↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Audio-visual learning struggles with efficiently integrating information from multiple modalities, especially when data is noisy or incomplete. Existing approaches often focus on fixed strategies for combining audio and visual information, leading to suboptimal performance in diverse scenarios.
This paper introduces AVMoE, a novel method that uses a Mixture of Experts architecture. AVMoE employs unimodal and cross-modal adapters as experts, with a lightweight router to dynamically allocate weights. Experiments on several benchmarks show that AVMoE outperforms other methods, highlighting its effectiveness and robustness in handling missing or inconsistent modality information.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in audio-visual learning due to its novel approach of using a Mixture of Experts (MoE) to enhance the flexibility and efficiency of parameter-efficient transfer learning. The superior performance demonstrated across multiple tasks and its robustness to variations in input data make it highly relevant to current research trends. The work opens up avenues for developing more adaptive and efficient audio-visual models, especially in real-world scenarios with noisy or incomplete data.
Visual Insights#

This figure illustrates a scenario where the video and audio labels don’t perfectly align. The video shows a basketball game with events like basketball playing, cheering, and clapping. However, the corresponding audio primarily contains speech and cheering, omitting the sound of clapping and the distinct sound of a basketball bounce. This discrepancy highlights the challenge of audio-visual learning where modalities may not always perfectly correlate. This example motivates the need for a flexible approach that can handle such mismatches and prioritize relevant information from each modality.

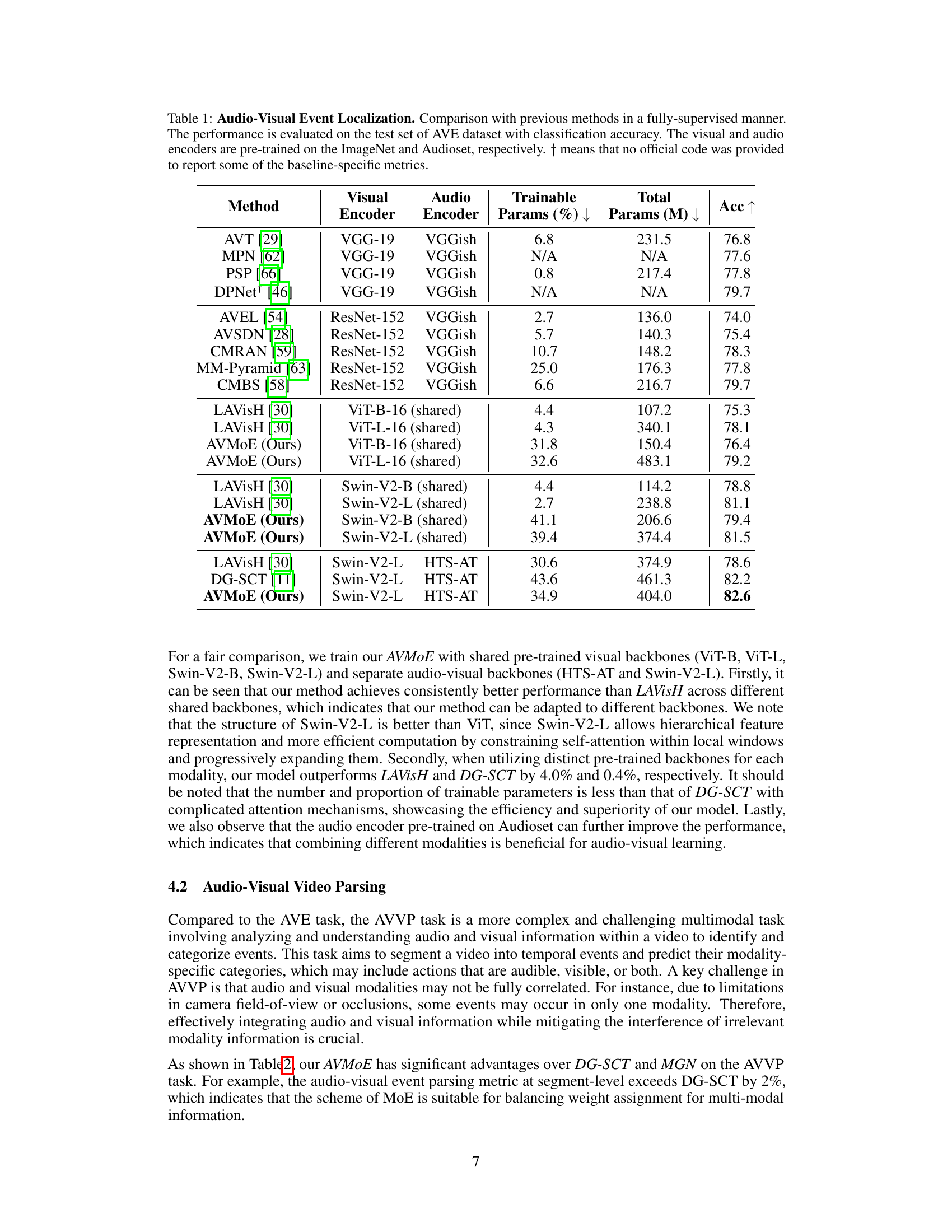
This table compares the performance of the proposed AVMoE model with several existing state-of-the-art methods on the Audio-Visual Event Localization (AVE) task. It shows the accuracy achieved by each method, along with details about the visual and audio encoders used (pre-trained on ImageNet and AudioSet, respectively), and the number of trainable parameters in millions. The table highlights the parameter efficiency of AVMoE by showcasing a lower number of trainable parameters while maintaining comparable or superior performance.
In-depth insights#
AVMoE Framework#
The Audio-Visual Mixture of Experts (AVMoE) framework presents a novel approach to audio-visual learning, focusing on parameter efficiency and flexibility. It leverages a Mixture of Experts architecture, incorporating both unimodal and cross-modal adapters to process intra- and inter-modal information. The key innovation is the dynamic weighting of these experts via a modality-agnostic router, allowing the model to adapt its strategy according to the