↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep neural networks often suffer from overconfidence, making incorrect predictions with high confidence scores. This is particularly problematic in high-risk applications where reliable predictions are crucial. Existing methods, such as calibrating confidence scores, often fail to adequately address the root cause of this overconfidence issue.
The paper introduces a novel approach called Typicalness-Aware Learning (TAL) to tackle this problem. TAL identifies and handles atypical samples (those that differ significantly from typical samples in their semantic features) differently during training. By adjusting the magnitude of prediction logits based on sample typicalness, TAL reduces overconfidence while preserving reliable prediction directions. Extensive experiments across several datasets show that TAL achieves significant improvements in failure detection performance compared to existing methods, outperforming state-of-the-art techniques.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on failure detection and deep learning, particularly those focusing on improving the reliability and trustworthiness of predictions in high-stakes applications. It introduces a novel approach to mitigate the overconfidence issue in deep neural networks, a significant problem hindering the applicability of these models in various domains. The proposed method, along with the comprehensive analysis and experiments, offers valuable insights and potential solutions that could advance the state-of-the-art. It also opens new avenues for exploring more robust and reliable deep learning models.
Visual Insights#
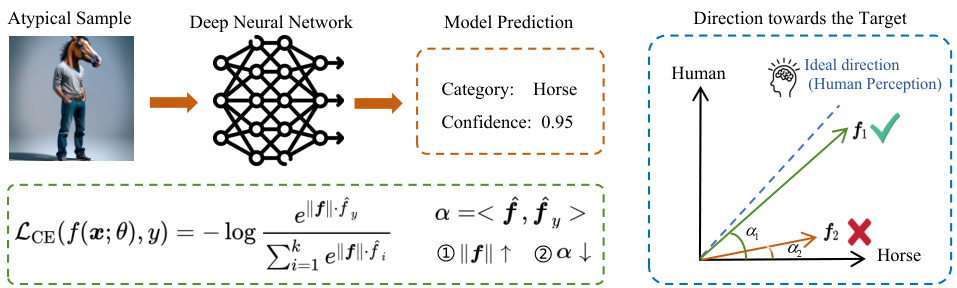
The figure illustrates the problem of overconfidence in deep neural networks (DNNs) when dealing with atypical samples. A cross-entropy loss function attempts to align model predictions with labels by increasing the magnitude of the logit vector or adjusting its direction. In the case of atypical images (e.g., a picture of a human body with a horse’s head), this approach can lead to overconfidence because the label may not reflect the image content accurately. The figure shows how the ideal prediction should align with human perception (f1) rather than being biased towards either the true label or a false label (f2), leading to more accurate confidence estimation.

