↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many joint object detection and instance segmentation models suffer from a performance imbalance, where detection lags behind segmentation. This imbalance, observed in the early transformer decoder layers, limits overall performance. This paper investigates this issue, revealing how initial feature tokens are crucial for both tasks.
The proposed solution, DI-MaskDINO, alleviates this imbalance by introducing two key modules: a De-Imbalance (DI) module to generate balance-aware queries, and a Balance-Aware Tokens Optimization (BATO) module to refine initial feature tokens. Experimental results on COCO and BDD100K benchmarks demonstrate that DI-MaskDINO significantly outperforms existing state-of-the-art methods, achieving substantial improvements in both detection and segmentation accuracy. This work offers valuable insights into handling task imbalances in multi-task learning and provides a highly effective model for joint object detection and instance segmentation.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical performance bottleneck in joint object detection and instance segmentation models. By identifying and mitigating the detection-segmentation imbalance, the research opens up new avenues for improving the accuracy and efficiency of these models, impacting various computer vision applications. The proposed DI-MaskDINO method provides a significant improvement over existing state-of-the-art models, making it highly relevant for researchers working on object detection and instance segmentation tasks. It also highlights the importance of considering task imbalances when developing multi-task learning models.
Visual Insights#
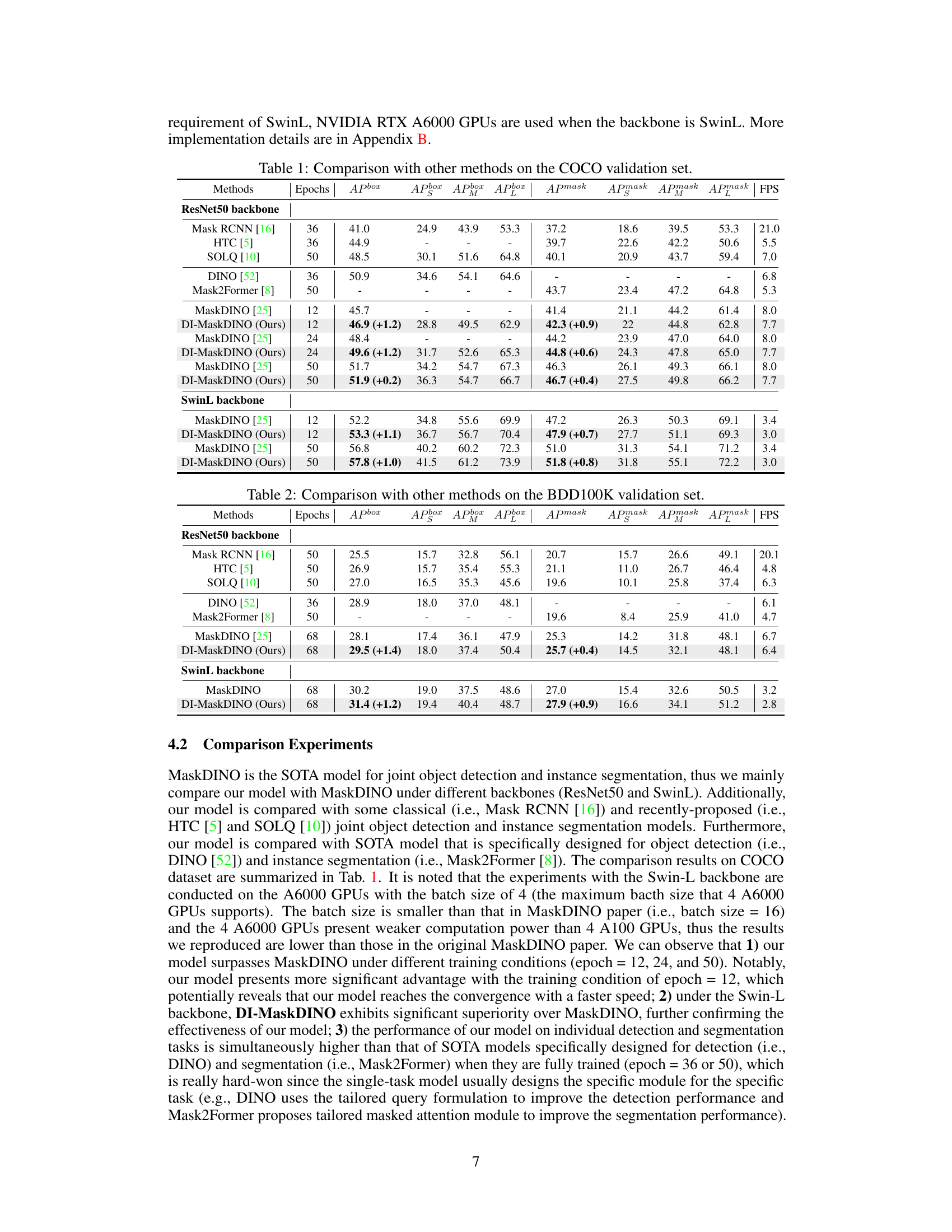
