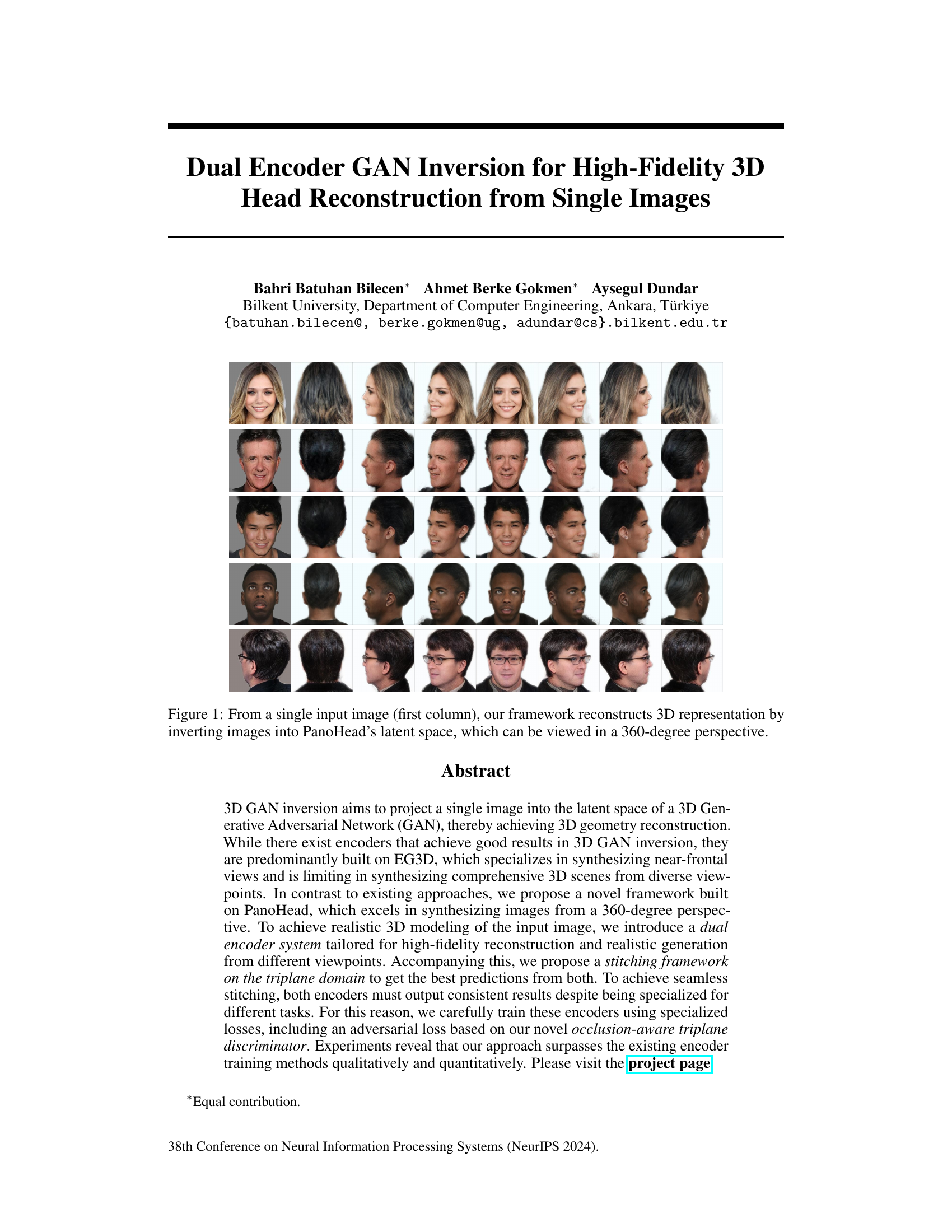
↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current 3D GAN inversion methods often struggle to generate realistic 3D head models from single images, especially when dealing with occluded regions. Existing techniques, predominantly built on EG3D, often prioritize near-frontal views, limiting their ability to synthesize comprehensive 3D scenes. This paper addresses these limitations.
This research introduces a novel dual encoder system built upon PanoHead, which excels at synthesizing images from a 360-degree perspective. The system includes a first encoder focusing on high-fidelity reconstruction of the visible input image and a second encoder specializing in generating realistic representations of occluded regions. A key innovation is the use of a novel occlusion-aware triplane discriminator, trained to enhance the realism of generated triplane structures, and a stitching framework that seamlessly integrates outputs from both encoders. Experiments show that this dual-encoder approach outperforms existing methods in terms of both fidelity and realism, demonstrating the effectiveness of the proposed approach.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to 3D head reconstruction from a single image, surpassing existing methods. It introduces a dual encoder system, improving accuracy and realism significantly. The occlusion-aware triplane discriminator and the stitching framework are key innovations, opening new avenues for high-fidelity 3D face generation and related applications in fields like virtual reality and animation.
Visual Insights#

