↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Vision-Language Models (LVLMs) are powerful but prone to “hallucinations,” generating text inconsistent with the input image. Existing methods using visual uncertainty to mitigate this issue often struggle due to the global nature of uncertainty, potentially leading to new hallucinations. These methods primarily focus on widening the contrast logits gap between correct and hallucinatory tokens during decoding, but their effectiveness is limited by their inability to precisely control the induced hallucinations.
This paper introduces Hallucination-Induced Optimization (HIO), a novel method to address this. HIO uses a refined theoretical preference model to effectively amplify the contrast between correct and hallucinatory tokens, resulting in more accurate and reliable LVLMs. The method outperforms existing visual contrastive decoding approaches on various benchmarks, demonstrating its efficacy in reducing hallucinations and improving the overall performance of LVLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on Large Vision-Language Models (LVLMs) because it directly addresses the persistent problem of hallucinations. By introducing a novel optimization strategy, Hallucination-Induced Optimization (HIO), the research offers a practical solution to improve the accuracy and reliability of LVLMs. This is highly relevant to current research trends focused on improving the factual consistency and reducing biases in LLMs and LVLMs. Furthermore, HIO opens new avenues for exploring more effective contrast decoding strategies and refining theoretical models for preference optimization in multimodal AI.
Visual Insights#

This figure presents a comparison of different decoding strategies for large vision-language models (LVLMs). The left panel illustrates the challenges of existing contrast decoding methods, which struggle to effectively widen the logits gap between hallucinated and correct tokens, leading to inaccurate outputs. In contrast, the proposed