↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) are increasingly used for collaborative tasks, but their debates often suffer from issues like echo chambers (where similar models reinforce each other’s biases) and shared misconceptions. This limits the accuracy and reliability of the results. The paper identifies and analyzes these issues.
To address these problems, the paper proposes a novel theoretical framework for analyzing LLM debates. This framework is used to design three interventions that improve debate efficacy: diversity-pruning (maximizes information entropy), quality-pruning (selects the most relevant responses), and misconception-refutation (identifies and corrects errors). Experiments show that these interventions consistently lead to better performance across multiple benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multi-agent systems, large language models, and decision-making. It offers a novel theoretical framework and practical interventions to enhance the effectiveness of LLM debates, paving the way for improved AI collaboration and more reliable outcomes. The proposed methods are generalizable and have potential implications for various AI applications. The identified limitations also encourage future research in these areas.
Visual Insights#
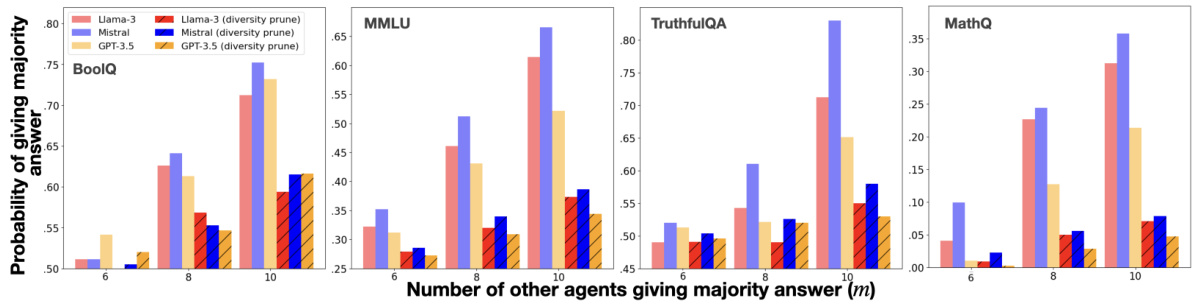
This figure shows the probability that a model will echo the majority answer at round 11 of a debate, given that a certain number of models provided that same answer at round 0. The x-axis represents the number of models giving the majority answer at round 0 (m), and the y-axis shows the probability of a single model echoing this majority opinion at round 11. Different colored bars represent different language models (Llama-3, Mistral, GPT-3.5). The striped bars show the result after applying a diversity pruning intervention. The figure illustrates the effect of ’echo chambers’ in multi-agent debate and how diversity pruning mitigates this effect.

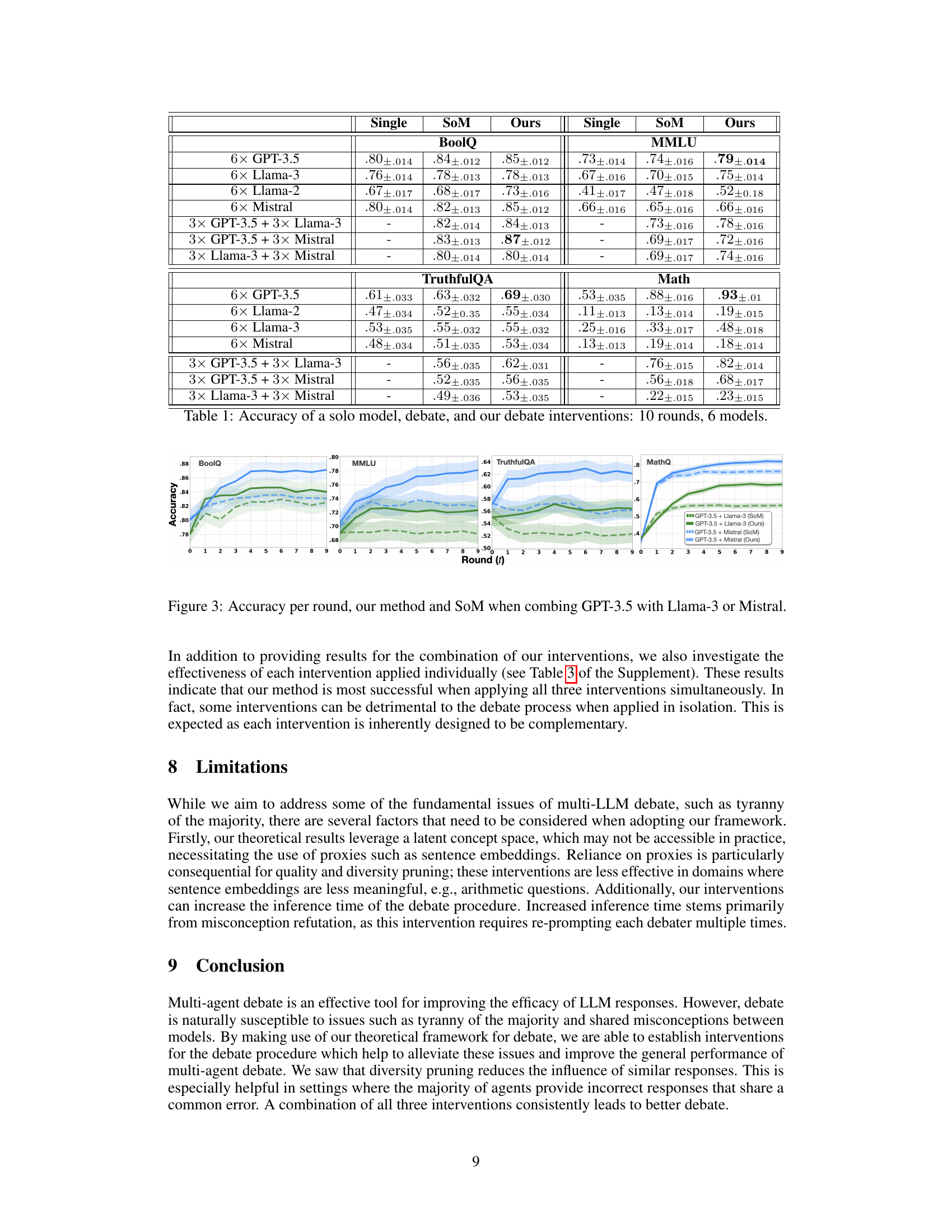
This table presents the accuracy results of four different settings: using a single model to answer the questions, the original multi-agent debate method, and the proposed method with three different model combinations. The accuracy is measured across four different benchmark datasets (BoolQ, MMLU, TruthfulQA, MathQ) and with different numbers of models (6 models of a single type and 3 models of two different types). The results demonstrate the improvement in accuracy achieved by the proposed approach.
