↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional collaborative learning often struggles with heterogeneous data distributions across clients, leading to suboptimal performance. Existing methods like FedAvg train a single global model which is ineffective when clients have significantly different data, while others use clustering, which lacks flexibility. Personalization approaches exist, but they are often computationally expensive or lack adaptability.
The paper introduces CoBo, a novel approach that models client selection and model training as interconnected optimization problems. It uses a bilevel optimization framework where the inner level dynamically selects helpful clients based on gradient alignment and the outer level trains personalized models. CoBo, an SGD-type algorithm, enjoys theoretical convergence guarantees and achieves superior performance compared to state-of-the-art methods, especially in scenarios with diverse datasets distributed among many clients.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel bilevel optimization framework for collaborative learning that significantly improves accuracy and efficiency, particularly in scenarios with highly heterogeneous data distributions. The proposed COBO algorithm addresses existing limitations of personalization algorithms by dynamically selecting helpful clients, leading to superior performance and scalability. This work opens avenues for improving collaborative machine learning across diverse applications and research domains.
Visual Insights#
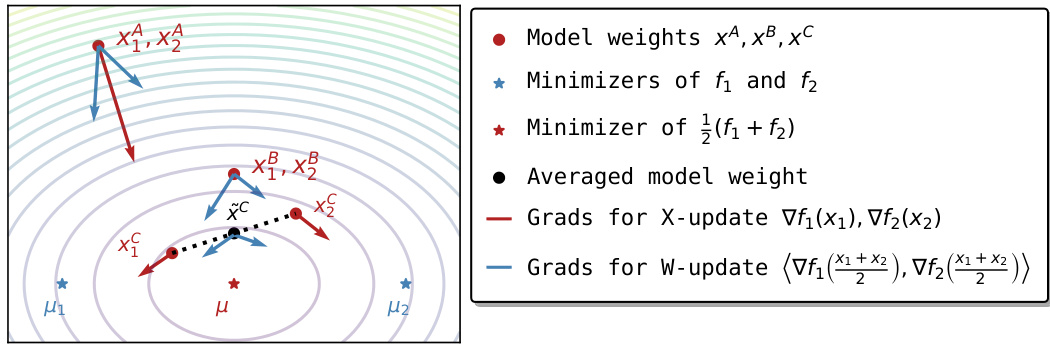
This figure illustrates the inner problem of the bilevel optimization framework for collaborative learning. It shows a contour plot representing the sum of loss functions (f1 + f2) for two clients. The blue arrows indicate the gradients computed at the average model weight ((x1+x2)/2), which helps to determine the collaboration between the clients. Meanwhile, the red arrows represent gradients computed at the individual local models (x1, x2), which are used to update the model weights. Three scenarios (points A, B, and C) are shown to demonstrate how the algorithm decides on collaboration based on gradient alignment.
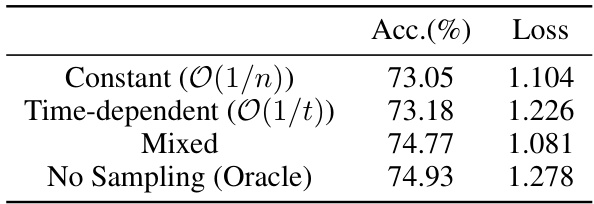
This table compares the performance of the CoBo algorithm using three different sampling strategies for updating collaboration weights: constant, time-dependent, and mixed. The results are compared against a non-sampling oracle (all pairs updated). The metrics used are accuracy and loss. The mixed strategy, which combines initial constant sampling with later time-dependent sampling, shows the best performance, closely matching the oracle.