Hallucination-Induced Optimization (HIO) method significantly amplifies this gap, resulting in improved accuracy. The right panel shows a bar chart comparing the performance of various methods, including HIO, on the CHAIR metric, a benchmark for evaluating hallucinations in image captioning. HIO demonstrates superior performance by generating descriptions with fewer hallucination tokens.
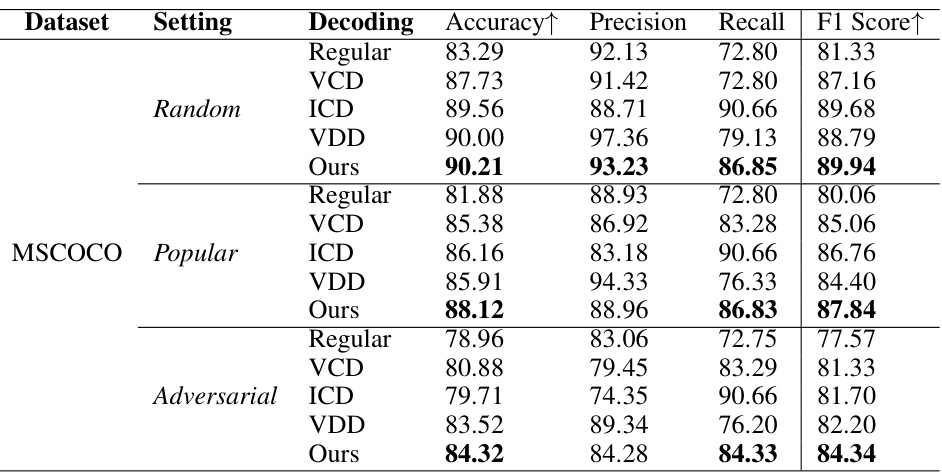
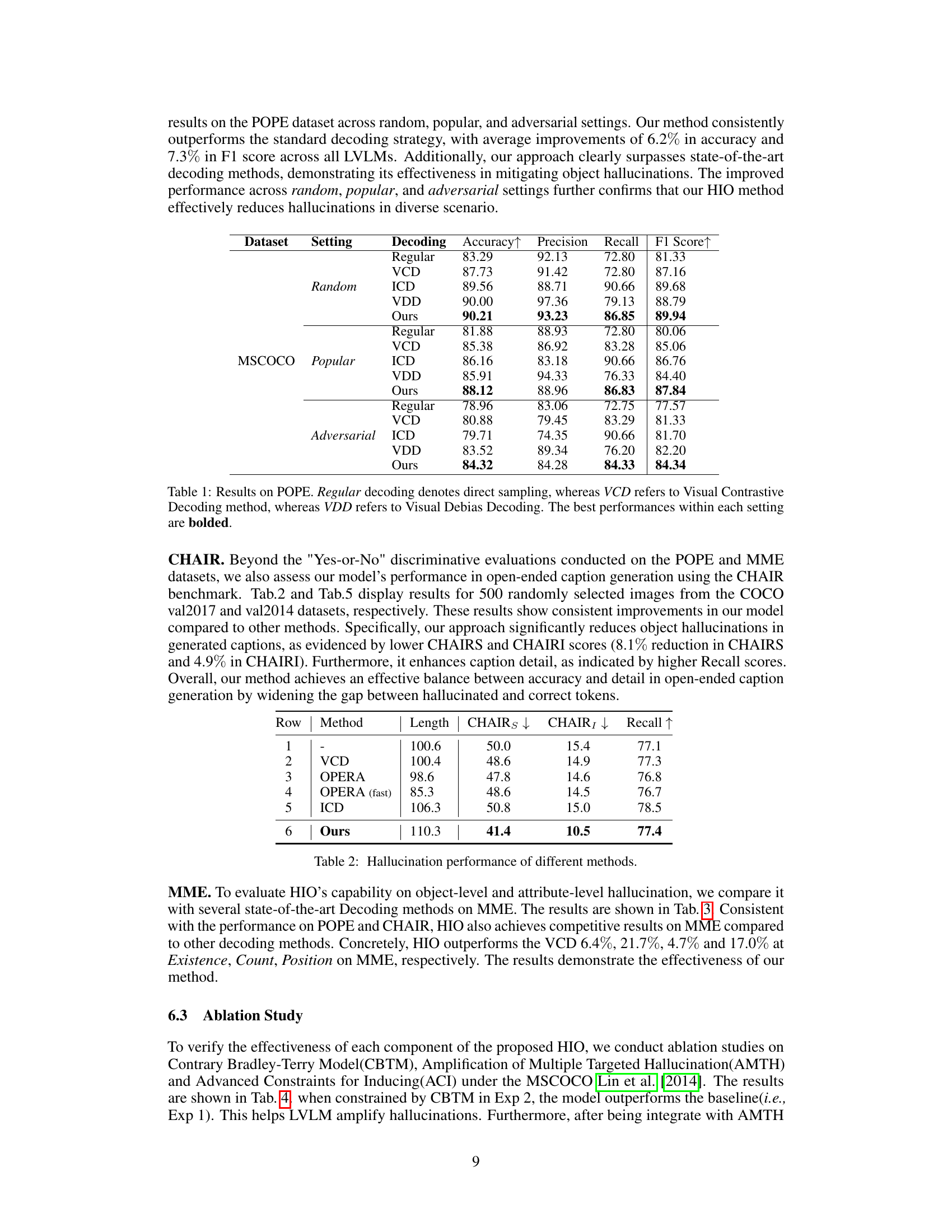
This table presents the performance of different decoding methods (Regular, VCD, ICD, VDD, and Ours) on the POPE dataset for object hallucination. The results are broken down by three different settings: random, popular, and adversarial. For each setting and decoding method, the accuracy, precision, recall, and F1 score are reported. The best performing method for each metric in each setting is shown in bold. The table helps to demonstrate the effectiveness of the proposed HIO method in reducing hallucinations compared to existing state-of-the-art techniques.
In-depth insights#
HIO: Core Method#
A hypothetical ‘HIO: Core Method’ section would delve into the technical specifics of the Hallucination-Induced Optimization strategy. It would likely detail the Contrary Bradley-Terry Model (CBTM), explaining how this fine-tuned preference model amplifies the contrast between hallucinatory and targeted tokens. The method’s reliance on amplifying multiple targeted hallucinations (AMTH) to enhance contrast would be explained, likely involving a multi-pair Bradley-Terry model application. Furthermore, the section should elaborate on the advanced constraints for inducing hallucinations (ACI), addressing the limitations of standard classification loss in achieving sufficient contrast and specifying the mathematical formulations used to enforce this amplified contrast. Crucially, the section would justify the approach’s effectiveness through a rigorous theoretical foundation, possibly demonstrating the necessity of specific conditions for successful contrast decoding.
