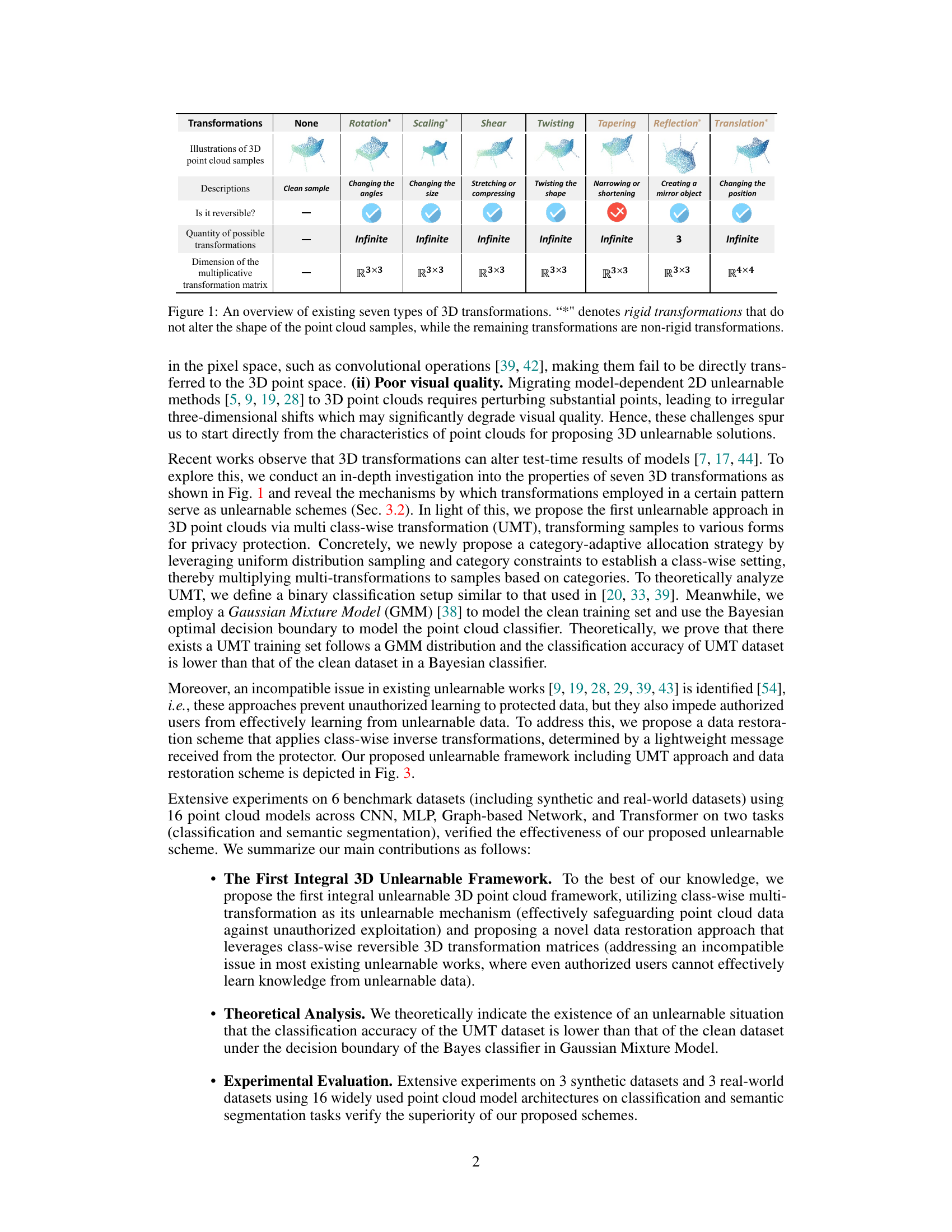
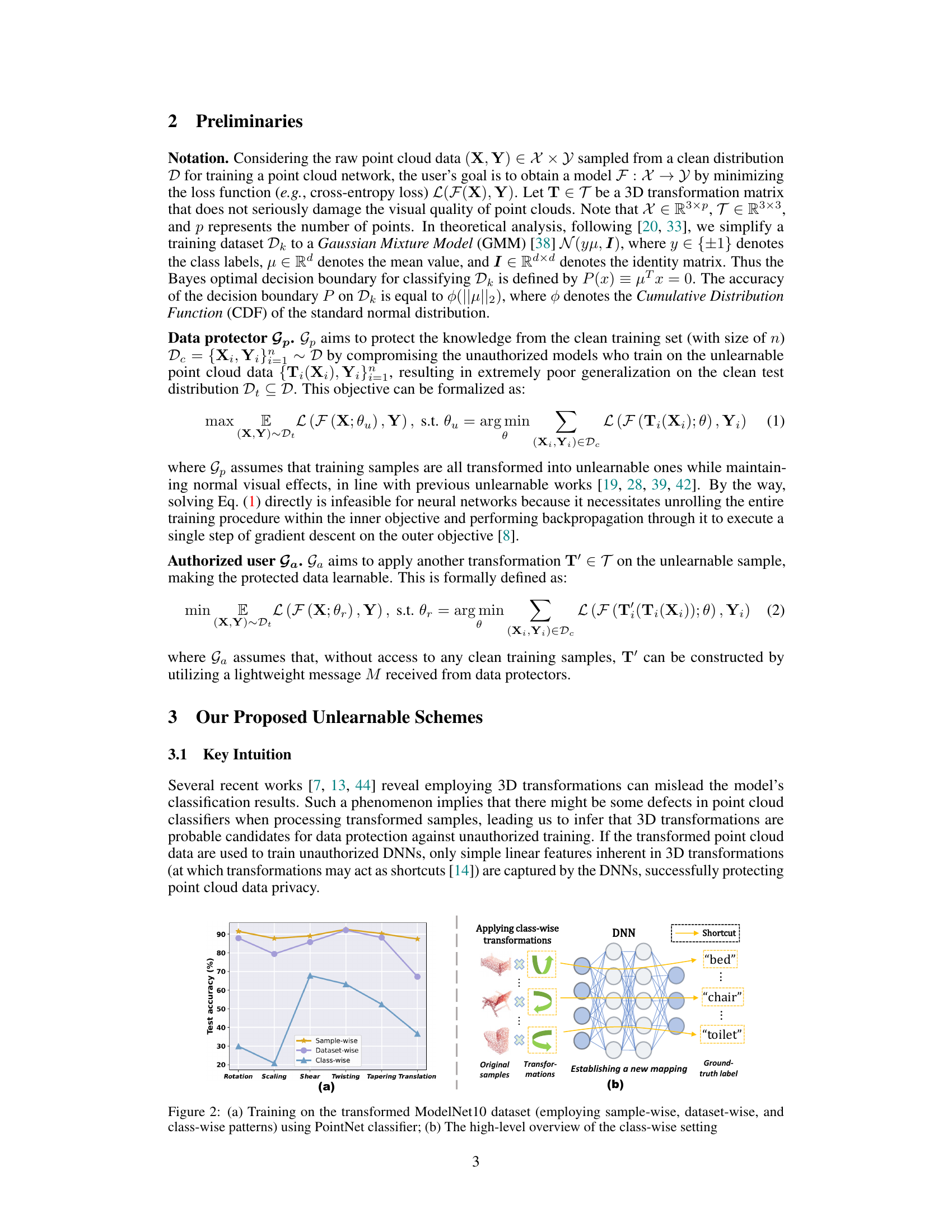
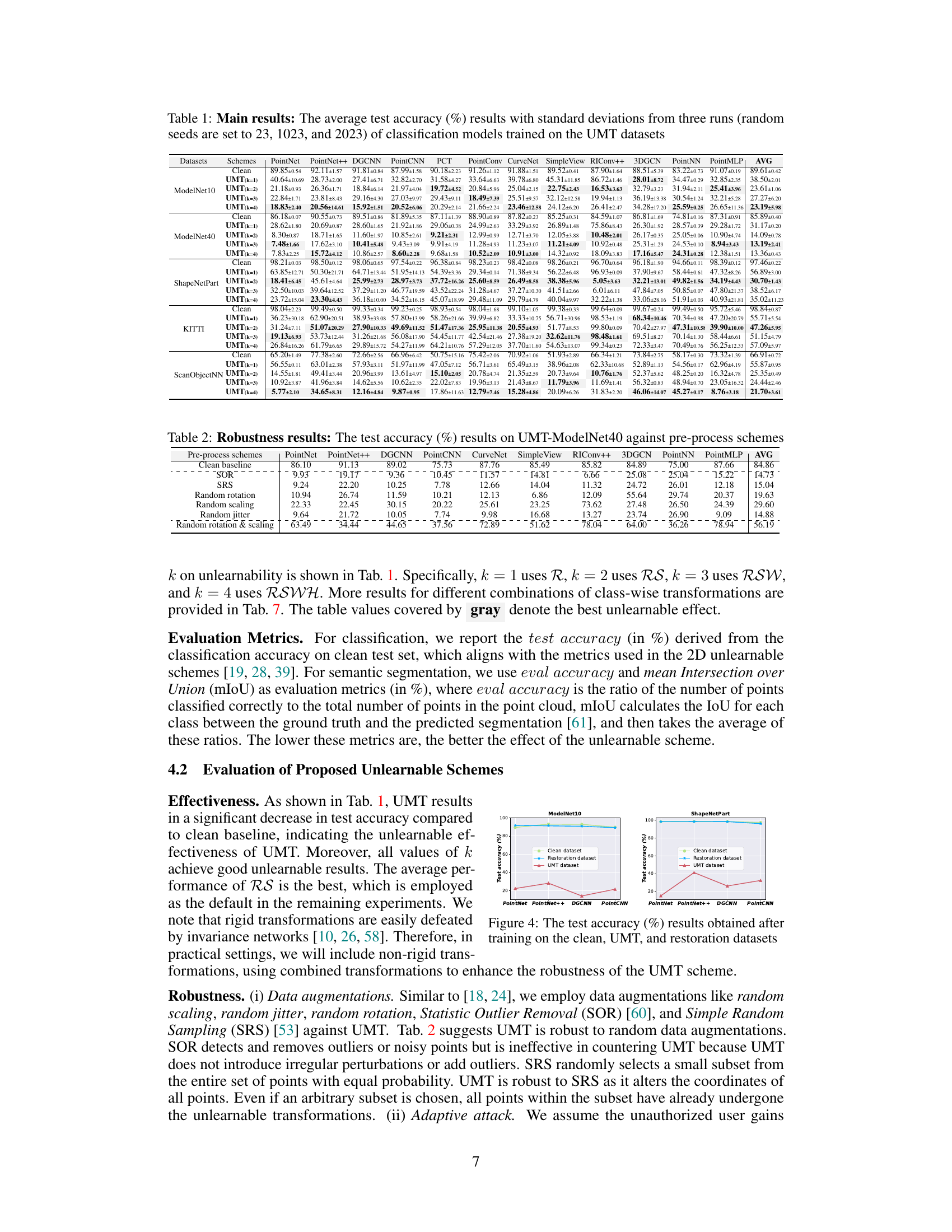
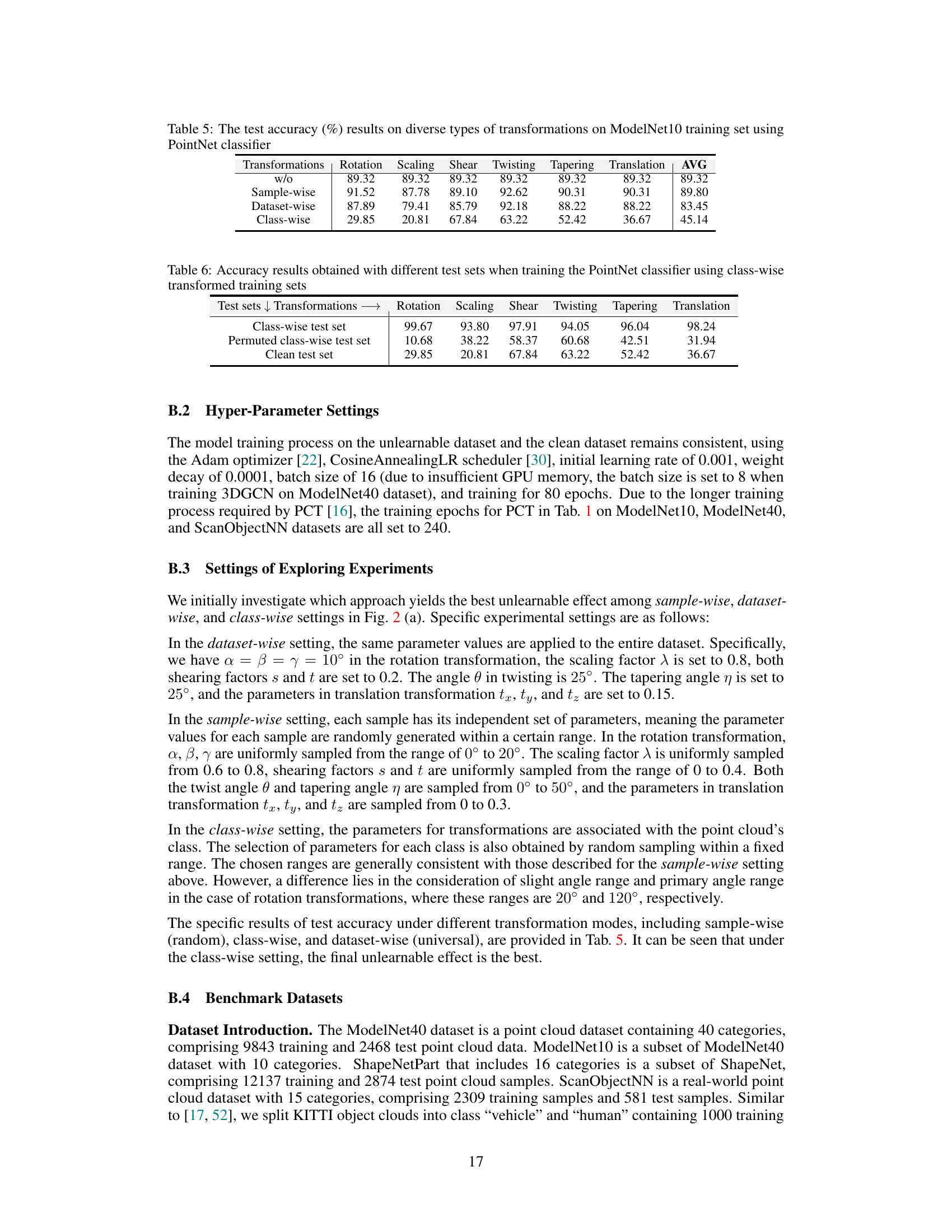
↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Protecting sensitive information in 3D point cloud data is crucial, but existing methods for 2D images are not directly transferable. This paper introduces a new challenge in protecting 3D data because current solutions cause significant visual degradation, making the data unusable. The main issue is that previous unlearnable approaches often prevent both unauthorized and authorized access to the data.
This paper proposes the first comprehensive unlearnable framework for 3D point clouds using class-wise multi-transformations (UMT). This approach applies different transformations to data points depending on their class, making it difficult for unauthorized models to learn effectively. Importantly, a data restoration scheme is also proposed to allow authorized users to access and use the transformed data. The framework is thoroughly evaluated on six datasets and sixteen models, proving effective in protecting data from unauthorized training while retaining the utility for legitimate use.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in data security and privacy, particularly those working with 3D point cloud data. It directly addresses the critical issue of unauthorized training on sensitive 3D data, a problem largely overlooked in existing literature. The proposed framework offers a practical solution with theoretical backing, paving the way for more secure and trustworthy applications of 3D point cloud technology. The work also opens new avenues for research into model-agnostic 3D unlearnable techniques and data restoration methods, pushing the boundaries of data protection in increasingly important domains.
Visual Insights#

