↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current dynamic scene generation methods often lack photorealism and are object-centric due to their reliance on synthetic data and multi-view models. These methods struggle to capture complex interactions between objects and environments, hindering the creation of truly immersive 4D experiences.
4Real addresses these challenges by leveraging the power of video diffusion models trained on real-world datasets. It employs a three-step process involving reference video generation, canonical 3D representation learning, and temporal deformation modeling. The method generates dynamic scenes viewable from multiple perspectives and achieves near-photorealistic appearance and 3D motion, setting a new standard for 4D scene generation. The use of score distillation sampling further enhances efficiency and results quality.
Key Takeaways#
Why does it matter?#
This paper is important because it presents 4Real, a novel pipeline for photorealistic 4D scene generation that surpasses existing methods by discarding the dependency on multi-view generative models and fully utilizing video generative models. This approach leads to more realistic and structurally sound dynamic scenes, opening up new avenues for research in fields like virtual and augmented reality, film production, and computer graphics. The improved efficiency of 4Real, requiring only 1.5 hours on an A100 GPU compared to 10+ hours for competing methods, also makes it a more practical tool for researchers.
Visual Insights#

This figure demonstrates the 4Real framework’s ability to generate photorealistic 4D dynamic scenes from text descriptions. It shows how the system uses deformable 3D Gaussian Splats (D-3DGS) to represent the scene and allows viewing the generated scene from different viewpoints and at various timesteps. The examples illustrate the photorealism and dynamic capabilities of the model.

