↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current speech generation models, while advanced, often ignore human preferences, resulting in suboptimal speech quality. This is mainly due to a distribution gap between training and inference stages. This paper addresses this critical limitation.
SpeechAlign tackles this issue through an innovative iterative approach. It leverages preference optimization, continuously improving the model by contrasting preferred (golden) codec tokens against synthetic ones. This cycle, involving preference dataset construction and optimization, enhances the model’s ability to generate realistic and human-preferred speech. The method shows promising results in bridging the distribution gap and improving overall speech quality.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical gap in aligning speech generation models with human preferences. Current methods neglect preference optimization, leading to suboptimal results. SpeechAlign provides a novel iterative framework, bridging this gap and enabling continuous model improvement. This opens doors for future research in human-centered AI, especially within speech synthesis and related fields.
Visual Insights#

This figure visualizes the distribution gap between golden AR tokens (from real speech) and synthetic AR tokens (generated by the model) using t-SNE. The left panel shows a clear separation between the two distributions, highlighting the distribution gap. The right panel demonstrates that after applying the SpeechAlign method, the distribution gap is significantly reduced, as the synthetic AR tokens are now more aligned with the golden AR tokens.
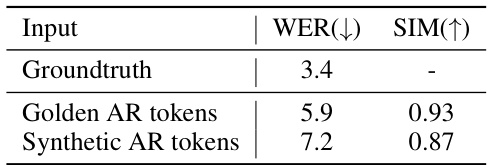
This table presents the results of a speech reconstruction experiment using a Neural Autoregressive (NAR) model. The model’s performance is evaluated using two different types of input: golden AR tokens (derived from real speech) and synthetic AR tokens (generated by an autoregressive model). The table shows that the model performs significantly better when using golden AR tokens, demonstrating a performance degradation caused by a distribution gap between the training and inference phases. WER (Word Error Rate) is used to quantify accuracy and SIM (Speaker Similarity) measures the consistency of timbre between the generated and prompt speech.
In-depth insights#
Codec Gap Analysis#
A hypothetical ‘Codec Gap Analysis’ section in a speech generation research paper would likely delve into the discrepancies between the distributions of codec tokens generated during training and inference phases. The core issue is that models are often trained using high-quality, human-curated “golden” codec tokens, while inference relies on automatically generated tokens which may not faithfully reflect the same distribution. This analysis would likely involve visualization techniques (e.g., t-SNE) to show the distinct clustering of golden versus synthetic tokens, quantitatively measuring the distributional difference using metrics like KL-divergence, and demonstrating the impact of this gap on downstream tasks like speech reconstruction or generation quality. The analysis would provide a strong rationale for the need for techniques like preference optimization, showing how bridging this codec gap is crucial for improving the overall realism and quality of generated speech. A robust analysis would ideally explore various aspects of the codec token distribution, examining whether particular token types or frequency ranges contribute disproportionately to the gap, and consider potential methods for mitigating the issue beyond simple preference learning.
SpeechAlign Method#
The SpeechAlign method is presented as an iterative self-improvement strategy designed to align the output distribution of speech language models with human preferences. It addresses a critical gap in existing codec language models where a mismatch occurs between training and inference distributions, negatively impacting performance. SpeechAlign cleverly leverages a preference codec dataset constructed by contrasting high-quality (‘golden’) codec tokens with those generated synthetically. This dataset avoids the need for extensive human annotation, a significant advantage. The method then employs preference optimization techniques, such as Chain-of-Hindsight or Direct Preference Optimization, to iteratively refine the model’s generation capabilities. This iterative process, involving the creation of a new preference dataset and subsequent model updates, aims to continuously bootstrap model performance, achieving stronger speech quality and naturalness. The approach demonstrates robust generalization across different models, including smaller-sized ones, highlighting its scalability and effectiveness. The iterative refinement is a key strength, enabling continuous improvement without the need for continuous manual intervention or large-scale data collection. This continuous self-improvement mechanism is a unique contribution and a significant advancement in speech language model training.