This figure shows the results of three different encoders applied to the same set of input images. The first column shows the input images and the sixth column shows the result obtained by the dual encoder. The results of Encoder 1 and Encoder 2 are presented in between. The dual encoder combines the results of both Encoder 1 and Encoder 2, leveraging the strengths of each to produce the final reconstruction. Encoder 1 focuses on reconstructing high-fidelity facial images from the input, while Encoder 2 generates more realistic representations for invisible views. The figure demonstrates the effectiveness of the dual-encoder approach in achieving both high-fidelity reconstruction and realistic generation from different camera viewpoints.
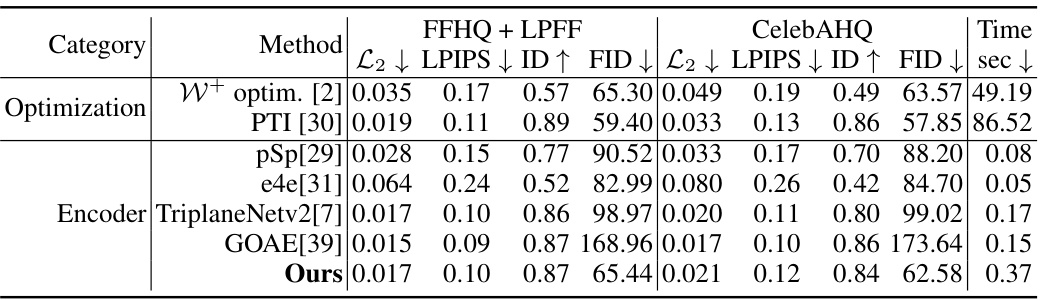
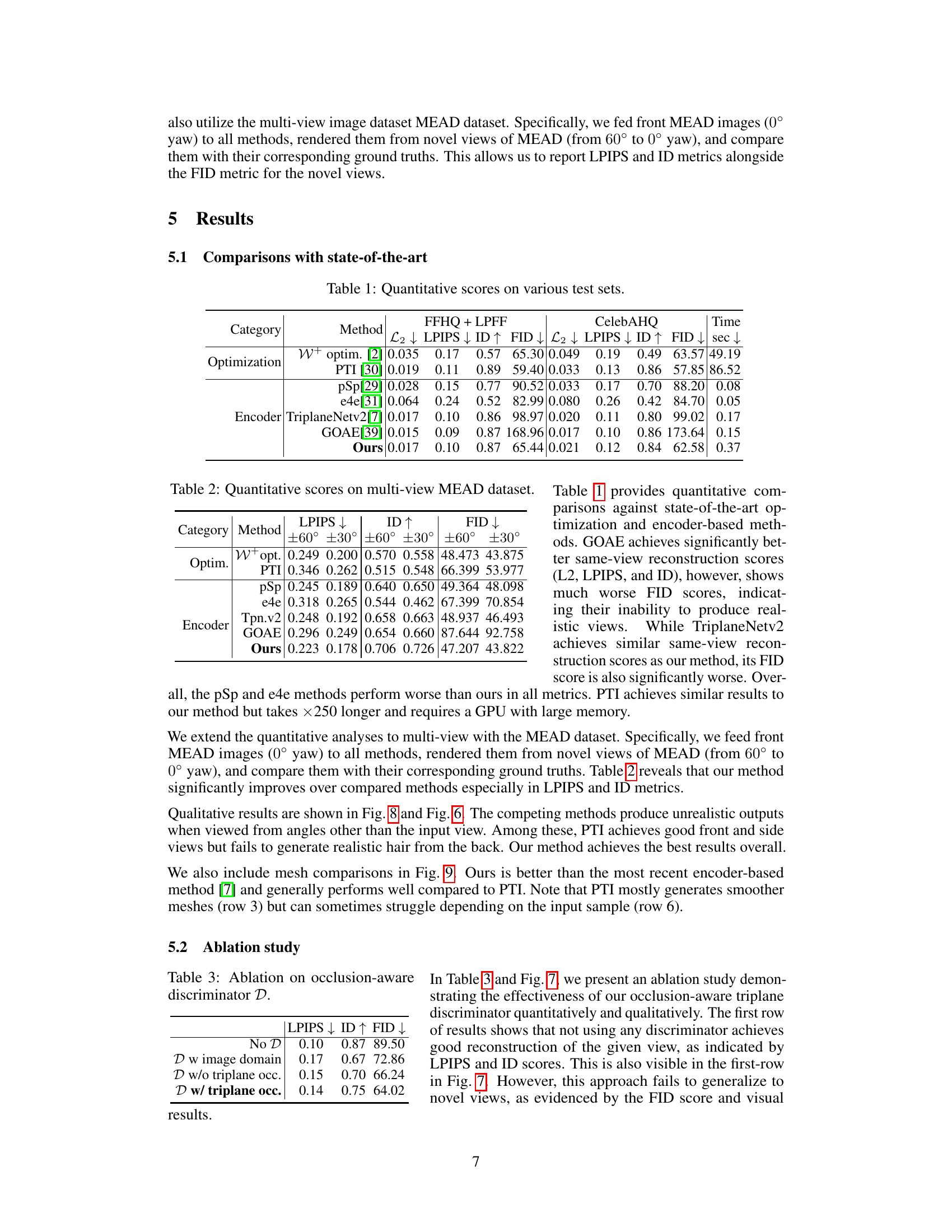
This table presents a quantitative comparison of different methods for 3D face reconstruction, including optimization-based and encoder-based approaches. The metrics used to evaluate the methods are L2, LPIPS, ID (Identity), and FID (Fréchet Inception Distance). The L2, LPIPS, and ID scores measure the fidelity of the reconstruction to the input image, while the FID score measures the quality and realism of the generated images from novel viewpoints. The table shows results on three datasets: FFHQ + LPFF, CelebAHQ and includes the time (in seconds) taken for each method. The results highlight the proposed method’s superior performance in terms of both reconstruction fidelity and novel-view generation quality.
In-depth insights#
Dual Encoder GAN#
The concept of a “Dual Encoder GAN” suggests a generative adversarial network (GAN) architecture enhanced by two distinct encoders. This setup likely aims to overcome limitations of single-encoder GAN inversion methods, particularly in complex 3D reconstruction tasks from a single image. One encoder might specialize in high-fidelity reconstruction of the visible parts of an image, focusing on accurate detail preservation. The second encoder could be tailored to generating realistic representations of occluded or invisible regions, crucial for achieving coherent 3D models. The combined output from both encoders would then feed into the GAN’s generator for producing a complete and realistic 3D model. This dual-encoder approach addresses the challenge of GAN inversion by handling both visible and invisible information streams efficiently, potentially achieving higher quality and more complete 3D reconstructions than traditional single-encoder methods. The use of a GAN framework further leverages the power of adversarial training to improve the realism and quality of the generated 3D output. The success of this approach hinges on careful design of the encoders, loss functions, and training strategies to ensure seamless integration and consistent outputs from both encoders.
Tri-plane Inversion#
Tri-plane inversion, in the context of 3D generative models, presents a unique challenge and opportunity. It involves the task of projecting a 2D image into the tri-plane latent space of a 3D generative model. This is more complex than inverting into a standard latent space because the tri-plane representation inherently encodes 3D geometry, requiring the inversion process to not only capture image features but also the underlying 3D structure. Successful tri-plane inversion is crucial for various downstream tasks, including novel view synthesis and 3D reconstruction. The main difficulty lies in the ambiguity of the mapping from 2D images to 3D structures. Many different 3D shapes could project to the same 2D image, making the inverse problem ill-posed. To address this, sophisticated methods often combine multiple loss functions, including adversarial losses, perceptual losses, and geometric consistency losses, to guide the model towards realistic and accurate 3D reconstructions. Another key aspect is the choice of the underlying