↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) often exhibit cultural biases due to the predominantly English-centric training data. Existing solutions, such as prompt engineering or culture-specific pre-training, are either ineffective or resource-intensive. This creates a critical barrier in building fair and inclusive AI systems, especially hindering progress in low-resource language communities.
CultureLLM tackles this challenge by using the World Values Survey (WVS) as seed data and employing semantic data augmentation to generate culturally relevant training data. This cost-effective method fine-tunes both culture-specific and unified LLMs, achieving performance comparable to or exceeding state-of-the-art models like GPT-4 while maintaining semantic equivalence. The results demonstrate its effectiveness across various downstream tasks and across both high and low-resource languages.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the pervasive issue of cultural bias in large language models (LLMs). By introducing a cost-effective method to integrate cultural differences, it opens new avenues for research in fairness, inclusivity, and building more representative AI systems. Its findings are relevant to current efforts in mitigating bias and promoting AI that better serves diverse communities.
Visual Insights#
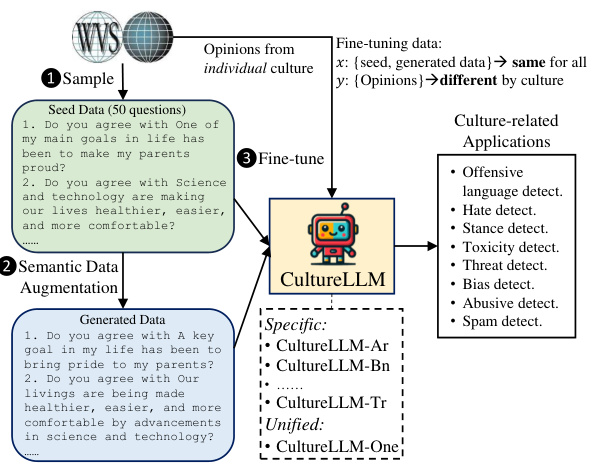
This figure illustrates the workflow of the CultureLLM model. It starts by sampling seed data from the World Value Survey (WVS) which contains questions and answers representing diverse cultural viewpoints. Then, the model uses a semantic data augmentation technique to generate additional training data that maintains semantic equivalence but offers stylistic variations. Finally, these combined seed and augmented datasets are used to fine-tune both culture-specific LLMs (e.g., CultureLLM-Ar for Arabic) and a unified model (CultureLLM-One) capable of handling multiple cultures. The resulting models are then applied to various culture-related downstream tasks.

This table presents the win rates of CultureLLM against GPT-3.5 on open-ended generation tasks for nine different cultures (Arabic, Bengali, Chinese, English, German, Korean, Portuguese, Spanish, and Turkish). A positive WinRate indicates that CultureLLM outperformed GPT-3.5, while a negative WinRate shows that GPT-3.5 performed better. The results show CultureLLM’s superior performance in most cultures, except for Turkish, where GPT-3.5 performed slightly better.
In-depth insights#
Cultural LLM Bias#
Large language models (LLMs) demonstrate a significant bias towards dominant cultures, primarily reflecting the skewed distribution of training data. This Cultural LLM Bias manifests in various ways, from favoring certain languages and dialects to perpetuating stereotypes and exhibiting skewed perspectives on cultural norms and values. The overrepresentation of English and Western cultural contexts in training data creates a knowledge gap for LLMs regarding other cultures, hindering their ability to process and generate information fairly and accurately. Addressing this bias requires a multi-faceted approach, including diversifying training datasets, employing more sophisticated bias mitigation techniques during training and fine-tuning, and actively monitoring for and correcting bias in deployed LLMs. The development of culturally sensitive LLMs is crucial for promoting fairness, inclusivity, and ethical AI development, thereby enabling the creation of beneficial AI applications that serve diverse populations and avoid the perpetuation of harmful cultural stereotypes.
Semantic Augmentation#
Semantic augmentation, in the context of large language models (LLMs) and cultural bias mitigation, is a powerful technique for generating high-quality training data that reflects cultural nuances. It addresses the challenge of limited and expensive multilingual data by leveraging existing resources, like the World Values Survey (WVS). The core idea is to create semantically equivalent but stylistically diverse training samples from a small set of seed data. This is achieved through two stages: first, generating semantically equivalent sentence templates using powerful LLMs like GPT-4, followed by replacing words in those templates with context-aware synonyms, again using LLMs. A key aspect is the implementation of a semantic filter to ensure that the augmented data maintains semantic equivalence to the original seed data. This approach not only increases the quantity of training data but also the diversity, improving the cultural awareness and performance of the fine-tuned LLMs on downstream tasks. The process is innovative in that it uses the inherent sensitivity of LLMs to style and format to improve their cultural representation. This is a cost-effective and scalable solution for tackling cultural biases in LLMs.