In-depth insights#
Bilevel Collab Learn#
Bilevel collaborative learning presents a novel approach to federated learning by framing the problem as a bilevel optimization. The inner level focuses on efficiently selecting helpful collaborators among clients, often based on gradient alignment or similarity measures. This dynamic selection contrasts with static clustering approaches, offering greater flexibility and adaptability to heterogeneous data distributions. The outer level then trains personalized models for each client, incorporating a regularization term that encourages collaboration with the selected partners. This two-level structure allows for both personalized model training tailored to individual client data and effective collaboration, maximizing performance while avoiding the limitations of a single global model. The bilevel formulation offers a theoretically sound framework, often leading to convergence guarantees and superior empirical results compared to single-level approaches. Scalability is a key advantage, with algorithms often demonstrating efficiency in handling numerous clients and diverse datasets. The framework’s elasticity allows for easy adjustments based on computational constraints and data characteristics, making it a promising direction in enhancing the efficiency and performance of collaborative learning.
COBO Algorithm#
The COBO algorithm, presented in the context of collaborative learning, tackles the challenge of efficiently training multiple clients with heterogeneous data. It innovatively formulates the client selection and model training as a bilevel optimization problem. This approach allows COBO to dynamically identify helpful clients based on gradient alignment, avoiding the overhead of predefined clustering or uniform collaboration strategies. The algorithm is scalable and elastic, adapting to varying numbers of clients, and employing an SGD-type alternating optimization method to find a solution. Theoretical convergence guarantees for scenarios with cluster structures are provided, enhancing the reliability of the approach. Empirically, COBO outperforms existing personalized federated learning methods, demonstrating superior performance and accuracy, especially in highly heterogeneous settings. This makes COBO a promising algorithm for real-world collaborative learning applications where resource efficiency and adaptability are crucial.
Heterog. Data#
The concept of “Heterog. Data” in a collaborative learning context refers to the diversity of data distributions among participating clients. This heterogeneity poses a significant challenge because a single global model trained on pooled data may underperform for clients with substantially different data characteristics. Personalization techniques attempt to address this by tailoring models to individual clients; however, directly personalizing often negates the benefits of collaboration. The paper likely explores how to effectively balance personalization with collaboration in the presence of heterogeneous data, possibly using a bilevel optimization approach where the inner level determines which clients to collaborate with and the outer level trains personalized models, leveraging the benefits of data diversity without sacrificing model performance. Efficient client selection is crucial, as incorporating all clients might introduce significant overhead and hinder overall learning efficiency. The method’s success depends on its ability to identify and exploit helpful collaborations while mitigating the negative impact of less relevant interactions, leading to improved accuracy and robustness.
Client Selection#
The concept of client selection in federated learning is crucial for efficiency and performance. Identifying which clients to participate in each round of training is key to mitigating communication overhead and ensuring model quality. The paper proposes a novel bilevel optimization approach where client selection is integrated into the overall training process. This is a significant departure from traditional methods that either select all clients or use static clustering techniques. The bilevel optimization framework allows for dynamic collaboration, adapting to the evolving relationships between clients based on gradient alignment. This adaptive approach is particularly beneficial in heterogeneous settings where client data distributions vary significantly. The resulting algorithm, COBO, offers theoretical convergence guarantees and demonstrated superior performance compared to baselines, especially in scenarios with high data heterogeneity. The pairwise nature of the client selection is another advantage; this avoids the limitations of clustering-based methods by not requiring the pre-determination of cluster number or centers.
Future Works#
Future work for this research could explore several promising avenues. Extending CoBo to handle more complex client relationships beyond pairwise interactions would significantly enhance its applicability to real-world scenarios. This might involve incorporating graph neural networks to model higher-order relationships between clients. Another critical area would be to incorporate formal privacy-preserving techniques to address the inherent privacy challenges of collaborative learning, especially when exchanging gradients between clients. Developing theoretical convergence guarantees for heterogeneous data distributions beyond the current cluster-based assumptions would strengthen the theoretical foundation. Additionally, empirical evaluation on a wider range of datasets and tasks, including those with varying levels of data heterogeneity and task similarity, is crucial to demonstrate CoBo’s robustness and generalizability. Finally, investigating the impact of different collaboration weight update strategies and step size selection could further optimize CoBo’s performance and efficiency.
