↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing visual grounding and referring segmentation methods often rely on bulky transformer-based fusion and various interaction technologies. They also struggle to capture nuanced image-text relationships. This leads to complex architectures with many parameters and intricate processes. The current mask visual language modeling (MVLM) techniques fail to fully capture the needed nuanced referential relationships.
OneRef addresses these issues with a minimalist, modality-shared one-tower transformer, unifying visual and linguistic feature spaces. It introduces a novel MVLM paradigm called Mask Referring Modeling (MRefM), including referring-aware mask image and language modeling, and a dynamic image masking strategy. OneRef’s unified architecture enables direct regression of results without complex techniques, achieving state-of-the-art performance on various grounding and segmentation benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents OneRef, a novel and efficient framework for visual grounding and referring segmentation tasks. Its minimalist design, built upon a modality-shared one-tower transformer, simplifies existing complex architectures. The Mask Referring Modeling (MRefM) paradigm enhances the model’s ability to capture nuanced referential relationships, leading to state-of-the-art performance across multiple datasets. This work opens new avenues for future research in unified multimodal models and efficient transfer learning.
Visual Insights#
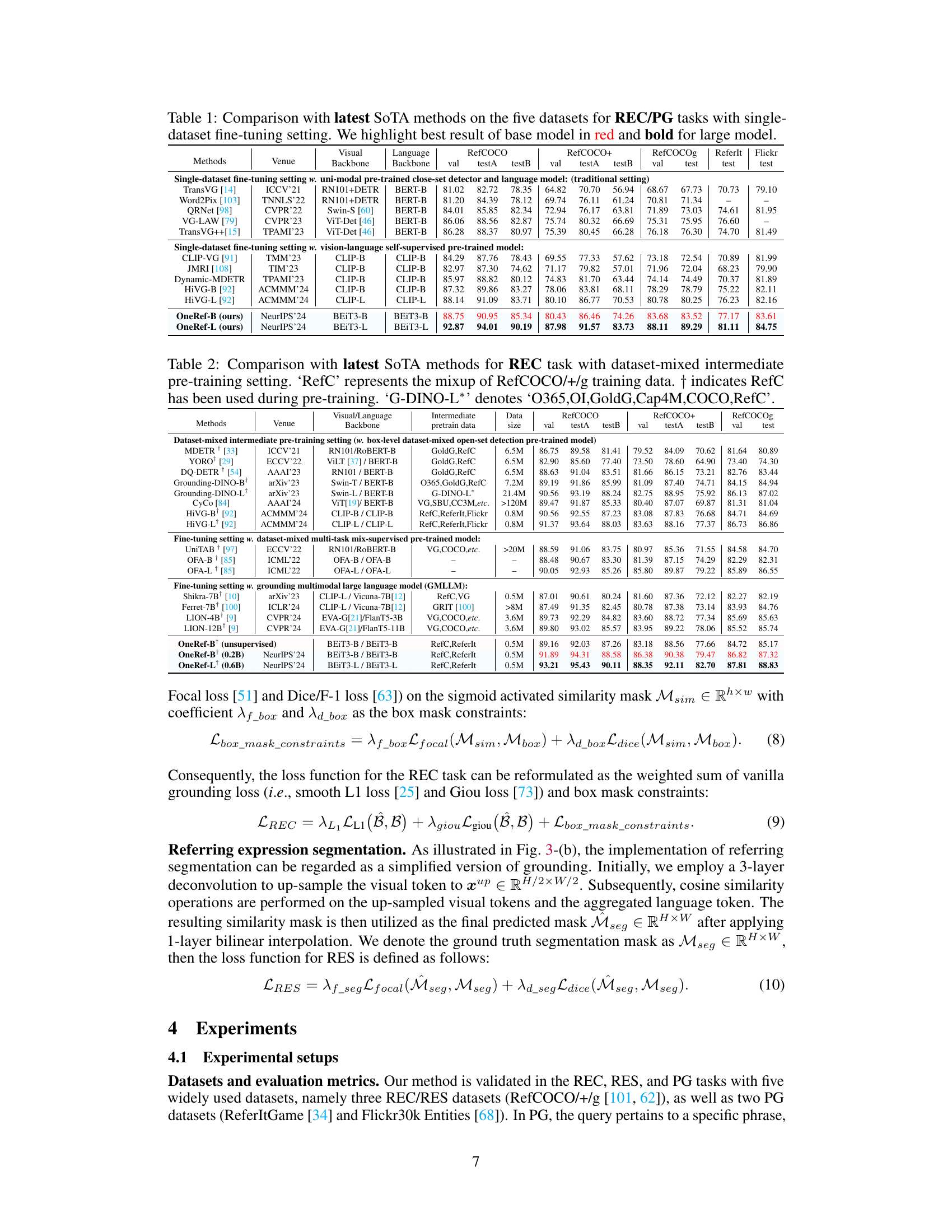
This figure compares the architecture of the proposed OneRef model with existing REC/RES architectures. It shows that existing models typically employ separate modality-dependent encoders (vision and language) with complex fusion mechanisms and often include decoders. In contrast, OneRef utilizes a unified modality-shared encoder, eliminating the need for complex fusion and interaction modules, resulting in a more efficient and concise architecture.