This table presents a quantitative comparison of the proposed 4Real model against three baseline methods (4Dfy, Dream-in-4D, and AYG) using two evaluation metrics: X-CLIP and VideoScore. X-CLIP assesses visual quality, temporal consistency, dynamic degree, text-video alignment, and factual consistency. VideoScore provides a numerical evaluation of video quality. Higher scores indicate better performance.
In-depth insights#
4D Scene Synthesis#
4D scene synthesis, the generation of dynamic 3D scenes over time, presents a significant challenge in computer graphics and vision research. Existing methods often rely on distilling knowledge from pre-trained 3D generative models, leading to object-centric results that lack photorealism. This limitation stems from the reliance on synthetic datasets, which do not fully capture the complexity and diversity of real-world scenes. A promising area of research focuses on leveraging the power of video diffusion models trained on large, real-world datasets. This approach offers the potential to generate photorealistic 4D scenes with more natural interactions and dynamics between objects and environments. However, challenges remain in handling temporal and geometric consistency, as well as efficiently reconstructing 3D representations from video data. Addressing these challenges through techniques like deformable 3D Gaussian Splats or novel video generation strategies is crucial for advancing the state-of-the-art in 4D scene synthesis.
Video Diffusion#
Video diffusion models represent a significant advancement in AI, enabling the generation of high-quality, realistic videos. They leverage the power of diffusion models, initially developed for image generation, to create videos from various inputs like text prompts, images, or even other videos. This process involves gradually adding noise to a video until it becomes pure noise, then reversing this process to generate a new video guided by the input. Key advantages include improved realism compared to previous methods and the ability to generate videos of diverse styles and content. However, challenges remain including computational cost, handling complex motions, and ensuring temporal consistency. Future research will focus on addressing these limitations to further enhance the capabilities of video diffusion models, making them an increasingly powerful tool for various applications such as film production, virtual reality, and video editing.
Canonical 3DGS#
The concept of ‘Canonical 3DGS’ in the context of photorealistic 4D scene generation likely refers to a canonical or standard 3D representation of a scene constructed from a video using deformable 3D Gaussian Splats. This canonical representation serves as a fundamental building block, capturing the essential 3D structure of the scene irrespective of temporal changes or viewpoint. The process likely involves generating a freeze-time video (a video with minimal motion), from which the canonical 3DGS is learned. This approach avoids relying on synthetic datasets, instead leveraging real-world video data. The resulting canonical 3D structure then forms the basis for generating dynamic variations of the scene, efficiently modeling temporal deformation and achieving photorealism. The creation of the canonical representation is a critical step, addressing potential inconsistencies within the freeze-frame video through techniques like jointly learning per-frame deformations. It represents a core innovation, allowing for photorealistic 4D scene generation from text prompts.