More visual insights#
More on figures
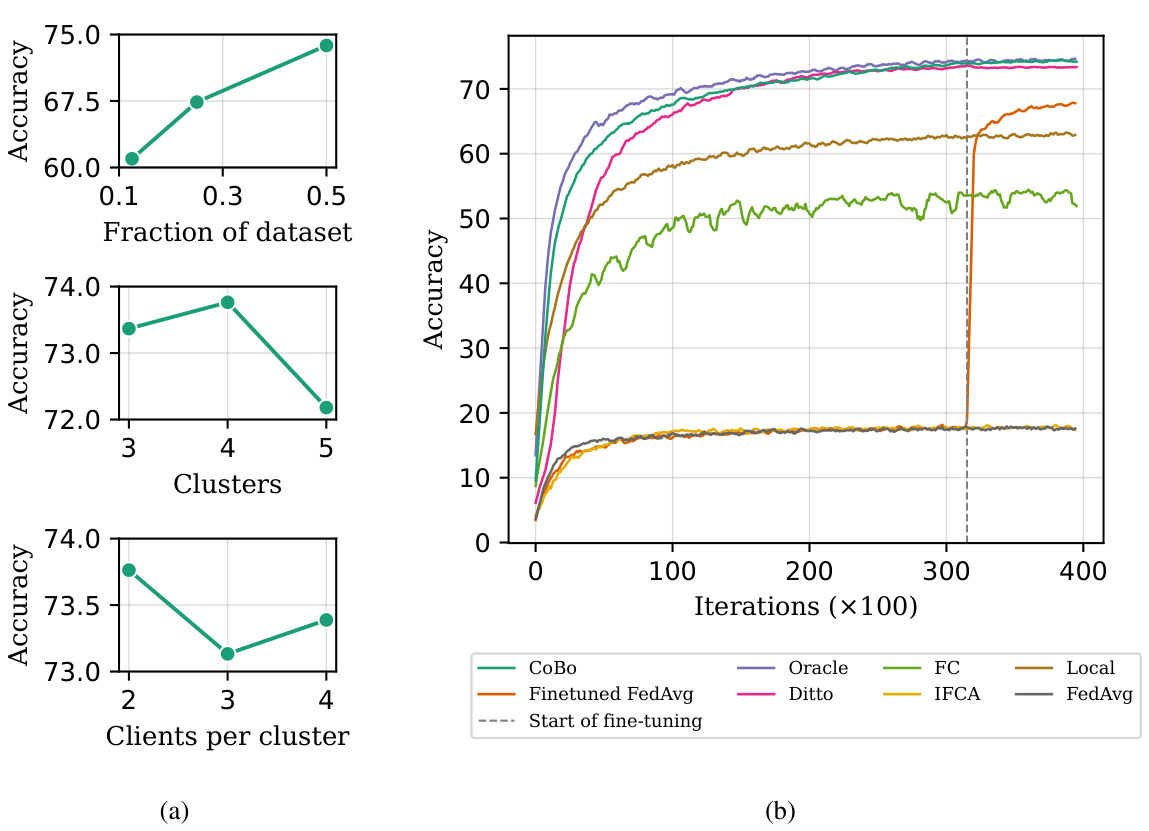
This figure shows the results of cross-silo experiments. (2a) demonstrates how the average accuracy changes based on the fraction of the dataset, number of clusters, and number of clients per cluster. (2b) compares the accuracy of personalized models trained using COBO against other collaborative learning baselines (FedAvg, Finetuned FedAvg, Ditto, FC, IFCA, Local, Oracle) over multiple iterations. The Oracle result represents the ideal performance achievable by applying FedAvg separately to each cluster.
