↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Adapting large language models (LLMs) to specific tasks efficiently is crucial, but existing methods often involve storing multiple task-specific adapters at the server, creating scalability issues. Prompt tuning offers a simpler solution but underperforms compared to other techniques. This paper addresses this by introducing LoPA, a novel approach that generates soft prompts combining task-specific and instance-specific information.
LoPA uses a low-rank decomposition for efficiency. The results show that LoPA performs comparably to state-of-the-art techniques, even full fine-tuning, while being more parameter-efficient and not requiring server-side adapters. This makes LoPA a highly effective and scalable approach for customizing LLMs. It achieves these results by balancing between shared task information and instance-specific adaptations, using a gating function to combine task and instance components and a low-rank decomposition to reduce the number of parameters. This is a significant contribution as LoPA combines the advantages of prompt tuning (simplicity, efficiency) with the superior performance of other parameter-efficient fine-tuning methods.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces a novel parameter-efficient fine-tuning method, addressing the scalability challenges of existing techniques. It bridges the gap between prompt tuning’s simplicity and other PEFT methods’ superior performance, offering a practical and efficient approach for customizing foundation models. This opens new avenues for research in low-rank adaptations and prompt engineering, impacting various downstream NLP tasks. Furthermore, the method’s server-side efficiency makes it particularly relevant for deploying large language models in resource-constrained environments.
Visual Insights#
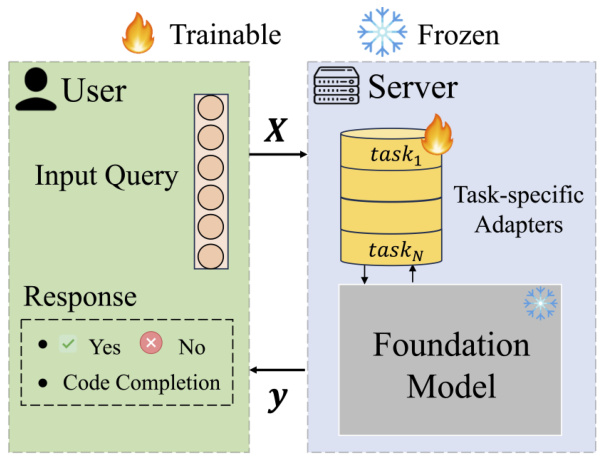
