↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current latent diffusion models suffer from limitations such as inferior visual quality, inadequate aesthetic appeal, and slow inference speed. Existing solutions often address these issues individually, lacking a comprehensive approach. This necessitates a unified framework to enhance diffusion models in all these aspects.
UniFL, a unified framework, leverages feedback learning to comprehensively improve diffusion models. It integrates perceptual feedback learning for visual quality, decoupled feedback learning for aesthetic appeal, and adversarial feedback learning for inference acceleration. Results demonstrate UniFL’s effectiveness in improving generation quality and inference speed across various models, outperforming existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image generation because it presents UniFL, a unified framework that significantly improves the quality and efficiency of latent diffusion models. UniFL addresses key limitations of existing models like low visual quality, poor aesthetics, and slow inference speed by integrating three types of feedback learning. This work opens up new research avenues in feedback learning for diffusion models and provides a strong foundation for future advancements in text-to-image generation.
Visual Insights#

This figure shows several images generated by the UniFL model. The images demonstrate the model’s ability to generate high-quality images in various styles. The caption indicates that the first two rows of images were generated using 20 inference steps, while the last three images in the bottom row used only 4 steps, highlighting the model’s efficiency.

This table presents a quantitative comparison of UniFL against several other state-of-the-art methods for improving the quality and speed of image generation using two different diffusion models: SD1.5 and SDXL. Metrics include FID (Fréchet Inception Distance), CLIP score (measuring text-image alignment), and aesthetic score. The results show UniFL’s superior performance across various metrics and different inference steps (20 steps and 4 steps).
In-depth insights#
Unified Feedback#
A unified feedback mechanism in machine learning models offers a holistic approach to training and optimization. Instead of treating different aspects of model performance (e.g., visual quality, aesthetic appeal, inference speed) in isolation, a unified framework integrates multiple feedback signals to improve these aspects concurrently. This synergistic approach leverages the strengths of various feedback modalities, potentially leading to superior performance compared to methods addressing each aspect individually. The core challenge lies in effectively combining and weighting diverse feedback sources, ensuring that they complement rather than conflict with each other. Successfully implementing a unified feedback strategy often involves careful design of loss functions and optimization algorithms to handle potentially conflicting objectives. Careful consideration of the type and quality of feedback, along with robust handling of noise and uncertainty, are also vital to the success of a unified framework. The potential benefits of unified feedback are significant, enabling models to achieve higher overall performance and address multiple limitations simultaneously.
Perceptual Learning#
Perceptual feedback learning, a core component in many advanced AI models, focuses on improving model performance by incorporating human-like perception. Instead of relying solely on numerical metrics like pixel loss, perceptual learning leverages pre-trained perception models (e.g., image segmentation, style transfer networks) to provide richer, more nuanced feedback. This shift from simple error minimization to higher-level perceptual evaluation allows the model to learn more robust features and generate outputs that are not just numerically accurate but also perceptually pleasing and realistic. The use of pre-trained models is a key strength as it significantly reduces the computational cost and data requirements. However, selecting appropriate pre-trained models and integrating their feedback effectively remains a significant challenge. The success of perceptual learning heavily depends on the quality and relevance of the perceptual models employed, the effective integration of their outputs, and the ability to guide the overall model training towards a perceptual goal. Future research may need to address these challenges by developing more sophisticated methods for model selection and integration, exploring the use of multiple perceptual models to capture various aspects of visual quality, and devising robust training strategies that balance perceptual and numerical objectives. Ultimately, the continuous evolution of this field promises remarkable advancements in AI’s ability to generate high-fidelity, human-quality outputs.
