↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision Transformers (ViTs), while powerful, are vulnerable to adversarial attacks. Existing attacks often struggle with transferability – the ability to fool unseen models. The challenge lies in the complex interactions between layers and the attention mechanism within ViTs, making it hard to generalize adversarial examples effectively. This paper addresses these issues.
This research introduces Adaptive Token Tuning (ATT), a novel approach. ATT uses three key strategies: adaptive gradient re-scaling to reduce variance, a self-paced patch-out method to improve input diversity, and attention gradient truncation to mitigate overfitting. Experiments show that ATT significantly improves the transferability of attacks against both undefended and defended models, surpassing current state-of-the-art methods, demonstrating its importance for advancing research in adversarial robustness for ViTs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on adversarial attacks against vision transformers. It significantly advances the state-of-the-art in transferability, a critical aspect for real-world security applications. The findings also open new avenues for research into adaptive optimization strategies and attention mechanisms within vision transformers, impacting broader areas within deep learning.
Visual Insights#

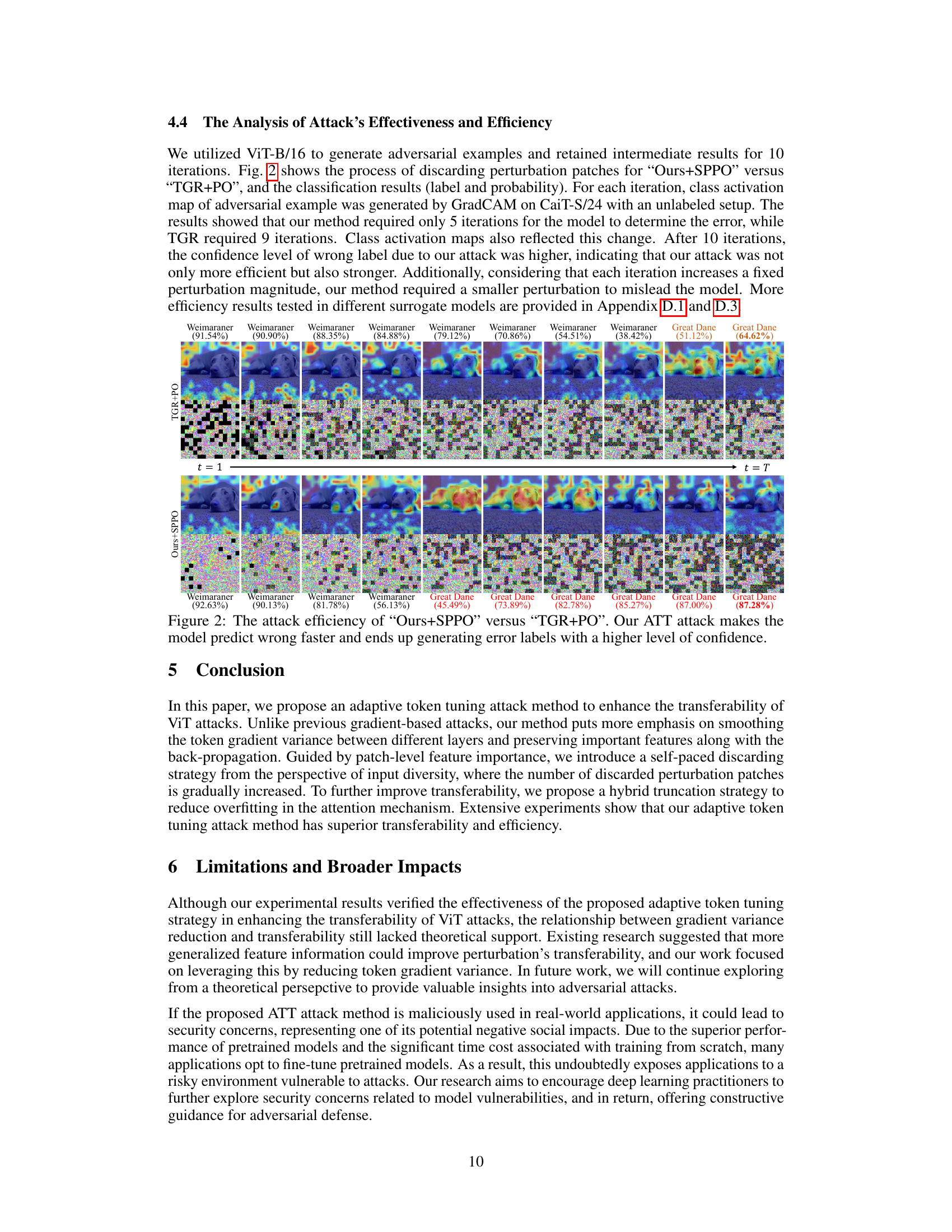
This figure shows the overall framework of the proposed Adaptive Token Tuning (ATT) attack method. The process starts with a clean image and its corresponding ground-truth label. A self-paced patch out strategy is used to dynamically discard patches in the adversarial perturbation. The adaptive variance reduced token gradient method then adjusts the token gradients within and across the ViT layers, mitigating overfitting and improving transferability. This gradient correction involves re-scaling the largest token gradient(s) and applying a hybrid token gradient truncation method to weaken the attention mechanism. The process culminates in the generation of adversarial examples.