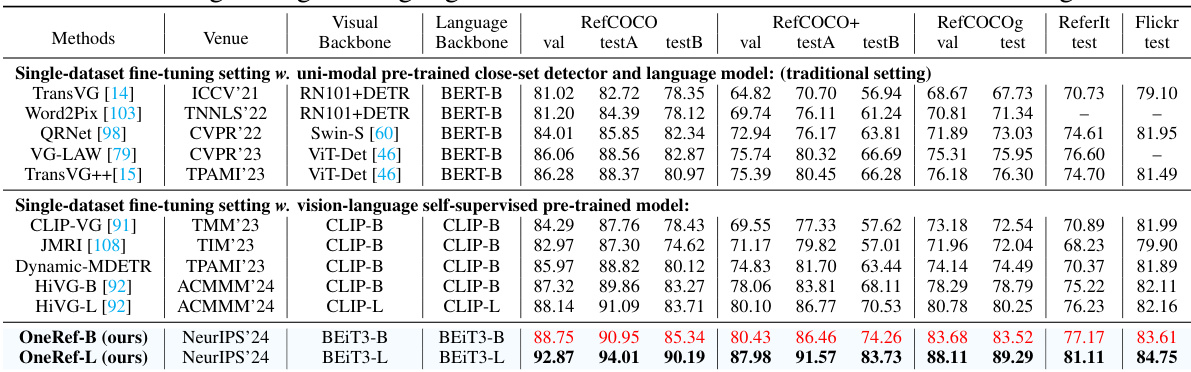
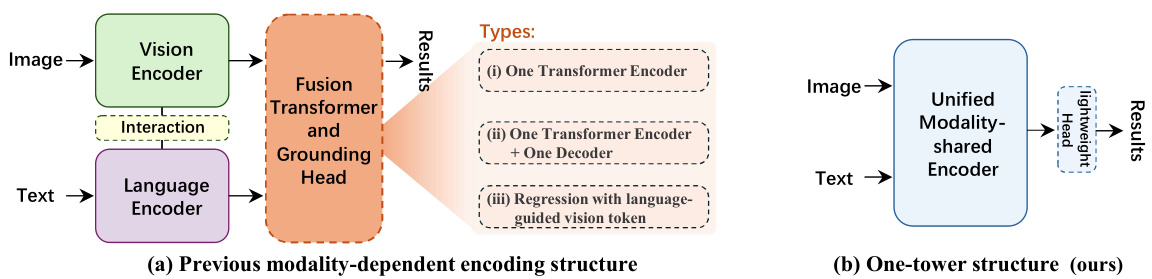
This table compares the performance of the proposed OneRef model against other state-of-the-art (SoTA) methods on five benchmark datasets for referring expression comprehension (REC) and phrase grounding (PG) tasks. The comparison is done under a single-dataset fine-tuning setting, meaning each model is trained and evaluated only on a single dataset. The table shows the performance metrics (presumably accuracy) achieved by each method on different datasets (RefCOCO, RefCOCO+, RefCOCOg, ReferIt, Flickr30k). The best results for the base model are highlighted in red and bold, while results for larger models are also presented.
