↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current text-video retrieval methods struggle with the inherent differences between text and video data, often referred to as the “modality gap.” Existing diffusion models, while promising, are not well-suited to the ranking problem inherent in retrieval, nor do they effectively deal with noisy data. The L2 loss they typically use doesn’t prioritize relevant pairs.
To overcome these issues, the researchers propose a new method, Diffusion-Inspired Truncated Sampler (DITS). DITS cleverly uses a truncated diffusion process, starting from the text embedding and progressively moving towards the video embedding, effectively modeling the modality gap. Further, it employs a contrastive loss function to focus on differentiating between relevant and irrelevant pairs, improving the discriminative power of the embedding space. This approach leads to significant improvements in retrieval accuracy, achieving state-of-the-art results on multiple benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to text-video retrieval using diffusion models, addressing a key challenge in the field. By improving the alignment of text and video embeddings and enhancing the structure of the embedding space, it achieves state-of-the-art performance on benchmark datasets. This opens up new avenues for research in multi-modal learning and retrieval. The proposed DITS method shows significant improvement in the CLIP embedding space, enhancing the performance of text-video retrieval. This work also contributes to the development of diffusion models for retrieval tasks.
Visual Insights#

This figure illustrates different approaches to multi-modality gap alignment in text-video retrieval. (a) Defines the modality gap as the difference between video and text embeddings. (b) Shows a fixed prior approach using a Gaussian distribution, which lacks flexibility. (c) Depicts the limitations of using vanilla diffusion models with L2 loss for retrieval tasks, highlighting the impact of random sampling. (d) Introduces the proposed DITS method, which progressively aligns text and video embeddings using a truncated diffusion process and contrastive loss for improved control and discriminative power.

This table presents a comparison of various text-to-video retrieval methods on two benchmark datasets: MSRVTT and LSMDC. The metrics used for comparison include Recall at ranks 1, 5, and 10 (R@1, R@5, R@10), Median Rank (MdR), and Mean Rank (MnR). The table shows the performance of different methods using two different CLIP backbones (ViT-B/32 and ViT-B/16). Bold values indicate the best performing method for each metric and dataset/backbone combination. A ‘-’ indicates that the result is not available for a specific method.
In-depth insights#
Diffusion in Retrieval#
Diffusion models, known for generative capabilities, are explored for their potential in retrieval tasks. The core idea revolves around progressively aligning text and video embeddings in a shared space, effectively bridging the modality gap. However, standard diffusion approaches face limitations: the L2 loss isn’t optimal for ranking, and reliance on isotropic Gaussian distributions for initialization can hinder accuracy. Innovative solutions, such as truncated diffusion samplers, address these issues by leveraging inherent proximity in embedding spaces, enhancing control and aligning relevant pairs while separating irrelevant ones via contrastive loss. This shift towards targeted alignment rather than pure generation yields improved retrieval performance. The integration of diffusion processes thus transforms the retrieval challenge into a controlled alignment problem, leading to state-of-the-art results and demonstrating the effectiveness of diffusion models beyond their typical generative role.
DITS Sampler#
The Diffusion-Inspired Truncated Sampler (DITS) is a novel approach to text-video retrieval that addresses the limitations of existing diffusion models. DITS leverages the inherent proximity of text and video embeddings, unlike methods using isotropic Gaussian distributions, creating a truncated diffusion flow directly from the text embedding to the video embedding. This enhances controllability and precision in alignment. Furthermore, DITS employs contrastive loss, focusing on differentiating relevant from irrelevant pairs, which improves the discriminative power of the embeddings and better fits the ranking nature of the retrieval task. Unlike L2 loss used in traditional diffusion models, the contrastive loss prioritizes the alignment of semantically similar pairs. The progressive alignment process of DITS, guided by the contrastive loss, offers a more effective way to bridge the modality gap between text and video data than existing methods. Experimental results highlight the state-of-the-art performance of DITS on benchmark datasets, further underscoring its effectiveness in improving the structural organization of the CLIP embedding space.