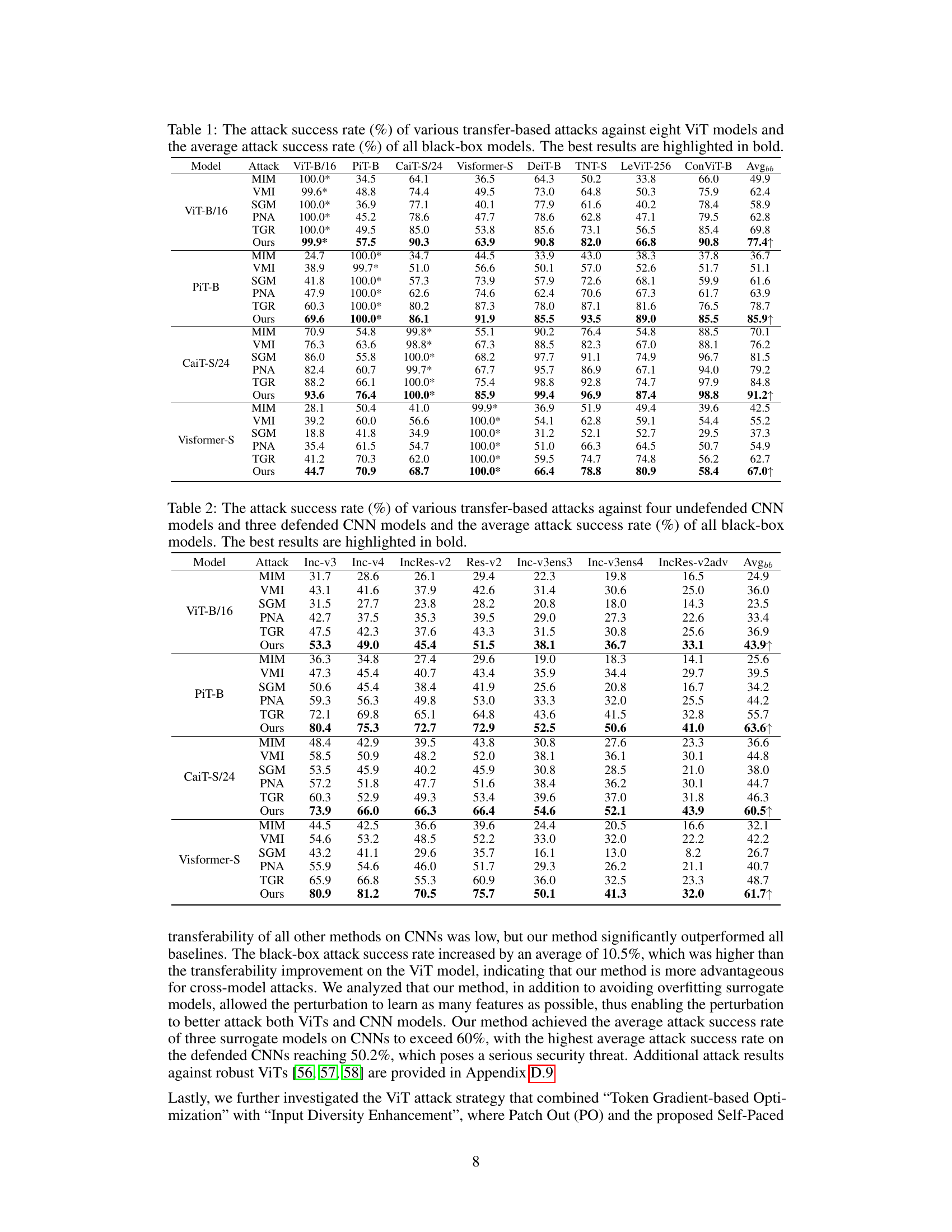
This table presents the results of various transfer-based attacks against eight different Vision Transformer (ViT) models. It shows the attack success rate (ASR) for each attack method on each ViT model, as well as the average ASR across all eight models. The purpose is to compare the effectiveness of different attack methods in terms of their transferability (the ability to successfully attack a target model that is different from the model used for generating adversarial examples). The table highlights the best performing attack method for each ViT model.
In-depth insights#
Adaptive Token Tuning#
Adaptive token tuning presents a novel approach to enhancing the transferability of adversarial attacks against vision transformers (ViTs). Instead of aggressively zeroing out gradients, as in previous methods, adaptive token tuning refines the gradient update process. This refinement involves three key strategies: adaptive gradient rescaling to manage variance, a self-paced patch-out strategy to promote input diversity, and a hybrid token gradient truncation to mitigate overfitting from complex attention mechanisms. The adaptive nature allows the algorithm to dynamically adjust its approach based on the model’s behavior, increasing robustness. The self-paced learning aspect ensures efficient and effective update, while the attention mechanism manipulation targets the source of overfitting. The combination of these strategies leads to significantly improved attack success rates across various ViT and CNN models, highlighting the effectiveness of this nuanced, adaptive approach. The adaptive nature of the method is key to its success, particularly its ability to balance feature preservation with effective gradient adjustments.
Transferability Boost#
The concept of “Transferability Boost” in adversarial attacks centers on enhancing the effectiveness of attacks trained on one model (the surrogate model) against unseen target models. Improved transferability is crucial for black-box attacks, where the target model’s architecture and parameters are unknown. The core idea is to develop attack strategies that generalize well, minimizing overfitting to the surrogate model. This often involves techniques that reduce the reliance on specific features or model internals of the surrogate. Approaches might involve manipulating gradients, regularizing the attack process or leveraging input diversity, thereby creating perturbations that are more robust and effective across a range of target models. Adaptive techniques that adjust the attack strategy based on feedback from the target model are particularly promising for achieving strong transferability. Ultimately, a “Transferability Boost” aims to bridge the gap between white-box and black-box adversarial attacks, making adversarial robustness significantly more challenging to achieve.
ViT Attack Method#
The core of this research paper revolves around a novel approach to enhance the transferability of adversarial attacks against Vision Transformers (ViTs). The proposed Adaptive Token Tuning (ATT) method tackles the limitations of existing ViT attacks by addressing three key areas. Firstly, it employs an adaptive gradient re-scaling strategy to effectively reduce the overall variance of token gradients without sacrificing crucial feature information. Secondly, it introduces a self-paced patch out strategy that leverages feature importance to selectively discard perturbation patches, enhancing diversity and mitigating overfitting. Lastly, it incorporates a hybrid token gradient truncation strategy to intelligently weaken the influence of the attention mechanism, thereby further improving transferability. The ATT method is evaluated extensively across various ViT architectures and CNN models (both defended and undefended), demonstrating superior performance compared to existing state-of-the-art techniques. The results highlight the method’s effectiveness in generating highly transferable adversarial examples, showcasing its potential significance in assessing the robustness of ViT models and inspiring future research in adversarial defense strategies.