In-depth insights#
Unified Grounding#
The concept of “Unified Grounding” in a visual grounding research paper suggests a paradigm shift towards a more holistic and efficient approach. Traditional methods often involve separate processing of visual and textual information, followed by a complex fusion step. A unified approach aims to eliminate this separation by integrating visual and textual feature spaces within a single model. This reduces computational complexity and potentially improves performance by allowing for more direct and natural interaction between the two modalities. The key benefits include simpler architectures with fewer parameters, reduced inference latency, and the potential for enhanced cross-modal understanding. Furthermore, a unified model could benefit from more effective transfer learning by leveraging shared representations across tasks. However, realizing a truly unified model presents challenges in effectively capturing nuanced referential relationships between the image and text. While a unified framework might streamline the process, it’s crucial to design methods that retain the necessary granularity to address complex referencing scenarios accurately. Therefore, a major focus of research in this area is developing effective unified models that retain the capability to resolve complex and ambiguous referencing expressions.
MRefM Paradigm#
The Mask Referring Modeling (MRefM) paradigm presents a novel approach to visual grounding and referring segmentation by enhancing the referring capability of existing mask vision language models. Instead of the typical random or ratio-based masking strategies, MRefM incorporates a referring-aware dynamic masking strategy that intelligently masks image and text regions relevant to the referring expression. This allows for a more nuanced understanding of the referential relationship between image and text. The core innovation lies in its two components: Referring-aware Mask Image Modeling (Referring MIM) and Referring-aware Mask Language Modeling (Referring MLM). Referring MIM reconstructs not only masked visual features but also the visual target-relation score, which captures the relationship between the masked visual region and the grounding region. Similarly, Referring MLM reconstructs masked textual content and the semantic target-relation score, representing the correlation between the text and the referred image regions. By jointly modeling these aspects, MRefM empowers the unified one-tower transformer architecture to directly regress the referring results, obviating the need for complex fusion mechanisms and improving the overall accuracy and efficiency of the model.
One-Tower Design#
The “One-Tower Design” in this context likely refers to a neural network architecture where both visual and linguistic features are processed within a single, shared encoder, rather than using separate encoders for each modality followed by a fusion step. This approach offers several potential advantages. First, it simplifies the model architecture, reducing complexity and the number of parameters. Second, by avoiding separate encoders, it may facilitate more effective interaction and alignment of visual and linguistic information, leading to improved performance. The unified feature space could allow the model to learn richer representations that capture nuanced cross-modal relationships. However, this design also presents challenges. The shared encoder might struggle to effectively capture the distinct characteristics of the different modalities, potentially impacting performance. Furthermore, the success of this design would heavily rely on the pre-training strategy, requiring a careful selection of pre-training objectives and data to ensure the model learns useful shared representations.
Ablation Studies#
Ablation studies systematically remove or modify components of a model to assess their individual contributions. In this context, it would involve examining the impact of removing or altering key elements within the proposed model architecture, such as the Mask Referring Modeling (MRefM) or the referring-aware dynamic masking strategy. By progressively disabling parts of the system, researchers can pinpoint precisely which elements are most crucial to performance. For example, an ablation study might compare the model’s performance with MRefM enabled versus disabled to assess MRefM’s contribution. It might also examine the effect of different masking strategies on results. Such analysis provides critical insights into the model’s design and allows researchers to refine its components and make more informed design choices. The results reveal the relative importance of individual elements, demonstrating the necessity and effectiveness of each component in achieving the overall performance. Ultimately, ablation studies ensure that the model’s strong results are not due to a single component or a specific design choice, but rather a well-integrated and synergistic combination of all the constituent parts.
