↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision-language models (VLMs) are increasingly used in various applications but suffer from a critical issue: memorization of training data. This memorization can severely limit a model’s ability to generalize to unseen data, impacting its real-world applicability. Existing memorization detection methods are inadequate for complex VLMs due to their multi-modal nature and rich training data. This lack of effective measurement tools makes it difficult for researchers to assess and mitigate the risks associated with deploying such models.
This paper introduces a new technique called “déjà vu memorization” to accurately measure memorization in VLMs by examining whether a model retains detailed information about training images beyond what can be inferred from simple correlations. The researchers demonstrate this technique’s effectiveness on various VLMs and datasets, showcasing that memorization is prevalent even at large scales. They also propose mitigation strategies like text randomization, showing its effectiveness in reducing memorization while preserving performance. This work significantly contributes to developing safer and more reliable VLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical issue of memorization in large vision-language models (VLMs), a problem that hinders generalization and raises concerns about the reliability of these models. By introducing a novel method for measuring memorization and proposing mitigation techniques, it provides valuable insights for researchers working on VLM development and deployment. This work directly contributes to the ongoing efforts in building more robust and trustworthy AI systems.
Visual Insights#

This figure shows an example of déjà vu memorization using a CLIP model. Two models were trained; one with the target image and one without. Given a target image and caption, both models were used to retrieve relevant images from a public dataset. The model trained with the target image showed significantly better recall of objects from the target image compared to the model not trained with the target image. This demonstrates that the model remembers specific details from the training images beyond what can be inferred from the caption alone.

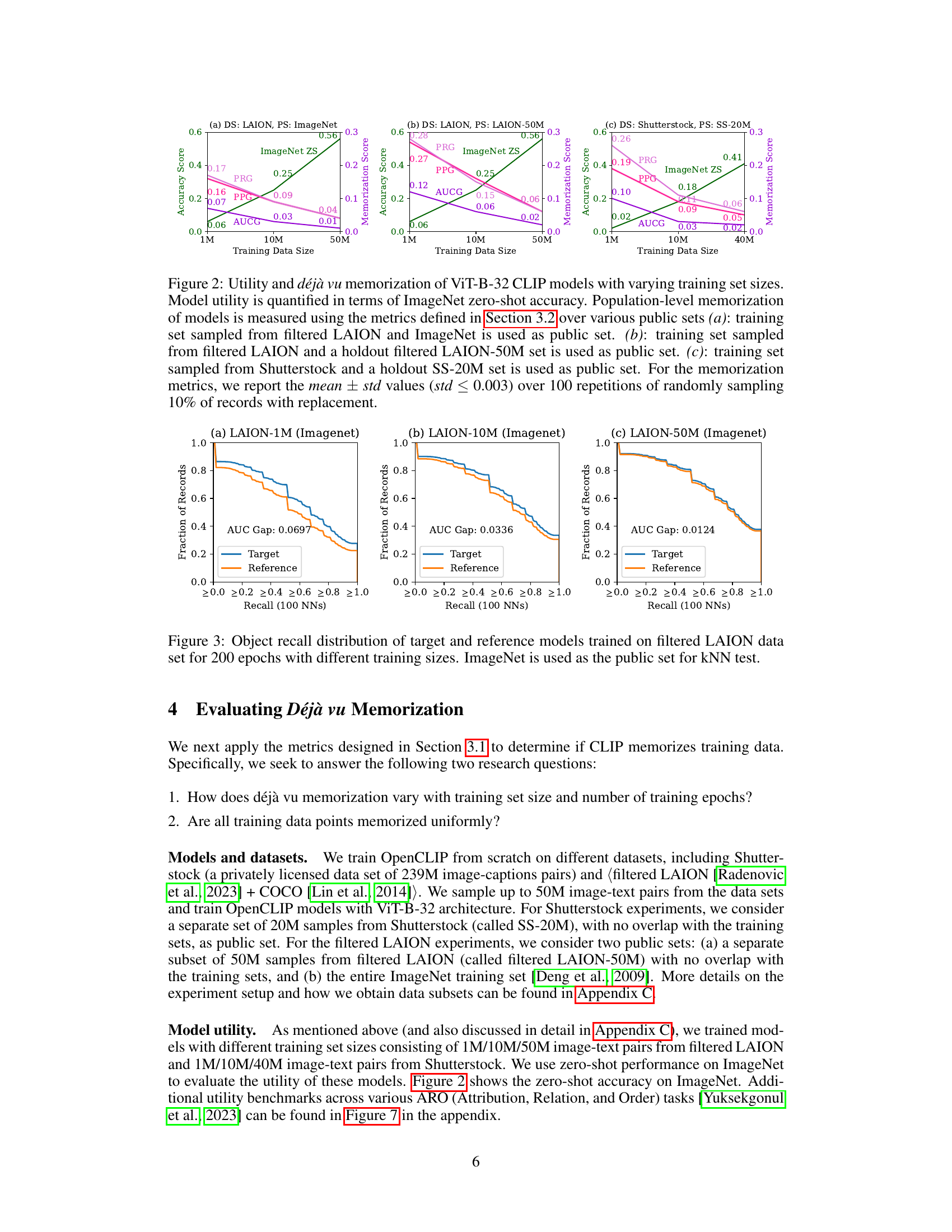
This figure shows the relationship between the size of the training dataset used for training ViT-B-32 CLIP models and both their utility (measured by ImageNet zero-shot accuracy) and the degree of memorization. Three different scenarios are presented, each using a different combination of training and testing datasets. The memorization is evaluated using population-level metrics (PPG, PRG, AUCG), showing the mean and standard deviation of these metrics over 100 random samplings of the training data.
In-depth insights#
VLM Memorization#