specific demands of each task. This adaptive mechanism is particularly valuable in handling scenarios with missing or noisy modalities, ensuring robust performance. The framework’s effectiveness is demonstrated across multiple audio-visual tasks, showcasing its superior performance compared to existing parameter-efficient transfer learning methods. Adaptability and robustness are its core strengths, making it a promising advancement in multimodal learning.
Multimodal Adapters#
Multimodal adapters are crucial for effectively integrating information from diverse sources in audio-visual learning. They act as bridges, enabling communication between unimodal (audio-only or visual-only) and cross-modal (audio-visual) representations. Their design is critical: poorly designed adapters might introduce noise or irrelevant information, hindering performance. A well-designed multimodal adapter focuses on relevant feature interactions and information compression, enhancing the model’s ability to discern crucial information even with noisy or incomplete modalities. Careful consideration of the architecture is important; methods like cross-modal attention and fusion mechanisms are key components, allowing the model to capture dependencies between audio and visual streams and dynamically weight their contributions. Efficient parameter usage is also key, since large adapter models might negate the advantages of parameter-efficient learning. Future research could investigate the optimal design choices for diverse audio-visual tasks and explore alternative integration strategies beyond simple concatenation or attention.
Ablation Study#
An ablation study systematically removes components or features from a model to assess their individual contributions. In the context of a research paper on audio-visual learning, this might involve removing different types of adapters (e.g., unimodal vs. cross-modal) to evaluate their impact on performance across various tasks (e.g., audio-visual event localization, segmentation, question answering). Key insights would include identifying which components are crucial for performance and which are redundant. The study might reveal whether cross-modal interaction is essential, or if unimodal processing is sufficient in certain scenarios. Analyzing performance changes when removing components allows researchers to understand the model’s architecture and the relative importance of different inputs and processing mechanisms. Furthermore, it could help in simplifying the model by removing unnecessary parts, thereby improving efficiency and reducing computational cost. The ablation study is a valuable tool for model interpretability and optimization, providing a deeper understanding of the factors driving performance. A well-designed study will carefully consider which components to remove, ensuring the experimental setup allows for a valid comparison of model performance with and without each component.