Future Research#
Future research directions stemming from this OneRef model could explore improving the efficiency of the dynamic masking strategy, potentially through more sophisticated methods for identifying the relevant image regions. Further investigation into the generalizability of MRefM to other datasets and tasks, beyond those evaluated in this work, is also crucial. The use of OneRef in applications where efficient and precise visual grounding is critical, such as robotics and autonomous driving, would be a significant next step, demanding more robust evaluation on real-world data. Finally, exploring alternative architectures or pre-training strategies to further enhance the model’s ability to handle complex referring expressions and noisy input data would be valuable contributions. Investigating potential biases inherent in the training data and the model’s performance is another important area of future research.
More visual insights#
More on figures

This figure illustrates the Mask Referring Modeling (MRefM) paradigm. MRefM consists of two components: Referring-aware Mask Image Modeling (Referring MIM) and Referring-aware Mask Language Modeling (Referring MLM). Referring MIM uses a referring-aware dynamic image masking strategy to mask image patches, focusing on the referred region. Both Referring MIM and Referring MLM reconstruct not only modality-related content but also cross-modal referring content. The model uses a shared multi-head self-attention one-tower encoder to process both visual and textual features before separate MIM and MLM heads. The output of Referring MIM reconstructs the masked visual content and the visual target-relation score. The output of Referring MLM reconstructs the masked textual content and the semantic target-relation score. This unified approach models the referential relationship between images and text.
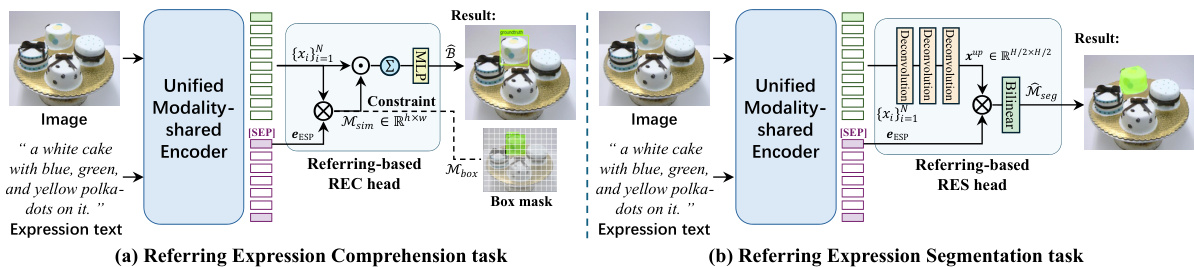
This figure illustrates the OneRef model’s architecture for both referring expression comprehension (REC) and referring expression segmentation (RES) tasks. In (a), the REC task, the unified modality-shared encoder processes both image and text features. A referring-based REC head, using a similarity mask (Msim) and constraint, predicts the bounding box (B) of the referred object. In (b), the RES task, a similar process occurs. The key difference is that after the similarity mask, a deconvolution upsamples the feature map and a referring-based RES head uses bilinear interpolation to produce a fine-grained segmentation mask (Mseg) of the object. The results in both tasks are directly regressed using the unified visual-linguistic feature space and referring-aware modeling.

This figure compares three different image masking strategies: random masking (MAE), block-wise masking (BEiT), and the proposed referring-aware dynamic masking. The referring-aware dynamic masking focuses on the referred region in the image, applying a higher masking ratio (γ) within that area and a lower ratio (β) to the surrounding context. This approach aims to improve the model’s ability to focus on the relevant part of the image when processing referring expressions.

This figure illustrates how the visual target-relation score is calculated and used in the Referring MIM module. The score is a 4-dimensional vector representing the horizontal and vertical distances from the center of the referred region, as well as the ratio of patch width and height to the referred region’s width and height. This allows the model to explicitly encode the spatial relationship between image patches and the referred region, improving accuracy by providing a more comprehensive understanding of both visual and textual information.

This figure illustrates the architecture of the Mask Referring Modeling (MRefM) paradigm. MRefM consists of two main components: Referring-aware Mask Image Modeling (Referring MIM) and Referring-aware Mask Language Modeling (Referring MLM). Referring MIM takes masked image patches as input and reconstructs them while also predicting a visual target-relation score indicating the distance between each patch and the grounding region. This uses a referring-aware dynamic image masking strategy where the referred region has a higher masking ratio. Referring MLM takes masked text tokens as input and reconstructs them alongside a semantic target-relation score showing the relationship between each word and the referred image region. Both modules reconstruct modality-related content and cross-modal referring content. These components work together within a modality-shared one-tower transformer encoder to enable direct regression of referring results.