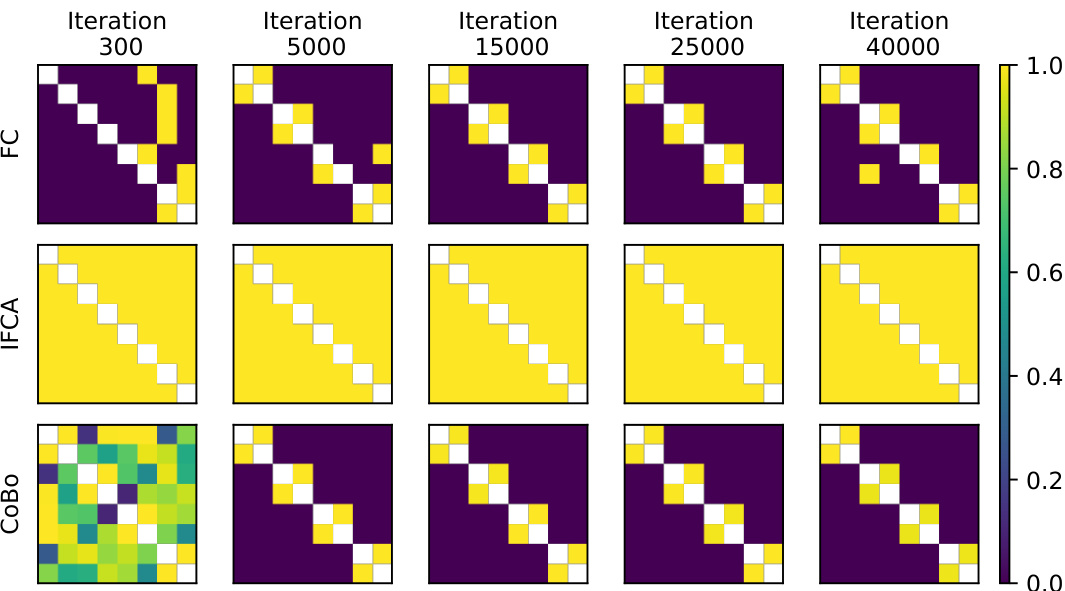
This figure compares the collaboration matrices learned by three different algorithms (Federated Clustering, IFCA, and COBO) at various stages of training during a cross-silo experiment with 8 clients. It visualizes how each algorithm determines the relationships between clients for collaboration. The oracle matrix (ideal solution) is a block diagonal matrix, indicating that clients within the same cluster should ideally collaborate more strongly than those in different clusters. COBO quickly converges to a collaboration matrix resembling the oracle, showing its effectiveness in identifying helpful collaborators. In contrast, IFCA shows full connectivity between all clients, while FC’s collaboration matrix is inconsistent and often deviates from the ideal structure, indicating these algorithms have difficulty in accurately identifying clusters for effective collaboration.
