↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Single image reflection separation (SIRS) is a critical but challenging task due to the complex entanglement of reflection and transmission layers, particularly in real-world scenarios. Existing dual-stream methods struggle with the intricate interaction between these layers and limited receptive fields, leading to unsatisfactory separation results.
The proposed Dual-Stream Interactive Transformer (DSIT) directly addresses these limitations. DSIT employs a novel dual-attention interaction mechanism to effectively capture both intra- and inter-layer feature correlations, solving the problem of limited receptive fields. Furthermore, it leverages pre-trained transformer embeddings, improving the model’s understanding of complex scenes and mitigating the ill-posed nature of the task. The extensive experimental results showcase DSIT’s superior performance over existing state-of-the-art methods, achieving significant improvements in accuracy and image quality, especially in complex scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the challenging problem of single image reflection separation, a crucial task in various fields like computer vision and autonomous driving. The proposed method, DSIT, significantly improves the accuracy and quality of reflection separation, particularly in complex scenarios. Its innovative dual-attention interaction mechanism and the integration of pre-trained transformers provide a valuable contribution to the field. This work opens new avenues for research in multi-layer image decomposition and other related applications.
Visual Insights#

This figure schematically illustrates three different dual-stream interactive mechanisms for single image reflection separation. (a) YTMT uses element-wise operations and a fusion process for interaction between transmission and reflection layer features. (b) MuGI also employs a fusion process, but the interaction is more direct. (c) The proposed DAI mechanism leverages dual-stream self-attention and cross-attention to explicitly capture both intra-layer and inter-layer feature correlations, offering a more sophisticated interaction strategy.