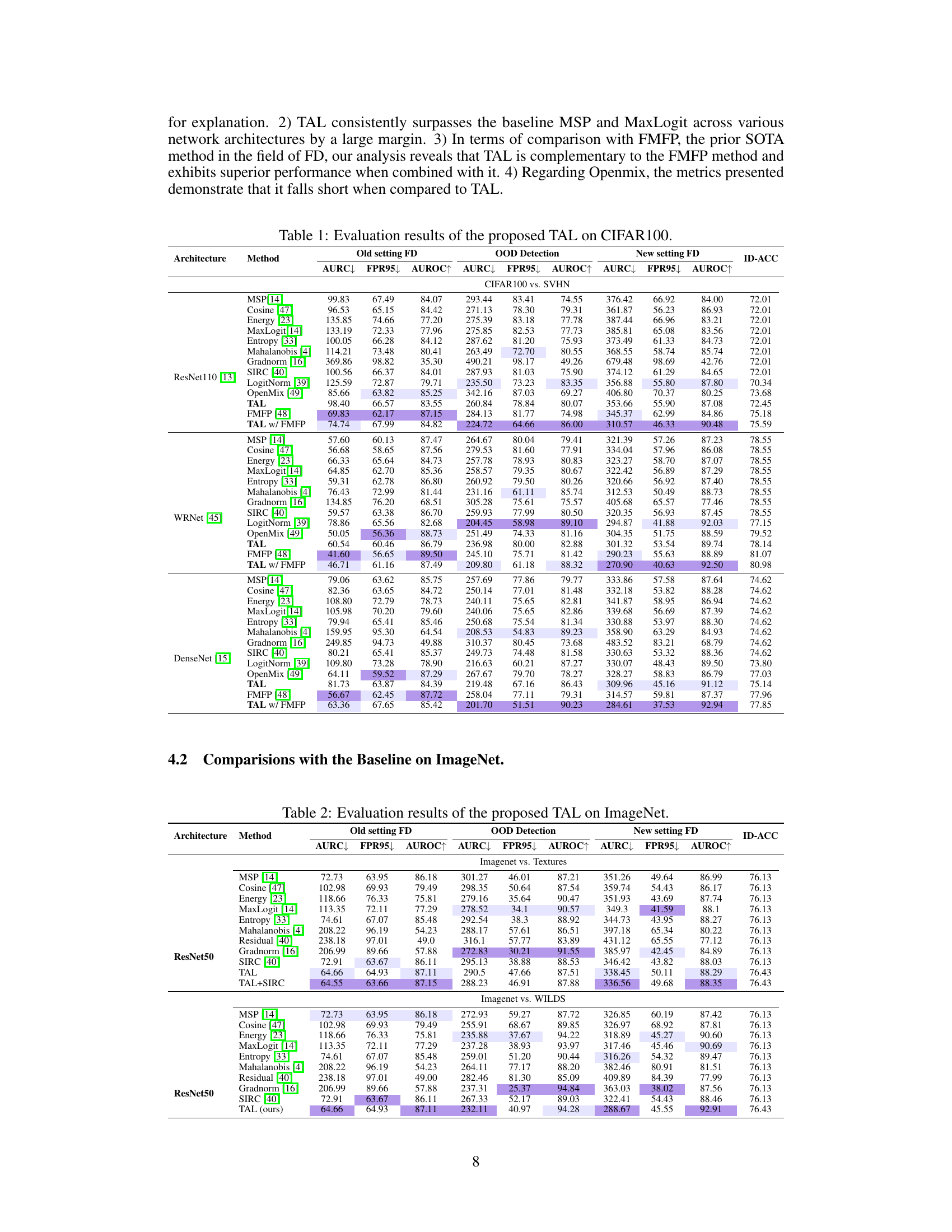
This table presents a comparison of the proposed TAL method with several baseline methods for failure detection on the CIFAR-100 dataset, using three different settings (Old FD, OOD Detection, and New FD) and various network architectures. The results are presented in terms of AURC (Area Under the Risk-Coverage Curve), FPR95 (False Positive Rate at 95% True Positive Rate), AUROC (Area Under the Receiver Operating Characteristic Curve), and ID-ACC (In-Distribution Accuracy). The table shows that TAL consistently outperforms baseline methods across different settings and architectures, demonstrating its effectiveness in improving failure detection performance.
In-depth insights#
Overconfidence Issue#
The overconfidence issue in deep neural networks (DNNs) is a critical problem where models produce incorrect predictions with high confidence scores. This is particularly problematic in high-stakes applications like medical diagnosis and autonomous driving where reliable predictions are paramount. The root cause often stems from the training process, specifically the use of cross-entropy loss, which optimizes model predictions to align with labels by increasing the magnitude of logits. This emphasis on magnitude, particularly with atypical samples (data points that deviate significantly from the majority), leads to overfitting and inflated confidence scores. Addressing this overconfidence requires methodologies that decouple confidence estimation from prediction accuracy. This often involves focusing on alternative measures of uncertainty that better reflect the model’s actual confidence, such as those based on the direction of logit vectors rather than their magnitude, or incorporating mechanisms to identify and handle atypical data points differently during training, leading to more calibrated and trustworthy model outputs.