This figure presents a qualitative and quantitative comparison of MaskDINO and DI-MaskDINO’s performance at the first and last decoder layers. (a) and (b) show visual examples of bounding box predictions against segmentation masks, highlighting the improved alignment in DI-MaskDINO. (c) and (d) use bar charts to illustrate the significant performance gap between object detection and instance segmentation in MaskDINO’s first layer, which is largely reduced in DI-MaskDINO, resulting in an overall performance improvement.

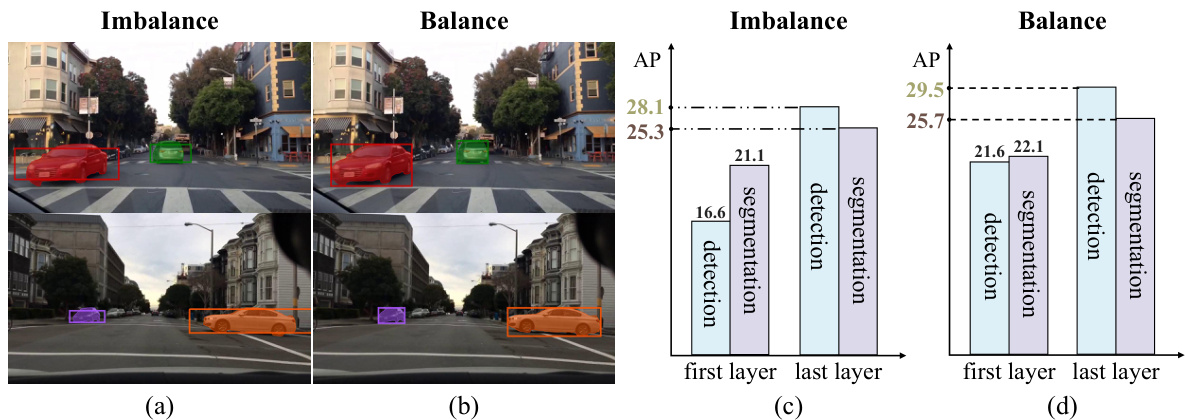
This table presents the comparison of DI-MaskDINO with other state-of-the-art object detection and instance segmentation models on the COCO validation dataset. It shows the performance metrics (APbox and Apmask) for different methods using both ResNet50 and SwinL backbones, along with the number of training epochs and Frames Per Second (FPS). The improvements achieved by DI-MaskDINO compared to the other models are highlighted in parenthesis. This demonstrates the superiority of DI-MaskDINO in terms of performance on this benchmark dataset.
In-depth insights#
Det-Seg Imbalance#
The concept of “Det-Seg Imbalance” highlights a crucial observation: object detection performance lags behind instance segmentation in many joint detection-segmentation models, particularly during initial processing stages. This imbalance, often stemming from differences in supervision strategies (dense for segmentation vs. sparse for detection) and inherent task characteristics (local detail focus for segmentation vs. global context for detection), can significantly limit the overall model performance. Addressing this imbalance is key to improving the upper bound of accuracy for both tasks. Strategies to mitigate this include modifying the model architecture to generate more balanced initial feature representations, adjusting loss functions to weigh detection and segmentation appropriately, or incorporating mechanisms that leverage the strengths of one task to improve the other.