This figure illustrates the typical parameter-efficient fine-tuning (PEFT) methods, such as LoRA. The user sends an input query to a server, which then uses task-specific adapters to modify a frozen foundation model. The modified model generates a response. This highlights the server-side computational overhead of storing and managing multiple task-specific adapters. The figure serves as a visual comparison for the proposed LoPA method, which avoids this server-side burden.
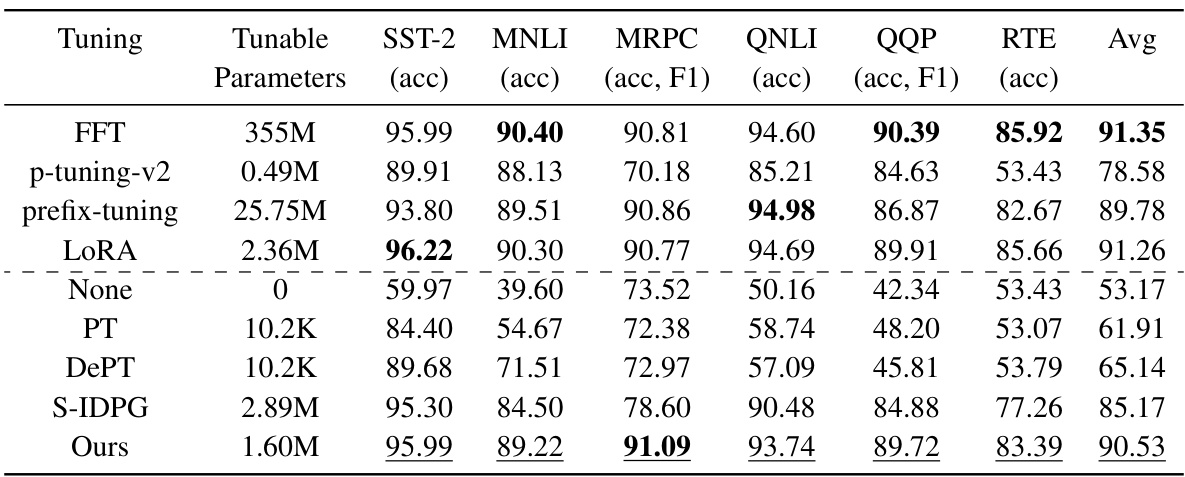
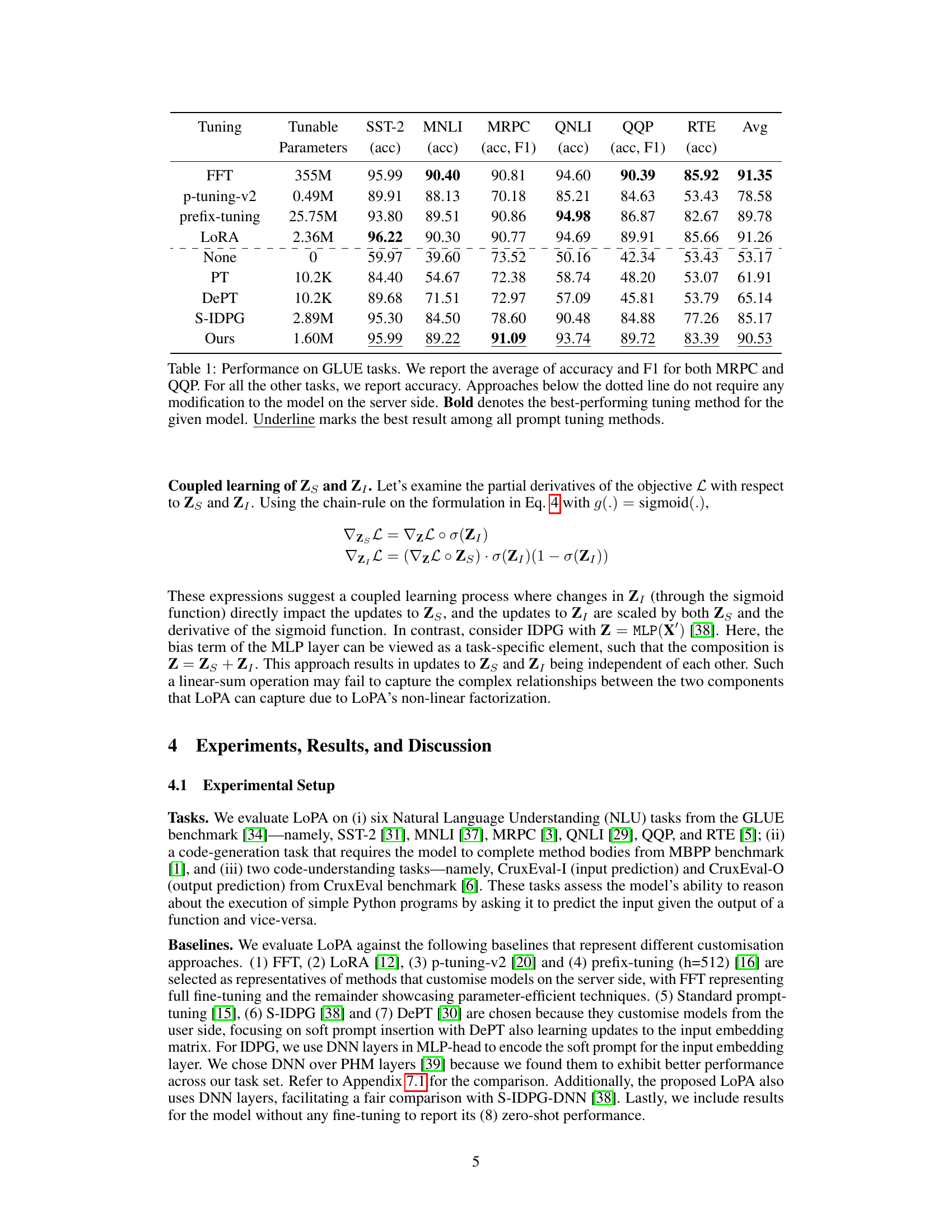
This table presents the performance comparison of different prompt tuning methods and other parameter-efficient fine-tuning methods on the GLUE benchmark. It shows the accuracy (and F1 score for MRPC and QQP) achieved by each method on six different natural language understanding tasks. The table highlights the parameter efficiency of each method and indicates whether the method requires server-side modifications. It demonstrates that the proposed LoPA method achieves competitive performance with significantly fewer parameters than other methods that do require server-side modifications.
In-depth insights#
LoPA: Prompt Tuning#
The proposed Low-Rank Prompt Adaptation (LoPA) method offers a novel approach to prompt tuning, addressing limitations of traditional methods. LoPA enhances parameter efficiency by employing a low-rank decomposition of the soft prompt, balancing shared task-specific information with instance-specific customization. This strategy allows for effective personalization without the scalability issues of storing multiple task-specific adapters on the server. The approach achieves performance comparable to state-of-the-art parameter-efficient fine-tuning methods like LoRA, while maintaining a significant advantage in parameter efficiency and server-side simplicity. LoPA’s effectiveness is validated through comprehensive experiments, demonstrating strong performance across diverse NLU and code generation tasks and across a range of foundation model sizes. The method’s ability to balance task-specific and instance-specific information is a key strength, significantly improving upon simpler prompt tuning strategies that rely on only one component. The results highlight LoPA as a promising and practical alternative for customizing foundation models.