Figure 2(a) shows the result of training a PointNet classifier on the ModelNet10 dataset after applying three different transformation patterns: sample-wise, dataset-wise, and class-wise. The class-wise pattern shows significantly lower test accuracy, satisfying the condition for an unlearnable scheme. Figure 2(b) illustrates the high-level concept of the class-wise setting, where a new mapping is established between class-wise transformations and their corresponding ground truth labels. This mapping makes it difficult for unauthorized users to learn the true relationship between the input data and labels.
This table presents the average test accuracy results of 16 different classification models trained on point cloud datasets transformed using the proposed UMT (multi-class-wise transformation) method. It shows the performance comparison between clean datasets and datasets with various levels of transformation (k=1, k=2, k=3, and k=4). The results are presented for four different benchmark datasets (ModelNet40, ModelNet10, ShapeNetPart, and KITTI), highlighting the impact of the UMT method on model accuracy across diverse model architectures and datasets. Standard deviations are included to indicate the reliability of the results.
In-depth insights#
UMT Framework#
The UMT (Multi-class-wise Transformation) framework is a novel approach for protecting 3D point cloud data from unauthorized training. It leverages the inherent properties of various 3D transformations, such as rotation, scaling, and shear, to modify the data in a way that hinders unauthorized model training while preserving usability for authorized users. The framework introduces class-wise adaptive allocation of transformations, ensuring a category-specific approach, and importantly addresses the data restoration challenge, a significant limitation in previous unlearnable methods. The core strength of UMT lies in its theoretical grounding, which provides mathematical justification for its effectiveness, supported by experimental results on various datasets and models. However, limitations include potential vulnerabilities against sufficiently powerful transformation-invariant models, and the practical feasibility of data restoration hinges on robust communication between authorized and unauthorized users.
Class-wise Transforms#
The concept of “Class-wise Transforms” in the context of securing 3D point cloud data introduces a novel approach to data protection. Instead of applying a single transformation across the entire dataset or individual samples, this method tailors transformations to specific classes of objects within the point cloud. This class-specific approach offers several potential advantages. First, it allows for a more nuanced level of protection, adjusting the intensity and type of transformation based on the sensitivity of individual classes. Second, it could potentially improve the resilience against attacks, making it harder for adversaries to deduce the underlying transformations and recover the original data. However, challenges remain. Determining an effective, category-adaptive allocation strategy for assigning transformations is crucial. A poorly chosen strategy could lead to uneven protection, leaving some classes vulnerable. Furthermore, the computational cost of managing and applying class-wise transformations may be significantly higher than simpler, dataset-wide methods. Finally, restoration of the data for authorized users must be carefully considered; an efficient and secure mechanism for reversing the class-specific transforms is essential for practical usability. The effectiveness of class-wise transforms hinges on a thorough understanding of the properties of various transformations and their impact on different classes of 3D point cloud data.
Data Restoration#
The concept of “Data Restoration” in the context of unlearnable 3D point cloud data is crucial for practical applications. The core idea is to allow authorized users to recover the original data after it has been transformed using a class-wise multi-transformation technique for protection. This restoration process addresses a critical gap in existing unlearnable literature, where even authorized parties often struggle to access and use the protected information. The paper introduces a solution employing class-wise inverse matrix transformations, determined by lightweight messages from the data protector. This ensures that only authorized users with the correct decryption keys can restore the data, making the system secure and usable simultaneously. The effectiveness of this restoration method is empirically validated and highlighted as a key contribution of this work, differentiating it from previous studies that only focused on making data unlearnable without considering the practical challenge of data retrieval. The reversible nature of the transformations is vital for this process to be successful, ensuring that the recovered data is identical or extremely close to the original data without significant loss of information or quality. This aspect is essential for practical utility as it avoids data degradation that might impede legitimate usage.
Robustness Analysis#
A robust system should withstand various attacks and unexpected situations. In the context of this research paper, a robustness analysis would thoroughly investigate the system’s resilience. This would involve evaluating the unlearnable framework’s performance under various attacks such as data augmentation techniques, including random scaling, jittering, and rotations, which aim to mimic real-world data variations and adversarial manipulations. The analysis should also assess the impact of pre-processing methods on the effectiveness of the unlearnable approach. Furthermore, an investigation into the impact of different model architectures on the robustness of the framework would provide valuable insights. Crucially, a robustness analysis should encompass the adaptability of the system to unseen attacks, which would test how well the proposed unlearnable framework generalizes to novel attacks and how it handles adaptive attacks that learn from the system’s defenses.
Future Directions#
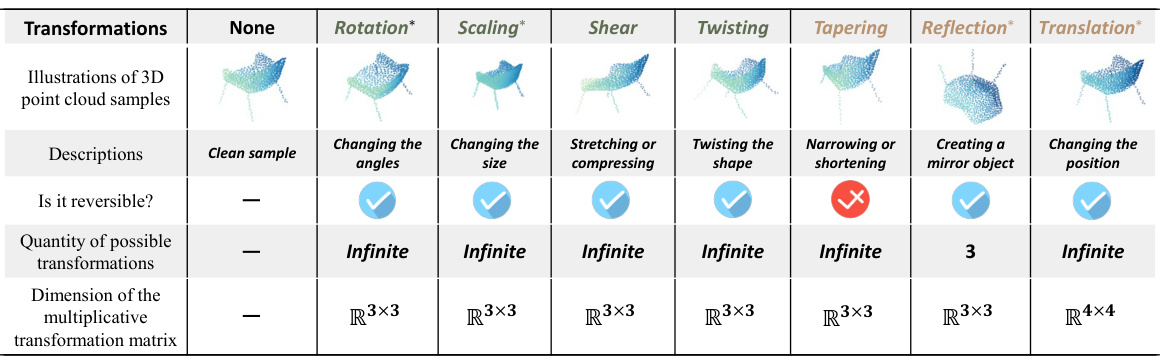
Future research could explore more sophisticated transformation techniques that are more resistant to adversarial attacks. This includes investigating transformations beyond the seven explored, and developing adaptive methods that dynamically adjust transformations based on the model’s behavior. Another crucial area is improving the data restoration scheme. Current methods rely on simple inverse transformations, which may not be fully effective in restoring the data’s original utility. More robust and efficient methods should be developed, potentially involving advanced machine learning techniques or generative models. The theoretical analysis could be extended to encompass a broader range of data distributions and model architectures, moving beyond the Gaussian Mixture Model and providing more robust guarantees. Finally, it would be beneficial to investigate the impact of unlearnable schemes on different downstream tasks beyond classification and segmentation to better understand the limitations and potential applications of this approach in broader scenarios. The practical implications of the balance between preventing unauthorized access and maintaining legitimate data usability also warrant further investigation.
More visual insights#
More on figures
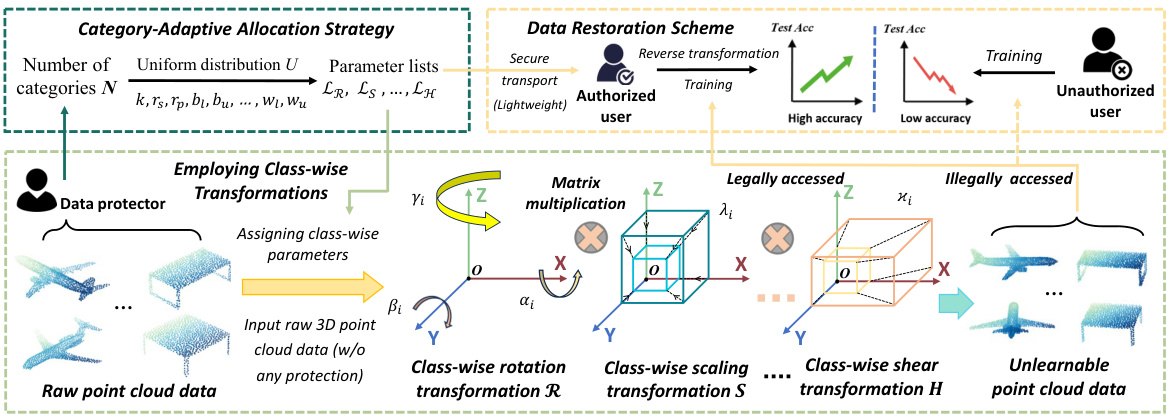
This figure illustrates the complete pipeline of the proposed unlearnable framework. It starts with the raw 3D point cloud data and shows the steps involved in protecting the data from unauthorized use (the unlearnable transformation process) and then restoring the data for authorized training (the data restoration scheme). The figure highlights the use of class-wise transformations, the category-adaptive allocation strategy, matrix multiplication, and inverse transformations. It also shows the roles of the data protector and the authorized user in the process, along with a visual representation of the transformation effect and its impact on the accuracy results for authorized and unauthorized users.