Modality Gap#
The concept of “Modality Gap” in the context of text-video retrieval is crucial. It highlights the inherent differences between textual and visual data representations, creating a significant challenge for algorithms aiming to bridge the semantic gap between the two modalities. This gap arises because text and video employ fundamentally different ways of representing information. Text is symbolic, sequential, and abstract, while video is continuous, spatiotemporal, and concrete. Directly comparing or aligning text and video embeddings without addressing the modality gap results in suboptimal performance. Effective text-video retrieval methods necessitate techniques to learn a joint embedding space that minimizes the modality gap. This might involve advanced feature extraction techniques to capture fine-grained details from both modalities, multi-granularity matching strategies (e.g., frame-level, word-level), or innovative loss functions designed specifically for the ranking task inherent in retrieval. The use of diffusion models is particularly promising here because of their ability to progressively align text and video embeddings in a unified space. However, as shown in the paper, vanilla diffusion methods suffer from limitations such as their reliance on the L2 loss, which is not suitable for ranking tasks. Overcoming the modality gap requires sophisticated methods that go beyond simple alignment and address the inherent differences in the nature of text and video data.
CLIP Embedding#
CLIP embeddings, derived from the CLIP (Contrastive Language–Image Pre-training) model, offer a powerful approach to representing both images and text in a shared semantic space. Their strength lies in the ability to directly compare the similarity between image and text representations, facilitating tasks like image retrieval using text descriptions or vice-versa. However, the inherent limitations of the CLIP embedding space, such as modality gaps and the uneven distribution of embeddings, impact performance in downstream applications like text-video retrieval. Research often focuses on strategies to refine or augment CLIP embeddings, for instance, by incorporating temporal information in video analysis or addressing the modality gap via advanced alignment techniques. The effectiveness of CLIP embeddings hinges on the quality of the pre-trained model and the specific data used for training. Therefore, careful consideration of these factors is crucial for successful application. Future research likely will involve exploring novel methods to enhance the semantic alignment of CLIP embeddings and mitigate existing biases, possibly through techniques such as diffusion models or contrastive learning.
Future of DITS#
The “Future of DITS” holds exciting potential for advancements in text-video retrieval. Further research should focus on enhancing DITS’s robustness to noisy or incomplete data, a common issue in real-world scenarios. Exploring applications beyond video retrieval, such as image captioning or question answering, could significantly broaden its impact. Investigating the interplay between DITS and other large language models is crucial. This could lead to synergistic improvements that surpass the current state-of-the-art. Improving the efficiency of the truncated diffusion process, which currently presents a computational bottleneck, would be highly beneficial. Finally, in-depth analysis of the modality gap’s distribution, as well as the investigation of alternative loss functions, could optimize the alignment process leading to even more accurate results. Ultimately, continued development of DITS has the potential to revolutionize how we interact with multimodal data, improving applications from search to creative content generation.
More visual insights#
More on figures

This figure illustrates the architecture of the proposed Diffusion-Inspired Truncated Sampler (DITS). It starts with pre-trained text and video embeddings, focusing on the progressive alignment of text and video embeddings by gradually modeling the modality gap (the difference between text and video embeddings). The process uses a truncated diffusion process starting from the text embedding, guiding the alignment towards the video embedding. The process is controlled by the contrastive loss, which simultaneously considers relevant and irrelevant text-video pairs, making the embedding space discriminative. The figure visually demonstrates the steps of the truncated diffusion process and its integration with the contrastive learning mechanism to accomplish text-video alignment, highlighting its key advantages over existing methods.

This figure shows the distribution of the modality gap (the difference between text and video embeddings) for relevant text-video pairs before and after applying a diffusion model for alignment. The x-axis represents the L2-norm of the modality gap, and the y-axis represents the count of pairs with that gap. Two distributions are presented: one for the pairs before diffusion model alignment and one for the pairs after alignment. The figure visually demonstrates how the diffusion model helps reduce the modality gap, improving the alignment of text and video embeddings in the joint space. The reduction in the spread of the distribution after the alignment is also evident.