generative model, since the complexity of the inversion process is often dictated by the model architecture itself. Models that explicitly represent 3D geometry, such as those using implicit representations, may present different challenges compared to voxel-based or mesh-based models. The development of efficient and accurate tri-plane inversion techniques is crucial for enabling a range of applications in computer vision and graphics, including high-fidelity 3D face reconstruction and interactive 3D content creation. Therefore, research in this area continues to focus on improving the accuracy, efficiency, and generalization capabilities of inversion methods.
Occlusion Handling#
Occlusion handling is a critical challenge in 3D face reconstruction from single images, as parts of the head are often hidden from the camera’s view. The effectiveness of any 3D reconstruction method hinges on how well it addresses occlusions. This paper’s approach employs a dual-encoder system. One encoder focuses on reconstructing the visible portion of the face, while a second encoder specializes in generating realistic estimations for the occluded areas. The ingenious use of an occlusion-aware triplane discriminator during training is a particularly noteworthy aspect. This discriminator is specifically trained to focus on occluded regions in the triplane representation of the face, thereby improving the realism of these areas without being unduly influenced by the visible portions. The training strategy, therefore, encourages a consistent output across both encoders, enabling seamless stitching of the generated views for a complete 3D model. This dual-encoder method, enhanced by the specialized discriminator, represents a significant advancement in handling occlusions during 3D face reconstruction. The stitching framework for merging the visible and invisible regions to create a consistent and realistic 3D representation is also a strength of the approach.
High-fidelity 3D#
The concept of “High-fidelity 3D” in this context likely refers to the paper’s goal of achieving highly realistic and detailed three-dimensional head reconstructions from single images. High-fidelity implies a strong emphasis on accuracy and visual quality, exceeding the limitations of previous methods. The 3D aspect signifies that the reconstruction is not just a 2D image but a complete 3D model, allowing for viewing from multiple angles. The paper likely addresses challenges in creating such high-quality 3D models, including handling occlusions (hidden areas of the head) and producing consistent detail across different viewpoints. Success would be measured by quantitative metrics (e.g., low reconstruction error) and qualitative assessments of the model’s visual realism and accuracy in representing the subject’s features.
Future Directions#
Future research could explore several promising avenues. Improving the fidelity and realism of generated 3D head models, especially in challenging poses and with diverse hair styles, is crucial. This requires further advancements in both the encoders and the generative model itself. Investigating alternative 3D representations beyond triplanes might unlock further enhancements in quality and efficiency. Developing more sophisticated loss functions tailored to the specific challenges of 3D GAN inversion, potentially incorporating perceptual metrics beyond LPIPS and addressing occlusions more effectively, could yield substantial improvements. Furthermore, exploring the application of this technique to other modalities like body reconstruction from single images, or extending the method to other GAN architectures beyond PanoHead, presents exciting possibilities. Finally, thorough investigation into the ethical implications of high-fidelity 3D face generation is essential to ensure responsible development and deployment of this technology.
More visual insights#
More on figures