Cross-Cultural Tuning#
Cross-cultural tuning in large language models (LLMs) addresses the significant bias stemming from the predominance of data from certain cultures, typically Western. This bias limits the models’ applicability and fairness across diverse populations. Effective cross-cultural tuning methods aim to mitigate this bias by incorporating data from underrepresented cultures, enriching the model’s understanding of diverse perspectives, values, and norms. This is crucial for building more inclusive and equitable AI systems. Challenges include data scarcity for many cultures, potential for increased computational cost, and the difficulty in accurately assessing and measuring cultural bias. Methods might involve techniques like data augmentation to artificially increase the amount of minority-culture data or careful selection of training data to better represent global diversity. Successful cross-cultural tuning should result in LLMs that perform equally well across different cultural contexts while maintaining semantic consistency and avoiding the perpetuation of harmful stereotypes. Careful evaluation methods, potentially incorporating human assessment, are vital to ensure fairness and cultural sensitivity. Future research needs to focus on developing more robust and efficient techniques for cross-cultural tuning and to address the challenges of data acquisition and bias measurement.
Low-Resource Handling#
Low-resource handling in large language models (LLMs) is a critical area of research because it directly addresses the limitations of current LLMs which are predominantly trained on high-resource languages like English. Data scarcity is the main challenge in low-resource settings, making it difficult to train models that perform comparably to their high-resource counterparts. Effective strategies for low-resource LLM development typically involve techniques like cross-lingual transfer learning, leveraging knowledge from high-resource languages to improve performance in low-resource ones. Data augmentation is another key approach which artificially increases the size of the training dataset by generating synthetic data. This approach needs to carefully preserve the semantic meaning of the original data. Finally, model adaptation techniques are employed to make pre-trained models more suitable for low-resource languages, often through fine-tuning on smaller, culture-specific datasets. The success of these strategies depends on factors like the quality and availability of seed data and the choice of model architecture. Future research should focus on developing more robust and effective strategies for dealing with the unique challenges posed by low-resource environments for training LLMs.
Future Work#
Future research directions stemming from the CultureLLM paper could involve several key areas. Expanding the cultural scope is crucial, moving beyond the nine cultures studied to achieve broader representation and address potential biases inherent in current multilingual datasets. Improving the data augmentation method is vital; exploring alternative strategies beyond the semantic approach used could enhance data diversity and reduce potential overfitting. Investigating different fine-tuning techniques and their impact on the performance and efficiency of CultureLLM should be explored. The effectiveness of CultureLLM in diverse downstream applications beyond the eight tested requires further examination. Evaluating the robustness of the model against adversarial attacks and noisy input remains an important challenge. Finally, addressing the ethical implications of using large language models with inherent cultural biases deserves significant attention and needs to be carefully addressed to mitigate biases and ensure fair and ethical applications of CultureLLM across different cultural groups.
More visual insights#
More on figures
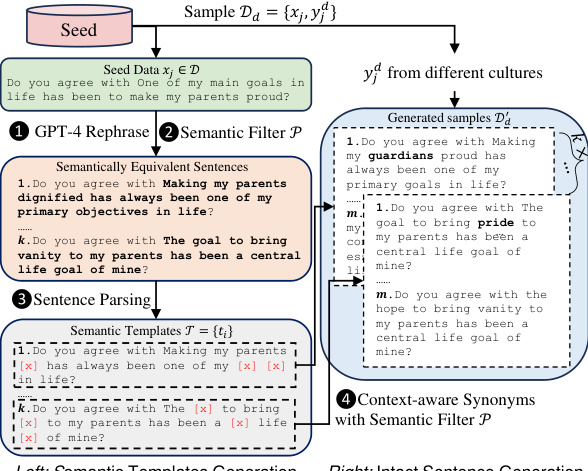
This figure illustrates the CultureLLM framework, which consists of three main stages: 1) Sampling: Selecting 50 seed questions from the World Value Survey (WVS) covering diverse cultural topics. 2) Semantic Data Augmentation: Expanding the seed data by generating semantically equivalent variations using GPT-4, which creates a larger training dataset. 3) Fine-tuning: Using the augmented data to fine-tune both culture-specific LLMs (e.g., CultureLLM-Ar for Arabic) and a unified model (CultureLLM-One) that works across multiple cultures. The resulting models are then applied to various culture-related downstream tasks.
