↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current training-free approaches for spatially grounding text-to-image generation often struggle to accurately place objects within designated bounding boxes, frequently producing imprecise or misaligned results. These methods usually rely on updating noisy images via backpropagation from custom loss functions, which often lack fine-grained control over individual bounding boxes. This paper introduces limitations in previous methods.
The paper introduces GROUNDIT, a novel training-free technique that leverages the flexibility of the Transformer architecture in Diffusion Transformers (DiT). GROUNDIT uses a two-stage approach: (1) Global Update, which uses cross-attention maps for coarse alignment, and (2) Local Update, which utilizes a novel noisy patch transplantation technique for fine-grained spatial control. This method demonstrates improved spatial grounding accuracy across benchmarks and addresses the limitations of prior approaches by achieving more precise spatial control over individual bounding boxes.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and AI due to its novel approach to spatial grounding in text-to-image generation. The training-free method offers significant advancements over existing techniques, which often struggle with precise spatial control, opening avenues for more controllable and creative image synthesis applications. The semantic sharing property discovered in the paper offers valuable insights for improving the flexibility and efficiency of future Transformer-based diffusion models. This research directly addresses the limitations of existing approaches and sets a new state-of-the-art in training-free spatial grounding.
Visual Insights#

This figure shows examples of images generated by the proposed method, GROUNDIT. Each image is accompanied by a text prompt and bounding boxes indicating the desired locations of the objects mentioned in the prompt. The figure highlights the method’s ability to precisely place objects within their designated bounding boxes, a significant improvement over existing methods.
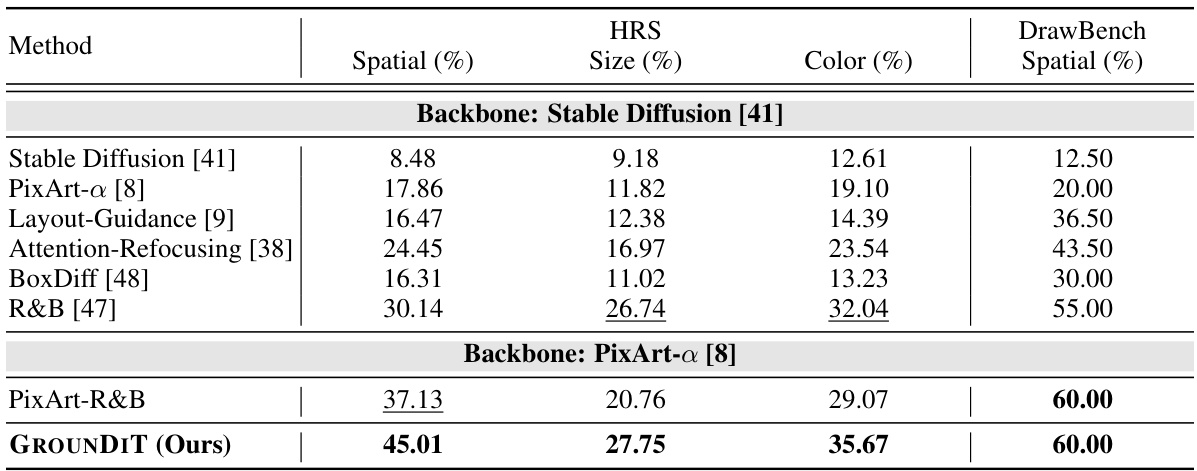
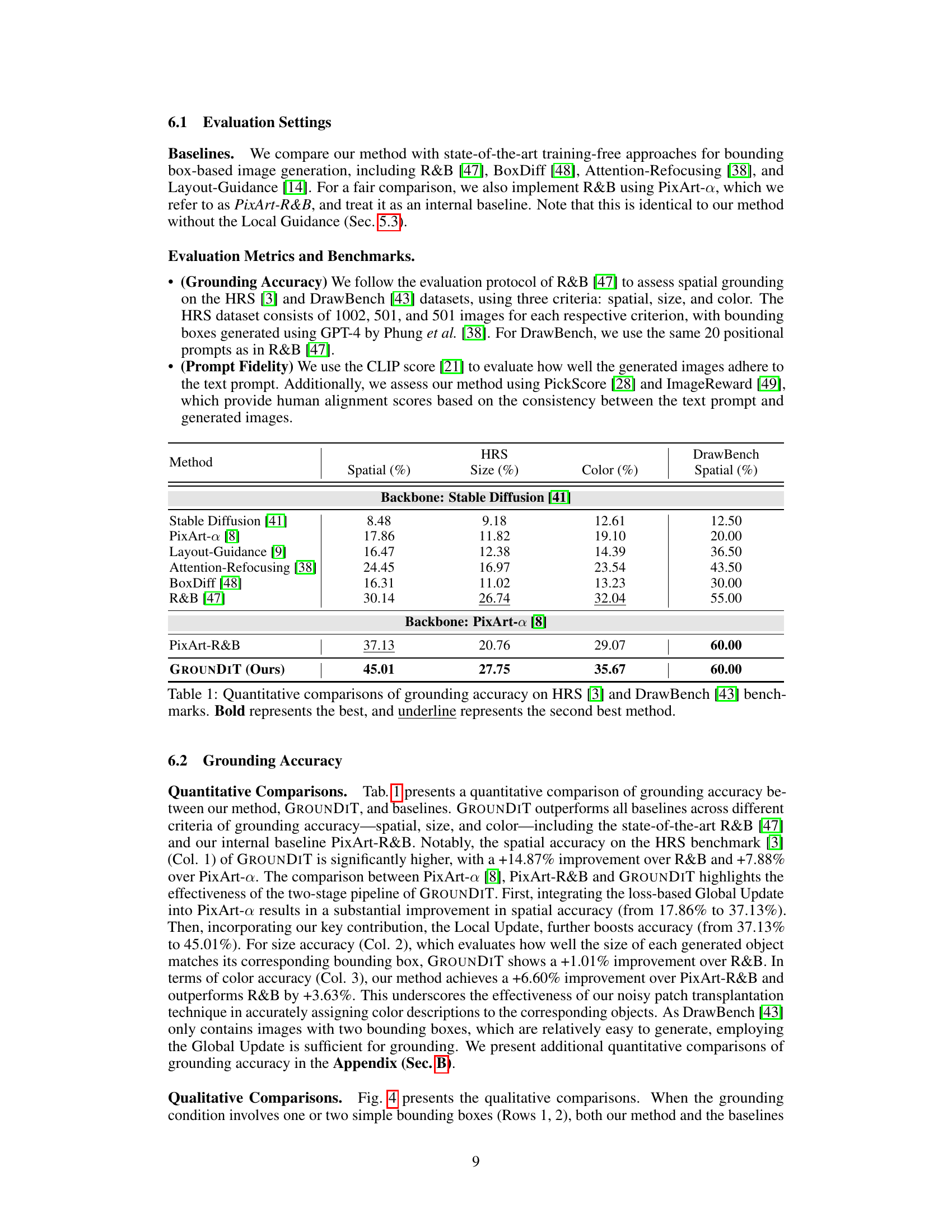
This table presents a quantitative comparison of the grounding accuracy achieved by different methods on two benchmark datasets: HRS and DrawBench. The grounding accuracy is evaluated using three criteria: spatial accuracy (how well the generated objects align with the given bounding boxes), size accuracy (how well the size of generated objects matches the size of the bounding boxes), and color accuracy (how well the color of generated objects matches the color of the objects in the bounding boxes). The results show that GROUNDIT outperforms all other methods across all three criteria on both datasets.
In-depth insights#
Noisy Patch Transplant#
