↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) rely on Key-Value (KV) caching to accelerate inference, but the cache size grows linearly with sequence length, hindering applications requiring long contexts. This poses a significant challenge for resource-constrained deployments. Existing compression methods like quantization and sparsity only focus on intra-layer redundancy.
MiniCache tackles this challenge by introducing a novel cross-layer merging strategy that exploits the high similarity between adjacent layers’ KV cache states. By disentangling states into magnitude and direction components and smartly merging similar directions, while selectively retaining distinct states, MiniCache significantly reduces memory footprint. Evaluation across various LLMs and datasets demonstrate exceptional performance, exceeding state-of-the-art compression ratios while maintaining near-lossless performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on efficient LLM deployment and inference. It directly addresses the critical issue of ever-growing KV cache memory consumption in LLMs, offering a novel and effective compression technique. The findings have significant implications for optimizing resource usage and improving inference speed, paving the way for broader LLM accessibility and application. This work is directly relevant to current research trends in efficient deep learning and opens avenues for further investigation in cross-layer redundancy and advanced compression strategies for LLMs.
Visual Insights#
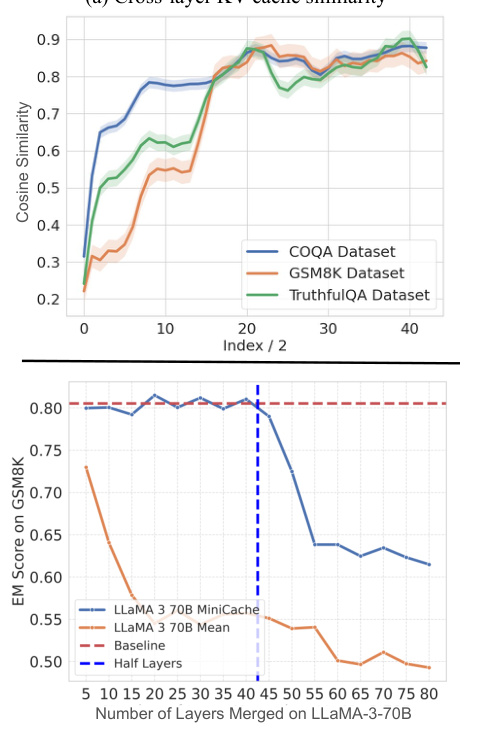
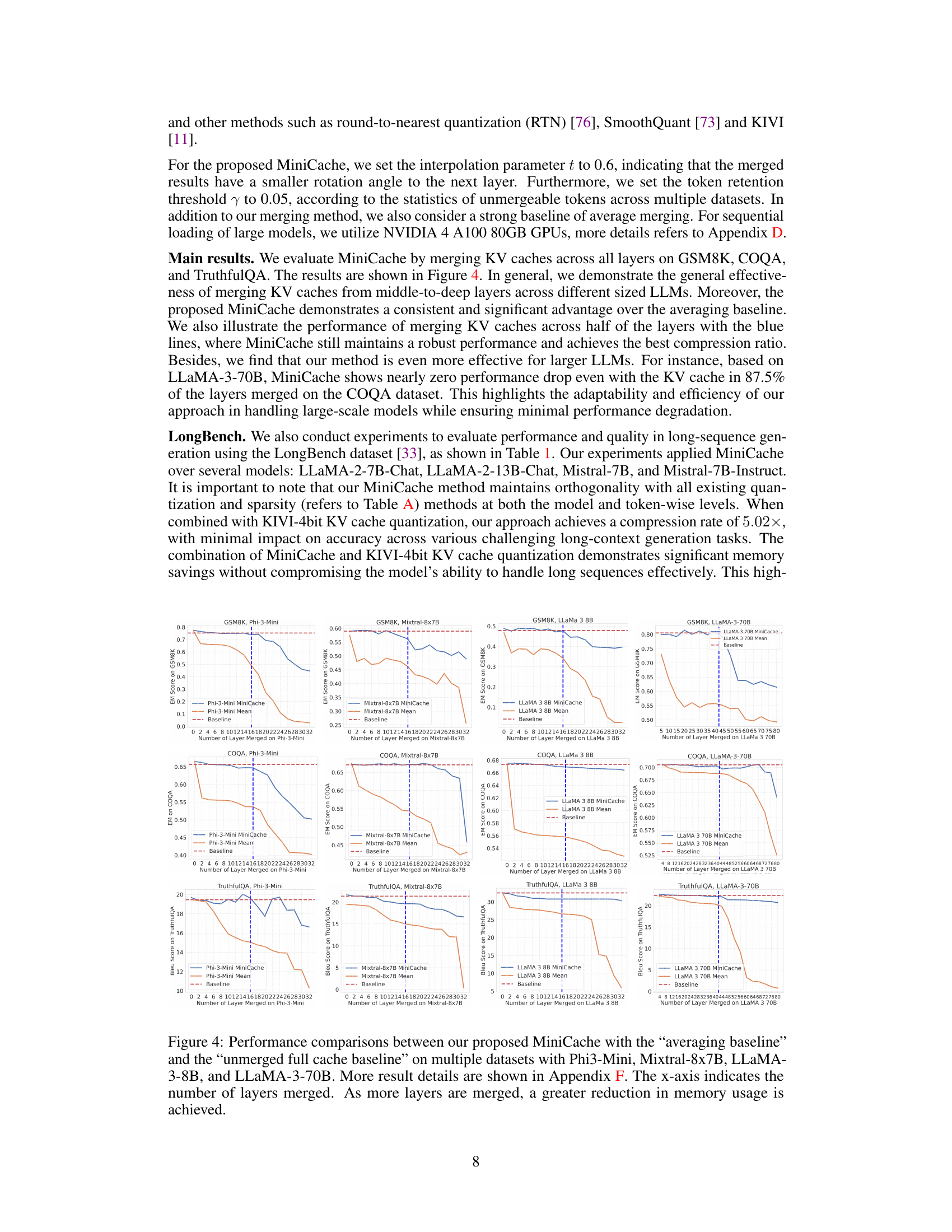
This figure provides an overview of the MiniCache strategy and shows example results. Panel (a) demonstrates the high similarity of KV cache states between adjacent layers, especially in the middle and deep layers of LLMs. Panel (b) compares MiniCache’s performance to a simple averaging baseline on the GSM8K dataset using the LLaMA-3-70B model, showing that MiniCache achieves near-lossless performance when merging layers from the halfway point. Finally, panel (c) illustrates the key difference between MiniCache and prior methods: MiniCache focuses on inter-layer redundancy in the depth dimension, whereas others focus on intra-layer redundancy.

