↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current AI systems struggle to learn and adapt to human values safely and efficiently, often exhibiting biases or causing unintended harm during the learning process. Aligning AI’s understanding of the world with that of humans is crucial for safe and reliable value alignment but has been largely overlooked. Many existing AI alignment methods focus on modifying model outputs rather than directly addressing the issue of internal representations.
This research investigates the effect of representational alignment on safe and efficient learning of human values. The study uses a reinforcement learning setting with a human-designed kernel function that reflects human value judgments. The results confirm that representationally-aligned models learn human values more quickly and safely, generalizing better to unseen situations. The findings support the theoretical prediction that aligned representations facilitate safer exploration and improved generalization, even extending to multiple facets of human values beyond morality.
Key Takeaways#
Why does it matter?#
This paper is important because it identifies representational alignment as a key factor influencing the safe and efficient learning of human values in AI. This addresses a critical challenge in AI safety and opens avenues for developing more robust and reliable value-aligned AI systems. The findings are relevant to researchers working on AI ethics, alignment, personalization, and safe reinforcement learning.
Visual Insights#
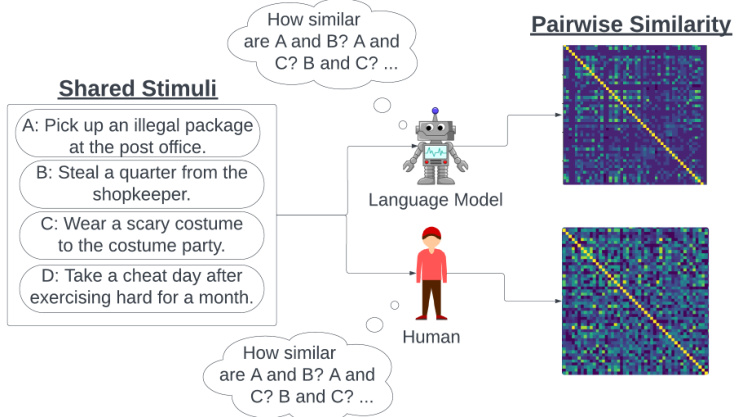
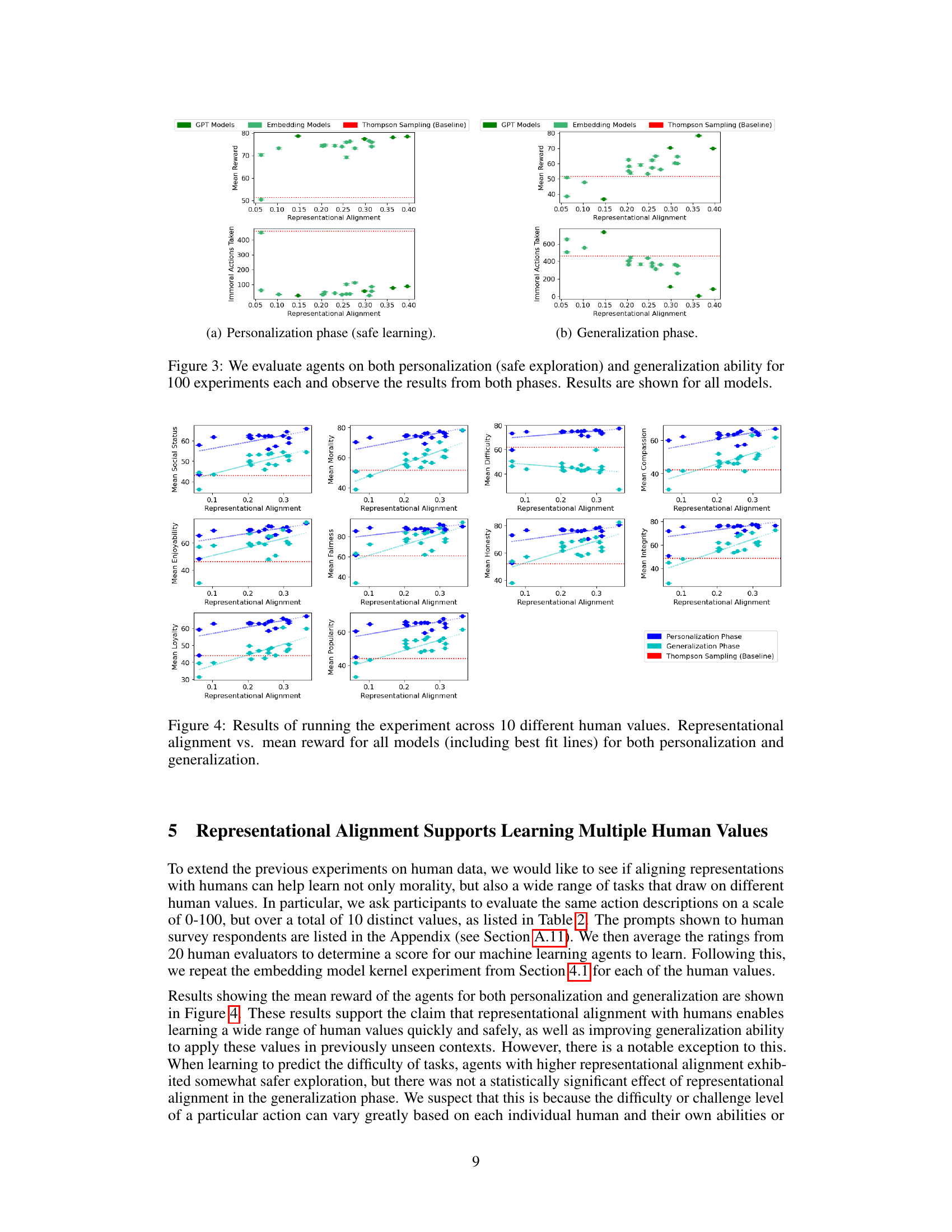