Aesthetic Feedback#
Aesthetic feedback, in the context of generative models, presents a fascinating challenge. It tackles the inherently subjective nature of human judgment of beauty. The core idea is using feedback to guide a model toward generating images that humans find aesthetically pleasing. A key question is how to effectively collect and represent this feedback. Simple ratings might be insufficient, requiring more nuanced methods such as pairwise comparisons or fine-grained annotations of specific aesthetic aspects (color palette, composition, lighting). Another major challenge lies in translating human preferences into a form that a model can understand and use for optimization. Reward models are often employed, learning to predict human preferences from labeled data. However, this approach relies heavily on the quality and quantity of the training data, and the reward model itself might introduce bias or artifacts. Adversarial methods could offer a means of fine-tuning, pitting a discriminator (reward model) against the generator to continuously improve the quality of generated outputs based on aesthetic feedback. The effectiveness of this approach depends on balancing the feedback’s impact on model speed and quality. Finally, the broader implications of this field extend beyond simple image generation; future research could investigate applications to other creative domains and address potential ethical concerns around automated aesthetic judgments.
Adversarial Training#
Adversarial training, in the context of generative models, is a powerful technique to enhance model robustness and efficiency. It involves framing the model improvement process as a game between two players: the generator and a discriminator. The generator attempts to produce realistic outputs that fool the discriminator, while the discriminator strives to accurately identify generated samples. This competitive setup pushes both components to improve—the generator to create increasingly realistic samples and the discriminator to become more discerning. In latent diffusion models, adversarial training can significantly reduce the number of denoising steps required during inference, directly translating to faster generation times. This acceleration is achieved by enabling the generator to produce high-quality images even with fewer iterations, thereby boosting the model’s efficiency without sacrificing quality. The key benefit is accelerated inference, a significant advantage considering the computational demands of generative models. However, careful implementation is crucial; improper adversarial training might lead to instability or overfitting, causing the generator to collapse into producing low-quality, repetitive outputs. Careful tuning of hyperparameters and regularization techniques are vital to harness the benefits of adversarial training effectively. Furthermore, the introduction of adversarial components can introduce additional complexity to training, potentially requiring adjustments in the training schedule and learning rates. This technique represents a promising avenue for optimizing the efficiency of generative models while preserving, or even improving, the quality of the generated output. The success of adversarial training highly depends on the careful design and balance between the generator and discriminator.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency and scalability of UniFL is crucial, particularly for handling extremely high-resolution images or complex scenes. Investigating alternative feedback mechanisms, beyond the perceptual, aesthetic, and adversarial approaches, such as incorporating reinforcement learning or evolutionary algorithms, might unlock further performance gains. Extending UniFL to other generative models, beyond diffusion models, such as GANs or VAEs, would demonstrate its broader applicability and robustness. Finally, a thorough investigation into the ethical implications of enhancing image generation capabilities, especially regarding the potential for misuse in creating deepfakes or other forms of misinformation, is warranted. Addressing these challenges could solidify UniFL’s position as a leading framework for advancing the state-of-the-art in generative AI.
More visual insights#
More on figures
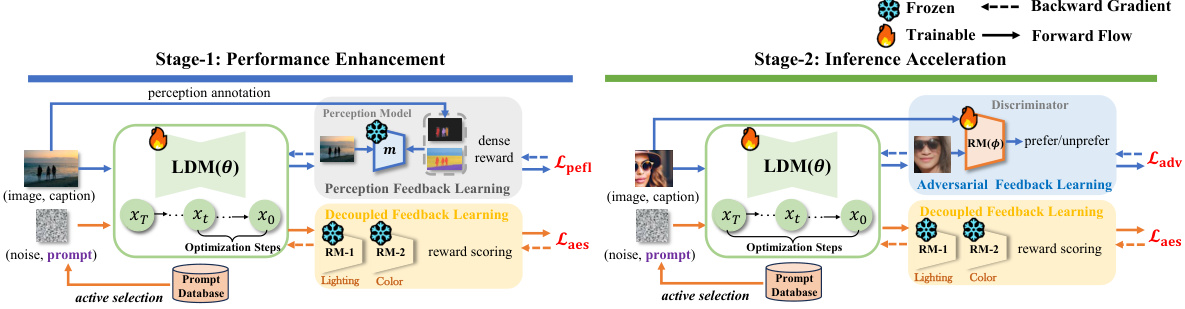
This figure shows the overview of the UniFL framework, which is divided into two stages. Stage 1 focuses on performance enhancement by improving visual quality and aesthetics using perceptual feedback learning and decoupled feedback learning. Stage 2 focuses on inference acceleration using adversarial feedback learning and decoupled feedback learning. The figure illustrates the flow of data and the interaction between different components of the framework.

