and pruning improve performance, with the extraction step contributing more significantly than the pruning step.
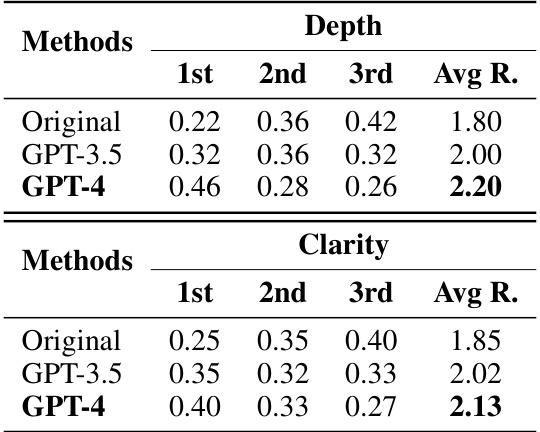
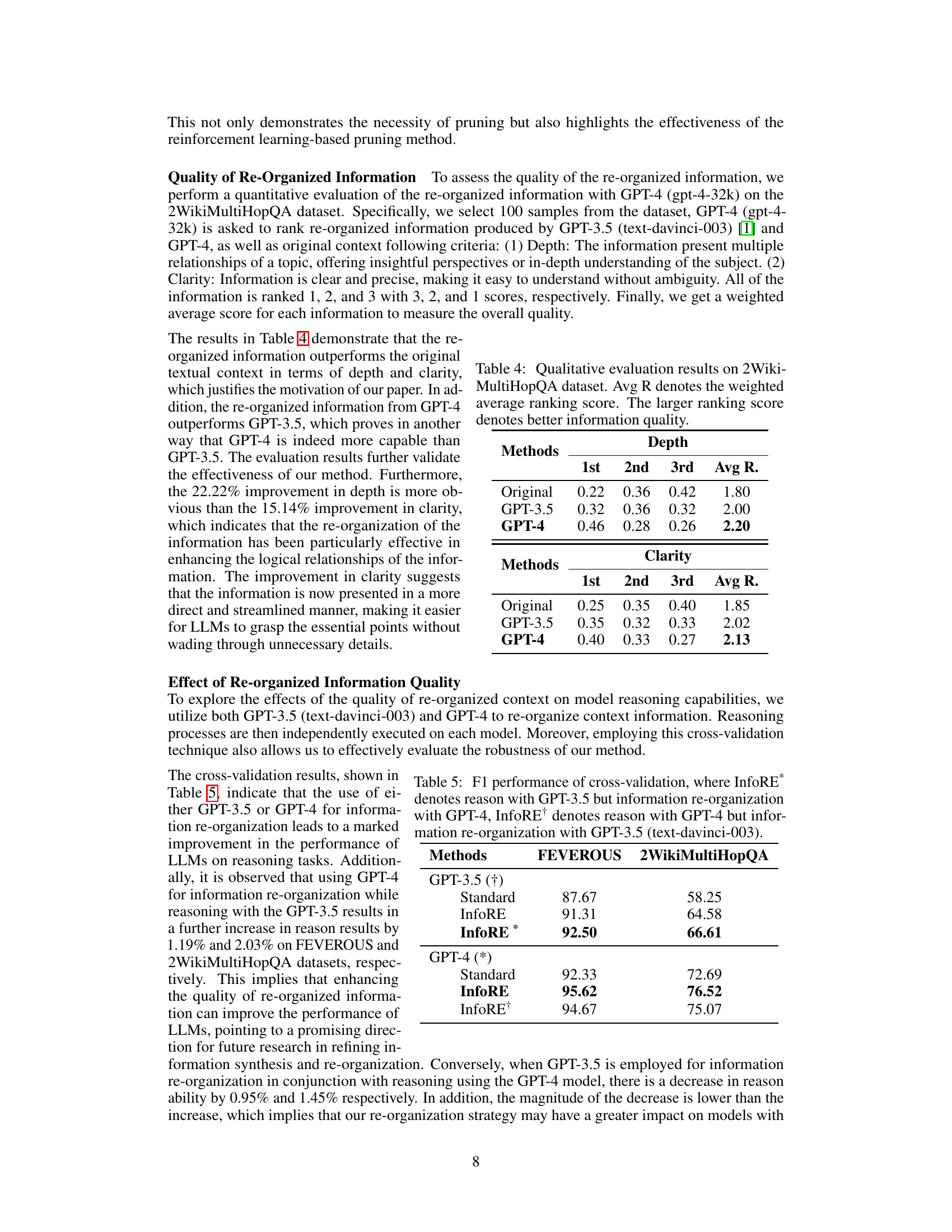
This table presents a qualitative evaluation of the quality of re-organized information generated by GPT-3.5 and GPT-4 models, compared to the original text. The evaluation is performed using GPT-4 (gpt-4-32k) on 100 samples from the 2WikiMultiHopQA dataset. Two aspects of information quality are assessed: Depth (presence of multiple relationships and insightful perspectives) and Clarity (clear and precise information). Each aspect is rated on a 3-point scale (1-3), with 3 representing the highest quality. The weighted average score (Avg R) summarizes the overall quality for each information type.