Iterative Refinement#
Iterative refinement, in the context of a research paper, likely describes a process of repeatedly improving a model or system through successive cycles of analysis and modification. This approach is particularly valuable when dealing with complex systems or those that are difficult to model perfectly from the outset. Each iteration builds upon the results of the previous one, allowing for a gradual refinement that accounts for previously overlooked factors or shortcomings. The iterative nature often necessitates well-defined metrics to evaluate progress and determine when the process has converged upon a satisfactory solution. A crucial aspect of iterative refinement is the feedback loop, which allows for adjustments based on observed performance, making it inherently adaptive. Careful consideration of resource constraints (computational, temporal, etc.) are necessary to avoid creating an unending loop of marginal improvements. This method is commonly employed in machine learning where models are trained and adjusted based on performance on training and validation sets. Ultimately, the strength of an iterative refinement strategy lies in its ability to tackle complexity, adapt to evolving data, and create robust solutions that are more likely to achieve their intended purpose.
Human Preference#
Incorporating human preferences is crucial for aligning AI systems with human values and expectations. The concept is multifaceted, encompassing not only explicit feedback but also implicit preferences inferred from user behavior and contextual cues. Effective integration of human preferences often requires a balance between direct elicitation (e.g., surveys, ratings) and indirect learning (e.g., reinforcement learning). Direct methods provide targeted feedback, while indirect methods leverage implicit signals to capture nuanced preferences. A major challenge lies in scaling preference gathering to handle diverse preferences and large datasets. Furthermore, ensuring the generalizability of learned preferences across diverse contexts and user groups is essential. Algorithmic techniques like reinforcement learning and preference optimization provide a means to incorporate human preferences directly into the model’s training or inference stage. However, such techniques require careful design to avoid biases and to ensure the alignment between the model and actual human values. Overall, effective incorporation of human preferences is crucial for developing AI systems that are both useful and beneficial for humanity.
Future Directions#
Future research could explore more nuanced human preference models that go beyond simple binary judgments, incorporating diverse aspects of speech quality (naturalness, clarity, expressiveness) and exploring individual preferences. Investigating preference optimization techniques for the non-autoregressive (NAR) models, currently neglected, is crucial for holistic codec language model improvement. Addressing scalability challenges in collecting human preferences, perhaps through more efficient sampling strategies or leveraging machine learning techniques, is key to broader applicability. Finally, it would be valuable to conduct comprehensive studies exploring the generalization capabilities of SpeechAlign to different languages, acoustic conditions, and unseen speakers, assessing its robustness in various real-world scenarios. Investigating the upper bound of iterative self-improvement and exploring methods to prevent performance degradation in later iterations is also important.
More visual insights#
More on figures
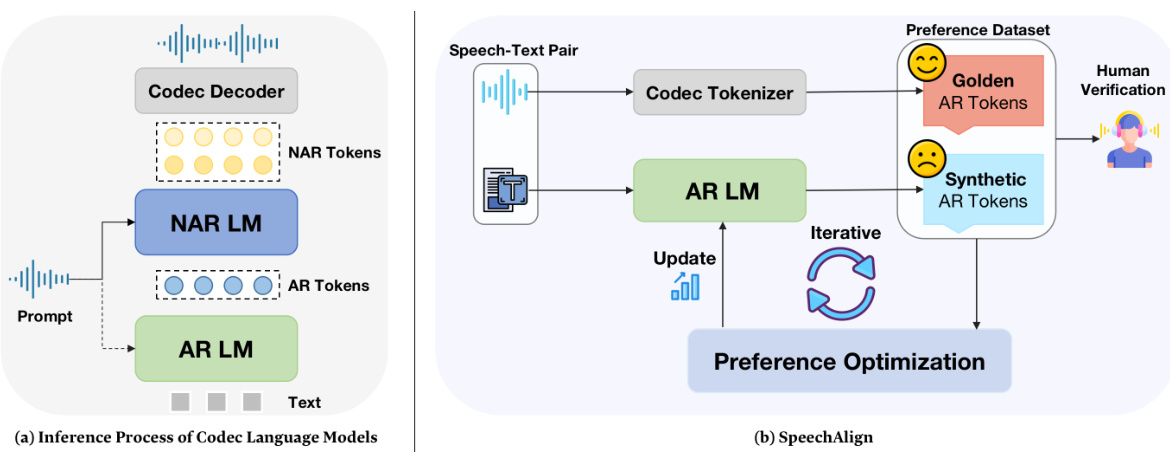
This figure shows the inference process of codec language models and the proposed SpeechAlign method. The left panel shows the standard process: text is fed into an autoregressive language model (AR LM) to generate autoregressive tokens (AR tokens); these tokens and a prompt are fed into a non-autoregressive language model (NAR LM) to produce non-autoregressive tokens (NAR tokens); finally, NAR tokens are decoded to generate speech. The right panel illustrates the SpeechAlign method, where a preference dataset is created comparing golden AR tokens (from real speech) to synthetic AR tokens (from the AR LM). This dataset is then used in preference optimization to iteratively improve the AR LM. The overall goal is to improve the alignment between the model’s generated speech and human preferences.

