↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many real-world applications of reinforcement learning, such as healthcare and education, involve significant participant heterogeneity. Existing off-policy selection (OPS) methods often struggle to handle this, particularly when a new participant joins and there is no prior data on their behavior. This necessitates a solution for selecting suitable policies online for new participants without the need for extensive online testing, which can be time consuming and expensive.
The paper introduces First-Glance Off-Policy Selection (FPS), a novel method that tackles this challenge head-on. FPS systematically addresses participant heterogeneity by grouping individuals with similar traits and applying tailored OPS criteria to each subgroup. This personalized approach ensures that the most suitable policy is selected for each new participant. The effectiveness of FPS is demonstrated through experiments in intelligent tutoring systems and sepsis treatment, showing substantial improvements over existing OPS methods in enhancing learning outcomes and improving patient care. FPS is a significant advancement in real-world applications of human-centric AI systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in human-centric AI, particularly those working on reinforcement learning and off-policy methods. It directly addresses the challenge of deploying policies to new participants in systems like healthcare and education, where individual differences are significant. The proposed FPS framework offers a novel solution and opens up exciting new research avenues, including the development of more personalized and robust off-policy selection methods.
Visual Insights#
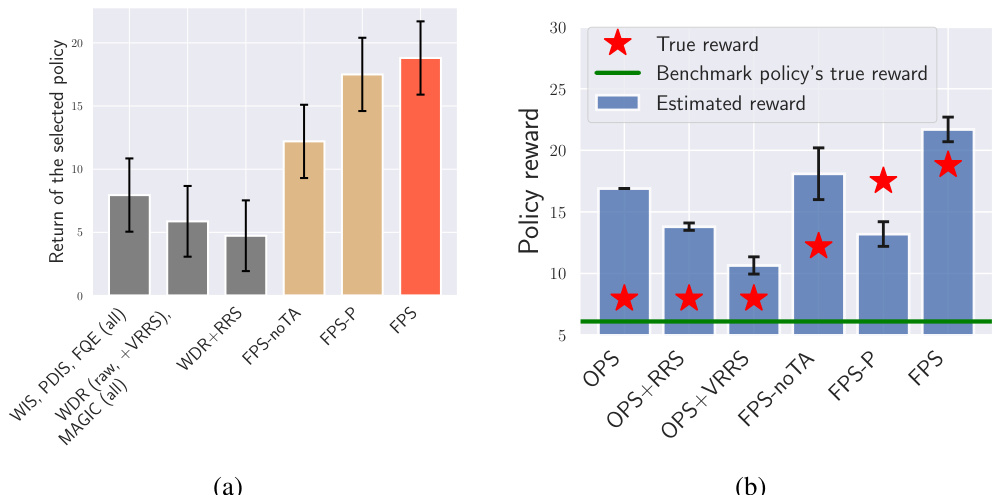
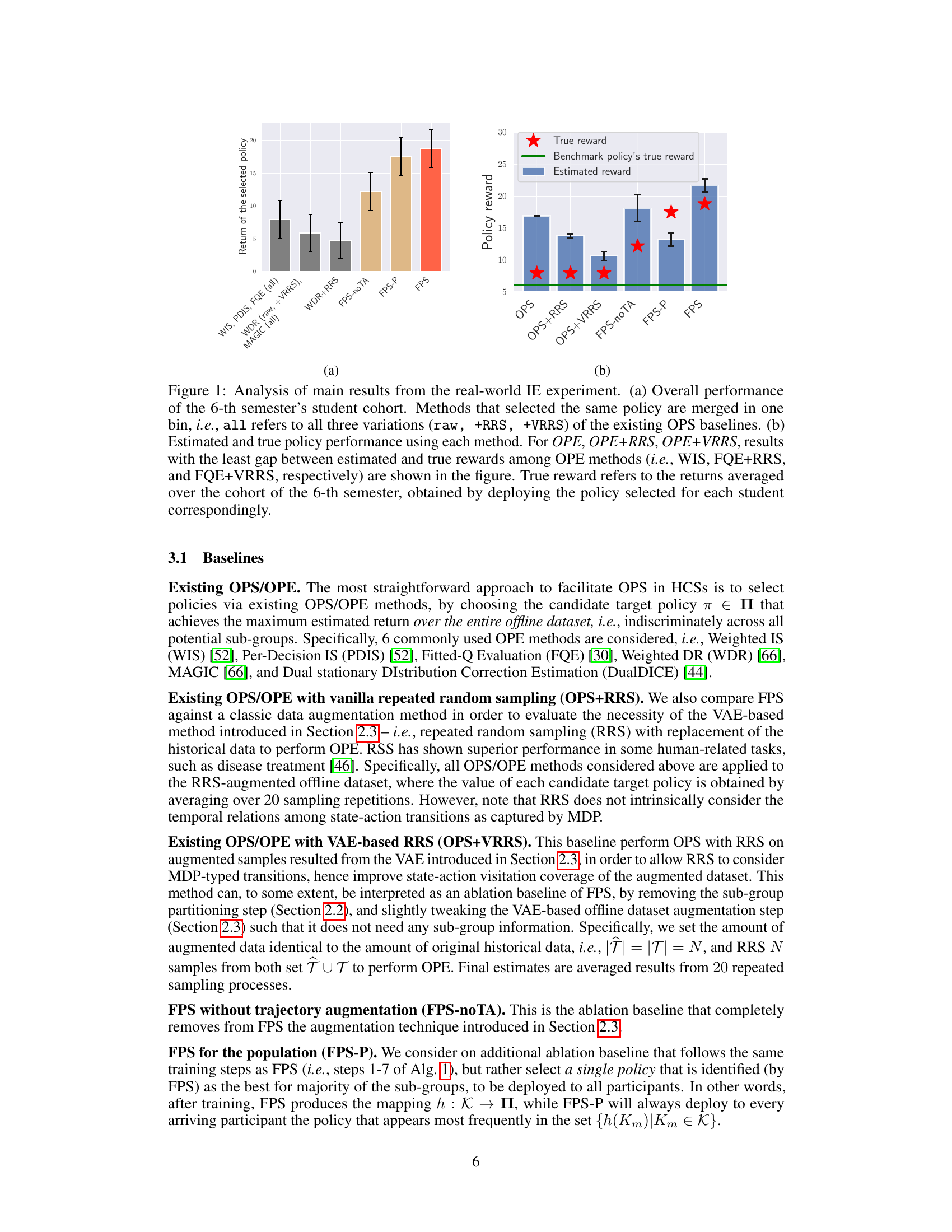