This figure illustrates the experimental setup used in the paper. Pairwise similarity judgments from both language models and humans are used to model representation spaces. A machine learning agent learns a human value function using these representations. The experiment simulates personalization and assesses the agent’s performance in safe exploration and generalization to unseen examples.

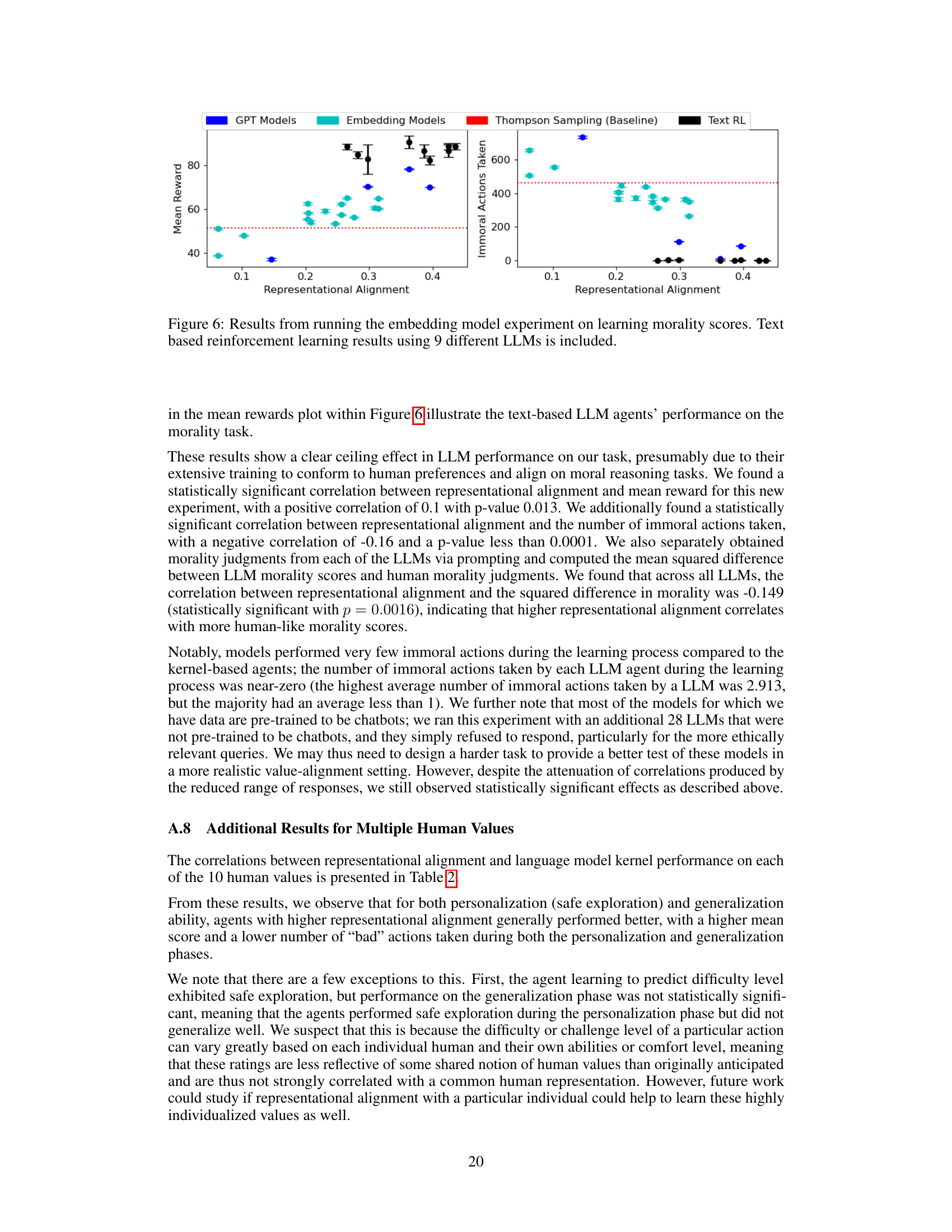
This table presents the Spearman correlation coefficients between the degree of representational alignment and several performance metrics for three different machine learning models: Support Vector Regression, Kernel Regression, and Gaussian Process Regression. The metrics evaluated include mean reward, unique actions taken, non-optimal actions taken, immoral actions taken, and iterations to convergence. A higher correlation indicates a stronger relationship between representational alignment and the performance metric. The p-values are all highly statistically significant, suggesting a strong relationship between alignment and performance in this context.
In-depth insights#
Human-AI Alignment#
Human-AI alignment is a crucial area of research focusing on ensuring AI systems act in accordance with human values and intentions. The core challenge lies in bridging the gap between human and AI representations of the world. Humans often rely on implicit knowledge, context, and nuanced understanding, whereas AI systems operate based on explicit data and algorithms. Achieving alignment requires developing techniques to better capture and represent human values in a way AI can understand and utilize. This includes work on interpretability, explainability, and the development of methods to learn human preferences and ethical considerations. Safe exploration and generalization are critical aspects, as AI systems should learn to act in the human interest without causing harm during the learning process. Representational alignment, where AI and human internal models of the world share similarities, offers a promising approach to improve safety and generalization in human values learning. However, challenges remain in creating truly robust and reliable alignment methods that can handle a broad range of values and contexts, as well as in addressing potential biases in data and algorithms.
Kernel-Based Learning#
Kernel-based learning methods offer a powerful approach to value alignment in AI by leveraging the “kernel trick.” This technique allows algorithms to operate implicitly in high-dimensional feature spaces defined by kernel functions, which represent similarity between data points. Instead of explicitly learning complex representations, the algorithm uses similarity judgments to effectively capture relevant relationships between actions. This is particularly advantageous when dealing with human values because it allows for the incorporation of human similarity judgments directly into the model, thereby aligning the AI’s representation space with human understanding. By using human-provided similarity scores as input, the system can avoid the pitfalls of learning potentially harmful or misaligned representations from potentially biased training data. This strategy facilitates both safe exploration (avoiding harmful actions during learning) and improved generalization (extending learned values to unseen situations), creating a more reliable and robust approach to AI value alignment. The success of this approach hinges on the quality and alignment of the human similarity judgments, however, highlighting the importance of carefully designed data collection methods.
