↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Diffusion Transformers (DiTs) have shown promise in image generation but have abandoned the U-Net architecture, which has been successful in other image tasks. This paper investigates the potential of combining the strengths of both architectures and explores several challenges and opportunities. DiTs, with their isotropic architecture (a linear chain of transformer blocks), have shown effectiveness and scalability but might overlook inherent advantages of U-Nets. Prior works have observed that U-Net backbones emphasize low-frequency features, suggesting redundancy in high-frequency details, which often get discarded in downsampling as a natural low-pass filter for diffusion models.
This paper proposes U-DiTs (U-shaped Diffusion Transformers), a novel approach that integrates a U-Net architecture with DiTs. The core improvement is incorporating token downsampling in self-attention within the U-Net structure. This change significantly reduces the computational cost (up to 1/3 less) while surprisingly improving performance compared to baseline DiTs. Extensive experiments show that U-DiTs consistently outperform existing DiTs across different model sizes and training iterations, reaching state-of-the-art results with significantly less computation. This work provides a valuable contribution to the image generation community.
Key Takeaways#
Why does it matter?#
This paper is important because it challenges the conventional wisdom in diffusion models by re-introducing the U-Net architecture, improving efficiency, and demonstrating state-of-the-art performance. It offers a new perspective on designing diffusion transformers and opens avenues for exploring the balance between model architecture and computational efficiency. The findings are particularly relevant to researchers working on image generation, especially those focusing on high-resolution image synthesis and efficient model design. This research could significantly advance the field of generative models and inspire further investigations into novel architectures for diffusion transformers.
Visual Insights#

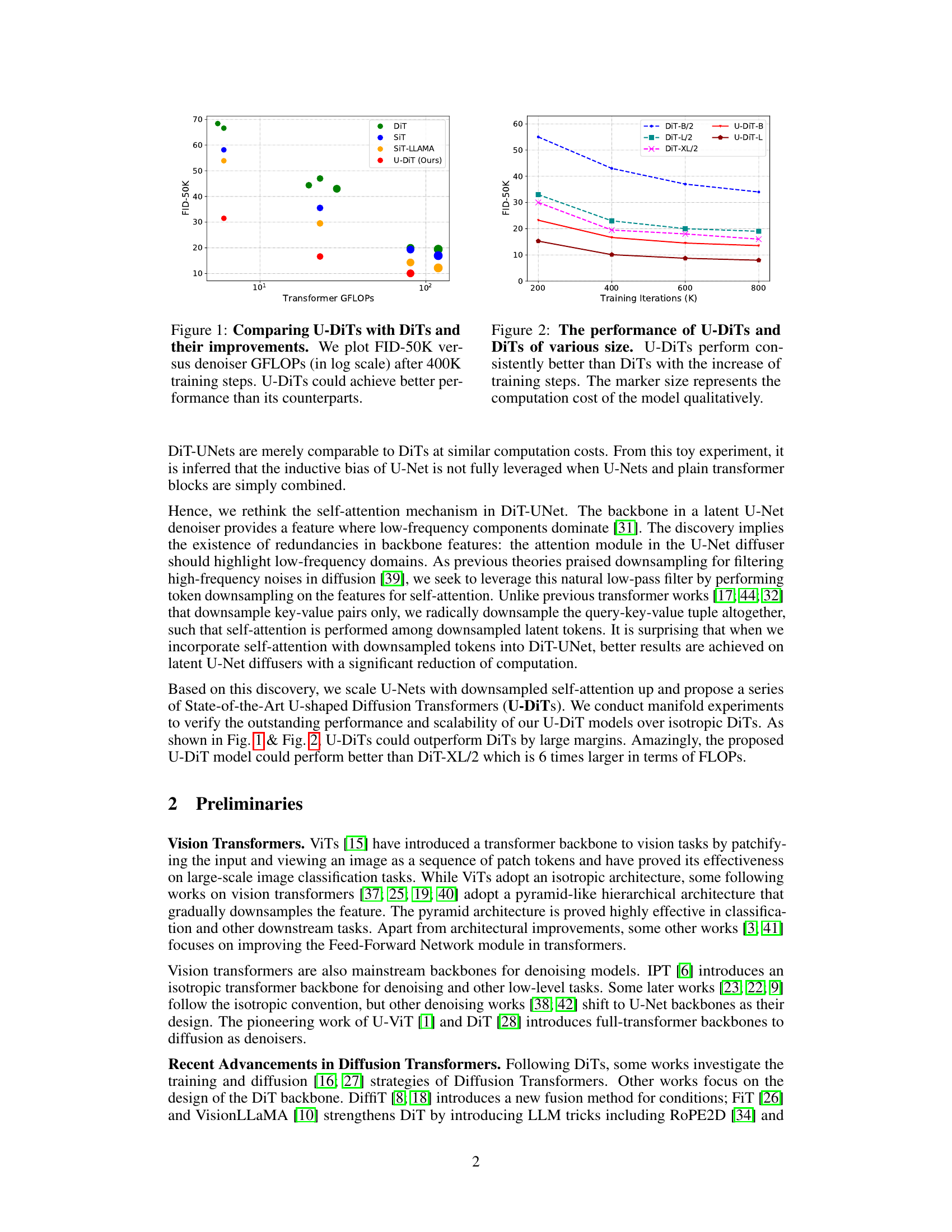
This figure compares the performance of U-DiTs (U-shaped Diffusion Transformers) with DiTs (Diffusion Transformers) and their variations across different model sizes. The x-axis represents the computational cost (GFLOPs) of the denoising models, and the y-axis represents the Fréchet Inception Distance (FID) score, a metric for evaluating the quality of generated images. Lower FID values indicate better image generation quality. The plot shows that U-DiTs consistently achieve lower FID scores compared to DiTs and other related methods at similar computational costs, suggesting superior efficiency and performance.
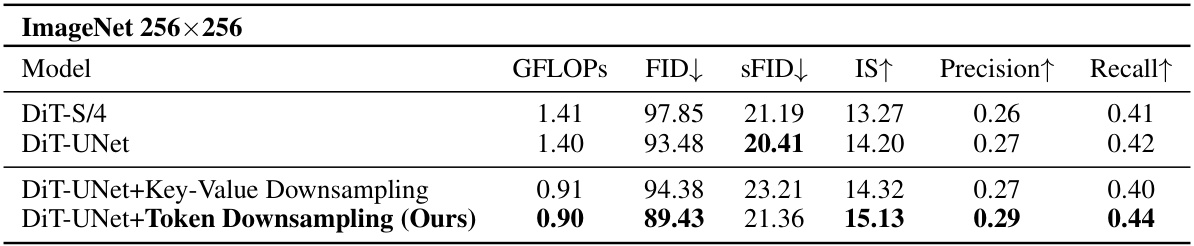