This table presents the results of evaluating different KV cache compression methods on the LongBench benchmark. The methods compared include the baseline (no compression), Round-to-Nearest Quantization (RTN), SmoothQuant, KIVI-2, and MiniCache. The table shows the performance of each method across several metrics (LCC, RepoBench-P, PR-en, TREC, 2wikimqa, GovReport, MQA-zh, and Average) for four different LLMs (Llama-2-7B-Chat, Llama-2-13B-Chat, Mistral-7B, and Mistral-7B-Instruct). The ‘Compression Ratio’ column indicates the memory savings achieved by each method compared to the baseline. MiniCache consistently demonstrates the highest compression ratio, indicating it is the most memory efficient.
In-depth insights#
Depthwise KV Compression#
Depthwise KV Cache compression is a novel approach to reduce memory usage in large language models (LLMs) by exploiting the redundancy present in the key-value (KV) cache across different layers. The core idea is that adjacent layers in the middle-to-deep sections of LLMs exhibit a high degree of similarity in their KV cache states. This similarity allows for compression by merging states from multiple layers, resulting in a reduced memory footprint. This method is orthogonal to existing KV compression techniques like quantization and sparsity, meaning it can be used in conjunction with these methods for even greater compression. The key challenge lies in developing efficient merging strategies that minimize information loss while maximizing compression. A successful approach involves disentangling the magnitude and direction components of state vectors, interpolating the directions, and preserving the magnitudes to reconstruct the original states with minimal distortion. Careful consideration of token retention is also essential to prevent significant performance degradation. Overall, depthwise KV cache compression offers a promising avenue for significantly improving LLM inference efficiency by reducing memory requirements, particularly beneficial for applications involving long sequences.
MiniCache: Design#
MiniCache’s design centers on addressing the limitations of existing KV cache compression techniques for LLMs. Its core innovation lies in exploiting the inter-layer redundancy of KV cache states, particularly in the middle-to-deep layers of LLMs. Instead of focusing solely on intra-layer compression, MiniCache introduces a cross-layer merging strategy. This involves decomposing state vectors into magnitude and direction components, interpolating directions across adjacent layers, while preserving magnitudes to minimize information loss. A crucial element is the token retention mechanism, which identifies and preserves highly distinct state pairs that are not suitable for merging, maintaining performance while maximizing compression. The design is training-free and computationally efficient, complementing existing techniques like quantization and sparsity, making it adaptable and easily integrable into various LLM inference frameworks. The overall approach is elegantly simple yet highly effective in substantially reducing memory footprint and increasing inference throughput.
Cross-Layer Merging#
Cross-layer merging, as a technique, aims to reduce redundancy in large language model (LLM) inference by leveraging the similarity of key-value (KV) cache states across adjacent layers. Instead of storing separate KV caches for each layer, this method merges information from multiple layers, significantly reducing memory footprint. The core idea is based on the observation that deeper layers in LLMs exhibit high similarity in their KV cache states. This allows for efficient compression by representing these similar states with a single, merged representation. The process likely involves a merging function that combines KV cache states from multiple layers, potentially through interpolation or averaging of state vectors, while preserving important information. This careful merging process is crucial for maintaining accuracy and preventing information loss. A key challenge in cross-layer merging is to accurately identify which layers and tokens are suitable for merging, as some token pairs may have unique semantic meanings that cannot be effectively merged. To address this, strategies may include using similarity metrics to identify suitable candidates for merging and retaining highly distinct state pairs separately to minimize performance degradation. Successful implementation of cross-layer merging can result in significant memory savings and improved inference throughput for LLMs.
MiniCache: Results#
MiniCache’s results demonstrate significant improvements in LLM inference efficiency by compressing the Key-Value (KV) cache. Cross-layer merging, a core component of MiniCache, leverages the high similarity of KV states across adjacent layers in deep LLMs to reduce memory footprint and enhance throughput. Experiments across multiple LLMs (LLaMA, Mixtral, Phi-3) and benchmarks show substantial compression ratios, often exceeding 1.5x without quantization and reaching up to 5.02x when combined with 4-bit quantization. Near-lossless performance is maintained even with aggressive merging, suggesting that MiniCache effectively handles the inherent redundancy in deep LLMs. Furthermore, the results highlight MiniCache’s compatibility with other KV compression techniques. Orthogonality with quantization showcases added benefits when combined, achieving superior compression ratios and memory reductions. Superior compression ratios and high throughput are reported across various datasets, demonstrating the general applicability and robustness of the proposed method for efficient LLM deployment.
Future of MiniCache#
The future of MiniCache looks promising, particularly concerning scalability and adaptability. Its training-free nature and compatibility with existing techniques make it readily integratable into various LLM deployment pipelines. Future work could focus on exploring cross-multiple-layer merging, potentially achieving even higher compression ratios. More sophisticated merging algorithms, such as spherical cubic interpolation, could improve merging accuracy while minimizing information loss. Expanding the framework to encompass other types of LLMs and addressing the handling of exceptionally diverse token pairs that are difficult to merge will be crucial. Research into dynamic parameter adjustment (like the interpolation parameter ’t’) based on observed characteristics of KV caches across layers promises performance gains. MiniCache’s success hinges on efficient implementation, so optimization efforts toward reducing computational overhead are essential. Finally, exploring MiniCache’s synergy with advanced memory management techniques and other optimization strategies would unlock its full potential for deployment in resource-constrained environments and high-throughput applications.
More visual insights#
More on figures
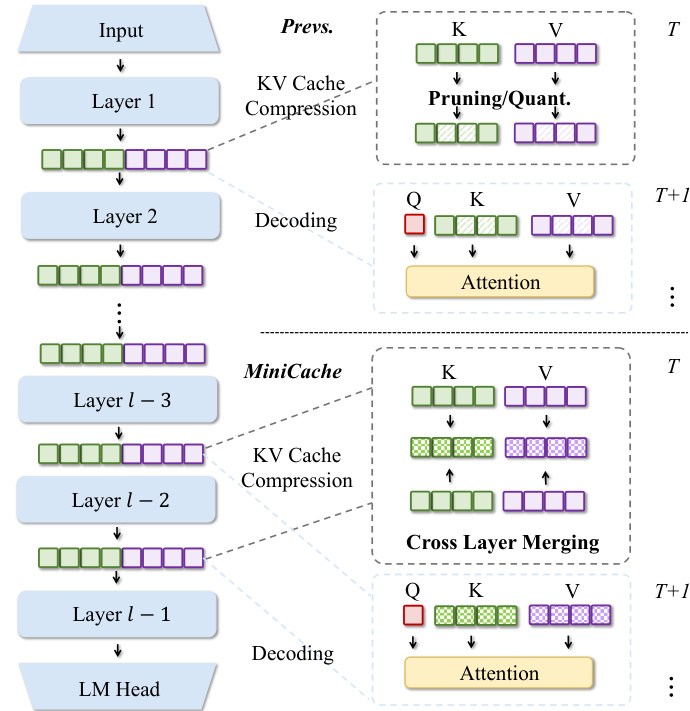
This figure illustrates the MiniCache strategy and its results. Panel (a) shows that KV cache states are highly similar between adjacent layers in LLMs, especially in the middle-to-deep layers. Panel (b) compares MiniCache’s performance to a simple averaging baseline on the GSM8K dataset, demonstrating that MiniCache achieves near-lossless performance by merging layers from the middle upwards. Panel (c) highlights the key difference between MiniCache and prior work: MiniCache focuses on the inter-layer redundancy of KV caches, which prior methods overlooked.
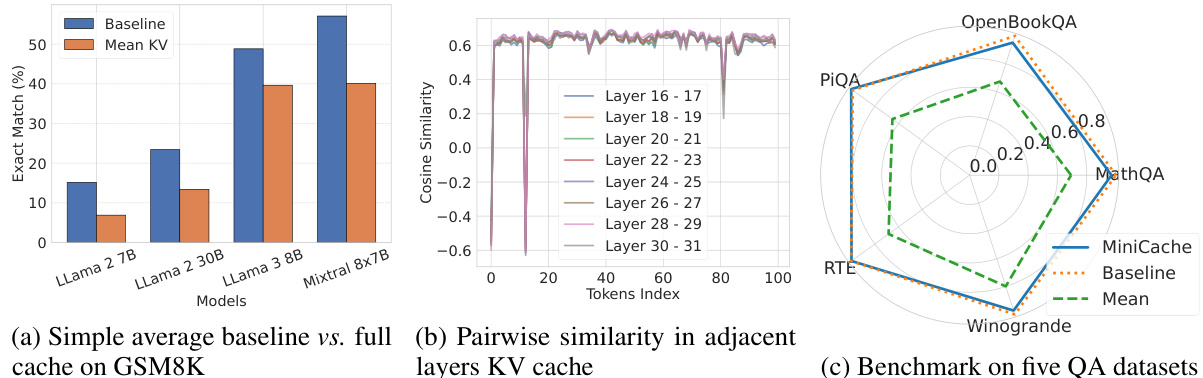
This figure provides a visual overview of MiniCache and its performance. Subfigure (a) demonstrates the high similarity of KV cache states between adjacent layers in LLMs, particularly in the middle and deep layers. Subfigure (b) compares MiniCache’s performance to a simple averaging baseline on the GSM8K dataset, showing MiniCache achieves near-lossless performance by merging from the half-layer depth. Subfigure (c) illustrates the key difference between MiniCache and prior methods: MiniCache focuses on inter-layer redundancy, a factor that previous methods overlooked.