DI & BATO Modules#
The core of the proposed DI-MaskDINO model lies in two novel modules: DI (De-Imbalance) and BATO (Balance-Aware Tokens Optimization), designed to address the detection-segmentation performance imbalance observed in the initial transformer decoder layers. The DI module cleverly employs a residual double-selection mechanism to generate a balance-aware query, effectively strengthening the detection aspect at the beginning layer and achieving better balance between detection and segmentation tasks. This query isn’t simply the initial feature tokens, but rather a refined subset informed by the intricate interplay between geometric, contextual, and semantic relationships within the initial feature tokens. BATO then leverages this refined query to guide the optimization of the initial feature tokens, ensuring the transformer decoder receives well-balanced input for both tasks, thereby improving the final performance. The synergy between DI and BATO is crucial, as DI generates the improved query, and BATO uses this query to improve the feature tokens. This combined approach leads to significant performance gains in both detection and segmentation compared to existing state-of-the-art models.
COCO & BDD100K#
The evaluation of object detection and instance segmentation models on the COCO and BDD100K datasets is crucial for assessing their real-world performance. COCO, a large-scale object detection dataset, provides a standardized benchmark for evaluating model accuracy across various object categories and difficulty levels. BDD100K, focusing on autonomous driving, offers a more challenging and diverse evaluation setting with complex traffic scenes and a greater variety of object interactions. The consistent strong performance of DI-MaskDINO across both datasets highlights its robustness and generalization capabilities. The comparison against state-of-the-art (SOTA) methods on these datasets emphasizes DI-MaskDINO’s significant improvement in both object detection and instance segmentation tasks. Comparing performance across COCO and BDD100K reveals the model’s ability to adapt to different scenarios and maintain high accuracy, suggesting that DI-MaskDINO is more adaptable and reliable than previous methods. The superior performance on BDD100K is particularly noteworthy, indicating the model’s potential for real-world applications like autonomous driving.
Ablation Studies#
Ablation studies systematically remove components of a model to understand their individual contributions. In the context of this research paper, likely scenarios for ablation studies would include removing the De-Imbalance (DI) module or the Balance-Aware Tokens Optimization (BATO) module, or both. By observing performance changes (e.g., on COCO or BDD100K benchmarks) after removing these components, the researchers could quantify the impact of each module on overall detection and segmentation accuracy, as well as assess whether there are synergistic effects between them. The results would likely demonstrate the importance of both modules for achieving the model’s improved performance, showing that DI effectively addresses the detection-segmentation imbalance while BATO enhances the optimization process. Further ablation experiments might also involve varying the number of transformer decoder layers or the parameters within the DI and BATO modules, helping to fine-tune the model’s architecture and hyperparameters. Such ablation studies are crucial for establishing a comprehensive understanding of the model’s design choices and their impact on overall effectiveness.
Future Works#
Future research directions stemming from this DI-MaskDINO model could explore several promising avenues. Extending the de-imbalance module to other multi-task learning scenarios beyond object detection and instance segmentation is crucial. This could involve adapting the residual double-selection mechanism to tasks like panoptic segmentation or semantic segmentation, evaluating its effectiveness in addressing task imbalances in these more complex domains. Furthermore, investigating the impact of different transformer architectures on the performance of DI-MaskDINO is warranted. Exploring alternatives to the current transformer structure could reveal further improvements in accuracy and efficiency. Improving the balance-aware tokens optimization module (BATO) by incorporating more sophisticated guiding mechanisms, perhaps based on advanced self-supervised learning techniques, could lead to even better performance. Finally, a comprehensive ablation study investigating the individual contributions of DI and BATO modules and their interaction is needed to fully understand the impact of each component on overall performance. This would aid in further refinement and optimization of the model architecture.