This figure presents the results of a real-world intelligent tutoring system (ITS) experiment. Subfigure (a) compares the overall performance of different off-policy selection (OPS) methods on a student cohort, showing FPS achieved the highest performance compared to existing baselines, which include various importance sampling and doubly robust methods. Subfigure (b) shows the accuracy of the policy performance estimations of the methods, revealing FPS provides better estimation than existing baselines. The true rewards, the benchmark policy’s true reward, and the estimated rewards are displayed for visual comparison across different OPS methods.

This table presents the results of a simulation comparing the performance of FPS against several baselines in a healthcare application for sepsis treatment. The metrics used are Absolute Error (AE) for off-policy evaluation, Return (the accumulative reward) for off-policy selection, and Top-1 Regret. These results illustrate the relative performance of FPS in terms of accuracy and regret in selecting the best treatment policy. The experiment was run multiple times (10 simulations) to assess the robustness of results. The table shows results for different sizes of the offline dataset (N) used for training.
In-depth insights#
Off-Policy in HCS#
Off-policy reinforcement learning presents a powerful paradigm for tackling challenges in human-centric systems (HCSs), such as personalized interventions in healthcare and education. However, the inherent heterogeneity of human participants poses significant obstacles to straightforward application. Traditional off-policy methods often struggle to accommodate the unique characteristics of individuals, necessitating the development of robust techniques that capture and utilize this variability. This necessitates methods capable of effective policy selection for newly arriving participants in HCSs without relying on prior data from those individuals. Overcoming this limitation is critical to the successful deployment of RL-driven personalized interventions in real-world settings. Addressing these key challenges is pivotal to unlocking the full potential of off-policy methods in HCSs and enabling more effective, personalized interventions.