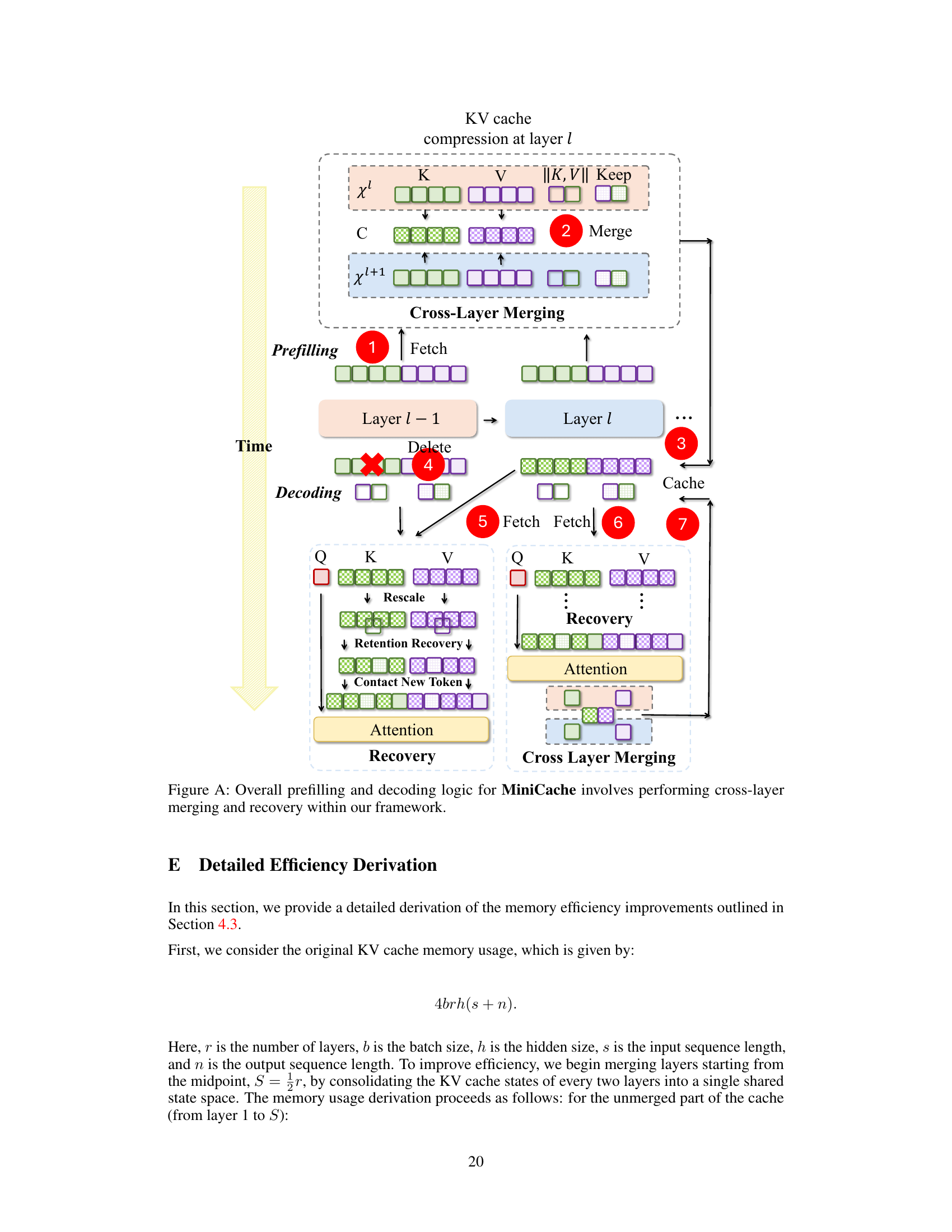
This figure illustrates the MiniCache method for cross-layer KV cache compression and restoration. (a) shows the compression process: fetching KV caches from layers l and l-1, merging them using a reparameterization technique (Eq. 3), calculating magnitudes, selecting unmergeable tokens for retention, and storing the merged cache, retention tokens, and magnitudes. (b) shows the restoration process: retrieving the merged cache and magnitudes, rescaling the magnitudes (Eq. 2), and recovering the retention tokens to reconstruct the original KV caches.