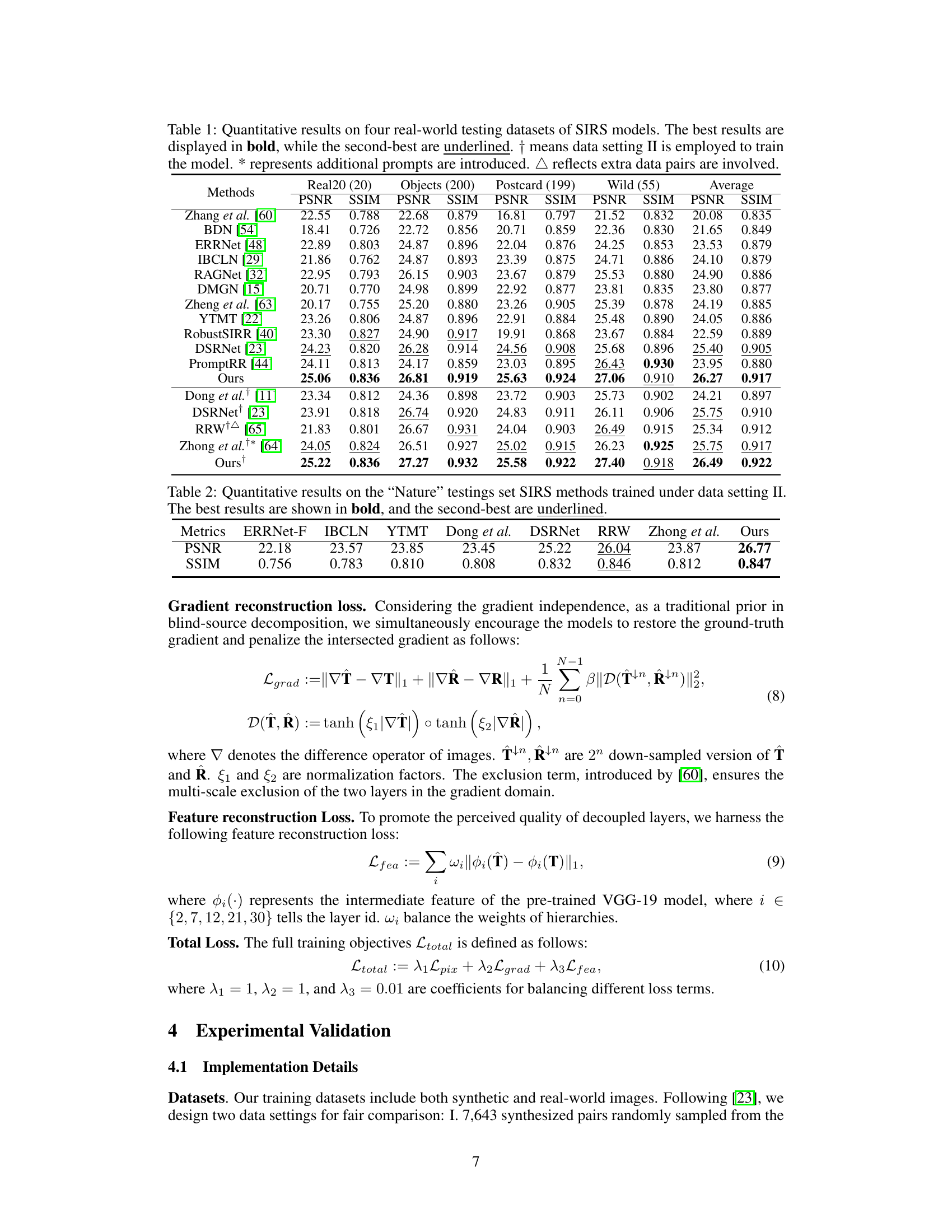
This table presents a quantitative comparison of various Single Image Reflection Separation (SIRS) models on four real-world datasets: Real20, Objects, Postcard, and Wild. The metrics used are PSNR and SSIM, which assess the quality of the transmission layer separation. The table highlights the best-performing model for each dataset and metric, indicating the superior performance of the proposed ‘Ours’ method compared to existing state-of-the-art approaches. Notes are included to clarify specific training conditions and data augmentation techniques used by certain methods.
In-depth insights#
Dual-Stream SIRS#
Dual-stream Single Image Reflection Separation (SIRS) methods aim to tackle the challenging task of separating superimposed transmission and reflection layers from a single image. Unlike single-stream approaches that treat reflection as noise, dual-stream methods leverage the valuable information present in both layers, simultaneously estimating both transmission and reflection components. This approach is inherently more complex but offers the potential for significantly improved accuracy and quality in reflection separation. However, existing dual-stream methods face limitations. A key challenge lies in effectively capturing the inter-layer correlations, which are crucial for disentangling the intertwined features of transmission and reflection. Limited receptive fields of traditional architectures also hinder the performance of these models. Future research in dual-stream SIRS should focus on developing novel interaction mechanisms that efficiently capture these correlations, addressing the limited receptive field problem, and exploring more robust loss functions to handle the inherent ill-posed nature of the problem. Furthermore, advancements in deep learning architectures, such as transformers, hold significant promise for improving the performance and efficiency of dual-stream SIRS methods. Ultimately, the goal is to achieve a high-fidelity separation of transmission and reflection layers under diverse and challenging conditions, paving the way for improved applications in various domains such as autonomous driving and image editing.
Transformer Fusion#
Transformer fusion, in the context of a research paper, likely refers to methods that integrate information from multiple Transformer models or layers. This might involve techniques like attention mechanisms to weigh the importance of different sources, concatenation to combine feature vectors from different Transformers, or more complex strategies such as gated fusion allowing for conditional selection of information. The goal of such fusion is often to leverage the strengths of different Transformer architectures or to incorporate various levels of abstraction into a unified representation. For instance, one Transformer may focus on local features while another captures global context; fusion could then combine this information for improved accuracy and robustness. Effective fusion is crucial for managing computational complexity and for achieving a balance between preserving the unique properties of each source and combining them meaningfully for downstream tasks.
DAIE’s Role#
The Dual-Architecture Interactive Encoder (DAIE) plays a pivotal role in this single image reflection separation method. It acts as a bridge, effectively integrating global semantic information from a pre-trained Transformer model with localized, dual-stream features extracted using a CNN. This fusion of global and local context is crucial because it addresses the inherent ill-posed nature of the reflection separation problem. The DAIE’s design facilitates cross-architecture interactions (CAI) which leverages the strengths of both the Transformer’s ability to capture long-range dependencies and the CNN’s proficiency in local feature extraction. The outcome is a more robust and accurate separation of transmission and reflection layers, enabling the subsequent modules to perform better. In essence, the DAIE enhances the model’s generalization and precision, particularly in challenging scenarios involving complex reflections and varying scene conditions. This innovative approach highlights the potential benefits of blending different network architectures to tackle under-constrained inverse problems.
Ablation Study#
An ablation study systematically removes or alters components of a model to understand their individual contributions. In the context of a reflection separation model, this might involve removing attention mechanisms, varying the depth or width of the network, or changing the type of feature extraction. Key insights are gained by comparing the performance of the full model to the models with specific components removed. This helps determine which parts are essential for good performance and which are less crucial or even detrimental. A well-designed ablation study isolates the effects of each component, leading to a better understanding of the model’s architecture and how different parts interact to achieve the final results. The results inform design choices for future model iterations by indicating areas for improvement or simplification. Furthermore, it can help to identify unexpected interactions between components, potentially highlighting areas where further investigation is needed.
Future Works#
Future research directions stemming from this single image reflection separation (SIRS) study could involve exploring more sophisticated interaction mechanisms within dual-stream networks to better capture complex inter-layer correlations. Incorporating advanced global context modeling techniques, like larger vision foundation models, could significantly improve the accuracy and robustness of reflection removal, particularly in challenging scenarios. Furthermore, research into more effective ways to handle ambiguous or weakly defined reflection regions is crucial. Finally, developing a more comprehensive loss function that considers both perceptual quality and physical accuracy of the separated layers would enhance the overall performance of SIRS models, and investigating the applications of SIRS in other image decomposition tasks such as watermark removal, could provide further valuable insights.
More visual insights#
More on figures

