↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current 4D generation methods struggle with inconsistent temporal appearance and spatial inconsistencies due to challenges in integrating multiple diffusion models. They lack effective multi-view spatial-temporal modeling, leading to flickering and artifacts. This paper introduces 4Diffusion to address these issues.
4Diffusion uses a unified diffusion model (4DM) that incorporates a motion module into a 3D-aware model, capturing multi-view spatial-temporal relationships. It employs a novel 4D-aware loss function to refine 4D representations and an anchor loss to enhance detail. The results show that 4Diffusion generates significantly better 4D content with improved spatial-temporal consistency compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to 4D content generation, addressing limitations of existing methods. Its unified diffusion model and innovative loss functions offer significant improvements in spatial-temporal consistency, leading to higher-quality 4D content. This work is particularly relevant to researchers in computer vision, graphics, and AI, opening new avenues for creating realistic and dynamic 3D experiences.
Visual Insights#

This figure shows three examples of 4D content generation from monocular videos using the proposed 4Diffusion method. Each example consists of three sequences: a top row showing the original monocular video frames, a middle row displaying the generated multi-view video frames at an intermediate viewpoint, and a bottom row presenting the generated multi-view video frames at a different viewpoint. The three examples feature a horse, a frog, and a squirrel, respectively. The figure demonstrates the capability of 4Diffusion to generate temporally and spatially consistent 4D content from single-view video input.