This figure shows the test accuracy results for four different point cloud models (PointNet, PointNet++, DGCNN, and PointCNN) trained on three different datasets: clean dataset, UMT dataset (unlearnable data created by applying class-wise multi-transformations), and restoration dataset (UMT data restored using the proposed data restoration scheme). The results demonstrate that the UMT dataset leads to significantly lower test accuracy compared to the clean dataset, indicating that the proposed unlearnable mechanism is effective. Moreover, the restoration dataset is able to restore the accuracy to a level comparable to that of the clean dataset, confirming the effectiveness of the data restoration scheme.
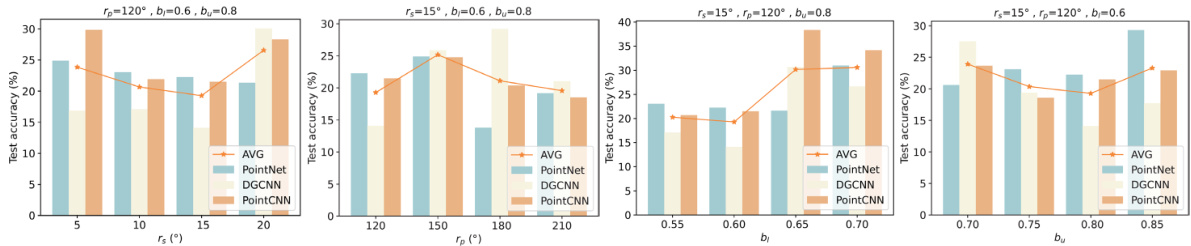
This figure shows the impact of four hyperparameters (rs, rp, b₁, and bᵤ) on the test accuracy of the UMT model using the RS transformation on the ModelNet10 dataset. Each subfigure shows the accuracy for different values of one hyperparameter while keeping the others constant. The results indicate the sensitivity of the UMT model’s performance to these hyperparameters, helping to guide the selection of optimal values for these parameters in the model.