This figure shows the overall architecture of the proposed Dual-Stream Interactive Transformer (DSIT) and a detailed illustration of its Dual-Attention Interactive Block (DAIB). The DSIT consists of two main components: a Dual-Architecture Interactive Encoder (DAIE) and a Dual-Stream Interactive Decoder (DSID). The DAIE combines global and local feature extractors, injecting global priors into the dual-stream local features through cross-architecture interactions. The DSID then uses DAIBs to refine and aggregate dual-stream features, ultimately separating the transmission and reflection layers. The DAIB itself employs dual-stream self-attention and cross-attention mechanisms to capture both intra-layer and inter-layer feature correlations, enhancing the accuracy of reflection separation.

This figure visualizes the feature maps at the second level of the DSIT model for two different reflection-superimposed input images. It shows the local priors extracted by the CNN, the global priors from the pre-trained Transformer, how these are combined through cross-architecture interaction, and the resulting dual-stream features before and after passing through the Dual-Attention Interactive Blocks (DAIBs). The channel-wise averaging helps to better visualize the information flow and the effects of the different processing stages.

This figure presents a visual comparison of transmission layer predictions. It compares the results of several different single image reflection separation (SIRS) methods on two example images. The methods compared include several state-of-the-art techniques as well as the authors’ proposed method. The two example images are chosen to represent different difficulty levels in reflection separation. Highlighted areas showcase differences in results.

This figure shows a qualitative comparison of the transmission layer predictions of several state-of-the-art single image reflection separation (SIRS) methods and the proposed Dual-Stream Interactive Transformer (DSIT) method on real-world images. The images depict diverse scenes and reflection challenges, demonstrating the superior generalization capability of DSIT across various conditions.

This figure visualizes the different feature extractions at the second level of the proposed DSIT model. It shows the local priors from a CNN, global priors from a pre-trained Transformer, the features after cross-architecture interaction, and finally the features after the dual-attention interactive blocks. The visualization helps understand how the model integrates different types of information and refines features progressively.

This figure shows the visual results obtained using different variants of the Dual-Stream Interactive Transformer (DSIT) model. The variations tested include different global prior extractors (GPEs), cross-architecture interaction (CAI) methods, Dual-Attention Interactive Block (DAIB) designs, the inclusion or exclusion of layered relative position biases (LRPB), and the use or non-use of reflection mixup (RefMix) data augmentation. The results demonstrate the impact of each component on the model’s ability to accurately separate the reflection and transmission layers in a single image. The input image and the ground truth are shown for comparison.