This figure provides an overview of the MiniCache strategy and its performance. Panel (a) shows that adjacent layers in LLMs exhibit high similarity in their KV cache states, especially in the middle to deep layers. Panel (b) illustrates the effectiveness of MiniCache compared to a simple averaging baseline on the GSM8K dataset, demonstrating near-lossless performance with layer merging starting from the middle layers. Panel (c) highlights the key difference between MiniCache and existing intra-layer methods: MiniCache leverages inter-layer redundancy in the depth dimension of LLMs for compression, an aspect not previously considered.
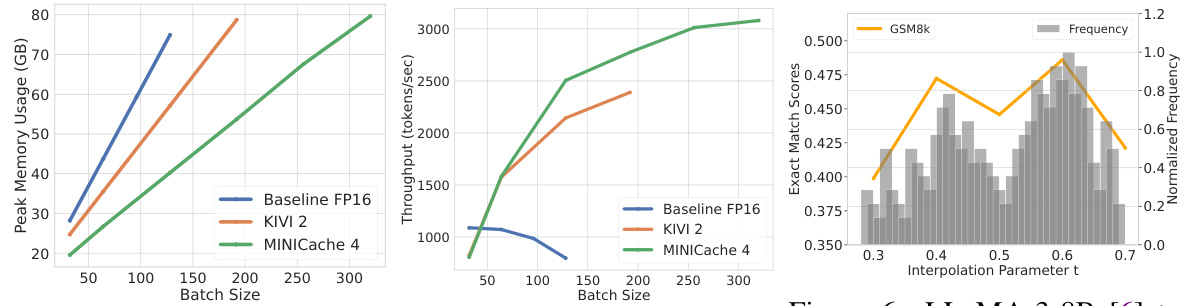
This figure shows the results of an experiment comparing the memory usage and throughput of three different methods: a baseline using FP16, KIVI-2, and MiniCache-4. The experiment was conducted using the LLaMA-2-7B model and varied the batch size. MiniCache-4 consistently demonstrates lower memory usage and significantly higher throughput compared to the other methods, especially as the batch size increases. This highlights MiniCache’s efficiency in handling large language models.

This figure illustrates the MiniCache method’s cross-layer compression and restoration processes. Part (a) shows how KV caches from adjacent layers are merged into shared states, magnitudes are calculated, and unmergeable tokens are retained and stored. Part (b) demonstrates the restoration of the original states from the merged cache, magnitudes, and retained tokens.