More visual insights#
More on figures
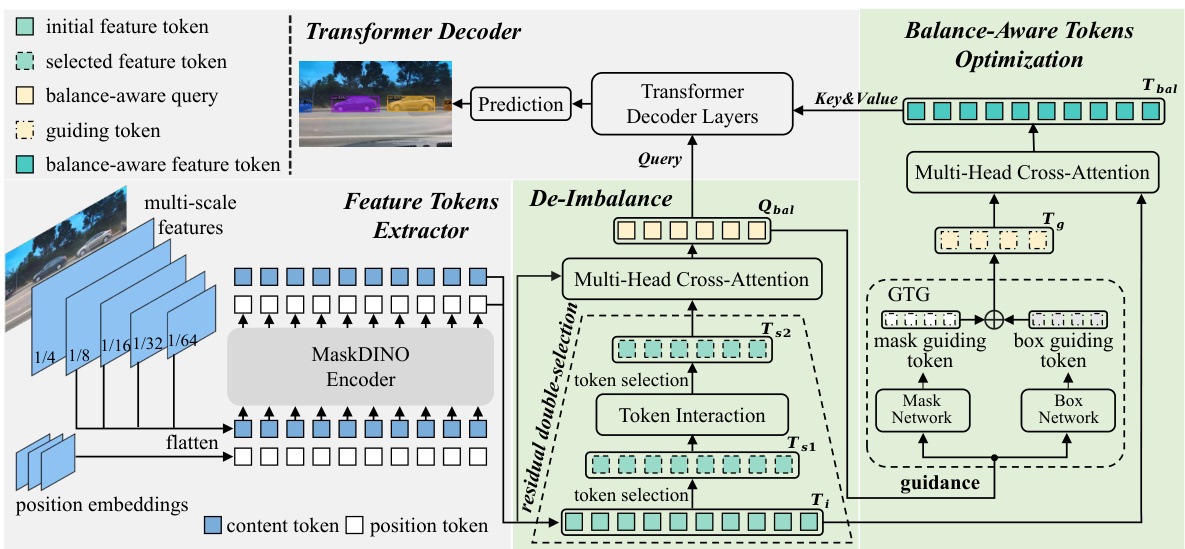
This figure shows the architecture of the proposed DI-MaskDINO model. It is built upon the existing MaskDINO model, enhancing it with two key modules: De-Imbalance (DI) and Balance-Aware Tokens Optimization (BATO). The DI module addresses the detection-segmentation imbalance by using a residual double-selection mechanism to generate a balance-aware query (Qbal). The BATO module then uses this query to optimize the initial feature tokens, generating balance-aware feature tokens. These optimized tokens are then fed into the transformer decoder for final prediction. The figure also highlights the different token types and their flow through the model.
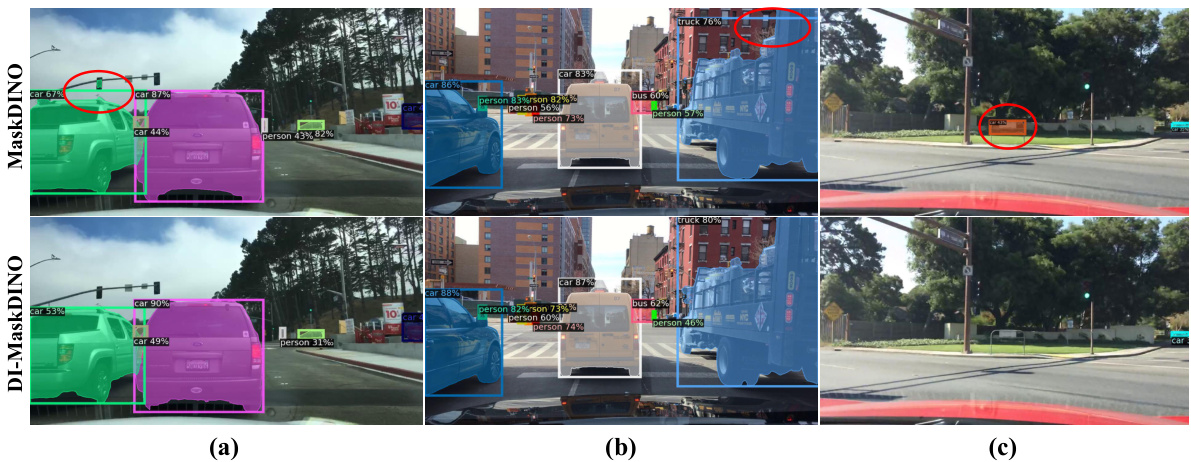
This figure demonstrates the qualitative and quantitative differences between MaskDINO and DI-MaskDINO in terms of detection and segmentation performance. (a) and (b) show visual comparisons of bounding box and segmentation mask alignment at the first decoder layer, highlighting the improved alignment in DI-MaskDINO. (c) and (d) present bar charts comparing the performance gap between detection and segmentation at the first and last decoder layers for both models, illustrating DI-MaskDINO’s success in reducing the performance imbalance and achieving a higher overall performance.