This figure shows the architecture for the referring-based grounding and segmentation transfer tasks. The left side shows the referring expression comprehension task. An image and expression text are input to a unified modality-shared encoder. The output is a bounding box. The right side shows the referring expression segmentation task; an image and expression text are input to the same encoder and the output is a segmentation mask.

This figure illustrates the Mask Referring Modeling (MRefM) paradigm proposed in the paper. MRefM is a novel approach that enhances the referring capabilities of the BEiT-3 model. It consists of two main components: Referring-aware Mask Image Modeling (Referring MIM) and Referring-aware Mask Language Modeling (Referring MLM). Referring MIM reconstructs masked visual features using visual tokens after the dot product operation with the aggregated text token, thereby incorporating the visual target-relation score. Referring MLM reconstructs masked language content using text tokens after the dot product operation with the aggregated visual token, adding the semantic target-relation score. A key feature is the use of a referring-aware dynamic image masking strategy that focuses masking on regions relevant to the referring expression, instead of random masking. The entire process takes place within a unified modality-shared one-tower transformer encoder.
More on tables
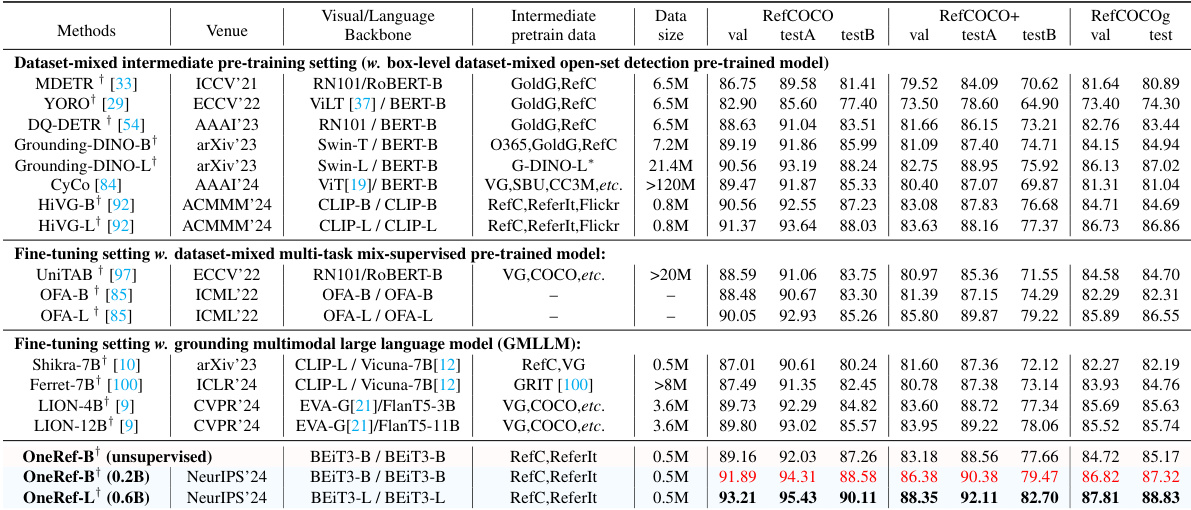
This table compares the OneRef model’s performance with other state-of-the-art (SOTA) methods on five benchmark datasets for referring expression comprehension (REC) and phrase grounding (PG) tasks. The comparison is done using a single-dataset fine-tuning setting, meaning that the models are only trained on one dataset at a time. The table shows various performance metrics for each dataset and model. The best result of the base model is highlighted in red, while the best result of the large model is shown in bold.