This figure illustrates the architecture of PanoHead, a generative model used in the paper. It takes a random vector z and camera conditioning πmapping as input. A mapping network (M) transforms z into a latent code w (14x512). This code is then fed into the generator (G) which produces tri-grid triplanes. Finally, these triplanes are rendered using a volumetric neural renderer (R) with a rendering camera pose πrender to generate multiple 2D images representing different views of the 3D head.
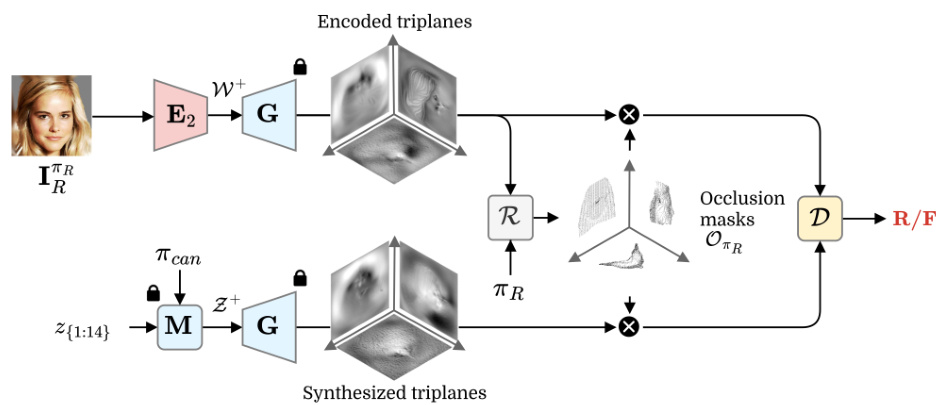
The figure illustrates the training process of an occlusion-aware triplane discriminator. Real samples are generated using PanoHead with sampled latent vectors Z+, while fake samples come from encoded images. To focus training on occluded regions and improve fidelity, the discriminator is trained only on features from these areas, minimizing the impact of visible regions like frontal views (TR).