This figure provides an overview of MiniCache and its results. Panel (a) demonstrates the high similarity of KV cache states between adjacent layers in LLMs, especially in deeper layers. Panel (b) shows that MiniCache, by merging KV caches from the middle layer downwards, achieves near lossless performance on the GSM8K benchmark while outperforming a simple averaging baseline. Panel (c) illustrates how MiniCache uniquely addresses inter-layer redundancy in KV caches—a factor ignored by other methods. It uses a novel approach of disentangling the states into magnitude and direction components, then interpolating the directions and preserving lengths.
More on tables
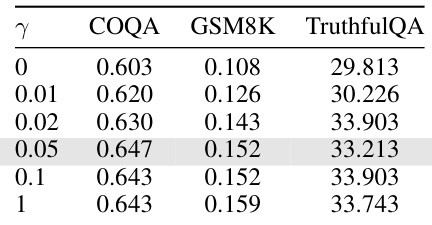
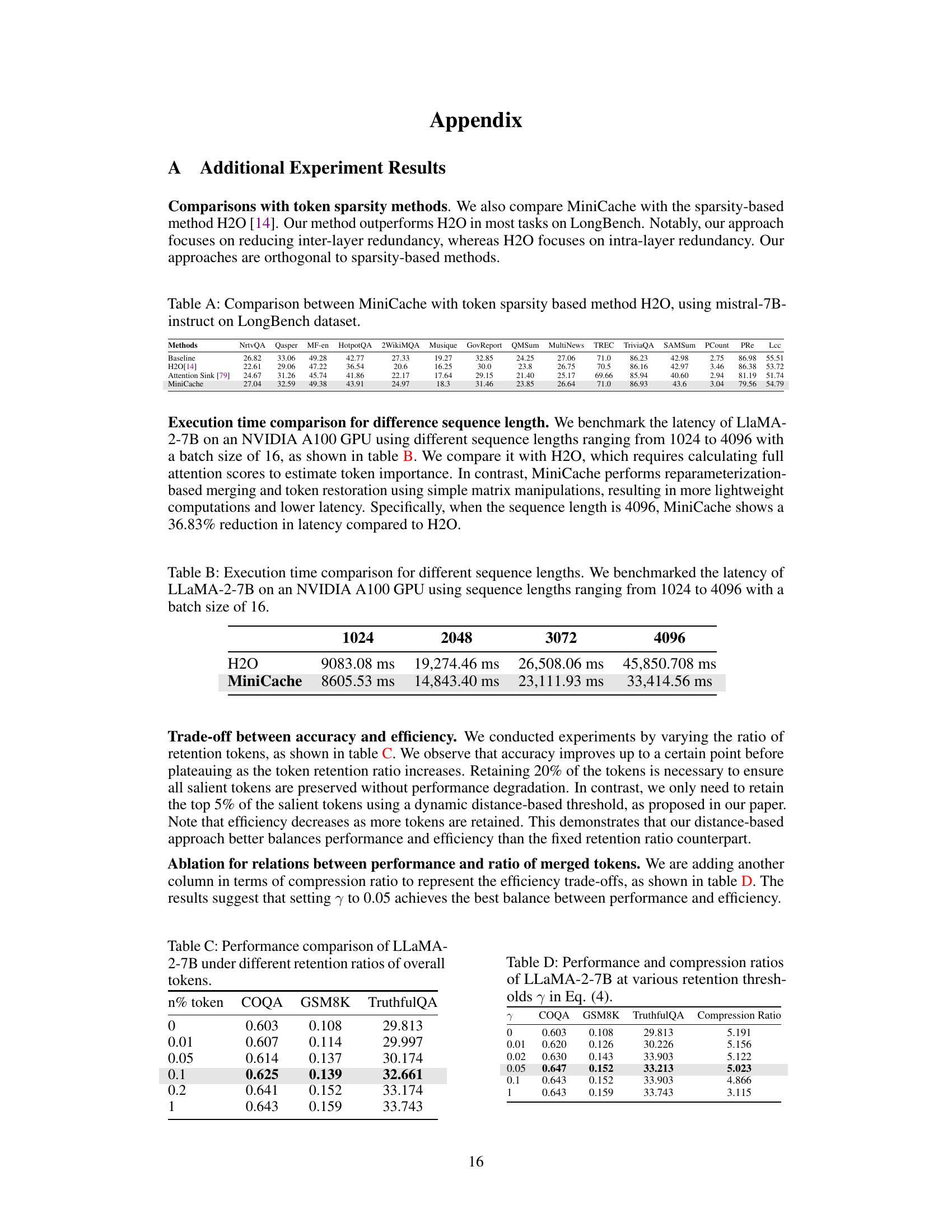
This table shows the performance of LLaMA-2-7B on three benchmark datasets (COQA, GSM8K, TruthfulQA) using different token retention thresholds (γ). The retention threshold controls how many tokens are kept during the merging process, balancing compression ratio and performance. The results show a tradeoff: Increasing γ improves performance but reduces compression. The optimal value seems to be around 0.05, offering a good balance between the two factors.

This table compares the performance of MiniCache against H2O (a token sparsity method) and Attention Sink on the LongBench dataset using the Mistral-7B-instruct model. It shows the exact match scores or BLEU scores across multiple question answering and summarization tasks to demonstrate MiniCache’s performance in comparison to other state-of-the-art approaches.

This table compares the execution time of the H2O method and MiniCache method for different sequence lengths (1024, 2048, 3072, and 4096 tokens) with a batch size of 16 using an NVIDIA A100 GPU. It demonstrates the latency reduction achieved by MiniCache compared to H2O, highlighting the efficiency improvements gained through the MiniCache’s lightweight computations and matrix manipulations.