Hallucination Theory#
A comprehensive ‘Hallucination Theory’ in the context of Large Visual Language Models (LVLMs) would delve into the root causes of these inaccuracies. It would explore the interaction between visual and linguistic modalities, examining how misalignments in feature extraction, representation, and fusion can lead to hallucinations. The theory should also consider the influence of model architecture and training data, specifically how biases or limitations in the training set might manifest as fabricated details or misinterpretations. Different types of hallucinations (factual, spatial, object) need to be distinguished and potentially modeled separately, leading to a more nuanced understanding of the phenomenon. The impact of decoding strategies on the likelihood of hallucinations is another critical component, highlighting the need for improved methods that accurately prioritize correct interpretations over spurious ones. Finally, a robust theory should propose mechanisms for detecting and mitigating hallucinations, moving beyond merely identifying them to actively preventing or correcting them during the generation process.
Benchmark Results#
The benchmark results section of a research paper is crucial for evaluating the effectiveness of a proposed method. A strong presentation will include a clear description of the chosen benchmarks, highlighting their relevance to the problem. Multiple metrics should be reported to provide a comprehensive assessment, going beyond simple accuracy. Statistical significance should be rigorously established, using appropriate tests and error bars to ensure the reported improvements are not due to chance. The results should be compared against relevant baselines, including both traditional and state-of-the-art methods. Detailed tables and figures should clearly present the findings, facilitating easy interpretation. Finally, a discussion should contextualize the results, discussing any limitations and potential reasons for discrepancies, paving the way for future research directions.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a complex system by removing or deactivating them one at a time. In the context of a research paper focusing on mitigating hallucinations in Large Vision-Language Models (LVLMs), an ablation study would be crucial for understanding the relative importance of different modules or techniques. For example, if the paper proposes a novel method