This table presents the results of a toy experiment comparing different variations of U-Net-style diffusion transformers (DiTs). It shows that a naive U-Net-style DiT (DiT-UNet) performs only slightly better than a standard isotropic DiT. However, incorporating token downsampling into the self-attention mechanism significantly improves performance while reducing computational cost.
In-depth insights#
U-Net DiT Fusion#
The concept of ‘U-Net DiT Fusion’ presents a compelling strategy for enhancing diffusion models. By combining the strengths of U-Net’s inductive bias for capturing spatial context and the scalability of Diffusion Transformers (DiTs), this approach aims to improve image generation quality and efficiency. The core idea involves integrating transformer blocks within a U-Net architecture, potentially leveraging the strengths of both model types. The success of this approach hinges on effectively managing the computational complexity of the combined model and ensuring that the U-Net’s inherent spatial resolution isn’t compromised by the transformer’s global focus. The challenge lies in achieving a harmonious balance between the localized processing of U-Net and the long-range dependencies facilitated by DiTs. Careful consideration needs to be given to the downsampling and upsampling stages within the U-Net structure to avoid loss of information and maintain efficient processing. The results of U-Net DiT fusion will need to show significant gains in image generation quality and efficiency compared to standalone U-Net or DiT models to justify the additional complexity of combining them.
Token Downsampling#
The concept of token downsampling, as presented in the context of diffusion transformers, offers a compelling approach to enhance efficiency and performance. By strategically reducing the number of tokens processed by the self-attention mechanism, it mitigates computational costs associated with large-scale models. This technique leverages the observation that U-Net backbones in diffusion models tend to be dominated by low-frequency components, implying potential redundancy in high-frequency information. Downsampling acts as a natural low-pass filter, focusing the model on salient, low-frequency features while discarding less relevant details. This approach, while seemingly simple, yields substantial performance gains. The paper showcases that this method not only reduces computational overhead but also surprisingly improves the overall model performance, outperforming larger models with significantly lower computational costs. The key to this method is to maintain the total tensor size and feature dimensions throughout the downsampling operation, preventing information loss and preserving the integrity of the attention mechanism. This approach is not simply downsampling key-value pairs but rather downsampling the query, key, and value tuples together and merging them after processing to ensure the total token count remains the same. The results demonstrate the effectiveness of token downsampling as a practical and efficient strategy for scaling up diffusion transformers, making them suitable for high-resolution image generation tasks.