Semantic PatchOut#
Semantic PatchOut is a novel approach to enhance the transferability of adversarial attacks against Vision Transformers (ViTs). Traditional PatchOut methods randomly remove patches, potentially discarding important information. Semantic PatchOut leverages feature importance maps to guide patch selection. This ensures that less crucial patches are preferentially removed, preserving more critical information for effective attacks. By incorporating a self-paced learning strategy, Semantic PatchOut dynamically adjusts the number of discarded patches during training. This prevents early overfitting and allows the attack to converge towards a more transferable solution. The semantic guidance and self-paced learning contribute to improved attack success rates, especially under black-box attack scenarios where limited information about the target model is available. The method’s strength lies in its ability to balance perturbation diversity and efficiency by intelligently discarding less informative patches, resulting in higher transferability.
Attention Weakening#
The concept of ‘Attention Weakening’ in the context of adversarial attacks against Vision Transformers (ViTs) presents a novel approach to enhancing the transferability of attacks. Standard gradient-based attacks often overfit to the specific surrogate model used for crafting adversarial examples. Attention mechanisms, central to ViTs, can exacerbate this overfitting by creating complex feature interactions. ‘Attention Weakening’ aims to mitigate this overfitting by strategically reducing the influence of the attention mechanism, particularly in deeper layers where overfitting is most pronounced. This might involve techniques like gradient truncation or attenuation within the attention modules, allowing the adversarial perturbations to learn more robust and transferable features, thereby improving the attack success rate against unseen, black-box ViT models. The key insight is that selectively weakening attention can improve generalization without completely disabling the mechanism’s beneficial properties.
More visual insights#
More on figures
This figure shows a flowchart summarizing the Adaptive Token Tuning (ATT) attack method. The method comprises three main strategies: adaptive variance reduced token gradient, self-paced patch out, and truncated attention layers. Adaptive variance reduction corrects the gradient variance across layers to produce more transferable adversarial examples. Self-paced patch out enhances the diversity of input tokens by discarding patches based on feature importance in a self-paced manner. Truncated attention layers mitigate overfitting by weakening the attention mechanism in deep layers of the Vision Transformer (ViT). The figure visually depicts the interaction and flow of information between these strategies during the attack process.
This figure shows a detailed flowchart of the Adaptive Token Tuning (ATT) attack method proposed in the paper. It illustrates the three main optimization strategies used: adaptive gradient re-scaling, self-paced patch out, and hybrid token gradient truncation. Each strategy is visually represented, highlighting the interactions and flow of information between different components. The figure is crucial in understanding how the method boosts the transferability of adversarial attacks on Vision Transformers.
This figure shows a schematic of the Adaptive Token Tuning (ATT) attack method proposed in the paper. It illustrates the three main components of the ATT attack: Self-Paced Patch Out, Adaptive Variance Reduced Token Gradient, and Truncated Attention Layers. Self-Paced Patch Out uses feature importance to selectively discard perturbation patches, improving diversity and efficiency. Adaptive Variance Reduced Token Gradient re-scales token gradients to reduce variance across layers, enhancing transferability. Finally, Truncated Attention Layers mitigate overfitting by weakening the attention mechanism in deeper layers. The figure visually represents the interactions and flow of information between these components during the adversarial attack process.