The core idea behind “Noisy Patch Transplantation” is to leverage the power of diffusion models’ ability to denoise images by transplanting carefully generated, smaller noisy patches into larger images. This allows for precise control over specific image regions. The process begins with generating a noisy image patch for each object within bounding boxes specified by the user. These smaller patches are then jointly denoised with portions of the main image to establish a strong semantic connection. The technique is particularly effective because it exploits a phenomenon termed ‘semantic sharing’ in Diffusion Transformers (DiT). Semantic sharing ensures that once the smaller, object-focused patches are jointly denoised with the original noisy image, they essentially become semantic clones of the respective regions in the main image. This approach overcomes limitations of existing training-free methods that struggle with accurate spatial grounding, often resulting in missing objects or inaccurate object placement within bounding boxes. By using this transplantation technique, precise spatial control is achieved, leading to higher-quality image generation that closely matches user expectations.
DiT’s Semantic Sharing#
The concept of “DiT’s Semantic Sharing” reveals a crucial, previously undocumented property of Diffusion Transformers (DiT). Joint denoising of two image patches, even of differing sizes, within DiT leads to semantically correlated content in the resulting denoised patches. This phenomenon, termed semantic sharing, is particularly intriguing because it’s observed even when the initial noise in the patches is entirely different. The implications are significant for spatial grounding in image generation, enabling more precise control than methods relying solely on loss-guided updates. The smaller patch, when jointly denoised with a larger patch, essentially becomes a semantic clone of the corresponding region in the larger image. This allows for robust generation of objects within constrained bounding boxes during image generation. This is because the smaller patch reliably incorporates the desired object features while maintaining compatibility with DiT’s architectural constraints, which prior methods often struggle with. Therefore, semantic sharing in DiT offers a new, powerful tool for enhancing spatial control in image generation models, offering a potentially more efficient and effective path for training-free spatial grounding.
Grounding Accuracy#
The evaluation of spatial grounding, termed “Grounding Accuracy,” is a crucial aspect of the research. The paper employs three key metrics: spatial accuracy, size accuracy, and color accuracy to assess how well the generated images align with the provided bounding boxes. The results reveal a significant improvement in spatial grounding accuracy by the proposed GROUNDIT method over existing training-free methods, particularly concerning challenging conditions with multiple or smaller bounding boxes. GROUNDIT’s novel noisy patch transplantation technique proves effective in ensuring precise object placement. Size and color accuracy show similar gains. These findings highlight GROUNDIT’s superiority in achieving precise spatial control compared to other training-free methods, demonstrating its ability to handle more complex spatial grounding tasks successfully.