Modality Robustness#
Modality robustness in audio-visual learning focuses on creating models that perform well even when one modality (audio or visual) is missing, noisy, or unreliable. Robustness is crucial because real-world data is often imperfect. A robust model effectively integrates information from available modalities and does not overly rely on a single source, mitigating the impact of missing data. The core challenge lies in designing architectures that can adaptively weight the contributions of different modalities based on their reliability in a specific context. Successful approaches often involve attention mechanisms, multi-modal fusion techniques, and potentially generative models to fill in missing or corrupted information from a single modality. Ultimately, the goal is to build systems that can handle real-world scenarios and exhibit reliable performance even under adverse conditions.
Future Enhancements#
Future enhancements for this audio-visual learning model, AVMoE, could explore several avenues. Increasing the number of experts within the MoE framework could lead to more nuanced handling of diverse audio-visual data, but would require careful consideration of computational resources. Investigating more sophisticated routing mechanisms, beyond simple MLPs, might improve expert selection accuracy. Exploring different adapter architectures, such as attention-based or convolutional adapters, could enhance feature extraction and integration. Furthermore, incorporating self-supervised learning techniques could reduce reliance on large labeled datasets, making the model more widely applicable. Finally, evaluating AVMoE’s performance on a wider range of audio-visual tasks and datasets, including those with significant noise or missing modalities, would strengthen its robustness and generalizability. Addressing potential biases present in the training data would be crucial for ensuring fairness and ethical implications in real-world applications.
More visual insights#
More on figures

This figure illustrates the architecture of the Audio-Visual Mixture of Experts (AVMoE) model. The AVMoE module takes visual and audio tokens as input, processes them through frozen pre-trained transformer encoders, and then uses a router to dynamically allocate weights to two types of adapters: unimodal and cross-modal. The unimodal adapters process information within a single modality (audio or visual), while the cross-modal adapters integrate information from both modalities. The output of the AVMoE is a weighted sum of the adapter predictions, effectively combining both unimodal and cross-modal information.

This figure shows the architecture of the two types of adapters used in the AVMoE model: the cross-modal adapter (CMA) and the unimodal adapter (UA). The CMA integrates information from both audio and visual modalities through token compression, feature fusion, and a bottleneck block. In contrast, the UA focuses on processing information within a single modality (either audio or visual) using token compression and a self-attention mechanism before passing it through a bottleneck block. Both adapters aim to enhance the model’s ability to process audio and visual inputs effectively, with the CMA handling cross-modal interactions and the UA focusing on intra-modal processing.

This figure shows qualitative results comparing the performance of the proposed AVMoE model and the DG-SCT baseline on the Audio-Visual Segmentation (AVS) task. The comparison is done across two settings: S4 (single sound source) and MS3 (multiple sound sources). Each row represents the results from a different method (DG-SCT, AVMoE, Ground Truth). The columns showcase different video clips, demonstrating how each method segments the visual content based on the corresponding audio cues. The results visually highlight the differences in performance, accuracy, and robustness of the two methods under varying conditions.

This figure illustrates how the proposed Audio-Visual Mixture of Experts (AVMoE) model is applied to four different audio-visual tasks: event localization, video parsing, segmentation, and question answering. Pre-trained visual and audio models are used as the base, with the AVMoE modules (shown in red) added as trainable adapters to enhance performance. Each task’s architecture is slightly modified to suit its specific needs, but the core AVMoE approach remains consistent.
