↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current hairstyle transfer methods are either slow (optimization-based) or produce low-quality results (encoder-based). This limits the usability of such technologies in interactive applications such as virtual try-on. The need for a fast and high-quality approach is evident, especially when dealing with variations in poses and diverse hairstyle attributes. These limitations highlight the importance of developing a more efficient and robust system.
HairFastGAN is proposed as a novel solution leveraging an encoder-based architecture that operates in the StyleGAN’s FS latent space. It incorporates a unique pose alignment module, enhanced inpainting, and improved color transfer techniques. The method achieves high-resolution, near real-time performance, surpassing state-of-the-art approaches in terms of both speed and image quality. This is demonstrated through comprehensive evaluations on standard realism metrics, showing significant improvement, particularly in challenging scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it presents HairFastGAN, a novel and efficient approach to hairstyle transfer that significantly outperforms existing methods in terms of speed and quality. This has important implications for virtual try-on applications and other areas requiring realistic hair manipulation in images. The open-source code and detailed experimental results also facilitate further research in this area.
Visual Insights#

This figure demonstrates the HairFastGAN method’s ability to transfer hairstyles realistically and efficiently. The left side shows the input face image, the desired hair shape, and the desired hair color. The result of applying the HairFastGAN method is shown in the ‘Result’ section. The right side provides a runtime comparison chart (seconds) of HairFastGAN against other state-of-the-art methods, highlighting its speed and superior performance. The chart uses FIDCLIP as a metric to evaluate the realism of the generated images.
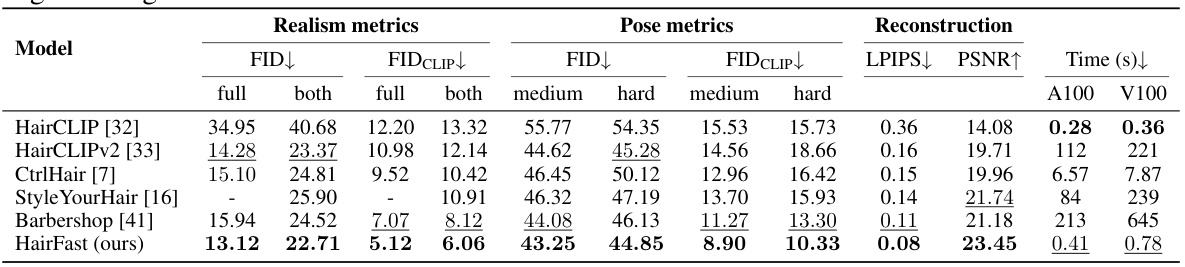
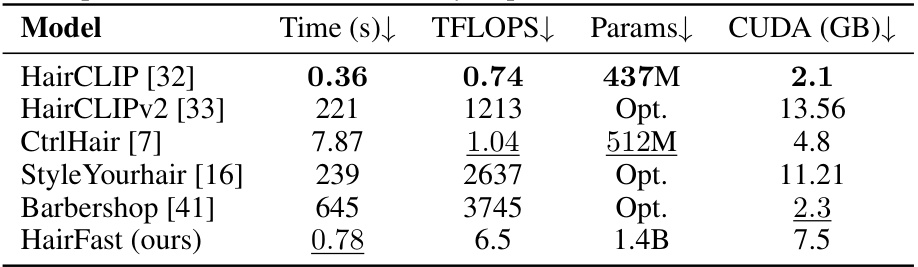
This table presents a quantitative comparison of HairFastGAN against other state-of-the-art hair transfer methods. It evaluates performance across several metrics: FID (Fréchet Inception Distance), FIDCLIP (a FID variant using CLIP), LPIPS (Learned Perceptual Image Patch Similarity), PSNR (Peak Signal-to-Noise Ratio), and runtime. The metrics are broken down into three categories: realism (how realistic the generated hair looks), pose (how well the method handles different head poses), and reconstruction (how well the model reconstructs the original hairstyle when transferring to itself).
In-depth insights#
Fast Hair Transfer#
The concept of “Fast Hair Transfer” in the context of AI-powered image manipulation is intriguing. It suggests a system capable of seamlessly and quickly altering an individual’s hairstyle in a digital image. Speed is a critical factor, suggesting the use of efficient algorithms and potentially encoder-decoder architectures, as opposed to slower iterative optimization methods. Realism is paramount; the transferred hair should blend naturally with the subject’s face and background, avoiding artifacts or unnatural appearances. A successful “Fast Hair Transfer” system would likely leverage advances in Generative Adversarial Networks (GANs) and StyleGAN architectures, possibly operating in latent spaces to directly manipulate hair features while preserving face identity. Robustness to pose variations is essential; the system should ideally handle images with varying head positions and orientations without compromising the quality of the hair transfer. The successful application of such technology could have significant implications for virtual try-ons, character creation in virtual reality, and digital content creation.
Encoder-Based GAN#