Training-Free Grounding#
Training-free grounding in text-to-image synthesis is a significant advancement, aiming to overcome the limitations of traditional fine-tuning methods. Fine-tuning demands substantial computational resources and retraining for each new model, hindering efficiency and scalability. Training-free approaches offer a compelling alternative by leveraging existing models and employing techniques that don’t require additional training. This often involves cleverly manipulating the model’s internal representations, such as attention maps or latent spaces, to guide the generation process based on spatial constraints (e.g., bounding boxes). However, training-free methods often struggle with precise spatial control, leading to imprecise object placement or even missing objects. The core challenge lies in effectively integrating spatial information without retraining, requiring innovative solutions to precisely control the image generation process within the given constraints. Successfully tackling this challenge will lead to more versatile and user-friendly text-to-image models, enabling finer-grained user control and enhanced creative potential.
Future Research#
Future research directions stemming from the GroundDiT paper could explore several promising avenues. Improving the efficiency of the model is crucial, potentially through architectural optimizations or leveraging more efficient diffusion models. The current approach’s computational cost increases significantly with the number of bounding boxes, limiting scalability. Another key area is enhancing the model’s robustness to handle more complex scenarios, such as highly overlapping objects or ambiguous object descriptions in text prompts. This could involve incorporating more sophisticated object detection and segmentation techniques within the framework. Expanding the range of spatial constraints beyond bounding boxes to encompass other forms of user input like sketches or segmentation masks would further enhance user control. Finally, investigating the potential for applying GroundDiT to other image generation tasks beyond text-to-image generation is worth exploring, such as image editing or video generation, to broaden its utility and impact. The semantic sharing concept demonstrated in this research is a particularly interesting avenue for further investigation, possibly leading to breakthroughs in multi-modal generative models.
More visual insights#
More on figures

