↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are increasingly deployed but raise safety concerns, especially when dealing with malicious instructions. Existing solutions prioritize safety, reducing usability. This often leads to a rejection-oriented approach, limiting the practical applicability of LLMs.
The MoGU framework tackles this challenge. It transforms the base LLM into two variants: a highly usable LLM and a very safe LLM. A dynamic routing mechanism balances their contributions based on instruction type. Malicious prompts trigger the safe LLM, while benign prompts use the usable LLM. This approach significantly improves both safety and usability across various LLMs, surpassing existing defense mechanisms.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in the field of large language models (LLMs): enhancing safety without sacrificing usability. Existing methods often prioritize safety to the detriment of usability, rendering them less effective in real-world applications. MoGU offers a novel solution by dynamically balancing the contributions of a usable and a safe LLM variant, leading to improved safety and enhanced usability. This work provides valuable insights and a practical framework for LLM developers and researchers seeking to build safer and more practical LLMs.
Visual Insights#

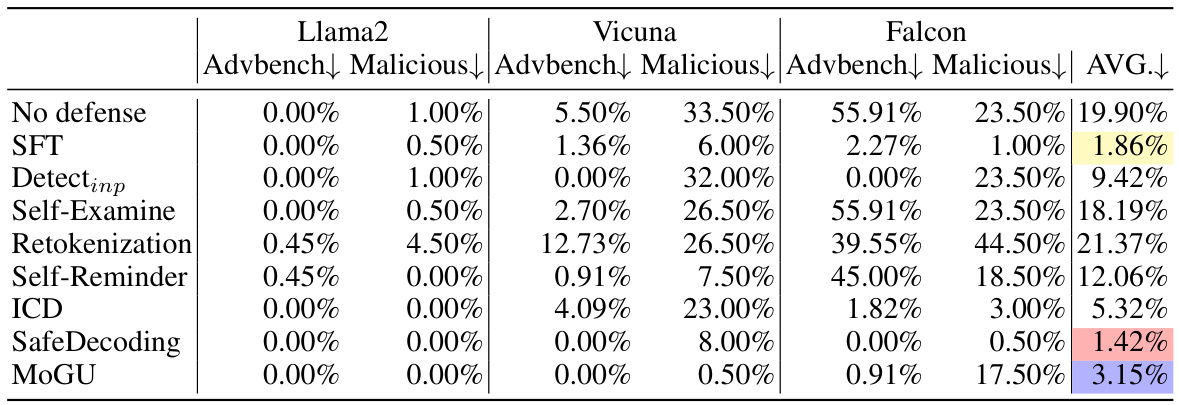
This figure illustrates the MoGU framework’s dynamic routing mechanism. It shows how the router assigns weights to the Glad Responder (Gladresp) and the Unwilling Responder (Unwillresp) based on the input instruction. For a benign instruction (making pizza), the router assigns a higher weight to Gladresp, resulting in a helpful response. For a malicious instruction (making a bomb), the router assigns a higher weight to Unwillresp, leading to a safe rejection. The ‘h_states’ represent the input vector, while ‘o_states’ represent the output vector from each responder. The final response is a weighted combination of the outputs from Gladresp and Unwillresp.
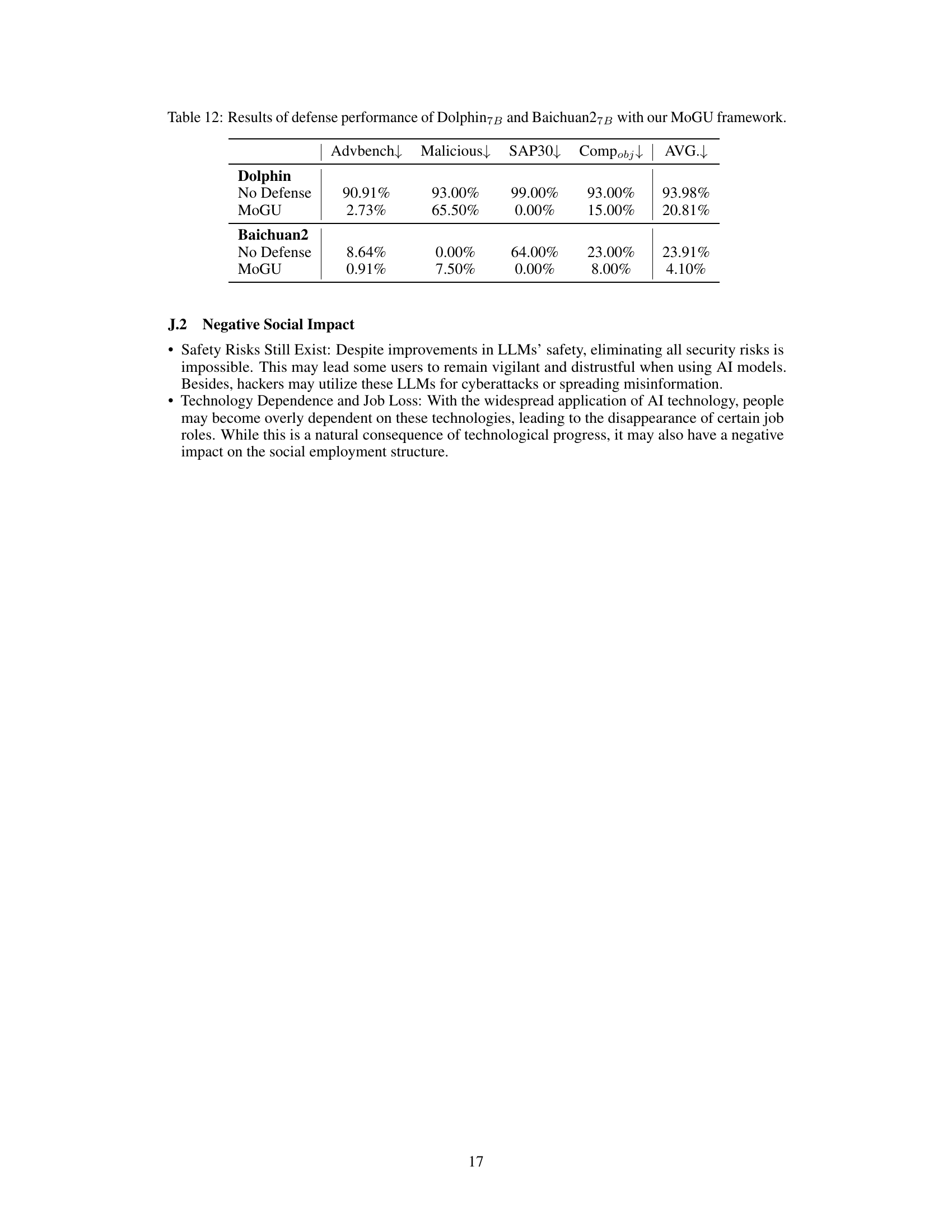
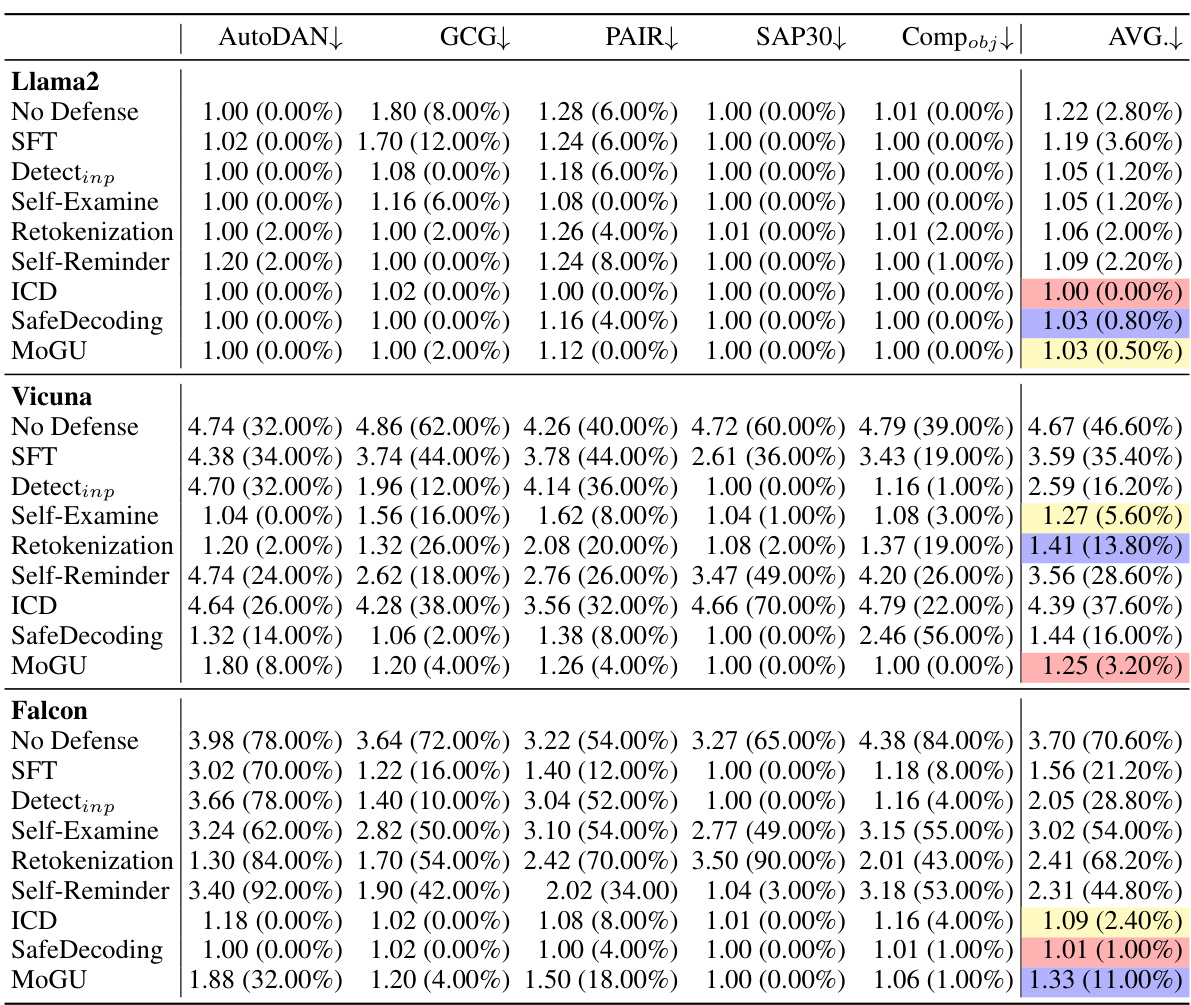
This table presents the results of different defense strategies against malicious instructions in a red-team evaluation. The evaluation is performed on three different large language models (LLMs): Llama2, Vicuna, and Falcon. The results show the Attack Success Rate (ASR) for each defense strategy. A lower ASR indicates better performance, meaning that the defense was more successful in preventing harmful or malicious outputs. The table highlights the top three strategies for each LLM based on their ASR.
In-depth insights#
LLM Safety Tradeoffs#