This figure presents a qualitative comparison of speech generated by different models using the zero-shot text-to-speech task. It shows the results of a human evaluation where listeners compared the speech quality produced by the baseline model (SFT), and several models that have undergone preference optimization (SpeechAlign-RLHF-PPO, SpeechAlign-DPO-Iter1, SpeechAlign-DPO-Iter2, SpeechAlign-DPO-Iter3, SpeechAlign-BoN, and SpeechAlign-CoH). The comparison is done for two datasets, LibriSpeech and VCTK. The results are displayed in terms of win, tie, and lose rates showing which model’s output was preferred by the human listeners. The visualization helps to understand how preference optimization strategies affect the qualitative aspects of speech generation, comparing to a model only trained with supervised finetuning.

This figure shows the results of zero-shot text-to-speech (TTS) experiments using different numbers of iterations of direct preference optimization (DPO). The left panel displays WER (Word Error Rate) and SIM (Speaker Similarity) scores. Lower WER indicates better accuracy, while higher SIM indicates better voice similarity to the reference speaker. The right panel shows QMOS (Quality Mean Opinion Score) and SMOS (Speaker Mean Opinion Score). Higher QMOS suggests better overall speech quality, and higher SMOS implies greater similarity between the generated and original speech in terms of speaker characteristics. The results indicate that the iterative DPO process improves various metrics of the generated speech, up to a certain point, after which performance might decrease slightly.

This figure shows the performance comparison of SpeechAlign with different preference data sizes and model sizes. The left subfigure shows that increasing the preference data size from 0 to 50k improves the model performance, but adding more data (250k) does not provide further improvement. This indicates an optimal size for the preference data. The right subfigure shows that SpeechAlign also works well with smaller models, improving the performance even with a relatively small model.
More on tables

This table presents the results of a human evaluation comparing speech reconstructed from two types of audio representations: golden AR tokens (ground truth) and synthetic AR tokens (model-generated). It shows the percentage of times human listeners preferred the speech generated from golden AR tokens (‘Golden Win’), found them equivalent (‘Tie’), or preferred the speech generated from synthetic AR tokens (‘Golden Lose’). The results demonstrate the preference for ground truth representations over model-generated ones.
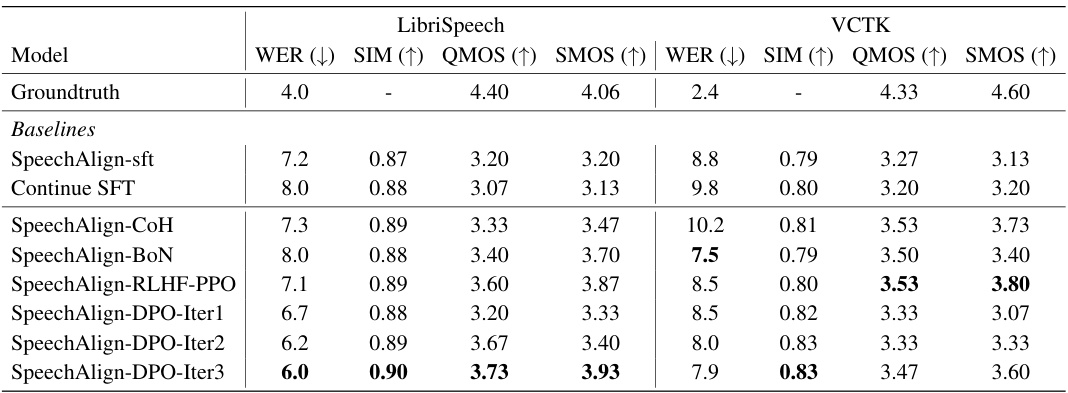
This table presents the results of a zero-shot text-to-speech experiment using several models on two datasets, LibriSpeech and VCTK. The models include a baseline (SpeechAlign-sft) and several variants using different preference optimization strategies (CoH, BoN, RLHF-PPO, and iterative DPO). For each model and dataset, the table shows the Word Error Rate (WER), Speaker Similarity (SIM), Quality Mean Opinion Score (QMOS), and Speaker Mean Opinion Score (SMOS). Lower WER is better, while higher SIM, QMOS, and SMOS are better. The ground truth results are included for comparison, providing a quantitative assessment of the performance of various models in generating speech from text without prior training on those specific datasets.
Full paper#

