This table presents the results of experiments evaluating the performance of the LLaMA-2-7B model under various retention ratios. It shows the impact of keeping different percentages of tokens on the model’s performance across three datasets: COQA, GSM8K, and TruthfulQA. The exact match scores and BLEU scores (for TruthfulQA) are reported for different retention ratios (0%, 0.01%, 0.05%, 0.1%, 0.2%, and 1%) illustrating the trade-off between model accuracy and the number of tokens retained (memory efficiency).

This table presents a comparison of the performance of LLaMA-2-7B across three benchmark datasets (COQA, GSM8K, TruthfulQA) while varying the token retention threshold (γ). The token retention threshold influences how many tokens are retained during merging which affects the final compression ratio. The table shows that a token retention threshold (γ) of 0.05 provides the best balance between performance and compression, achieving the highest compression ratio of 5.023x while maintaining relatively high scores on all three benchmarks.

This table presents a benchmark of the computational overhead of different components within the reparameterization and restoration stages of the MiniCache algorithm using the LLaMA-2-7B model. It breaks down the running times (in milliseconds) and standard variations for the magnitude, direction, distance calculation, token replacement, and overall attention computation. The results highlight that the computational overhead of the reparameterization and restoration processes is negligible compared to the overall attention computation.
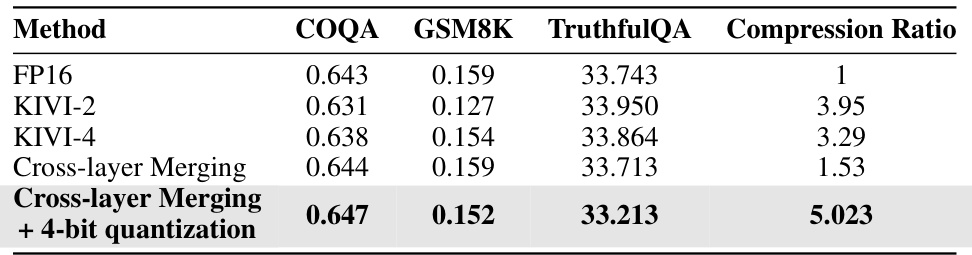
This table compares the performance (Exact Match scores on COQA, GSM8K, and TruthfulQA datasets) and compression ratios of different KV cache compression methods: FP16 (full precision), KIVI-2 (2-bit quantization), KIVI-4 (4-bit quantization), Cross-layer Merging (MiniCache without quantization), and Cross-layer Merging + 4-bit quantization. It highlights that MiniCache’s cross-layer merging is orthogonal to existing quantization techniques and shows the combined effect of both techniques. The compression ratios are relative to the FP16 baseline.

This table compares the performance of three different cross-layer merging strategies: Average, Max Norm, and SLERP, across three datasets (COQA, GSM8K, and TruthfulQA). The results show that SLERP consistently outperforms the other two strategies, indicating its superior effectiveness in merging KV cache states while preserving performance.
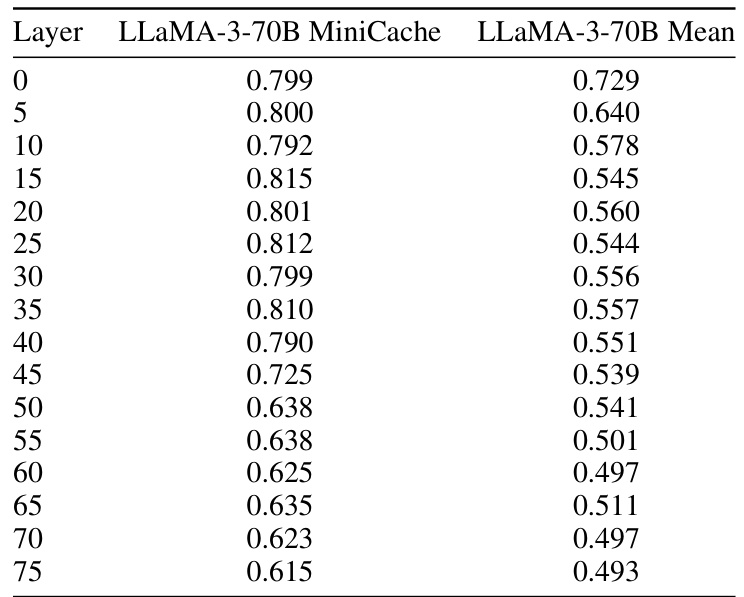
This table presents a detailed comparison of the performance of LLaMA-3-70B with and without MiniCache on the GSM8K dataset. The results are broken down by layer, showing the Exact Match (EM) score for both the baseline LLaMA-3-70B model and the model enhanced with MiniCache. This allows for a layer-by-layer analysis of the effectiveness of MiniCache in improving performance.