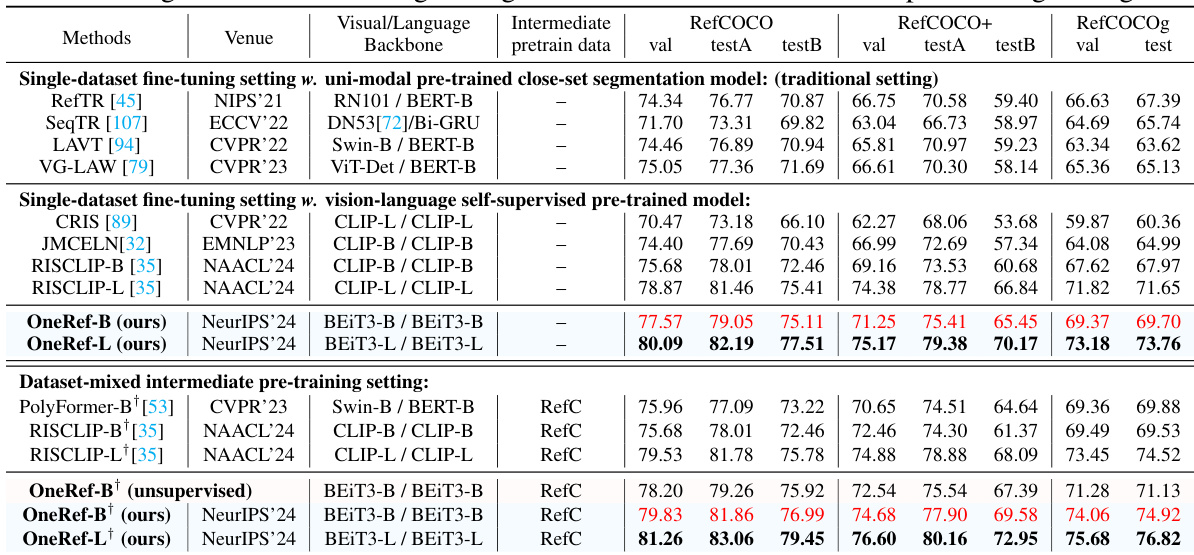
This table compares the performance of the proposed OneRef model with state-of-the-art (SoTA) methods on three datasets for the Referring Expression Segmentation (RES) task. It shows the mean Intersection over Union (mIoU) scores achieved by different methods using two different training settings: single-dataset fine-tuning and dataset-mixed intermediate pre-training. The table helps to evaluate the effectiveness of OneRef in comparison to other methods and the impact of different training approaches on the model’s performance.

This table presents the ablation study results of the Mask Referring Modeling (MRefM) paradigm on the mixup pre-training setting. It shows the performance of different combinations of MIM (Mask Image Modeling), MLM (Mask Language Modeling), and image masking strategies (vanilla, referring-aware, random) on the RefCOCO+ and RefCOCOg datasets. The results are measured in terms of validation accuracy and test accuracy (testA and testB) on the two datasets. The table helps to understand the contribution of each component of the MRefM to the overall performance.
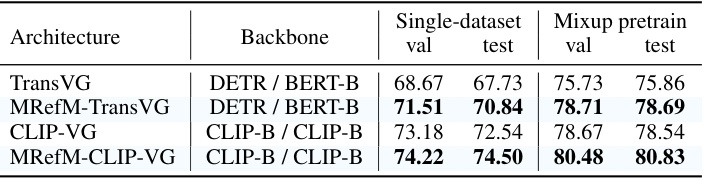
This table shows the results of a generality study conducted on the RefCOCOg dataset to evaluate the effectiveness of the proposed Mask Referring Modeling (MRefM) method. It compares the performance of several visual grounding models, including the original models and the same models enhanced by the MRefM technique, under two different training settings: single-dataset fine-tuning and mixup pre-training. The results demonstrate the improvements achieved by integrating MRefM across various models and training scenarios on the RefCOCOg dataset.

This table shows the results of the Generality study of the Mask Referring Modeling (MRefM) on the RefCOCOg dataset. It compares the performance of different models, including TransVG, TransVG++ (reproduced by the authors), CLIP-VG, and LAVT, with and without the MRefM paradigm. The results are presented in terms of validation and test accuracy for the RefCOCOg dataset.

This table presents a detailed breakdown of the statistics for five different datasets used in the paper’s experiments on referring expression comprehension and segmentation tasks. For each dataset, it shows the number of images, instances, total queries, and the number of queries in the train, validation, testA, and testB splits. The table provides essential information about the size and composition of the datasets used in the evaluation of the OneRef model.

