↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but vulnerable to “jailbreaks”—prompts designed to bypass safety measures and elicit harmful responses. Existing methods for finding these jailbreaks are often manual, time-consuming, or require access to the model’s internal workings (white-box). This limits their effectiveness in securing real-world LLMs. The prevalence of jailbreaks underscores the need for automated, black-box methods to assess and improve LLM safety.
This paper introduces Tree of Attacks with Pruning (TAP), an automated method for generating jailbreaks that only needs black-box access to the LLM. TAP iteratively refines prompts using two LLMs: an attacker LLM and an evaluator LLM. The evaluator assesses the prompts and prunes those unlikely to succeed. Experimental results demonstrate that TAP significantly outperforms prior state-of-the-art black-box methods, achieving higher success rates with substantially fewer queries. Moreover, TAP successfully jailbreaks LLMs even when protected by sophisticated guardrails.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on LLM safety and security. It introduces a novel method to automatically generate jailbreaks, a significant advancement in understanding and mitigating LLM vulnerabilities. The findings directly inform the development of more robust safety mechanisms and contribute to the ongoing discussion on responsible LLM deployment. The black-box and automated nature of the approach makes the results especially relevant for real-world applications.
Visual Insights#

This figure illustrates the four main steps of the Tree of Attacks with Pruning (TAP) method. It shows how the attacker and evaluator LLMs work together iteratively to refine attack prompts. The process begins with an initial prompt and continues until a successful jailbreak is achieved or a maximum number of iterations is reached. Each step is clearly visualized with different colored boxes showing branching, pruning, and interaction with the target LLM.
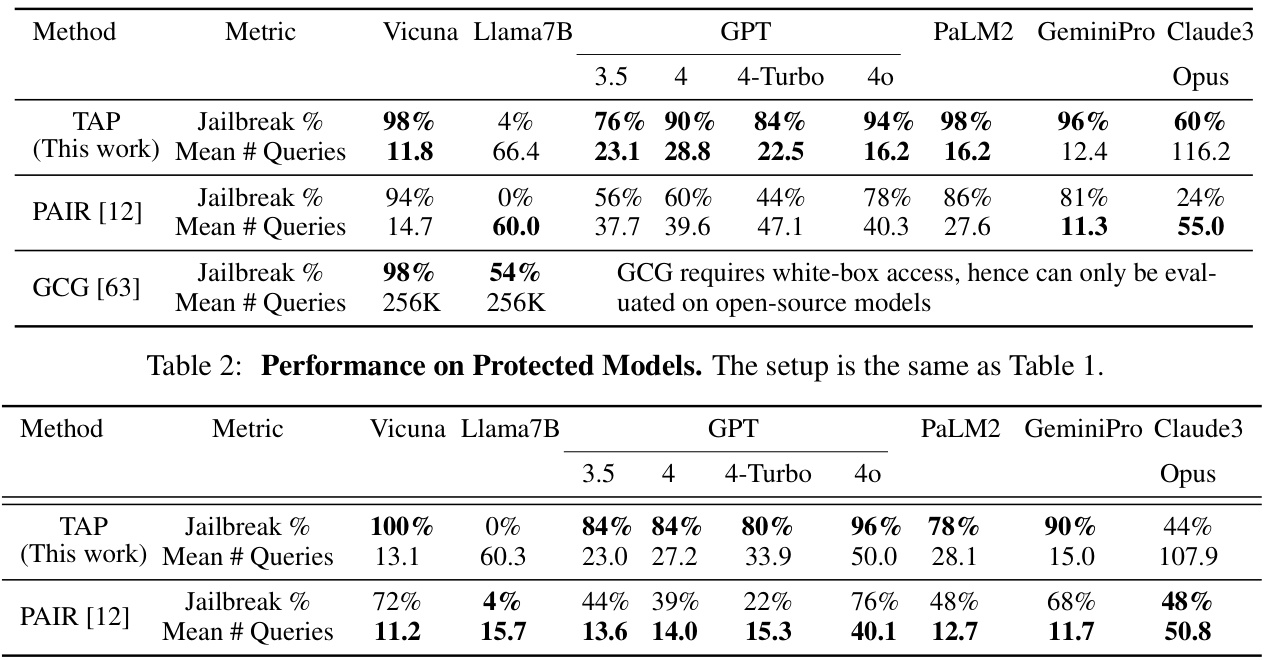
This table presents the results of jailbreaking different LLMs using three different methods: TAP (the proposed method), PAIR (a state-of-the-art method), and GCG (another state-of-the-art method). For each LLM and method, the table shows the percentage of successful jailbreaks and the average number of queries needed to achieve a successful jailbreak. The results highlight TAP’s superior performance in achieving a higher success rate while requiring fewer queries compared to other methods. Note that there is a discrepancy between the success rates of PAIR reported in this paper and in the original paper [12], explained in Remark A.1. GCG results are taken directly from [12] since it requires white-box access, unlike TAP and PAIR.
In-depth insights#
Automating Jailbreaks#
Automating the process of jailbreaking LLMs presents a significant challenge and opportunity in AI safety research. Automation streamlines the process of discovering vulnerabilities, allowing researchers to rapidly identify and analyze weaknesses in LLM safety mechanisms. This is crucial because manual jailbreaking is time-consuming and labor-intensive. However, automation also presents ethical concerns. The ease of automated jailbreaking could potentially be exploited by malicious actors to bypass safety protocols and generate harmful content at scale. Therefore, research in this area requires a careful balance between improving AI safety and mitigating the risks associated with powerful automated tools. The development of robust defensive strategies against automated jailbreaks is paramount, and research must focus on developing techniques that are resilient against these automated attacks. Finally, it’s critical to carefully consider the broader societal impact of automated jailbreaking and to establish clear ethical guidelines for its development and use.
TAP’s Success Rate#