This table presents a detailed comparison of the performance of the LLaMA-3-70B model with and without MiniCache on the COQA dataset. It shows the exact match scores for both methods across different layers of the model, allowing for an assessment of the impact of MiniCache on performance at varying depths.
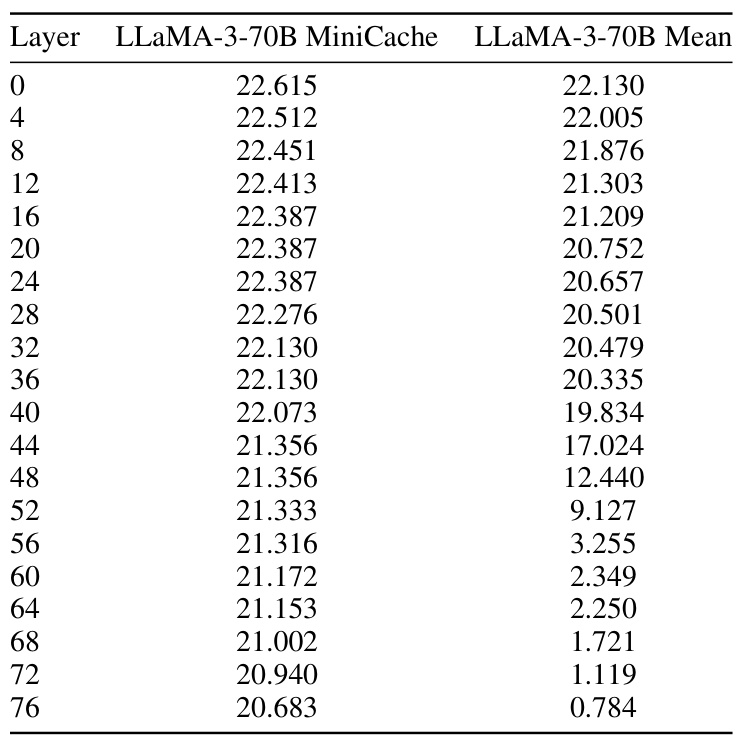
This table presents a detailed performance comparison of the LLaMA-3-70B model on the TruthfulQA dataset, broken down by layer. It shows the exact match scores achieved by both the standard LLaMA-3-70B model and the MiniCache-enhanced version, allowing for a layer-by-layer analysis of the impact of MiniCache on performance. The ‘Mean’ column likely represents the average performance across all layers.

This table presents a detailed comparison of the performance of the LLaMA-3-8B model on the GSM8K dataset, comparing the model’s performance using the MiniCache technique against its performance using a simple averaging method. It shows the exact match scores for both methods across various layers of the model, providing a layer-by-layer analysis of performance differences between the two methods.
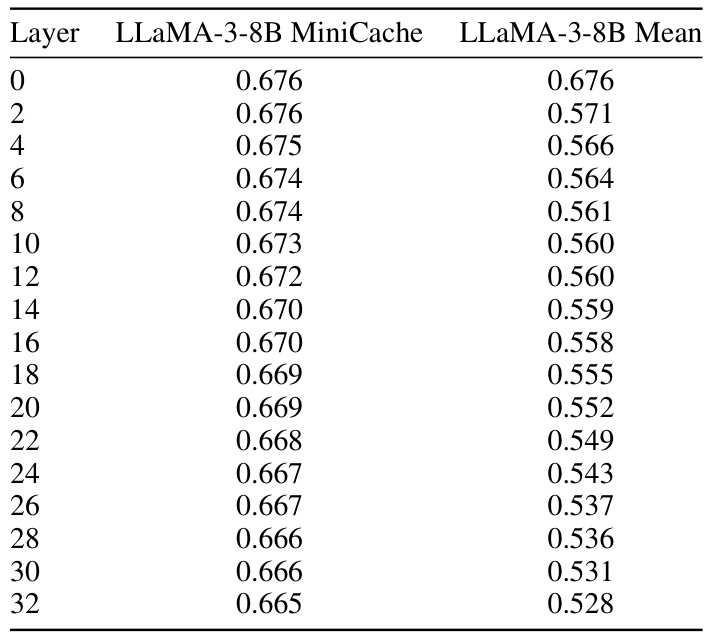
This table presents a detailed comparison of the performance of the LLaMA-3-8B model with and without the MiniCache technique on the COQA dataset. It shows the exact match scores for each layer of the model, allowing for a layer-by-layer analysis of the impact of MiniCache on performance. The comparison includes scores for the baseline LLaMA-3-8B model, the LLaMA-3-8B model using MiniCache, and the mean score across all layers for the MiniCache model.
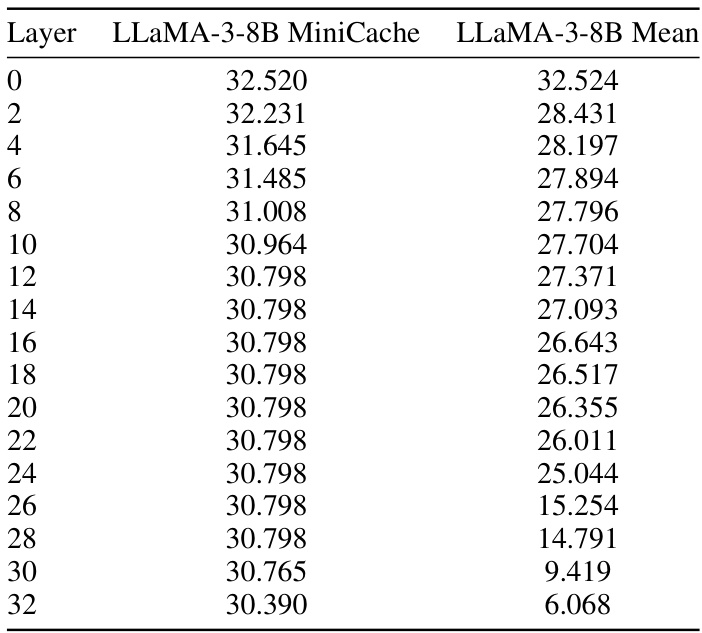
This table presents a detailed comparison of the performance of the LLaMA-3-70B model with and without MiniCache on the GSM8K dataset. It shows the Exact Match (EM) scores for both methods across different layers of the model. The ‘MiniCache’ column represents the performance achieved by applying the MiniCache compression technique. The ‘LLaMA-3-70B Mean’ column indicates the average EM score across all layers. The table allows for a layer-by-layer analysis of the impact of MiniCache on the model’s performance.
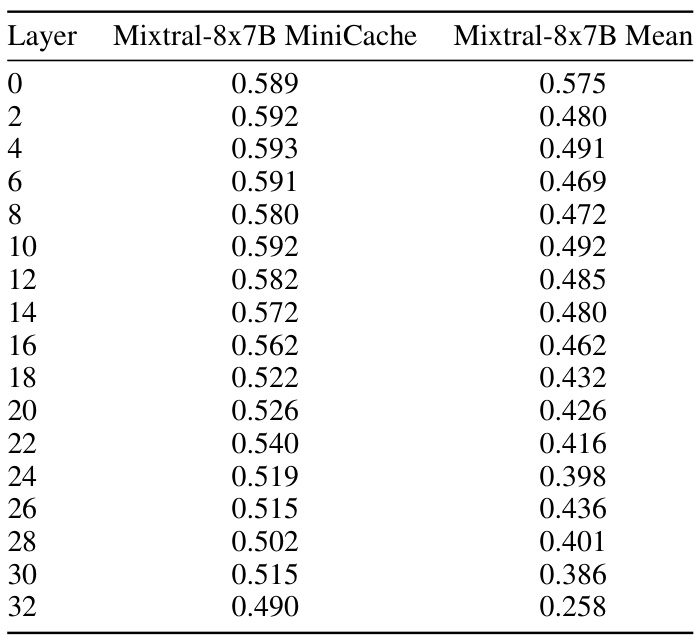
This table presents a detailed comparison of the performance of the Mixtral-8x7B model on the GSM8K dataset, comparing the full cache baseline, the simple average method, and MiniCache. For each method, the exact match score is shown for different layers (0-32) of the model.

