↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Existing novel view synthesis methods struggle with unconstrained photo collections due to variations in appearance and transient occlusions. They often require extensive training and slow rendering, hindering practical applications. Furthermore, many methods sacrifice rendering quality for efficiency.
Wild-GS tackles these issues by cleverly adapting 3D Gaussian Splatting (3DGS). It uses a hierarchical appearance model incorporating global and local features, along with techniques for handling transient objects and depth regularization. This results in significantly faster training and inference compared to state-of-the-art methods, while maintaining high rendering quality. The method demonstrates superior performance in experiments, achieving real-time rendering.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Wild-GS, a novel and efficient method for novel view synthesis from unstructured photo collections. This addresses a critical limitation of existing methods, enabling real-time rendering with high-quality results. It opens up new avenues for research in areas such as augmented reality, virtual tourism, and other applications needing efficient 3D scene reconstruction from readily available images.
Visual Insights#

This figure compares the novel view synthesis results of Wild-GS against other state-of-the-art methods (Ha-NeRF, CR-NeRF) on the Brandenburg Gate scene. It highlights Wild-GS’s superior computational efficiency (training time and inference speed) while achieving higher PSNR and SSIM scores, indicating better visual quality. The bottom row demonstrates the capability of Wild-GS to modify the appearance of the entire scene by simply adjusting appearance features.
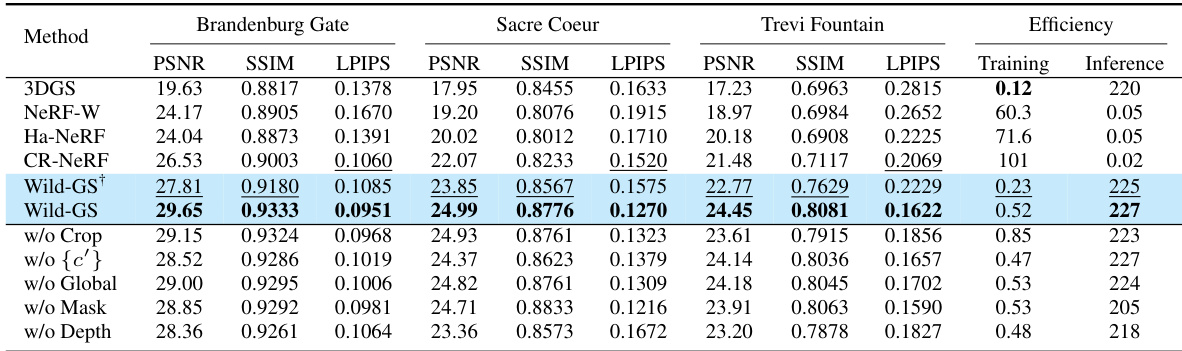
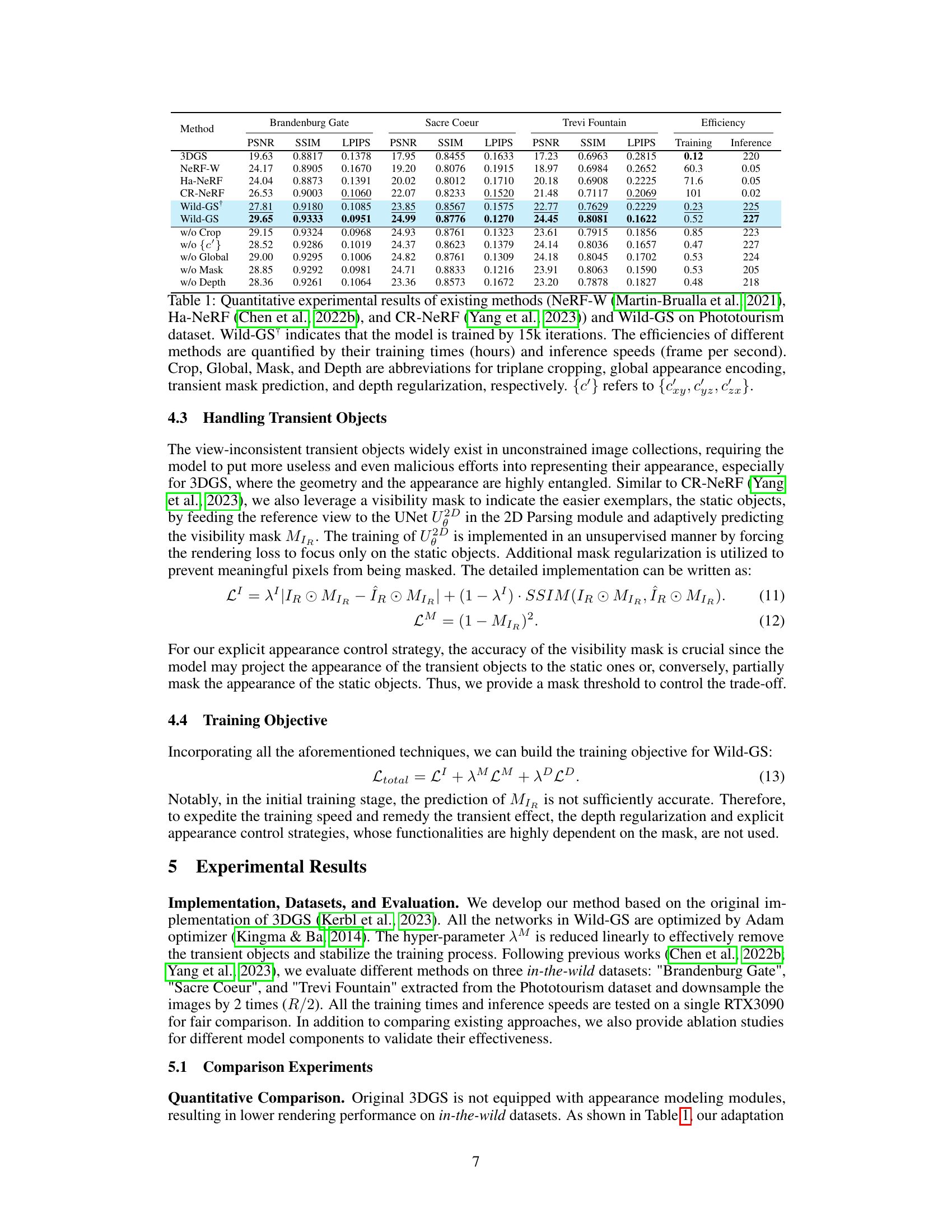
This table presents a quantitative comparison of Wild-GS against existing novel view synthesis methods (NeRF-W, Ha-NeRF, and CR-NeRF) on the Phototourism dataset. It shows metrics like PSNR, SSIM, and LPIPS, along with training time and inference speed for each method. Ablation studies are also included to demonstrate the impact of different components within the Wild-GS model.