This figure illustrates the inference pipeline of the proposed dual-encoder system for 3D head reconstruction. It takes a single input face image (IπR) as input. Two encoders (E1 and E2) process the image separately. Encoder 1 specializes in reconstructing the visible parts of the face from the input view (πR), while Encoder 2 focuses on generating realistic features for the occluded parts of the head. Both encoders utilize the generator (G) to produce triplane representations. These triplanes are then rendered (R) for the given view (πR) and a novel view (πnovel). The occlusion mask (OπR) is used to selectively combine the outputs of the two encoders; the visible regions from Encoder 1 and the occluded regions from Encoder 2 are merged to generate a complete triplane. This final triplane can be rendered to produce images from any viewpoints, enabling a full 360-degree reconstruction.

This figure shows a comparison of the results obtained using three different encoders: Encoder 1, Encoder 2, and the Dual encoder. The first and sixth columns display the input images. The remaining columns show the 3D head reconstruction results from different viewpoints (frontal, profile, and back views) generated by each of the three encoders. This visualization highlights the strengths and weaknesses of each encoder, demonstrating the improved fidelity and realism achieved by the dual encoder approach, which combines the outputs of Encoder 1 and Encoder 2 to achieve a more complete and accurate 3D model.

This figure presents a visual comparison of the results obtained using three different methods for 3D head reconstruction: Encoder 1, Encoder 2, and the proposed Dual Encoder method. The first and last columns show the input images. Each row represents a different subject, and each subsequent column shows the 3D reconstruction of that subject from different viewpoints using the three different methods. The results demonstrate the effectiveness of the Dual Encoder approach in producing more realistic and complete 3D reconstructions compared to the individual Encoder methods.

This figure shows the qualitative results of an ablation study on the occlusion-aware discriminator. It compares the results of using no discriminator, a discriminator trained on the image domain, a discriminator trained on the triplane domain without occlusion awareness, and a discriminator trained on the triplane domain with occlusion awareness. The results demonstrate the improved image quality and realism achieved by using the occlusion-aware discriminator. Specifically, it showcases better generation of hair and overall detail when utilizing this method.