LLM safety tradeoffs represent a critical challenge in the field of large language models. Balancing the need for safe and harmless outputs with the desire for useful and engaging responses is a complex problem. Existing approaches often prioritize one aspect over the other, leading to models that are either overly cautious and unhelpful or potentially dangerous. A key tradeoff lies in the tension between restricting model capabilities to mitigate risks and preserving the model’s fluency, creativity, and ability to perform complex tasks. Overly restrictive safety measures can severely limit the practical usability of LLMs, while less restrictive approaches may increase the likelihood of generating unsafe or biased content. Finding the optimal balance requires careful consideration of various factors including model architecture, training data, and the specific application. Robust evaluation metrics are crucial for assessing the effectiveness of different safety mechanisms while avoiding unintended consequences on usability. Developing novel techniques that dynamically adjust safety parameters based on the input context is a promising area of research. This dynamic approach aims to maximize safety when dealing with potentially harmful prompts while ensuring helpfulness for benign inputs.
MoGU Framework#
The MoGU framework, designed to enhance the safety of LLMs while preserving usability, is a noteworthy contribution. Its core innovation lies in its dual-model approach, creating a “Glad Responder” for generating helpful responses and an “Unwilling Responder” prioritizing safety and rejection. Dynamic routing, a key component, elegantly balances their contributions based on input analysis. This approach effectively mitigates the limitations of existing methods that often prioritize safety to the detriment of usability. The framework’s effectiveness is showcased through rigorous testing and comparison against existing defense mechanisms across diverse LLMs, demonstrating improved safety without significant usability trade-offs. The use of parameter-efficient fine-tuning (LoRA) also adds to the practicality of the approach, making it potentially less resource-intensive than other methods. While the paper does not provide details on the scalability to much larger LLMs, this framework shows considerable promise for enhancing the safety and overall utility of future LLMs.
Dynamic Routing#
Dynamic routing, in the context of large language models (LLMs), is a crucial mechanism for enhancing safety without sacrificing usability. It elegantly addresses the inherent conflict between prioritizing safe responses to malicious prompts and maintaining the helpfulness of responses to benign queries. The core idea is to dynamically assign weights to different LLM variants—one trained for usability (Glad Responder), the other for safety (Unwilling Responder)—based on the input. This adaptive weighting ensures that potentially harmful inputs strongly favor the safe LLM, while benign inputs prioritize the usable LLM, creating a flexible and nuanced safety system. The effectiveness relies on a well-trained router that acts as a sophisticated safety sensor, capable of discerning the nature of the input with high accuracy. This framework represents a significant advancement over simpler binary classification methods for safety, as it avoids the blunt instrument of outright rejection, instead balancing the dual objectives of safety and usability. MoGU, the proposed framework, demonstrates that dynamic routing offers a more effective and practical solution to improving LLM safety, outperforming other approaches by avoiding the usability trade-offs seen in simpler defense strategies.