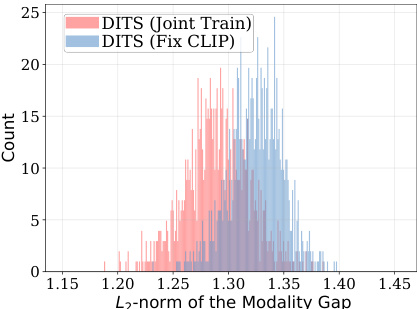
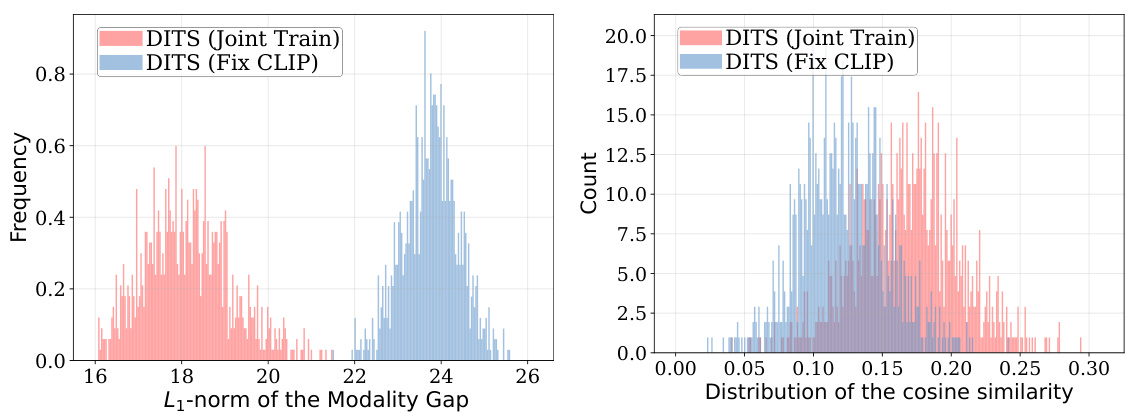
This figure shows the distribution of the modality gap (the L2-norm of the difference between video and text embeddings) for relevant pairs before and after applying DITS. The results indicate that DITS successfully reduces the modality gap, aligning the embeddings of text and video more closely. The comparison between ‘DITS (Joint Train)’ and ‘DITS (Fix CLIP)’ further highlights the effectiveness of jointly training the DITS model and CLIP embedding space, leading to a more significant reduction in the modality gap than simply using a pre-trained CLIP space.

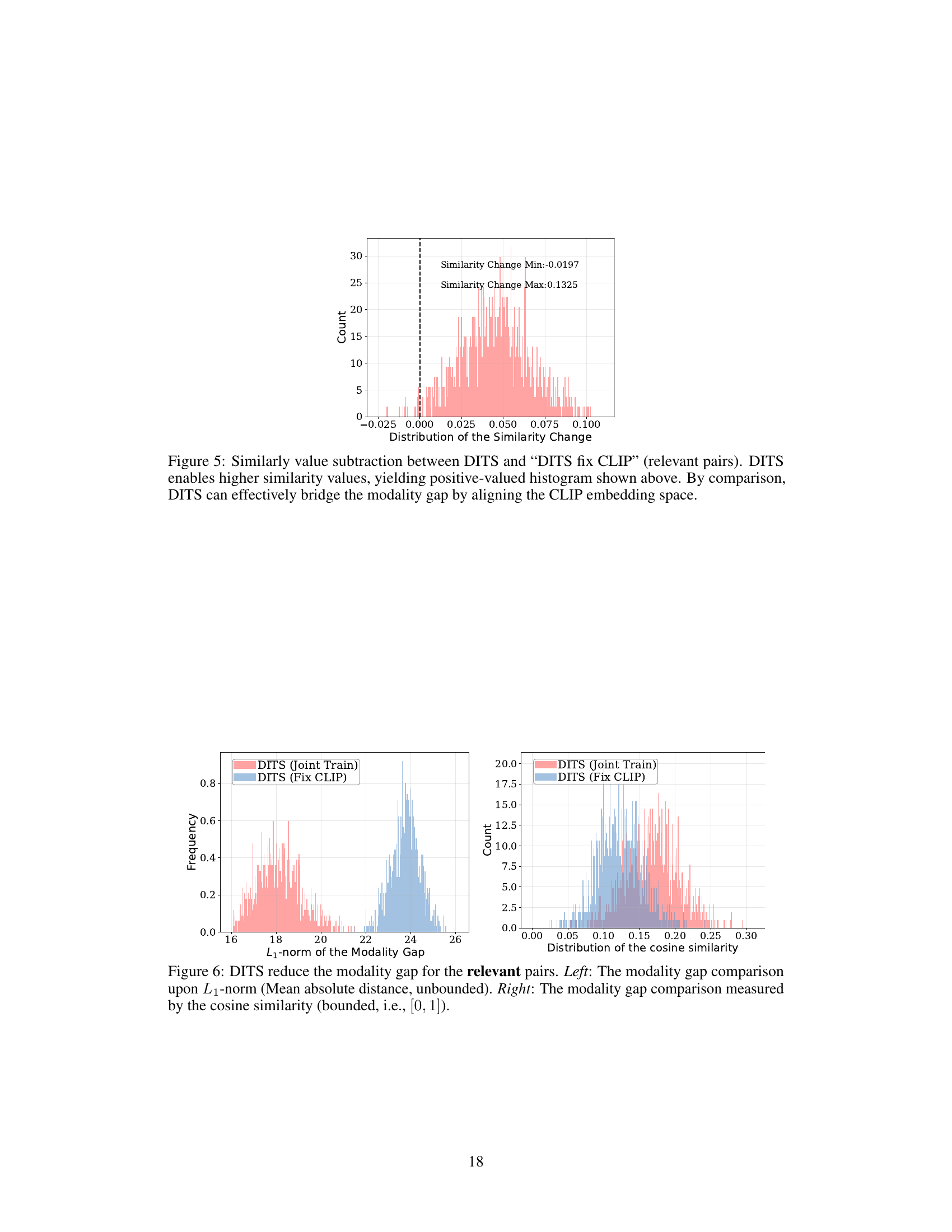
This figure shows the distribution of the difference in similarity scores between two methods: DITS and DITS with a fixed CLIP embedding space. The positive values in the histogram indicate that DITS improves the similarity between text and video embeddings, particularly for relevant pairs. This aligns with the paper’s central claim that DITS effectively reduces the modality gap by aligning the embeddings in the CLIP space.
