↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating realistic 3D human head models is crucial for various applications, but existing methods often rely on large, expensive 3D datasets or lack the ability to generate diverse facial expressions while maintaining identity consistency. Current approaches also struggle to achieve detailed textures and geometries from limited input data. These limitations hinder progress in creating realistic virtual characters or avatars for different fields.
This paper introduces ID-to-3D, a novel method that addresses these challenges. ID-to-3D leverages score distillation sampling and task-specific 2D diffusion models to generate expressive, identity-consistent 3D human heads from limited input data, such as a small set of images. By employing a compositional approach and a lightweight model architecture, the method achieves high-quality results without needing large 3D scanned datasets. The findings demonstrate significant improvements in geometry and texture detail, and an unprecedented level of identity consistency across various expressions.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to generating high-quality 3D human head assets from limited input data, addressing a key challenge in fields like digital avatars, gaming, and virtual reality. The method’s efficiency and high-quality output have significant implications for researchers and practitioners, opening new avenues for research in 3D face modeling, image synthesis, and related areas. Its focus on identity consistency and expressiveness also addresses limitations in current approaches, making it a valuable contribution to the field.
Visual Insights#

This figure shows the results of the ID-to-3D model. The left side displays renderings of 3D human heads generated by the model, showcasing high-quality textures and realistic appearance. The middle section shows the input images, which are casually captured images of the individuals in the wild, not studio quality photos. The rightmost section provides the normal maps for the generated heads. The figure demonstrates the model’s ability to create high-quality, realistic 3D human heads from low-quality input images.
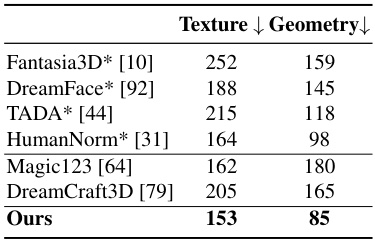
This table presents a quantitative comparison of different methods for generating 3D heads, focusing on the quality of both the geometry and texture. The Frechet Inception Distance (FID) score, a common metric for assessing the quality of generated images, is used to evaluate the realism of the generated 3D heads’ textures and geometries. Lower FID scores indicate better quality, meaning the generated assets are more realistic and closer in style to real-world examples. The table includes results from several state-of-the-art methods (indicated by an asterisk (*)) that use Score Distillation Sampling (SDS) from text prompts, along with the results from the proposed ID-to-3D method. Comparing the FID scores allows one to see how the proposed method performs against the others in creating high-quality 3D head assets.
In-depth insights#
ID-Guided 3D Heads#
The concept of “ID-Guided 3D Heads” presents a significant advancement in 3D human modeling. It suggests a paradigm shift from generic 3D head generation towards personalized, identity-consistent models. This approach leverages individual characteristics, likely derived from images or other identifying data, to create highly realistic 3D head models that accurately reflect a specific person’s features. The “ID-Guidance” aspect is key, ensuring generated heads maintain consistent identity across various expressions and poses, thereby solving challenges of identity drift in previous methods. This technology has broad implications, spanning virtual reality, gaming, and digital entertainment, creating realistic avatars and personalized virtual representations. The success of this method hinges on robust feature extraction and sophisticated generative models that can accurately capture and reproduce individual nuances. However, ethical considerations regarding privacy and potential misuse of such technology must be addressed. The ability to generate highly realistic 3D models raises concerns about deepfakes and identity theft, highlighting the need for responsible development and deployment strategies.
Score Distillation#
Score distillation, in the context of generative models, is a powerful technique that leverages pre-trained models to guide the generation of new data. It bridges the gap between the high-quality output of large diffusion models and the challenges of training on limited 3D data. By using score-based diffusion models as priors, score distillation enables the generation of detailed and realistic 3D assets, even with limited training data. The approach is compositional, allowing for disentangled control over identity and expression, and offering remarkable flexibility in creating diverse and high-fidelity outputs. The inherent challenge lies in aligning the distribution of generated 3D asset renderings with the target distribution created by the 2D diffusion model, often requiring careful decomposition of the optimization objective into more manageable sub-objectives for geometry and texture generation. This method avoids the need for large, difficult-to-acquire 3D datasets, making it a very efficient approach to 3D asset generation. The effective use of score distillation for 3D modeling hinges on thoughtful consideration of the target distributions, guidance strategy, and careful handling of lighting and camera conditions in rendering.