combining a fine-tuned theoretical preference model, multiple targeted hallucination amplification, and advanced constraints for inducing contrast, an ablation study would isolate each component. By comparing the performance of the full model against versions lacking each component, the researchers can determine which parts are essential for achieving the desired outcome (hallucination reduction). This provides quantitative evidence supporting the claims made and aids in identifying any redundant or counterproductive elements. The results should explicitly show the impact of each component on relevant metrics, helping to pinpoint the most effective aspects of the proposed methodology and offering valuable insights for future improvements and related research.
Future Work#
Future research could explore refining the theoretical framework of hallucination mitigation in Large Vision-Language Models (LVLMs) by investigating the precise interplay between visual uncertainty and hallucination generation. Improving the efficiency of contrast decoding is crucial, potentially through exploring alternative optimization strategies beyond Hallucination-Induced Optimization (HIO). Additionally, researching training-free methods to induce hallucinations could significantly reduce computational costs and improve efficiency. The study’s limitations, such as the specific models and datasets used, suggest the need for broader experimentation across diverse LVLMs and benchmark datasets to validate the generalizability of HIO. Finally, future work should concentrate on addressing the ethical considerations surrounding hallucination in LVLMs, such as the potential for misuse and the need for robust safeguards.
More visual insights#
More on figures
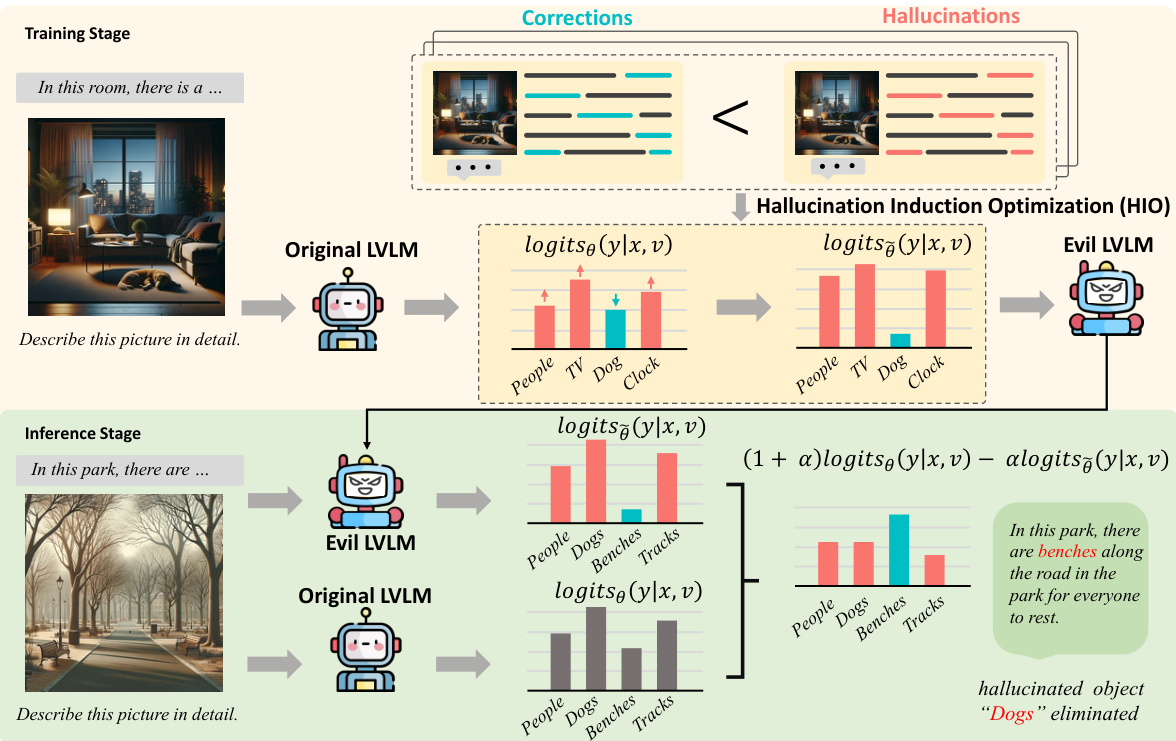
This figure illustrates the two-stage process of the proposed Hallucination-Induced Optimization (HIO) method. In the training stage, an original LVLM generates outputs with hallucinations, which are then used to train an ‘Evil’ LVLM that amplifies these hallucinations. During inference, logits from both the original and ‘Evil’ LVLMs are combined to reduce hallucinations in the final output.