This figure provides a visual overview of the UniFL framework, illustrating its two-stage training process. The first stage focuses on enhancing visual quality and aesthetic appeal through perceptual and decoupled feedback learning. The second stage accelerates inference speed via adversarial feedback learning. The diagram shows the flow of data and the interactions between the different components of the model.

This figure shows a qualitative comparison of image generation results from different methods, all based on the SDXL model. The top row shows images generated from the prompt ‘A high-contrast photo of a panda riding a horse. The panda is wearing a wizard hat and is reading a book.’ The bottom row shows images generated from the prompt ‘A bloody mary cocktail.’ The columns show the results from SDXL base model, SDXL with DPO, SDXL with ImageReward, SDXL with UniFL, SDXL with LCM (4 steps), SDXL with Turbo (4 steps), and SDXL with UniFL (4 steps). This allows for visual comparison of the image quality and stylistic differences produced by each method and the impact of using fewer inference steps with UniFL.

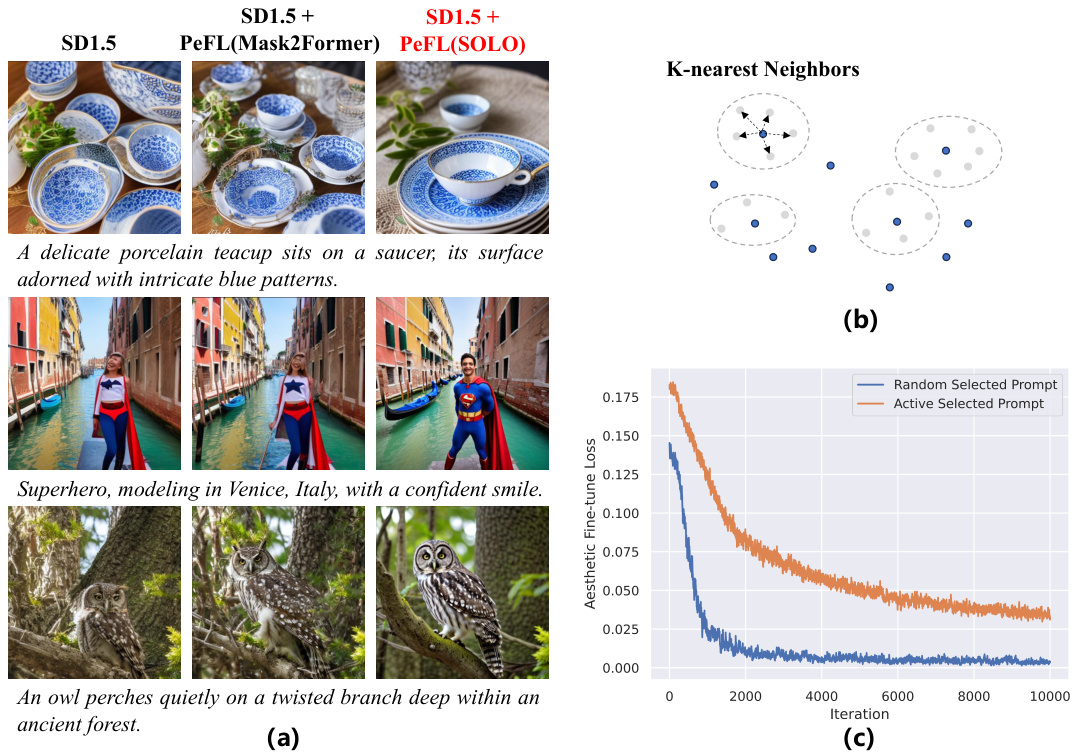
This figure shows the results of using perceptual feedback learning (PeFL) with the SOLO instance segmentation model to improve the structure of generated images. (a) illustrates the process of PeFL, showing the ground truth image, the ground truth segmentation