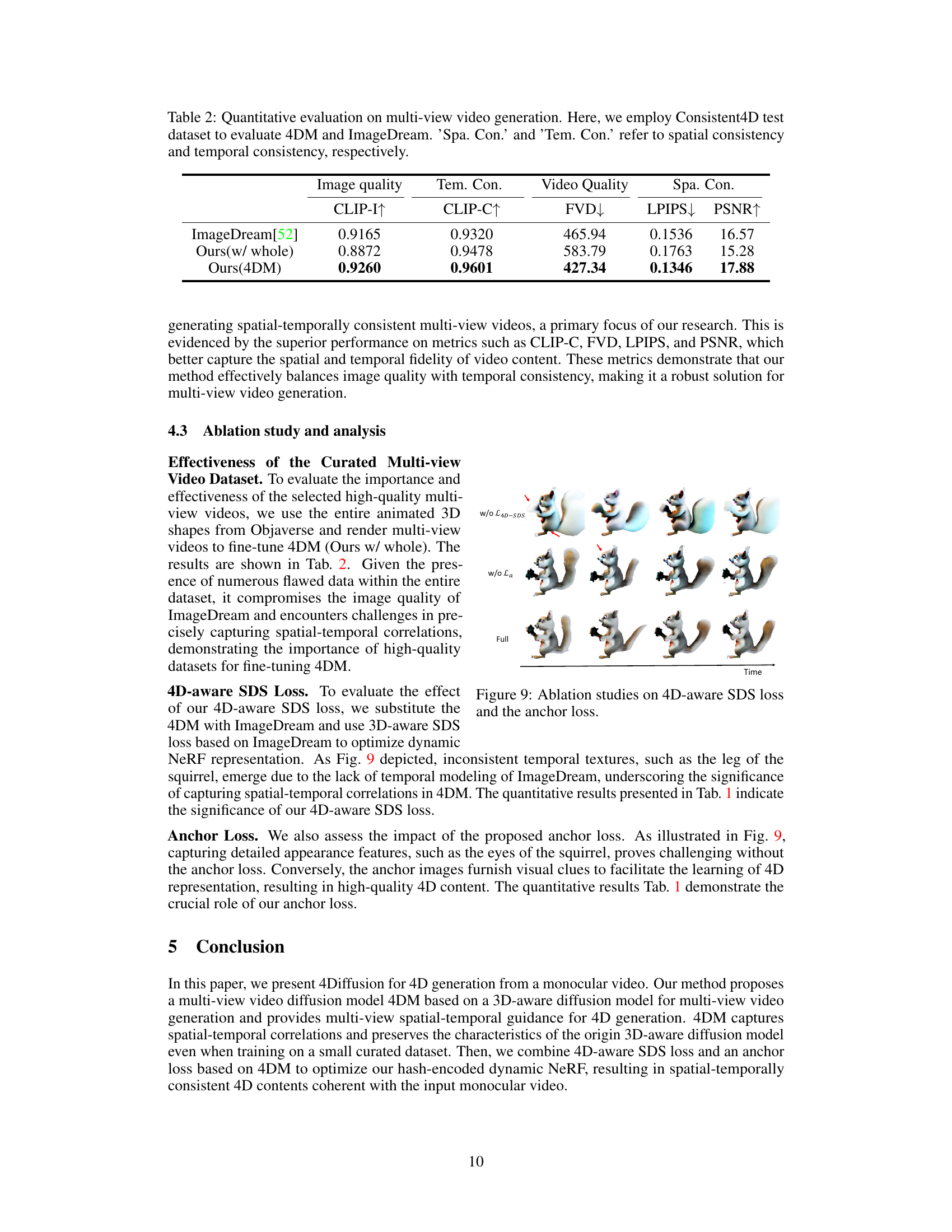
This table presents a quantitative comparison of different methods for 4D generation, focusing on image quality, temporal consistency, video quality, and spatial consistency. The metrics used are CLIP-I (higher is better), CLIP-C (higher is better), FVD (lower is better), LPIPS (lower is better), and PSNR (higher is better). The results show that the proposed method (‘Ours’) outperforms existing methods in most of the metrics.
In-depth insights#
Multi-view Diffusion#
Multi-view diffusion models represent a significant advancement in 3D and 4D content generation. By leveraging multiple viewpoints simultaneously, these models overcome limitations of single-view approaches, offering enhanced spatial consistency and realism. The core idea involves training a diffusion model on datasets comprising multi-view images or videos. This allows the model to learn complex relationships between different perspectives, enabling it to generate novel views with improved coherence. Incorporating motion information further extends this capability to 4D, facilitating realistic simulations of dynamic scenes. Key challenges involve efficiently handling the increased data dimensionality and computational cost associated with multi-view data. Effective architectures and loss functions are crucial for achieving high-quality results and mitigating issues like temporal inconsistencies or artifacts. Future research should focus on improving efficiency, exploring new architectures, and expanding application to more complex scenarios and data modalities. The ability to generate consistent, high-fidelity content from multiple views will have significant implications across various fields.
4D-Aware Sampling#
The concept of “4D-Aware Sampling” in the context of a research paper likely refers to a novel sampling method for generating or processing four-dimensional (4D) data, encompassing three spatial dimensions and one temporal dimension. This approach would likely deviate from traditional sampling techniques by explicitly considering the temporal evolution of the data. Key improvements could involve reducing temporal inconsistencies, artifacts or flickering commonly observed in naive 4D data generation. The method might involve sophisticated temporal correlations or modeling, potentially using neural networks or other advanced techniques to predict or infer missing or unseen temporal data points. The core innovation might lie in the way the sampling strategy adapts and learns from the temporal context, enabling more coherent and realistic 4D representations. Applications could range from generating realistic 4D videos or simulations to analyzing time-varying phenomena, allowing a more accurate understanding of complex dynamical systems.
Dynamic NeRF#
Dynamic Neural Radiance Fields (NeRFs) represent a significant advancement in novel view synthesis by representing a scene as a continuous 5D function of spatial coordinates and time. This allows for the generation of photorealistic videos from a single input video. The core challenge with dynamic NeRFs lies in efficiently modeling temporal consistency while maintaining high-fidelity spatial detail, especially when dealing with complex scenes and intricate movements. Different approaches exist, including those employing explicit time representations or implicit learning mechanisms. The choice of method critically influences the trade-off between temporal coherence and computational cost. Furthermore, the training process for dynamic NeRFs often necessitates substantial amounts of data. Effective loss functions tailored to temporal consistency, such as those that penalize flickering or temporal discontinuities, are crucial for successful training. Future research should investigate innovative architectural designs, data efficiency improvements, and generalization capabilities to enhance the performance and practicality of dynamic NeRFs, particularly in real-world scenarios.
Motion Module#
A motion module in a video generation model is a critical component for realistically animating generated content. Its purpose is to learn and apply temporal dynamics to the spatial representations created by other parts of the model, such as a spatial module or a 3D-aware diffusion model. Effective motion modules are crucial for generating videos that appear natural and coherent, avoiding jerky or unrealistic movements. The design of a motion module can vary significantly. It might involve recurrent neural networks (RNNs) to process temporal sequences, convolutional layers to capture local motion patterns, or attention mechanisms to focus on relevant parts of the video frames for motion prediction. The training process for a motion module is equally important. It needs sufficient training data to learn diverse and realistic motion patterns. If the training data is limited, the motion module may struggle to capture the complexity of real-world movement, leading to poor quality animations. Furthermore, incorporating a motion module into a pre-trained model can be particularly effective. This approach leverages the pre-trained model’s ability to generate high-quality spatial features, while the motion module enhances this with temporal coherence. Finally, the evaluation of a motion module necessitates careful metrics, such as the temporal consistency of generated videos, the naturalness of movements, and the avoidance of artifacts like flickering or jittering. These aspects are central to assessing the module’s overall performance and contribution to the quality of the generated videos.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, it would involve removing or deactivating parts of the 4Diffusion model (e.g., the motion module, the 4D-aware SDS loss, or the anchor loss) one at a time and evaluating the performance on relevant metrics (like multi-view consistency, temporal coherence, or visual fidelity). The results would reveal which components are most crucial for the model’s success. This analysis is critical for understanding the architecture’s design choices, demonstrating the relative importance of different modules, and potentially suggesting areas for improvement or simplification. For instance, if removing the anchor loss significantly degrades performance, it highlights its essential role in enhancing spatial details. Conversely, if removing a module barely affects the results, it suggests potential redundancy and a possible direction for model optimization by removing it for better efficiency.
More visual insights#
More on figures