In-depth insights#
Debate Framework#
The core of this research paper centers around a novel debate framework designed for multi-agent large language models (LLMs). This framework moves beyond simple collaborative question-answering, instead framing the debate process as a form of Bayesian inference and in-context learning. By modeling agent responses as stemming from underlying latent concepts, the authors mathematically analyze debate dynamics, highlighting the potential for echo chambers and the importance of response diversity. The framework’s strength lies in its ability to theoretically justify and guide the design of interventions, such as diversity pruning and quality pruning, which are shown to mitigate problematic tendencies and improve the efficacy of the multi-LLM debate process. The mathematical rigor of the framework makes it a significant contribution towards a deeper understanding of LLM collaboration and provides a solid foundation for future research in this rapidly evolving area. The focus on latent concepts offers a particularly insightful approach, going beyond the surface level analysis of individual agent responses to uncover underlying conceptual agreement or disagreement.
Intervention Effects#
The effectiveness of interventions to improve multi-LLM debate hinges on addressing fundamental issues like echo chambers and shared misconceptions. Diversity pruning, by maximizing information entropy, successfully combats echo chambers, ensuring a broader range of perspectives are considered. Quality pruning, prioritizing relevant responses, focuses the debate on crucial information. Misconception refutation directly tackles inaccurate beliefs ingrained in the models, leading to more accurate conclusions. Theoretical analysis supports these interventions’ efficacy, demonstrating that they counteract the negative effects of homogeneity, resulting in improved performance across various benchmarks. The synergy between these interventions underscores their complementary nature—each tackles a distinct aspect of debate’s limitations, resulting in significantly improved outcomes and demonstrating a more robust and effective debate process. Empirical results validate these theoretical findings.
