↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Spiking Neural Networks (SNNs) are energy-efficient alternatives to Artificial Neural Networks (ANNs) but suffer from lower accuracy due to limited expressiveness from binary spike feature maps. Existing methods like direct ANN-SNN weight transfer or knowledge distillation often yield suboptimal results. This paper addresses the challenge of improving SNN accuracy by focusing on enriching the output feature representation.
The paper proposes two key methods: 1) LAF Loss, a novel knowledge distillation technique that aligns ANN and SNN output features using an ANN classifier, effectively transferring knowledge from the high-performing ANN to the SNN; 2) RepAct, which replaces the LIF activation layer with a ReLU layer to generate richer, full-precision output features. Experiments demonstrate that these methods significantly improve SNN performance across various datasets, outperforming current state-of-the-art techniques. The findings suggest a promising approach to bridging the accuracy gap between SNNs and ANNs.
Key Takeaways#
Why does it matter?#
This paper is important because it presents novel methods to improve the accuracy of spiking neural networks (SNNs), a crucial area for energy-efficient AI. The proposed techniques, focusing on enhancing output feature representation, offer significant improvements over existing state-of-the-art algorithms, opening avenues for further research in this rapidly evolving field. The results have implications for low-power AI applications, pushing the boundaries of energy-efficient computing.
Visual Insights#

This figure illustrates the proposed EnOF-SNN method. It shows three network structures: a trained ANN, a vanilla SNN, and the proposed improved SNN. The ANN is used as a teacher network, its output features guiding the training of the SNN via a Kullback-Leibler (KL) divergence loss (LAF loss). The proposed SNN modifies the vanilla SNN by replacing the last LIF activation layer with a ReLU activation, aiming to create a richer output feature representation. This results in a full precision output feature for the SNN, improving its performance.
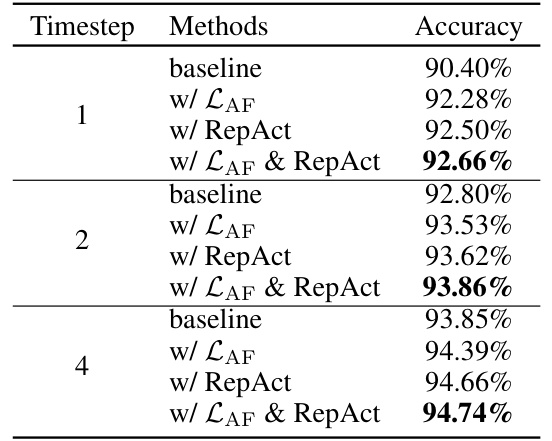
This table presents the results of ablation experiments conducted to evaluate the impact of the proposed methods, LAF and RepAct, individually and in combination. It shows the top-1 accuracy achieved on the CIFAR-10 dataset using a spiking ResNet20 architecture with different numbers of timesteps (1, 2, and 4). The baseline represents the accuracy without LAF and RepAct. The table demonstrates the improvements in accuracy gained by incorporating each method and the synergistic effect of using both techniques together.
In-depth insights#
EnOF-SNN: Output Feature Enhancement#
EnOF-SNN, focusing on output feature enhancement, presents a novel approach to improve the accuracy of spiking neural networks (SNNs). The core idea is to leverage the richer representational capacity of their full-precision ANN counterparts. This is achieved through two key methods: First, a novel knowledge distillation method, termed LAF loss, aligns the SNN’s feature representation with that of the ANN using the ANN’s classifier. This ensures the SNN learns a more discriminative feature space. Second, replacing the LIF activation layer with a ReLU layer in the final output layer generates a full-precision output feature, further enhancing the expressiveness of the SNN, with minimal computational overhead. This dual approach effectively bridges the representational gap between ANNs and SNNs, leading to significant improvements in classification accuracy across diverse benchmark datasets, demonstrating the efficacy of enhancing SNN output features for improved performance.
ANN-SNN Knowledge Distillation#
ANN-SNN knowledge distillation aims to transfer the knowledge learned by a high-performing Artificial Neural Network (ANN) to a more energy-efficient Spiking Neural Network (SNN). This is crucial because SNNs, while biologically inspired and promising for low-power applications, often lag behind ANNs in accuracy. The core idea is to leverage the rich feature representations and superior classification capabilities of a pre-trained ANN to guide the training of an SNN. This can involve various techniques, such as aligning the output features of both networks, using the ANN’s classifier to supervise the SNN’s learning, or transferring weight parameters with modifications. Effective knowledge distillation is vital in bridging the performance gap between ANNs and SNNs. However, challenges exist: directly transferring ANN weights may not capture the temporal dynamics of SNNs, and aligning features may need sophisticated loss functions to accommodate the binary nature of SNN spike trains. Successful ANN-SNN distillation methods need to carefully address these challenges to unlock the full potential of SNNs for real-world applications.