Encoder-based GANs represent a significant advancement in generative modeling, offering a streamlined approach to image manipulation compared to traditional GAN architectures. By directly mapping input images to the latent space of a pre-trained generator, they bypass the computationally expensive optimization processes often required for image-to-image translation tasks, such as hairstyle transfer or face editing. This results in faster inference times, a crucial advantage for interactive applications. However, encoder-based methods also present challenges. The accuracy of the latent space mapping is critical, as inaccuracies can lead to artifacts or poor reconstruction quality. Furthermore, handling variations in pose or lighting in input images remains a complex issue, as it can severely impact the fidelity of the latent space representation. The choice of latent space (e.g., StyleGAN’s W+ or FS space) significantly impacts the trade-off between editing capability and reconstruction quality. Advanced encoder-based GANs often employ strategies like multi-stage encoders and incorporate additional losses (e.g., perceptual losses, CLIP embeddings) to improve realism and controllability. Despite these advances, research continues to address limitations in preserving fine details, handling complex poses, and ensuring high-fidelity reconstruction in a computationally efficient manner. The development of more robust and versatile encoders remains a key area of focus for future research in this exciting field.
Pose & Color Align#
In a hypothetical research paper section titled ‘Pose & Color Align’, the core concept would involve aligning the pose and color of a source image with a target image for a specific task, likely image manipulation or transfer. Pose alignment would address differences in head orientation and position, aiming for consistent posture between images, potentially using techniques like facial landmark detection and image warping. Color alignment would tackle discrepancies in lighting, shadows, and overall color palette, ensuring color harmony between the source and target. The integration of both methods implies a complex process involving multiple steps; a pose estimation step followed by a color transformation. Successful alignment requires robust image processing and sophisticated algorithms, accounting for variations in image quality and preventing artifacts. Achieving a seamless integration of pose and color transformations without distorting the original image would be a crucial challenge. The effectiveness of this ‘Pose & Color Align’ would significantly impact downstream tasks. This section would likely present metrics such as structural similarity, color difference metrics, and execution time to evaluate performance.
Ablation Study#
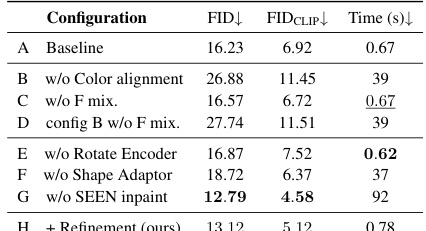
An ablation study systematically removes components of a model to understand their individual contributions. In this case, it helps determine the impact of each module (Pose Alignment, Shape Alignment, Color Alignment, and Refinement Alignment) in the HairFastGAN architecture. By progressively disabling modules, researchers can isolate the effect of each part on the model’s performance. The results from an ablation study could reveal that certain components are crucial for achieving high quality hair transfer, while others might be less important or even detrimental. Key insights gained could inform future model design, potentially leading to a more efficient or robust system by removing unnecessary complexities. The ablation study also helps evaluate the effectiveness of novel techniques introduced in the paper. By comparing the performance of the full model against variants with specific modules removed or replaced with simpler alternatives, the researchers can quantitatively assess the advantages of their proposed design choices. For example, evaluating whether the novel pose alignment module significantly improves results. Ultimately, the ablation study provides a detailed understanding of the HairFastGAN’s inner workings and validates the importance of individual components to the overall system’s success.
Future Work#
The ‘Future Work’ section of this research paper on HairFastGAN presents exciting avenues for improvement and expansion. Improving the model’s handling of complex hairstyles (like braids and ponytails) is crucial, as current performance in these areas is limited. Addressing the challenges of cross-domain transfer – applying hairstyles from cartoon or artistic styles to realistic images – could significantly broaden the application of the technology. Developing more robust metrics for evaluating hairstyle realism and transfer quality is another key area. The current FID and FID-CLIP metrics, while useful, do not fully capture the nuances of human perception, and more comprehensive assessment techniques would advance the field. Finally, exploring more sophisticated user interaction methods is vital for practical applications. Enhancing the flexibility and control provided to users will enable more creative and precise hairstyle editing capabilities, making HairFastGAN an even more powerful tool for virtual try-ons and image manipulation.
More visual insights#
More on figures