TAL Framework#
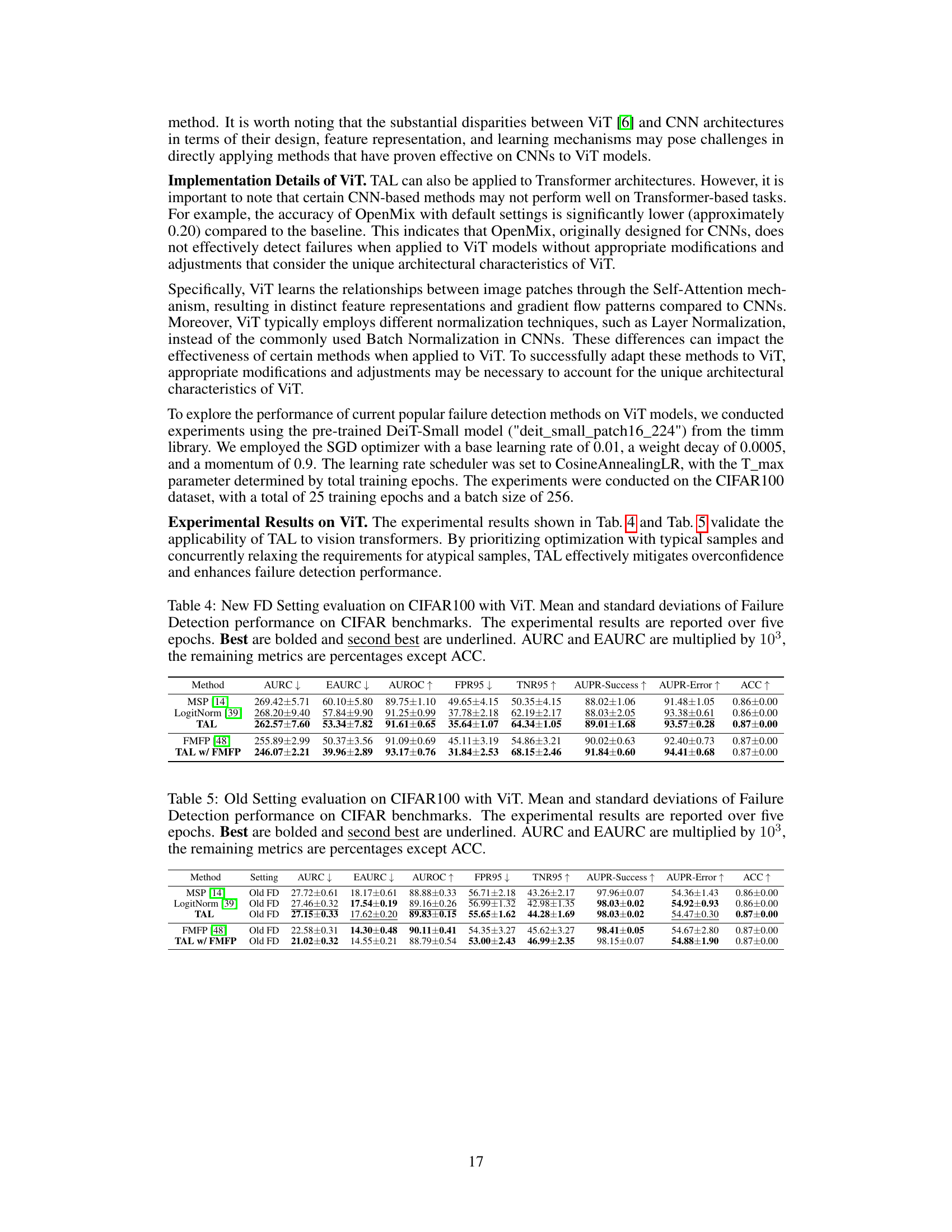
The TAL (Typicalness-Aware Learning) framework introduces a novel approach to failure detection by addressing the overconfidence issue in deep neural networks. It dynamically adjusts the magnitude of logits based on a calculated typicalness score for each sample. This score reflects how representative a sample is of the overall data distribution, with atypical samples receiving a lower typicalness score. The framework uses this score to modulate the influence of the cross-entropy loss and a proposed typicalness-aware loss. Atypical samples, which might lead to overconfidence, are less strongly optimized, preserving more reliable logit directions. The framework also utilizes a historical features queue to maintain a representation of typical samples for calculating the typicalness score. The TAL framework’s model-agnostic nature allows for easy integration with various architectures, enhancing reliability and trustworthiness in failure detection predictions. The decoupling of logit magnitude and direction is a crucial element in mitigating overconfidence, making the direction a more reliable confidence indicator.
