↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Foundation models, while powerful, often struggle to provide diverse outputs. Existing methods, like temperature sampling, often sacrifice accuracy for diversity. This is particularly problematic for applications requiring precision, such as code generation. The lack of diversity can lead to unsatisfactory user experiences and limit the model’s adaptability to varied user preferences.
This paper introduces the Synthesize-Partition-Adapt (SPA) framework to address this issue. SPA leverages synthetic datasets, partitioning them based on influence functions, and training multiple specialized model adaptations. This approach successfully generates diverse outputs while maintaining high accuracy across various tasks, including code generation and natural language understanding. SPA demonstrates significant improvements in diversity without compromising the quality of the generated responses.
Key Takeaways#
Why does it matter?#
This paper is significant for researchers because it introduces a novel framework for eliciting diverse and high-quality responses from foundation models. This addresses a critical challenge in enhancing user experience and satisfaction. It opens new avenues for research on data partitioning techniques, model adaptation methods, and the effective use of synthetic datasets to improve the diversity and quality of foundation model outputs.
Visual Insights#

This figure illustrates the problem of generating diverse responses from a foundation model. A user requests a personal website template. The model provides two different templates as responses, highlighting the diversity of the outputs. This scenario motivates the need for methods that generate diverse and high-quality responses, without sacrificing accuracy.
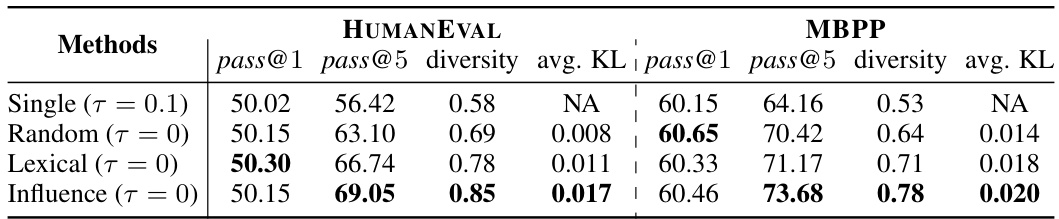
This table presents the results of the SPA framework and baseline models on the HumanEval and MBPP benchmarks for code generation. It compares performance metrics such as pass@1 (the percentage of problems for which at least one of the generated samples passes all the test cases), pass@5, diversity score, and average KL divergence across different methods, including single adaptation, random partitioning, lexical overlap, and influence function. The results show that SPA with influence function achieves the best diversity while maintaining high quality.
In-depth insights#
Diverse Sample Synthesis#
Diverse sample synthesis within the context of large language models (LLMs) is a crucial area of research. The goal is to generate a variety of high-quality outputs for a single prompt, catering to different user preferences and needs. This requires going beyond simple sampling techniques, which often trade off diversity for accuracy. Effective strategies must leverage the model’s inherent capabilities while carefully managing potential risks like hallucination or nonsensical outputs. One promising approach involves the use of synthetic data, which can be pre-processed using techniques like data partitioning or influence functions. This allows the creation of tailored subsets for fine-tuning multiple specialized models, each capturing unique aspects of the input data and, thus, generating diverse responses. Careful selection of data partitioning methods is critical to achieving a desirable balance between diversity and quality. The evaluation of such methods is typically performed using metrics such as average KL divergence or sample diversity, while the quality of outputs is assessed through human evaluation or task-specific metrics. Further research is needed to fully explore the capabilities of diverse sample synthesis methods, including the development of more efficient data partitioning and model adaptation techniques.
SPA Framework#
The SPA framework, presented as a novel approach for eliciting diverse responses from foundation models, leverages the readily available synthetic data in various domains. Its core strength lies in the three-stage process: Synthesize, Partition, and Adapt. First, it utilizes existing synthetic datasets. Second, it employs data attribution methods (like influence functions) to partition the data into subsets, each capturing unique data aspects. Finally, it trains multiple model adaptations—using efficient methods such as LoRA—that are optimized for these distinct subsets. This methodology contrasts with traditional diversity-enhancing techniques (temperature sampling) by prioritizing quality while promoting diversity. The SPA framework’s effectiveness is demonstrated through experiments on HumanEval, MBPP, and other natural language understanding tasks, showing its ability to generate diverse, high-quality outputs across various domains. A key advantage is its compatibility with greedy sampling, offering precision without sacrificing diversity. The framework’s reliance on readily available synthetic data further enhances its scalability and applicability. However, further exploration is needed to mitigate the computational demands of influence functions and refine data partitioning strategies.