U-DiT Scalability#
The scalability of U-DiT, a novel U-shaped diffusion transformer, is a key aspect of its design. Its modular U-Net structure allows for efficient scaling up by increasing the number of layers and channels. This contrasts with isotropic DiTs which scale by simply adding more transformer blocks. The use of downsampled tokens in self-attention drastically reduces computational cost while maintaining performance. This is crucial for large-scale image generation, as it allows the model to handle higher-resolution images and more complex data without becoming computationally intractable. Experiments demonstrate the ability of U-DiT to outperform larger, more computationally expensive DiTs, highlighting the effectiveness of its scaling strategy. Further investigation into the limits of U-DiT scalability with respect to computation and training time would be valuable to fully assess its potential.
Ablation Studies#
Ablation studies systematically remove or alter components of a model to understand their individual contributions. In a deep learning context, this might involve removing layers from a neural network, changing hyperparameters, or disabling certain functionalities. The goal is to isolate the impact of each component and demonstrate its necessity or redundancy. Well-designed ablation studies provide strong evidence supporting a model’s architecture and design choices. By observing the performance degradation after removing a component, we can quantify its importance. Conversely, a lack of significant performance drop suggests potential redundancy, guiding improvements like model simplification or optimization. Analyzing ablation study results requires careful consideration. It is crucial to define meaningful metrics that capture the essential aspects of the model’s function and to interpret changes in performance within the context of the overall system.
Future Work#
The paper’s core contribution is proposing U-DiTs, demonstrating their superior performance and scalability over existing DiTs for latent-space image generation. Future work could explore several promising avenues. Firstly, extending the training iterations beyond 1 million and scaling up the model size to fully tap the potential of U-DiTs would be valuable. Secondly, a deeper investigation into the downsampling mechanism itself is warranted. While effective, a more nuanced understanding could potentially yield further performance improvements or even the development of more efficient downsampling strategies. Finally, exploring applications of U-DiTs beyond image generation is crucial. Their architecture could be adapted for diverse vision tasks like video generation, 3D modeling, or other diffusion-based applications. Investigating the impact of different downsampling ratios on various tasks would be a significant step forward. In addition, investigating different types of downsampling techniques or incorporating them with other advancements in the field of diffusion models warrants exploration. Ultimately, the effectiveness of U-DiTs needs to be evaluated on datasets beyond ImageNet to verify their generalizability and robustness.
More visual insights#
More on figures

This figure compares the performance of U-DiTs and DiTs of different sizes over various training iterations. The y-axis represents the FID-50K score, a lower score indicating better image generation quality. The x-axis shows the number of training iterations in thousands. Different colored lines represent different model sizes (U-DiT-B, U-DiT-L, DiT-B/2, DiT-L/2, and DiT-XL/2). The size of the markers on the lines corresponds to the model’s computational cost, larger markers representing more computationally expensive models. The results demonstrate that U-DiTs consistently outperform DiTs across all sizes and training steps.