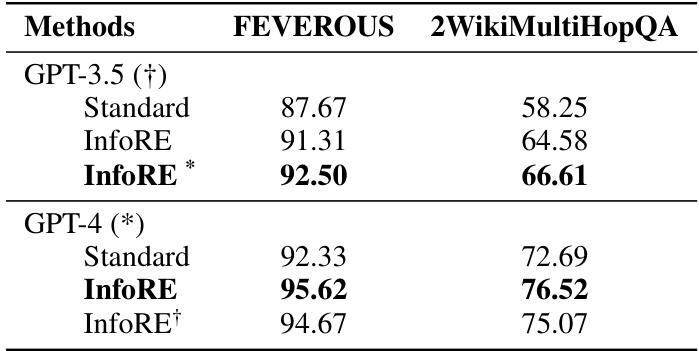
This table presents a comprehensive performance comparison of three large language models (LLMs): Llama2-70B, GPT-3.5, and GPT-4, across three different claim verification datasets (HOVER, FEVEROUS, and SCIFACT) using a zero-shot setting. The performance is measured in terms of F1 score for each model on various hop levels. Comparisons are made between the standard approach, the Chain-of-Thought (CoT) method, the proposed InfoRE method, and the combination of InfoRE and CoT. The table showcases the significant improvements achieved by the InfoRE method, particularly in complex multi-hop reasoning scenarios.

This table presents a comparison of zero-shot performance on claim verification tasks across three different large language models (LLMs): Llama2-70B, GPT-3.5, and GPT-4. The performance is measured across different datasets (HOVER, FEVEROUS, SCIFACT) and various experimental setups (Standard, InfoRE, CoT, InfoRE + CoT). The results show the improvement achieved by the proposed InfoRE method in improving the zero-shot reasoning performance of LLMs.
This table presents a comprehensive performance comparison of three large language models (LLMs) — Llama2-70B, GPT-3.5, and GPT-4 — on claim verification tasks. The models are evaluated using several different methods: a standard approach, a chain-of-thought (CoT) approach, the proposed InfoRE method, and a combination of InfoRE and CoT. The results are shown for three different datasets (HOVER with 2-hop, 3-hop, and 4-hop levels, FEVEROUS, and SCIFACT) and demonstrate the impact of each method on the models’ ability to perform zero-shot claim verification.
This table presents a comparison of the performance of three different large language models (LLMs) - Llama2-70B, GPT-3.5, and GPT-4 - on claim verification tasks. It shows the zero-shot performance (no fine-tuning) across three different datasets (HOVER, FEVEROUS, SCIFACT) using several methods: Standard (baseline), InfoRE (the proposed method), Chain-of-Thought (CoT), and the combination of InfoRE and CoT. The results are presented as F1 scores for 2-hop, 3-hop, and 4-hop reasoning tasks for the HOVER dataset, and overall F1 score for FEVEROUS and SCIFACT.
Full paper#