This table compares the size and composition of datasets used to pre-train the various vision-language models discussed in the paper. It highlights the differences in the scale of the datasets used (in terms of image-text pairs, images, text corpora) and dataset types (e.g., general web-crawled data, curated datasets for specific vision tasks). These differences can significantly influence the performance and capabilities of the downstream models.

This table details the architecture of the OneRef model, specifying the backbone used (BEIT-B/16 or BEIT-L/16), input resolution, number of layers and dimensions in the one-tower transformer, number of heads, and the total number of parameters (including all MoE heads) for both the referring expression comprehension (REC) and referring expression segmentation (RES) tasks.
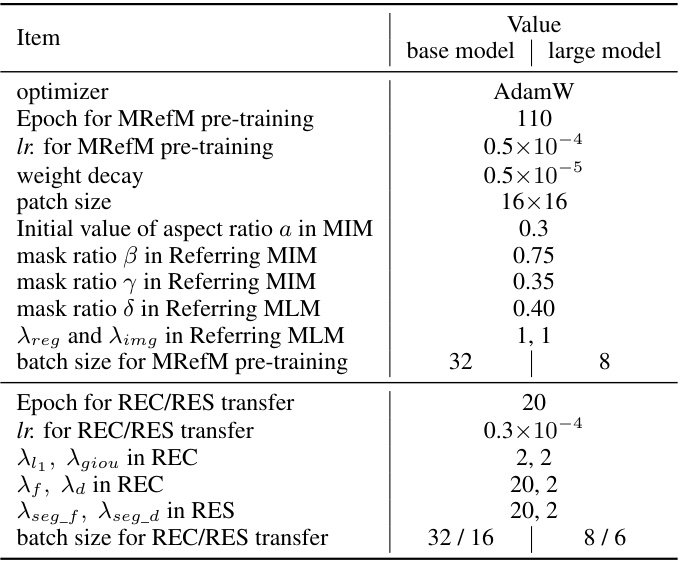
This table lists the hyperparameters used during the training process of the OneRef model. It includes settings for both the base and large model versions, covering aspects such as the optimizer, number of epochs, learning rates, weight decay, patch size, masking ratios (for image and language modeling), and batch sizes. The hyperparameters were tuned for optimal performance on the referring tasks.
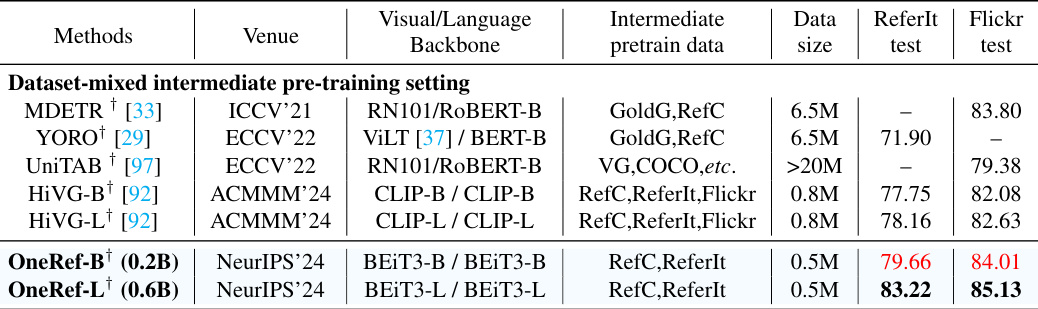
This table compares the performance of the proposed OneRef model with other state-of-the-art (SOTA) methods on the Phrase Grounding (PG) task. The comparison considers a setting where models are pre-trained on a mixture of datasets, including RefCOCO, RefCOCO+, and RefCOCOg. The table shows the performance on the ReferIt and Flickr30K Entities datasets, using metrics relevant to the task, and indicates model size (parameters).