SDS for 4D#
The concept of “SDS for 4D” in the context of photorealistic video generation using diffusion models presents a significant advancement. Score Distillation Sampling (SDS), traditionally used for 2D and 3D generation, is extended here to the temporal dimension. This allows for learning of high-quality, temporally consistent 4D scenes by aligning the generated video frames with a learned canonical 3D representation. This approach is particularly valuable because it allows for generating videos from multiple perspectives, creating a more realistic and immersive experience that surpasses traditional object-centric methods. However, challenges may arise in handling inconsistencies from the video model during the canonical 3D reconstruction, requiring additional techniques like modeling per-frame deformations. The effectiveness and efficiency of this 4D-SDS approach will depend heavily on the underlying video diffusion model’s ability to generate consistent videos. This suggests that advancements in video diffusion models would have a direct impact on the overall quality and capability of this method.
Future of 4D#
The “Future of 4D” in scene generation hinges on overcoming current limitations. While impressive progress has been made in photorealistic 4D generation using video diffusion models, challenges remain. Improved video generation models are crucial, capable of producing higher-resolution, more temporally consistent videos with smoother object motion. Addressing inherent ambiguities in freeze-time video generation and achieving better multi-view consistency are also key. Furthermore, developing more efficient training methods is needed, reducing the substantial computational cost currently associated with these models. Exploring alternative representations beyond Gaussian Splats could also unlock further improvements in fidelity and efficiency. Finally, integrating more robust methods for handling complex scenes with multiple interacting objects and intricate lighting effects will significantly advance the realism of 4D environments.
More visual insights#
More on figures
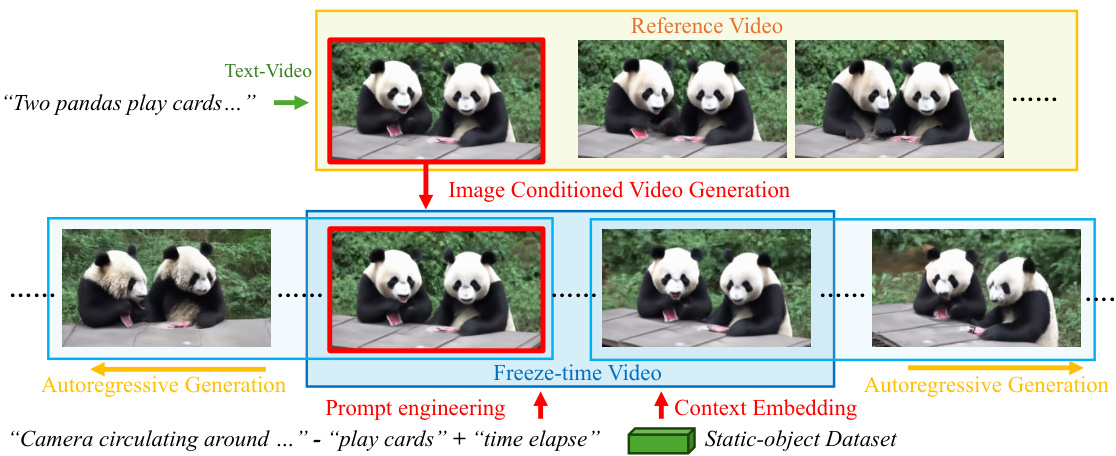
This figure illustrates the process of generating a reference video and a freeze-time video. First, a reference video is generated from a text prompt using a text-to-video diffusion model. This video will serve as the target for 4D reconstruction. Then, a freeze-time video is created using frame-conditioned video generation, along with prompt engineering and context embedding, which ensures that the resulting video contains only minimal object movement while the camera moves around the scene. Finally, autoregressive generation is used to expand the viewpoint coverage of the freeze-time video.
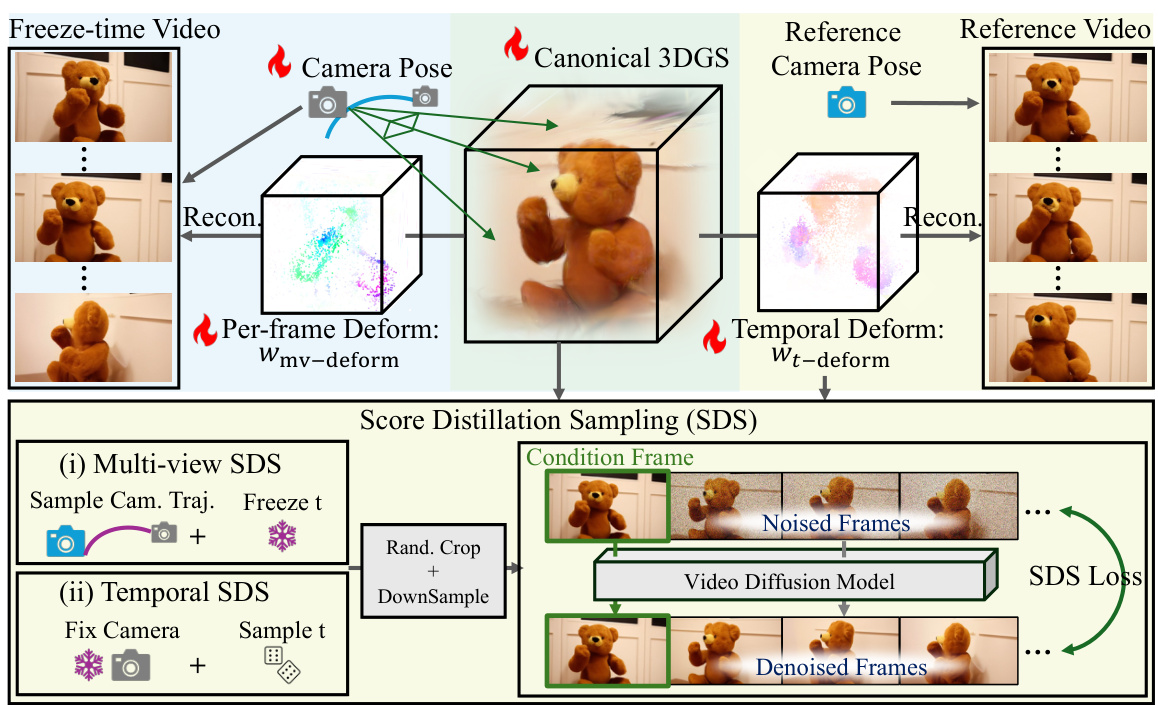
This figure illustrates the process of reconstructing deformable 3D Gaussian Splats (D-3DGS) from a freeze-time video and a reference video. It shows how the canonical 3D representation is learned from the freeze-time video, handling inconsistencies through per-frame deformations. Temporal deformations are then learned from the reference video to capture dynamic interactions. The process utilizes a video Score Distillation Sampling (SDS) strategy involving multi-view and temporal SDS to improve reconstruction quality.