The figure’s left panel illustrates the challenges of existing contrast decoding strategies, comparing greedy decoding, visual contrastive decoding, and the proposed Hallucination-Induced Optimization (HIO). It highlights how HIO effectively widens the logit gap between hallucinated and correct tokens, leading to improved accuracy. The right panel presents a bar chart comparing the performance of various methods, including the proposed HIO, on CHAIR metrics. HIO achieves the lowest scores, showing its superior performance in reducing hallucinations.
More on tables

This table presents a comparison of hallucination performance between different methods on the CHAIR benchmark. It shows the length of generated captions, the CHAIRS and CHAIRI scores (lower is better, indicating fewer hallucinations), and the Recall score (higher is better, indicating more details in captions). The results demonstrate the effectiveness of the proposed HIO method in reducing hallucinations while maintaining a good level of detail in generated captions.
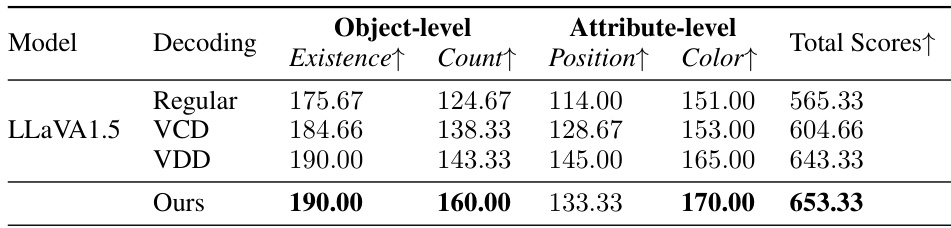
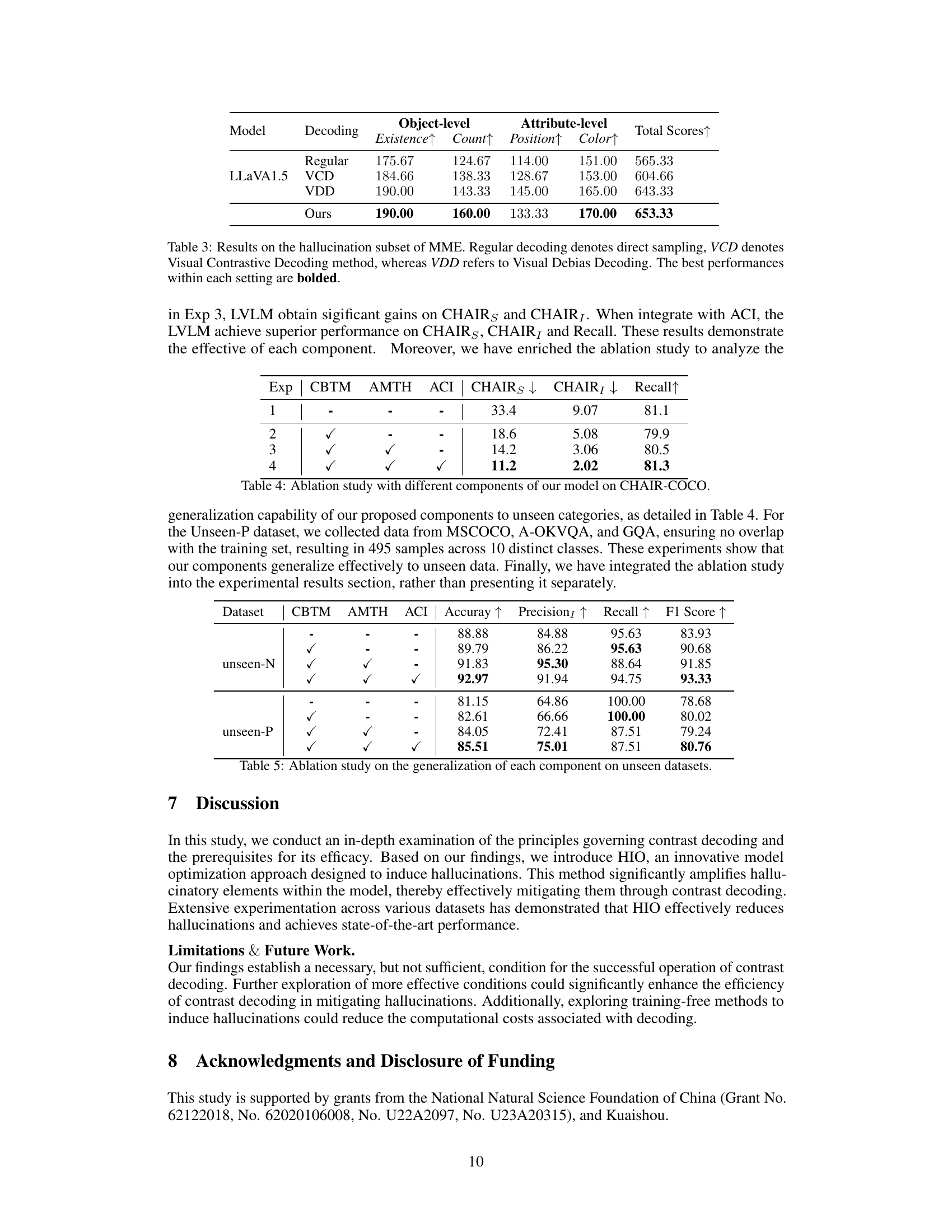
This table presents the results of the Hallucination-Induced Optimization (HIO) method compared to other state-of-the-art methods on the Multimodal Large Language Model Evaluation (MME) benchmark’s hallucination subset. It evaluates the performance of different decoding strategies (Regular, Visual Contrastive Decoding - VCD, Visual Debias Decoding - VDD, and HIO) across various metrics: Existence, Count, Position, and Color at object-level and attribute-level. The best performance for each setting is highlighted in bold, showcasing the effectiveness of HIO in reducing hallucinations.

This table presents the ablation study results evaluating the impact of individual components of the proposed Hallucination-Induced Optimization (HIO) method on the CHAIR-COCO benchmark. The rows represent different experimental configurations, showing which components (CBTM, AMTH, ACI) were included. The columns show the resulting CHAIRS, CHAIR1 scores (lower is better), and Recall scores (higher is better). This demonstrates the individual and combined contributions of each component to the overall performance.

This table presents the results of an ablation study conducted to evaluate the generalization capability of the proposed HIO method’s components (CBTM, AMTH, and ACI) on unseen datasets. It shows the performance (Accuracy, Precision, Recall, F1 Score) of the model with different combinations of these components on two unseen datasets: unseen-N and unseen-P. The results demonstrate how each component contributes to the overall performance and their effectiveness in generalizing to unseen data.