This figure presents a flowchart illustrating the Adaptive Token Tuning (ATT) attack method. The method comprises three main strategies: adaptive variance reduced token gradient, self-paced patch out, and hybrid token gradient truncation. The adaptive variance reduced token gradient strategy aims to reduce the gradient variance across different layers of the Vision Transformer (ViT) model while preserving crucial feature information. The self-paced patch out strategy leverages feature importance to dynamically control the number of discarded patches. Finally, the hybrid token gradient truncation strategy weakens the effect of the attention mechanism. The flowchart shows the interplay of these three strategies during the attack process.

This figure shows the overall framework of the proposed Adaptive Token Tuning (ATT) attack method. It illustrates three optimization strategies: adaptive gradient rescaling to reduce variance, self-paced patch out to enhance input diversity, and hybrid token gradient truncation to weaken the attention mechanism. The figure visually represents the flow of the attack process, highlighting the interaction between these strategies and their impact on improving the transferability of adversarial attacks on Vision Transformers (ViTs).

This figure illustrates the Adaptive Token Tuning (ATT) attack method proposed in the paper. It shows three main components: Adaptive Variance Reduced Token Gradient, Self-Paced Patch Out, and Truncated Attention Layers. The Adaptive Variance Reduced Token Gradient component aims to reduce the overall variance of token gradients, improving the stability and transferability of the attack. The Self-Paced Patch Out component enhances the diversity of input tokens by selectively discarding patches based on feature importance. The Truncated Attention Layers component weakens the effectiveness of the attention mechanism to mitigate overfitting. The figure visually represents the flow of information and the interactions between these components during the attack process.