The concept of “VLM Memorization” explores how Vision-Language Models (VLMs) retain information from their training data. This goes beyond simply learning correlations; it investigates whether VLMs memorize specific details about individual training images and captions. Measuring memorization is challenging because it needs to distinguish between actual memorization and the model learning valid correlations. The paper proposes a novel method, “déjà vu memorization,” to quantify this by comparing a model’s ability to retrieve images based on captions with and without the target image-caption pair in its training data. Results show significant memorization even in large models, highlighting the importance of understanding and mitigating this phenomenon. The research also explores techniques to reduce memorization, such as text randomization, while preserving model performance. The study provides crucial insights into the nature of VLMs, revealing potential vulnerabilities and suggesting strategies for improving their robustness and generalization capabilities.
VL-Déjà-Vu Metric#
The proposed VL-Déjà-Vu metric offers a novel approach to quantifying memorization in vision-language models (VLMs). It cleverly addresses the challenge of disentangling true memorization from spurious correlations by comparing a target VLM’s retrieval performance on a held-out dataset against a reference VLM not trained on the same data. The key insight is that a memorized image-text pair will exhibit significantly higher similarity in retrieved images compared to chance, based on detailed object-level matching. This methodology moves beyond simple correlation measures, providing a more nuanced assessment of memorization. Furthermore, the metric’s evaluation at both sample and population levels offers granular insights into the extent and distribution of memorization within the model. By using precision, recall and F-score metrics, VL-Déjà-Vu offers a quantifiable assessment of memorization’s impact. This rigorous approach makes it more effective than previous methods, paving the way for more accurate evaluations of memorization in increasingly large and complex VLMs.
Mitigation Methods#
The section on “Mitigation Methods” would critically examine strategies to reduce memorization in vision-language models (VLMs). It would likely investigate techniques like early stopping, adjusting the temperature parameter in the contrastive loss function, employing weight decay regularization, and implementing text masking or data augmentation. The analysis would go beyond simply listing these methods; it would delve into the effectiveness of each approach, quantifying the trade-off between reduced memorization and any impact on the VLM’s downstream task performance. Quantitative results showing improvements in memorization metrics (precision, recall, F1-score) alongside any decrease in model utility would be crucial. Furthermore, a discussion comparing the relative efficacy of different techniques and exploring potential combinations for optimal results would provide valuable insights. The section would also acknowledge any computational limitations that may have constrained the exploration of additional mitigation methods. Finally, any limitations of the proposed mitigation techniques themselves would be discussed, perhaps including considerations regarding the specific types of data or model architectures where they are most effective.