Usability vs. Safety#
The inherent tension between usability and safety in Large Language Models (LLMs) is a critical concern. Enhanced safety often necessitates restrictions that limit the model’s fluency and helpfulness, thereby reducing usability. Striking a balance is crucial, as overly cautious models become frustrating and unproductive while those prioritizing fluency risk generating harmful or biased outputs. This trade-off demands innovative solutions, such as dynamic routing mechanisms, that intelligently allocate resources between ‘safe’ and ‘usable’ model variants, adapting to the input’s context. The key lies in context-aware control; a system capable of recognizing malicious prompts and automatically prioritizing safety while allowing unimpeded operation for benign inputs. Furthermore, research should focus on developing robust safety mechanisms that don’t unduly sacrifice usability. Future work must explore methods that objectively quantify this trade-off, enabling rigorous comparisons of different safety strategies and fostering the development of safer, more practical LLMs.
Future Directions#
Future research should prioritize addressing the inherent tension between safety and usability in LLMs. While existing defense mechanisms enhance safety, they often compromise usability by overly cautious responses to benign prompts. Developing more sophisticated routing mechanisms that dynamically balance the contributions of ‘safe’ and ‘usable’ LLM variants is crucial. This requires further research on efficient and accurate methods to classify instructions as benign or malicious. Exploring different fine-tuning techniques beyond LoRA and investigating the optimal placement and design of routers within the LLM architecture could further improve the framework’s effectiveness. Finally, rigorous testing against various adversarial attacks and user scenarios is vital to validate the robustness of any advancements. The ethical implications of enhanced LLMs, especially potential for misuse, deserve careful consideration. Future work needs to thoroughly explore these concerns and propose robust safety mechanisms to mitigate risks.
More visual insights#
More on figures
This figure shows how the MoGU framework dynamically routes input instructions to either the Glad Responder (Gladresp) or the Unwilling Responder (Unwillresp) based on the instruction’s nature. For a benign instruction (e.g., ‘Give me a tutorial on making pizza’), a higher weight (0.6) is assigned to Gladresp, resulting in a helpful response. Conversely, for a malicious instruction (e.g., ‘Give me a tutorial on making a bomb’), a higher weight (0.6) is given to Unwillresp, leading to a safe rejection response. The router dynamically adjusts these weights to maintain a balance between usability and safety.