Echo Chamber Effect#
The “Echo Chamber Effect” in multi-agent large language model (LLM) debates describes a phenomenon where models with similar capabilities or initial responses converge towards a consensus, even if that consensus is incorrect. This is especially problematic when the models share a common misconception, potentially stemming from biases in their training data. The shared training data creates a homogeneity of thought, hindering the debate’s ability to explore diverse perspectives and reach a more accurate conclusion. This effect is amplified as the number of similar models increases, creating a reinforcing feedback loop where dissenting opinions are overshadowed. Diversity-pruning interventions, which aim to maximize the information entropy in model responses, are crucial to mitigate this problem by actively introducing varied perspectives and disrupting the echo chamber. These interventions are essential to promote more robust and accurate outcomes in multi-agent LLM debates.
Diversity’s Role#
The concept of diversity plays a crucial role in the success of multi-agent language model debates. A lack of diversity, whether in model capabilities or in the range of responses generated, can lead to stagnation and an echo chamber effect where the debate converges on a single, possibly erroneous, viewpoint. Promoting diversity, on the other hand, increases the information entropy of the debate, allowing for a more robust exploration of the topic and increasing the likelihood of reaching a correct conclusion. This can be achieved through various interventions such as diversity pruning, which selects responses that maximize information entropy, or by ensuring a variety of model architectures are involved. However, simply increasing the number of models is not sufficient, as similar models will likely reinforce the same biases, hindering the beneficial effects of diversity. Therefore, a well-designed debate mechanism must actively manage and nurture diversity to ensure its effectiveness.
Future Research#
Future research directions stemming from this multi-LLM debate framework could explore several key areas. Improving the theoretical framework itself is crucial; refining the latent concept modeling to better capture nuances in language generation and integrating different types of LLMs with varying strengths and weaknesses would enhance the model’s accuracy and efficiency. Investigating new interventions to mitigate echo chamber effects and the spread of misinformation is of paramount importance. This could involve developing advanced pruning strategies based on more sophisticated measures of information entropy or creating novel refutation techniques that leverage external knowledge sources or human-in-the-loop verification. Understanding and addressing the limitations of current methods in diverse domains is crucial. This would require rigorous testing and validation across various tasks and datasets. Finally, researching ethical implications of using multi-agent LLMs in real-world applications would be essential before widespread deployment. This includes examining issues of bias, fairness, and transparency in the debate process, ensuring responsible use of this powerful technology.
More visual insights#
More on figures
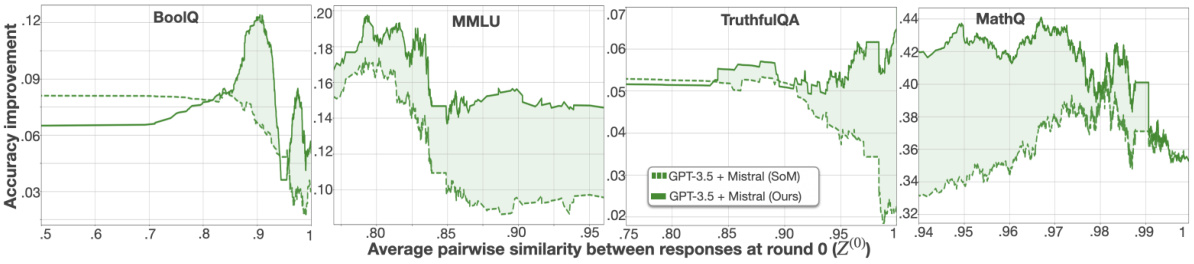
This figure shows how the accuracy improvement of the proposed method and the baseline method (SoM) changes as a function of response diversity at round 0. Response diversity is measured by the average pairwise similarity between responses at round 0. The results are shown separately for four datasets: BoolQ, MMLU, TruthfulQA, and MathQ. The figure demonstrates that the proposed method consistently outperforms the baseline method, especially when the response diversity is low (high similarity). The effectiveness is more significant in BoolQ, MMLU, and TruthfulQA, while the improvement is not that substantial in MathQ.