Compositional Approach#
A compositional approach in the context of 3D head generation likely refers to a method that breaks down the complex task into smaller, more manageable sub-problems. Instead of directly generating a complete 3D head as a single unit, a compositional approach might involve generating separate components such as geometry, texture, and expression independently, and then combining them. This modularity offers several advantages. First, it simplifies the training process, allowing for the use of specialized models for each component. Second, it enhances controllability, enabling independent manipulation of individual attributes. Third, it promotes efficiency, as smaller models generally require fewer resources and converge faster. However, such an approach introduces new challenges. Careful design is required to ensure seamless integration of the components, avoiding visual artifacts and maintaining consistency across different attributes. The effectiveness of a compositional approach heavily depends on the choice of component representation and the method of integration. For example, using parametric representations for each component can help ensure smooth transitions and preserve consistency, but selecting appropriate parameterizations can be a challenging task. Ultimately, the success of a compositional approach hinges on balancing the advantages of modularity and control with the complexity of component integration.
Expressive 3D Avatars#
Expressive 3D avatars represent a significant advancement in digital character creation, bridging the gap between static models and truly lifelike representations. High-quality 3D models are crucial, not only for visual appeal, but also for enabling realistic interactions and immersive experiences in virtual and augmented reality applications. The ability to generate expressive avatars that authentically convey emotions and personality is a major step towards more engaging and believable virtual interactions. Real-time performance and efficient generation methods are key challenges, particularly for applications requiring quick turnaround times, such as video games and digital filmmaking. Data-driven approaches are promising, leveraging machine learning to learn from large datasets of human faces and expressions. However, ethical considerations are paramount, particularly regarding the potential for misuse in creating deepfakes or for perpetuating biases present in the training data. Future research should focus on developing more efficient and robust generation techniques, along with methods to mitigate ethical concerns and enhance inclusivity in the generation of expressive 3D avatars.
Future Directions#
Future research directions for ID-to-3D could explore improving the efficiency and scalability of the model, enabling real-time generation of 3D avatars. This could involve exploring more efficient architectures and optimization techniques. Another area of focus could be enhancing the expressiveness and realism of the generated avatars, potentially by incorporating more sophisticated models of facial expressions, emotions and hair, or using higher-resolution datasets for training. The current reliance on pre-trained 2D diffusion models could be addressed by developing dedicated 3D diffusion models for head generation, potentially yielding improved 3D fidelity and greater control over the generative process. Furthermore, the model’s performance on individuals with diverse ethnicities and facial features needs further investigation and enhancement for improved inclusivity and representational diversity. Finally, exploration of techniques for direct manipulation of generated 3D head assets would be a valuable extension of the current work. This could range from simple editing functionalities to enabling full-fledged avatar rigging and animation.