Low-Rank Adaption#
Low-rank adaptation methods are crucial for efficiently personalizing large foundation models. They offer a parameter-efficient alternative to full fine-tuning, which is computationally expensive for large models. The core idea is to decompose the update to the model parameters into low-rank matrices, thereby reducing the number of parameters that need to be learned. This approach enables effective adaptation to various downstream tasks without needing to store multiple task-specific adapters, thus improving scalability and reducing the storage requirements of the model. Low-rank decomposition is key, enabling significant reduction in the number of trainable parameters while maintaining performance comparable to full fine-tuning, which is a major advantage. Different methods employ various strategies to achieve low-rank decomposition; some might focus on specific layers of the model, while others might apply it globally. The choice of method depends on various factors, including the specific application and the size of the model.
Parameter Efficiency#
Parameter efficiency is a crucial consideration in adapting large foundation models (FMs) to specific downstream tasks. Traditional fine-tuning, which updates all model parameters, becomes computationally expensive and impractical for massive FMs. Parameter-efficient fine-tuning (PEFT) methods address this by modifying only a small subset of parameters, significantly reducing computational costs and memory requirements. The paper’s proposed Low-Rank Prompt Adaptation (LoPA) is a prime example of a PEFT method focusing on parameter efficiency. By employing low-rank decomposition of the soft-prompt component, LoPA achieves comparable performance to full fine-tuning and other state-of-the-art PEFT methods like LoRA while using substantially fewer parameters. This makes LoPA particularly attractive for resource-constrained environments or when deploying models with limited computational power. The balance between task-specific and instance-specific information in LoPA’s soft prompt design further enhances its efficiency by avoiding redundancy and promoting effective parameter usage. In essence, LoPA’s parameter efficiency stems from its innovative approach to prompt tuning, offering a practical and effective way to customize FMs without the excessive computational burden of full fine-tuning.
Experimental Results#
The Experimental Results section of a research paper is crucial for demonstrating the validity and effectiveness of the proposed method. A strong results section should present a comprehensive evaluation across various metrics, datasets, and baselines. Clear visualizations, such as graphs and tables, are essential for easily conveying key findings. The discussion should go beyond simply reporting numbers; it should provide a nuanced interpretation of the results, highlighting strengths and weaknesses, and addressing potential limitations. Comparing performance against strong baselines is vital for establishing the novelty and significance of the contributions. Furthermore, a robust results section should delve into ablation studies, illustrating the impact of individual components or hyperparameters, demonstrating a thorough understanding of the system. Finally, a compelling conclusion summarizing the key takeaways, and placing the work within a broader context, leaves a lasting impression and strengthens the paper’s impact.
Future Work#
The paper’s ‘Future Work’ section suggests several promising avenues for extending their research on Low-Rank Prompt Adaptation (LoPA). Investigating LoPA’s performance on more diverse, real-world tasks beyond the benchmark datasets used is crucial. This would provide a more robust evaluation of LoPA’s generalizability and practical applicability. Exploring alternative soft prompt placements (suffixes or random insertions) beyond the prefix method presents another avenue for potential improvement. The researchers also plan to explore the conditional autoencoder perspective, analyzing whether the performance gains stem from compressing task-specific knowledge. Finally, a deeper investigation into the interplay between the task-specific and instance-specific components of the soft prompt, perhaps through alternative non-linear functions, is proposed. This multifaceted approach is essential to fully understand and optimize LoPA for broader application.
More visual insights#
More on figures
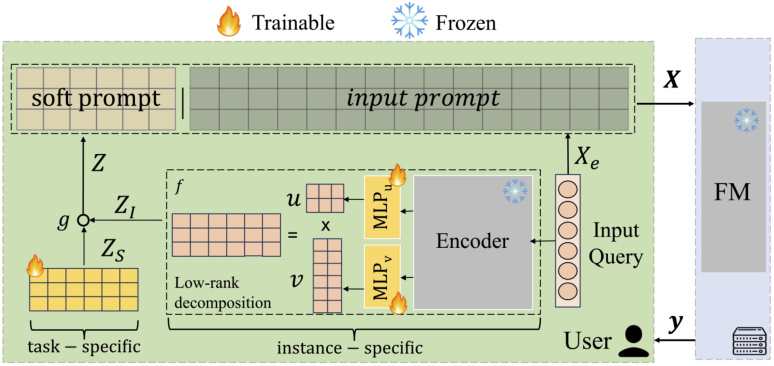
The figure illustrates the architecture of Low-Rank Prompt Adaptation (LoPA). It shows how the soft prompt (Z) is constructed from two components: a task-specific component (Zs) and an instance-specific component (Z1). The instance-specific component is generated using a low-rank decomposition (u x v) to enhance parameter efficiency. The task-specific and instance-specific components are combined using a gating function (g). The resulting soft prompt is then concatenated with the input prompt (Xe) before being fed into the foundation model (FM). No task-specific adapters are needed on the server, making LoPA parameter-efficient and server-side adapter-free.