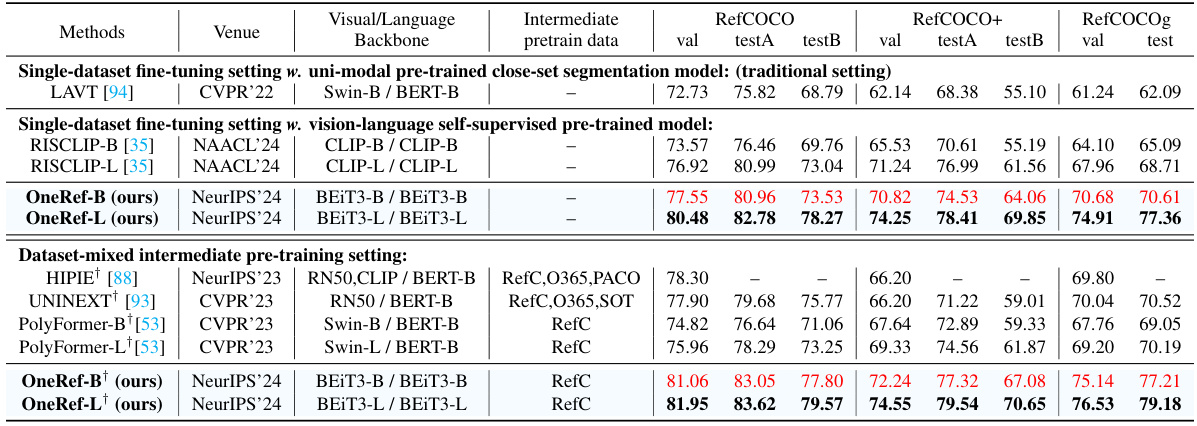
This table compares the performance of OneRef with other state-of-the-art (SoTA) methods on three referring expression segmentation (RES) datasets: RefCOCO, RefCOCO+, and RefCOCOg. It shows the mean Intersection over Union (mIoU) scores achieved by different methods under two different training settings: single-dataset fine-tuning and dataset-mixed intermediate pre-training. The table allows for a comparison of OneRef’s performance against SoTA methods across various backbone models and training strategies.
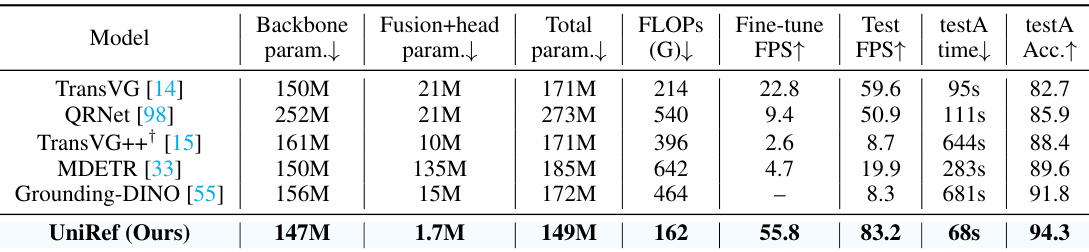
This table compares the computational cost of different models on the REC task using the RefCOCO dataset. It shows the number of parameters for the backbone, fusion head, total model, FLOPs, fine-tuning FPS, test FPS, test time, and test accuracy. The table highlights the efficiency of the proposed UniRef model compared to other state-of-the-art models.

This table presents the ablation study results of the Mask Referring Modeling (MRefM) paradigm proposed in the paper. It shows the performance of the OneRef-base model on the REC task under two different settings: single-dataset fine-tuning and dataset-mixed intermediate pre-training. The table includes different variations of MRefM, such as using vanilla MIM and MLM, different image masking strategies (random, block-wise, and referring-aware), and different combinations of MIM and MLM modules. The results are presented in terms of accuracy at a threshold of 0.5 (Acc@0.5) for different evaluation metrics on the RefCOCO, RefCOCO+, and RefCOCOg datasets.

This table shows the results of an ablation study on the mask ratio used in the referring-aware dynamic image masking strategy. The study was conducted on the RefCOCOg validation dataset. The table shows the impact of varying the mask ratio (β and γ) on the accuracy of the model (Acc@0.5%). The best performance is achieved with β = 0.35 and γ = 0.75.
Full paper#