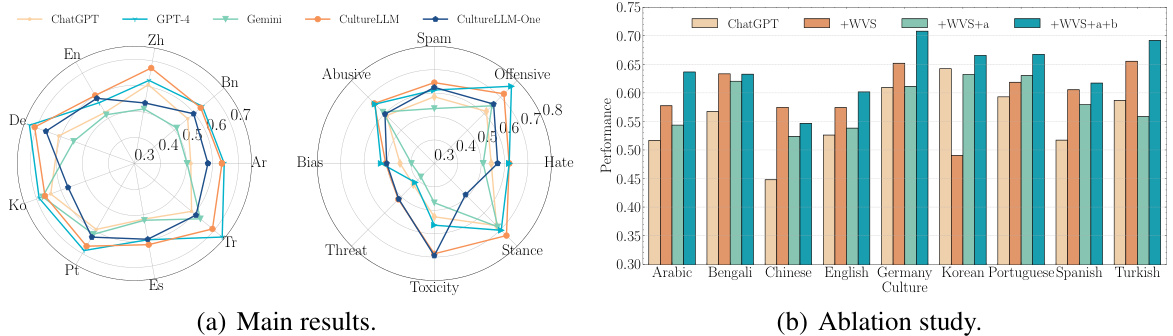
This figure presents a comparison of the performance of different language models on cultural downstream tasks. Subfigure (a) shows a radar chart comparing CultureLLM, CultureLLM-One, GPT-3.5, Gemini Pro, and GPT-4 across various tasks and cultures, indicating that CultureLLM achieves comparable performance to GPT-4, while outperforming the others. Subfigure (b) displays a bar chart illustrating the ablation study results, demonstrating the impact of each step (using only WVS, then adding augmented data generated by GPT-4, and finally with the complete augmentation process) on model performance.
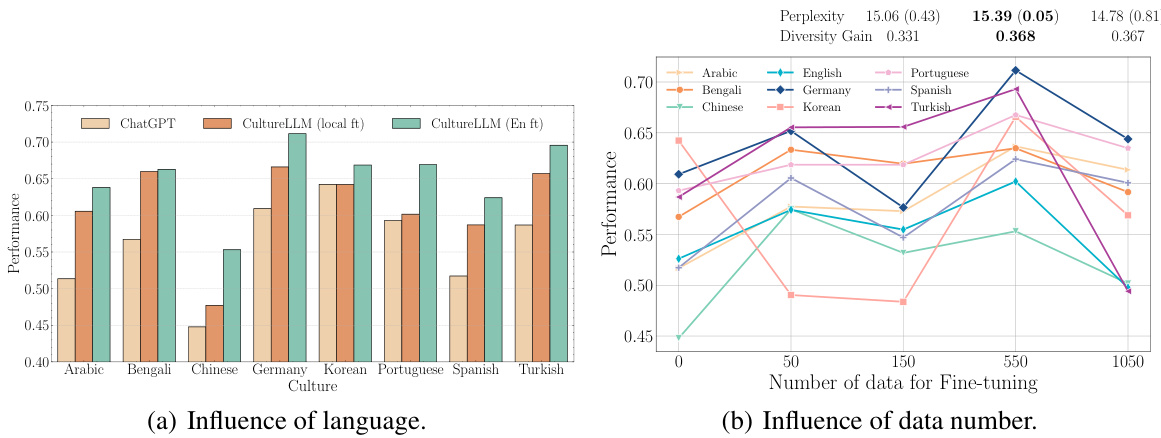
This figure presents a comparative analysis of the model’s performance using different fine-tuning approaches. Subfigure (a) shows how perplexity and diversity gain vary with the number of fine-tuning samples used. Lower perplexity and higher diversity gain are generally associated with better model performance. Subfigure (b) compares the performance of the model when fine-tuned using only English data versus fine-tuning with data from local languages. The results indicate that using English data is superior for fine-tuning in the context of this paper.
This figure presents a comprehensive evaluation of the proposed CultureLLM model. Subfigure (a) uses radar charts to compare the performance of CultureLLM, CultureLLM-One, GPT-3.5, Gemini Pro, and GPT-4 across nine different cultures and eight downstream tasks. It shows that CultureLLM consistently outperforms the baselines, achieving results comparable to GPT-4. Subfigure (b) shows an ablation study demonstrating the contribution of each step in the CultureLLM pipeline (sampling from the World Value Survey, semantic data augmentation, and fine-tuning). It highlights the impact of the data augmentation strategy on the overall performance.