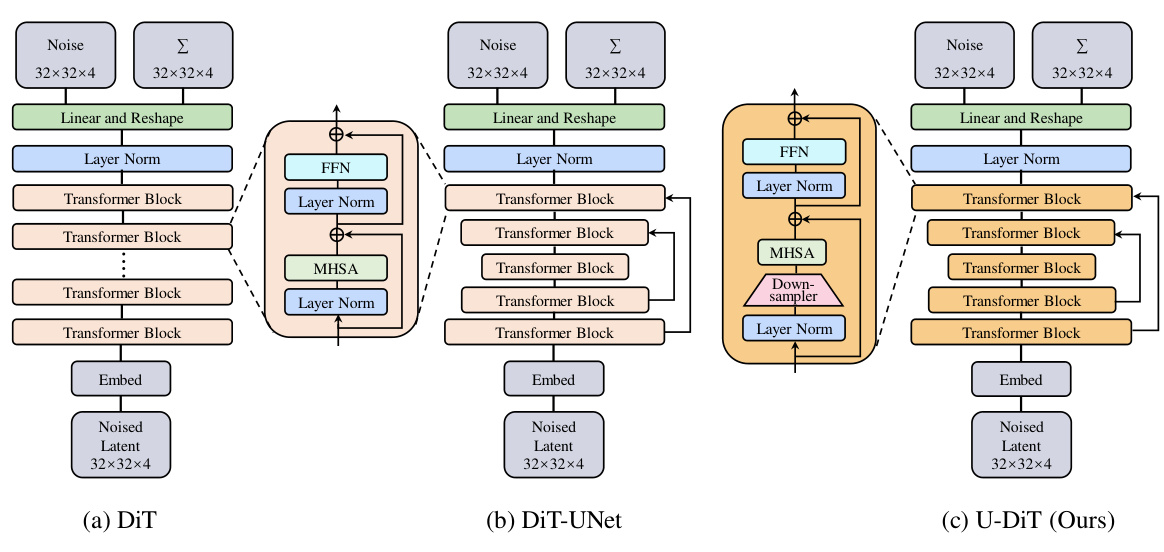
This figure illustrates the architectural evolution from the original Diffusion Transformer (DiT) to the proposed U-shaped DiT (U-DiT). It starts with the isotropic DiT (a), which uses a standard transformer architecture. It then shows DiT-UNet (b), a simple attempt to integrate the U-Net architecture with DiT blocks. Finally, it presents the U-DiT (c), which incorporates downsampled tokens in the self-attention mechanism for computational efficiency and performance improvement. The key difference is the introduction of a downsampler in U-DiT, leading to improved efficiency and performance compared to DiT-UNet.

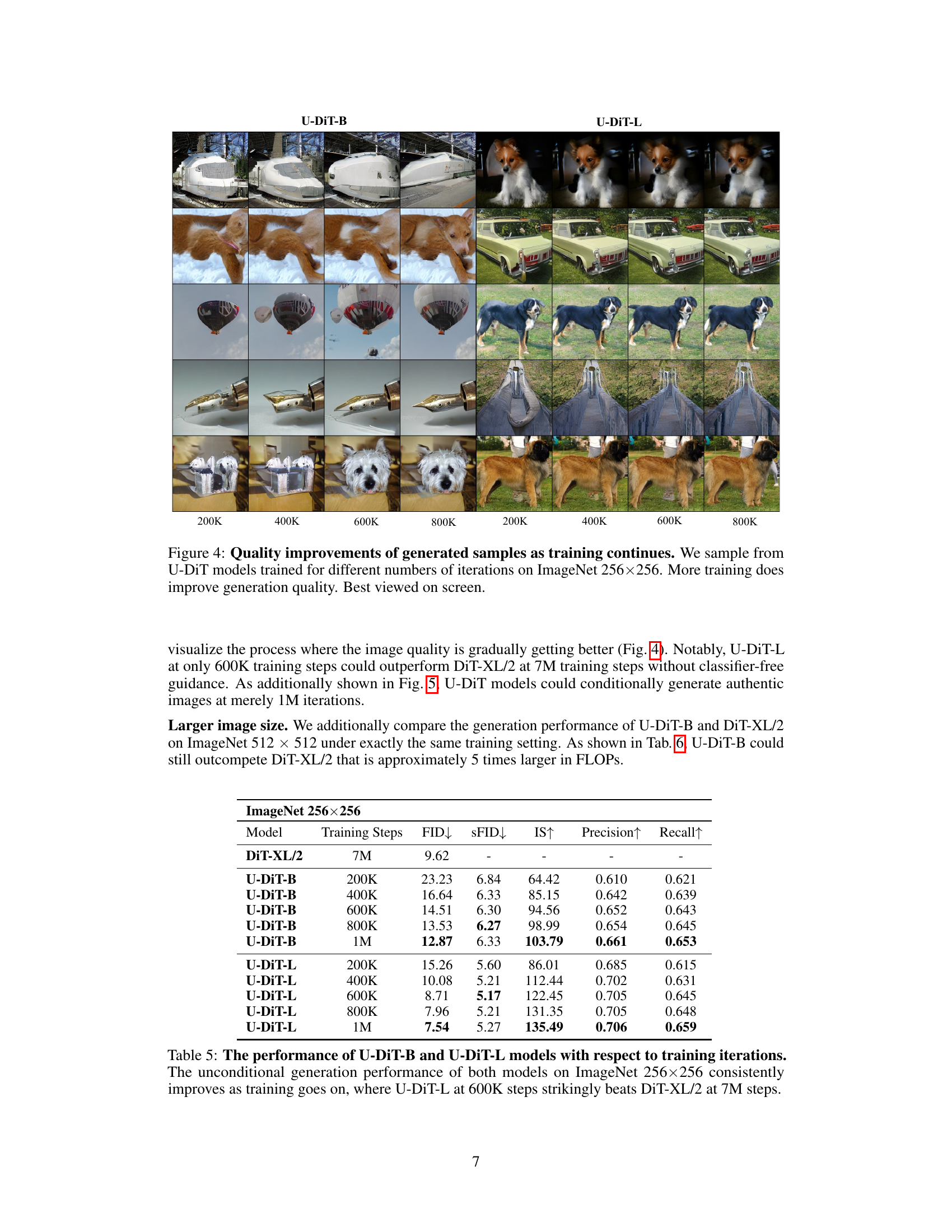
This figure shows the visual quality of images generated by U-DiT models at various training iterations (200k, 400k, 600k, 800k). Each row represents a different object class, demonstrating how the model’s generation quality improves with increased training. The improvement in detail, sharpness, and overall realism is clearly noticeable as the training iterations increase.