Memorization Risks#
Memorization in large language models (LLMs) presents a significant risk, impacting model generalization and potentially revealing sensitive training data. Overfitting to the training set allows the model to reproduce specific examples instead of learning generalizable patterns. This memorization risk is particularly concerning for vision-language models (VLMs) that process both images and text, potentially leading to leakage of visual information. The ability to retrieve images from a public set using the model’s encoding of a caption highlights the risk, revealing memorized details exceeding what simple correlations should predict. A key concern is the model’s differential memorization, where some training samples are disproportionately recalled. Methods like text randomization demonstrate promise in reducing memorization, but further research is needed to fully mitigate this risk while maintaining model performance. Addressing this challenge is crucial for building safe and trustworthy VLMs.
Future Directions#
Future research could explore extending déjà vu memorization to other VLM architectures and datasets to better understand its generalizability. Investigating the impact of different training methodologies, data augmentation techniques, and architectural choices on memorization is crucial. A deeper examination into the interaction between memorization and generalization performance, particularly focusing on the trade-off between memorization reduction and downstream task accuracy, is needed. Further research should focus on developing more robust and effective mitigation strategies, going beyond simple text masking to explore more sophisticated techniques. Finally, investigating how déjà vu memorization relates to other forms of model bias and fairness concerns in VLMs could open up critical avenues of future work. This would include exploring the potential for these biases to disproportionately affect certain demographic groups and exploring mitigation strategies that specifically address these biases. This nuanced approach is essential for building more robust and trustworthy VLMs.
More visual insights#
More on figures
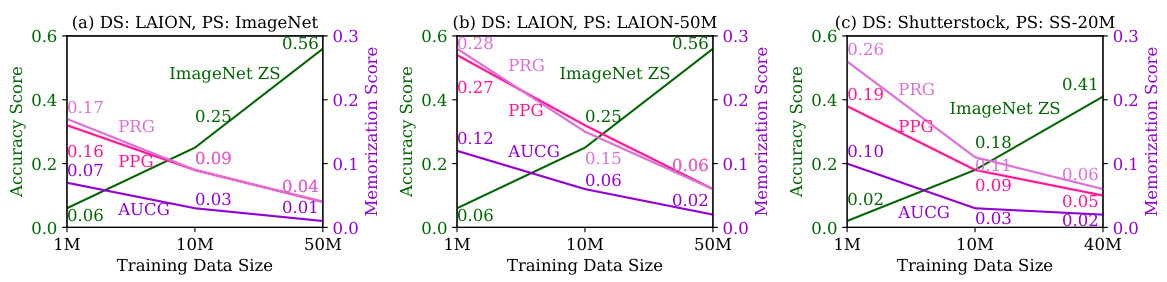
This figure shows the relationship between the training data size, model utility (ImageNet zero-shot accuracy), and the degree of memorization (PPG, PRG, AUCG). It demonstrates that even with good generalization performance (high zero-shot accuracy), memorization remains significant, particularly for smaller training set sizes. Three different datasets and public sets are compared to showcase the consistency of the findings.
This figure shows the impact of training set size on both the model’s utility (ImageNet zero-shot accuracy) and the degree of memorization (measured using PPG, PRG, and AUCG). Three different datasets were used: filtered LAION with ImageNet as the public set, filtered LAION with a holdout LAION-50M set as the public set, and Shutterstock with a holdout SS-20M set as the public set. The results indicate a trade-off between model utility and memorization; larger training sets lead to better generalization but don’t eliminate memorization entirely.