This figure illustrates the Diffusion-Inspired Truncated Sampler (DITS) process for text-video retrieval. Starting from the text embedding, DITS progressively aligns it with the video embedding using a truncated diffusion process guided by a contrastive loss. The figure depicts the different components involved in the process, including the video and text encoders, the alignment network, and the contrastive loss calculation. It also shows how DITS models the modality gap between text and video embeddings over time.
More on tables
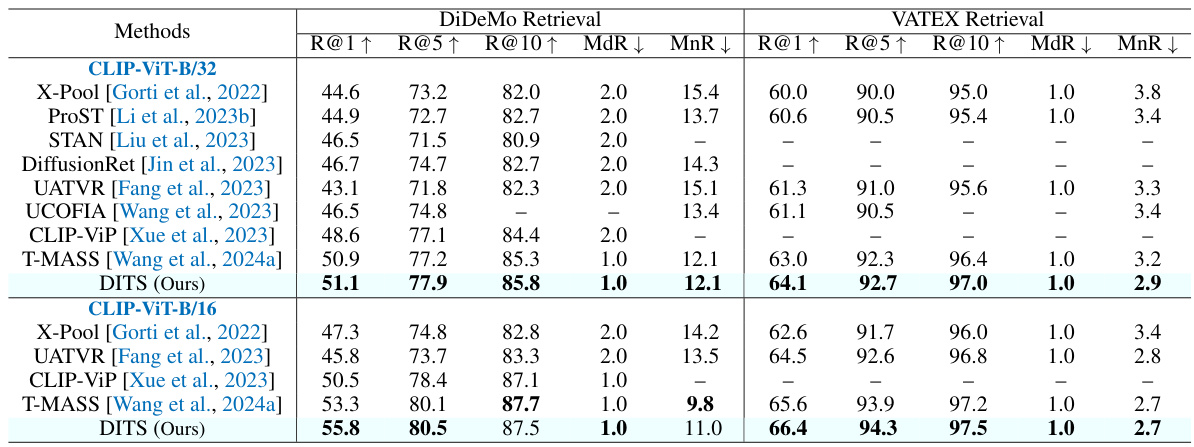
This table presents the performance comparison of different text-to-video retrieval methods on two benchmark datasets: DiDeMo and VATEX. The metrics used for comparison include Recall@1, Recall@5, Recall@10, Median Rank (MdR), and Mean Rank (MnR). The best performance for each metric is highlighted in bold. The ‘-’ symbol indicates that results were unavailable for a specific method and dataset.
