↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current diffusion models struggle with prompt compliance issues like low object recall and difficulties in fine-grained editing. These limitations hinder creative image synthesis and limit the usability of these models for complex tasks. Manually generating fine-grained semantic maps needed for high-quality image editing is also tedious and time consuming.
The paper proposes Factor Graph Diffusion Models (FG-DMs) to address these issues. FG-DMs model the joint distribution of images and conditioning variables via factor graph decomposition, enabling efficient prompt compliance and semi-automated editing. An attention distillation loss further enhances the quality and consistency of generated images and conditions. Experiments demonstrate significant improvements in object recall and image quality compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on image synthesis and generative modeling. It introduces Factor Graph Diffusion Models (FG-DMs), a novel framework that significantly improves prompt compliance and enables controllable image synthesis. This addresses a major limitation of current diffusion models and opens exciting avenues for fine-grained image manipulation and data augmentation. The findings have implications for various downstream applications requiring high-quality and controllable image generation.
Visual Insights#
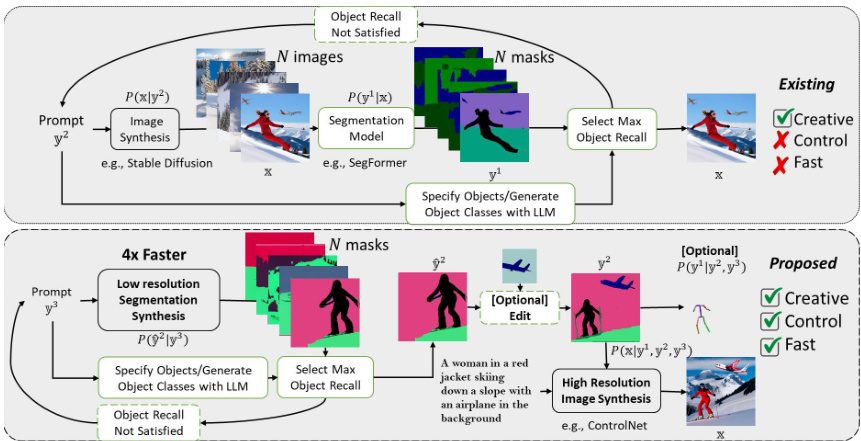
This figure compares the proposed Factor Graph Diffusion Model (FG-DM) with the traditional Stable Diffusion model for image synthesis. The top half shows Stable Diffusion, which generates images based on a text prompt but may have low recall in generating multiple objects or difficulty meeting constraints like object location and pose. The bottom illustrates FG-DM which models the joint distribution of images and conditioning variables (semantic, sketch, depth, or normal maps), leading to improved object recall, faster synthesis (4x), better control, and increased interpretability. Classifier-free guidance training is optional and allows for scenarios with missing conditions.
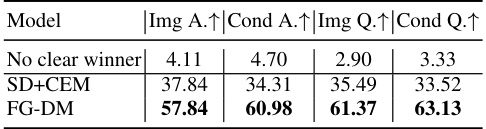
This table presents the results of a user study comparing the qualitative performance of the FG-DM and a combination of Stable Diffusion (SD) and a Condition Extraction Model (CEM). Ten human evaluators assessed image and condition quality, as well as prompt adherence for both methods. The FG-DM significantly outperforms SD+CEM in all four categories.
In-depth insights#
FG-DM Framework#
The FG-DM framework presents a novel approach to image synthesis by modeling the joint distribution of images and conditioning variables using a factor graph. This modular design allows for flexible incorporation of various conditioning modalities, such as segmentation, depth, and sketch maps, leading to enhanced control and improved prompt compliance. The framework’s strength lies in its ability to handle complex scenes efficiently, supporting creative image editing through the manipulation of individual factors. Furthermore, prompt compliance is improved via a sampling-based approach, which selects the image that best meets the prompt conditions. A key advantage is the enhanced efficiency gained through using low-resolution synthesis for conditions, enabling faster image synthesis compared to inference-based methods. The FG-DM’s modularity also facilitates continual learning and allows for training with missing data, adding flexibility and scalability. The attention distillation loss further enhances the fidelity and consistency of the generated images and conditions.
SBPC for DMs#
Sampling-based prompt compliance (SBPC) offers a novel approach to enhance prompt compliance in diffusion models (DMs). Unlike traditional methods that modify loss functions during inference, SBPC leverages the inherent randomness of DMs to generate multiple image candidates. An external model, like a segmentation network, then evaluates these candidates for prompt adherence, selecting the best-performing image. SBPC’s key advantage is its scalability. Unlike inference-based methods whose complexity grows with scene complexity, SBPC’s evaluation cost remains relatively constant regardless of scene complexity. The modular nature of SBPC enables easy integration into existing DM pipelines, offering a practical method to improve prompt compliance without significant architectural changes. However, a limitation is the increased computational cost associated with generating multiple images. While mitigated by employing lower-resolution sampling for condition generation, this trade-off still needs careful consideration for real-time applications. Furthermore, the reliance on an auxiliary model for evaluation introduces additional complexity and potential failure points. Despite these challenges, SBPC’s simplicity and scalability make it a promising direction for improving the creative control and efficiency of diffusion-based image synthesis.