Data Attribution Methods#
Data attribution methods are crucial for understanding the influence of individual data points on a model’s behavior. Influence functions, a prominent technique, quantify this impact by assessing how changes in a single data point’s weight affect model parameters. While effective, influence functions can be computationally expensive, especially for large models, making approximations necessary. Alternative methods, such as lexical overlap, offer computationally cheaper alternatives but might lack the nuanced understanding provided by influence functions. The choice of method depends on the specific application and available computational resources. A key challenge lies in balancing the trade-off between accuracy and computational cost when selecting a data attribution method. Future research could explore more efficient methods and investigate the effectiveness of various approaches across diverse datasets and model architectures.
Adaptation Strategies#
Adaptation strategies in the context of foundation models are crucial for enhancing their performance and capabilities in specific domains. Fine-tuning, a common method, involves training a pre-trained model on a new dataset relevant to the target application. However, this approach can be resource-intensive. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, offer a more efficient alternative by only updating a small subset of model parameters. The choice of adaptation strategy depends on factors like dataset size, computational resources, and desired performance gains. Data augmentation can be used to increase the size and diversity of training datasets, improving model generalization. Techniques like knowledge distillation leverage the knowledge of larger models to train smaller, faster ones. Successfully choosing and implementing an appropriate adaptation strategy leads to enhanced model performance and enables wider application of foundation models across various tasks and domains. Model selection and the quality of the adaptation datasets also significantly influence the success of these strategies.
Future Work#
The paper’s ‘Future Work’ section would ideally explore several avenues to advance the Synthesize-Partition-Adapt (SPA) framework. Expanding the data attribution methods beyond influence functions and lexical overlap is crucial; investigating techniques like TRAK and K-FAC, and potentially exploring novel methods, could significantly enhance SPA’s adaptability and performance. Addressing the computational cost of influence function calculations for large models is paramount; exploring efficient approximations or alternative, less computationally intensive strategies will be key to making SPA practical for real-world applications. Refinement of the data partitioning techniques beyond the ranking heuristic is important, perhaps employing clustering algorithms like k-means to achieve more balanced partitions and robust performance. Evaluating the robustness of SPA across various model sizes and architectures would provide valuable insights into its generalizability and limitations. Finally, conducting a more comprehensive analysis of the interplay between diversity and quality is warranted, as it’s a central aspect of SPA, aiming to move beyond simple metrics like pass@1 and pass@5 towards more nuanced evaluation criteria that encompass human judgment and user experience.
More visual insights#
More on figures

This figure shows the performance (pass@1 on the HumanEval benchmark) of a model fine-tuned using LORA on increasing amounts of the OSS-Instruct dataset. The plot demonstrates the law of diminishing returns; while performance improves with more data, the rate of improvement slows significantly as the amount of training data increases. This highlights the potential benefit of SPA, which uses data partitioning to train multiple specialized models rather than training a single model on the entire dataset.