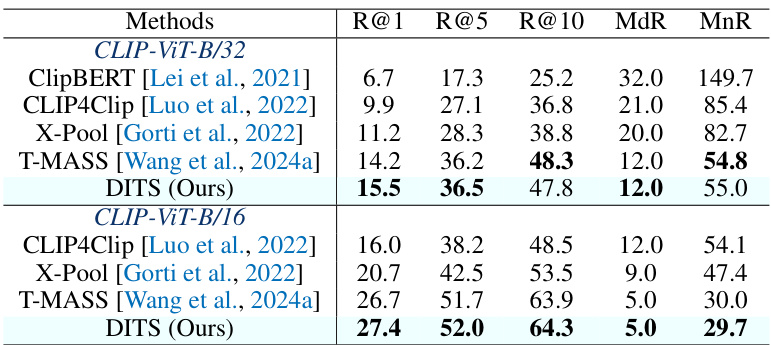
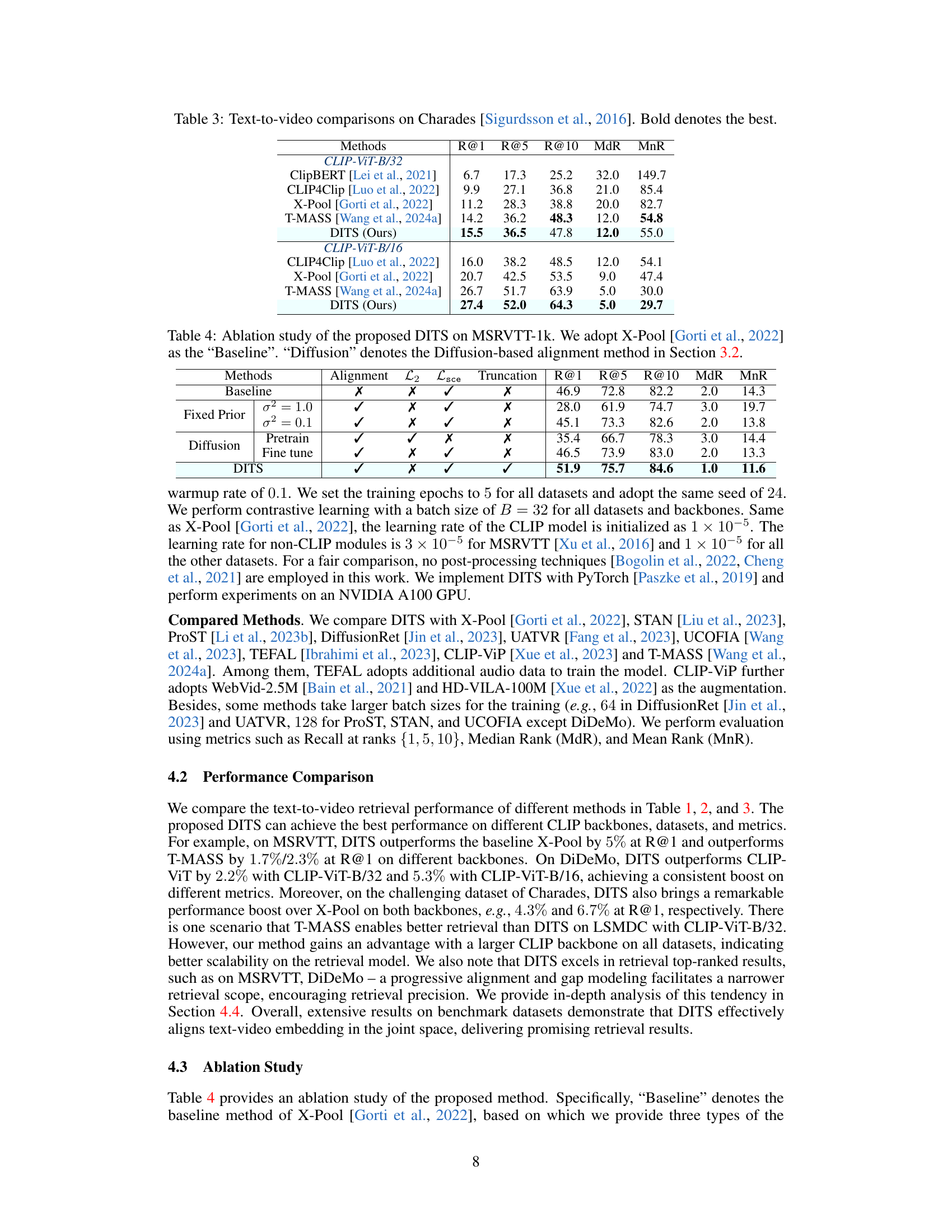
This table presents the results of text-to-video retrieval experiments conducted on the Charades dataset. The table compares several methods, showing their performance using the metrics R@1, R@5, R@10, MdR, and MnR. The best performance for each metric is highlighted in bold. The results are broken down by the CLIP model variant used (CLIP-ViT-B/32 and CLIP-ViT-B/16).

This ablation study analyzes different components of the proposed Diffusion-Inspired Truncated Sampler (DITS) method on the MSRVTT-1k dataset. It compares the performance of DITS against a baseline (X-Pool) and explores variations in the alignment method (fixed prior vs. diffusion), the loss function (L2 vs. contrastive loss), and the use of truncation. The results highlight the contribution of each component to the overall performance gains achieved by DITS.