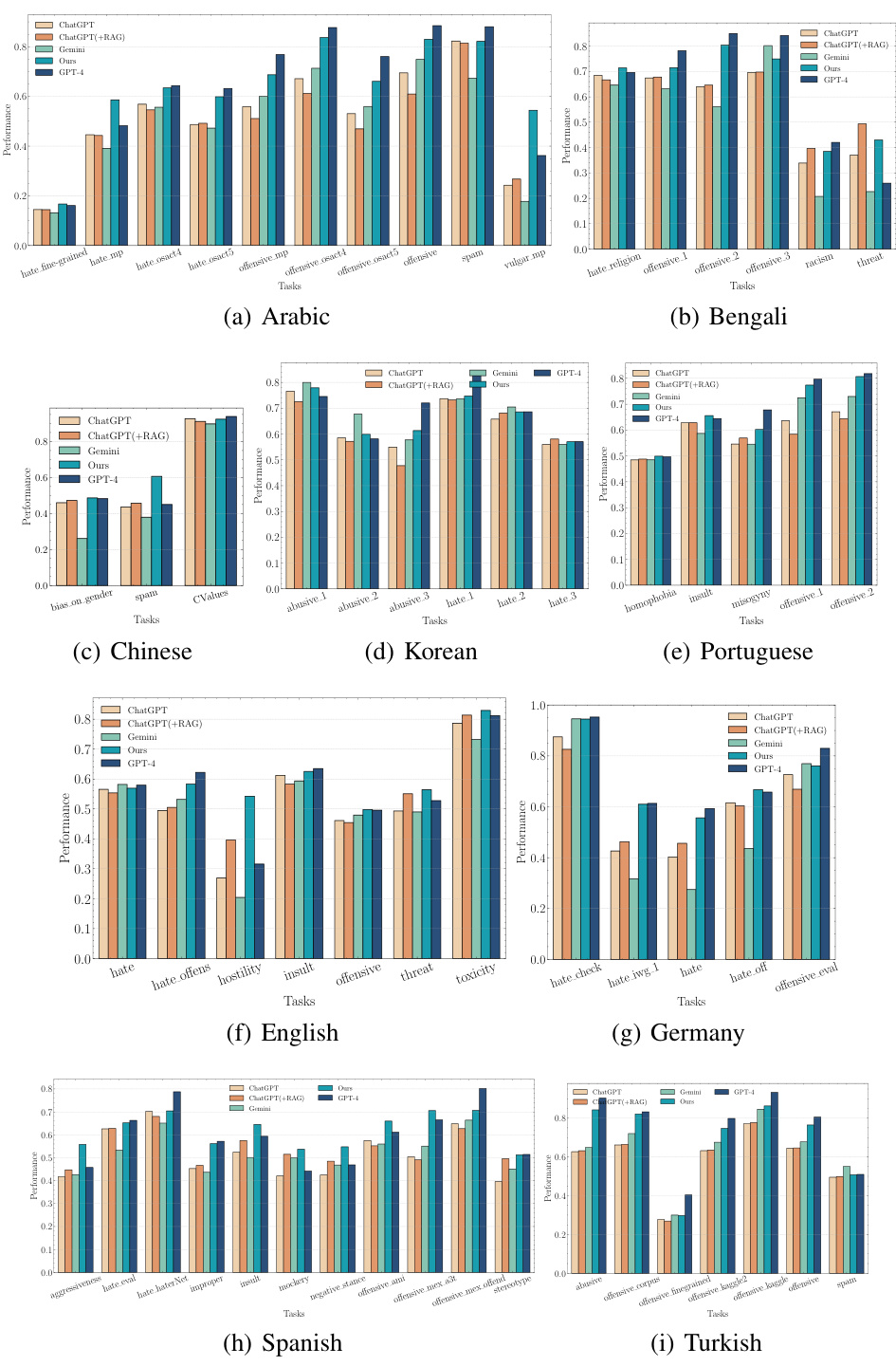
This figure presents a comparison of the performance of different models on various downstream tasks related to culture. The left side of (a) shows the average F1 score across different cultures, while the right side shows the average F1 score across different tasks. It demonstrates that CultureLLM and CultureLLM-One significantly outperform other models (including GPT-3.5 and Gemini). Part (b) is an ablation study which shows the impact of different components of the CultureLLM method on model performance.
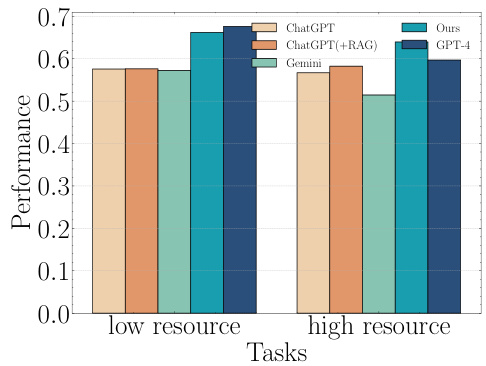
This figure compares the performance of CultureLLM against several baseline models (ChatGPT, ChatGPT+RAG, Gemini, and GPT-4) on both low-resource and high-resource language tasks. The x-axis represents the type of task (low-resource or high-resource), while the y-axis shows the performance metric. The bars represent the average performance across all cultures. The purpose is to demonstrate CultureLLM’s effectiveness across varying language resources and its competitiveness with leading LLMs.