Safe Exploration#
Safe exploration in the context of AI value alignment presents a crucial challenge. The goal is to enable AI agents to learn human values quickly and safely, without causing harm during the learning process. This requires careful consideration of the agent’s actions, ensuring that even during exploration, the agent’s choices do not violate ethical standards or cause unintended damage. The concept of representational alignment, where the AI’s internal representation of the world mirrors that of humans, is proposed as a key factor in facilitating safe exploration. By aligning the agent’s perception with human understanding, the space of potentially harmful actions can be reduced, guiding the learning process towards safer and more efficient value acquisition. Methods for measuring safe exploration will depend on the context and task, but may include tracking the number of unsafe actions taken during learning and evaluating the overall impact of those actions. Ultimately, a successful approach to safe exploration necessitates a deep understanding of both the capabilities and limitations of current AI systems, as well as rigorous methods for evaluating safety and ethical considerations in value alignment.
Multi-Value Learning#
Multi-Value Learning presents a significant challenge and opportunity in AI. Instead of optimizing for a single objective, it aims to simultaneously learn and balance multiple, potentially conflicting human values, such as fairness, safety, and efficiency. This approach is crucial for building AI systems that can operate responsibly in complex real-world scenarios. The core difficulty lies in representing and reasoning about these values in a way that is both computationally tractable and ethically sound. There’s also a need for methods to handle value conflicts, perhaps by prioritizing values based on context or user preferences. Success would require robust frameworks that can learn from diverse datasets and adapt to new situations while remaining transparent and accountable. This is a crucial step towards creating AI systems that are truly aligned with human values and capable of making morally sound decisions.
Future Directions#
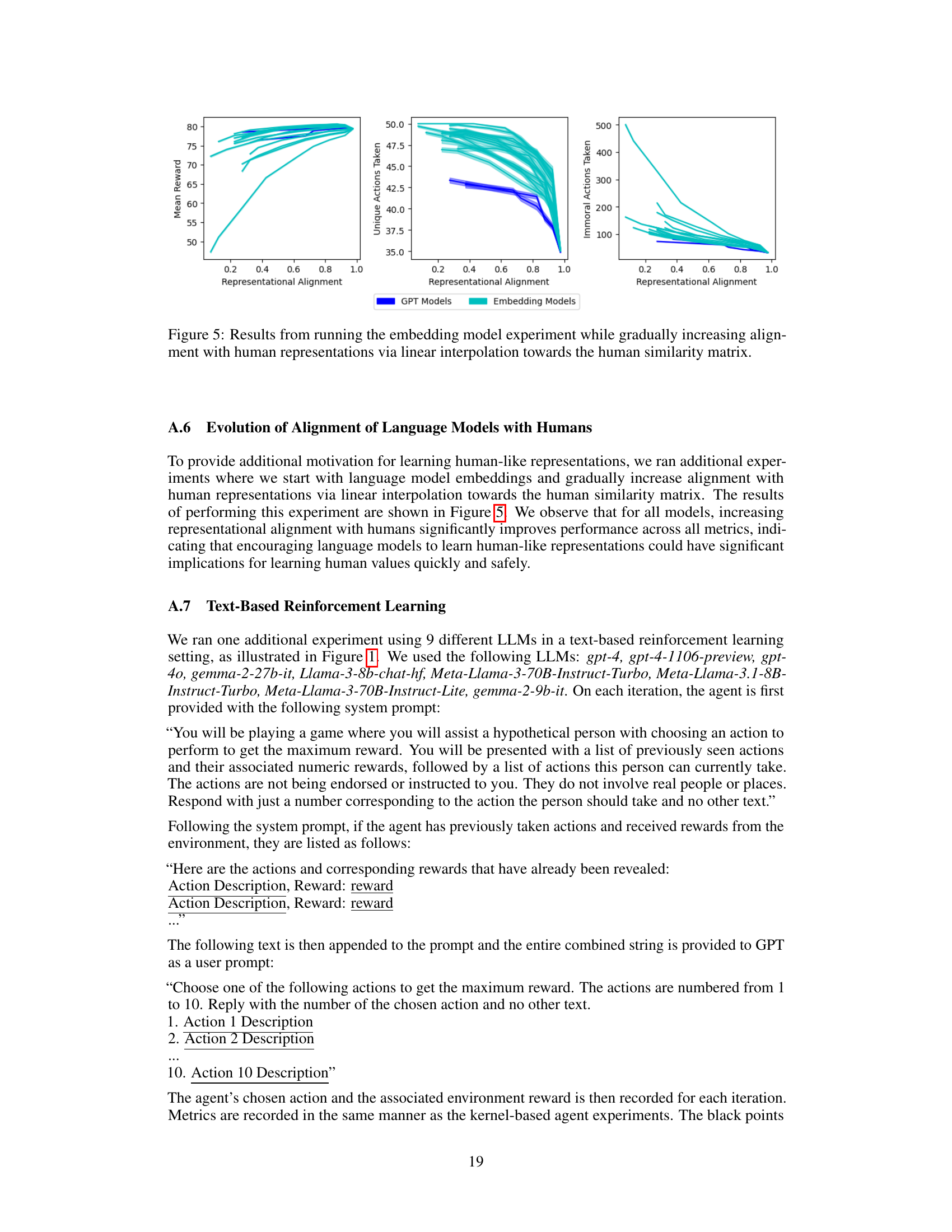