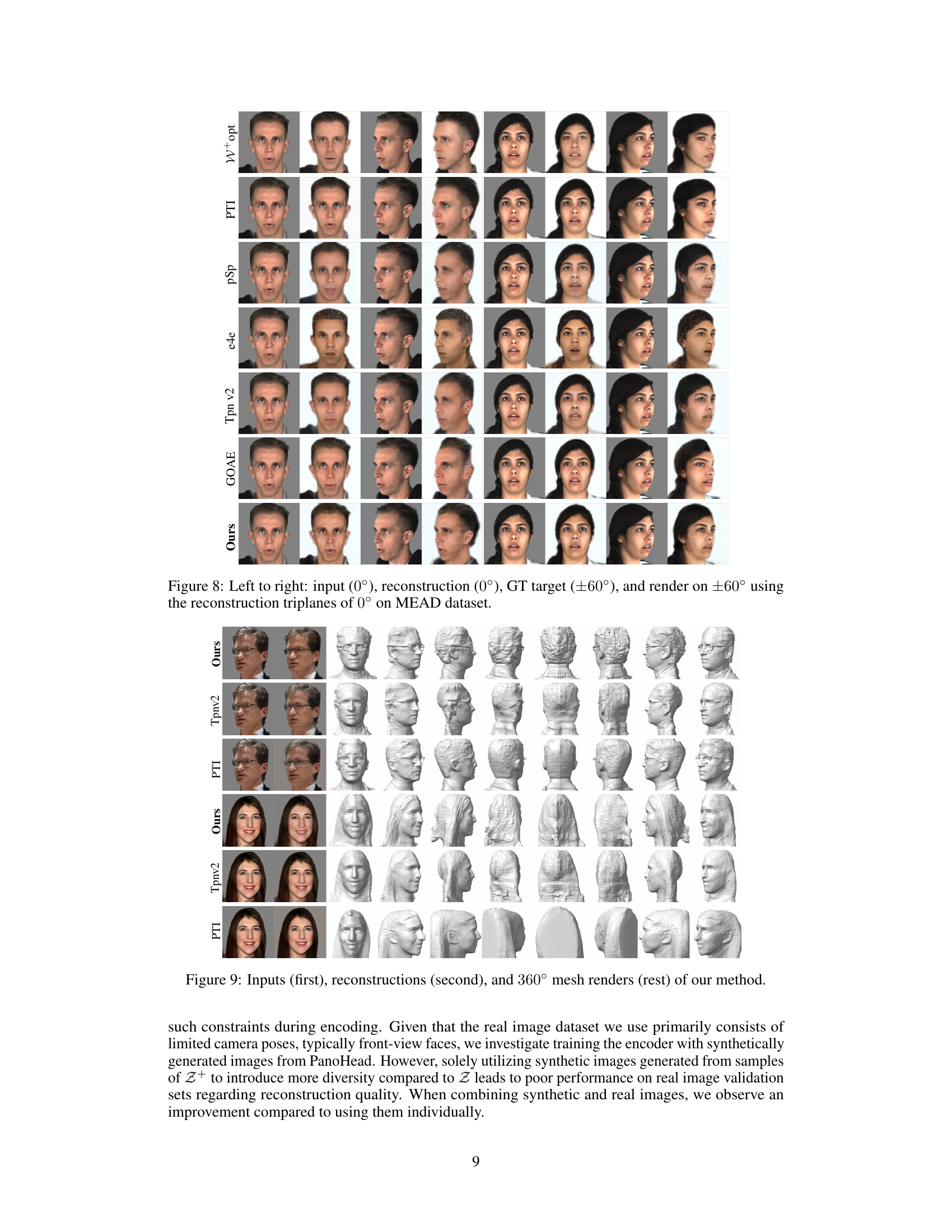
This figure presents a qualitative comparison of the proposed method against several state-of-the-art techniques for 3D face reconstruction from a single image. It shows results from various viewpoints for multiple subjects, highlighting the differences in reconstruction fidelity, realism, and ability to handle novel views. Each row displays results for a different method (W+opt, PTI, pSp, e4e, TriplaneNetv2, GOAE, and the proposed method), with the input image in the first column, followed by reconstructions from several viewpoints.

This figure showcases the results of the proposed dual encoder method for 3D head reconstruction. The first column displays the input images. The second column shows the 2D reconstruction generated by the model. The remaining columns present the 360° mesh renderings generated from different viewpoints. This demonstrates the model’s ability to reconstruct a high-fidelity 3D head model from a single image and to generate realistic views from various angles.

This figure shows the results of the proposed 3D head reconstruction method. For each subject, the first image is the input image; the remaining images are the generated 3D head model views from different angles, demonstrating the method’s ability to reconstruct a 3D representation from a single 2D image.

This figure shows the results of three different encoders on several input images. The first column shows the input images. The second, third, and fourth columns display the results from Encoder 1, Encoder 2, and the dual encoder approach respectively. The dual encoder combines outputs from Encoder 1 (which focuses on high-fidelity reconstruction of the input view) and Encoder 2 (which focuses on generating realistic invisible views) to produce a more comprehensive 3D reconstruction.

This figure showcases the results of the proposed dual encoder method on a diverse set of input images. The first column displays the input images, featuring individuals of various ethnic backgrounds and with poses that present challenges for 3D reconstruction (e.g., extreme angles, occlusions). The second column shows the reconstructed images by the model. The remaining columns show the 360-degree views generated by the model from the reconstructed representation. This provides a comprehensive view of the generated 3D head model from various angles, demonstrating the ability of the model to accurately reconstruct the facial features and details despite varying poses and ethnicities.

This figure showcases a comparison of 3D head reconstruction results from three different methods: Encoder 1, Encoder 2, and the proposed Dual Encoder. Each row represents a single input image (shown in the first column), with the subsequent columns displaying the 3D reconstruction results from various viewpoints (angles) generated by each method. The results highlight the strengths and weaknesses of each approach in terms of reconstruction fidelity, realism of generated views, and handling of occluded areas. The Dual Encoder aims to combine the strengths of Encoder 1 (high-fidelity reconstruction of the input view) and Encoder 2 (realistic generation of unseen views).