More visual insights#
More on figures
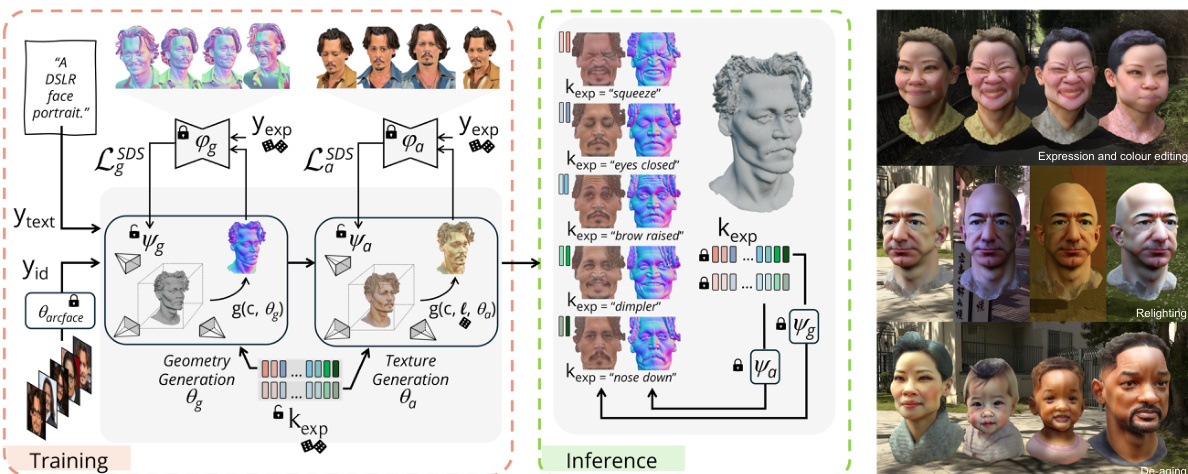
This figure illustrates the overall pipeline of ID-to-3D, a method for generating expressive 3D human head avatars. The left panel shows the training and inference stages. During training, a two-stage Score Distillation Sampling (SDS) pipeline optimizes 3D geometry and texture using ArcFace embeddings for identity and text for expression. Random lighting and expressions are also used. Inference involves extracting high-quality identity-aware and expressive 3D meshes. The right panel displays examples of ID-consistent 3D heads generated by the method, highlighting its ability to support relighting, editing, and physical simulation.

This figure shows a qualitative comparison of different 3D face generation methods, including the proposed ID-to-3D model. It compares the results of several state-of-the-art text-to-3D and image-to-3D methods against the proposed ID-to-3D approach. The figure highlights the high geometric quality and realistic textures achieved by ID-to-3D using only 5 input images. The normal maps of the generated 3D faces are shown to visualize the geometry quality.
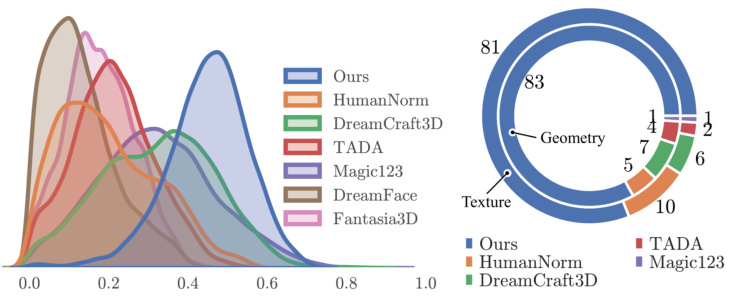
This figure shows a comparison of different methods for generating 3D heads, specifically focusing on identity preservation and quality of generated textures and geometry. The left panel displays the distribution of identity similarity scores for different methods, illustrating how well each method preserves the identity of the input image. The right panel presents the results of a user preference survey comparing the quality of textures and geometry generated by each method.

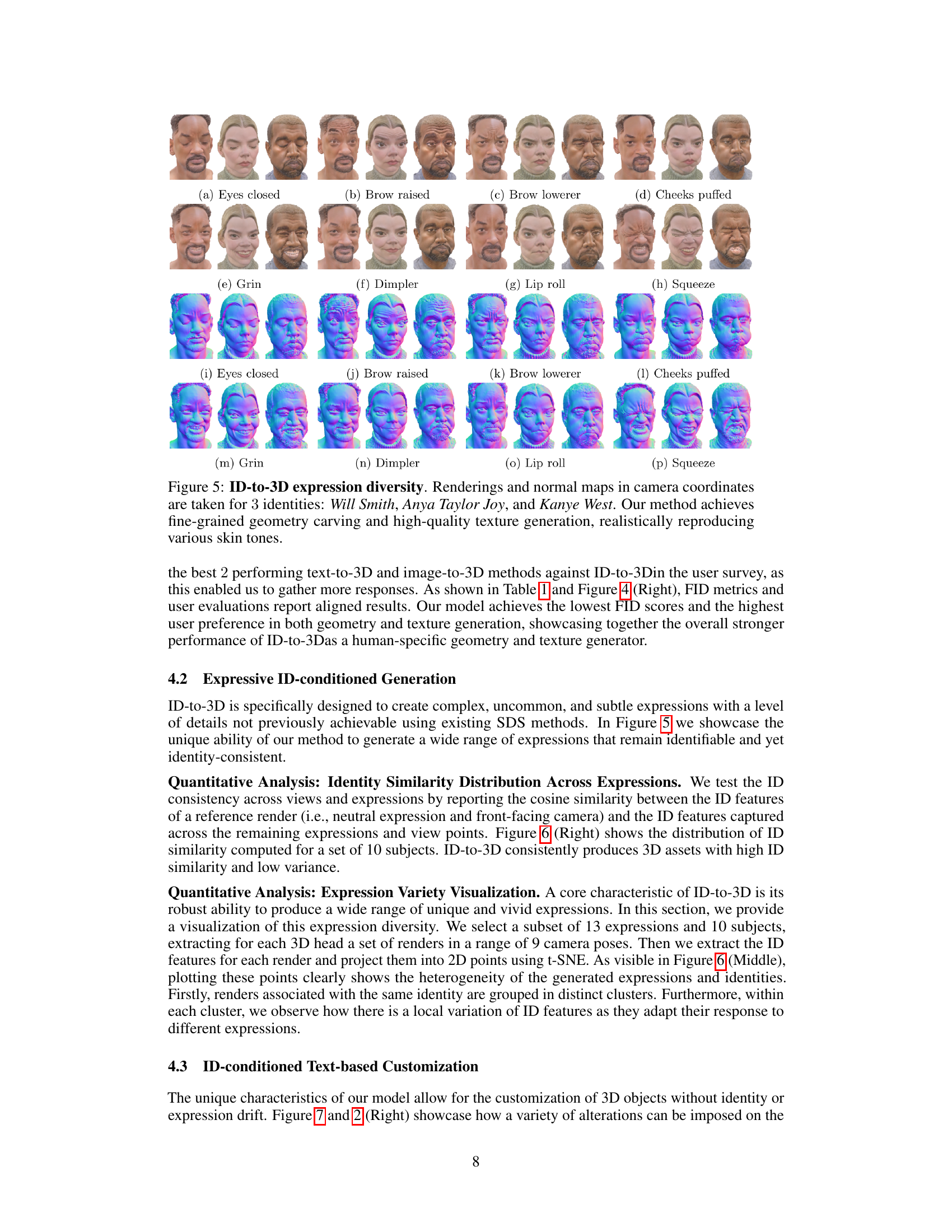