Attention Distillation#
The concept of ‘Attention Distillation’ in the context of diffusion models is a clever technique to improve the fidelity of synthesized conditions like segmentation masks or depth maps. By leveraging the attention maps of a pre-trained, high-performing model (like Stable Diffusion), the method guides the training of individual factors within a Factor Graph Diffusion Model (FG-DM). This distillation process encourages consistency between the attention maps of different factors, ensuring that the generated conditions align well with each other and the final synthesized image. The use of a knowledge distillation loss (like KL divergence) helps transfer the semantic understanding from the teacher model to the student factors. This approach is particularly valuable as it significantly reduces the need for extensive training data for each factor within the FG-DM framework and promotes better generalization to novel inputs. The technique represents a powerful strategy for improving efficiency and reducing the computational burden associated with training complex generative models.
Adaptation of DMs#
Adapting pre-trained diffusion models (DMs) presents a powerful approach to enhance image synthesis. This method avoids the resource-intensive process of training DMs from scratch, significantly reducing computational costs and time. The adaptation process leverages the knowledge embedded within pre-trained models, effectively transferring this expertise to new tasks. Careful consideration must be given to the adaptation strategy, such as fine-tuning or using adapters, to avoid catastrophic forgetting or suboptimal performance. The choice of adaptation method will depend on factors like the target task’s complexity and the level of similarity to the pre-trained model’s domain. While effective, adaptation limits the ability to explore completely novel architectures or functionalities that may surpass the capabilities of existing pre-trained models. Successful adaptation requires careful hyperparameter tuning and a robust evaluation framework to gauge the effectiveness of the adaptation and to mitigate the risk of overfitting or underfitting. The attention distillation loss function is a particularly important component to enhance alignment between adapted and pre-trained models. Finally, the success of the adapted model will also depend on the quality and quantity of the data used in the adaptation process.
Future Work#
The ‘Future Work’ section of a research paper on adapting diffusion models for image synthesis would naturally explore several promising avenues. Extending the Factor Graph Diffusion Model (FG-DM) to handle more complex scenes and a larger number of conditioning variables is crucial for scalability and real-world applicability. This could involve investigating more efficient inference methods or exploring hierarchical structures within the factor graph. Addressing the computational cost associated with multiple conditioning variables remains a significant challenge, thus, exploring methods for parallelization or approximation techniques would be valuable. Improving the robustness of the attention distillation loss and investigating alternative methods for ensuring consistency among attention maps across different factors is another key area for improvement. Finally, exploring the potential of the FG-DM for other generative tasks beyond image synthesis, such as video generation or 3D model generation, presents exciting opportunities. Further research could also focus on developing more user-friendly tools for image editing, facilitating broader adoption and usability of the proposed approach.
More visual insights#
More on figures