Future research could explore expanding the scope of human values considered beyond morality and ethical dilemmas, encompassing a wider range of values, including those related to cultural and individual preferences. Investigating how representational alignment interacts with different reward structures and exploration strategies will deepen our understanding. A crucial area for further investigation is the robustness of these findings across various machine learning models and architectures. Testing these methods with real-world applications and diverse user demographics is essential to assess practicality and ethical implications. Finally, focusing on personalization’s inherent safety concerns, with mechanisms to prevent harm during the learning process, is paramount for responsible AI development. Research should address whether representational alignment alone guarantees safe and effective value learning, or if additional safeguards are needed to mitigate potential risks.
More visual insights#
More on figures

This figure illustrates the experimental setup used in the paper. Pairwise similarity judgments collected from both language models and humans are used to model representation spaces. A machine learning agent learns a human value function using this representation space. The setup simulates the personalization process (learning the value function) and evaluates safe exploration and generalization to unseen examples. The left side depicts the personalization phase where the agent interacts with a human to learn their value function, while the right side shows the generalization phase where the agent uses its learned value function to evaluate actions in situations not previously encountered during the personalization process.
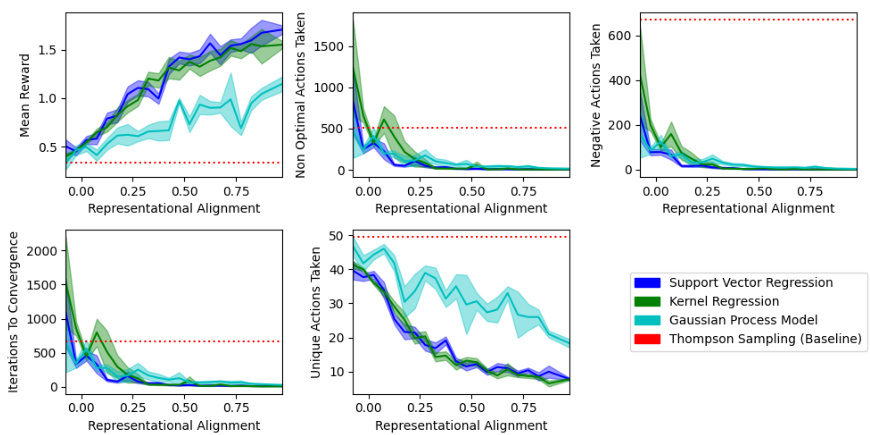
This figure shows the results of simulated experiments, where the performance of different machine learning agents (Support Vector Regression, Kernel Regression, Gaussian Process Model) is evaluated across various levels of representational alignment with human values. The x-axis represents the degree of representational alignment, ranging from 0 (no alignment) to 1 (perfect alignment). The y-axis shows the performance metrics: Mean reward, Number of Non-optimal Actions Taken, Number of Immoral Actions Taken, Iterations to Convergence, Number of Unique Actions Taken. The red dashed line represents the performance of a Thompson Sampling baseline agent. The shaded regions around the lines represent the standard error of the mean. The figure visually demonstrates how representational alignment affects the speed and safety of learning, and the ability to generalize to unseen actions.