Typicalness Metric#
A crucial aspect of the proposed Typicalness-Aware Learning (TAL) framework is the quantification of sample typicality. The “Typicalness Metric” isn’t explicitly named as such in the provided text, but the concept is central. The method leverages statistical analysis of feature representations, comparing a sample’s mean and variance to a historical queue (HFQ) of features from previously correctly classified, typical samples. This comparison produces a scalar value (τ) representing the sample’s typicalness; high τ indicates typicality, while low τ suggests atypicality. The design inherently acknowledges the limitations of directly aligning predictions of atypical samples with their labels, which the authors posit can lead to overconfidence. By dynamically adjusting logit magnitudes based on τ during training, TAL effectively mitigates the influence of atypical samples while preserving reliable logit directions for better confidence estimation. The HFQ acts as a dynamic representation of typicality, constantly adapting based on training data, making the metric robust and effective even with evolving data distributions. However, the specific choice of mean and variance for comparison, while justified empirically, warrants further investigation to ascertain its optimality and generality across diverse datasets and model architectures.
CIFAR/ImageNet Res.#
The heading ‘CIFAR/ImageNet Res.’ likely refers to the results section of a research paper focusing on image classification using Convolutional Neural Networks (CNNs), where performance is evaluated on the CIFAR-10/100 and ImageNet datasets. A thoughtful analysis would expect this section to present quantitative results, comparing the model’s performance (e.g., accuracy, precision, recall, F1-score) against established baselines. Detailed tables and graphs visually presenting these metrics across various model architectures (e.g., ResNet, EfficientNet) would be expected. The discussion should highlight key performance differences between the datasets, potentially revealing model robustness or limitations. Important observations might include whether the model generalizes well from smaller datasets (CIFAR) to the significantly larger ImageNet, or if performance plateaus indicate a need for architectural improvements. Finally, a thorough examination would compare the attained results to the state-of-the-art for each dataset, emphasizing any significant improvements and providing contextual explanations for any performance shortfalls.
Future Works#
Future work in this research area could explore several promising avenues. Extending the TAL framework to other modalities, such as audio or sensor data, would broaden its applicability. Investigating the impact of different typicality measures and their effect on model performance is crucial. A deeper understanding of the interplay between typicality, overconfidence, and failure detection is needed, particularly in the context of complex, real-world scenarios. Developing more sophisticated methods for identifying atypical samples is also important, potentially using techniques like anomaly detection or generative models. Finally, exploring the generalizability of TAL across various architectures and datasets would strengthen its robustness and practical value. Furthermore, analyzing the effectiveness of TAL in conjunction with other uncertainty quantification methods deserves attention.
More visual insights#
More on figures

This figure compares three different approaches to failure detection: Out-of-Distribution detection (OoD-D), traditional failure detection (Old FD), and the proposed new failure detection method (New FD). It illustrates their differences in how they handle correct and incorrect predictions under various scenarios: in-distribution data, covariate shifts, and semantic shifts. The figure highlights that New FD considers both in-distribution data and covariate shift predictions as ‘success’ cases, rejecting only incorrect predictions regardless of their origin. In contrast, OoD-D only considers semantic shifts, and Old FD only addresses covariate shifts.
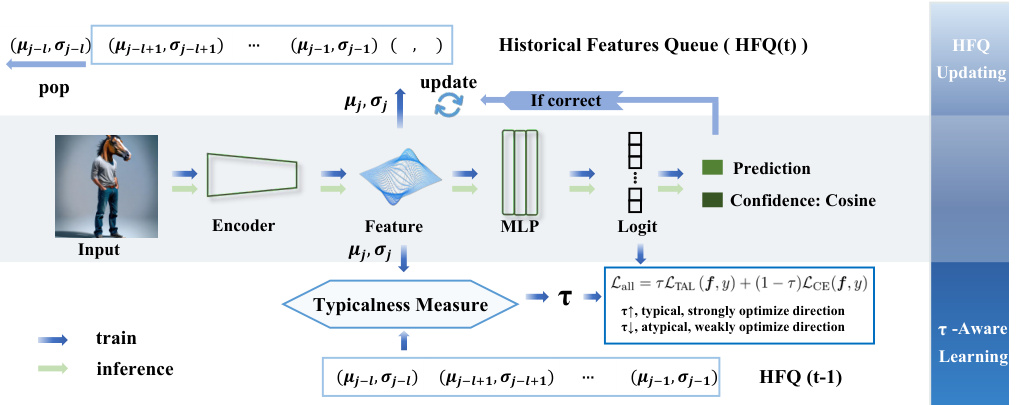
This figure illustrates the framework of the Typicalness-Aware Learning (TAL) method proposed in the paper. It shows how TAL dynamically adjusts logit magnitudes based on a sample’s typicalness, which is calculated by comparing the sample’s features to a historical queue of typical features. The figure details the training and inference processes, emphasizing the use of cosine similarity for confidence estimation in the inference phase.