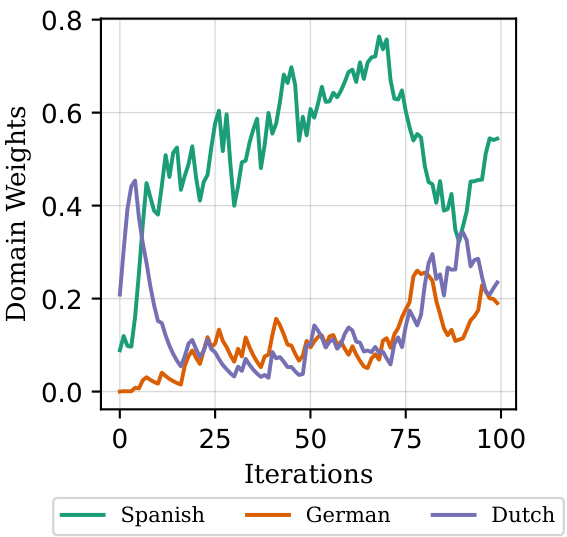
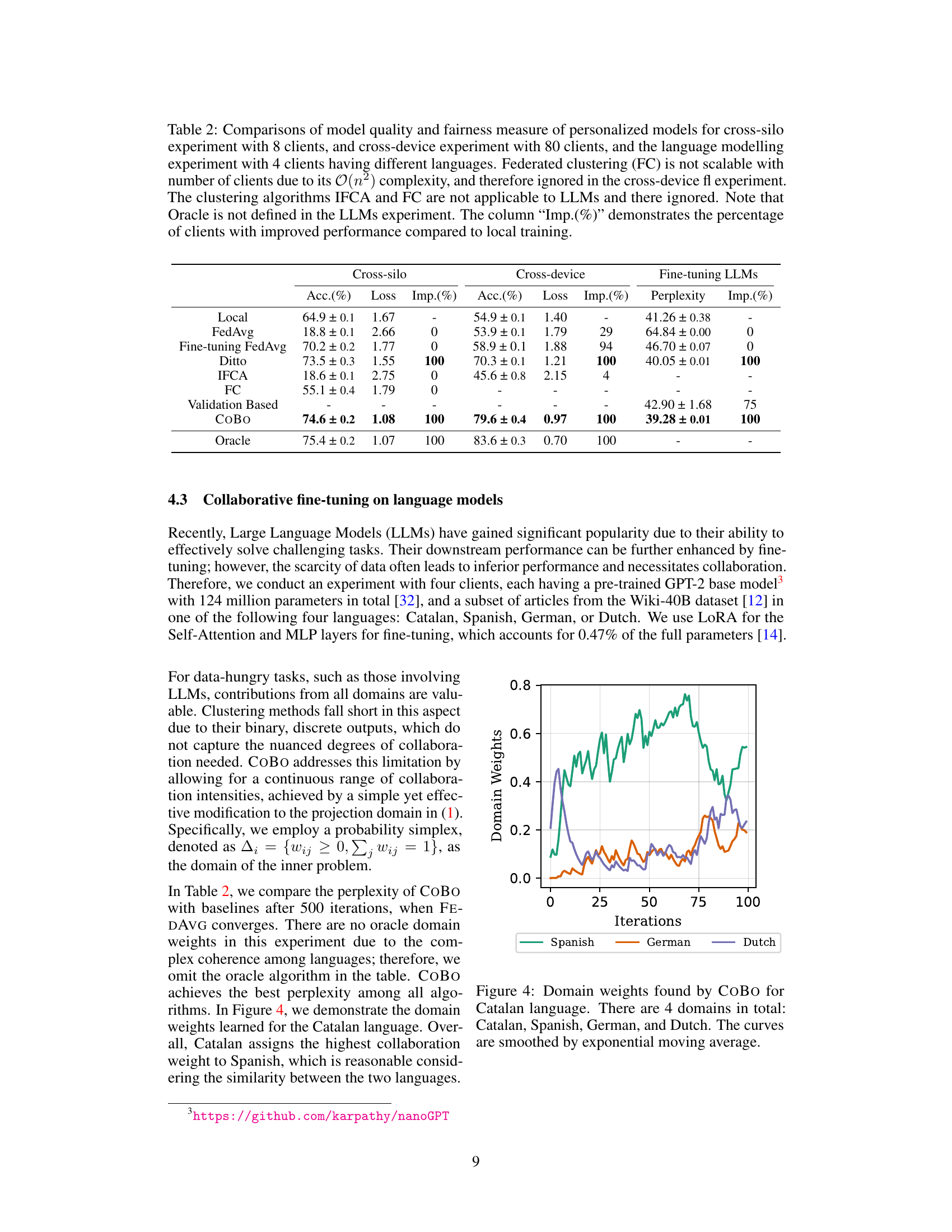
This figure shows the domain weights learned by the CoBo algorithm for the Catalan language during the language modeling experiment. The x-axis represents the number of iterations, and the y-axis shows the weight assigned to each of the four languages (Catalan, Spanish, German, and Dutch). The lines are smoothed using exponential moving averaging to better visualize trends. The figure illustrates that CoBo dynamically adjusts the collaboration weights between different languages based on their similarity and relevance to the target language (Catalan). The relatively high weight given to Spanish likely reflects its close linguistic relationship to Catalan. The weights for German and Dutch are lower, indicating less influence during the fine-tuning process.