ReLU Activation Layer Replacement#
Replacing the LIF (Leaky Integrate-and-Fire) activation layer with a ReLU (Rectified Linear Unit) layer in spiking neural networks (SNNs) is a significant modification with substantial implications. The LIF layer, a cornerstone of SNNs, inherently produces binary spike outputs, limiting the network’s representational capacity. ReLU, on the other hand, offers a full-precision output, substantially enhancing the expressiveness of the network’s feature representation before classification. This shift facilitates easier training and potentially leads to improved accuracy, especially in deeper networks. The trade-off, however, involves a slight increase in computational complexity, as ReLU’s continuous output necessitates slightly more processing than the binary nature of LIF spikes. The effectiveness of this replacement hinges on the balance between the increased accuracy and computational costs. This makes it crucial to carefully evaluate performance gains against hardware resource constraints for practical deployment.
Spiking ResNet20 Architecture#
A Spiking ResNet20 architecture would likely involve replacing the traditional ReLU activation units in a standard ResNet20 with spiking neuron models, such as the Leaky Integrate-and-Fire (LIF) neuron. This conversion presents several key challenges and opportunities. The inherent binary nature of spikes (0 or 1) in SNNs compared to the continuous values in ANNs necessitates careful consideration of how to represent and process information effectively. Methods such as temporal coding, where information is encoded in the timing of spikes, become crucial. The training process would also differ significantly. Backpropagation through time (BPTT) or surrogate gradient methods are often employed to address the non-differentiability of spike events. A well-designed spiking ResNet20 architecture would need to balance accuracy with energy efficiency, the primary motivation behind using SNNs. The depth of the network would need careful tuning as increased depth can lead to vanishing gradients or poor information transmission. Strategies to enhance the representational power of the spiking layers, such as incorporating more sophisticated neuron models or employing novel learning rules, would likely be crucial for achieving high accuracy. The architecture’s performance would need to be evaluated on benchmark datasets, comparing it to both traditional ANN-based and other SNN approaches to highlight its advantages and limitations.
Future Research Directions#
Future research could explore several promising avenues. Improving the efficiency of the training process is crucial, especially for deeper SNNs, by investigating alternative training algorithms beyond STBP and addressing the vanishing gradient problem. Exploring different neural architectures beyond the ResNet family and implementing hybrid ANN-SNN models could significantly enhance performance. Investigating alternative spiking neuron models and exploring different coding schemes could lead to more robust and efficient SNNs. Finally, applying SNNs to more complex tasks such as object detection and natural language processing, along with developing novel applications in energy-efficient hardware, represents a significant challenge and opportunity for future work. Benchmarking efforts on standardized datasets using established metrics would facilitate better comparisons and progress tracking in the field.