FPS Framework#
The First-Glance Off-Policy Selection (FPS) framework is a novel approach to address the challenge of selecting optimal policies for new participants in human-centric systems (HCSs) without prior data. It cleverly combines sub-group segmentation based on initial participant characteristics with tailored off-policy selection criteria for each subgroup. This personalized approach contrasts with traditional OPS methods which often overlook individual heterogeneity. FPS’s strength lies in its ability to leverage limited initial observations to make effective policy choices for incoming participants, bypassing the need for extensive online data collection. This makes it particularly relevant and practical for HCSs where online testing is costly and time-consuming. The two real-world case studies in intelligent tutoring systems and sepsis treatment showcase its effectiveness and practical value in improving outcomes in challenging scenarios. The combination of sub-grouping and a variance-bounded value function estimator are crucial components contributing to the success of the FPS framework.
Real-World IE#
The ‘Real-World IE’ section likely details the application of intelligent tutoring systems (ITS) in a real-world educational setting. This likely involved a large-scale experiment with numerous students over multiple semesters, directly assessing the impact of different ITS policies on learning outcomes. The use of real student data and a natural learning environment distinguishes this experiment from lab-based studies, making the results more generalizable and impactful. The authors probably present a comparative analysis against various baselines, demonstrating the effectiveness and practicality of their proposed method in a realistic, high-stakes scenario. Key aspects to consider are the methodology used to collect and analyze the data, the metrics employed to evaluate learning gains, and the robustness of the findings given potential confounding factors. Further details would reveal specific insights into the student population, the types of learning interventions used, and the broader implications for educational technology. The success of this real-world implementation holds significant value for both advancing research and informing practical applications of ITS.
Healthcare App#
The application of reinforcement learning (RL) in healthcare is a rapidly evolving field, and this research paper explores its potential through a focus on sepsis treatment. The “Healthcare App,” as described, likely represents a system leveraging RL, specifically off-policy selection (OPS), to personalize treatment interventions. The core challenge lies in the heterogeneity of patients, making generic approaches ineffective. This application likely demonstrates the efficacy of the proposed FPS (First-Glance Off-Policy Selection) method by showing improved sepsis treatment outcomes compared to existing OPS methods. The results highlight the potential of FPS in adapting dynamically to patient-specific characteristics, leading to better treatment plans without relying on extensive pre-existing data. The simulation environment utilized is probably carefully calibrated to reflect real-world complexities such as comorbidities, allowing for a robust evaluation. A key strength is the method’s ability to select policies immediately upon patient arrival, making it immediately applicable in high-stakes scenarios such as sepsis treatment in ICUs.
FPS Limitations#
The First-Glance Off-Policy Selection (FPS) method, while innovative, has limitations. Its reliance on initial state observations for policy selection might overlook crucial information present later in the interaction. This could lead to suboptimal policy assignments, particularly in dynamic human-centric systems where participant behavior evolves. The effectiveness hinges on accurate subgroup partitioning, which demands sufficient data and a robust clustering algorithm. Inadequate partitioning may lead to inaccurate policy recommendations or limit generalization. The need for pre-trained policies is a constraint; generating these policies might be computationally expensive or require significant domain expertise. Furthermore, the success of FPS depends on the assumptions made about initial state distributions and their independence. Violations of these assumptions could negatively impact performance. Finally, while the framework addresses heterogeneity, the ability to capture the full complexity of individual differences within subgroups remains a challenge. Addressing these limitations would enhance FPS’s robustness and applicability across diverse human-centric tasks.