This figure shows the results of the Reflection Mixup (RefMix) data augmentation technique used in the paper. RefMix adjusts the intensity of the reflection layer by blending the input image (I) and the transmission layer (T) at different ratios (γ). The series of images demonstrates how varying γ values from 0 to 1 affect the resulting image, enriching the training data with a wider range of reflection intensities.

This figure compares the transmission layer predictions of several state-of-the-art single image reflection separation (SIRS) models with the proposed DSIT model. Two examples are shown, one from the Real20 dataset and one from the SIR² dataset. The boxes highlight areas where the differences between the models are most apparent. The results demonstrate the superior performance of the proposed DSIT model in accurately reconstructing the transmission layer, especially in challenging cases with complex reflections.

This figure visualizes the different feature stages of the Dual-Stream Interactive Transformer (DSIT) model. It shows the local priors, global priors, and how they interact through cross-architecture interactions (CAI) and Dual-Attention Interactive Blocks (DAIBs). The visualization helps demonstrate the information flow and how the model progressively refines the features to achieve reflection separation. The features are averaged across channels for clearer display.

This figure shows a visual comparison of the transmission layer predictions from various state-of-the-art (SOTA) single image reflection separation (SIRS) methods and the proposed method (DSIT). The results are displayed for different models on a sample image from the SIR² dataset. The ground truth transmission layer is included for comparison, allowing for a qualitative assessment of the performance of each model in separating the transmission and reflection components of the superimposed image.

This figure shows a visual comparison of the reflection layer predictions from various state-of-the-art (SOTA) single image reflection separation (SIRS) models and the proposed model (DSIT). The results are presented for two different training data settings (I and II) of the DSIT model. The figure demonstrates that the proposed DSIT model produces more accurate and visually appealing results compared to other models for the task of separating reflection layers from images.

This figure compares the transmission layer predictions of various single image reflection separation (SIRS) methods, including the proposed DSIT model, on real-world images with diverse scenarios and reflection characteristics. It highlights the superior generalization capability of the DSIT model by demonstrating its effectiveness across different conditions.
More on tables

This table presents a quantitative comparison of different single image reflection separation (SIRS) methods on the ‘Nature’ dataset. The models were trained using data setting II, which is described in the paper. The metrics used for comparison are Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM). Higher values indicate better performance. The best performing method for each metric is highlighted in bold, and the second-best is underlined.
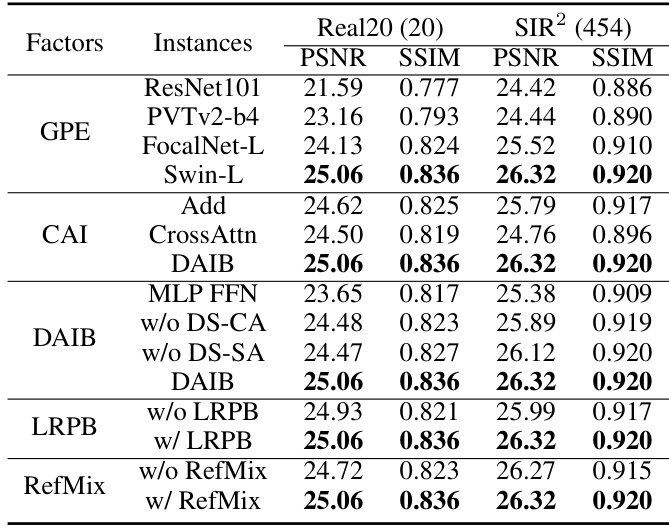
This table presents the ablation study results, evaluating the impact of different components of the proposed Dual-Stream Interactive Transformer (DSIT) model on the Real20 and SIR2 datasets. It shows the performance (PSNR and SSIM) variations when changing the global prior extractor (GPE), the cross-architecture interaction (CAI) method, the dual-attention interactive block (DAIB) components, whether layered relative position biases (LRPB) are used, and whether the reflection mixup (RefMix) data augmentation is applied. The results illustrate the contribution of each component to the overall performance.
Full paper#