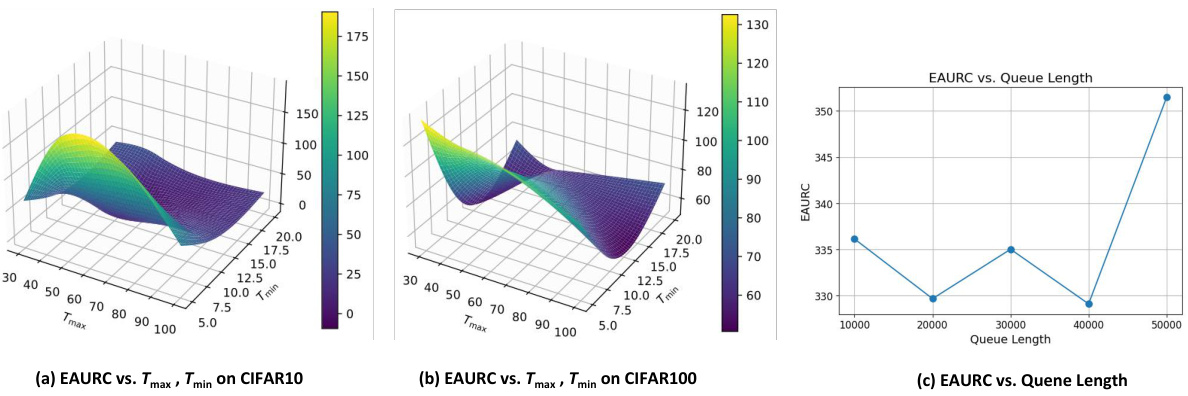
This figure presents the results of ablation studies conducted to evaluate the impact of different hyperparameters and architectural choices on the proposed TAL model. Specifically, subfigures (a) and (b) show the effect of varying Tmin and Tmax (lower and upper bounds for the dynamic magnitude T(τ)) on the EAURC metric for CIFAR10 and CIFAR100 datasets respectively. The 3D surface plots visualize the EAURC scores across a range of Tmin and Tmax values. Subfigure (c) illustrates the effect of varying the length of the Historical Feature Queue (HFQ) on EAURC for CIFAR100. The line plot shows that the performance is stable for queue lengths between 10,000 and 50,000 but decreases when the length exceeds 50,000.

This figure shows four subfigures that illustrate different aspects of the Typicalness-Aware Learning (TAL) method. (a) compares the mean of features between in-distribution (ID) and out-of-distribution (OOD) samples. (b) compares different methods for measuring typicality, including GMM, mean & variance, and KNN. (c) shows the risk-coverage curves for both old and new failure detection tasks, illustrating the performance improvement achieved by TAL. (d) shows examples of typical and atypical samples, further clarifying the concept of typicalness used in the TAL method.

This figure displays kernel density estimations for confidence scores produced by three different out-of-distribution (OOD) detection methods: MSP, Energy, and LogitNorm. Each plot shows the distributions for correctly classified in-distribution (ID) samples, incorrectly classified ID samples, and OOD samples. The overlap ratios between these distributions are quantified, illustrating that OOD methods result in greater overlap between correctly and incorrectly classified samples compared to what is desired, hindering their effectiveness for failure detection.