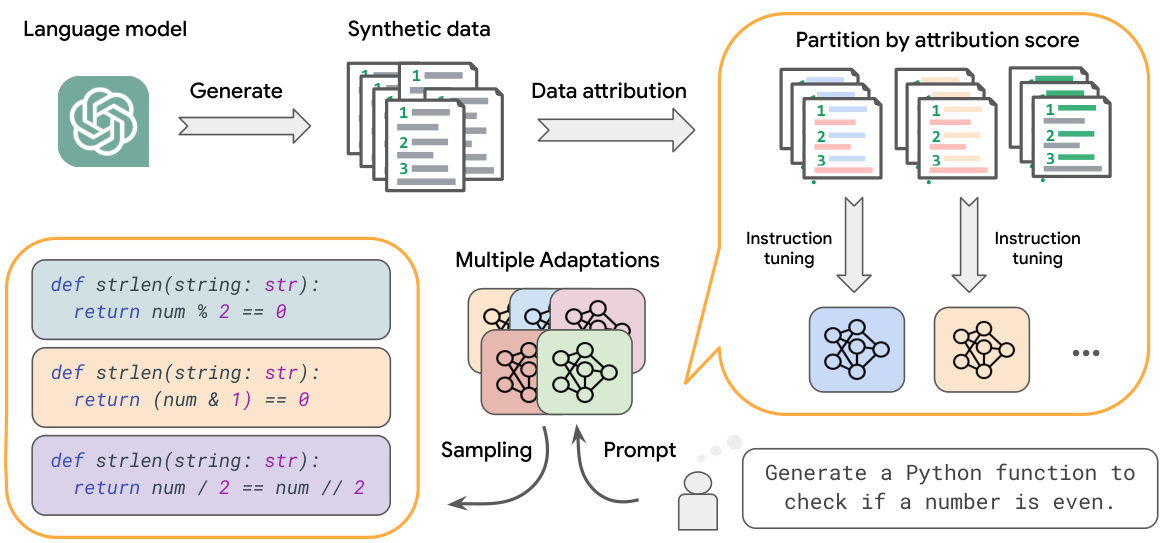
This figure illustrates the SPA framework. First, synthetic data is generated and then analyzed using data attribution methods (like influence functions or lexical overlap) to score each data point’s importance. These scores are used to partition the dataset into subsets. Finally, multiple model adaptations are trained on these subsets, allowing the model to generate diverse responses by sampling from the adapted models.
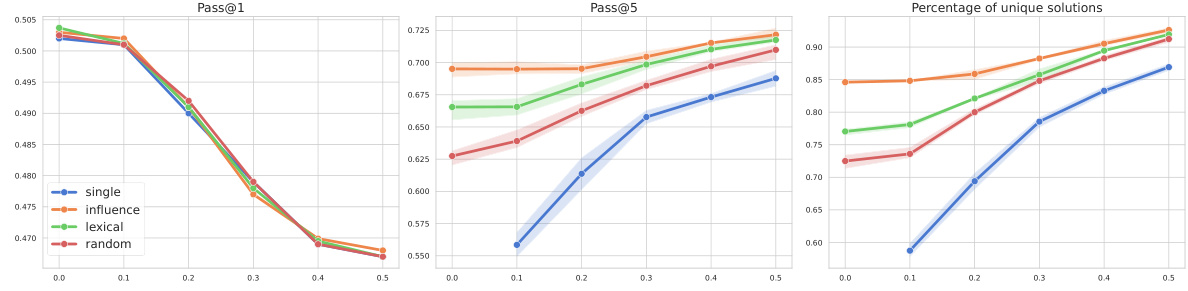
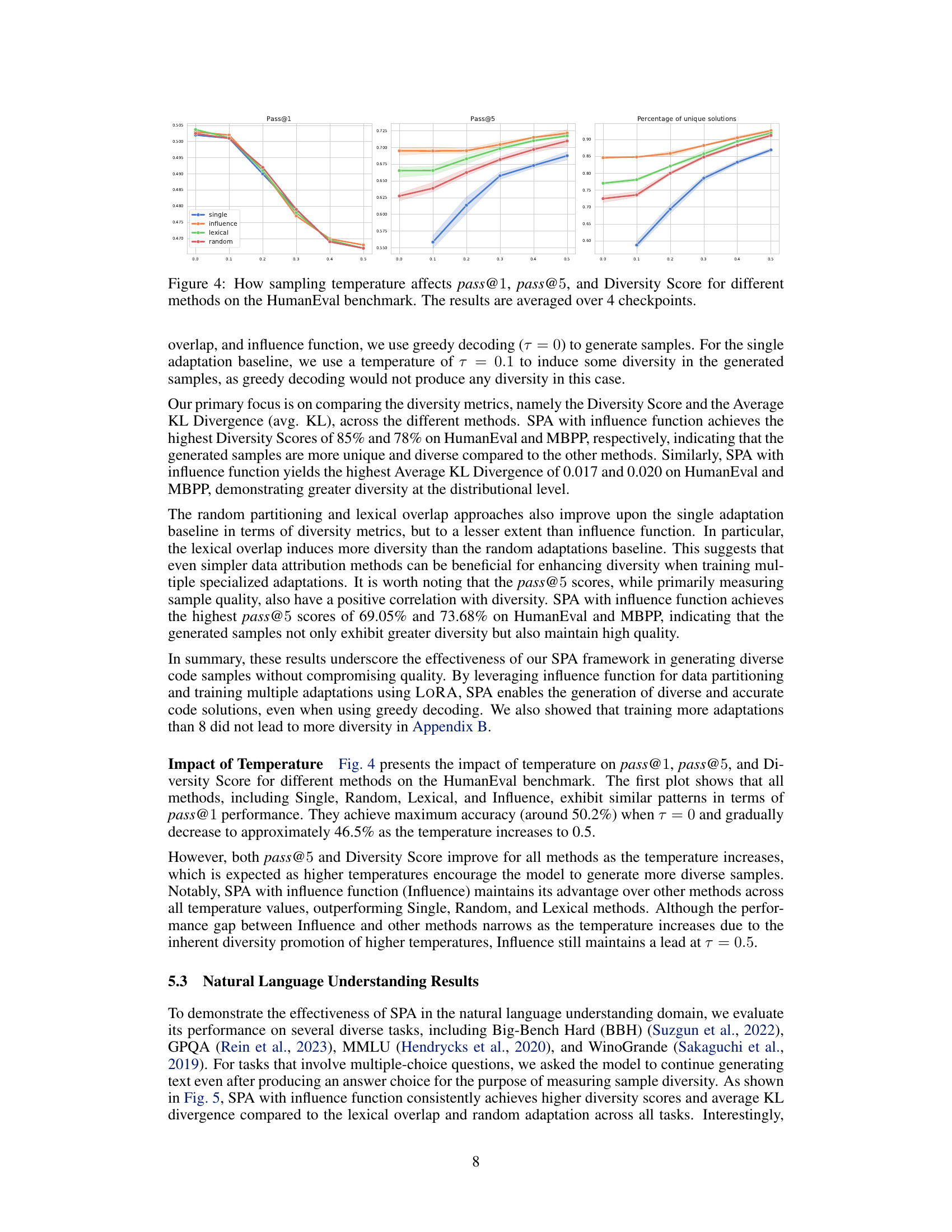
This figure shows the impact of different sampling temperatures on the performance of various methods (single adaptation, random partitioning, lexical overlap, and influence function) for the HumanEval benchmark. The x-axis represents the temperature used for sampling, while the y-axes represent pass@1 (the percentage of problems where at least one of the generated samples passes all test cases), pass@5 (the percentage of problems where at least five of the generated samples pass all test cases), and the Diversity Score (a measure of the uniqueness of generated samples). Error bars are included to show variability across different checkpoints. The results demonstrate a trade-off between diversity and accuracy, with higher temperatures leading to greater diversity but potentially lower accuracy. The influence function consistently outperforms other methods across all temperature values.