The figure illustrates a single denoising step in the GROUNDIT framework, which involves two stages: a global update and a local update. The global update utilizes cross-attention maps to perform coarse spatial grounding, while the local update employs noisy patch transplantation for fine-grained spatial control over individual bounding boxes. This process leverages DiT’s semantic sharing property to improve accuracy in generating images that precisely align with user-specified bounding boxes.

This figure demonstrates the concept of joint denoising and semantic sharing in Diffusion Transformers. (A) shows the process of jointly denoising two noisy images of potentially different sizes using DiT by merging their image tokens, processing them through the DiT, and then splitting the denoised tokens back into the two images. (B) and (C) illustrate the effect of semantic sharing, where the joint denoising of two images, initially with different random noise, leads to increasingly similar generated images as the proportion of joint denoising steps (indicated by γ) increases. This effect is observed for images with equal resolutions (B) and different resolutions (C), highlighting the flexibility and intriguing property of semantic sharing in DiT.

This figure presents a qualitative comparison of GROUNDIT against other state-of-the-art training-free spatial grounding methods for text-to-image generation. Each row displays the results for a given text prompt and set of bounding boxes. The leftmost column shows the input bounding boxes provided as spatial constraints. Subsequent columns present results from various baseline methods, such as Layout Guidance, Attention Refocusing, BoxDiff, and R&B. The final column shows the results produced by the proposed GROUNDIT method. The comparison highlights how GROUNDIT consistently and more accurately places objects within the designated bounding boxes, particularly when dealing with more complex scenes or a greater number of bounding boxes.

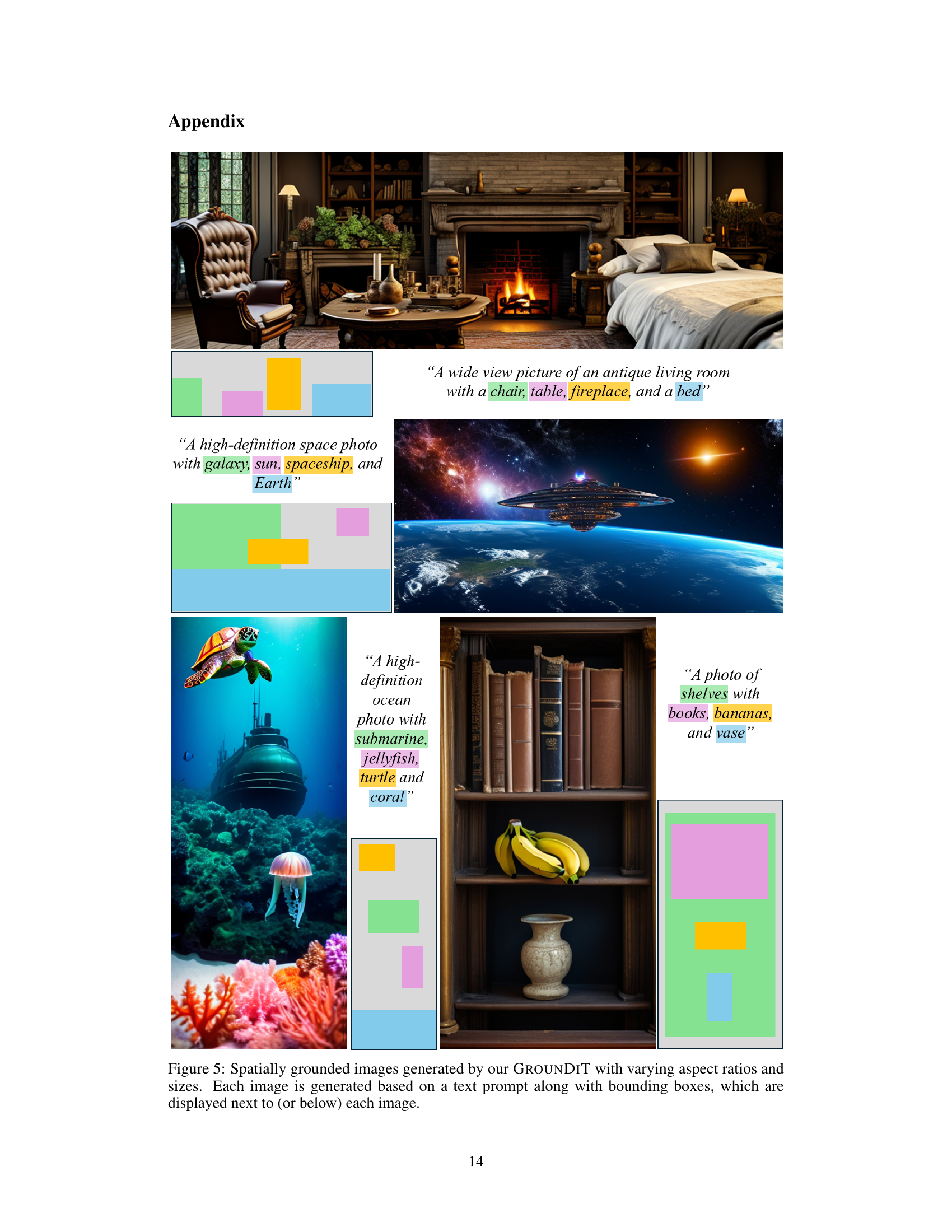
This figure showcases the versatility of the GROUNDIT model in generating images with diverse aspect ratios and sizes, all while accurately placing objects within their specified bounding boxes. Each image is accompanied by a text prompt and its corresponding bounding boxes, highlighting the model’s ability to maintain precise spatial control regardless of the image’s dimensions.