mask, the predicted segmentation mask, and the generated image with improved structure. (b) visually demonstrates the positive effects of PeFL on structure optimization, highlighting improved structural accuracy.
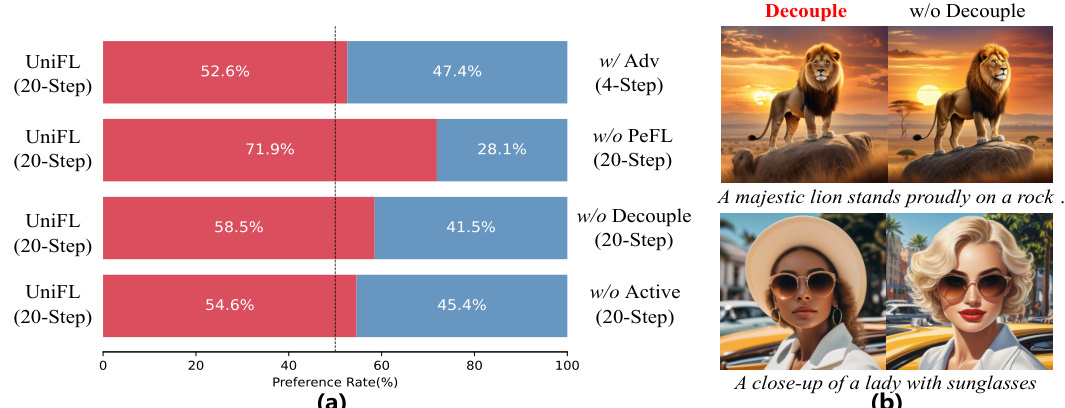
This figure presents the ablation study of UniFL, showing the impact of each component on the model’s performance. (a) shows a bar chart illustrating the preference rates for UniFL with different components removed (adversarial feedback learning, perceptual feedback learning, decoupled feedback learning, and active prompt selection). (b) provides a visual comparison of image generation results with and without decoupled aesthetic feedback learning, highlighting the improved aesthetic appeal achieved through decoupling.
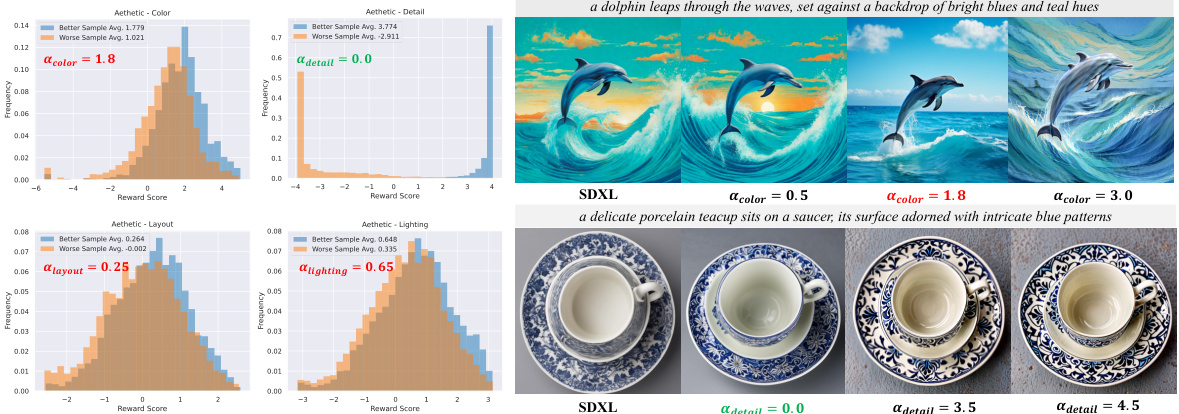
This figure shows the distribution of reward scores for different aesthetic aspects (color, detail, layout, lighting) obtained from 5,000 validation preference image pairs. The left side displays histograms showing the distribution of reward scores for each aspect, with the optimal hinge coefficient (ad) values highlighted. The right side shows an ablation study on the effect of varying the hinge coefficient (ad) for color and detail, demonstrating how different ad values influence the generated images. The images illustrate how the choice of ad impacts the color and detail aspects of the generation.