This figure presents a qualitative comparison of the proposed method’s performance against several state-of-the-art techniques for 3D head reconstruction. The results show the reconstructed images from different viewpoints for multiple subjects. Each row represents a different method (W+ opt., PTI, pSp, e4e, TriplaneNetv2, GOAE, and the proposed method), with the input image on the far left. The subsequent images in each row demonstrate the reconstruction quality from various angles. This allows for a visual assessment of each approach’s ability to reconstruct high-fidelity 3D head models from a single input image.

This figure shows a comparison of the results obtained using three different methods for 3D head reconstruction from a single image: Encoder 1, Encoder 2, and the proposed Dual encoder. The first and last columns display the input images. Each row shows the reconstruction of the same input image using each of the three methods, across various viewpoints (different camera poses) generated from the trained model. The results illustrate that the Dual encoder approach combines the strengths of both Encoder 1 (high-fidelity reconstruction of the input view) and Encoder 2 (realistic generation of invisible views) to provide a superior overall 3D reconstruction.

This figure shows a comparison of the results obtained using three different methods: Encoder 1, Encoder 2, and the proposed Dual Encoder method. The first and sixth columns display the input images. The remaining columns illustrate the generated images from different viewpoints for each method. This visual comparison highlights the strengths and weaknesses of each method, demonstrating how the dual encoder combines the best aspects of the individual encoders to produce higher-fidelity and more realistic 3D head reconstructions from various angles.

This figure shows a comparison of the results obtained using three different methods for 3D head reconstruction from a single image: Encoder 1, Encoder 2, and the proposed Dual Encoder. The first and last columns display the input images. The other columns show the reconstructed views from various angles using each method. This allows for a visual assessment of the strengths and weaknesses of each approach in terms of reconstruction fidelity and realism across different viewpoints.

This figure shows a comparison of the results obtained using three different methods: Encoder 1, Encoder 2, and the proposed Dual Encoder. The first and last columns display the input images. Each row represents a different subject, showcasing the 360-degree head reconstruction from various viewpoints. The results highlight the strengths and weaknesses of each approach; Encoder 1 excels in high-fidelity frontal views but struggles with other viewpoints, Encoder 2 generates more realistic but less accurate images, and the Dual Encoder combines their strengths for superior results.

This figure shows a comparison of the results obtained using three different methods: Encoder 1, Encoder 2, and the proposed dual encoder approach. The first and sixth columns display the input images. Subsequent columns showcase the 360-degree renderings generated by each method from multiple viewpoints. This visualization allows for a qualitative assessment of the performance of each approach in terms of image fidelity and realism across various viewing angles.

This figure presents a comparison of the proposed method’s performance against several competing methods for 3D head reconstruction. The results are visualized from multiple viewpoints (front, various side, and back views) for each method applied to the same set of input images. This allows a qualitative assessment of reconstruction accuracy, realism, and consistency across viewpoints.