In-depth insights#
Wild-GS: Novel Approach#
Wild-GS presents a novel approach to real-time novel view synthesis by adapting 3D Gaussian Splatting (3DGS). Wild-GS directly addresses the challenges of using unconstrained photo collections, a common problem in real-world applications. Unlike previous methods, Wild-GS leverages a hierarchical appearance decomposition, explicitly aligning pixel appearance features to corresponding 3D Gaussians via triplane extraction. This unique approach significantly improves training efficiency and rendering quality. Further enhancements include 2D visibility maps to mitigate transient objects and depth regularization for improved geometry. The method demonstrates state-of-the-art results, excelling in both efficiency and rendering accuracy compared to existing techniques. The core innovation lies in its explicit and efficient handling of appearance variations and transient objects within unstructured photo collections, a significant step forward in realistic novel view synthesis.
3DGS Efficiency Gains#
3D Gaussian Splatting (3DGS) offers significant efficiency advantages over traditional Neural Radiance Fields (NeRFs) for novel view synthesis. 3DGS’s explicit scene representation using point-based Gaussians, rather than implicit density and radiance fields, dramatically reduces computational cost during both training and inference. This is achieved by avoiding unnecessary computations in empty space, as only Gaussians within the field of view are projected onto the screen. The splatting process itself is highly efficient, leading to real-time rendering capabilities. However, the original 3DGS struggles with unconstrained photo collections due to challenges like transient objects and appearance variations. Adaptations like Wild-GS address these limitations while preserving the core efficiency benefits of 3DGS. Wild-GS achieves this by incorporating hierarchical appearance modeling, explicit local appearance control using triplanes, and depth regularization. The result is a substantial efficiency improvement over previous state-of-the-art in-the-wild novel view synthesis methods, demonstrating that real-time performance and high-quality rendering are not mutually exclusive.