This figure shows the training trajectory of model weights in the weight space when using clean data and UMT data. The blue arrows represent the trajectory with clean data, showing a smooth path to low loss on the clean test set (Figure 6a). The red arrows represent the trajectory with UMT data, showing a different path that leads to low training loss but high loss on the clean test set (Figure 6a). When testing on the UMT test set (Figure 6b), both trajectories converge to low loss, which is expected given the consistent application of UMT to both training and test data.

This figure illustrates the complete process of the proposed unlearnable framework for 3D point clouds. It starts with raw 3D point cloud data without any protection, and then applies a category-adaptive allocation strategy to assign class-wise transformation parameters for different categories of data. The data protector then performs class-wise multi-transformations to the data, creating unlearnable transformed point cloud data. The authorized user receives a lightweight message containing class-wise parameters from the data protector, uses these parameters to construct the inverse transformation matrix, and applies it to the unlearnable data for restoration. This process ensures only authorized users can access and use the data for training.

This figure illustrates the proposed integral unlearnable framework for 3D point clouds. It shows two main processes: (1) unlearnable data protection and (2) authorized data restoration. The unlearnable data protection involves a class-wise setting using category-adaptive allocation strategy. The data is transformed using class-wise multi-transformations, which makes it difficult for unauthorized users to train a model effectively. The authorized data restoration uses a lightweight message from the data protector to perform a class-wise inverse transformation, making the data learnable again for authorized users. The figure highlights the key components involved in each process, illustrating the flow of data from clean data to unlearnable data and then back to learnable data for authorized training.
More on tables
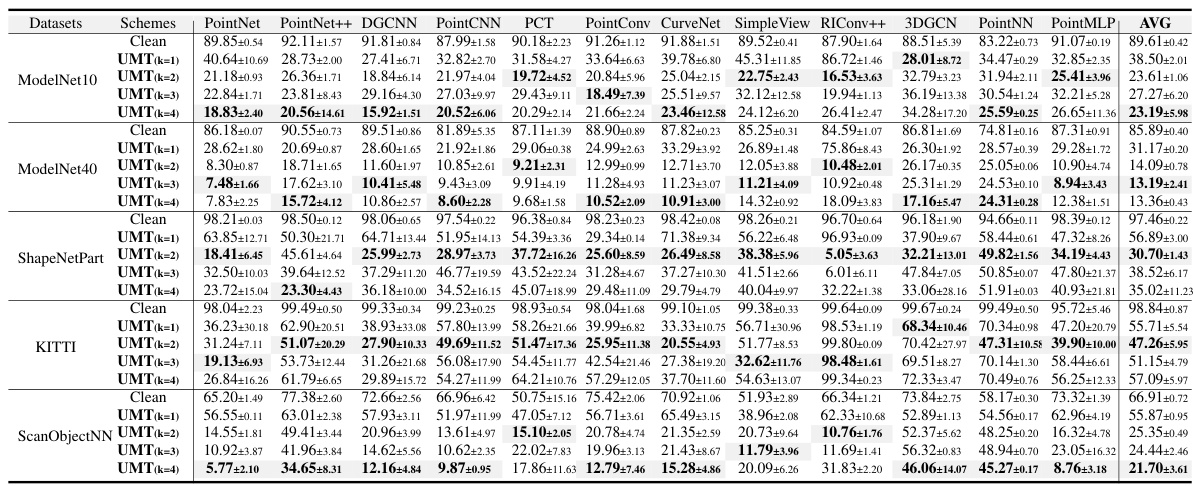
This table presents the average test accuracy and standard deviation for 16 different 3D point cloud classification models trained on datasets protected by the proposed UMT (Unlearnable Multi-Transformation) framework. The table compares the performance of these models on four different datasets (ModelNet40, ModelNet10, ShapeNetPart, and KITTI), with results broken down by the number of transformations used (k=1, k=2, k=3, k=4). The results showcase the impact of the UMT framework on model performance, demonstrating the effectiveness of the proposed method in hindering unauthorized training.

This table presents the robustness of the proposed UMT (Unlearnable Multi-Transformation) framework against various pre-processing techniques. It shows the test accuracy of the PointNet, PointNet++, DGCNN, PointCNN, CurveNet, SimpleView, RIConv++, 3DGCN, PointNN, and PointMLP models trained on the UMT-ModelNet40 dataset when different data augmentation or pre-processing methods (SOR, SRS, random rotation, random scaling, random jitter, and random rotation & scaling) are applied. The results demonstrate the effectiveness of the UMT framework in maintaining its unlearnable properties even after pre-processing.

This table presents the results of applying the proposed Unlearnable Multi-Transformation (UMT) framework to the semantic segmentation task using the Stanford 3D Indoor Spaces dataset (S3DIS). It compares the performance of different segmentation models (PointNet++, Point Transformer v3, and SegNN) on clean data versus data transformed using the UMT method. The evaluation metrics used are evaluation accuracy and mean Intersection over Union (mIoU), which measure the correctness and completeness of the segmentation results. The table aims to show the effectiveness of UMT in protecting point cloud data by significantly reducing the performance of trained models on the transformed data.

This table presents the average test accuracy results achieved by various classification models trained on the UMT (Unlearnable Multi-Transformation) datasets. The results are categorized by dataset (ModelNet40 and ModelNet10), transformation level (k=1, k=2, k=3, k=4), and model. Standard deviations are included to reflect the variability in the results across three independent runs. The table shows the performance drop when using UMT-processed data compared to clean data, demonstrating the effectiveness of the UMT approach.

This table presents the test accuracy achieved using a PointNet classifier trained on ModelNet10 datasets with different transformation methods. It compares the performance of three transformation patterns: sample-wise, dataset-wise, and class-wise, along with a baseline without any transformations. The results show that the class-wise transformation significantly reduces the test accuracy, indicating that it makes the data unlearnable.