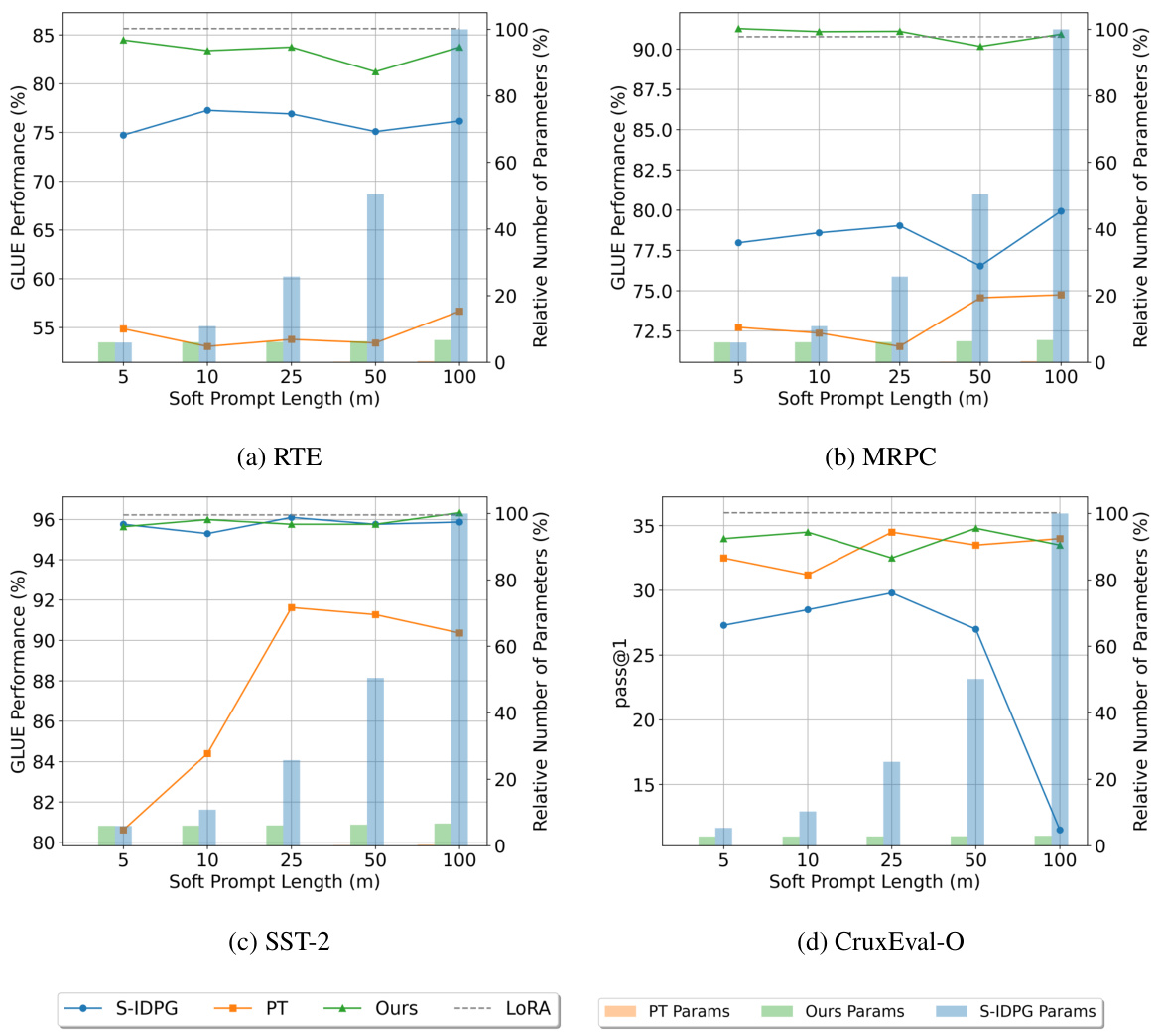
This figure compares the performance of different prompt tuning methods (S-IDPG, PT, LoPA, and LoRA) across various soft prompt lengths (m). Subfigures (a)-(c) show results on the GLUE benchmark (RTE, MRPC, and SST-2 tasks), while subfigure (d) shows results on the CruxEval-O task, using the DeepseekCoder-1.3B foundation model. The x-axis represents the length of the soft prompt, the left y-axis shows the performance (accuracy or F1 score), and the right y-axis represents the number of tunable parameters relative to the method with the most parameters. The figure demonstrates that LoPA generally achieves comparable performance to the best-performing methods (LoRA and full fine-tuning) but with significantly fewer parameters, particularly as the soft prompt length increases.

This figure compares the performance of different prompt-tuning methods (LoPA, S-IDPG, PT, and Lora) on various tasks (RTE, MRPC, SST-2, and CruxEval-O) against the number of tunable parameters used. It shows how performance changes as the length (m) of the soft prompt increases. Higher performance with fewer parameters is better. The results indicate that LoPA generally outperforms other methods, especially with longer prompts on some tasks, without requiring significantly more parameters.