Appearance Modeling#
Appearance modeling in novel view synthesis aims to realistically capture and reproduce the visual characteristics of a scene, which is challenging due to the variability in real-world photos. Wild-GS addresses this by employing a hierarchical approach, decomposing appearance into global (illumination, camera settings) and local (material properties, positional reflectance) components. The global component uses a global average pooling strategy on features extracted from the reference image, capturing scene-wide illumination and tone variations. Local appearance is tackled with a novel triplane-based approach, explicitly aligning pixel features from the reference image to corresponding 3D Gaussians. This explicit local modeling efficiently captures high-frequency details and significantly improves rendering quality. Furthermore, Wild-GS incorporates an intrinsic material feature for each Gaussian, enhancing robustness to viewpoint changes. This hierarchical approach, coupled with depth regularization and transient object handling, enables Wild-GS to achieve state-of-the-art results in real-time novel view synthesis from unconstrained photo collections.
Transient Object Handling#
Handling transient objects in novel view synthesis from unconstrained photo collections presents a significant challenge. Standard methods struggle because the appearance of a scene changes over time due to moving objects or temporary occlusions. Approaches like Wild-GS address this by leveraging visibility masks to identify and exclude transient elements from the scene representation. This is crucial for accurate scene reconstruction, as including transient objects can lead to artifacts and inaccuracies in novel view generation. The effectiveness of this strategy depends heavily on the accuracy of the visibility mask prediction, which itself is a non-trivial task and is usually done through a separate prediction network. Wild-GS utilizes a 2D parsing module to predict a visibility mask that isolates static objects, which improves the 3D scene representation by discarding misleading data. The resulting synthesis achieves higher quality by focusing exclusively on the stable components of the scene. Despite this masking, challenges remain in handling edge cases and subtle artifacts due to the inherent difficulty of fully separating static and dynamic elements. Careful consideration of the tradeoffs between accuracy and efficiency in the mask prediction is also crucial for computational feasibility, indicating a balance between computational efficiency and visual fidelity.
Future Work Directions#
Future research could explore several promising avenues. Improving the robustness of Wild-GS to handle even more challenging, highly dynamic scenes is crucial. This involves addressing limitations like the handling of extremely transient objects and refining the visibility mask estimation to enhance the quality of reconstruction. Developing more sophisticated appearance modeling techniques that account for complex lighting conditions and material properties would further enhance realism. Investigating the application of Wild-GS to other 3D representation methods, beyond the current 3D Gaussian Splatting, could lead to novel hybrid approaches that combine the efficiency of explicit representations with the high-fidelity achievable through implicit methods. Additionally, exploring real-time applications of Wild-GS, such as augmented reality and virtual reality, would be impactful. Finally, a comprehensive benchmark dataset tailored for evaluating novel view synthesis from unconstrained photo collections could serve as a standard for future progress in the field.