This figure illustrates the challenges of using multiple diffusion models for 4D generation. It shows the output of three different diffusion models (Stable Diffusion, MVDream, and ZeroScope) when generating images of a monkey eating a candy bar, starting from a noisy input. The results from each model exhibit discrepancies in terms of visual quality, temporal consistency, and multi-view spatial consistency, highlighting the difficulty of integrating multiple models for a coherent output. The inconsistent results make it challenging to create high-quality, spatially and temporally consistent 4D content.

This figure provides a high-level overview of the 4Diffusion pipeline. It shows the process of using a monocular video as input to generate multi-view videos and then using those to create a 4D representation (Dynamic NeRF). The core of the process involves training a unified diffusion model, 4DM, that leverages a pre-trained 3D-aware model (ImageDream) with added motion modules. This 4DM model is used to generate consistent multi-view videos. These videos are then used with a 4D-aware Score Distillation Sampling (SDS) loss and an anchor loss to optimize the parameters of the Dynamic NeRF, which is the final 4D representation.
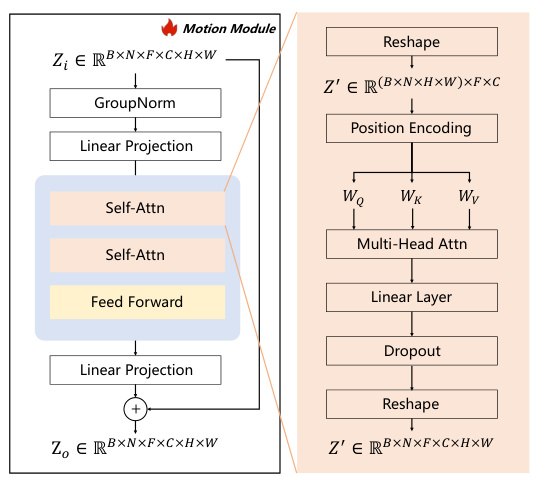
The figure shows the detailed architecture of the motion module, a key component of the 4DM (Multi-view Video Diffusion Model). It illustrates how the motion module processes input video features to capture temporal dynamics and integrates this temporal information with spatial information. The input is a tensor representing multi-view video latents, which is reshaped and processed through group normalization, linear projections, self-attention blocks (both spatial and temporal), and feed-forward networks. The output of the module is then added back to the input via a residual connection, enhancing the temporal consistency of multi-view video generation.

This figure presents a detailed architecture of the motion module used in 4DM (Multi-view Video Diffusion Model). The motion module is designed to capture temporal correlations and consists of several components, such as group normalization, linear projections, self-attention blocks, feed-forward blocks, and another linear layer. The input to the module is a tensor representing multiple video frames from different viewpoints and the output is a modified tensor that incorporates temporal information. The diagram shows how the input latent representations are reshaped and passed through the different layers to finally output temporally enriched feature tensors.