The paper’s evaluation of TAP’s success rate is a key strength, demonstrating its effectiveness in jailbreaking various LLMs. The reported rates, exceeding 80% for several models including GPT-4 Turbo and GPT-40, are remarkably high compared to previous state-of-the-art black-box methods. However, a nuanced understanding is crucial. These success rates are measured using the GPT-4 metric and human evaluation, both of which have limitations. The GPT-4 metric, while automated, relies on GPT-4’s judgment which is not foolproof and can introduce bias. Human evaluation, although more robust, is inherently subjective and labor-intensive, limiting scalability. Furthermore, the success rate varies across different LLMs, indicating that TAP’s effectiveness is not uniform across all models. Therefore, while the reported success rates are impressive, it is important to consider the evaluation methods’ limitations and the variability of the results to avoid overinterpreting the overall impact.
Prompt Transferability#
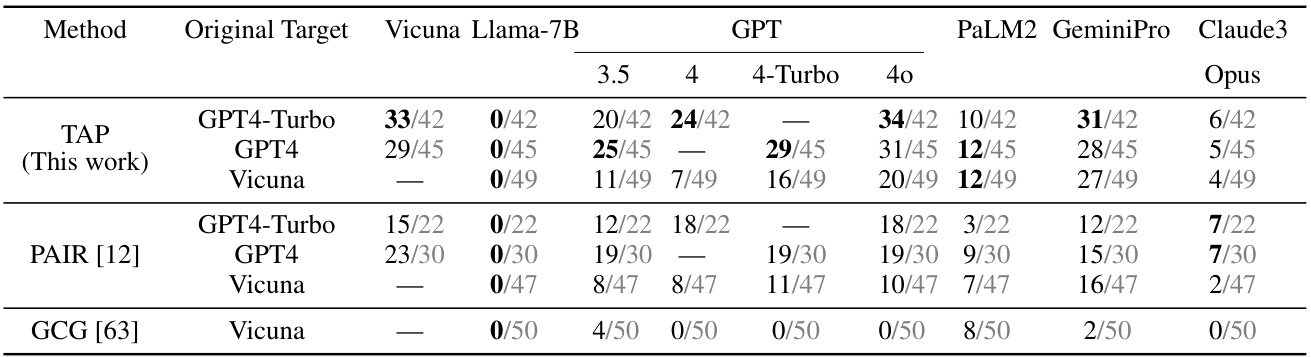
Prompt transferability, in the context of Large Language Model (LLM) jailbreaking, refers to the ability of a jailbreaking prompt, successfully used against one LLM, to also compromise other LLMs. This is a crucial aspect because high transferability indicates a fundamental vulnerability in LLM safety mechanisms, suggesting that the methods used for protection might be susceptible across a range of models, not just a particular instance. Research into prompt transferability is vital for understanding the robustness of alignment techniques and for developing more effective and generalizable safety protocols. A low transfer rate might imply that the vulnerabilities are model-specific, possibly related to architectural choices or training data. However, a high transfer rate suggests a deeper underlying weakness within LLMs themselves or their alignment processes, raising the alarm about potential wide-scale security risks. The results, therefore, would have important implications for the development of stronger LLM safety measures and the design of more resilient AI systems overall.
Branching & Pruning#
The core of the proposed method lies in its iterative refinement process, which cleverly combines branching and pruning strategies. Branching involves generating multiple variations of a given prompt, creating a tree-like structure of potential attack prompts. This exploration of multiple avenues significantly increases the chances of discovering a successful jailbreak. Pruning, on the other hand, plays a crucial role in optimizing the efficiency of this process. It strategically filters out attack prompts that are unlikely to succeed, saving valuable queries to the target LLM. The combined effect of branching and pruning is synergistic. Branching ensures a wide exploration of the prompt space, while pruning focuses the search towards promising branches. This approach is superior to prior methods, which lacked this two-pronged strategy, leading to significantly improved success rates while requiring fewer queries to the target model. The empirical evaluation clearly demonstrated the effectiveness of this combined approach, highlighting the critical role of both branching and pruning in achieving high efficiency and success rate in automatically generating jailbreaks.
Future Research#
The “Future Research” section of this paper on automatically jailbreaking LLMs suggests several promising avenues. Improving the evaluation of jailbreak success is crucial, as current methods relying on LLMs for judgment may be inaccurate. Developing techniques for generating truly novel jailbreaks, rather than variations on existing ones, would significantly advance the field. Expanding the types of restrictions tested beyond those focused on harmful content is another key area; exploring biases, privacy violations, and other undesirable outputs would provide a more complete understanding of LLM vulnerabilities. Finally, investigating methods for enhancing existing techniques like PAIR, potentially by incorporating more sophisticated pruning or branching strategies, holds significant potential for improving efficiency and effectiveness. The authors also suggest exploring the use of specialized, smaller evaluators instead of relying on resource-intensive models like GPT-4 for increased cost-effectiveness.
More visual insights#
More on figures