This figure shows several examples of images generated by the GROUNDIT model. Each image is accompanied by a text prompt and bounding boxes indicating the desired location of each object. The key aspect highlighted is the ability of GROUNDIT to handle images with various aspect ratios and sizes, demonstrating its flexibility and robustness in spatial grounding.

This figure demonstrates the limited range of resolutions that the Diffusion Transformer (DiT) model can effectively handle. The experiment uses the text prompt ‘A dog’ and generates images at various resolutions (128x128, 256x256, 288x288, 384x384, 512x512). The results show that while the model can produce reasonable images within a certain resolution range, images generated outside this range (specifically lower resolutions) become significantly less coherent and realistic. This illustrates the concept of ‘generatable resolution’ for the DiT model, a constraint the paper’s method addresses.
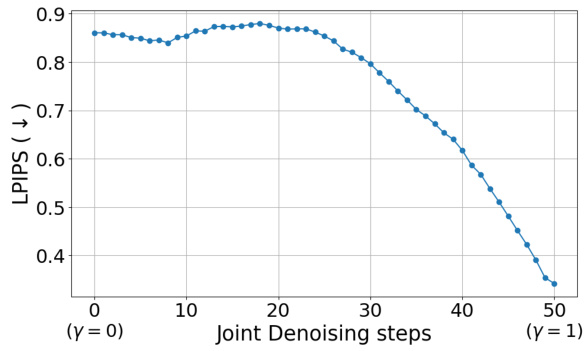
This figure shows the effect of joint denoising on the semantic similarity of two generated images. The x-axis represents the number of joint denoising steps, and the y-axis represents the LPIPS score, a measure of perceptual similarity. As the number of joint denoising steps increases (γ increases from 0 to 1), the LPIPS score decreases, indicating that the generated images become more semantically similar. This demonstrates the concept of ‘semantic sharing’, a key property of Diffusion Transformers exploited in the GROUNDIT model.
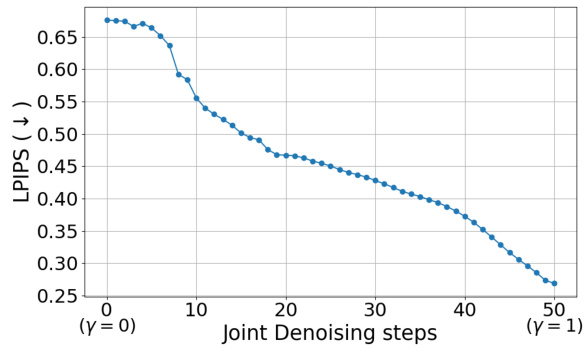
This figure shows the results of an experiment to measure the semantic similarity between two images generated using the joint denoising technique described in the paper. The experiment varies a parameter (γ) that controls the proportion of denoising steps where joint denoising is applied. The x-axis represents the number of joint denoising steps, and the y-axis represents the LPIPS (Learned Perceptual Image Patch Similarity) score, a metric that measures perceptual similarity between images. As γ increases (more joint denoising), the LPIPS score decreases, indicating that the generated images become increasingly similar. This demonstrates the concept of ‘semantic sharing’ where joint denoising causes the two generated images to become semantically correlated.

This figure compares the image generation results of GROUNDIT with several baseline methods for spatially grounded image generation. Each row represents a different text prompt with specified bounding boxes for different objects. The leftmost column displays the bounding boxes provided as input. The following columns show the generated images by different baselines (Layout-Guidance, Attention-Refocusing, BoxDiff, R&B, and PixArt-R&B), and the rightmost column shows the output generated by GROUNDIT. The results demonstrate GROUNDIT’s superior ability to accurately place objects within their designated bounding boxes compared to baselines, especially when handling complex scenes with multiple objects and bounding boxes.