This table presents an ablation study of the proposed DITS method on the MSRVTT dataset. It shows the impact of different numbers of timestamps (T’) on the model’s performance, highlighting the optimal value for T’. Additionally, it compares the performance of DITS when used to align embeddings within a fixed CLIP embedding space versus when it is jointly trained with CLIP. The results show that jointly training DITS with CLIP leads to the best performance and improves the structure of the CLIP embedding space.

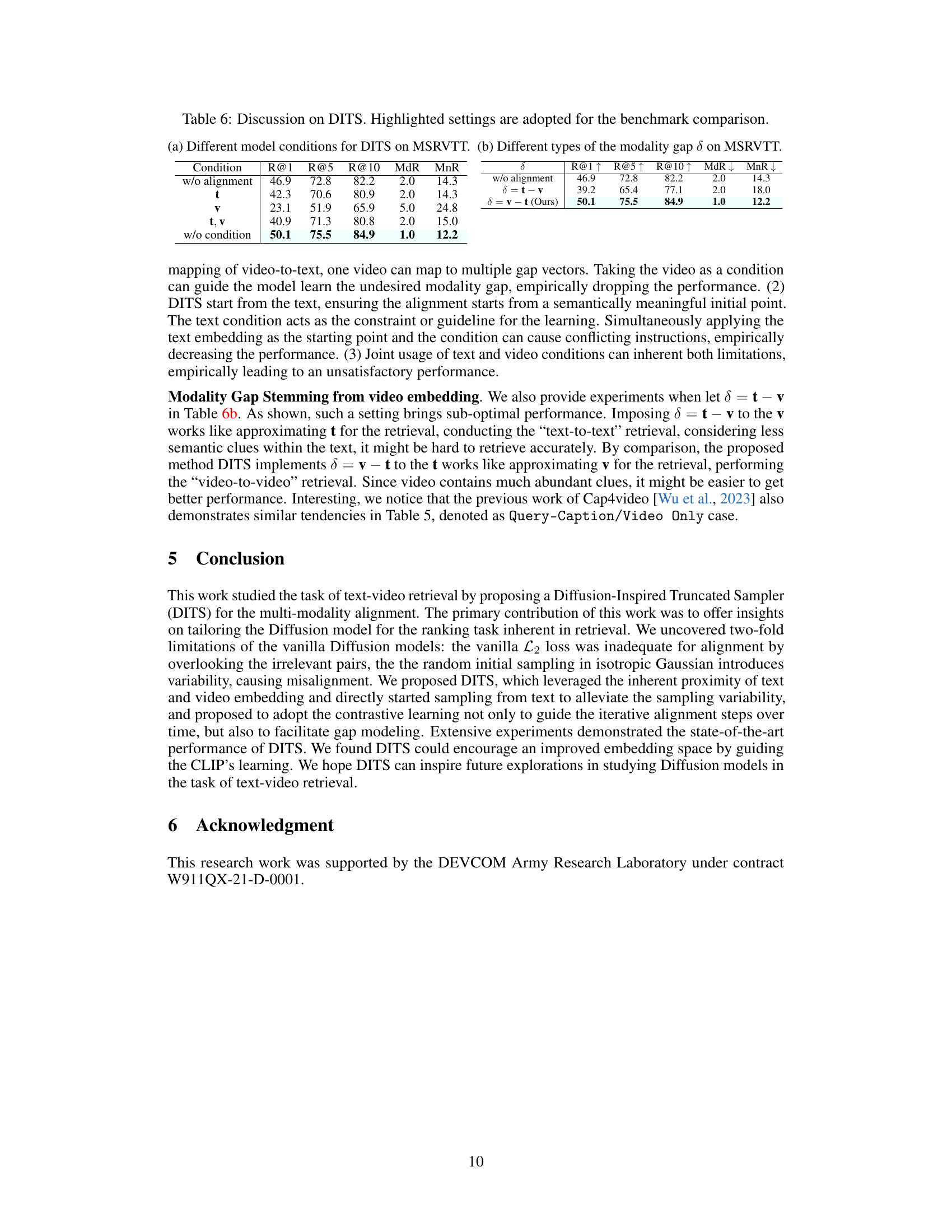
This table shows the ablation study of different model conditions (with text, video, both, or no condition) and different modality gap definitions (δ=v-t and δ=t-v) on the performance of the Diffusion-Inspired Truncated Sampler (DITS) method on the MSRVTT dataset. The results demonstrate that using text as both the starting point and condition in DITS leads to the best performance and using v-t as the modality gap results in significantly better performance compared to t-v.