This figure shows the results of directly optimizing the generated multi-view videos. The left side shows only the videos generated from 4DM, while the right side shows the results of directly optimizing on those videos using the dynamic NeRF. The difference highlights the impact of using the 4D-aware Score Distillation Sampling (SDS) loss and the anchor loss in improving the quality and consistency of the final 4D representation. It demonstrates that directly optimizing on the generated multi-view videos can lead to suboptimal results, highlighting the need for the 4D-aware SDS and anchor loss.

This figure compares the 4D generation results of the proposed 4Diffusion method with three other state-of-the-art methods: 4D-fy, Consistent4D, and DreamGaussian4D. The comparison uses three different video sequences (each shown across two rows): a bird, Yoda, and a robot. For each sequence, several views (both across time and across different viewpoints) are shown. This allows a visual assessment of the methods’ ability to generate temporally consistent, high-quality 4D content, considering both spatial and temporal coherence across viewpoints. The differences in visual quality and consistency between the methods are readily apparent.
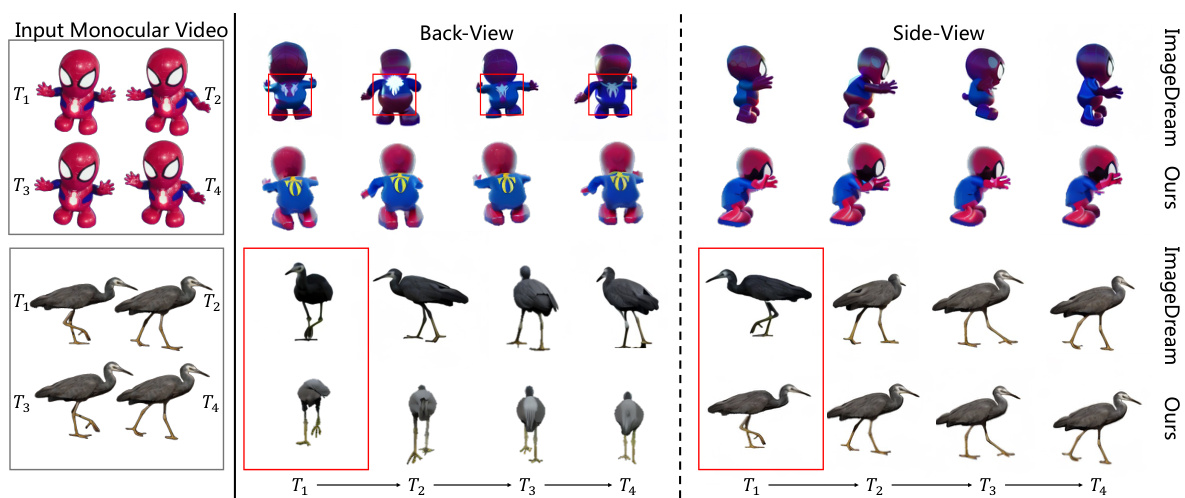
This figure shows a comparison of multi-view video generation results between the proposed 4DM model and the ImageDream model. The results demonstrate that 4DM generates videos with better spatial and temporal consistency compared to ImageDream, as evidenced by more coherent and realistic motion across multiple viewpoints. The temporal consistency is highlighted using the timestep ‘T’ to indicate the frame sequence.