This figure shows a detailed breakdown of the HairFastGAN model’s architecture. Panel (a) illustrates the mixing block, which combines features from the FS and W+ latent spaces of StyleGAN to enable color adjustments to the hair. Panel (b) details the Pose and Shape alignment modules which, using encoders, generate the pose-aligned hair mask and then modify the F tensor in StyleGAN’s latent space to transfer the new hair shape.
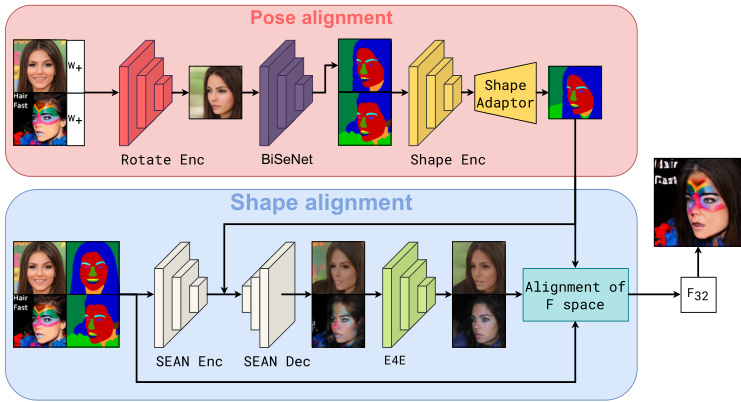
This figure provides a visual overview of the HairFast model’s pipeline. It details the four main modules: Pose alignment, Shape alignment, Color alignment, and Refinement alignment. Each module plays a crucial role in transferring the hairstyle from a reference image to an input image, accounting for pose differences and maintaining high-resolution details.

This figure showcases the HairFastGAN model’s ability to realistically transfer hair styles. The left side demonstrates the input face, desired hair shape and color, and the resulting hair transfer. The right-hand side provides a comparison of HairFastGAN’s performance against other state-of-the-art models based on FID and runtime.

This figure showcases the HairFastGAN model’s ability to realistically transfer hairstyles. The left side demonstrates the process, starting with input images of a face, desired hair shape, and color, culminating in a final image with the transferred hairstyle. The right side shows a runtime comparison of HairFastGAN against other methods, highlighting its speed and image quality.

This figure shows the results of HairFastGAN, a novel method for realistic and robust hair transfer. The left side demonstrates the hair transfer process: given a face image, a desired hair shape, and a hair color, HairFastGAN generates a new image with the transferred hairstyle. The right side displays a comparison of HairFastGAN’s performance against other state-of-the-art methods in terms of runtime and image quality, highlighting HairFastGAN’s efficiency and realism.
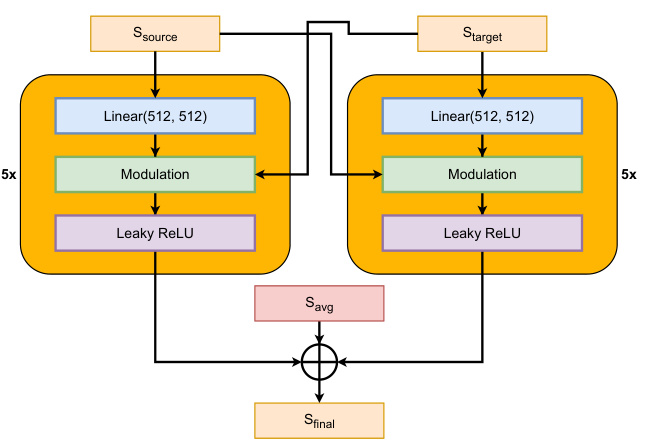
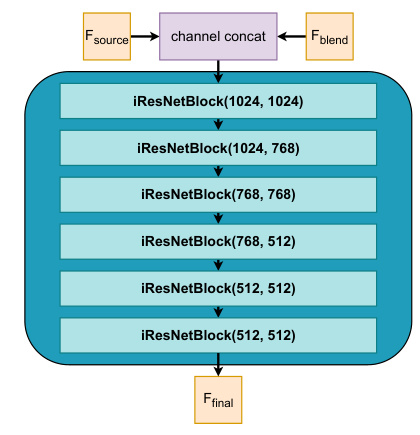
This figure shows the architecture of the two fusing encoders used in the Refinement alignment stage of the HairFast model. The left-hand side (a) illustrates the modulation architecture for fusing S spaces (StyleGAN’s style vectors), using a series of linear layers, modulation, and leaky ReLU activations. The right-hand side (b) depicts the architecture for fusing F spaces (StyleGAN’s feature vectors), which employs IResNet blocks. Both architectures take multiple input vectors and combine them to produce a final output vector (Sfinal and Ffinal respectively).
This figure shows a detailed diagram of the HairFastGAN architecture. Panel (a) illustrates the ‘Mixing Block,’ which combines StyleGAN’s FS and W+ latent spaces to enable flexible hair color editing. Panel (b) details the Pose and Shape alignment modules. The Pose alignment module generates a pose-aligned mask using a rotate encoder and BiSeNet, ensuring consistent hair placement regardless of pose. The Shape alignment module then transfers the desired hairstyle shape by modifying StyleGAN’s F tensor, leveraging a SEAN inpainting model for realistic hair integration.