More on tables
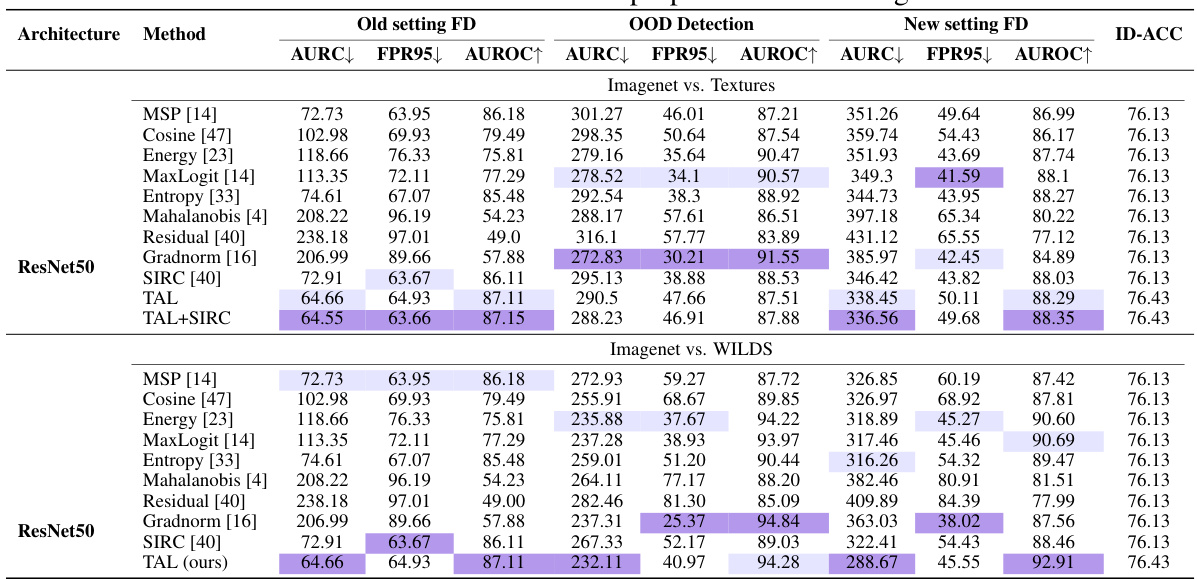
This table presents the performance comparison of the proposed TAL method against various baseline methods for failure detection on the CIFAR100 dataset. It shows the results across three different settings: Old FD, OOD Detection, and New FD. Each setting has different criteria for evaluating the performance, with metrics including AURC, FPR95, and AUROC. The table also indicates the ID-ACC (In-distribution Accuracy) for each method. It further breaks down the results across different network architectures, such as ResNet110, WRNet, and DenseNet, providing a comprehensive analysis of TAL’s effectiveness in various scenarios.

This table presents the ablation study results for the key components of the Typicalness-Aware Learning (TAL) method. It shows the impact of removing or modifying core components of TAL on its performance for failure detection using the Old FD and New FD settings. Specifically, it compares the performance of TAL with a fixed magnitude T (Fixed T), and TAL with a fixed magnitude T and the addition of cross-entropy loss (Fixed T + Cross entropy). The results demonstrate the contribution of each component of TAL to improving failure detection performance. The metrics include AURC, EAURC, AUROC, FPR95, TNR95, AUPR-Success, AUPR-Error, and ACC.

This table presents a comparison of the proposed TAL method against several baselines on the CIFAR100 dataset for failure detection. It shows the performance of each method across different metrics under three settings: Old FD, OOD detection, and New FD. The metrics include Area Under the Risk-Coverage Curve (AURC), False Positive Rate at 95% True Positive Rate (FPR95), Area Under the Receiver Operating Characteristic Curve (AUROC), and Area Under the Precision-Recall Curve (AUPR) for both success and error, along with the test accuracy (ACC). The results demonstrate the superior performance of TAL, especially in the New FD setting, which considers a broader range of failure scenarios.

This table presents the performance comparison of different failure detection methods on the CIFAR100 dataset, using three different settings: Old FD, OOD detection, and New FD. The results show the Area Under the Risk-Coverage Curve (AURC), False Positive Rate at 95% True Positive Rate (FPR95), Area Under the ROC Curve (AUROC), Area Under the Precision-Recall Curve for Success and Error (AUPR-Success and AUPR-Error), and accuracy (ACC). It compares the proposed TAL method with multiple baseline methods across various network architectures.
Full paper#