This figure compares the accuracy of the proposed method and the Society of Minds (SoM) method across different rounds of debate. Two model combinations are shown: GPT-3.5 and Llama-3, and GPT-3.5 and Mistral. For each combination, two lines are plotted, representing the accuracy of SoM and the proposed method. The shaded area around each line represents the confidence interval. The plot shows how accuracy evolves over the course of the debate for each method and model pair, highlighting the differences in performance between the proposed method and SoM. The x-axis represents the round of debate, and the y-axis shows the accuracy.
More on tables

This table presents the accuracy results of four different methods for solving tasks using large language models (LLMs): a single LLM, the standard multi-LLM debate method, and the proposed method with three interventions (diversity pruning, quality pruning, and misconception refutation). It shows the accuracy for each method across four different benchmark datasets (BoolQ, MMLU, TruthfulQA, and MathQ) and for various combinations of six LLMs. The results demonstrate the improvement in accuracy achieved by using the proposed multi-LLM debate method with the three interventions compared to using a single LLM or the standard multi-LLM debate approach.

This table shows the accuracy results of four different settings: using a single model to answer questions, using the original multi-agent debate method, and two versions of the proposed method with and without the interventions. Each setting was tested using 6 models (either all the same type or a mix of different types) and 10 rounds of debate for the BoolQ, MMLU, TruthfulQA, and MathQ datasets. The table allows a direct comparison of accuracy across the different approaches.
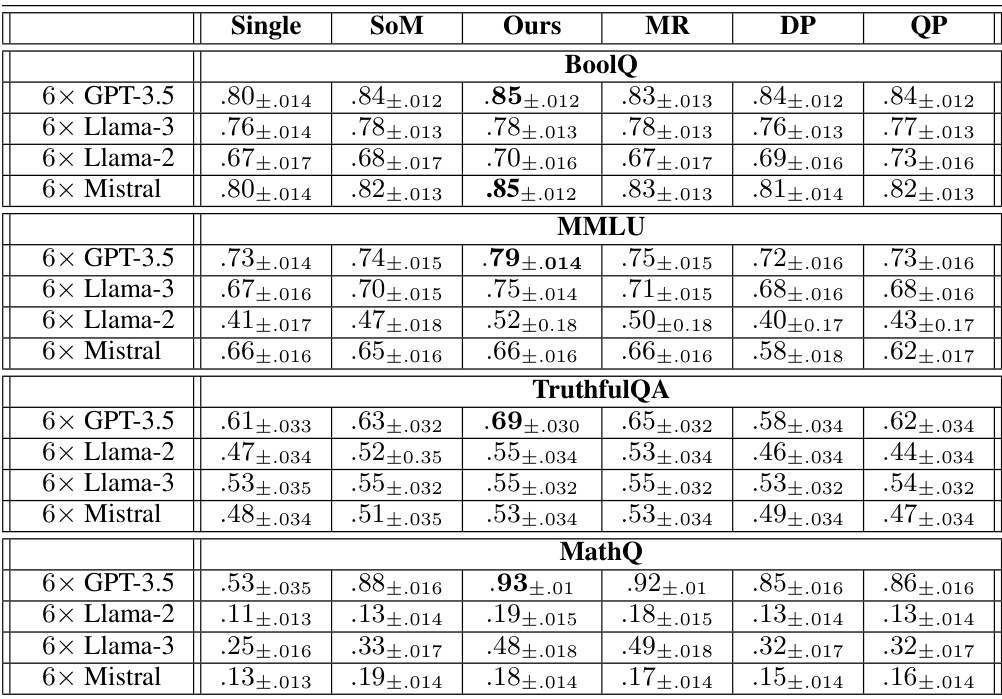
This table presents the accuracy results of four different experimental setups: using a single model, using the standard multi-agent debate method, using the proposed method with the three interventions combined, and using each intervention individually. The table shows the accuracy for each setup across four different benchmark datasets (BoolQ, MMLU, TruthfulQA, MathQ) and four different language models (GPT-3.5, Llama-2, Llama-3, Mistral). The results demonstrate the improvement in accuracy achieved by the proposed method compared to the baseline methods.
Full paper#