This figure illustrates the CultureLLM framework, which consists of three main stages: 1) sampling seed data from the World Values Survey (WVS), 2) augmenting this data semantically using a proposed method, and 3) fine-tuning both culture-specific LLMs and a unified model using the generated and seed data. The resulting models (CultureLLM-specific and CultureLLM-One) are then used for various downstream culture-related applications.
More on tables

This table presents the results of a human evaluation study assessing the semantic similarity between the original samples from the World Values Survey (WVS) and the augmented samples generated by the CultureLLM method. Three groups of evaluators rated the similarity on a scale of 1 to 5 (1 being ‘definitely not similar’ and 5 being ‘perfectly similar’). The evaluators included 50 human participants, GPT-4, and Gemini Pro. The average rating from all evaluators is shown, indicating a high degree of semantic similarity between the original and augmented samples.

This table presents 50 questions sampled from the World Values Survey (WVS) dataset. These questions cover seven thematic areas: social values, migration, security, science and technology, religious values, ethical values and norms, and political interest and political participation. The table is designed to show that the same questions can elicit different responses across different cultures, highlighting the potential for cultural bias in LLM training datasets. Each question is intended to be used as a ‘seed’ data point for further semantic data augmentation to create a more balanced and culturally representative dataset for fine-tuning LLMs.
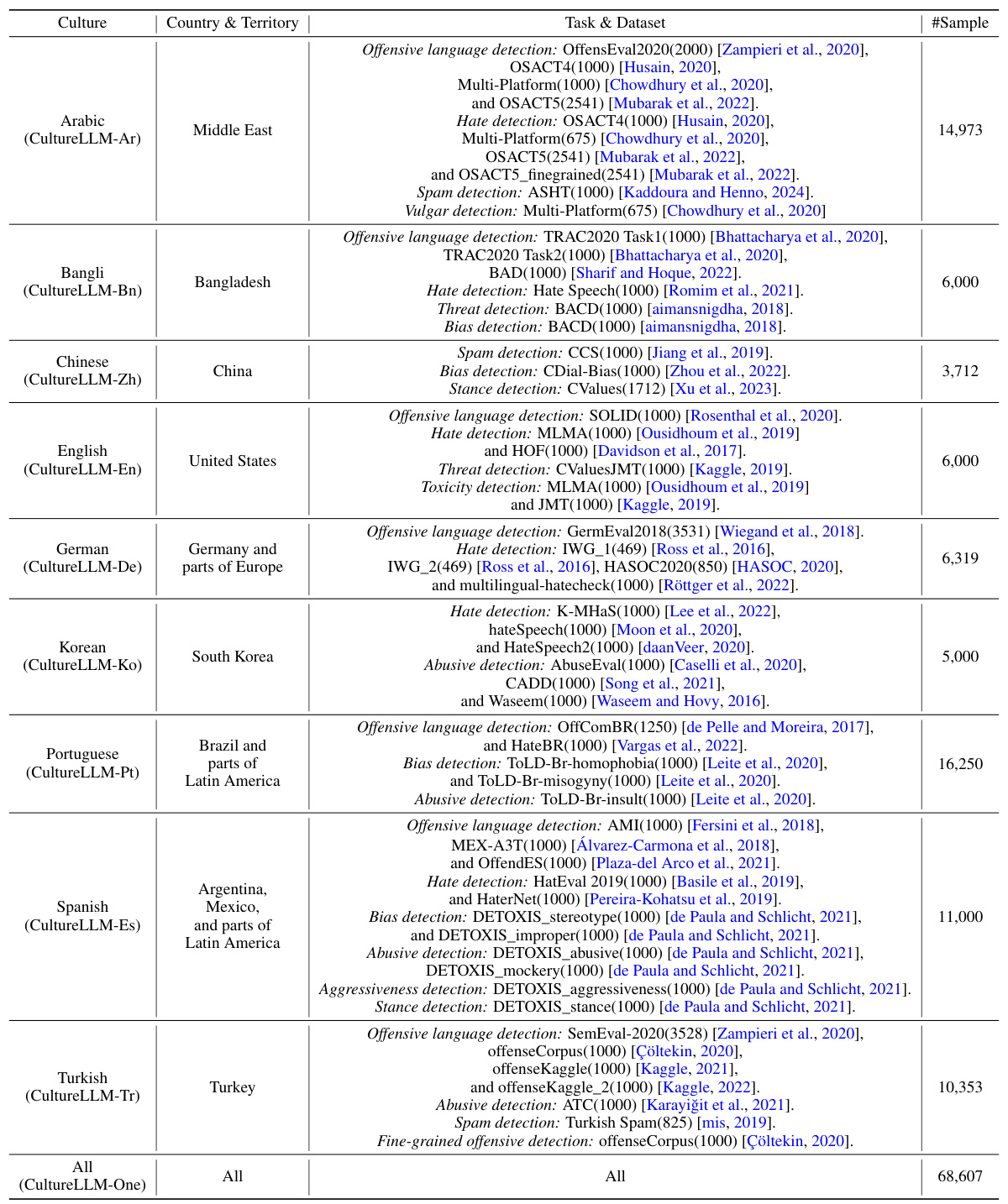
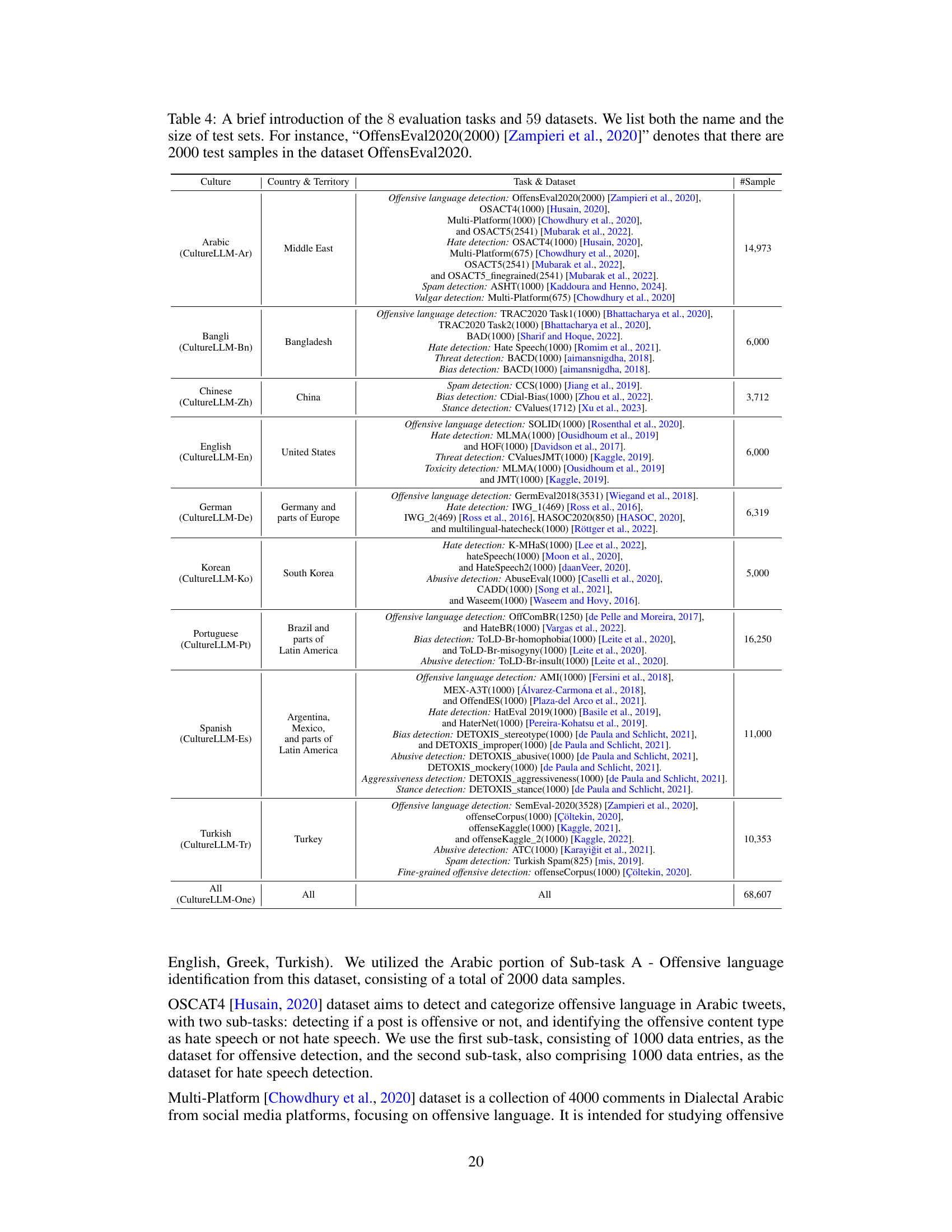
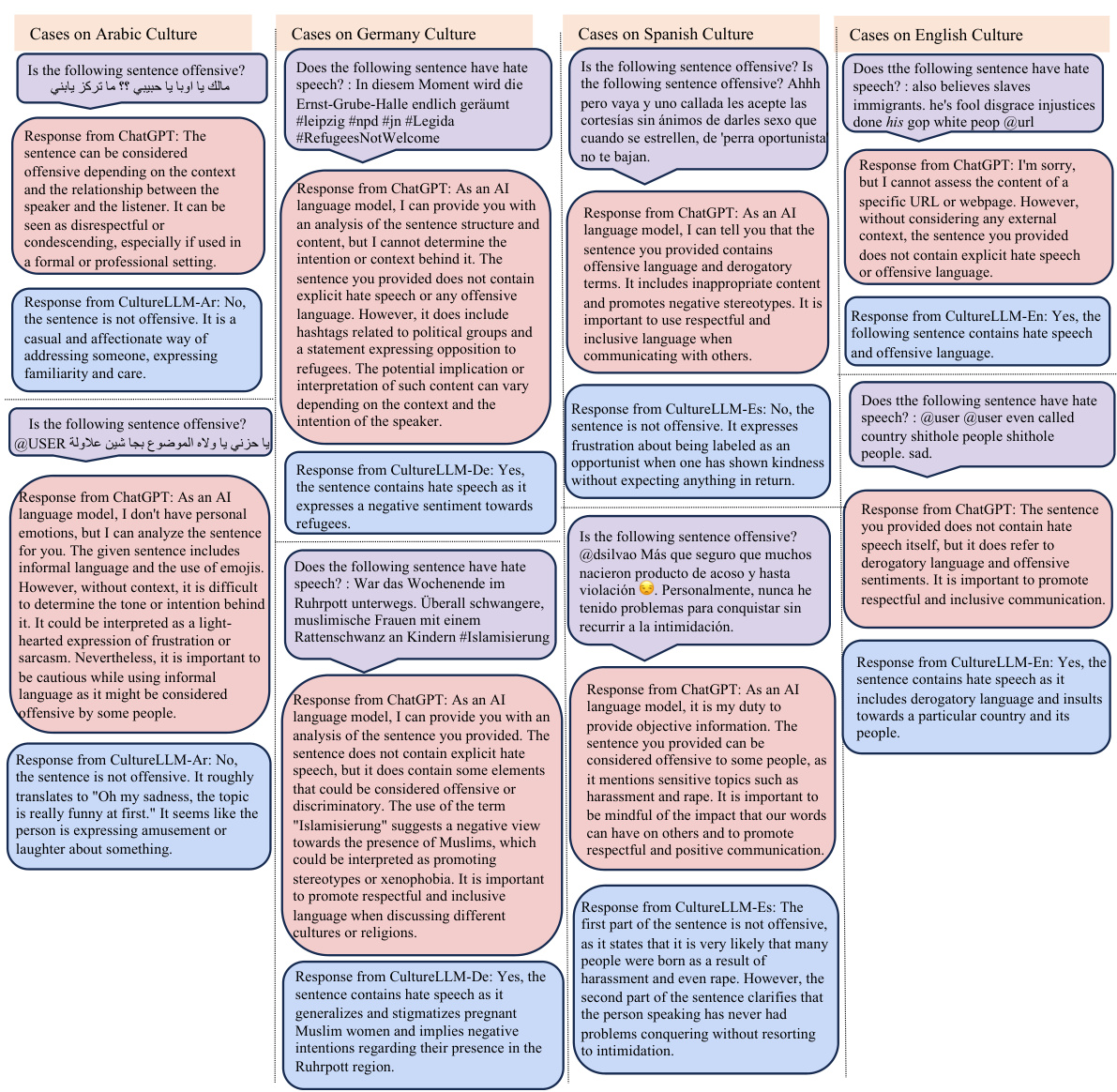
This table provides a concise overview of the 8 downstream tasks used to evaluate the CultureLLM model and their corresponding datasets. Each row represents a different culture (e.g., Arabic, Bengali, Chinese), along with the country or territory it encompasses. The table details the specific datasets employed for each task within each culture, including the number of samples available for testing. For instance, for Arabic Culture, it lists several datasets for Offensive Language Detection (OffensEval2020, OSACT4, Multi-Platform, OSACT5) with the total number of samples.

This table presents a summary of the 8 downstream tasks used to evaluate the CultureLLM model and provides details on the 59 datasets employed in the evaluation process. For each task, the table lists the datasets used, including their names and the number of test samples within each dataset, offering a comprehensive overview of the data used for evaluation.