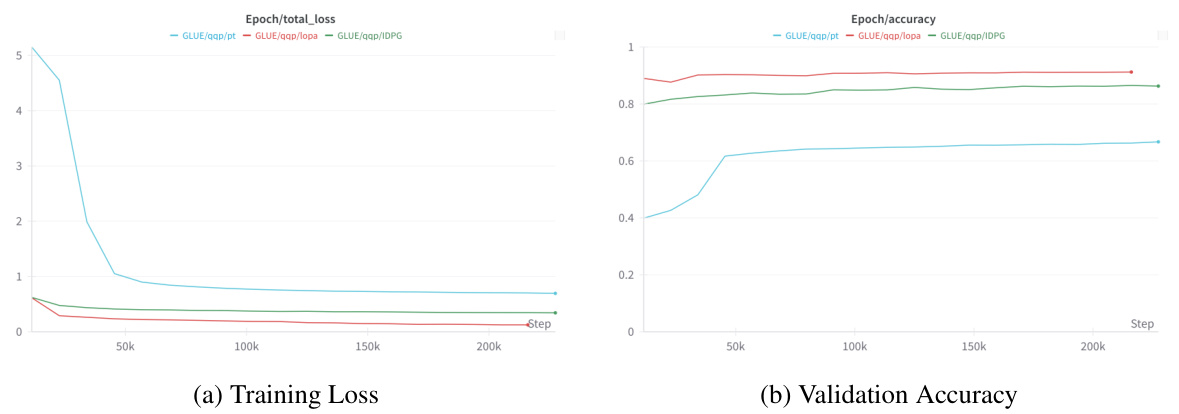
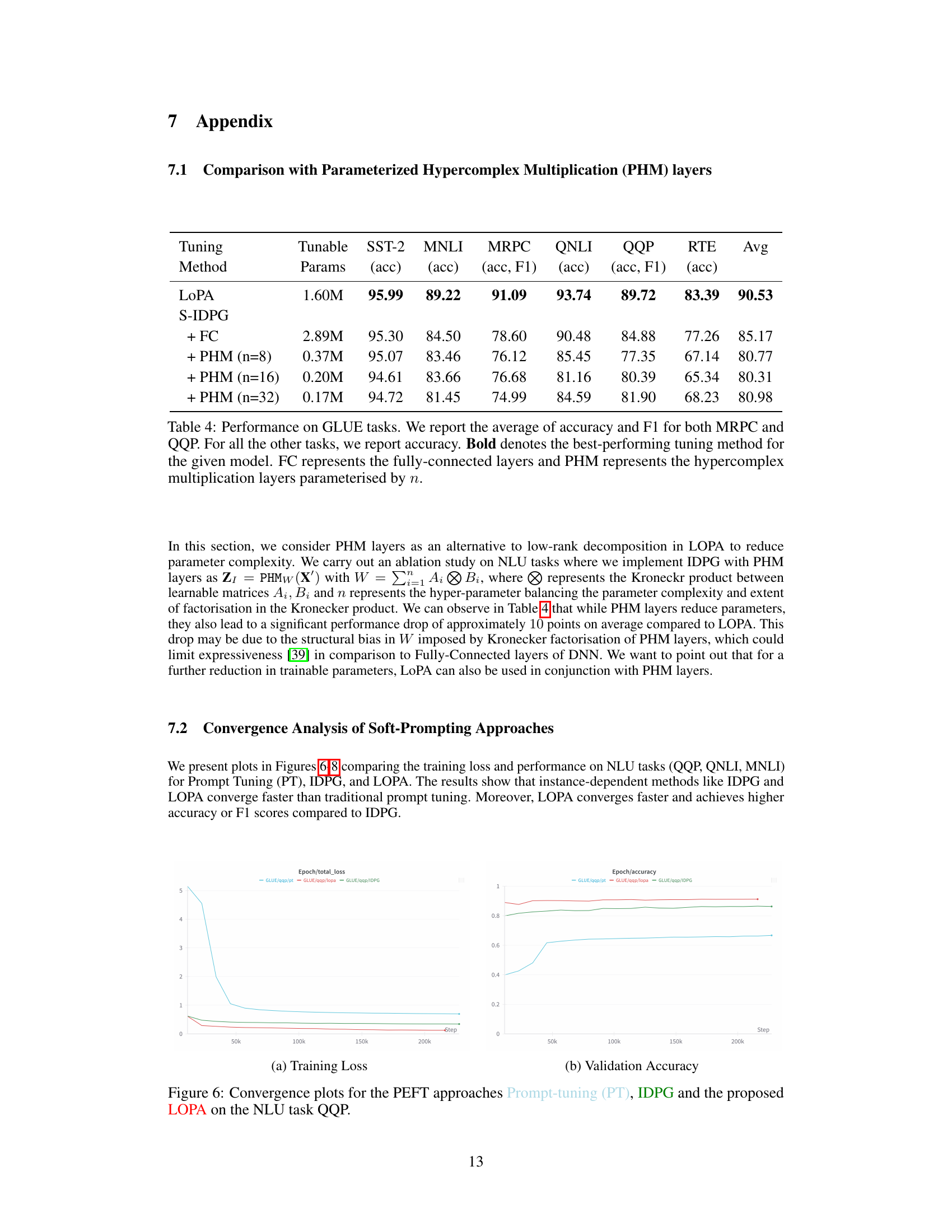
The figure shows the training loss and validation accuracy curves for three parameter-efficient fine-tuning (PEFT) approaches on the QQP task from the GLUE benchmark. Prompt Tuning (PT), IDPG, and the proposed Low-Rank Prompt Adaptation (LoPA) methods are compared. The plot illustrates that LoPA converges faster than PT and IDPG and achieves higher validation accuracy. This suggests that LoPA is a more efficient and effective approach to adapting large language models.