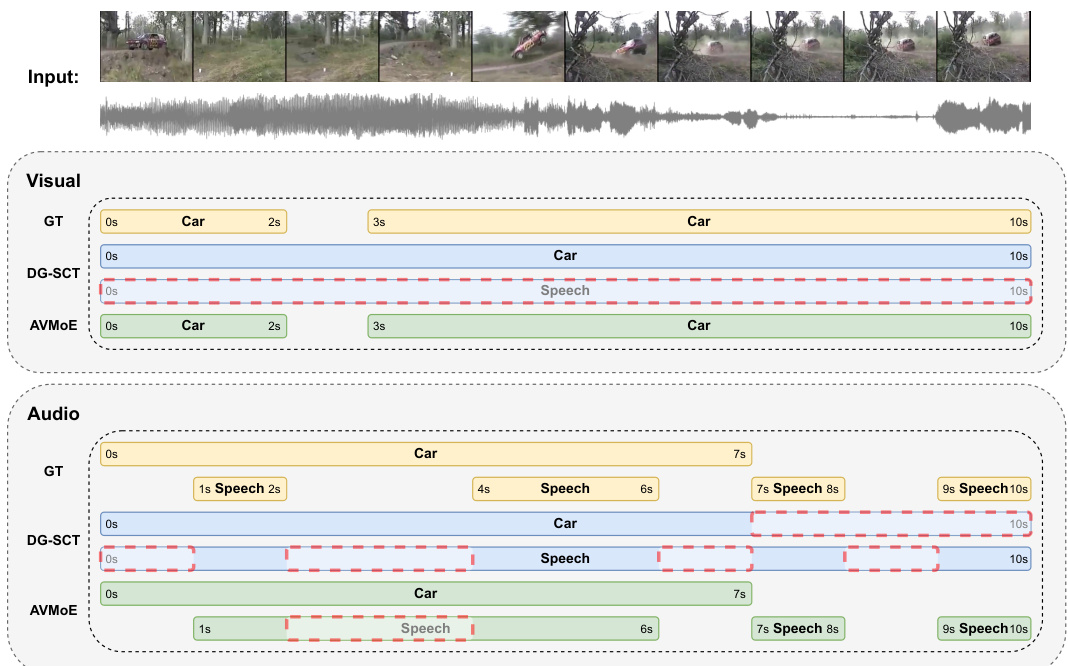
This figure showcases a qualitative comparison of the AVVP task’s results between the proposed AVMoE model and the DG-SCT model. It presents input video frames, the ground truth (GT) labels for both visual and audio tracks, and the predictions made by both models. The comparison highlights the ability of AVMoE to more accurately segment and label audio and visual events, especially in cases where the audio and visual information do not perfectly align (e.g., instances where the audio contains speech but the visual track only shows a car).

This figure illustrates the architecture of the proposed Audio-Visual Mixture of Experts (AVMoE) model. AVMoE injects trainable adapters into pre-trained models to adapt to audio-visual tasks. The model uses a mixture of experts approach, combining unimodal and cross-modal adapters. A router layer dynamically allocates weights to each expert based on the input. This allows the model to leverage the strengths of each adapter, improving performance in various audio-visual tasks.

This figure visualizes the learned audio and visual features using t-SNE. Each point represents a feature from an individual audio or visual event, with color indicating its category. The visualization demonstrates that the features extracted by the proposed AVMoE model are more compact within classes and more distinct between classes, showing that AVMoE learns discriminative features for each modality across audio-visual downstream tasks. The ‘Original’ columns show feature visualizations from baseline methods, while the ‘Ours’ columns show feature visualizations from the AVMoE method. This comparison highlights how AVMoE improves feature representation.
More on tables

This table compares the performance of the proposed AVMoE model with several other state-of-the-art methods on the Audio-Visual Video Parsing (AVVP) task using the LLP dataset. The results are broken down by two evaluation metrics (Type and Event) and two annotation levels (segment-level and event-level). Each metric shows results for audio (A), visual (V), audio-visual (AV) modalities separately, offering a comprehensive view of the model’s performance across different aspects of the AVVP task.
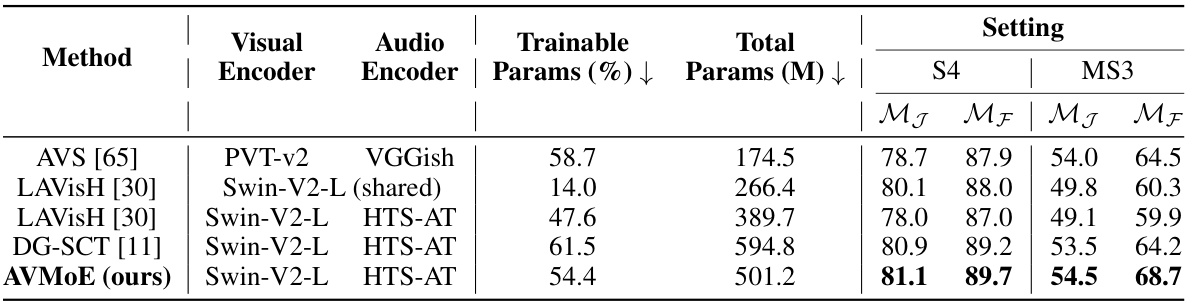
This table compares the performance of the proposed AVMoE model with several existing state-of-the-art methods on the Audio-Visual Segmentation (AVS) task. The comparison is made using two different settings of the AVSBench dataset: S4 and MS3. The S4 setting is for single-sound sources while the MS3 setting is for multiple-sound sources, representing a more challenging scenario. The results are evaluated using the Jaccard Index (MJ) and F-score (MF), representing region similarity and contour accuracy, respectively. The table also shows the number of trainable parameters for each model, providing an indication of the model’s complexity.