This figure presents a flowchart that illustrates the framework of the proposed Adaptive Token Tuning (ATT) attack method. It shows three main components working together: 1) Self-Paced Patch Out, which selectively discards less important patches during the adversarial perturbation process; 2) Adaptive Variance Reduced Token Gradient, which adjusts the gradient variance to avoid overfitting and improve transferability; and 3) Truncated Attention Layers, which reduces the influence of the attention mechanism in deeper layers of the Vision Transformer (ViT). The combination of these strategies is intended to boost the effectiveness of adversarial attacks against ViTs.

This figure shows a schematic of the proposed Adaptive Token Tuning (ATT) attack method. The method consists of three optimization strategies: adaptive gradient rescaling to reduce token gradient variance, self-paced patch-out to improve input diversity, and hybrid token gradient truncation to weaken the attention mechanism. The figure highlights the interactions between these strategies and the overall workflow of the attack.

This figure shows the overall framework of the proposed Adaptive Token Tuning (ATT) attack method. The framework consists of three main components: Self-Paced Patch Out, Adaptive Variance Reduced Token Gradient, and Truncated Attention Layers. Self-Paced Patch Out uses a self-paced learning strategy to discard patches from the input image, improving input diversity. Adaptive Variance Reduced Token Gradient adjusts token gradients by reducing their variance, preventing overfitting and leading to more stable optimization. Finally, Truncated Attention Layers mitigate the effect of the attention mechanism in deep ViT layers, further improving transferability. The figure illustrates the interactions between these components, showing the flow of information during the attack process.
More on tables
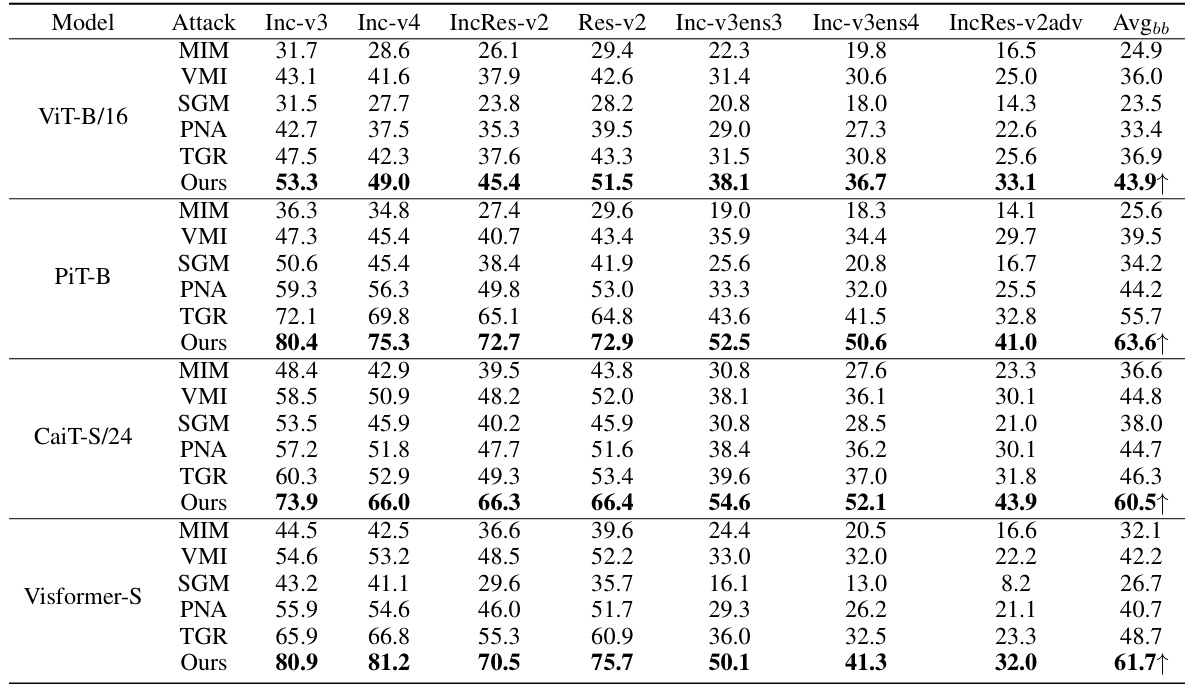
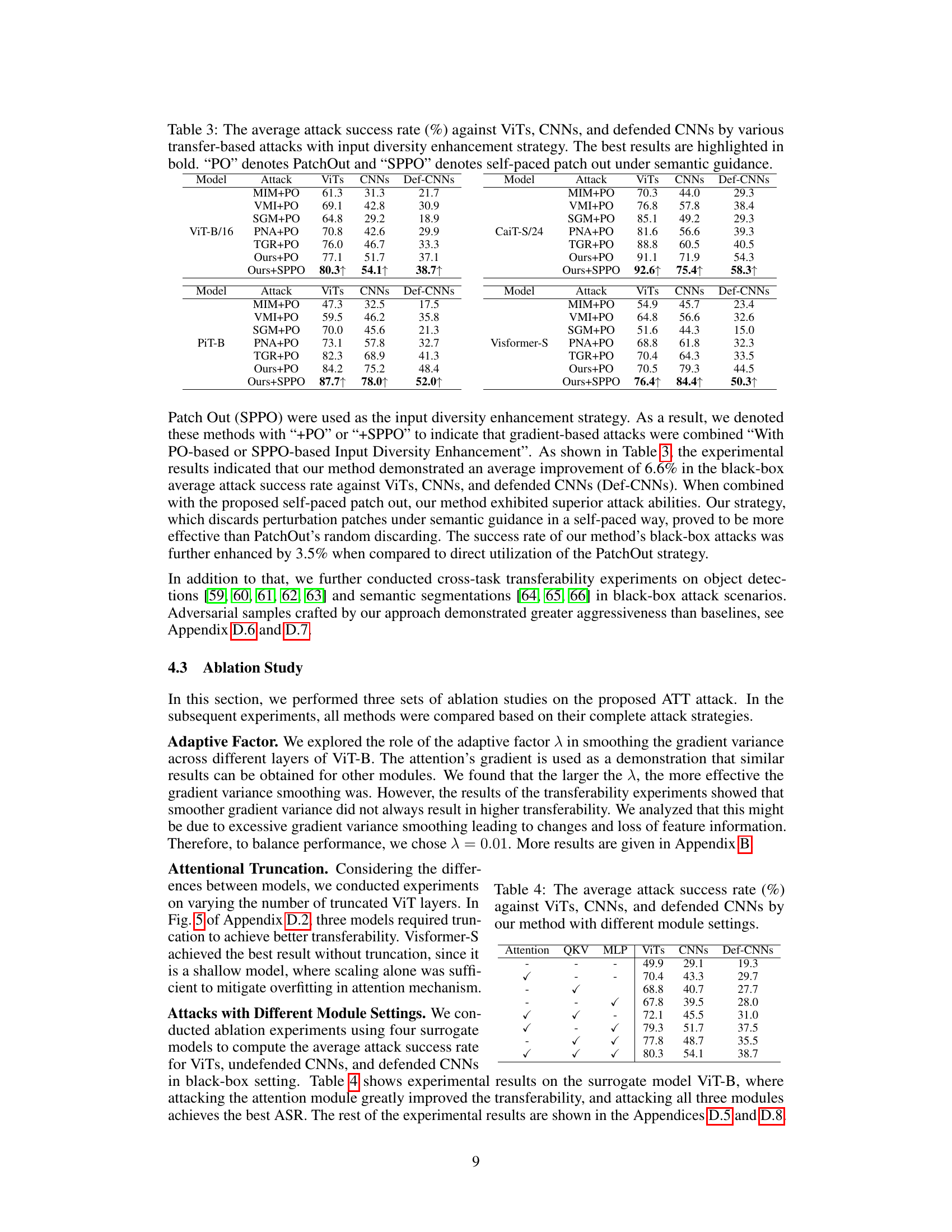
This table presents the attack success rates achieved by different transfer-based attack methods against four undefended and three defended Convolutional Neural Networks (CNNs). The success rates are shown for various ViT models used as surrogates to generate the attacks. The ‘Avgbb’ column represents the average attack success rate across all black-box models (both undefended and defended CNNs). Higher values indicate better transferability of the adversarial attacks.

This table presents the attack success rates achieved by various transfer-based attack methods against eight different Vision Transformer (ViT) models. It evaluates the transferability of these attacks by comparing performance on a set of black-box ViT models (DeiT-B, TNT-S, LeViT-256, ConViT-B) to the performance on the corresponding surrogate models. The average attack success rate across all black-box models is also provided. The table allows for a comparison of different attack strategies and their effectiveness in fooling different ViT architectures.