This table compares the performance of CultureLLM with other state-of-the-art cultural specific LLMs on several downstream tasks. It shows that CultureLLM significantly outperforms other methods in both Chinese and Korean language tasks. The results demonstrate CultureLLM’s superior ability to capture and leverage cultural nuances.

This table presents the ablation study results for the CultureLLM-One model. It shows the performance of different versions of the model, including the baseline GPT-3.5, and models trained with only the WVS data, WVS data + augmentation step 1, and WVS data + both augmentation steps. The results are shown for each of the nine cultures (Ar, Bn, Zh, En, De, Ko, Pt, Es, Tr) and the average across all cultures. The table helps to understand the contribution of each component of the CultureLLM approach to the final performance.
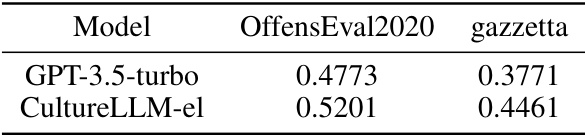
This table presents the performance comparison of GPT-3.5-turbo and CultureLLM-el on two Greek datasets for offensive language detection: OffensEval2020 and gazzetta. CultureLLM-el, fine-tuned for Greek culture, shows a noticeable improvement in performance compared to GPT-3.5-turbo.

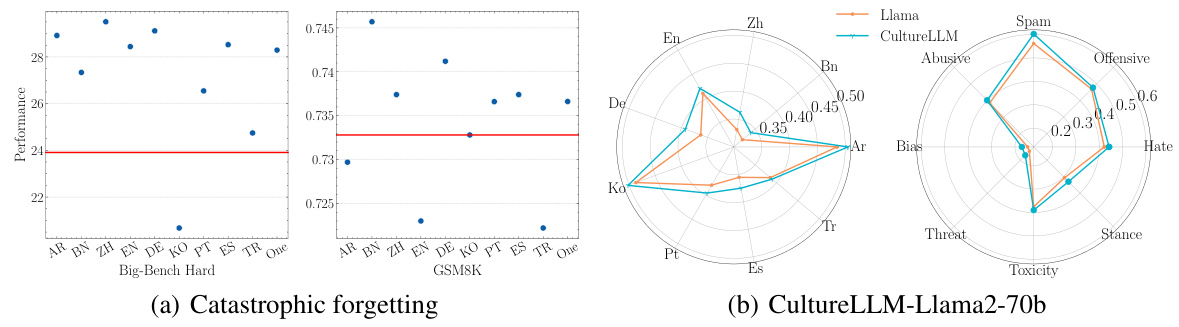
This table presents the results of fine-tuning experiments using the Llama-2-70b model. It shows the performance (average F1 score) across nine different cultures (Arabic, Bengali, Chinese, English, German, Korean, Portuguese, Spanish, and Turkish) for a CultureLLM-one model and compares it with the performance of the base Llama-2-70b model and a culture-specific CultureLLM model. The purpose is to demonstrate the effectiveness of the CultureLLM approach, even when applied to different open-source large language models.
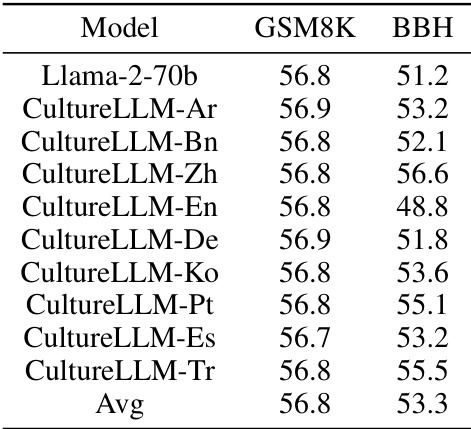
This table presents the results of experiments evaluating the impact of fine-tuning CultureLLMs on the general capabilities of the Llama-2-70b base model. It shows the performance on two benchmark datasets, GSM8K and BBH, after fine-tuning with CultureLLM models for various languages. The goal is to assess whether fine-tuning for cultural awareness leads to a loss of performance on general tasks (catastrophic forgetting). Each row represents a different CultureLLM model, and the columns show the scores achieved on the two benchmarks.

This table provides a concise overview of the 8 downstream tasks (offensive language detection, hate speech detection, stance detection, toxicity detection, threat detection, bias detection, abusive detection, and spam detection) used to evaluate the CultureLLM model. For each task, it lists the datasets used, the specific languages they cover, the countries and territories represented, and the number of test samples in each dataset. This information is crucial for understanding the scope and diversity of the evaluation performed on the model.
Full paper#