This table shows the test accuracy results obtained from training a PointNet classifier using class-wise transformed training data and testing on three different test sets: a class-wise test set (using consistent transformation parameters with the training set), a permuted class-wise test set (transformation parameters permuted), and a clean test set (no transformations). It demonstrates that the model learns the mapping between transformations and labels resulting in high accuracy on the consistent test set. However, accuracy drops significantly when the test set’s transformations are permuted or when testing on a clean test set.
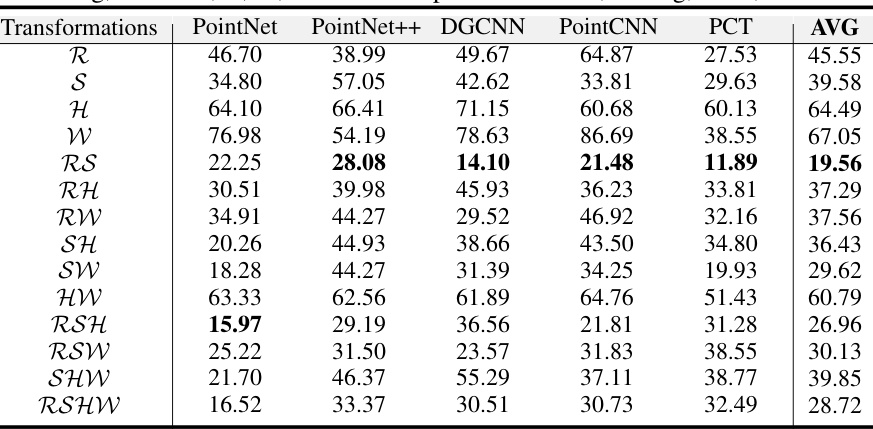
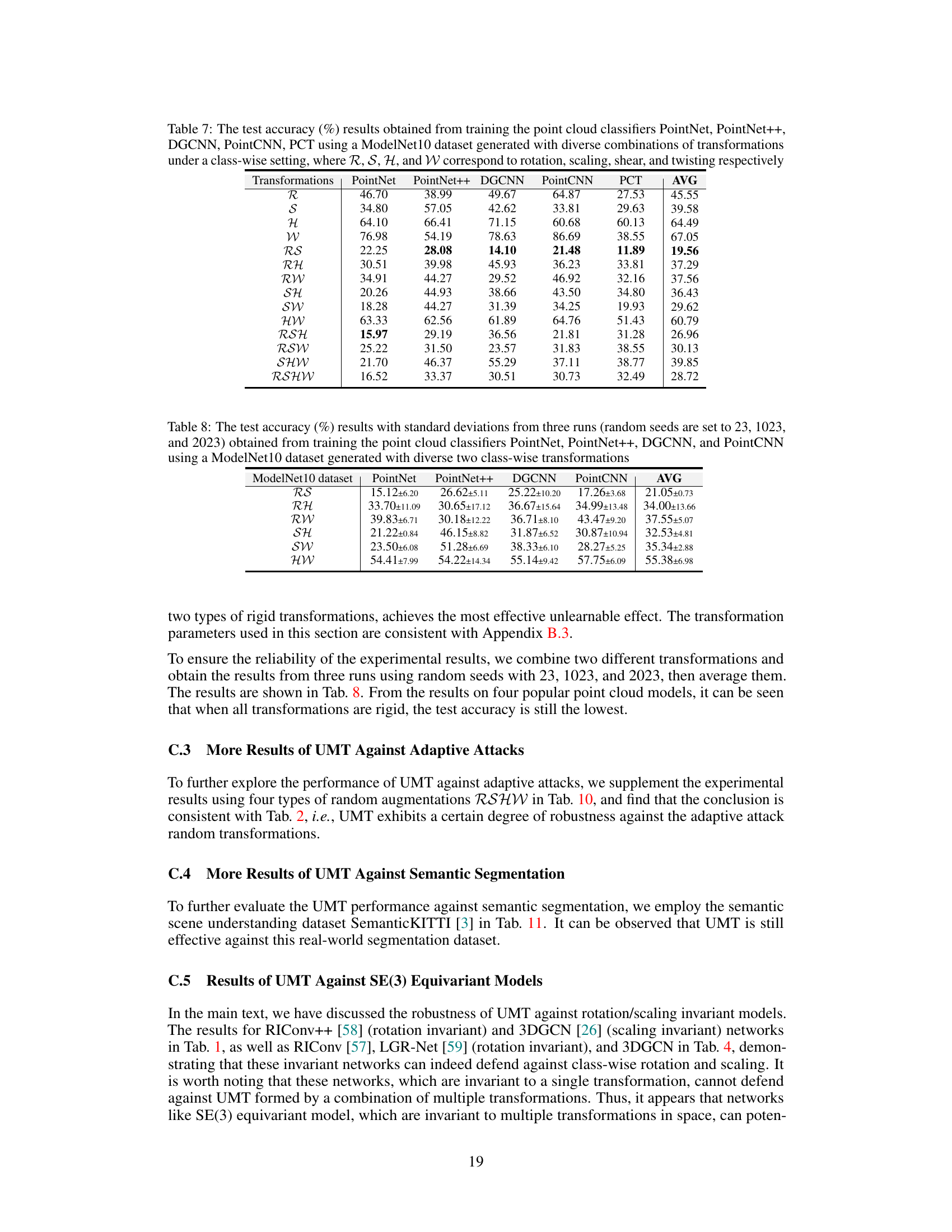
This table presents the test accuracy results achieved using five different point cloud classifiers (PointNet, PointNet++, DGCNN, PointCNN, PCT) trained on a ModelNet10 dataset. The dataset was generated using various combinations of class-wise transformations (rotation, scaling, shear, and twisting). Each row represents a unique combination of transformations, showing the average accuracy across the five classifiers for that specific combination. This illustrates the impact of different class-wise transformation combinations on model performance.

This table presents the test accuracy results obtained from training four different point cloud classifiers (PointNet, PointNet++, DGCNN, and PointCNN) on a ModelNet10 dataset. The dataset was generated using diverse combinations of two class-wise transformations. The results are averages from three runs with different random seeds (23, 1023, and 2023), and standard deviations are also reported.