This figure shows examples of how FG-DM can be used for controllable image generation by editing the conditioning variables (segmentation, depth, and sketch maps). The top row shows the generated conditions and corresponding images, while the bottom row shows the results after editing the segmentation map only. The model then conditionally generates the pose and image given the edited segmentation map, illustrating fine-grained control over image generation.

This figure showcases the FG-DM’s ability to generate various types of conditioning maps (segmentation, depth, sketch, normal) along with their corresponding images. Importantly, it highlights the model’s generalization capabilities by successfully handling prompts for objects (porcupine, chimp) not present in its COCO training data. This demonstrates the model’s ability to synthesize realistic images across diverse conditions and creative prompts.

This figure illustrates the architecture of the Factor Graph Diffusion Model (FG-DM). The left side shows the training process, detailing how a pretrained Stable Diffusion (SD) model is adapted to generate visual conditions for each factor in a factor graph. The SD model’s weights are frozen, and only small adapters are trained. The right side depicts the flexible inference process enabled by classifier-free guidance, allowing for efficient sampling by activating only a subset of the factors as needed.

This figure shows more examples of the FG-DM generating various types of maps (segmentation, depth, normal, sketch) and corresponding images, demonstrating its ability to handle different creative prompts. The appendix includes higher-resolution versions of these images.

This figure demonstrates the image editing capabilities of the proposed FG-DM model by showing examples of image manipulation such as flipping people, adding text, and generating images for complex prompts. The results are compared to those obtained using Stable Diffusion v1.4 and v1.5, highlighting the FG-DM’s superior performance in these tasks.

This figure presents the results of an ablation study on attribute recall using the FG-DM model on the MM-CelebA-HQ dataset. The left panel shows a bar chart comparing the attribute recall of the FG-DM against other methods (Ours, OCGP, Imagen, LDM, LAFITE) across three attributes: Wearing Earrings, Bald, and Pale Skin. The right panel displays a histogram showing the distribution of the number of trials required to achieve 70% and 80% recall thresholds. The histograms show that the FG-DM achieves high recall with a relatively low number of trials.

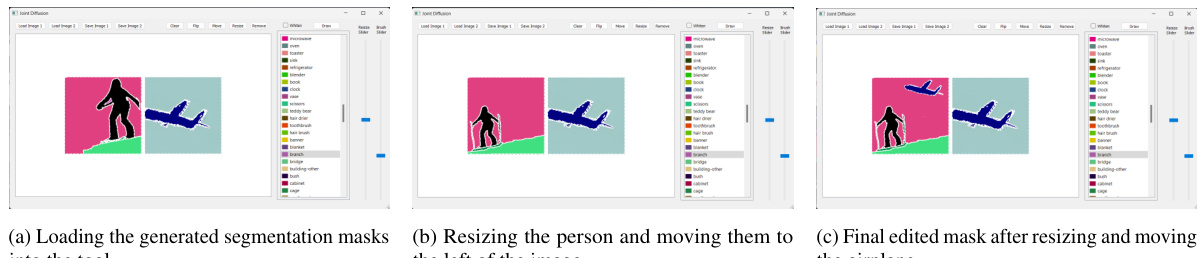
This figure shows the results of image editing using the FG-DM model. The top part demonstrates semantic-level editing, where a segmentation mask is inverted and then edited using the LEDITS++ tool to either replace a woman with a chimp or remove an umbrella. This semantic-level editing shows high robustness and quality. The bottom part of the figure compares pixel-level image inversion and editing. The FG-DM is compared to stable diffusion for the quality of image synthesis, demonstrating its ability to maintain the background of the original image and produce more realistic edits. The overall figure showcases FG-DM’s capabilities for image manipulation and editing.

This figure compares the image generation results of three different models: FG-DM with attention distillation, FG-DM without attention distillation, and 4M-XL. It demonstrates that FG-DM, particularly when using attention distillation, produces higher-quality images and more accurate segmentations compared to the 4M-XL model. The differences in segmentation quality are highlighted by examples showcasing the inaccuracies present in the model without attention distillation.