More visual insights#
More on tables
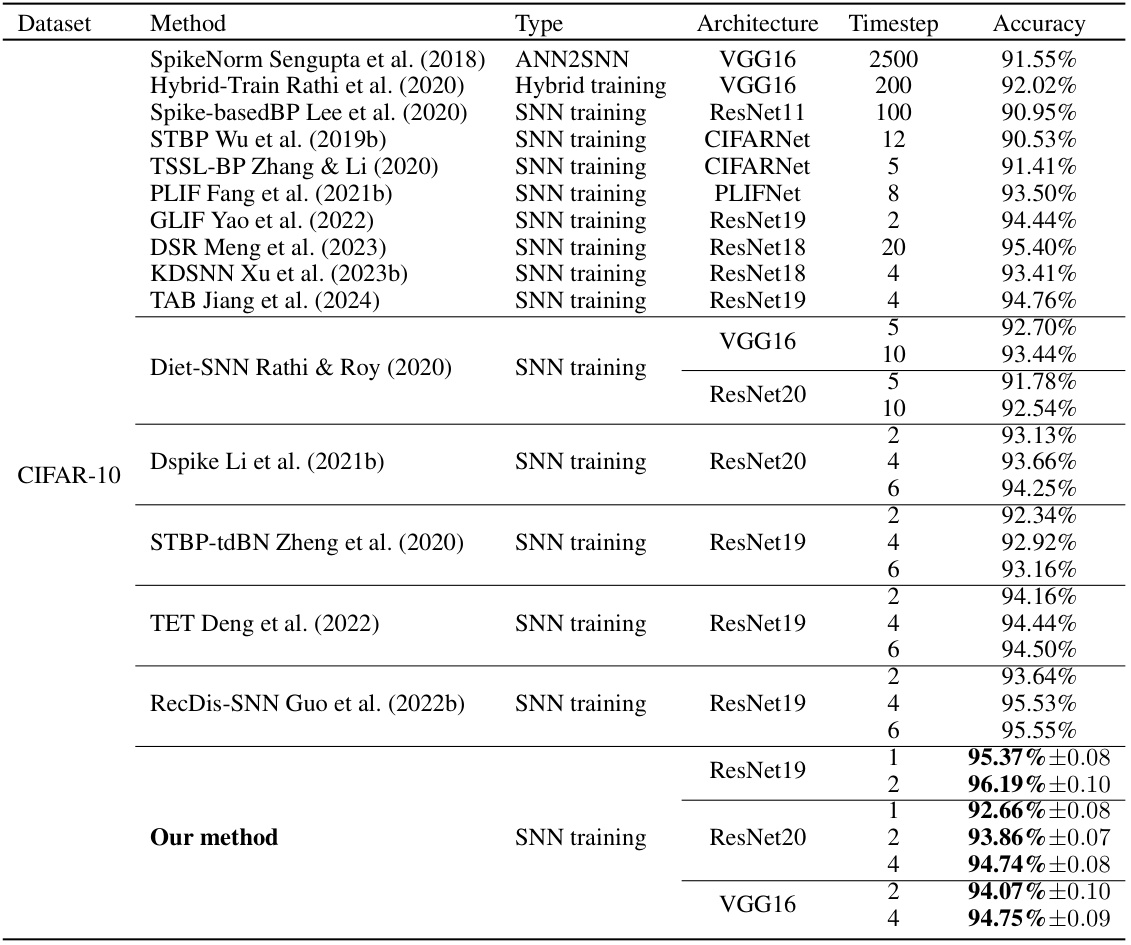
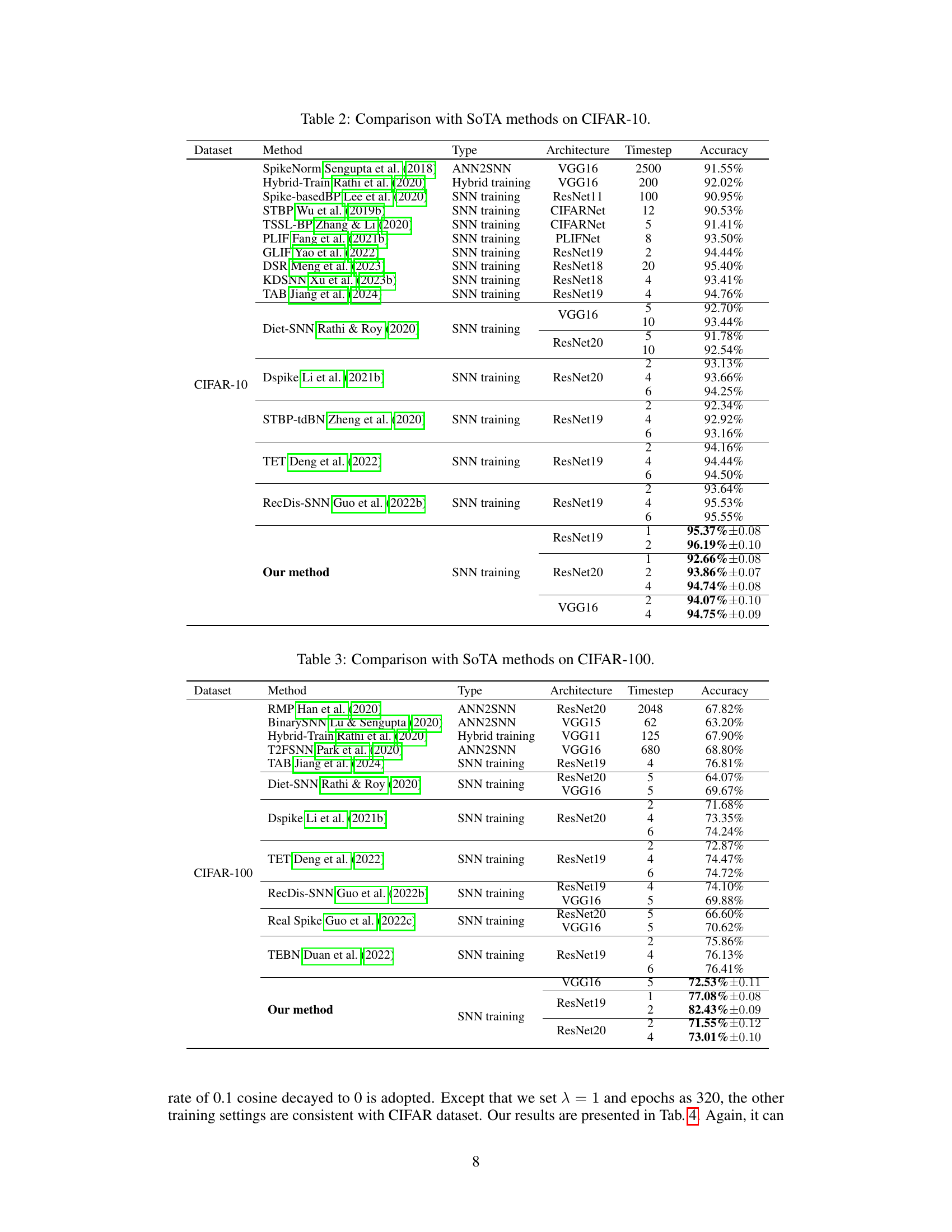
This table compares the performance of the proposed method with other state-of-the-art (SOTA) methods on the CIFAR-10 dataset. It shows the architecture, number of timesteps, and accuracy achieved by each method. The table highlights that the proposed method outperforms other SOTA methods, achieving higher accuracy with fewer timesteps.