This figure shows more examples of images generated by the proposed GROUNDIT model, showcasing its ability to generate images with multiple objects placed precisely within their corresponding bounding boxes. The layout of the bounding boxes is shown alongside each generated image to demonstrate the accuracy of the spatial grounding achieved. Each image illustrates a different scene, further highlighting the model’s versatility and control over object placement.
More on tables

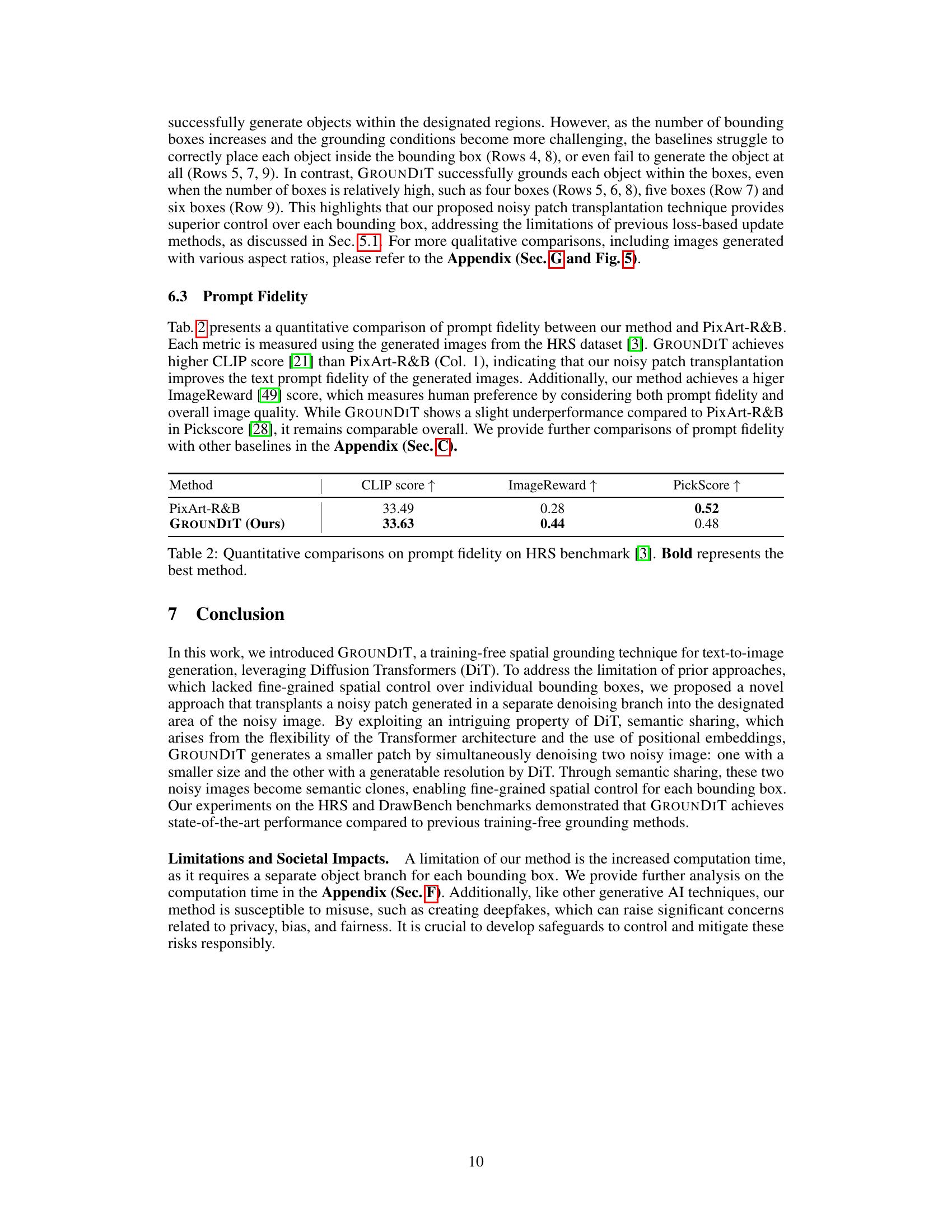
This table presents a quantitative comparison of prompt fidelity between the proposed method (GROUNDIT) and the baseline method (PixArt-R&B). Three metrics are used to evaluate the generated images from the HRS dataset: CLIP score, ImageReward, and PickScore. GROUNDIT demonstrates higher CLIP and ImageReward scores, indicating improved adherence to text prompts and better overall image quality, respectively. While PickScore shows a slight decrease, it remains comparable to the baseline. This highlights the effectiveness of GROUNDIT in generating images that closely match the intended prompt.