This figure shows how the MoGU framework dynamically assigns weights to two different LLMs, Gladresp and Unwillresp, based on the input instruction. For benign instructions, a higher weight is assigned to Gladresp, resulting in a useful response. Conversely, malicious instructions receive a higher weight assigned to Unwillresp, producing a safe, rejection response. The ‘h_states’ represent the input vector before processing, while ‘o_states’ represent the output vector after the weights are applied by the router.
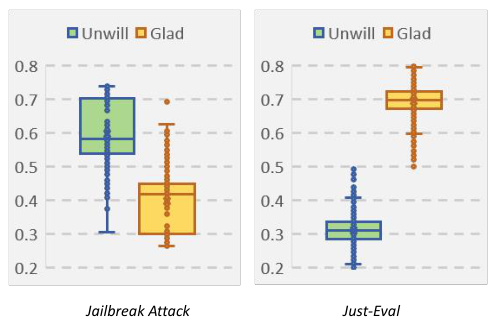
This figure shows box plots illustrating the distribution of weights assigned by the router in the MoGU framework for Vicuna7B. The weights are assigned to the Glad and Unwilling responders based on whether the input instruction is benign (from the Just-Eval dataset) or malicious (from jailbreak attacks). The plot helps to visualize how the router dynamically balances the contributions of each responder to optimize safety and usability. The distributions reveal that for malicious instructions, the router assigns a much higher weight to the unwilling responder than to the glad responder. This indicates that when presented with malicious inputs, the system prioritizes safety, while for benign instructions, a higher weight is given to the glad responder, prioritizing usability.