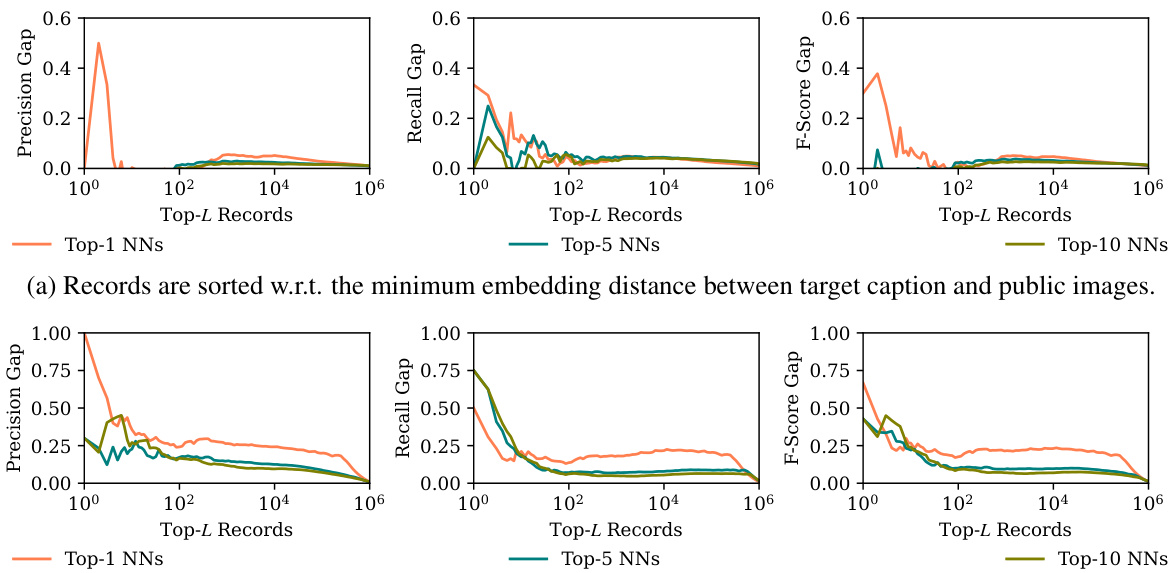
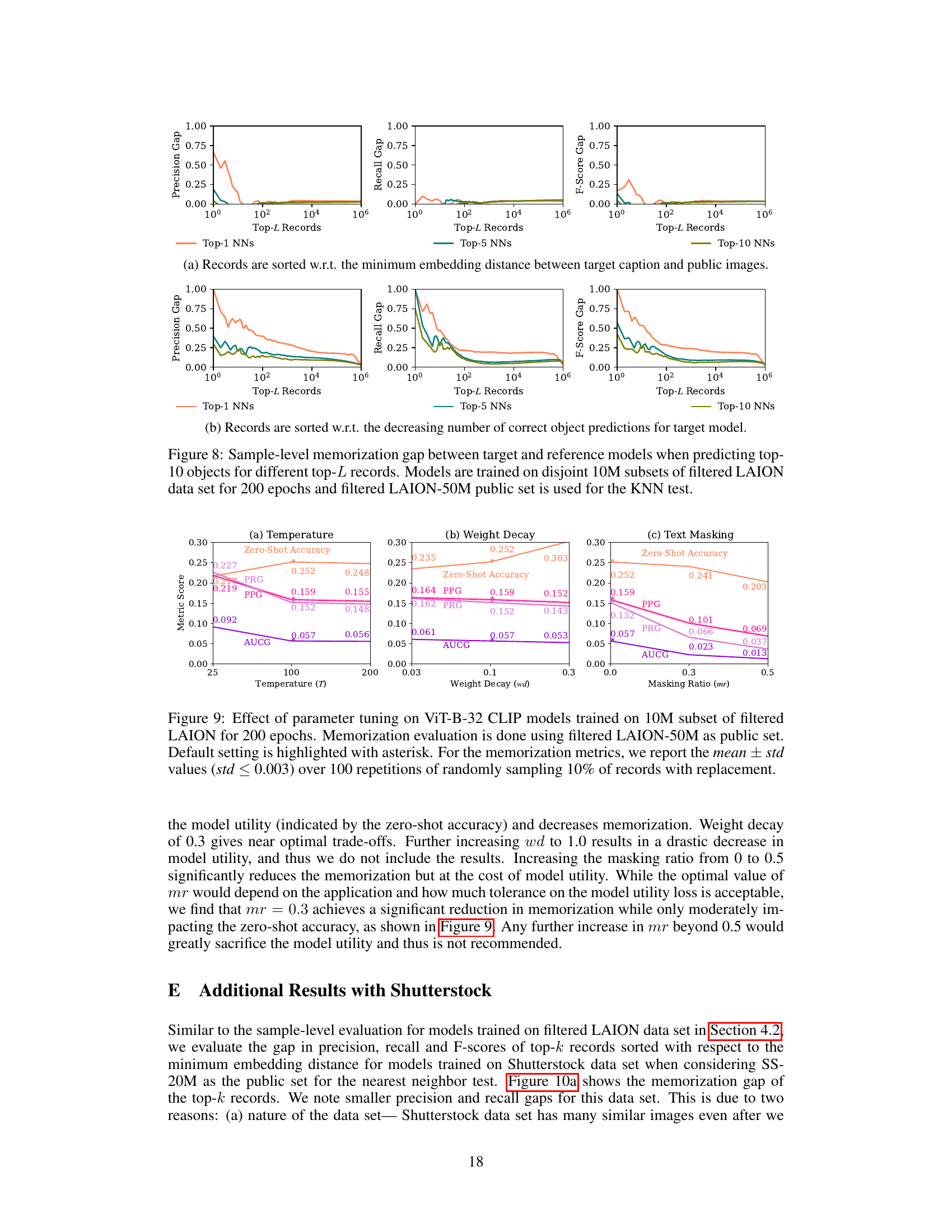
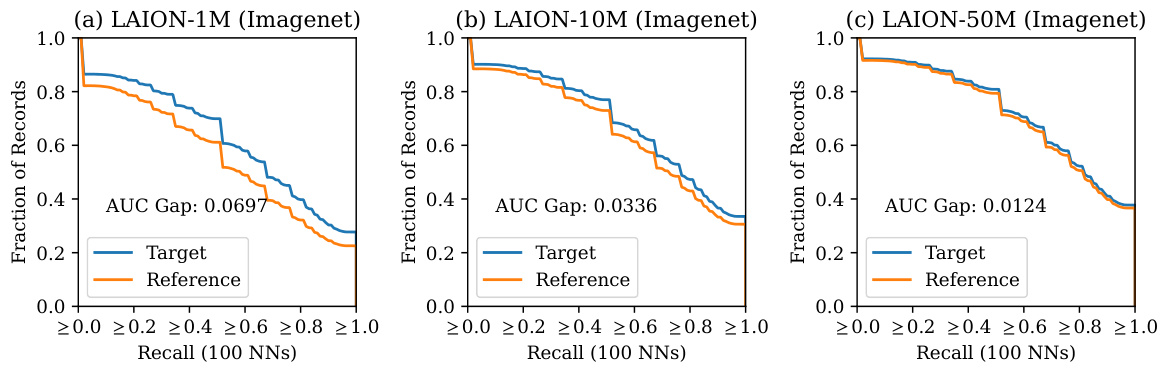
This figure shows sample-level memorization results. Two plots are shown, one where records are sorted by minimum embedding distance between target captions and public images, and another where records are sorted by the decreasing number of correct object predictions for the target model. Each plot shows precision, recall, and F-score gaps between the target and reference models for different top-L records (L=1, 5, 10). The large gaps for small L (especially top-1) indicate that the model exhibits strong déjà vu memorization on a small subset of training data points.