This figure demonstrates the ability of the ID-to-3D model to generate a wide variety of realistic facial expressions while maintaining identity consistency. It shows renderings and normal maps for three different individuals (Will Smith, Anya Taylor-Joy, and Kanye West), each displaying eight distinct expressions. The high-quality textures and fine-grained details highlight the model’s ability to capture subtle nuances in facial features.

This figure demonstrates the expressiveness and identity consistency of the ID-to-3D model. The left panel shows example renders of various expressions for two individuals. The middle panel uses t-SNE to visualize the clustering of ID embeddings based on various expressions and camera poses, showing clear separation of identities and expressions. The right panel shows the distribution of identity similarity scores for various expressions, highlighting the model’s ability to maintain consistent identity.

This figure shows the results of identity-consistent editing using ID-to-3D. The left side displays de-aged 3D heads generated using different identity conditioning and the text prompt ‘…as a cute baby’. Normal maps are shown alongside photorealistic renderings. The right side demonstrates geometry and texture editing using text prompts, highlighting ID-to-3D’s ability to modify appearance and geometric features while maintaining identity consistency.

This figure demonstrates the ability of the ID-to-3D model to perform identity-consistent editing based on rich textual prompts. It shows three example identities, each with three variations generated using detailed descriptions that specify aspects like hair color, style, and even fantastical elements (e.g., Dragonborn features). The results highlight the model’s capability to make detailed, consistent modifications to the generated 3D head models, showing a combination of photorealistic renderings and normal maps for each variation.
Full paper#