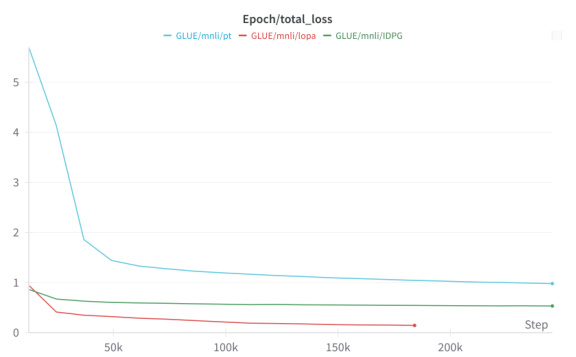
This figure shows the training loss and validation accuracy for three different parameter-efficient fine-tuning (PEFT) methods on the MNLI (Multi-Genre Natural Language Inference) task. The methods compared are Prompt Tuning (PT), Instance-Dependent Prompt Generation (IDPG), and the authors’ proposed method, Low-Rank Prompt Adaptation (LoPA). The plots illustrate the convergence behavior of each method during training, showing how quickly the loss decreases and the accuracy increases. The figure provides evidence of LoPA’s superior convergence compared to the other methods, showcasing faster improvement in both loss and accuracy.
This figure compares the performance of different prompt tuning methods (Prompt Tuning, S-IDPG, LoRA, and the proposed LoPA) on several tasks (RTE, MRPC, SST-2, and CruxEval-O) as the length of the soft prompt (m) varies. It illustrates that LoPA consistently outperforms other methods and achieves comparable performance to LoRA, while using significantly fewer parameters.

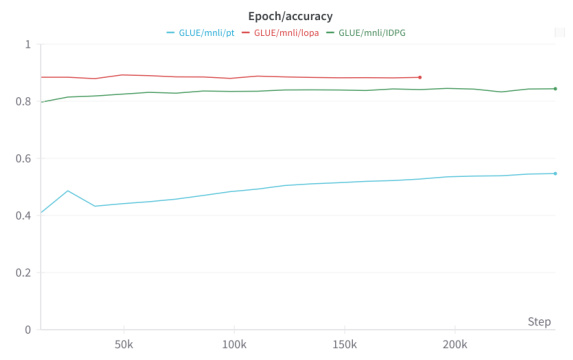
This figure shows the training loss and validation accuracy curves for three parameter-efficient fine-tuning (PEFT) methods: Prompt Tuning (PT), Instance-Dependent Prompt Generation (IDPG), and the proposed Low-Rank Prompt Adaptation (LoPA) on the Question-Question Pair (QQP) task from the GLUE benchmark. The plots illustrate the convergence behavior of each method during training, indicating how quickly they learn and how well they generalize to unseen data. Comparing the curves provides insights into the relative efficiency and effectiveness of these PEFT approaches.
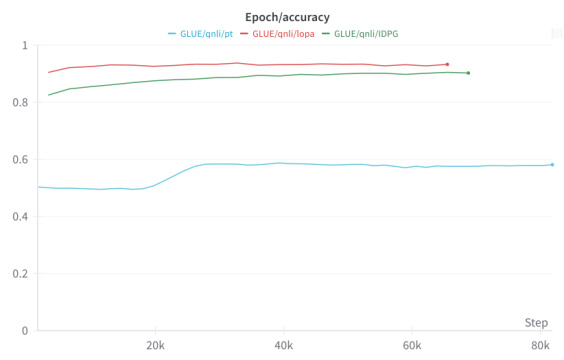
This figure shows the training loss and validation accuracy for three parameter-efficient fine-tuning (PEFT) methods on the QQP (Question-Question Pair) task from the GLUE benchmark. The three methods compared are Prompt Tuning (PT), Instance-Dependent Prompt Generation (IDPG), and the proposed Low-Rank Prompt Adaptation (LoPA). The plots illustrate the convergence behavior of each method during training. LoPA shows faster convergence and higher validation accuracy compared to PT and IDPG.
More on tables
This table presents the performance of various parameter-efficient fine-tuning (PEFT) methods and full fine-tuning (FFT) on the GLUE benchmark. It compares different methods’ accuracy on six natural language understanding tasks and highlights the parameter efficiency of methods that do not modify the model on the server. The table shows that the proposed method (LoPA) achieves comparable performance to state-of-the-art methods while being more parameter-efficient and not requiring server-side modifications.