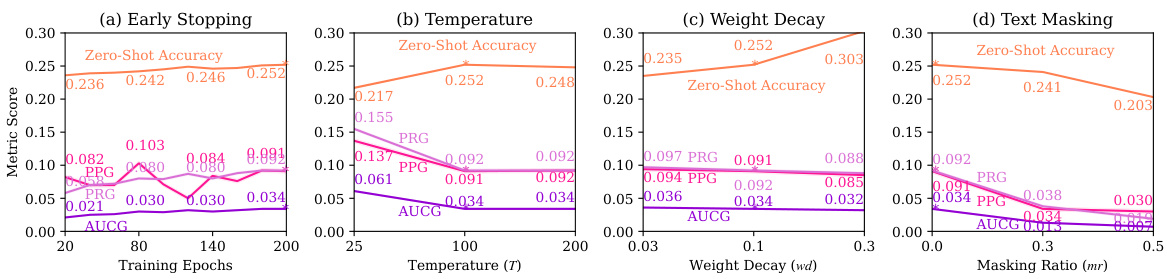
This figure shows the effect of different mitigation techniques on memorization in ViT-B-32 OpenCLIP models trained on a 10M subset of the filtered LAION dataset. The techniques evaluated are early stopping, temperature scaling, weight decay, and text masking. The results are evaluated using ImageNet as a public set and reported as the mean ± std (standard deviation) of memorization metrics (PPG, PRG, AUCG) over 100 random sampling trials. The default settings are marked with asterisks. The graph shows that text masking offers the best compromise, reducing memorization significantly without substantially impacting model utility.

This figure compares example images from the ImageNet and COCO datasets to highlight the difference in their complexity and labeling. ImageNet images typically have a single label, while COCO images often depict complex scenes with multiple objects and detailed captions.

This figure displays the impact of training set size on both the utility and memorization level of ViT-B-32 CLIP models. The utility is measured by ImageNet zero-shot accuracy. Memorization is assessed using population-level metrics (PPG, PRG, AUCG) calculated across three different public image sets, each with varying degrees of overlap with the training data. The results show a decrease in memorization with increasing training set sizes, indicating improved generalization.
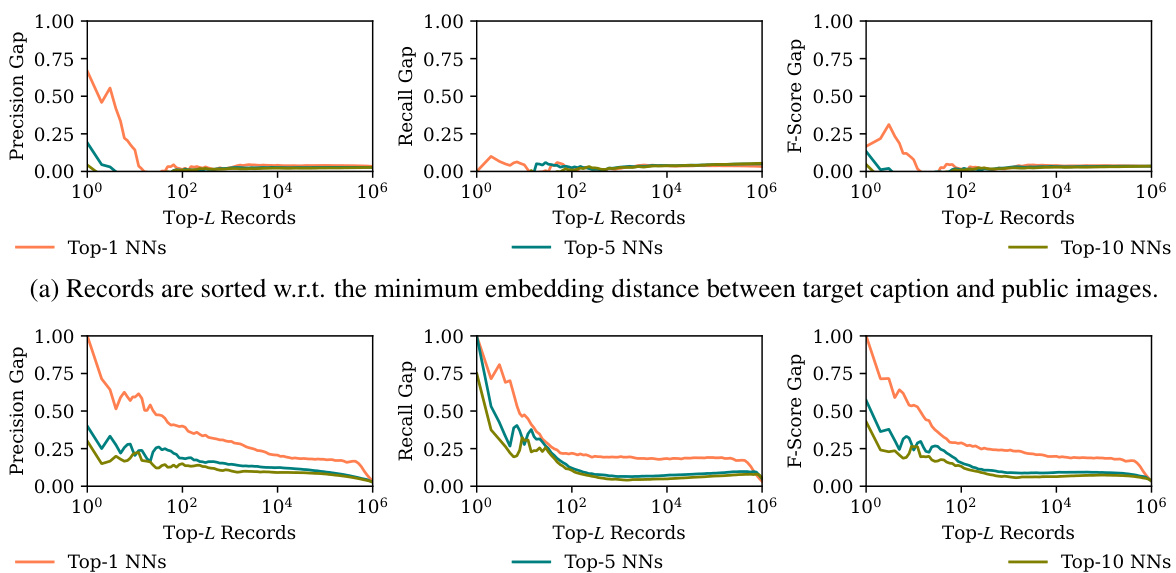
This figure shows the sample-level memorization gap between a target model (trained on the target image-text pair) and a reference model (not trained on the target image-text pair). The results are shown for different numbers of nearest neighbors (Top-1, Top-5, Top-10). The x-axis represents the number of top-L records considered, and the y-axis represents the gap in precision, recall, and F1-score between the target and reference models. The figure demonstrates that the memorization gap is much larger for a small subset of training samples, indicating stronger memorization for these specific samples.