More on tables
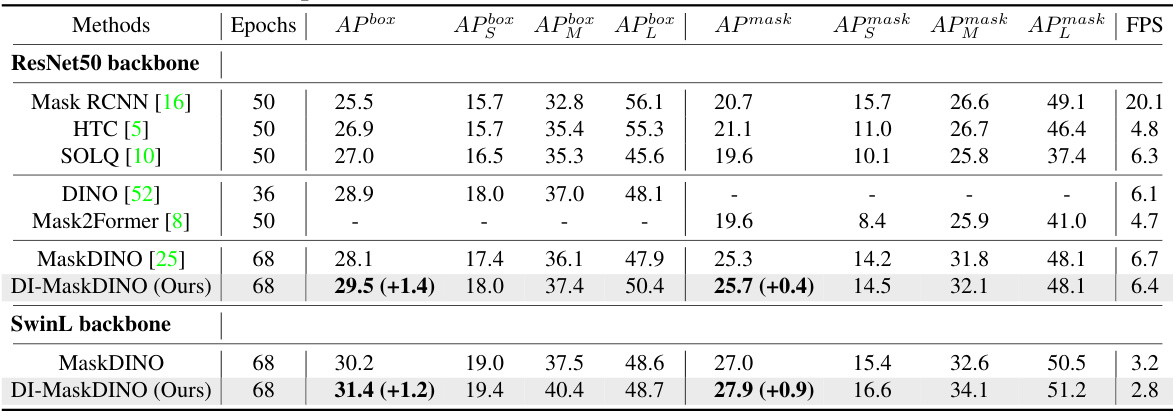
This table compares the performance of DI-MaskDINO with other state-of-the-art object detection and instance segmentation models on the BDD100K validation set. It shows the APbox (average precision for bounding boxes) and Apmask (average precision for masks) scores for each model, along with the number of training epochs and frames per second (FPS). The results highlight DI-MaskDINO’s improvement over existing models on this more challenging dataset.

This table presents the results of an imbalance tolerance test comparing the performance of MaskDINO and DI-MaskDINO under different imbalance conditions. The test was conducted to assess how well each model handles scenarios with a significant imbalance between object detection and instance segmentation. The ‘standard’ row represents the performance under normal conditions. The ’loss weight constraint’ and ‘position token constraint’ rows simulate conditions where the balance is significantly worsened by adjusting the loss weights and manipulating position tokens respectively. The percentage changes in APbox and Apmask relative to the standard condition are shown in parentheses. This experiment helps evaluate the robustness of each model to imbalance and highlights the effectiveness of DI-MaskDINO’s strategy in mitigating this issue.