This table presents a quantitative comparison of the Intersection over Union (IoU) metric across three different datasets: a subset of MS-COCO-2014, HRS-Spatial, and a custom dataset. The comparison is made between GROUNDIT and several baseline methods. The table highlights the performance of GROUNDIT in terms of spatial grounding accuracy, demonstrating its superiority over the baselines, especially when dealing with a greater number of bounding boxes.
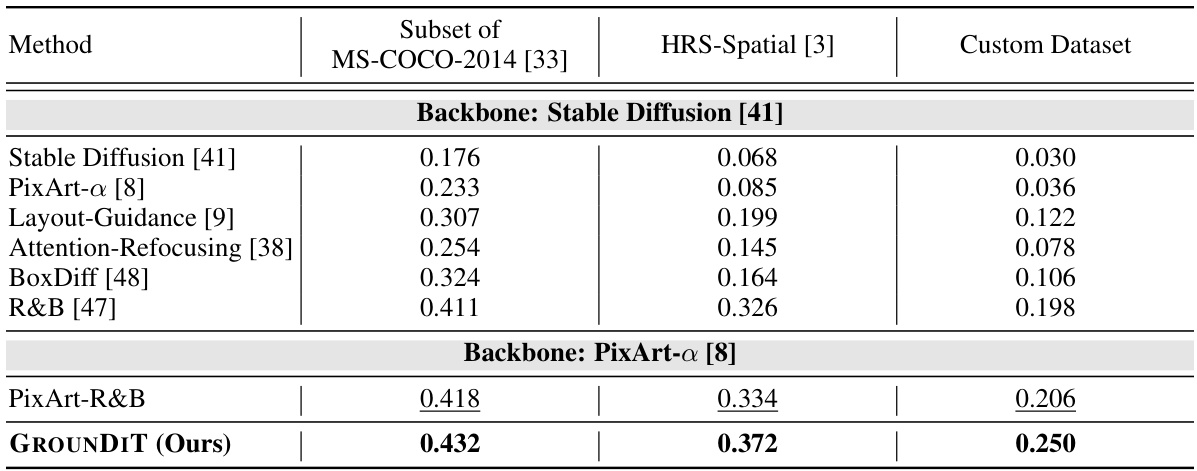
This table presents a quantitative comparison of the mean Intersection over Union (mIoU) scores achieved by different methods on three datasets: a subset of MS-COCO-2014, HRS-Spatial, and a custom dataset. The mIoU metric measures the overlap between the predicted bounding boxes generated by each method and the ground truth bounding boxes. Higher mIoU indicates better spatial grounding accuracy. The table is broken down by backbone model used (Stable Diffusion and PixArt-α), showing the performance of various training-free spatial grounding approaches including Layout-Guidance, Attention-Refocusing, BoxDiff, and R&B, in comparison to the proposed GROUNDIT method. The results highlight GROUNDIT’s superior performance across different datasets, demonstrating its effectiveness in spatial grounding.

This table presents a quantitative comparison of prompt fidelity (how well the generated images adhere to the text prompt) between the proposed GROUNDIT method and the PixArt-R&B baseline. Three metrics are used for evaluation: CLIP score (measures how well the generated image matches the text prompt), ImageReward (measures human preference by considering both prompt fidelity and overall image quality), and PickScore (measures preference between pairs of images). The table shows that GROUNDIT achieves a higher CLIP score and ImageReward compared to PixArt-R&B, indicating better prompt fidelity. The PickScore shows a slight underperformance, but overall, GROUNDIT’s prompt fidelity is comparable to the baseline.

This table presents a quantitative comparison of the spatial grounding accuracy achieved by different methods on two benchmark datasets: HRS and DrawBench. The methods compared include several state-of-the-art training-free approaches for spatial grounding, along with the authors’ proposed method, GROUNDIT. The table shows the performance of each method across three criteria for spatial grounding: spatial accuracy (percentage of objects correctly placed within their bounding boxes), size accuracy (how well the size of the generated object matches the specified size), and color accuracy (how well the generated object’s color matches the specified color). The results demonstrate that GROUNDIT achieves superior performance compared to existing methods on both datasets, particularly in terms of spatial accuracy.

This table compares the average inference time in seconds for different methods (R&B [47], PixArt-R&B, and GROUNDIT) across varying numbers of bounding boxes (3, 4, 5, and 6). It showcases the impact of the number of bounding boxes on the computational cost of each method. GROUNDIT shows a modest increase in inference time as the number of bounding boxes increases, highlighting its scalability.
Full paper#