This figure shows the ablation study results of 4D-aware Score Distillation Sampling (SDS) loss and anchor loss. The top row shows the results without 4D-aware SDS loss, demonstrating inconsistent temporal textures, such as the tail of the squirrel. The middle row shows the results without anchor loss, highlighting the difficulty in capturing fine details like the eyes of the squirrel. The bottom row presents the results with both losses included, illustrating the improvements in temporal consistency and details. This demonstrates the importance of both components in 4Diffusion for high-quality 4D content generation.
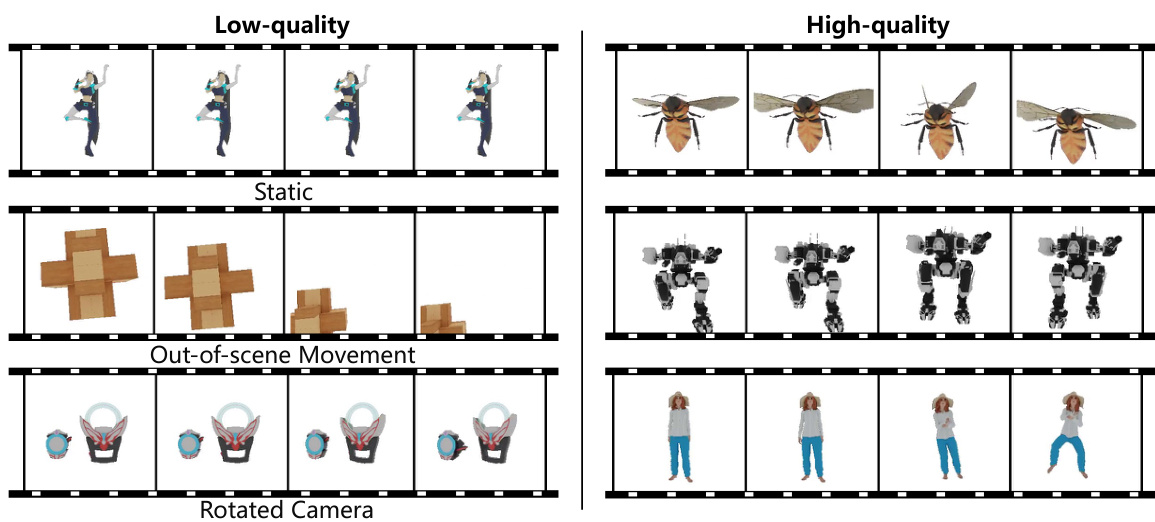
This figure shows examples of low-quality and high-quality animated 3D data used to train the model. The low-quality examples suffer from static motion, objects moving outside the scene, or camera rotations, while high-quality examples have natural and realistic movement. The goal was to create a dataset with consistent and high-quality appearance.

This figure shows three examples of 4D generation results using the proposed 4Diffusion model. Each example shows a sequence of images of a different object (a blue jay, a cat, and a character riding a wolf) viewed from two different viewpoints. The top row shows the reference images, while the bottom row displays the results generated by 4Diffusion. This figure visually demonstrates the model’s ability to generate high-quality spatial-temporally consistent 4D contents from a monocular video.

This figure compares the 4D generation results of 4Diffusion with three other methods (4D-fy, DreamGaussian4D, and Consistent4D) on several examples from the Objaverse dataset. The models were tested on examples not used during training. Red arrows highlight areas where 4Diffusion demonstrates improvements over the other methods in terms of temporal and spatial consistency.

This figure shows two examples of text-to-4D generation results from 4Diffusion. The top row shows a sequence of images generated from the text prompt “A photo of a horse walking, toy, 3d asset”. The bottom row displays another sequence generated from the prompt “Astronaut walking in space, full body, 3d asset”. Each sequence demonstrates the model’s capability to generate temporally consistent 4D content from simple text descriptions.
More on tables

This table presents a quantitative comparison of multi-view video generation results between the proposed 4DM model, the ImageDream model, and the results obtained when using the entire Objaverse dataset to train 4DM. The metrics used for comparison include CLIP-I (image quality), CLIP-C (temporal consistency), FVD (video quality), LPIPS (spatial consistency), and PSNR (spatial consistency). The table highlights the superior performance of the proposed 4DM model in generating high-quality, spatially and temporally consistent multi-view videos.
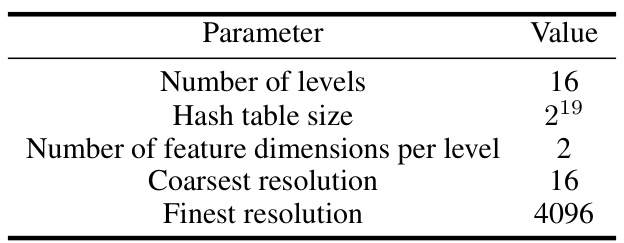
This table lists the hyperparameters used for the hash encoding of the spatial and spatio-temporal features in the dynamic NeRF representation. Specifically, it details the number of levels in the multiresolution hash table, the size of each hash table, the number of feature dimensions per level, and the coarsest and finest resolutions used.
Full paper#