This figure compares the results of different hair transfer methods on various scenarios, including transferring hair color and shape together or separately. The authors highlight that their method (HairFastGAN) best preserves the source image’s identity and produces more realistic hair color and texture, especially when dealing with significant differences in pose between source and target images.

This figure compares the results of HairFastGAN against other state-of-the-art hair transfer methods. It demonstrates the visual quality of hair and color transfer, showcasing how HairFastGAN better preserves facial identity and achieves more realistic results across different scenarios including complex poses and separate or combined shape/color transfer.

This figure shows the results of experiments on cross-domain hair transfer, where the target hairstyles come from various sources, including cartoons and anime styles. The results demonstrate the robustness of HairFastGAN in handling such diverse inputs, highlighting its ability to adapt to different image styles and maintain a good quality of the generated results.

This figure demonstrates the HairFastGAN model’s ability to realistically transfer hair styles. The left side shows the input face, desired hair shape and color. The right side shows the results of HairFastGAN, along with a comparison of its runtime performance against other state-of-the-art models.

This figure showcases the HairFastGAN model’s ability to realistically transfer hairstyles. It demonstrates the process: input face, desired hair shape and color are used to generate a resulting image with the transferred hairstyle. A comparative graph highlights HairFastGAN’s superior performance against other methods, showcasing its speed and realism.

This figure demonstrates the HairFastGAN model’s ability to realistically and robustly transfer hairstyles in near real-time. The left side shows the process: a face image is combined with a desired hair shape and color to produce a final image with the transferred hairstyle. The right side provides a runtime comparison chart of HairFastGAN against other state-of-the-art methods, highlighting its speed advantage while maintaining high image quality.

This figure compares the visual results of different hair transfer methods on various scenarios. The methods are compared based on their ability to transfer hair color and shape, both individually and simultaneously, while preserving the identity of the original face and handling different pose differences. The authors’ method (HairFastGAN) is highlighted as producing more realistic and accurate results, especially when dealing with complex poses.

This figure shows a visual comparison of HairFastGAN against several state-of-the-art methods for hair transfer. The comparison is performed on images with various levels of difficulty, including those with detailed facial skin textures, objects or jewelry on the face, and complex backgrounds. This demonstrates the robustness and performance of HairFastGAN in challenging scenarios.