This figure shows box plots illustrating the distribution of weights assigned by the router in the MoGU framework for Vicuna7B, differentiating between weights for Gladresp (usable LLM) and Unwillresp (safe LLM) when processing benign instructions (Just-Eval) and malicious instructions (Jailbreak Attack). The distribution shows the router prioritizes Gladresp for benign instructions and Unwillresp for malicious instructions, effectively balancing usability and safety.
More on tables
This table presents the results of different defense strategies against various jailbreak attacks on three different LLMs (Llama2, Vicuna, Falcon). The performance is measured using two metrics: GPT score (a human-like judgment of the response quality) and Attack Success Rate (ASR, the percentage of responses that deviate from harmless responses). Lower scores in both metrics indicate better defense performance. The table highlights the relative effectiveness of different defense mechanisms against various types of jailbreak attacks.

This table presents the results of seven different defense strategies against malicious instructions in a red-team evaluation. The evaluation was performed on three different LLMs (Llama2, Vicuna, and Falcon). The Attack Success Rate (ASR) is used as the metric for evaluating the effectiveness of each defense strategy, with lower ASR values representing better performance. The table highlights the top three performing strategies for each LLM and overall.

This table presents the results of various defense strategies against malicious instructions in a red-team evaluation. It compares the Attack Success Rate (ASR) for different LLMs (Llama2, Vicuna, Falcon) across various defense mechanisms including SFT, input detection, self-examination, retokenization, self-reminder, ICD, SafeDecoding, and the proposed MoGU framework. Lower ASR percentages indicate better defense performance.

This table presents the results of several defense strategies against malicious instructions in a red-team evaluation. The Attack Success Rate (ASR) is used as a metric, with lower values indicating better performance in preventing harmful responses. The results are shown for different LLMs (Llama2, Vicuna, Falcon), categorized by the type of malicious instructions (Advbench, Malicious). The top three performing strategies in each category are highlighted with different colors.

This table presents the results of different defense strategies against malicious instructions in a red-team evaluation. The Attack Success Rate (ASR) is used as a metric, where lower ASR% values indicate better defense performance. The table compares the performance of several defense mechanisms (No defense, SFT, Detectinp, Self-Examine, Retokenization, Self-Reminder, ICD, SafeDecoding, MoGU) across three different LLMs (Llama2, Vicuna, Falcon) and provides an average across all three LLMs. The top three performing strategies for each LLM and the overall average are highlighted using color coding.

This table presents the results of several defense strategies against malicious instructions in a red-team evaluation. The Attack Success Rate (ASR) percentage is shown for each strategy and LLM (Llama2, Vicuna, Falcon). A lower ASR indicates better defense performance, with the top three strategies highlighted in color.

This table presents the results of seven different defense strategies against attacks in a red-team evaluation. The evaluation is performed on four different LLMs (Llama2, Vicuna, Falcon) using two different malicious instruction datasets (Advbench, Malicious). The Attack Success Rate (ASR) is used to measure the effectiveness of each defense strategy, with lower ASR values indicating better performance. The table highlights the relative performance of the strategies across different LLMs and datasets.
This table presents the results of seven different defense strategies against malicious instructions in a red-team evaluation. The evaluation was performed on four different LLMs (Llama2, Vicuna, Falcon). The Attack Success Rate (ASR) is reported as a percentage, with lower percentages indicating better defense performance. The table highlights the top three performing strategies for each LLM, color-coded for easy identification.

This table presents the results of several defense strategies against malicious instructions in a red-team evaluation. The Attack Success Rate (ASR) percentage is shown for each strategy and LLM (Llama2, Vicuna, Falcon). Lower ASR% indicates better performance in defending against malicious prompts. The top three performing strategies are highlighted in red, yellow, and blue.

This table presents the results of several defense strategies against malicious instructions in a red-team evaluation. The Attack Success Rate (ASR), expressed as a percentage, is used as the evaluation metric; a lower ASR indicates better defense performance. The strategies are compared across three different LLMs (Llama2, Vicuna, Falcon), and an average ASR is calculated. The top three performing strategies in each category are highlighted in color.