This figure shows various images generated by the U-DiT-L model after being trained for 1 million iterations. The images demonstrate the model’s ability to generate high-quality, realistic images of diverse subjects, including animals, objects, and scenes, highlighting the model’s capability even with relatively fewer training steps compared to other models.
More on tables
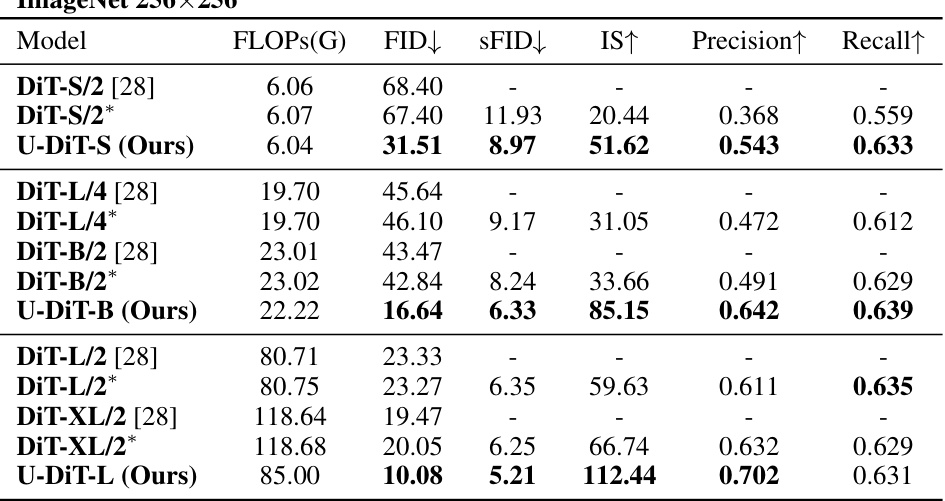
This table compares the performance of U-DiTs and DiTs on ImageNet 256x256 image generation. It shows that U-DiTs achieve significantly better results (lower FID, higher IS, etc.) than DiTs, even with fewer computational resources (GFLOPs). The results are particularly striking for U-DiT-B, which surpasses DiT-XL/2 despite using only 1/6th of the computation.
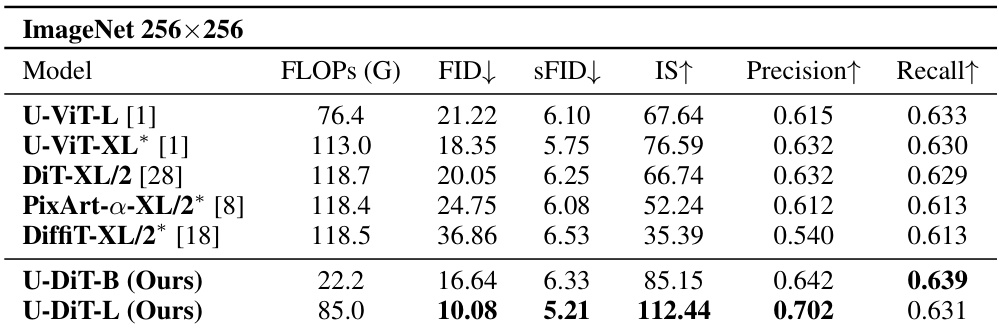
This table compares the performance of U-DiTs with other competitive diffusion architectures on the ImageNet 256x256 dataset. The comparison is done using several evaluation metrics including FLOPs, FID, sFID, IS, Precision, and Recall. The key takeaway is that U-DiTs achieve better performance with significantly lower computational costs.