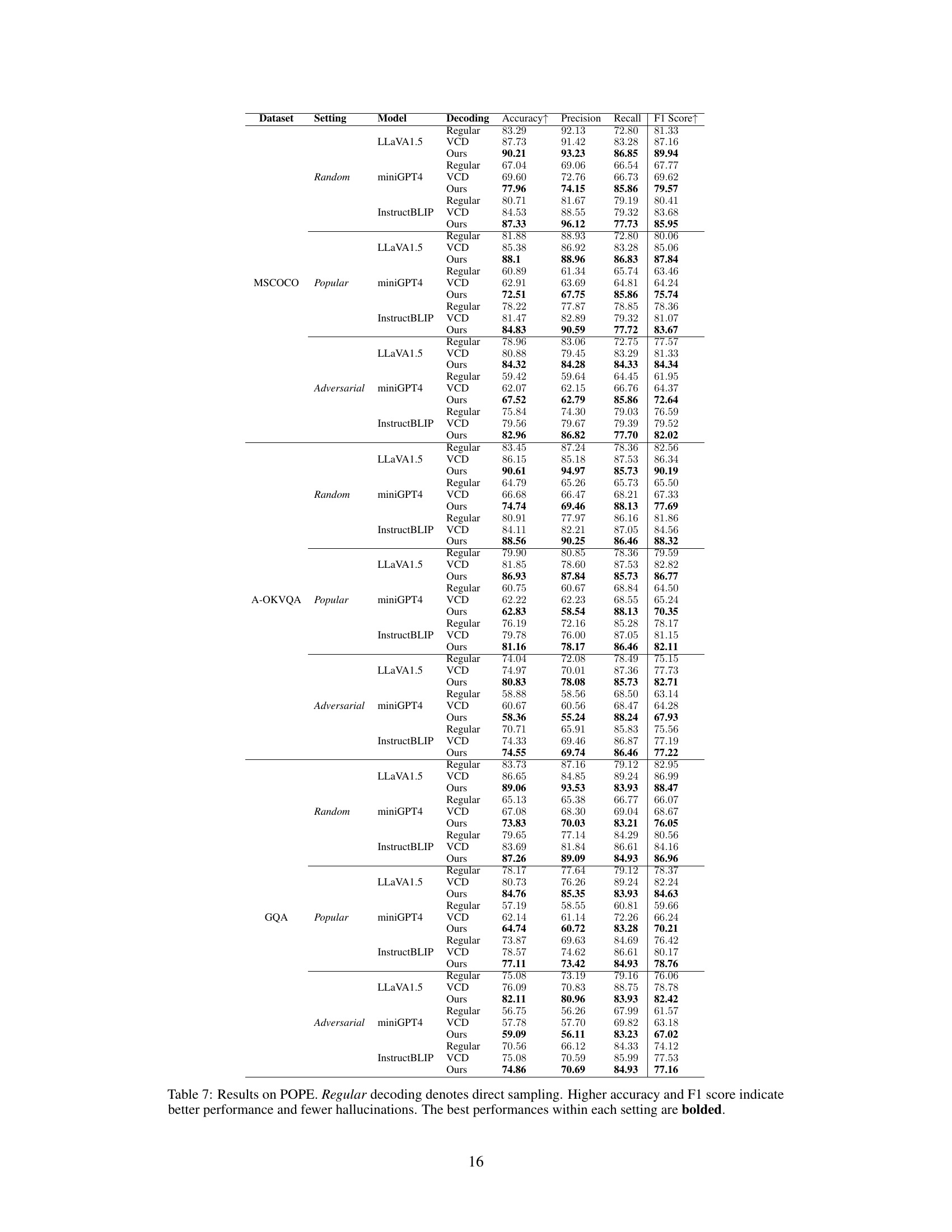
This table presents the results of the hallucination subset of the MME (Multimodal Large Language Model Evaluation) benchmark. It compares three different decoding methods: Regular (direct sampling), Visual Contrastive Decoding (VCD), and Visual Debias Decoding (VDD). The table shows the performance of each method across various attributes, including Existence, Count, Position, Color, and Total Scores. The best performance for each metric is highlighted in bold.

This table presents the quantitative results of the proposed Hallucination-Induced Optimization (HIO) method and compares it against several state-of-the-art decoding methods on the POPE benchmark. The POPE benchmark evaluates the ability of Large Vision-Language Models (LVLMs) to avoid hallucinating objects when answering questions about images. The table shows the accuracy, precision, recall, and F1-score for each method across different settings (random, popular, and adversarial). The bolded values indicate the best-performing method for each metric and setting, demonstrating HIO’s superior performance in reducing hallucinations.
Full paper#