This table presents the attack success rates of different transfer-based adversarial attack methods against eight different Vision Transformer (ViT) models and the average attack success rate across all models tested. The methods compared include MIM, VMI, SGM, PNA, TGR, and the proposed ATT method. The table demonstrates the performance of each attack method on various ViT architectures and the overall transferability of the attacks (average performance across all models). Higher success rates indicate greater effectiveness and transferability of the attack method.

This table presents the attack success rates achieved by different attack methods against eight Vision Transformer (ViT) models. It showcases the transferability of adversarial examples generated by four different ViT models (ViT-B/16, PiT-B, CaiT-S/24, Visformer-S) against four other ViT models (DeiT-B, TNT-S, LeViT-256, ConViT-B) acting as target models. The methods compared include several baseline methods (MIM, VMI, SGM, PNA, TGR) and the proposed ATT method. The table shows the attack success rate for each surrogate model against each target model, along with the average attack success rate across all target models (Avgbb). Higher values indicate better transferability of the attack.

This table presents the results of various transfer-based attacks against four undefended and three defended Convolutional Neural Networks (CNNs). The attacks originate from four different Vision Transformers (ViTs) used as surrogate models. The table shows the attack success rate (%) for each CNN model, categorized by the ViT surrogate model used to generate the adversarial examples, and provides the average attack success rate across all CNN models (Avgbb). The highest average attack success rate for each ViT is highlighted in bold.

This table presents the average attack success rates achieved by the proposed ATT attack method with different module settings (Attention, QKV, MLP) when trained using the PiT-B surrogate model. It shows the impact of targeting specific modules during the attack on the transferability of the adversarial examples across various ViT, CNN, and defended CNN models.
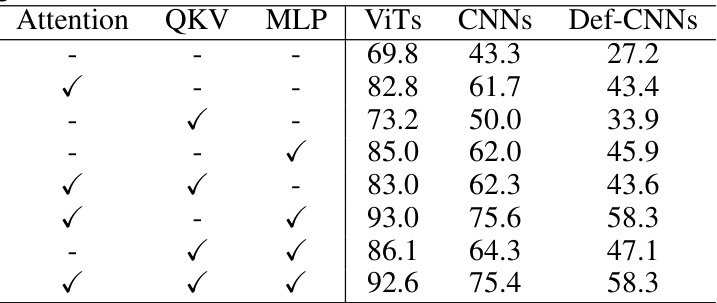
This table presents the attack success rates achieved by different transfer-based attack methods against 8 different ViT models. Each row represents a different attack method, and each column represents a different ViT model or the average success rate across all ViT models (Avgbb). The table demonstrates the transferability of various adversarial attacks. Higher success rates indicate better transferability.

This table presents the results of various transfer-based attacks against eight different Vision Transformer (ViT) models. The attack success rate (ASR) is shown for each model and averaged across all the models. The highest ASR is marked in bold for each model, allowing for easy comparison between methods. The table demonstrates the transferability of adversarial attacks, highlighting the effectiveness of different approaches across various ViT architectures.

This table presents the attack success rates achieved by different transfer-based attack methods against eight different Vision Transformer (ViT) models. The methods are compared using their attack success rates on various ViT models, and an average attack success rate across all the target models is calculated. The results show the transferability of adversarial attacks across different ViT architectures. The highest average attack success rate is highlighted in bold, indicating the most effective method.

This table presents the results of an ablation study evaluating the impact of gradient variance reduction strategies on the attack success rate (ASR). It compares the ASR achieved using only a fixed variance reduction method (“Only VR”) versus an adaptive variance reduction method (“Only AVR”). The results are shown separately for ViTs, CNNs, and defended CNNs across four different surrogate ViT models: ViT-B/16, PiT-B, CaiT-S/24, and Visformer-S. This helps isolate the contribution of the adaptive variance reduction technique.

This table presents the attack success rates achieved by different transfer-based attack methods against eight different ViT models and the average attack success rate across all tested models. The methods compared include several baselines (MIM, VMI, SGM, PNA, TGR) and the authors’ proposed ATT method. The results demonstrate the transferability of adversarial examples generated by each method across various ViT models, showing the effectiveness of the proposed approach in achieving a higher attack success rate.
Full paper#