This figure displays several examples of depth maps generated by the Factor Graph Diffusion Model (FG-DM) alongside their corresponding images. The FG-DM successfully generates high-quality depth maps and realistic images. The examples showcase the model’s ability to handle a variety of objects and scenes, demonstrating its effectiveness in synthesizing depth information and producing high-fidelity images.

This figure shows qualitative results of FG-DM in generating normal maps and sketch maps with corresponding images. The model generalizes well, producing outputs for prompts (e.g., a polar bear, a statue of Mary) not seen in the training data, showcasing its ability to synthesize diverse and high-quality results across various conditioning variables.

This figure showcases qualitative results of the FG-DM’s ability to synthesize segmentation maps and images for creative prompts. The FG-DM demonstrates the capacity to generate segmentation maps for object classes unseen during training. The semantic maps utilize distinct color-coding for each object class, simplifying object mask and class label extraction. The model also demonstrates interesting generalization properties—for example, despite training primarily on human segmentation, it correctly labels a chimpanzee, highlighting the model’s ability to leverage prior knowledge from the pre-trained stable diffusion model.

This figure compares the image generation results of FG-DM against two prior works, Make-a-Scene and SpaText. The top row shows the input prompts and the corresponding segmentation maps generated by each method. FG-DM generates both a segmentation map and the image, while the other two methods use manually sketched segmentation maps. The comparison shows that FG-DM achieves better results.

This figure shows several examples of images generated by the FG-DM model, along with their corresponding segmentation, depth, normal, and sketch maps. The prompts used to generate each image are shown below the image. The figure demonstrates the model’s ability to generate high-quality images and maps for a variety of prompts, even those involving complex scenes or objects not present in the training data. The high-resolution version of this figure is available in the appendix.

This figure compares the quality of generated conditions (segmentation and depth maps) by the proposed FG-DM model against those extracted from images using existing methods (Stable Diffusion + CEM). It visually demonstrates that the FG-DM generates more accurate and higher quality conditions, particularly for depth maps, highlighting one of FG-DM’s key advantages.

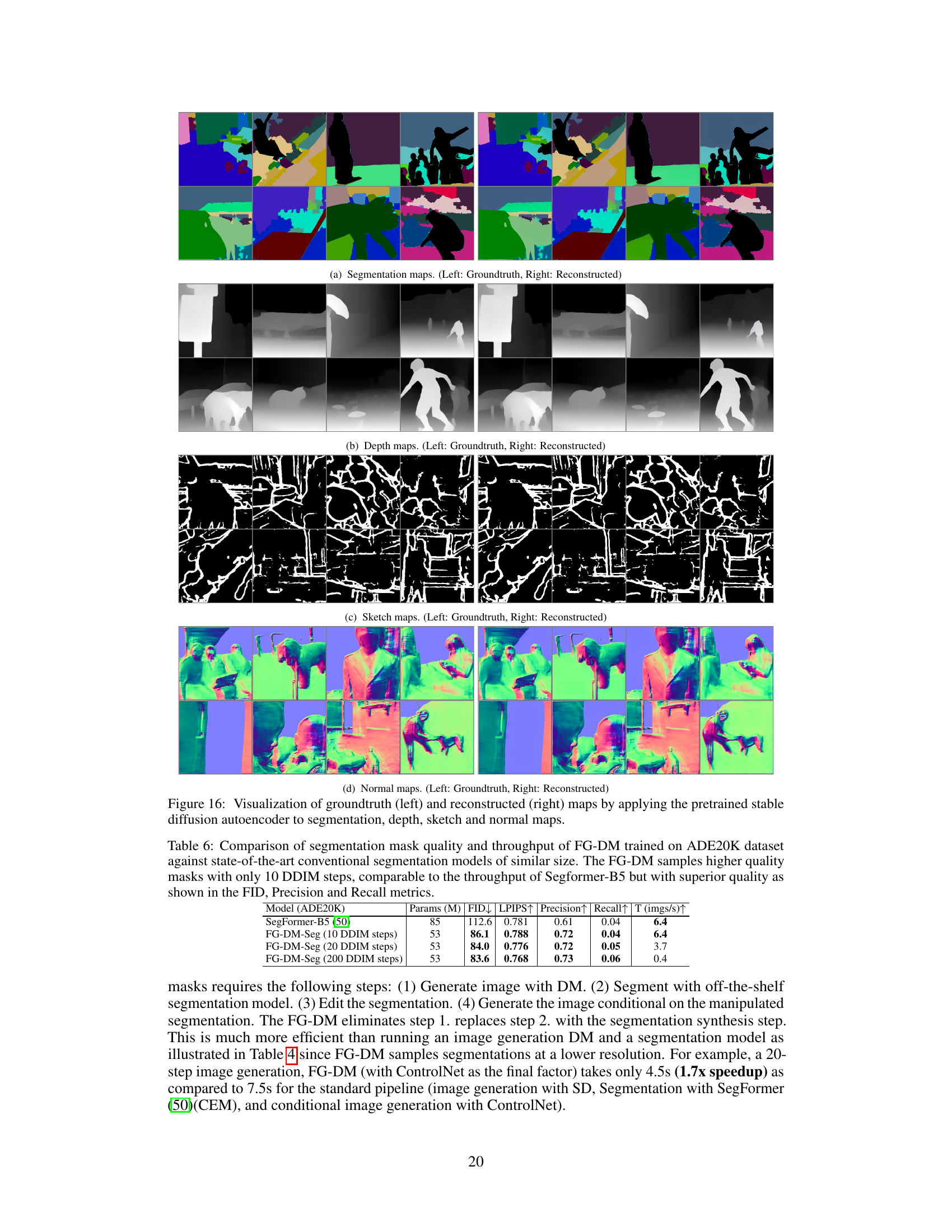
This figure visualizes the quality of reconstruction of groundtruth maps for segmentation, depth, sketch, and normal maps by applying a pretrained stable diffusion autoencoder. The left column shows the groundtruth maps, and the right column shows the maps reconstructed by the autoencoder. This demonstrates the effectiveness of using a pre-trained autoencoder to generate these conditioning variables for the FG-DM.