More visual insights#
More on figures

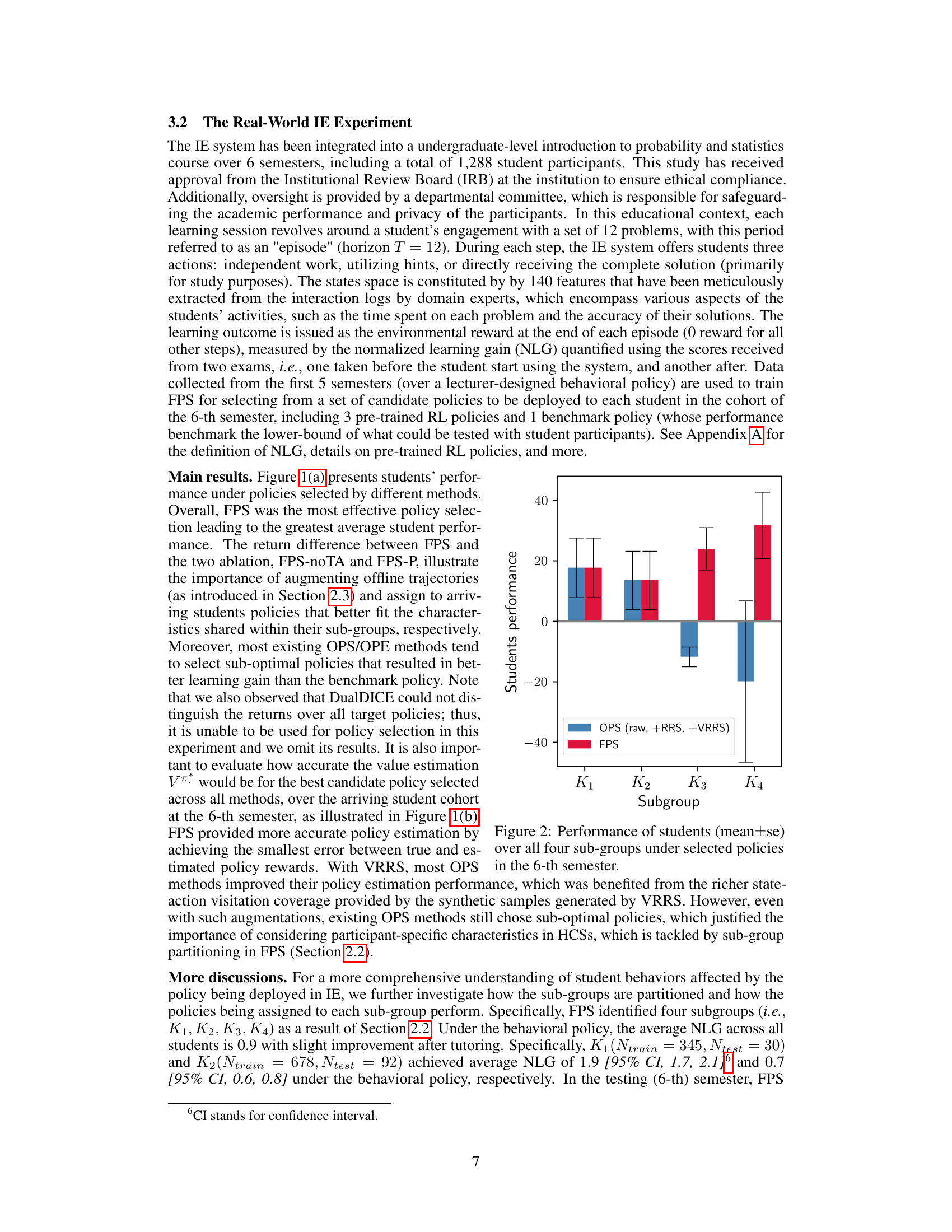
The figure shows the average performance (mean ± standard error) of students across four subgroups (K1, K2, K3, K4) in the 6th semester. Two sets of policies are compared: policies selected by existing OPS methods (including raw, +RRS, and +VRRS variations) and policies selected by the proposed FPS method. The x-axis represents the four subgroups, and the y-axis represents the students’ performance. Error bars illustrate the standard error of the mean.

The figure shows the results of a real-world intelligent education experiment. Subfigure (a) compares the overall performance of different off-policy selection methods on student learning outcomes in the 6th semester, highlighting the superiority of the FPS method. Subfigure (b) contrasts the estimated and true policy performances of various methods, indicating the accuracy and effectiveness of FPS in estimating the true performance of policies.