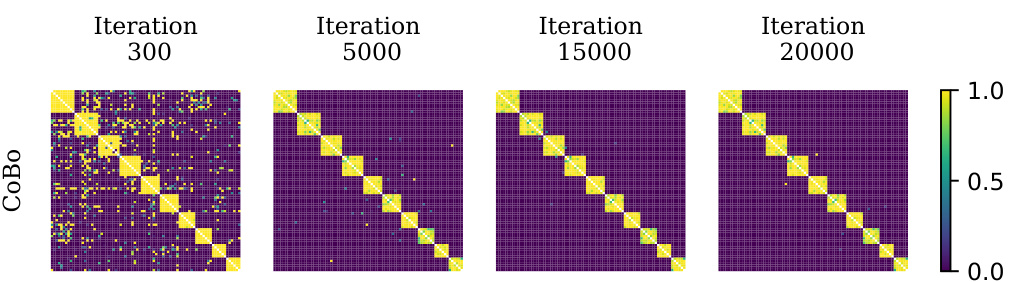
This figure shows the collaboration matrices learned by the CoBo algorithm at different stages (300, 5000, 15000, and 20000 iterations) during the cross-device experiment with 80 clients. The diagonal elements are masked for clarity. The oracle matrix (ideal collaboration structure) has a block diagonal form representing the 10 clusters of varying sizes (two clusters of size 6, two of size 7, and so on). The CoBo matrices progressively converge toward this oracle matrix, demonstrating its ability to effectively learn the optimal collaboration structure even in a large-scale, heterogeneous setting.
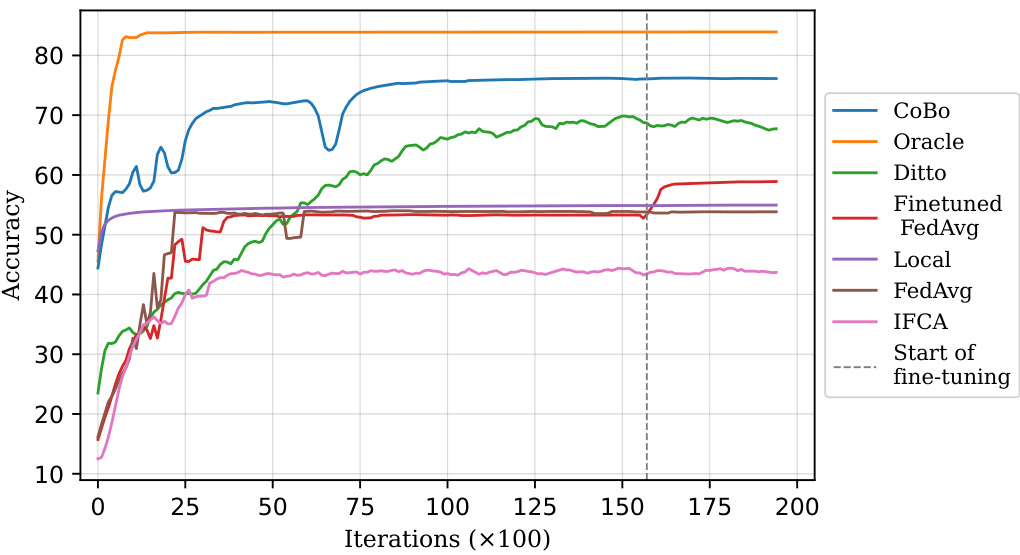
This figure presents results from cross-silo federated learning experiments. Subfigure (2a) shows how the average accuracy changes based on variations in the dataset fraction per client, the number of clusters, and the number of clients per cluster. Subfigure (2b) compares the accuracy of personalized models achieved by CoBo against other baseline methods, with an ‘Oracle’ representing the optimal performance achievable by using FedAvg on perfectly separated clusters.
Full paper#