This figure shows four examples of unconditional image generation from an FG-DM model trained on the MM-CelebA-HQ dataset. For each example, the figure shows the generated semantic mask (top row), pose mask (middle row), and the resulting image (bottom row). The results showcase the FG-DM’s ability to generate diverse and high-quality images without explicit textual or visual conditioning.

This figure shows four image sets generated by FG-DMs. Each set contains segmentation masks and the corresponding images generated for the MM-CelebA-HQ, ADE-20K, Cityscapes, and COCO datasets. The FG-DMs were trained from scratch with 53 million parameters for each factor. The results demonstrate the FG-DM’s ability to synthesize high-quality images and segmentation masks for diverse datasets and image types.

This figure compares the proposed Factor Graph Diffusion Model (FG-DM) against the Stable Diffusion model. FG-DM models the joint distribution of images and conditioning variables (e.g., segmentation maps, poses) to improve object recall and enable controllable image synthesis. The diagram illustrates how FG-DM achieves faster inference and higher creative control than Stable Diffusion through its modular factor graph structure.

This figure compares the proposed FG-DM model with the Stable Diffusion model for image synthesis. The FG-DM models the joint distribution of images and conditioning variables (like segmentation maps), offering more control and faster synthesis compared to the Stable Diffusion model. The FG-DM achieves higher object recall. Classifier-free guidance training allows some conditions to be optional.
This figure compares the proposed Factor Graph Diffusion Model (FG-DM) with Stable Diffusion. It shows how FG-DM models the joint distribution of images and conditioning variables (like segmentation maps), enabling more control, higher object recall, and faster image synthesis than Stable Diffusion. The FG-DM’s modular design allows for creative image editing and efficient sampling-based prompt compliance.
More on tables
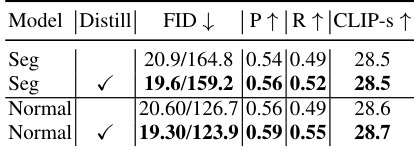
This table presents the results of an ablation study evaluating the impact of the attention distillation loss on the quality of text-to-image (T2I) synthesis using the Factor Graph Diffusion Model (FG-DM). The experiment was performed on the COCO validation dataset. The table shows FID scores (Frechet Inception Distance) for both the generated images and conditions, with and without the attention distillation loss. Lower FID values generally indicate higher quality. The results demonstrate the effectiveness of the attention distillation loss in improving the fidelity of the generated conditions and images.
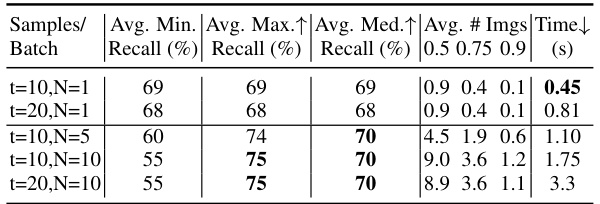
This table presents the results of an experiment evaluating the object recall performance of the Factor Graph Diffusion Model (FG-DM) using different sampling strategies. The experiment varies the number of timesteps (t) in the diffusion process and the number of different seeds (N) used for sampling. The results are reported as average minimum, maximum, and median recall values across 2000 prompts in the ADE20K validation set. The table also shows the average number of images in a batch that satisfy object recall thresholds of 0.5, 0.75, and 0.9, as well as the average time taken per sampling batch.
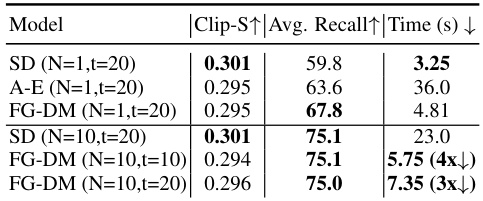
This table compares the object recall performance of different models and sampling strategies on the ADE20K validation set. It contrasts Stable Diffusion (SD) with and without multiple sampling (N=10), and compares both with the Attend & Excite (A-E) method, and the proposed Factor Graph Diffusion Model (FG-DM) with different numbers of sampling timesteps (t). The table highlights FG-DM’s superior recall and efficiency compared to SD and A-E, especially when using multiple samples to enhance prompt compliance.
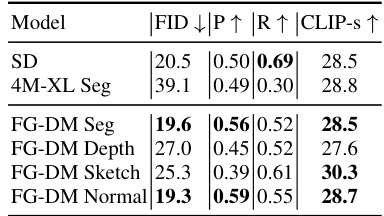
This table compares the object recall performance of different models and configurations on the ADE20K validation set prompts. It contrasts Stable Diffusion (SD) with the proposed Factor Graph Diffusion Model (FG-DM), showing the improvements in recall achieved by FG-DM, especially when using multiple sampling seeds. The table also highlights the significant reduction in inference time achieved by FG-DM compared to SD, particularly when employing multiple seeds.

This table compares the performance of FG-DM (trained on the ADE20K dataset) against the state-of-the-art SegFormer-B5 model for semantic segmentation. The metrics used for comparison are FID (Frechet Inception Distance), LPIPS (Learned Perceptual Image Patch Similarity), Precision, Recall, and throughput (images per second). The results show that FG-DM achieves comparable throughput to SegFormer-B5 while exhibiting superior quality (lower FID and higher LPIPS) using significantly fewer DDIM (Denoising Diffusion Implicit Models) steps.

This table presents the results of an ablation study comparing the performance of FG-DMs trained separately and jointly with a segmentation factor. The study evaluates image synthesis quality and semantic segmentation performance across four datasets: MM-CelebA-HQ, ADE-20K, Cityscapes, and COCO-Stuff. The metrics reported include FID (Fréchet Inception Distance), LPIPS (Learned Perceptual Image Patch Similarity), Precision, and Recall. The comparison highlights the impact of joint training on the overall performance of the model.