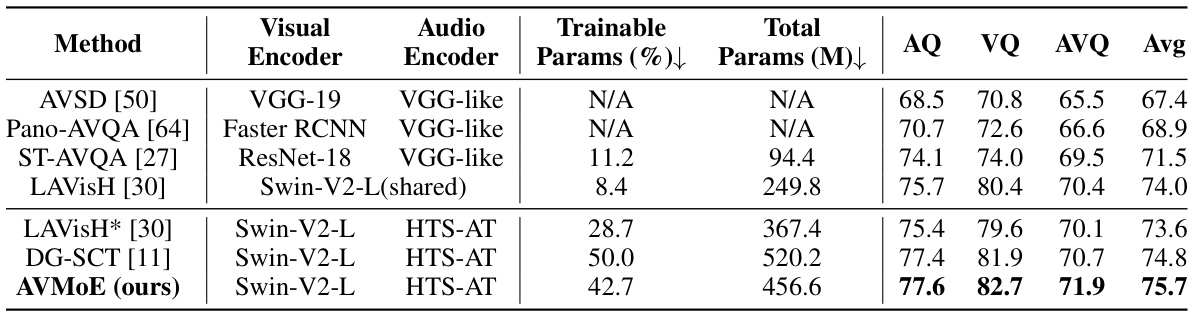
This table compares the performance of the proposed AVMoE model against several state-of-the-art methods on the MUSIC-AVQA dataset. The comparison is done across three question types: Audio Question (AQ), Visual Question (VQ), and Audio-Visual Question (AVQ). The table shows the accuracy achieved by each method for each question type, along with details on the model architecture, including the visual and audio encoders used, the percentage of trainable parameters, and the total number of parameters in millions.
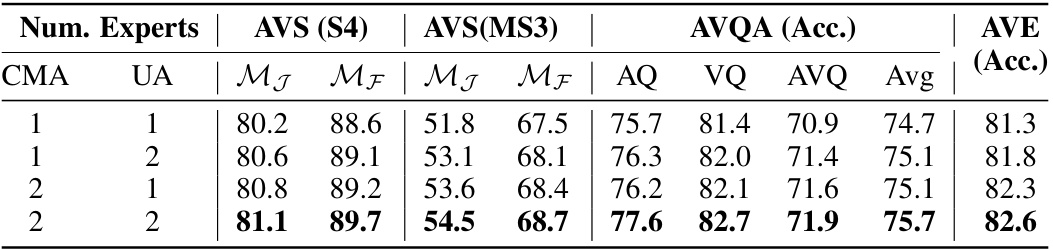
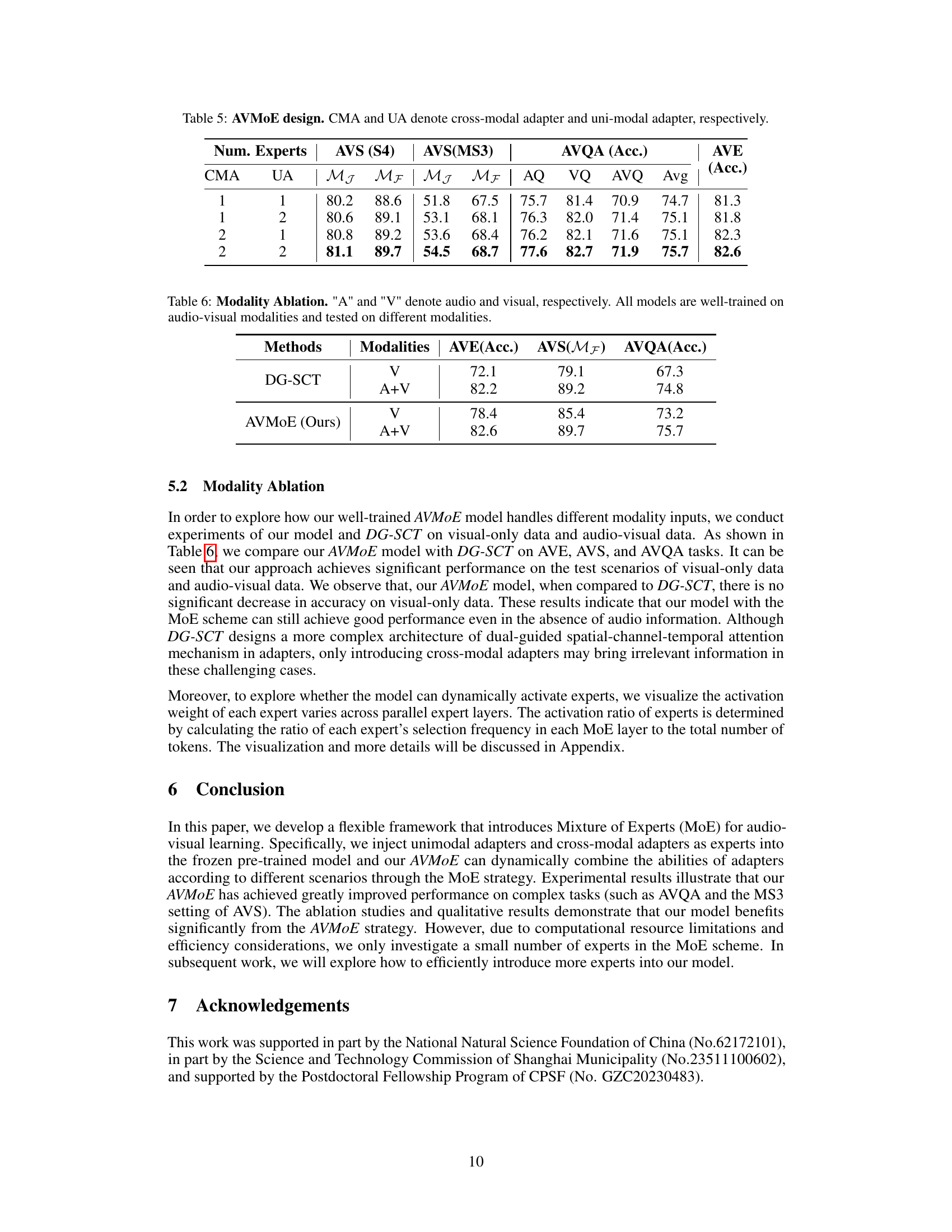
This table presents the results of ablation studies on the number of experts (cross-modal and unimodal adapters) used in the Audio-Visual Mixture of Experts (AVMoE) model. It shows how varying the number of each type of adapter affects the performance on three