This figure shows the results of applying style and structure optimization objectives simultaneously using the perceptual feedback learning (PeFL) method. The left side demonstrates the results for the prompt ‘a strong American cowboy with dark skin stands in front of a chair.’ It illustrates that adding style optimization on top of structure optimization doesn’t negatively impact the structure; instead, both are improved. The right side shows the same for the prompt ‘a baby Swan, graffiti.’ This shows that PeFL can effectively incorporate multiple visual aspects and improve both simultaneously without negative interference.

This figure shows the overall architecture of UniFL, a unified framework that enhances latent diffusion models. It’s divided into two stages: Stage 1 focuses on improving visual quality and aesthetics through perceptual and decoupled feedback learning. Stage 2 focuses on accelerating inference speed using adversarial feedback learning. The figure illustrates the flow of data and the interaction between different components within the framework.

This figure shows the results of an ablation study on the number of inference steps used by UniFL. The top row shows images generated using 25 steps with the SDXL model and then using UniFL with 8, 4, 2, and 1 steps, respectively. The same process is repeated for the LCM and SDXL-Turbo models in the subsequent rows. The goal is to demonstrate how the quality of the generated images changes as the number of steps decreases, highlighting the effectiveness of UniFL in generating high-quality images even with a significantly reduced number of steps.

This figure shows a comparison of style optimization using PeFL on two different diffusion models, Stable Diffusion 1.5 (SD1.5) and Stable Diffusion XL (SDXL). The images demonstrate the improved style generation achieved by incorporating PeFL. Each row represents a different artistic style (impasto, oil painting, frescos, Victorian) applied to a prompt (family portrait, tree, girl, woman in a dress). The leftmost column shows the results from the base model, the middle shows results with pre-trained style, and the rightmost shows results using PeFL for style optimization. The aim is to show that PeFL significantly enhances style consistency and accuracy compared to just using pre-trained styles.

This figure provides a visual overview of the UniFL framework, highlighting its two-stage training process. Stage 1 focuses on enhancing visual quality and aesthetics using perceptual and decoupled feedback learning. Stage 2 concentrates on accelerating inference speed through adversarial feedback learning. The diagram showcases the interplay between the latent diffusion model (LDM), various feedback modules (PeFL, Decoupled Feedback Learning, Adversarial Feedback Learning), and the optimization process, demonstrating a unified approach to improving various aspects of the LDM.

This figure demonstrates the Perceptual Feedback Learning (PeFL) method. Subfigure (a) shows the process of PeFL using the SOLO instance segmentation model. It takes an image and its corresponding ground truth segmentation mask as input. The model predicts the segmentation mask for the generated image and calculates the loss between the predicted mask and the ground truth mask. Subfigure (b) visualizes the results of PeFL on structure optimization, showing how it improves the structure of the generated image by comparing images generated with and without PeFL. The examples show improvements in object structure details.