This figure shows examples of 4D scenes generated by the 4Real model, demonstrating its ability to handle complex lighting conditions, semi-transparent materials (like water), and scenes with multiple interacting objects. The image showcases the model’s versatility in generating photorealistic and diverse dynamic scenes. The caption directs the reader to the supplementary materials for more examples.

This figure compares the results of 4Real with two other state-of-the-art object-centric 4D generation methods (4Dfy and Dream-in-4D). For each method, the figure shows example video frames generated from the same text prompts at different viewpoints and time steps. The comparison highlights the improved photorealism and scene diversity achieved by 4Real, particularly in handling complex scenes with multiple objects, semi-transparent materials, and dynamic lighting.

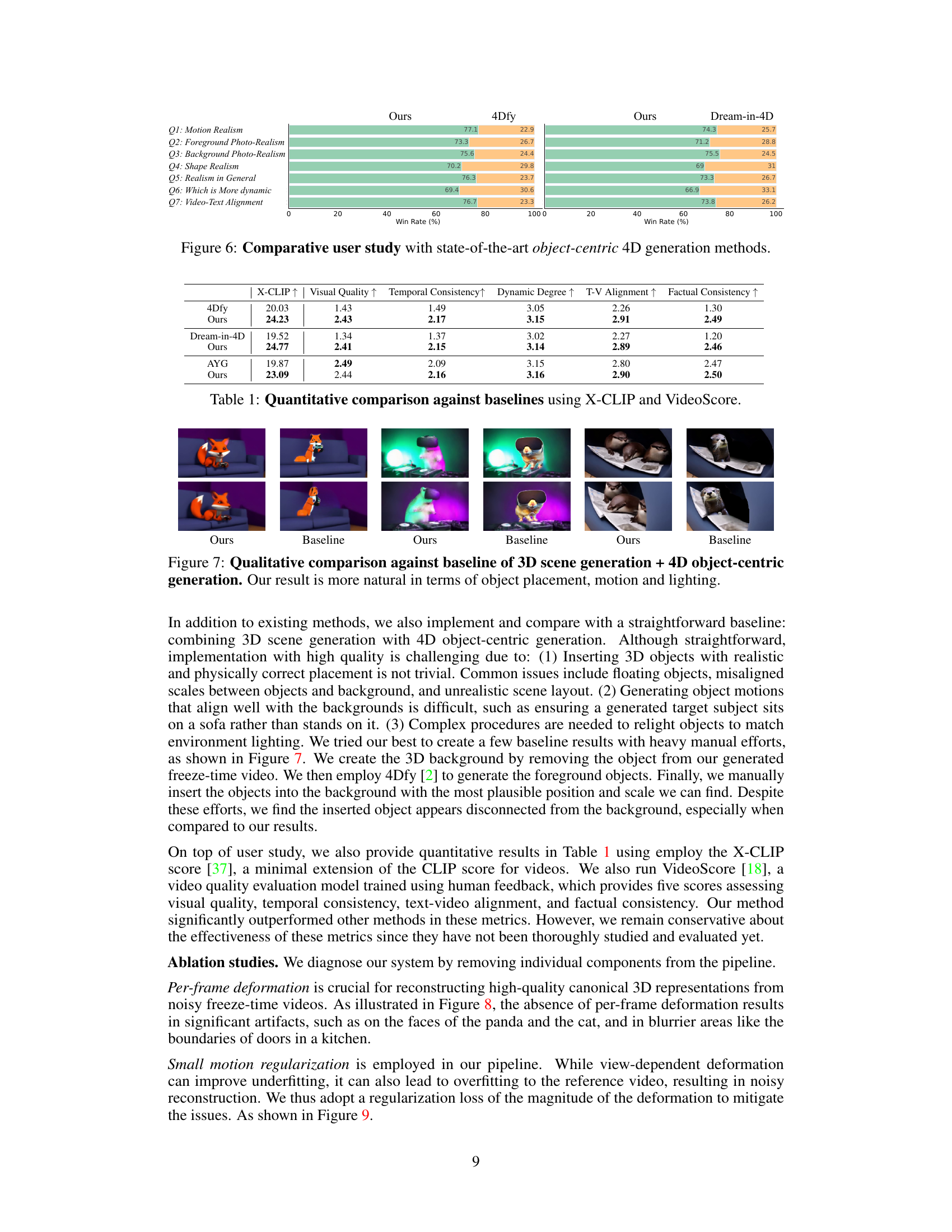
This figure displays the results of a user study comparing the proposed 4Real method to two state-of-the-art object-centric 4D generation methods: 4Dfy and Dream-in-4D. Seven qualitative aspects were evaluated: Motion Realism, Foreground Photo-Realism, Background Photo-Realism, Shape Realism, Realism in General, Which is More dynamic, and Video-Text Alignment. For each criterion, a bar chart shows the percentage of times each method was preferred. The results indicate that 4Real significantly outperforms the competing methods across all seven criteria, demonstrating its superiority in generating photorealistic and dynamic 4D scenes.

This figure presents a qualitative comparison of 4Real’s 4D scene generation results against two state-of-the-art object-centric methods: 4Dfy and Dream-in-4D. The comparison highlights 4Real’s superior ability to generate photorealistic dynamic scenes with complex lighting and semi-transparent materials. The figure showcases examples demonstrating different scenarios and object combinations, revealing 4Real’s strength in creating diverse, high-quality 4D content.

This figure shows the ablation study results of removing each component from the proposed pipeline. It demonstrates the individual contributions of per-frame deformation, multi-view SDS, freeze-time videos, and joint temporal & multi-view SDS to the overall quality and realism of the generated videos. By comparing the results with and without each component, the figure highlights the importance of each component for achieving high-quality photorealistic dynamic scenes.

This figure shows an ablation study evaluating the impact of removing different components from the proposed 4Real pipeline. By systematically removing key parts, such as per-frame deformation, multi-view SDS, freeze-time videos, and joint temporal & multi-view SDS, the authors analyze how each component affects the final generated video’s quality and visual fidelity. The results highlight the importance of each component in achieving near-photorealistic dynamic scene generation.

This figure illustrates the process of reconstructing deformable 3D Gaussian Splats (D-3DGS) for dynamic scene representation. It starts with a freeze-time video (containing minimal motion) and uses it to reconstruct canonical 3DGS. To address inconsistencies in the freeze-time video, per-frame deformations are learned jointly with the canonical 3DGS. Finally, temporal deformations are learned from the reference video to capture dynamic scene behavior. The process uses a video score distillation sampling (SDS) strategy for improved quality and regularization.
Full paper#