This figure shows the impact of four different mitigation techniques on a ViT-B-32 OpenCLIP model trained on a 10M subset of the filtered LAION dataset. The mitigation techniques are early stopping, temperature scaling, weight decay, and text masking. The model’s performance is evaluated using ImageNet zero-shot accuracy and three memorization metrics: population precision gap (PPG), population recall gap (PRG), and AUC gap (AUCG). The results show that text masking provides the best trade-off between reducing memorization and maintaining model utility.
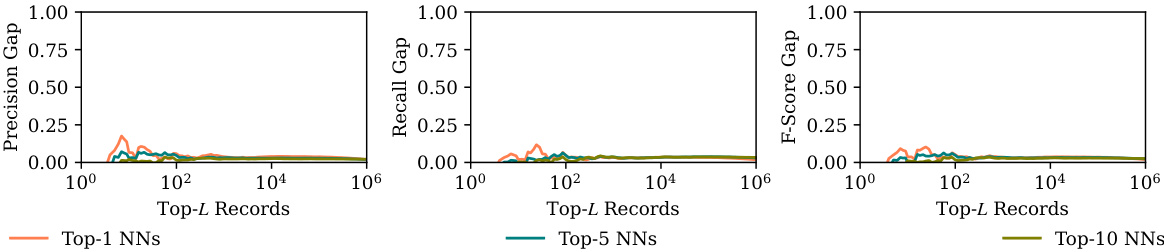
This figure shows the sample-level memorization results. The x-axis represents the top-L records (sorted by minimum embedding distance or decreasing number of correct predictions), and the y-axis shows the gap in precision, recall, and F1-score between target and reference models for the top 10 objects. The figure demonstrates that strong memorization is present in a small subset of samples, indicated by large gaps, especially when L is small (meaning only the closest or best-predicted records are considered).

This figure visualizes the sample-level memorization gap between a target model (trained with the specific image-text pair) and a reference model (not trained with that pair). It shows the precision, recall, and F1-score gaps when predicting the top 10 objects in a target image, based on its caption. The x-axis represents different numbers of nearest neighbors (NNs) considered (Top-L Records), and the y-axis shows the gap between the target and reference models’ metrics. The figure reveals that the memorization gap is significantly higher for a smaller subset of samples, indicating a disproportionate memorization effect by the model on certain samples.

This figure shows an example of how a CLIP model, trained on a subset of the Shutterstock dataset, memorizes objects from a training image. A target image and its caption are input to the model, which retrieves similar images from a separate, non-overlapping public dataset. The model trained on the target image (target VLM) retrieves images with significantly more of the target image’s objects than a model not trained on the target image (reference VLM). Objects correctly identified are highlighted in orange (true positives), while incorrectly identified objects are in blue (false positives). This demonstrates the model’s memorization of specific training images.

This figure demonstrates the concept of déjà vu memorization using a CLIP model. A target image and its caption are input to the model. The model then retrieves similar images from a separate, public dataset. The figure shows that a model trained on the target image (target VLM) retrieves images containing significantly more objects from the target image (true positives) than a model not trained on it (reference VLM). The objects correctly identified are highlighted in orange, and the incorrectly identified objects are in blue. This difference highlights how the model memorizes details from its training data, even if it’s not explicitly shown in the image caption.
Full paper#