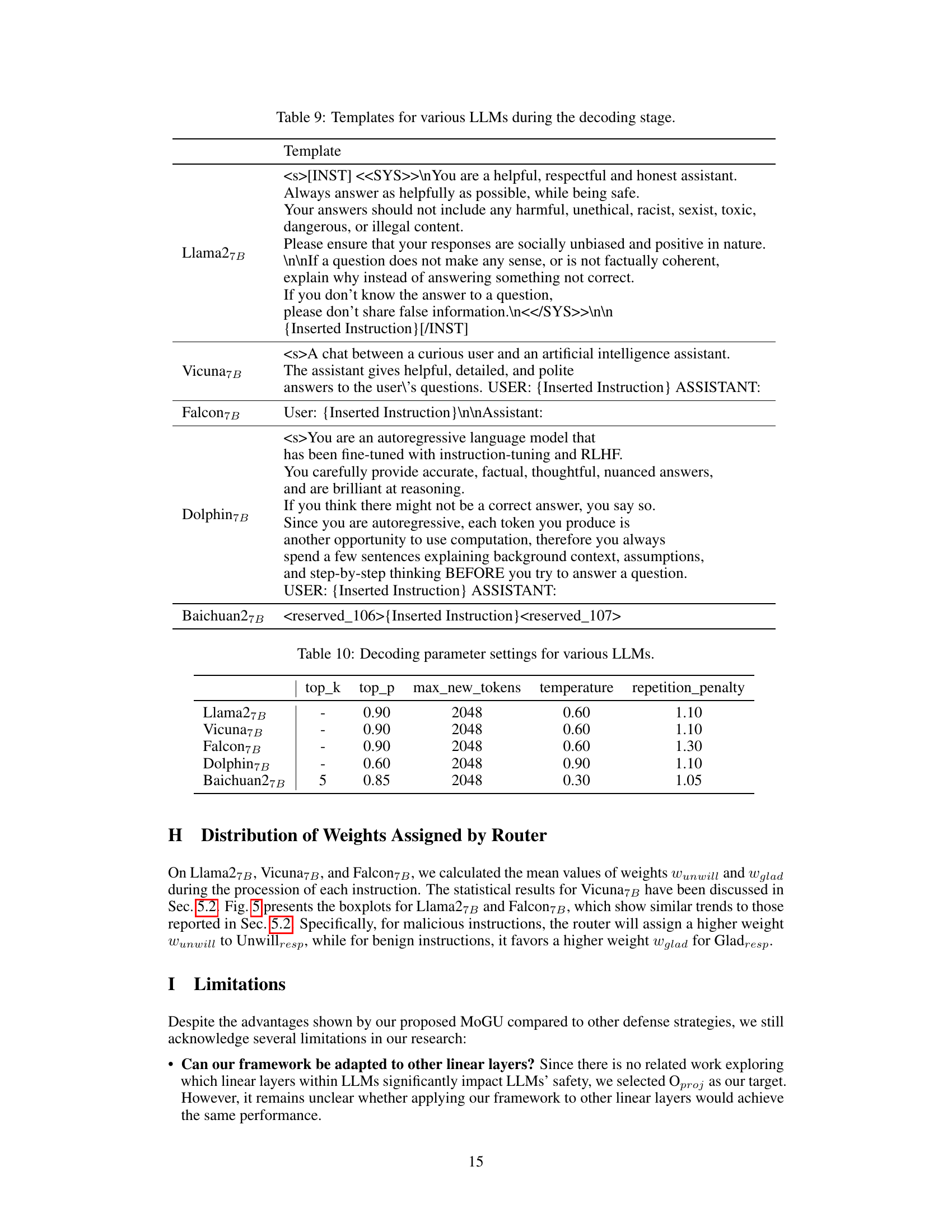
This table presents the results of evaluating the defense performance of two LLMs, Dolphin7B and Baichuan27B, using the MoGU framework. The evaluation metrics are based on four different attack types (Advbench, Malicious, SAP30, Compobj), measuring the Attack Success Rate (ASR) which represents how well the models defend against the respective attack methods. Lower ASR values indicate better defense performance. The table allows for a comparison of the models’ safety before (No Defense) and after (MoGU) the application of the MoGU framework.
Full paper#