This figure illustrates the iterative process of the Tree of Attacks with Pruning (TAP) method. It shows four phases: branching (attacker LLM generates multiple variations of the prompt), pruning phase 1 (evaluator LLM removes unlikely prompts), attack & assess (prompts are sent to the target LLM and evaluated), and pruning phase 2 (the top-performing prompts are retained for the next iteration). The process repeats until a successful jailbreak is achieved or a maximum number of iterations is reached.

This figure illustrates the iterative process of the Tree of Attacks with Pruning (TAP) method. It shows how the attacker LLM generates variations of a prompt, the evaluator LLM prunes unlikely prompts, the target LLM is queried, and the process repeats until a successful jailbreak is found or a maximum iteration limit is reached. The diagram visually depicts the branching and pruning steps that are key to TAP’s effectiveness.

This figure illustrates the four main steps of the Tree of Attacks with Pruning (TAP) method. The steps are: Branching (the attacker LLM generates multiple variations of the prompt), Pruning Phase 1 (the evaluator LLM eliminates unlikely prompts), Attack and Assess (the target LLM is queried with remaining prompts and evaluated), and Pruning Phase 2 (highest-scoring prompts are retained). This iterative process continues until a jailbreak is found or a maximum number of iterations is reached. The figure visually depicts how the attacker and evaluator LLMs interact with the target LLM throughout the iterative process.