This figure presents a qualitative ablation study demonstrating the impact of the occlusion-aware discriminator (D) on the overall quality of the 3D head reconstruction. The top row shows results with no discriminator, the second row with a discriminator trained on the entire image domain, the third row with a discriminator trained only on visible regions, and the bottom row with the proposed occlusion-aware discriminator. Each row shows the input image and several views of the reconstructed 3D head, illustrating how the different discriminator training strategies affect both the fidelity of the frontal view and the realism of the novel views.
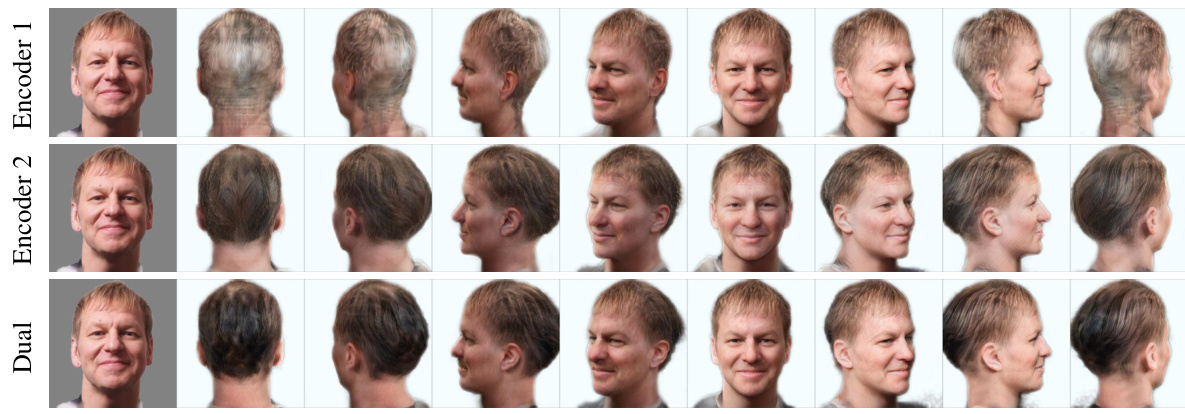
This figure shows the visual comparison of 3D head reconstruction results using three different methods: Encoder 1, Encoder 2, and the proposed dual encoder approach. The first and last columns display the input images. The remaining columns demonstrate the 3D reconstruction from different viewpoints for each method. Encoder 1 focuses on high-fidelity reconstruction of the input image, but results are less realistic from other views. Encoder 2 generates more realistic results for unseen views, but with some loss of fidelity to the input. The dual encoder combines the strengths of both, aiming for both high fidelity to the input and realistic rendering across multiple views.

This figure shows the 3D head reconstruction results of three different methods: Encoder 1, Encoder 2, and the Dual Encoder. Each row represents a different reconstruction technique. The first column shows the input image. The remaining columns depict the results from various viewpoints obtained by each method. The dual encoder combines the results of Encoder 1 and Encoder 2 to achieve high-fidelity and realistic results from both visible and invisible views.

This figure showcases a comparison of the results obtained using three different methods: Encoder 1, Encoder 2, and the Dual encoder approach. Each row represents the reconstruction of a head from a single input image (shown in the first and sixth columns). Encoder 1 focuses on high-fidelity reconstruction of the input view but may struggle with other viewpoints. Encoder 2 aims for generating realistic views from unseen perspectives but may not achieve the same level of detail in the main view. The Dual encoder approach combines the strengths of both methods, aiming for both high fidelity and realistic rendering from various angles.
More on tables

This table presents a quantitative comparison of different methods for 3D head reconstruction on the MEAD dataset, focusing on multi-view performance. It shows the LPIPS, ID, and FID scores for each method at ±30° and ±60° yaw angles from the frontal view. Lower LPIPS and FID scores indicate better performance, while higher ID scores reflect better identity preservation.

This table presents the results of an ablation study on the occlusion-aware triplane discriminator. It shows the impact of using different discriminator configurations on the model’s performance, measured by LPIPS, ID, and FID scores. The different configurations include using no discriminator, a discriminator operating on the image domain, a discriminator without triplane occlusion, and the proposed occlusion-aware triplane discriminator. The results demonstrate the effectiveness of the proposed occlusion-aware discriminator in improving the overall quality of the generated images.

This table presents a quantitative comparison of different methods for 3D GAN inversion on various datasets (FFHQ + LPFF, CelebAHQ). The methods are categorized into optimization-based and encoder-based approaches. Metrics include L2, LPIPS, ID (identity), and FID (Fréchet Inception Distance) to assess the quality of reconstruction and generation. Time taken for each method is also given.
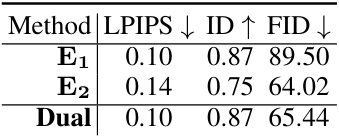
This table presents the ablation study on the dual-encoder. It compares the performance of three different models: Encoder 1, Encoder 2, and the Dual encoder in terms of LPIPS, ID, and FID scores. The results show that the dual encoder achieves a good balance between high fidelity reconstruction (similar to Encoder 1) and good novel view generation (similar to Encoder 2).

This table presents a quantitative comparison of different methods for 3D face reconstruction on various datasets (FFHQ+LPFF, CelebAHQ). The metrics used include L2 loss, LPIPS (Learned Perceptual Image Patch Similarity), ID (identity) score, and FID (Fréchet Inception Distance). Lower scores for L2 and LPIPS indicate better reconstruction quality, while higher ID and FID scores (for the latter on novel views) also indicate better performance. The ‘Time’ column shows the inference time in seconds for each method.
Full paper#