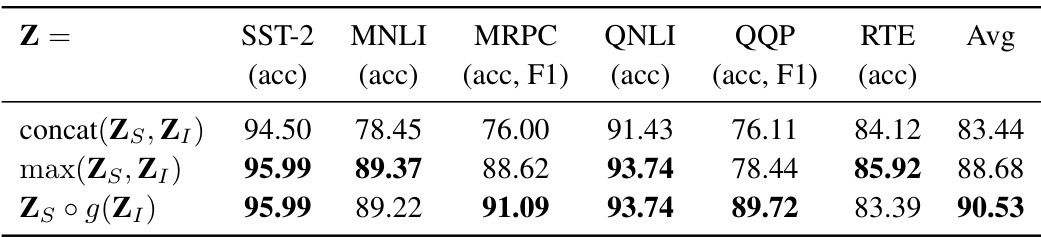
This table presents the performance of the proposed Low-rank Prompt Adaptation (LoPA) method on the GLUE benchmark across various function encoding strategies for combining task-specific and instance-specific components of the soft prompt (Z). The results show the impact of different fusion methods on the overall accuracy and F1-score across six different tasks.
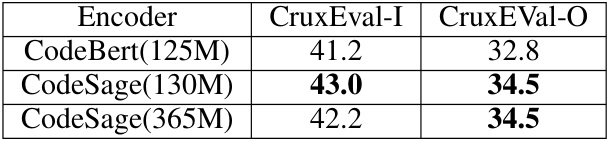
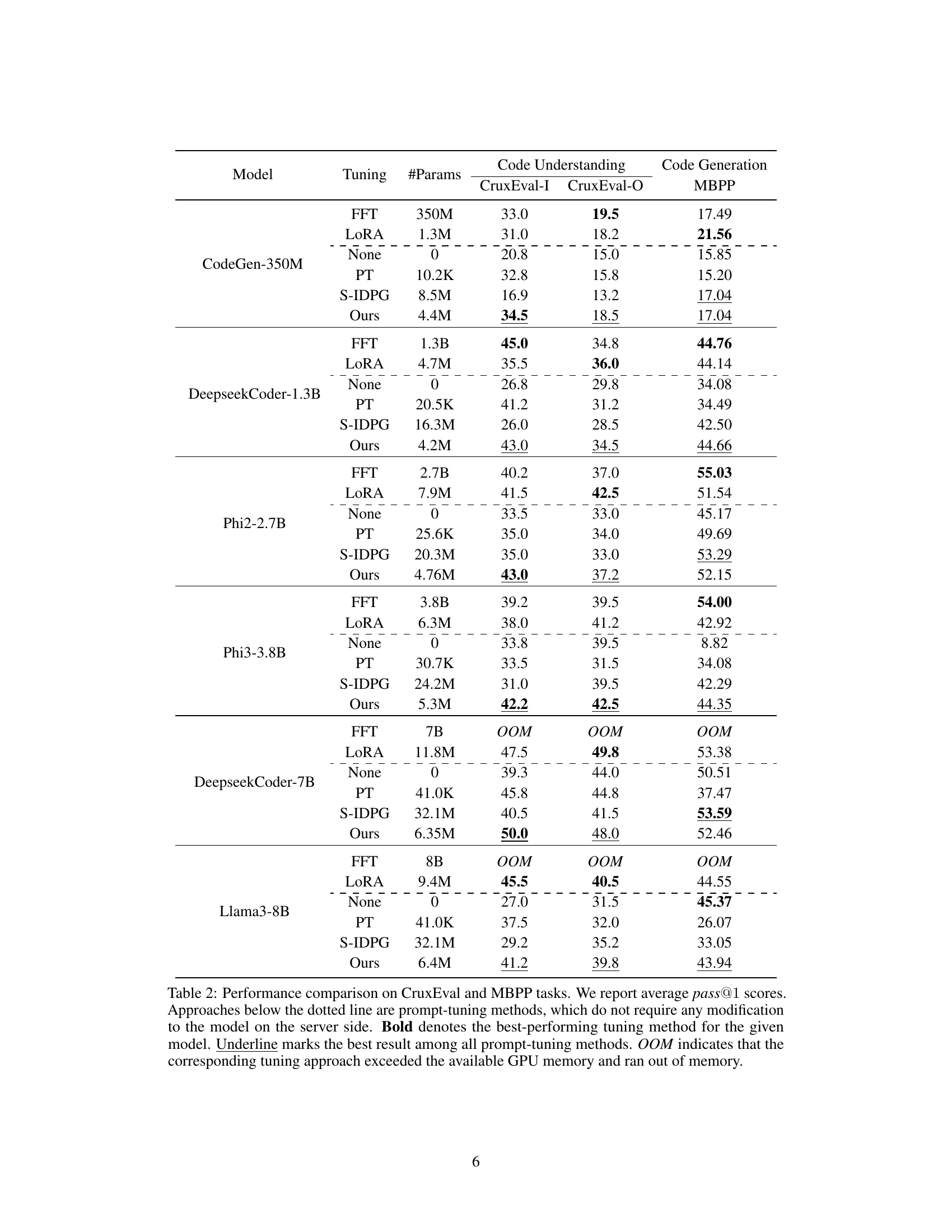
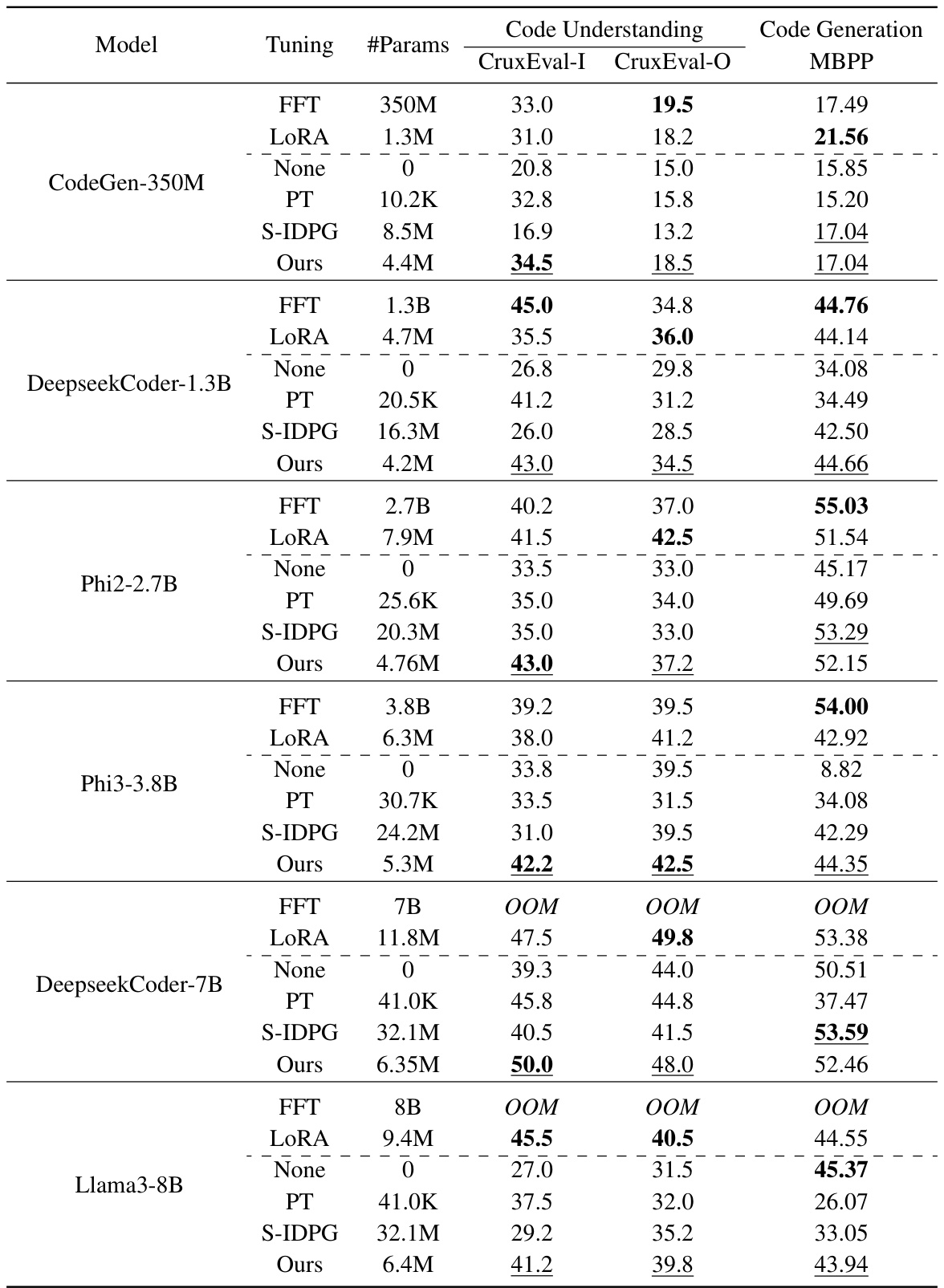
This table presents the performance comparison results of LoPA against other fine-tuning methods on two code understanding tasks (CruxEval-I and CruxEval-O) and one code generation task (MBPP). It shows the average pass@1 score for each method across various foundation models of different sizes. The table highlights the parameter efficiency of LoPA compared to other methods while demonstrating comparable or superior performance in most cases.

This table presents the performance of various prompt tuning methods and other parameter-efficient fine-tuning techniques on the GLUE benchmark. It compares the accuracy (and F1 score for MRPC and QQP) achieved by different methods, highlighting the parameter efficiency and server-side modification requirements of each. The best-performing method for each model and the overall best prompt tuning method are also identified.
Full paper#