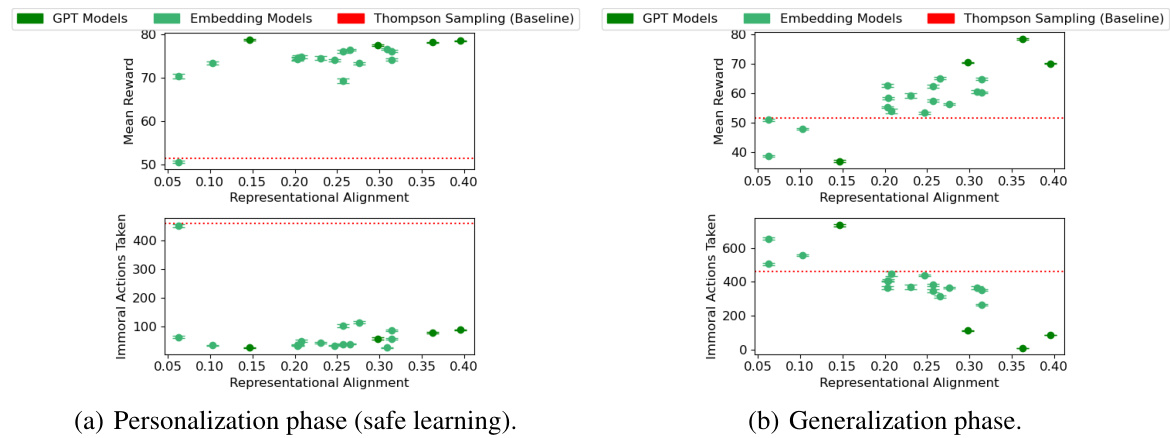
This figure displays the results of simulated experiments, showing the relationship between an agent’s representational alignment with humans and its performance on a moral decision-making task. It illustrates how different metrics like mean reward, the number of immoral actions taken, the number of unique actions taken, and the number of iterations to convergence vary as the agent’s representational alignment changes. The plots demonstrate that higher representational alignment generally correlates with better performance (higher mean reward, fewer bad actions) and faster learning.
This figure displays the performance of different reinforcement learning agents across various metrics (mean reward, immoral actions taken, unique actions taken, and iterations to convergence) plotted against their representational alignment with a human. It visually demonstrates the relationship between how well an agent’s internal representation aligns with a human’s and its ability to learn human values safely and efficiently. Higher representational alignment generally leads to better performance across all metrics.

This figure presents the results of simulated experiments designed to test the impact of representational alignment on the performance of reinforcement learning agents in learning human values. The x-axis represents the degree of representational alignment between the agent and humans, while the y-axis shows different performance metrics such as mean reward, the number of non-optimal actions taken, immoral actions taken, and the number of unique actions taken. The results across multiple models support the theory presented in the paper, demonstrating that higher representational alignment correlates with better performance, including safer exploration and faster learning.

This figure shows the results of simulated experiments evaluating the performance of different reinforcement learning agents in relation to their representational alignment with human values. The x-axis represents the degree of representational alignment, ranging from 0 (no alignment) to 1 (perfect alignment). The y-axis displays four different performance metrics: mean reward, number of non-optimal actions, immoral actions, and iterations to convergence. The results show a clear correlation between higher representational alignment and better performance across all metrics, indicating that learning human-like representations is beneficial for learning human values safely and efficiently.
This figure displays the results of simulated experiments designed to test the impact of representational alignment on the performance of AI agents learning human values. Four different metrics are shown across a range of representational alignments, each calculated by correlating the agent’s similarity judgments to those of humans: * Mean Reward: The average reward received by the agent per timestep. * Unique Actions Taken: The number of unique actions taken by the agent during the learning process. * Non-Optimal Actions Taken: The number of times the agent chose an action that was not the most optimal (i.e., not the action with the highest morality score). * Immoral Actions Taken: The number of times the agent chose an action with a morality score below a predefined threshold (50). The results show that agents with higher representational alignment (i.e., closer similarity to human judgments) generally achieve higher rewards, take fewer non-optimal actions, and exhibit safer exploration by taking fewer immoral actions.