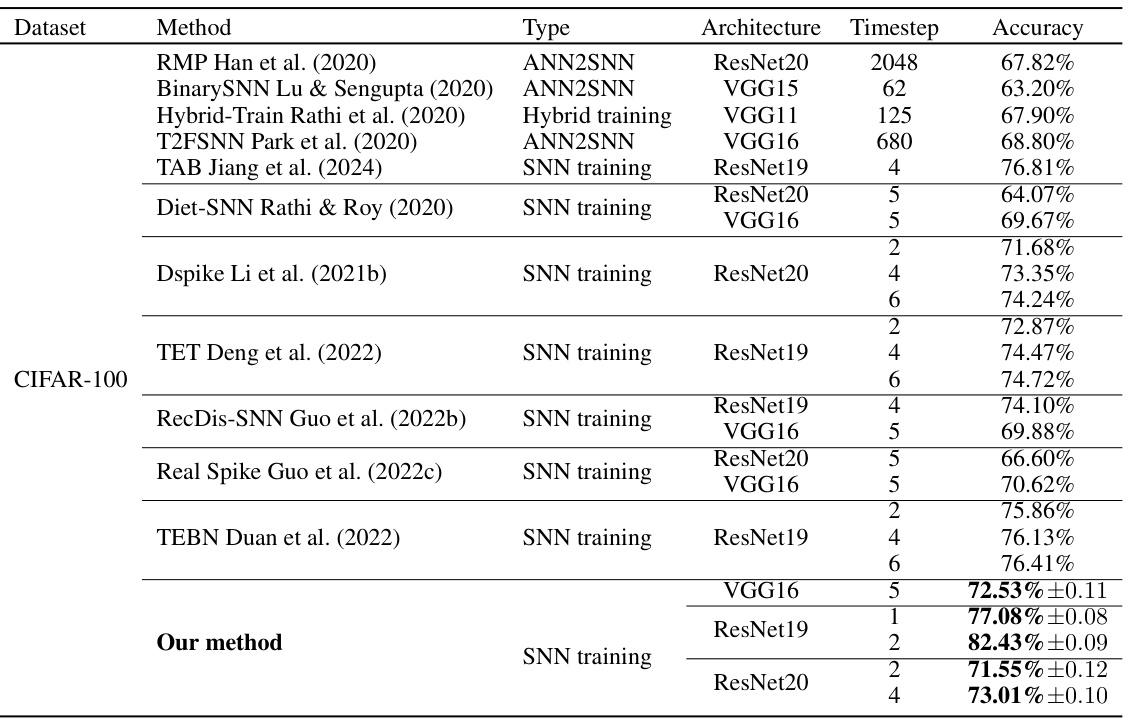
This table compares the performance of the proposed method with other state-of-the-art (SoTA) methods on the CIFAR-100 dataset. It shows the method, type (ANN2SNN or SNN training), architecture, number of timesteps, and accuracy achieved. The table highlights the superior performance of the proposed method, particularly in terms of achieving high accuracy with fewer timesteps.