This table presents a detailed comparison of the performance of the Mixtral-8x7B model on the COQA dataset, broken down by layer. It shows the performance of the full model (Mixtral-8x7B Mean), the model using MiniCache, and the difference between the two. This allows for a layer-by-layer analysis of how MiniCache impacts performance.
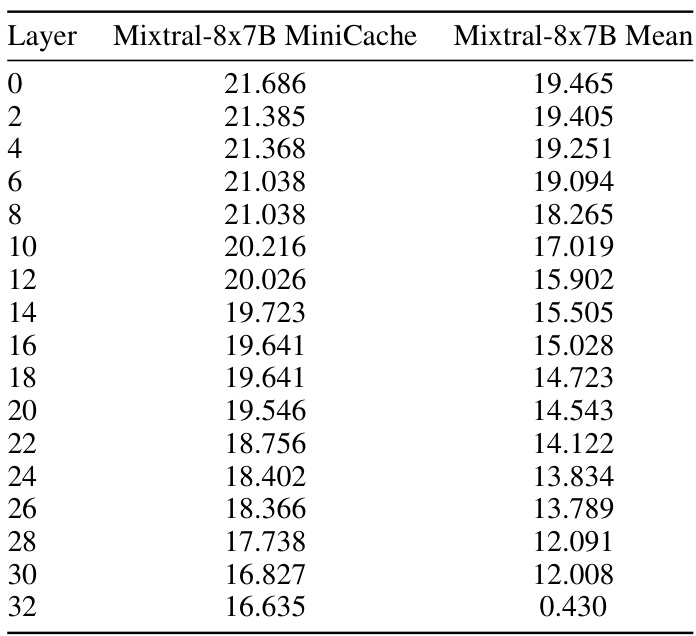
This table presents a detailed comparison of the performance of the Mixtral-8x7B model on the GSM8K dataset, showing the results for both the MiniCache method and a baseline approach (simple average). It breaks down the results by layer, indicating the exact match scores obtained at each layer. This allows for a layer-by-layer analysis of the impact of MiniCache on model performance.
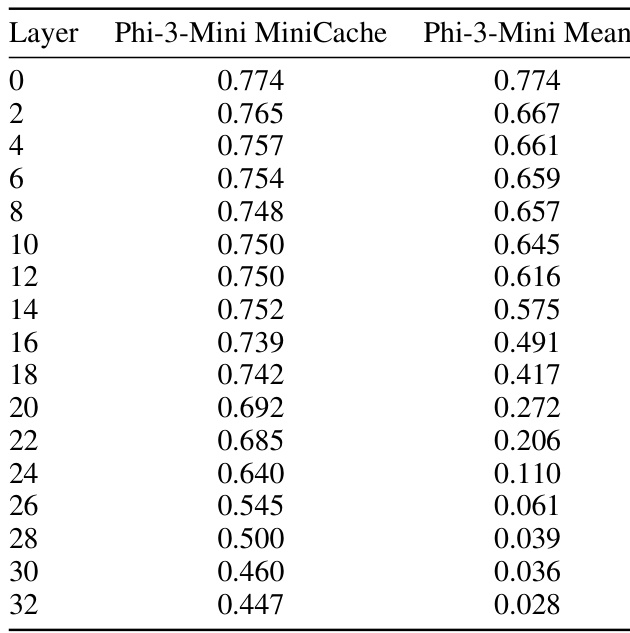
This table presents a detailed comparison of the performance of the Phi-3-Mini model with and without the MiniCache technique on the GSM8K dataset. It shows the EM score for both methods across different transformer layers (0-32). The data illustrates the performance degradation when merging layers, particularly in deeper layers. This provides quantitative evidence to support the paper’s claims regarding the effectiveness of the MiniCache method in preserving performance while achieving compression.

This table presents a detailed comparison of the performance of the Phi-3-Mini model and the MiniCache technique on the COQA dataset. It shows the exact match scores achieved by each method at various layers of the model. This allows for a layer-by-layer analysis of the impact of MiniCache on the performance of Phi-3-Mini on this specific dataset.

This table presents a detailed breakdown of the performance comparison between the Phi-3-Mini model and the MiniCache method on the TruthfulQA dataset. It shows the performance scores for each model at different layers of the model. The ‘Phi-3-Mini Mean’ column shows the average performance score across the layers for the Phi-3-Mini model.
Full paper#