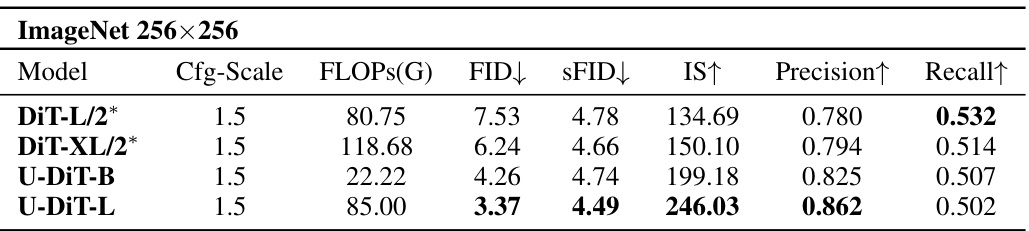
This table compares the performance of U-DiTs and DiTs on the ImageNet 256x256 dataset. It shows that U-DiTs achieve better FID (Fréchet Inception Distance), IS (Inception Score), precision, and recall scores compared to DiTs, even with significantly fewer FLOPs (floating point operations). This highlights the efficiency and performance advantages of U-DiTs.
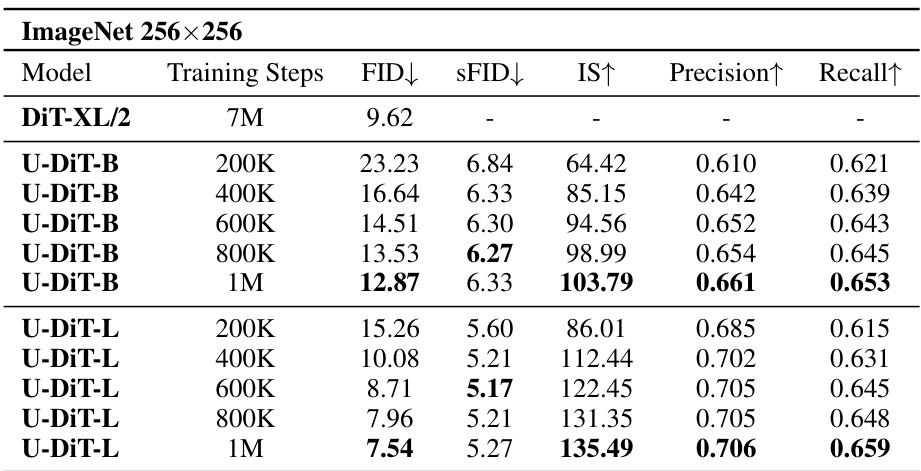
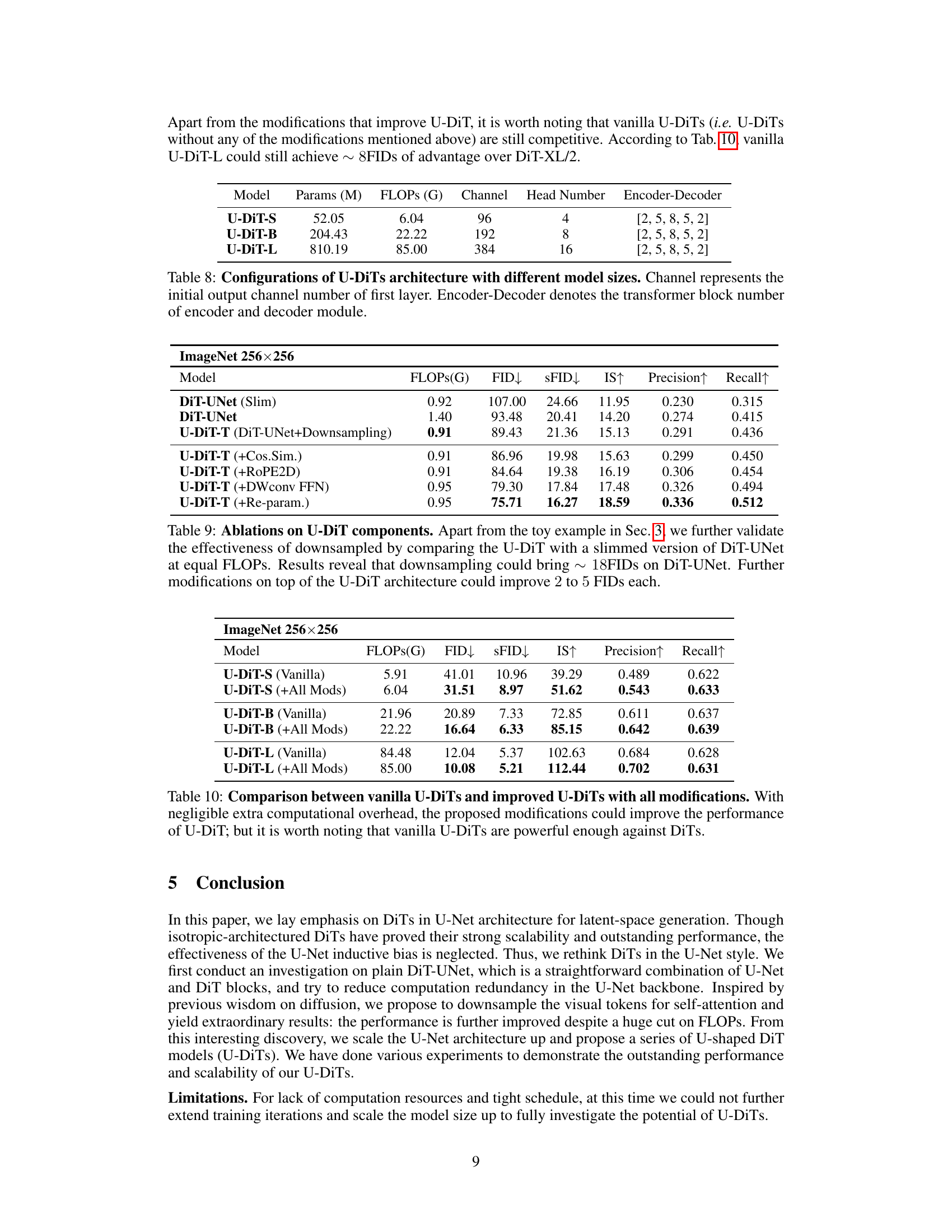
This table presents the FID, sFID, IS, precision, and recall scores for the U-DiT-B and U-DiT-L models trained for different numbers of iterations (200K, 400K, 600K, 800K, and 1M) on the ImageNet 256x256 dataset. It shows the improvement in the model’s performance (lower FID and sFID, higher IS, precision and recall) as the training progresses, demonstrating the models’ ability to learn better image generation with more training. U-DiT-L at 600k steps surpasses the performance of DiT-XL/2 trained for 7 million steps.

This table compares the performance of U-DiTs and DiTs on ImageNet 512x512 image generation. It shows that U-DiT-B significantly outperforms DiT-XL/2 in terms of FID and IS scores, while having a much lower computational cost (FLOPs). The asterisk (*) indicates experiments that replicated the original DiT code for fair comparison.