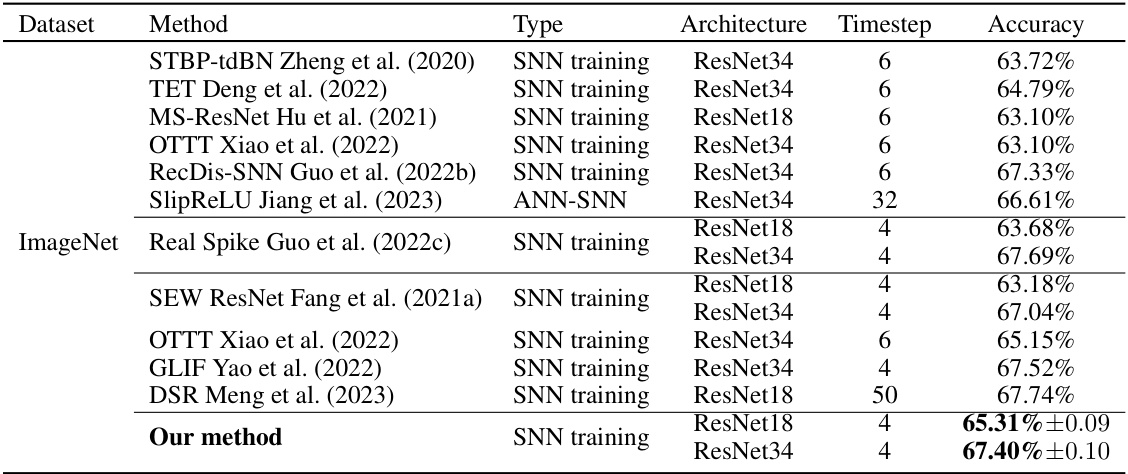
This table compares the proposed method’s performance on CIFAR-10 against other state-of-the-art (SoTA) methods. It lists each method, its type (ANN2SNN, hybrid training, or SNN training), the architecture used, the number of timesteps, and the achieved accuracy. The table provides a quantitative comparison to showcase the effectiveness of the proposed approach.
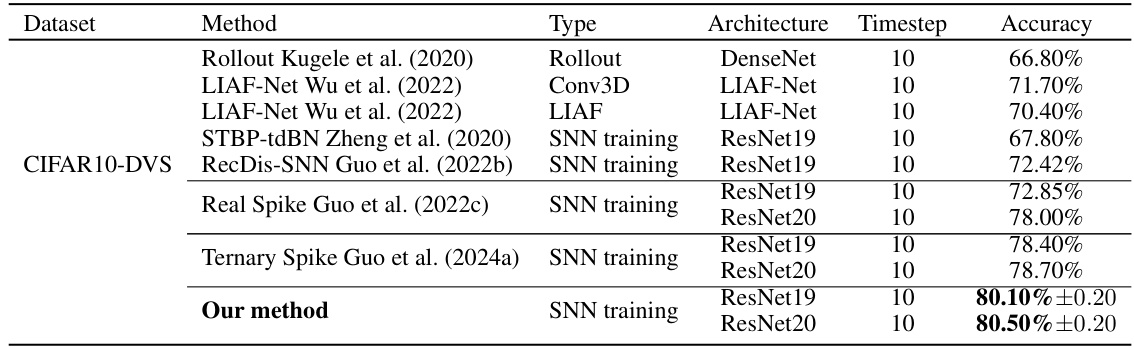
This table compares the performance of the proposed method with other state-of-the-art (SOTA) methods on the CIFAR10-DVS dataset. The table shows the method, type (SNN training, Rollout, etc.), architecture, number of timesteps, and accuracy achieved by each method. It highlights that the proposed method achieves the highest accuracy on this neuromorphic dataset.
Full paper#