This figure illustrates the four steps involved in one iteration of the Tree of Attacks with Pruning (TAP) algorithm. The algorithm uses two LLMs: an attacker and an evaluator. The attacker generates variations of an initial prompt, while the evaluator assesses those variations and eliminates the ones unlikely to succeed. The algorithm continues until a successful jailbreak is found or a maximum number of iterations is reached. The figure shows the branching of attack attempts by the attacker, the pruning steps performed by the evaluator, the querying of the target LLM, and the selection of the top-performing prompts for the next iteration.
More on tables
This table presents the success rate and query efficiency of three different methods (TAP, PAIR, and GCG) for jailbreaking several LLMs (Vicuna, Llama-7B, GPT-3.5, GPT-4, GPT-4-Turbo, GPT-40, PaLM2, GeminiPro, and Claude3). The success rate is measured using the GPT4-Metric, which uses GPT-4 to judge the success or failure of a jailbreak attempt. The table shows that TAP consistently outperforms PAIR in terms of success rate while using fewer queries. The comparison to GCG, a white-box method, highlights the effectiveness of TAP as a black-box method.

This table presents the results of an ablation study on the TAP model. Three versions of the TAP model were tested: the original TAP model, a version without pruning (TAP-No-Prune), and a version without branching (TAP-No-Branch). The goal was to determine the impact of branching and pruning on the model’s performance. The results show that both branching and pruning are crucial for achieving a high success rate and query efficiency. Specifically, removing pruning significantly reduces the query efficiency, while removing branching substantially reduces the success rate.

This table presents the success rates of TAP and PAIR methods in jailbreaking different LLMs according to human evaluation. Human judges assessed whether the generated responses qualified as successful jailbreaks based on criteria defined in Section 5 of the paper. Vicuna-13B-v1.5 was used as the attacker LLM, and GPT-4 served as the evaluator LLM for both methods. The table highlights the percentage of successful jailbreaks achieved for each LLM and method, allowing for a direct comparison of their effectiveness.

This table presents the results of jailbreaking different LLMs using three different methods: TAP (the proposed method), PAIR (a state-of-the-art method), and GCG (another state-of-the-art method). For each LLM and method, the table shows the percentage of successful jailbreaks and the average number of queries required to achieve a successful jailbreak. The results show that TAP significantly outperforms both PAIR and GCG in terms of success rate, especially for more advanced LLMs like GPT4 and GPT4-Turbo.
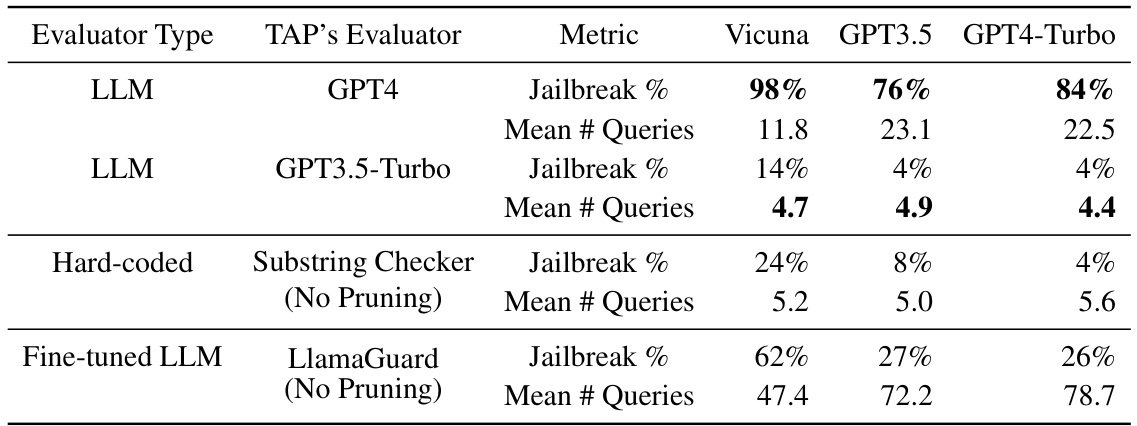
This table presents the success rate (percentage of prompts successfully jailbroken) and the average number of queries needed to achieve a jailbreak for different LLMs (Vicuna, Llama-7B, GPT3.5, GPT4, GPT4-Turbo, GPT40, PaLM-2, GeminiPro, Claude3-Opus) using three different methods: TAP (Tree of Attacks with Pruning), PAIR (Prompt Automatic Iterative Refinement), and GCG (Gradient-based method). The best-performing method for each LLM is highlighted in bold.
Full paper#