This table presents ablation studies on different downsampling methods used in the U-DiT architecture. It compares the performance (FID, SFID, IS, Precision, Recall) of three different downsamplers: Pixel Shuffle (PS), Depthwise Convolution (DW) Conv + PS, and DW Conv. || Shortcut + PS. The results show that combining depthwise convolution with a shortcut and then using pixel shuffling achieves the best performance with a relatively low computational cost.

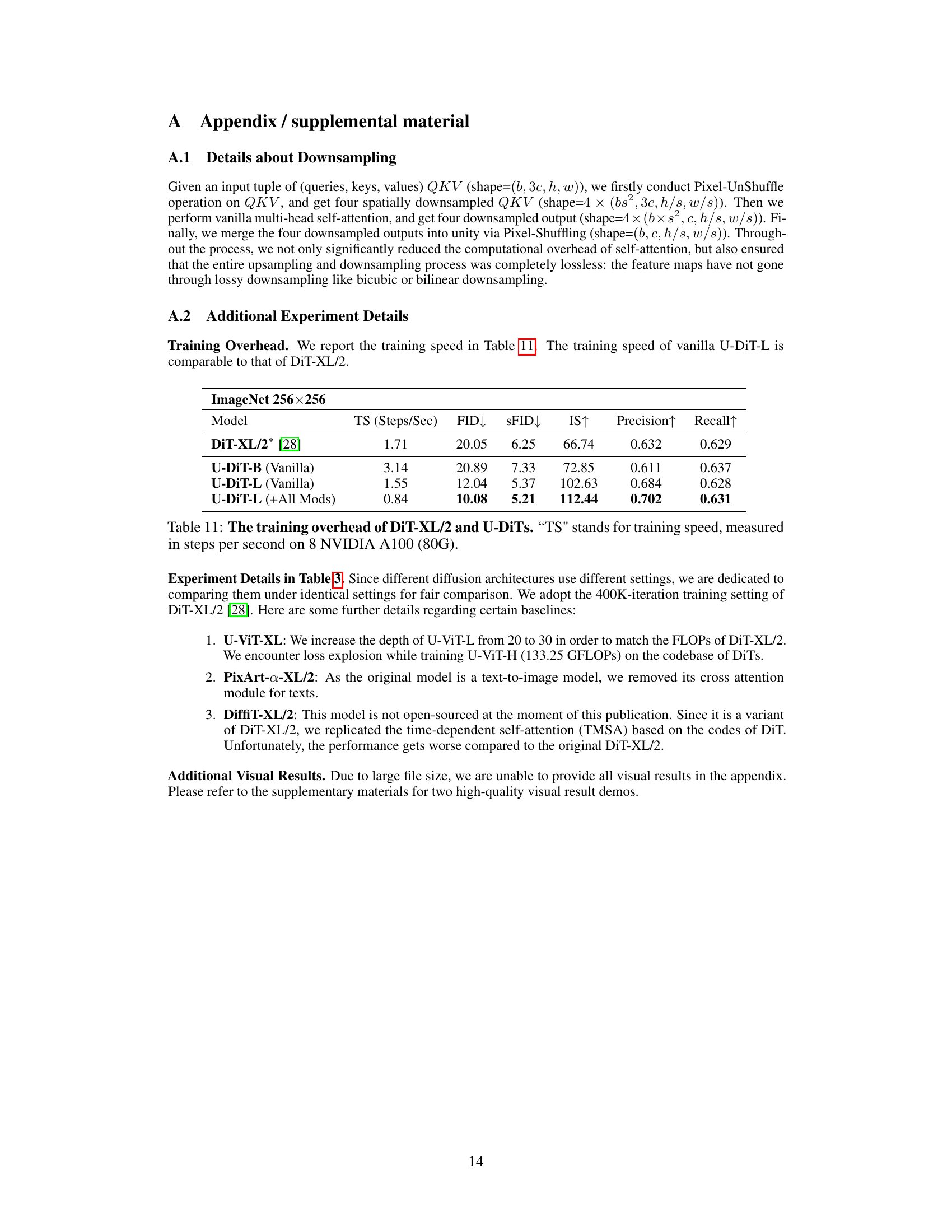
This table presents the configurations for three different sizes of the U-DiT model: U-DiT-S, U-DiT-B, and U-DiT-L. It lists the number of parameters (in millions), the number of floating-point operations (GFLOPs), the initial channel number, the number of attention heads, and the number of encoder and decoder blocks in each stage. The table provides essential details about the model’s architecture and computational complexity.