More visual insights#
More on figures
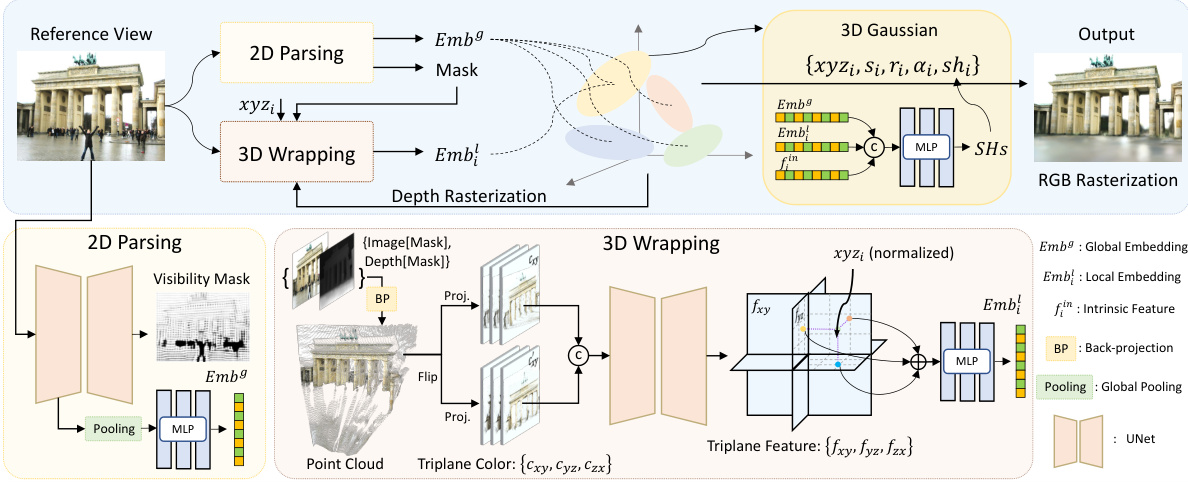
This figure illustrates the architecture of Wild-GS, which consists of three main components: 2D Parsing Module, 3D Wrapping Module, and a fusion network. The 2D Parsing Module extracts the visibility mask and global appearance embedding from the reference view. The 3D Wrapping Module uses the depth information from 3DGS to back-project the reference image and constructs the 3D point cloud. This point cloud is then used to generate triplane features, which are used by each 3D Gaussian to query its local appearance embedding. Finally, the fusion network combines the global and local embeddings with the intrinsic feature to predict the SH coefficients for RGB rasterization.

This figure shows the process of generating triplane features from the reference image’s point cloud in Wild-GS. (a) illustrates the back-projection of the point cloud onto three orthogonal planes and their reverses to create six triplane color maps (Cxy, Cyz, Czx, Cry, C’yz, C’zx). (b) demonstrates an efficiency improvement by cropping the original triplane to a smaller Axis-Aligned Bounding Box (AABB) which contains most of the 3D Gaussian points, thereby reducing computation.

This figure shows a visual comparison of the rendering quality produced by different novel view synthesis methods on three example scenes from the Phototourism dataset. The methods compared are NeRF-W, Ha-NeRF, CR-NeRF, and the proposed Wild-GS (trained for 15k and 30k iterations). Each row represents a different scene. For each scene, the ground truth image is shown alongside the results from each method. Red boxes highlight areas where appearance differences are particularly noticeable, while blue boxes highlight areas with geometric discrepancies.

This figure shows the results of an ablation study on the Wild-GS model. It compares the full Wild-GS model to versions where depth regularization, the transient mask, and global appearance encoding have been removed, individually. The red boxes highlight areas where the removal of these components leads to missing geometry or color inconsistencies. The figure demonstrates the importance of each component for the quality of novel view synthesis.

This figure demonstrates the appearance and style transfer capabilities of Wild-GS and CR-NeRF. It shows novel view synthesis results where the appearance of the scene has been altered using different reference images, both from within and outside the training datasets used to train the models. The results highlight the ability of Wild-GS to more accurately capture and transfer the appearance of the reference image compared to CR-NeRF, showcasing the superior performance of Wild-GS in appearance and style transfer tasks.