This ablation study shows the performance of different variations of the proposed method, DITS, on the MSRVTT-1k dataset. The baseline is X-Pool. It compares the baseline against methods using fixed priors (with different variance settings), a pretrained diffusion model (with fine-tuning and without), and the full DITS approach. The metrics used are R@1, R@5, R@10, MdR, and MnR, which are standard retrieval metrics.

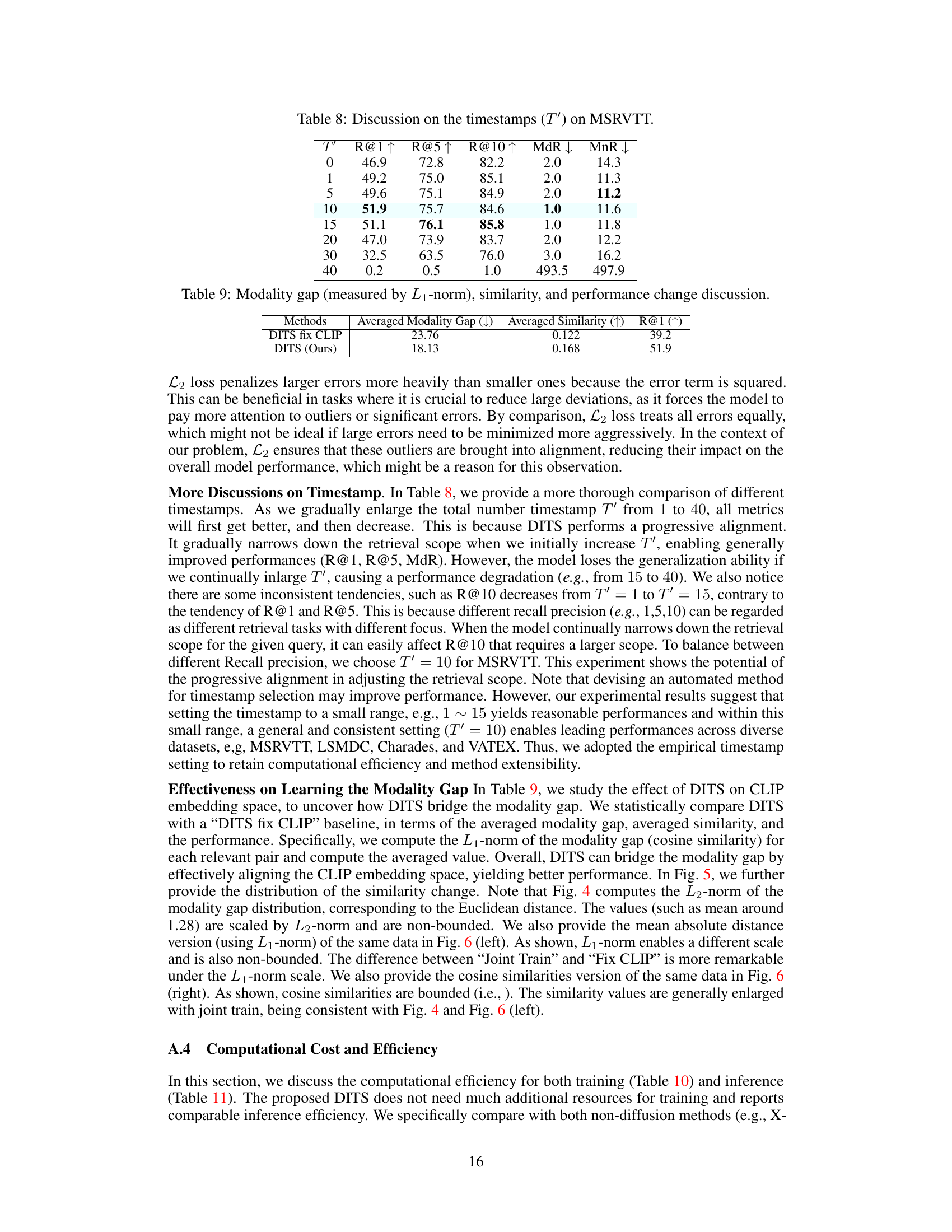
This table shows the impact of varying the number of truncated timestamps (T’) in the Diffusion-Inspired Truncated Sampler (DITS) on the text-to-video retrieval performance. The results are presented using several metrics, including Recall@1, Recall@5, Recall@10, Median Rank (MdR), and Mean Rank (MnR), evaluated on the MSRVTT dataset. It demonstrates how the choice of T’ significantly affects performance; there is an optimal value for T’ that balances the accuracy of alignment with the computational efficiency of the model.