different audio-visual tasks: Audio-Visual Segmentation (AVS) under two settings (S4 and MS3), Audio-Visual Question Answering (AVQA), and Audio-Visual Event Localization (AVE). The metrics used are Mean Jaccard Index (MJ) and Mean F-score (MF) for AVS, and accuracy for AVQA and AVE. The results illustrate the impact of different expert configurations on model performance and the trade-offs between using more cross-modal versus unimodal adapters.
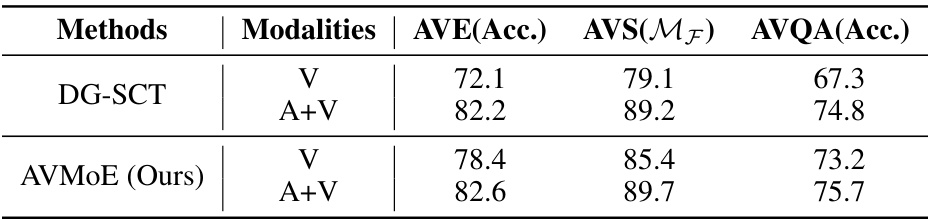
This table presents the results of an ablation study evaluating the performance of the proposed AVMoE model and the baseline DG-SCT model under different modality conditions. It compares performance on three audio-visual tasks (AVE, AVS, AVQA) when using only visual data (V) versus both audio and visual data (A+V). The goal is to assess the robustness of each model when one modality is missing.
Full paper#