This table presents the results of an ablation study on the impact of data augmentation using synthetic data generated by the FG-DM for facial part segmentation. It shows the performance of a model trained on the original MM-CelebA-HQ dataset compared to models trained with additional synthetic data generated by the FG-DM. The metrics used to evaluate performance are mIoU, frequency-weighted mIoU (F.W. mIoU), and F1-score. The results indicate whether adding synthetic data improves the performance of the model for facial part segmentation.
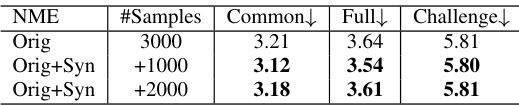
This table presents the results of an ablation study evaluating the impact of data augmentation using synthetic data generated by the FG-DM on face landmark estimation performance. The study used the 300W dataset. Three different scenarios are compared: using only the original dataset, augmenting with 1000 synthetic samples, and augmenting with 2000 synthetic samples. The performance is measured using the Normalized Mean Error (NME), a common metric for evaluating face landmark localization accuracy. The table breaks down the NME for three landmark difficulty levels: ‘Common’, ‘Full’, and ‘Challenge’. Lower NME values indicate better performance.
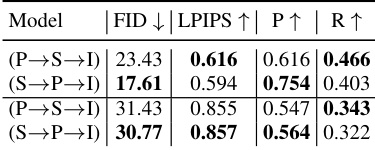
This table presents an ablation study on the order of generating semantic maps (S) and pose (P) within the FG-DM framework. It compares two different orders: (P→S→I) where pose is generated first, followed by semantics, and finally the image; and (S→P→I) where the order is reversed. The results show that different orders significantly impact the FID and LPIPS scores, especially on the CelebA-HQ dataset, suggesting an optimal sequence for generating these conditions to maximize image quality and alignment with the prompts. The metrics used are FID (lower is better) and LPIPS (higher is better). Precision (P) and Recall (R) are also given.
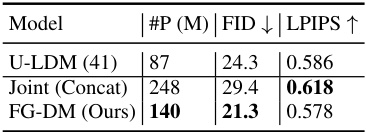
This table compares the performance of FG-DM against a joint synthesis approach using concatenation and U-LDM. The FG-DM model demonstrates superior results (lower FID) while having a significantly smaller number of parameters.

This table presents the results of an ablation study comparing the image alignment performance of FG-DMs trained using separate and joint training methods. The metric used is mIoU (mean Intersection over Union) and frequency weighted mIoU (f.w. IoU), which measure the degree of overlap between the generated images and their corresponding ground truth segmentation masks. The results are shown for four different datasets: MM-CelebA, Cityscapes, ADE20K, and COCO. The table helps assess the impact of joint training on the alignment of generated images with their segmentation masks across various datasets.
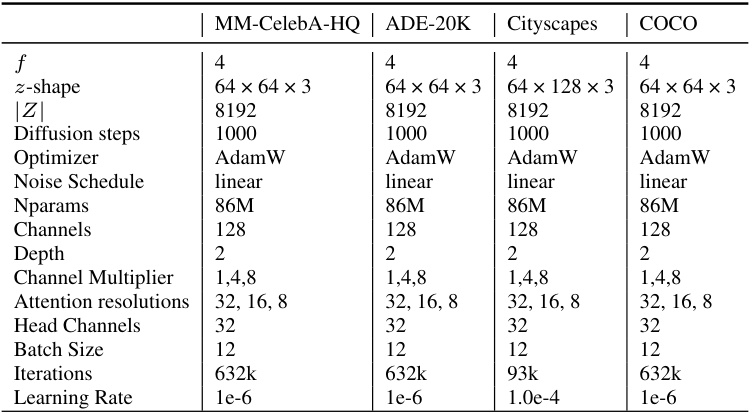
This table details the hyperparameters used for training the Factor Graph Diffusion Models (FG-DMs) from scratch on four different datasets: MM-CelebA-HQ, ADE20K, Cityscapes, and COCO. It shows the hyperparameters for each dataset, highlighting differences in image resolution (256x512 for Cityscapes, 256x256 for others), network architecture details (f, z-shape, |Z|, channels, depth, channel multiplier, attention resolutions, head channels), training settings (optimizer, noise schedule, batch size, iterations, learning rate), and the total number of parameters (Nparams).
Full paper#