This table presents a comparison between two approaches: DITS fix CLIP and DITS (Ours). The comparison is based on three metrics: Averaged Modality Gap (lower is better), Averaged Similarity (higher is better), and R@1 (Recall at rank 1, higher is better). The results show that DITS (Ours) significantly outperforms DITS fix CLIP across all three metrics, indicating a more effective modality gap reduction and improved retrieval performance.

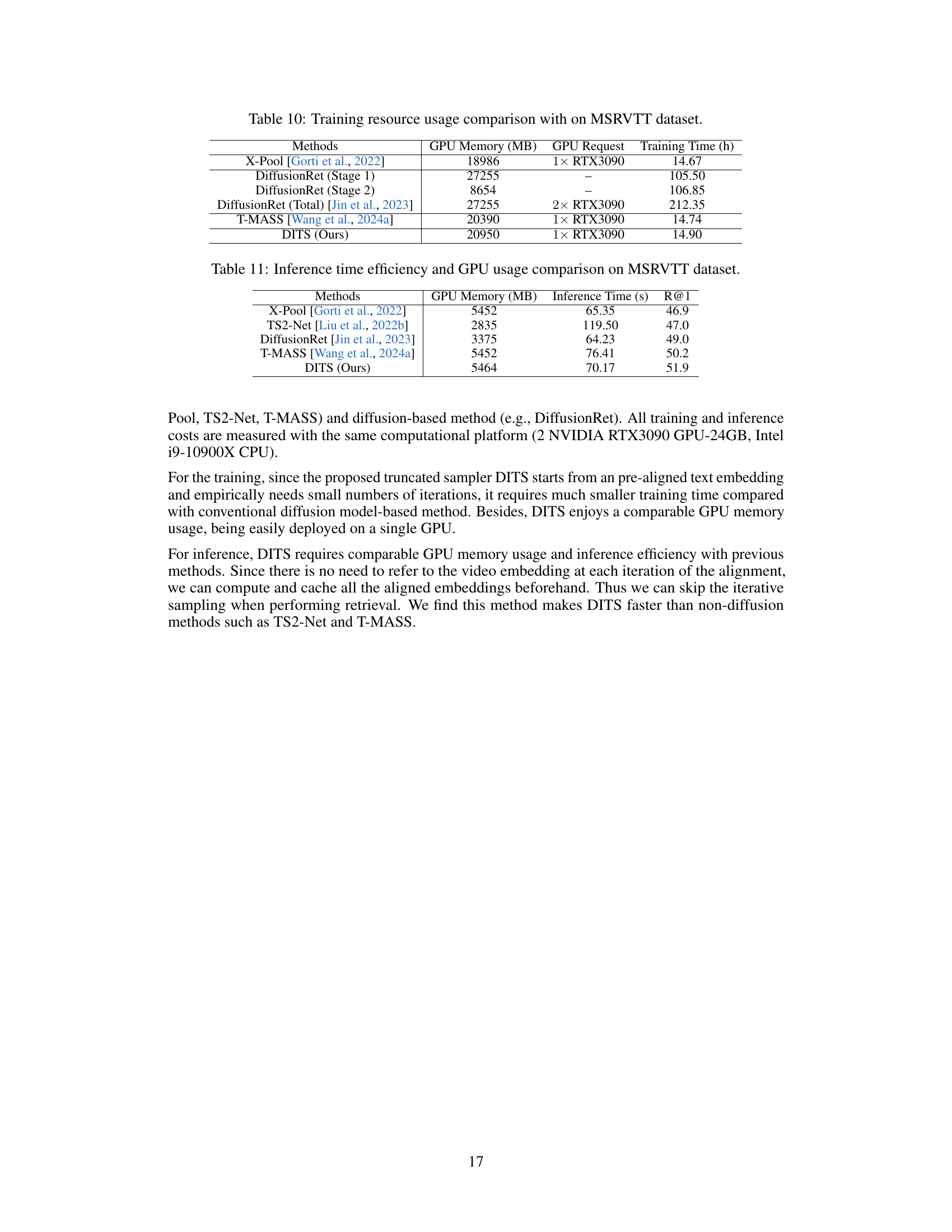
This table compares the training resource usage, including GPU memory (MB), GPU request, and training time (h), of different methods on the MSRVTT dataset. It provides a comparison of the computational efficiency and resource demands of various approaches to text-video retrieval, allowing for a relative assessment of their scalability and feasibility for different computational settings.

This table compares the inference time and GPU memory usage of different text-video retrieval methods on the MSRVTT dataset. It shows that DITS, while having comparable GPU memory usage to other top-performing methods, demonstrates faster inference time.
Full paper#