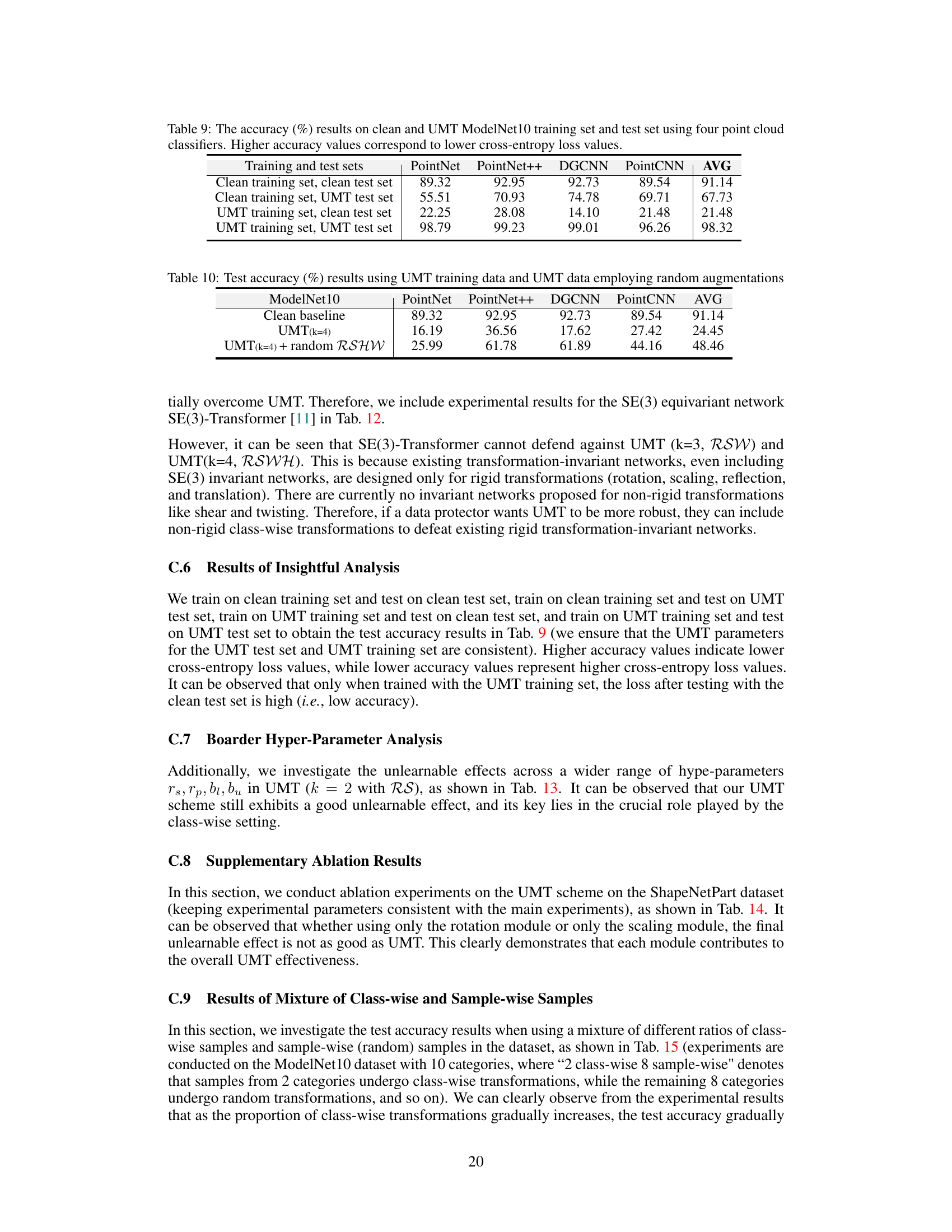
This table presents the test accuracy results obtained using four different point cloud classifiers (PointNet, PointNet++, DGCNN, PointCNN). The accuracy is measured under four different scenarios: (1) training and testing on clean data, (2) training on clean data and testing on UMT (unlearnable) data, (3) training on UMT data and testing on clean data, and (4) training and testing on UMT data. Higher accuracy indicates a lower cross-entropy loss, suggesting better model performance. The results highlight the effectiveness of the UMT method in making the data unlearnable for unauthorized users.

This table presents the test accuracy results obtained using UMT training data and UMT data with random augmentations. It shows the effectiveness of UMT against adaptive attacks by comparing the accuracy of different models (PointNet, PointNet++, DGCNN, PointCNN) on clean baseline data, UMT data (k=4), and UMT data (k=4) with random RSHW augmentations. The results indicate that the UMT scheme is robust against adaptive attacks.

This table presents the results of the proposed Unlearnable Multi-Transformation (UMT) method on a semantic segmentation task using the S3DIS dataset. It compares the performance of different segmentation models (PointNet++, Point Transformer V2, and SegNN) on both a clean baseline and data processed by the UMT method (k=2, RS). The evaluation metrics used are Eval Accuracy and mIoU, which are common metrics used in evaluating semantic segmentation performance. The data shows the significant reduction in segmentation accuracy after applying the UMT data protection scheme.

This table presents the test accuracy results obtained when using data protected by the UMT scheme to train the SE(3)-Transformer model. It compares the performance of the model trained on clean data against the performance achieved when training on data that has undergone various UMT transformations (using different combinations of transformations). The results highlight the effectiveness of the UMT framework in reducing the accuracy of unauthorized models.

This table presents the test accuracy results obtained from experiments on the ModelNet10 dataset using PointNet, DGCNN, and PointCNN classifiers. The experiments were conducted with a broader range of hyperparameters (rs, rp, b₁, bu) than those used in the main experiments, to analyze the sensitivity of the unlearnable scheme to these hyperparameters. Each row represents a different combination of these parameters. The table aims to demonstrate the robustness of the unlearnable method across a range of parameter settings.

This table presents the test accuracy results obtained from training on mixture data that combines class-wise UMT samples and sample-wise UMT samples. The varying proportions of class-wise to sample-wise data (from 20% to 100%) are tested, and the accuracy results across four point cloud models (PointNet, PointNet++, DGCNN, PointCNN) are shown. The results demonstrate how the proportion of class-wise samples affects the test accuracy.

This table shows the results of evaluating the function g(t) with different values of β₁ and t (0.3 and 0.4). The function g(t) is part of the proof for Lemma 5, which bounds the accuracy of the unlearnable decision boundary. The bold values highlight cases where the inequality p₁ < ½ holds true, a crucial element in establishing the unlearnable nature of the proposed method.

This table presents the results of calculating the function h(t) with different values of β2 and t (0.3 and 0.4). The function h(t) is used in the proof of Lemma 5, which provides an upper bound on the accuracy of the unlearnable decision boundary. The bold values highlight cases where the condition p2 < 1/2, a crucial component of Theorem 6 is met, indicating the unlearnable effect.
Full paper#