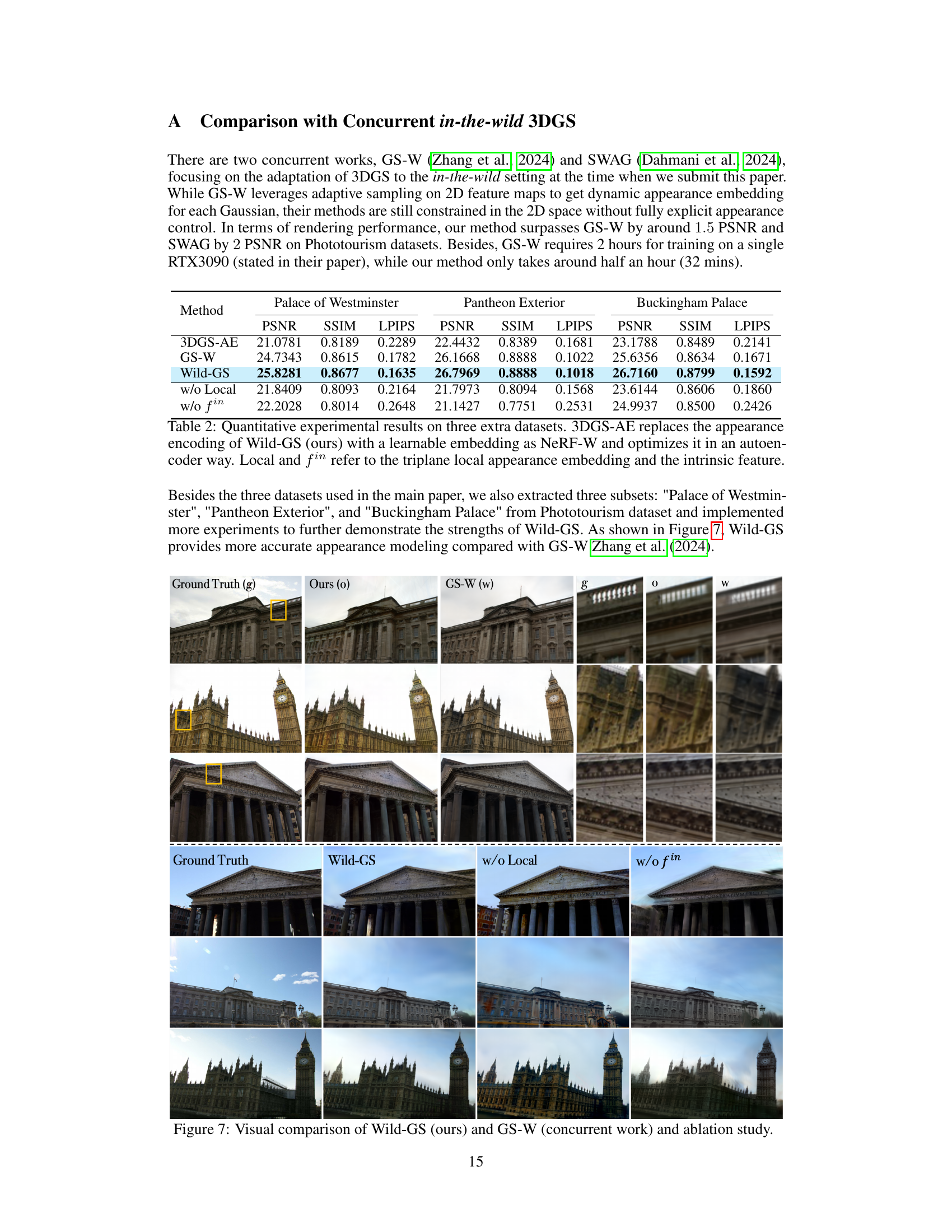
This figure compares the visual results of Wild-GS with a concurrent work, GS-W, and also shows the effects of removing the local appearance embedding and intrinsic feature from the Wild-GS model. The top row shows three images: Ground Truth, Wild-GS, and GS-W. The bottom row shows Wild-GS, Wild-GS without local appearance, and Wild-GS without intrinsic features. The yellow boxes highlight details, and it is evident that Wild-GS shows improved details and visual quality compared to GS-W. The ablation study demonstrates that both the local appearance and intrinsic features are essential for high-quality results.

This figure visualizes the transient masks generated by the Wild-GS model. The masks identify areas of the image containing transient objects, which are those that change between different views of the scene, like moving people or vehicles. The unsupervised learning process means the model learns to identify these areas without explicit training data specifying where transient objects are. The masks allow the model to focus on static elements when rendering novel views, which improves the quality and consistency of the synthetic images.

This figure compares the novel view synthesis results of Wild-GS against other state-of-the-art methods (Ha-NeRF, CR-NeRF) on the Brandenburg Gate scene. Wild-GS demonstrates superior performance in terms of both visual quality (PSNR and SSIM) and computational efficiency (training time and inference speed). The figure highlights Wild-GS’s ability to reconstruct fine details and handle complex scenes with dynamic appearance changes more effectively than previous methods.
Full paper#