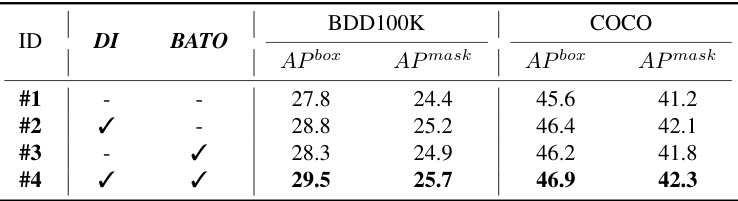
This table presents the results of ablation experiments on the main modules of the proposed DI-MaskDINO model. It shows the impact of the De-Imbalance (DI) module and the Balance-Aware Tokens Optimization (BATO) module on the performance of object detection and instance segmentation tasks on the BDD100K and COCO datasets. Four configurations are compared: (1) neither DI nor BATO are used, (2) only DI is used, (3) only BATO is used, and (4) both DI and BATO are used. The results show that using both DI and BATO leads to the best performance on both datasets.
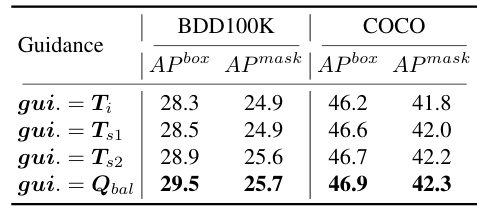
This table presents the ablation study results of the De-Imbalance (DI) module. It shows the performance of the model when different intermediate results from the DI module (Ti, Ts1, Ts2, Qbal) are used as guidance for the Balance-Aware Tokens Optimization (BATO) module. The results demonstrate the effectiveness of the residual double-selection mechanism in the DI module, showing improved performance when using Qbal (balance-aware query) compared to using the initial feature tokens (Ti).
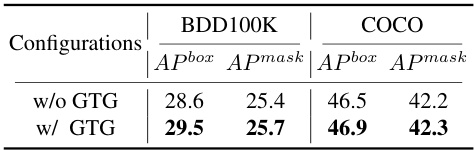
This table presents the ablation study results for the Balance-Aware Tokens Optimization (BATO) module. It compares the performance (APbox and Apmask) on the BDD100K and COCO datasets with and without the Guiding Token Generation (GTG) component of BATO. The results show that including GTG improves the performance of the model, highlighting the importance of GTG in BATO for enhancing the model’s ability to balance object detection and instance segmentation tasks.

This table presents the results of ablation experiments conducted to evaluate the impact of the number of token selection steps (single, double, or triple) on the performance of the DI-MaskDINO model. The experiment varied the number of selections while keeping the final number of selected tokens consistent. This helps determine the optimal number of selection steps for balancing performance and information loss.
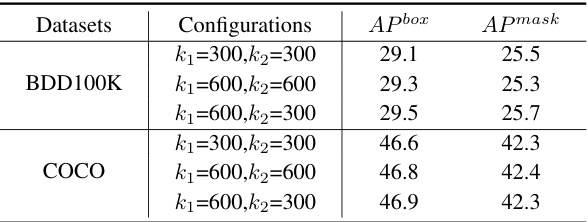
This table presents the results of experiments conducted to evaluate the impact of varying the number of selected tokens in the double-selection mechanism on the performance of the model. The experiments were performed on the BDD100K and COCO datasets. The results show the effect of different combinations of k1 (number of tokens selected in the first selection) and k2 (number of tokens selected in the second selection) on the APbox and Apmask metrics.
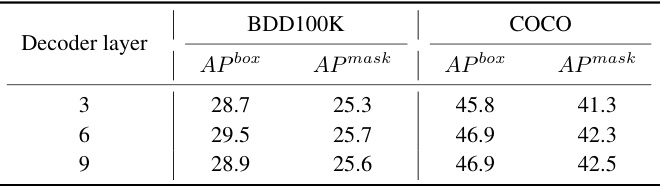
This table presents the results of experiments conducted to determine the optimal number of decoder layers in the DI-MaskDINO model. The performance, measured by Average Precision (AP) for both bounding boxes (APbox) and instance masks (APmask), is shown for different numbers of decoder layers (3, 6, and 9). The experiments were run on both the BDD100K and COCO datasets.
Full paper#