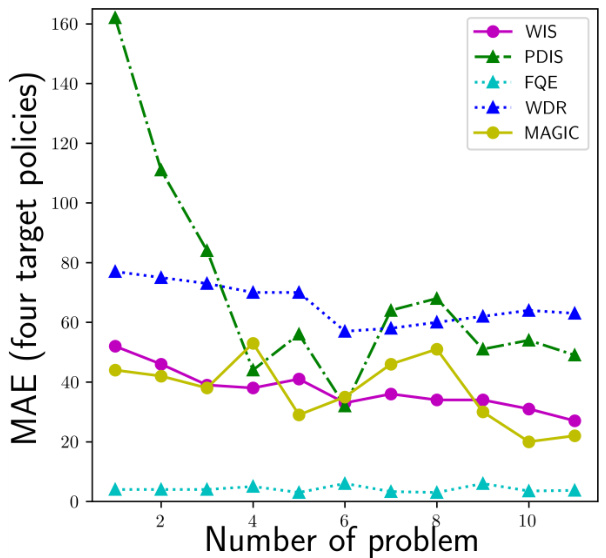
This figure shows the mean absolute error (MAE) for different off-policy evaluation (OPE) methods, specifically WIS, PDIS, FQE, WDR, and MAGIC, when applied with the augmentation method RRS and the subgroup partitioning method on the historical data. The x-axis represents the number of problems included in the trajectory used for evaluation, and the y-axis shows the MAE. The figure aims to illustrate how including more problems (longer trajectories) affects the accuracy of these OPE methods. Generally, MAE decreases with more problems, but the relative performance of these methods remains relatively consistent.
More on tables
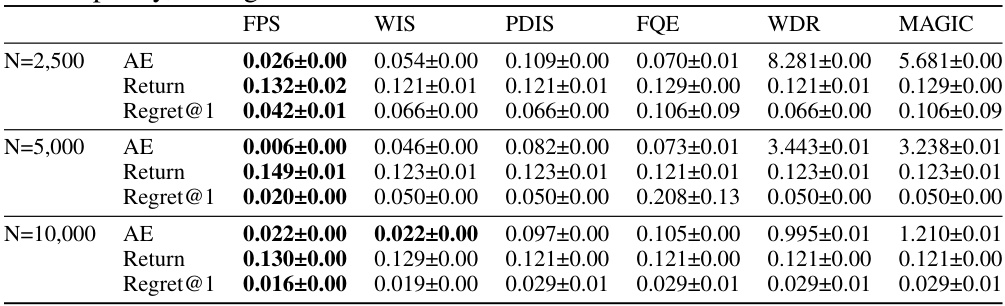
This table presents the results of a sepsis treatment simulation comparing the performance of FPS against several baseline off-policy selection methods. For various dataset sizes (N=2500, 5000, 10000), it shows the absolute error (AE) in estimating the policy return, the actual return obtained, and the top-1 regret, representing the difference between the FPS selected policy and the best performing policy. Lower AE and regret values indicate better performance.

This table presents the performance comparison between FPS and other baselines in a healthcare experiment. It shows the average absolute error (AE), average return, and top-1 regret for different methods across multiple simulation runs, using various sample sizes. Lower AE and higher return indicate better performance.

This table presents the performance comparison of FPS against other baselines in a sepsis treatment simulation. It shows the absolute error (AE) between the estimated and true returns for each policy, the average return for each policy, and the top-1 regret (the difference between the return of the best policy and the return of the selected policy). The results are averaged across 10 different simulation runs, with standard errors provided for each metric. Different sample sizes (N) of offline datasets are evaluated.

This table presents the results of a simulation comparing the performance of FPS (First-Glance Off-Policy Selection) against several baseline methods. The metrics used are Absolute Error (AE), Return, and Regret@1. The table shows how these metrics vary for different numbers of patients (N=2500, 5000, 10000). The results demonstrate FPS’s superior performance in terms of lower error and higher return, especially evident in lower regret@1 values.

This table shows the 20 post-exam problems given to students in the intelligent tutoring system experiment. Each problem tests one or more of the 10 probability principles taught in the course. The table indicates which principles are tested by each problem. There are 14 problems that are isomorphic to the pre-exam and 6 problems that are not.
Full paper#