This figure presents the results of a user study comparing UniFL with other methods in terms of generation quality and inference speed. Ten users evaluated 500 image prompts generated by UniFL and competing methods. The left side shows the user preference for generation quality (good, same, bad), while the right side displays user preference for inference speed (fast, same, slow). The bar charts visually represent the percentage of users who preferred each method in each category, providing a clear comparison of UniFL’s performance against other models.
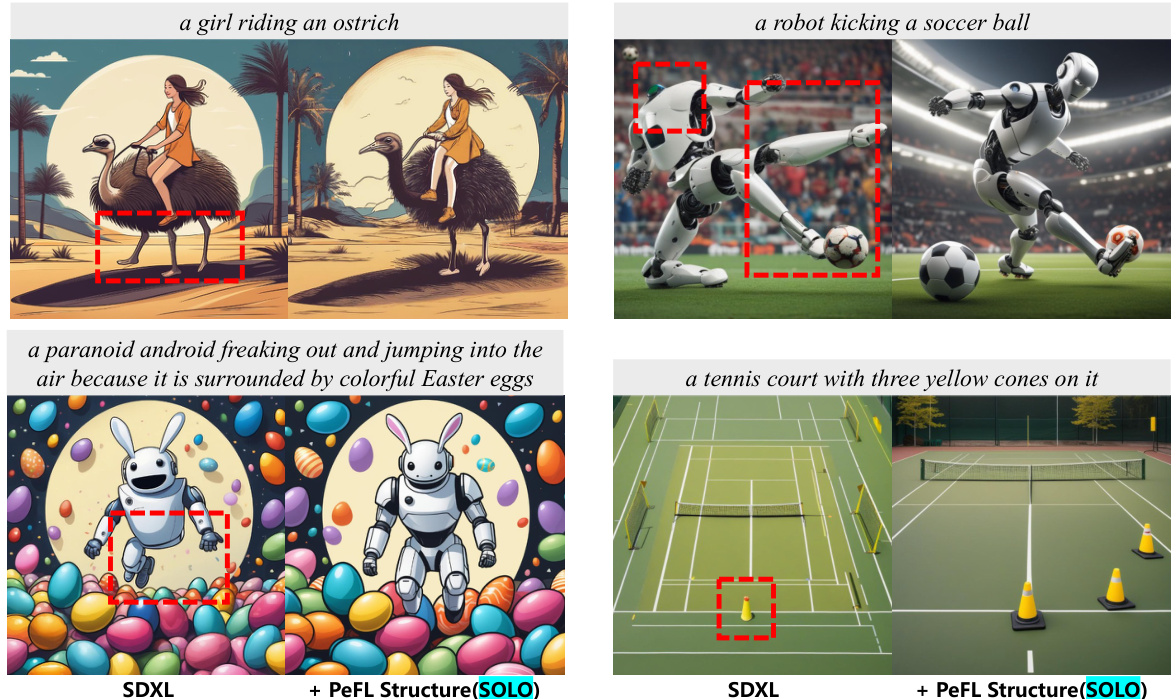
This figure demonstrates the generalization ability of the Perceptual Feedback Learning (PeFL) method. Even though PeFL uses a model trained on the COCO dataset (which has a limited set of concepts), the improved image generation is not limited to those concepts. The examples shown illustrate that the method also improves generation of images with concepts not present in the COCO dataset, such as ostriches, robots, and traffic cones. This shows that the method is not overly reliant on the training data and can generalize to a broader range of subjects.

This figure shows the overall architecture of UniFL, a unified feedback learning framework for enhancing latent diffusion models. UniFL is a two-stage process. Stage 1 focuses on improving visual quality and aesthetics using perceptual, decoupled aesthetic, and active prompt selection feedback learning. Stage 2 accelerates inference speed using adversarial feedback learning. The diagram illustrates the flow of data and the interaction between the different components of the model.
This figure shows images generated using the UniFL method. The top two rows demonstrate images generated with a 20-step inference process, while the bottom row highlights images generated with a faster 4-step process, showcasing the inference speedup achieved by UniFL.

This figure shows the results of applying UniFL to both Stable Diffusion 1.5 and SDXL, demonstrating their ability to adapt to different styles even when using fewer denoising steps. The images showcase the successful application of UniFL with various LoRA (Low-Rank Adaptation) models for different artistic styles like Anime Lineart, Pixel Art XL, and others, and also its integration with ControlNet for more sophisticated image manipulations.

This figure shows a qualitative comparison of image generation results from different methods using the Stable Diffusion XL model. Each row presents the same text prompt and shows the generated images from the base SDXL model and several other methods including DPO, ImageReward, LCM, SDXL Turbo, and UniFL. This allows for visual comparison of image quality and style across different models and inference steps. The examples chosen highlight the strengths and weaknesses of each approach in terms of visual detail, coherence, and artistic style.
Full paper#



