This table presents ablation studies on different components of the U-DiT model. It compares a baseline model (DiT-UNet (Slim)) with several variations of the U-DiT, each incorporating a different modification. The modifications evaluated are downsampling, cosine similarity, RoPE2D, depthwise convolution FFN, and re-parameterization. The table shows the impact of each modification on FID, SFID, IS, Precision, and Recall, demonstrating the contribution of each component to the model’s overall performance.

This table compares the performance of vanilla U-DiT models (without any modifications) to the performance of U-DiT models that include all proposed modifications. The results show that while the modifications improve performance metrics (FID, sFID, IS, Precision, Recall), the vanilla U-DiTs already perform competitively against DiTs, indicating the effectiveness of the core U-DiT architecture.
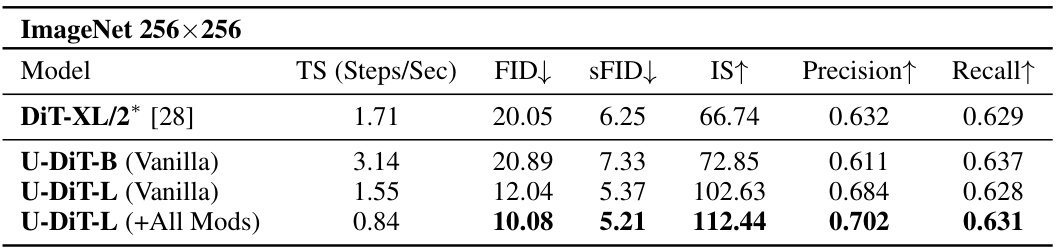
This table compares the training speed (steps per second) of the DiT-XL/2 model and different variants of the U-DiT model. It shows that the training speed of the vanilla U-DiT-L model is comparable to that of DiT-XL/2. Adding all modifications to the U-DiT-L model slightly decreases the training speed.
Full paper#