This figure showcases the HairFastGAN model’s ability to realistically transfer hair styles and colors onto input face images. The left side shows the input face, desired hair shape and color, and the resulting image with the transferred hairstyle. The right side provides a runtime comparison of HairFastGAN with other state-of-the-art methods, highlighting its superior speed and realism.
More on tables
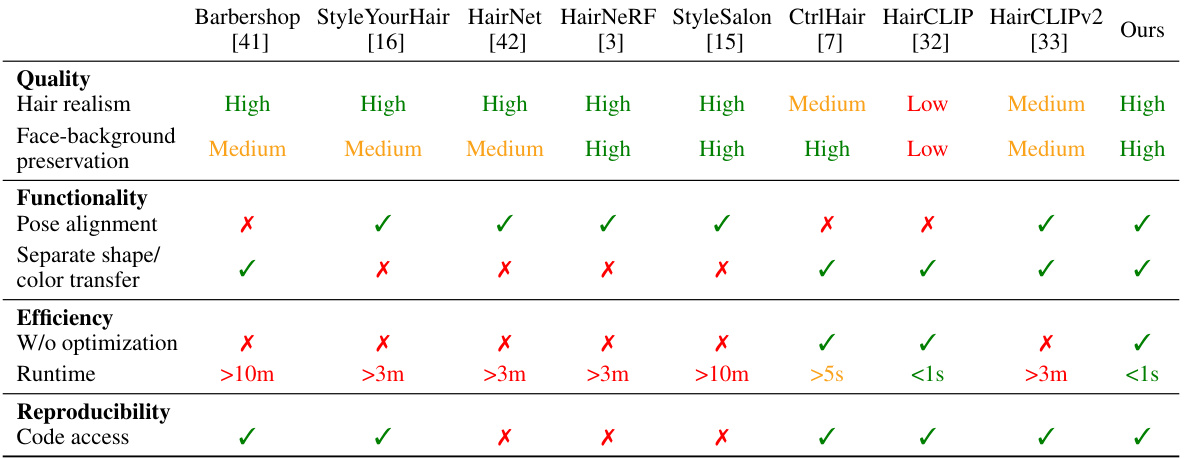
This table provides a comparative overview of several state-of-the-art hair transfer methods, including the proposed HairFastGAN. The comparison is structured into four categories: Quality (hair realism and face-background preservation), Functionality (pose alignment and separate shape/color transfer capabilities), Efficiency (optimization-based vs. encoder-based, and runtime), and Reproducibility (code accessibility). Each method is rated for each characteristic, with checkmarks indicating the presence or absence of a specific feature, and runtime estimates provided.
This table presents a quantitative comparison of HairFastGAN against other state-of-the-art hair transfer methods. It evaluates performance across various metrics, including FID and FIDCLIP (to assess image quality), LPIPS and PSNR (for perceptual similarity and reconstruction fidelity), and runtime. The comparison is done for various scenarios of hair transfer: full transfer (shape and color from different images), only shape change, only color change, and both shape and color from the same image. The table also includes pose-dependent metrics broken down into difficulty levels, and reconstruction metrics measuring how well each model can reconstruct the original hairstyle after transferring it.
This table presents a comparison of different hair transfer methods across various metrics, including realism (FID, FIDCLIP, LPIPS, PSNR), pose transfer difficulty (easy, medium, hard), and reconstruction quality. The metrics evaluate the quality and speed of hairstyle transfer, considering both individual attribute changes (color, shape) and combined changes.