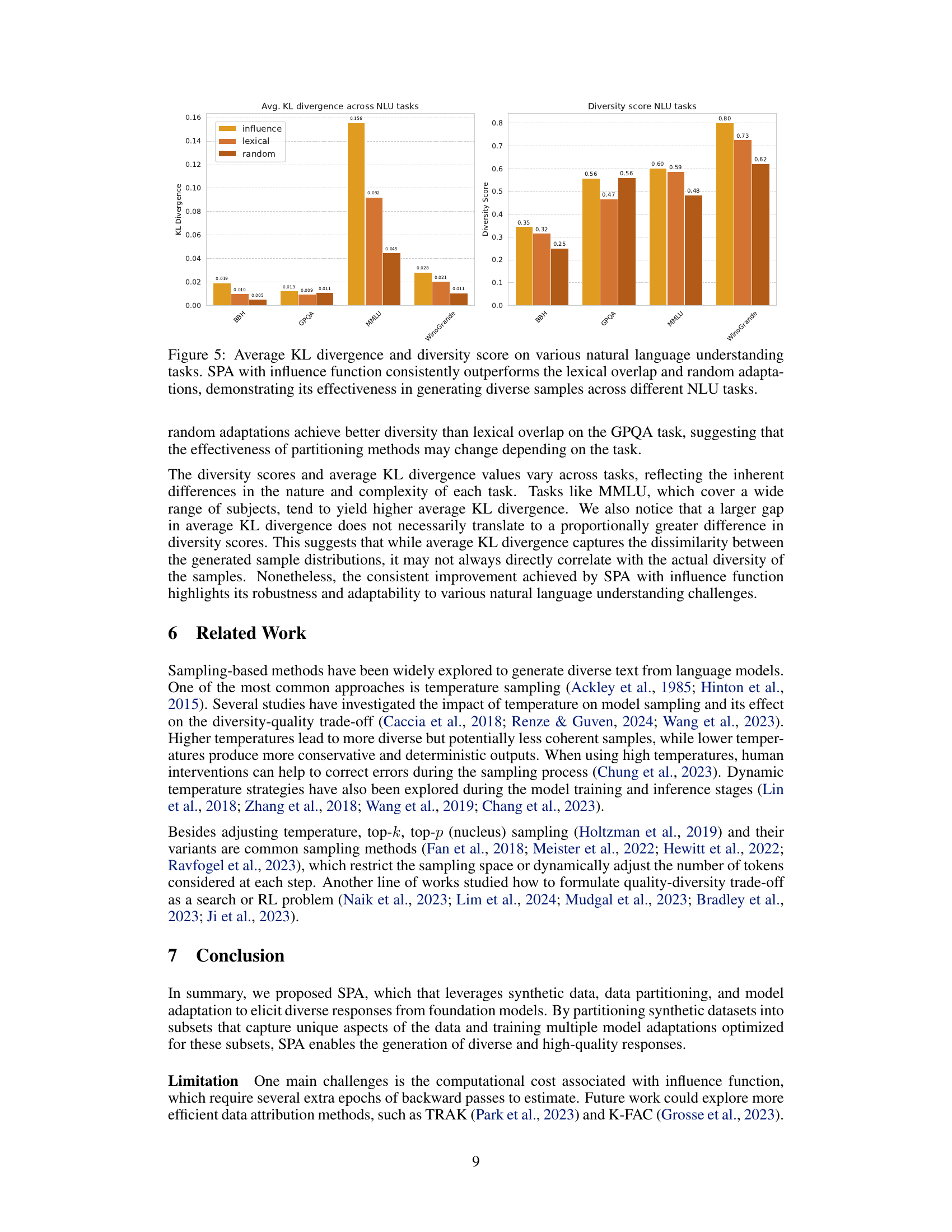
This figure compares the performance of three different methods for generating diverse responses from language models on four natural language understanding tasks: BBH, GPQA, MMLU, and Winogrande. The methods are SPA with influence function, SPA with lexical overlap, and random adaptation. The figure shows that SPA with influence function consistently achieves higher average KL divergence and diversity scores across all four tasks, indicating that it is the most effective method for generating diverse responses.
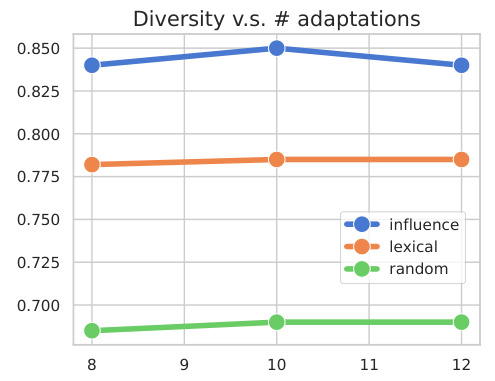
This figure shows the diversity score obtained using different data partitioning methods (influence, lexical, random) as the number of model adaptations is varied from 8 to 12. The results indicate that increasing the number of adaptations beyond a certain point does not significantly improve diversity, regardless of the chosen partitioning method. The influence method consistently achieves higher diversity scores than the other two methods.
Full paper#