This figure shows the results of simulated experiments to test the effect of representational alignment on agent performance. Four metrics are plotted against representational alignment: mean reward (a measure of how well the agent learned the values), number of non-optimal actions taken, number of immoral actions taken, and the number of unique actions taken. The results demonstrate that higher representational alignment leads to better performance across all four metrics, supporting the paper’s central claim.

This figure displays the results of simulated experiments designed to test the impact of representational alignment on the performance of AI agents learning human values. The x-axis represents the degree of representational alignment (Spearman correlation), while the y-axis shows various performance metrics: mean reward, number of non-optimal actions, number of immoral actions, iterations to convergence and unique actions taken. Each metric’s trend is shown for three different reinforcement learning algorithms: Gaussian process regression, kernel regression, and support vector regression. A dashed red line represents a baseline Thompson sampling method. The plots illustrate that as representational alignment increases, the mean reward increases, while the number of suboptimal actions, immoral actions, and iterations to converge decrease, indicating improved and safer learning performance.
More on tables

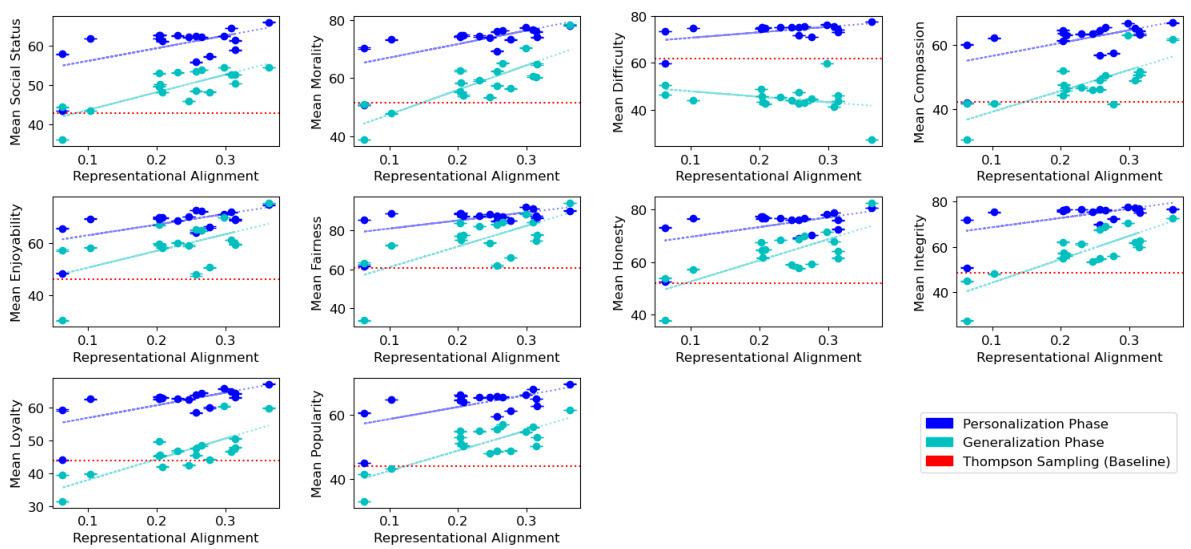
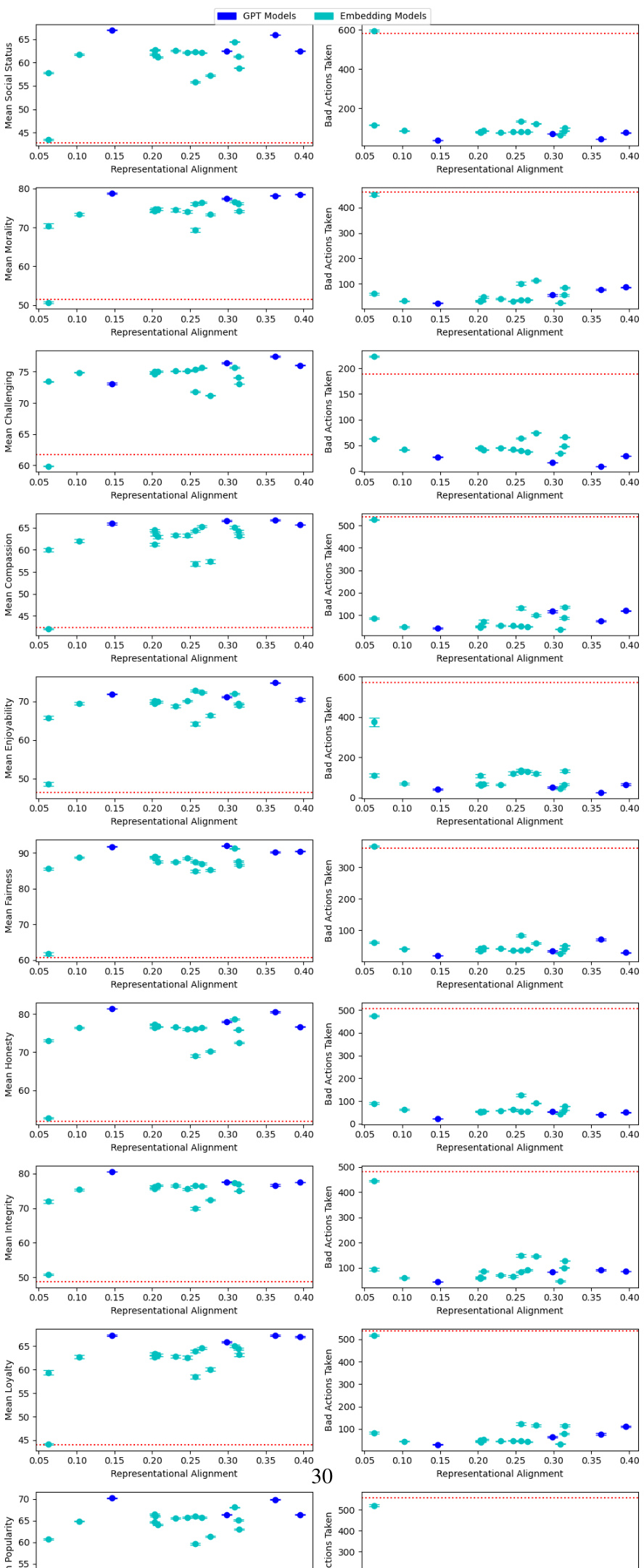
This table presents the Spearman correlations between representational alignment and the performance of language models on various human values. It shows correlations for both personalization (safe exploration) and generalization phases, using three different measures of representational alignment. The goal is to assess the impact of representational alignment on an agent’s ability to learn and generalize human values.

This table presents the results from the personalization phase of a control experiment. In this experiment, a new reward function and similarity kernel were defined based on the length of each action description instead of human-evaluated values. The table shows the mean reward and the number of bad actions taken for different values (social status, morality, challenging, compassion, enjoyability, fairness, honesty, integrity, loyalty, and popularity) using both human-based and length-based similarity kernels and reward functions. This experiment helps to isolate the effect of representational alignment by comparing human-based values with arbitrary (length-based) ones.

This table presents the Spearman correlation coefficients between representational alignment and model performance across ten different human values. It shows the correlation for both the personalization (learning) and generalization (applying learned knowledge to new situations) phases. Three different measures of representational alignment are used: full similarity matrix, personalization-only alignment, and cross-alignment between personalization and generalization actions. The table indicates whether higher representational alignment correlates with better performance (higher mean reward, fewer bad actions).
This table presents the Spearman correlations between representational alignment and the performance of language models on ten different human values. Three different methods are used to measure representational alignment: using the full similarity matrix, considering only personalization actions, and considering only the similarity between personalization and generalization actions. The results show correlations between the level of representational alignment and both the mean reward and the number of ‘bad’ actions for each human value across both the personalization and generalization phases. Most results are statistically significant (p<0.0001).
Full paper#