This table presents a comparison of different hair transfer methods using various realism metrics such as FID and FIDCLIP, pose transfer metrics (categorized by difficulty levels), and reconstruction metrics. Lower FID and FIDCLIP scores indicate better image realism. The runtime is also provided for different GPU configurations. Reconstruction metrics evaluate the models’ ability to reconstruct the original hairstyle after transfer.
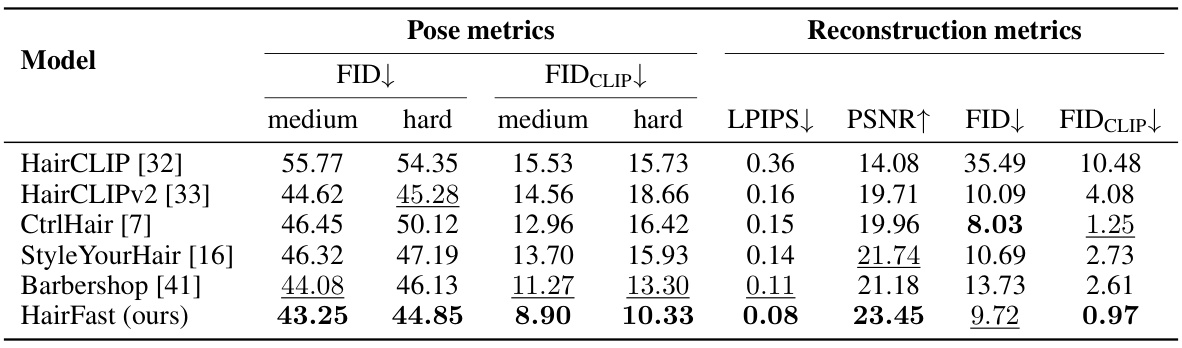
This table presents quantitative results comparing HairFastGAN against other state-of-the-art hair transfer methods. Metrics include FID, FIDCLIP, LPIPS, PSNR, and runtime, evaluated across various scenarios of hair transfer (transferring both color and shape from different images, shape only, color only, and both from the same image), pose difficulty (easy, medium, hard), and reconstruction (transferring the hairstyle to itself). Lower FID and FIDCLIP values indicate higher realism, while higher PSNR and LPIPS values represent better image quality. The runtime reflects the inference time.
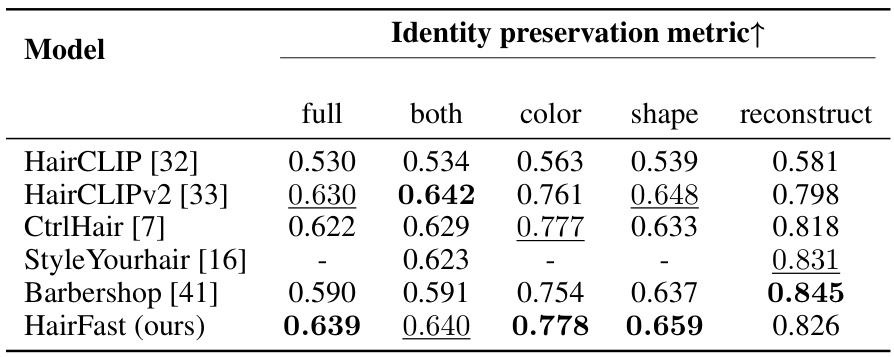
This table presents a quantitative comparison of HairFastGAN against other state-of-the-art hair transfer methods. It shows the FID, FID-CLIP, and LPIPS scores (lower is better for FID and FID-CLIP, higher is better for LPIPS) along with PSNR and runtime (seconds). Results are broken down by several conditions: full (transferring both shape and color from different images), both (transferring both shape and color from the same image), color (transferring color only), shape (transferring shape only). For pose metrics, performance is further categorized as easy, medium, and hard based on pose similarity. The reconstruction metrics evaluate the methods’ ability to reconstruct the original hairstyle after a transfer.
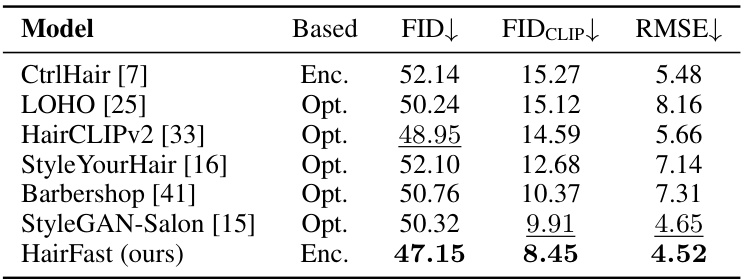
This table presents a comparison of different hair transfer methods using various metrics. It shows the FID, FID-CLIP, and LPIPS scores for each method, along with the PSNR and runtime. The table also breaks down the results based on the difficulty of the pose (easy, medium, hard), and includes metrics for reconstruction tasks where each method was evaluated on transferring its own hairstyle to itself.
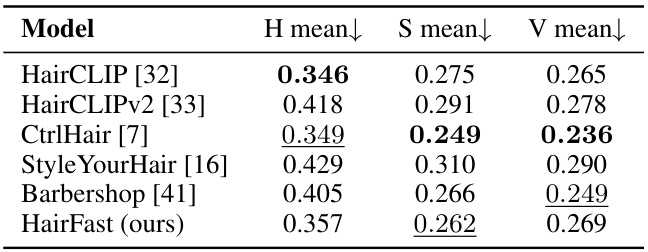
This table presents a quantitative comparison of HairFastGAN against other state-of-the-art hair transfer methods. It evaluates the realism of the generated images using FID and FID-CLIP scores, assesses the speed of each method, and analyzes their performance across different levels of pose difficulty (easy, medium, hard). It also includes reconstruction metrics, where each model attempts to transfer its hairstyle to itself, thus providing a measure of reconstruction accuracy.
Full paper#



















