↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) often struggle with timely and precise knowledge updates. Fine-tuning with paraphrased data is a common but expensive solution, often lacking sample diversity. This is a problem because LLMs are increasingly deployed in specialized domains with continuously evolving information.
The paper proposes LaPael, a latent-level paraphrasing method that injects input-dependent noise into early LLM layers, directly within the model itself. This approach generates diverse and semantically consistent augmentations, eliminating the repeated costs of external paraphrase generation. Experiments showed LaPael improves knowledge injection compared to standard fine-tuning and existing noise-based methods. Combining LaPael with data-level paraphrasing further enhanced performance. LaPael offers a more efficient and effective approach to knowledge injection in LLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and efficient method for enhancing knowledge injection in LLMs. It addresses the limitations of existing methods by significantly improving performance while reducing computational costs. This opens new avenues for research in LLM adaptation and continuous learning, impacting various downstream applications.
Visual Insights#
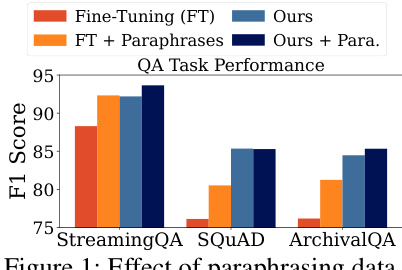
This figure compares the F1 scores of different methods on three question answering datasets (StreamingQA, SQUAD, ArchivalQA). The methods compared include standard fine-tuning (FT), fine-tuning with paraphrases (FT + Paraphrases), the proposed LaPael method (Ours), and the combination of LaPael and paraphrases (Ours + Para.). The results show that adding paraphrases enhances knowledge injection, and that LaPael further improves the performance, with the combination of LaPael and paraphrases yielding the best results. This highlights the effectiveness of data augmentation and the latent paraphrasing approach.

This table presents the experimental results of different knowledge injection methods on three question answering datasets with synthetic documents. The results compare standard fine-tuning, noise-based methods (FreeLB and NEFTune), and the proposed LaPael method, both with and without additional data-level paraphrasing. The table shows the Exact Match (EM), Recall, and F1 scores for each method on each dataset.
In-depth insights#
Latent Paraphrasing#
The concept of ‘Latent Paraphrasing’ presents a novel approach to knowledge injection in large language models (LLMs). Instead of relying on computationally expensive external paraphrasing methods, it proposes injecting noise directly into the model’s latent layers. This input-dependent noise, generated by a trained ’latent paraphraser,’ aims to create diverse yet semantically consistent augmentations within the model itself. This internal process bypasses the need for repeated external paraphrasing during knowledge updates, leading to significant computational savings. The method’s effectiveness relies on the carefully trained latent paraphraser, which learns the optimal noise distribution from a set of paraphrased documents. The key advantage is achieving data augmentation benefits without the overhead of generating paraphrases, thus improving knowledge injection efficiency and cost-effectiveness. Experimental results demonstrate that latent paraphrasing surpasses traditional methods, and the synergy between latent and data-level paraphrasing suggests a powerful combination for enhanced LLM knowledge injection.
Knowledge Injection#
The concept of ‘Knowledge Injection’ in large language models (LLMs) focuses on methods for efficiently updating or expanding an LLM’s knowledge base after its initial training. Fine-tuning is a common approach, but it’s computationally expensive and may not fully integrate new information. Data augmentation, particularly using paraphrased data, is explored as a way to improve knowledge injection by increasing the diversity of training examples and mitigating the limitations of fine-tuning. The paper introduces a novel method called LaPael, which injects knowledge at the latent level of the LLM, introducing noise that enhances knowledge injection while being significantly more cost-effective than traditional methods. LaPael offers improved performance compared to both fine-tuning and data augmentation, showcasing the benefits of working directly with the LLM’s internal representations. However, there’s a trade-off between efficiency and knowledge retention, and LaPael’s effectiveness might depend on the type of LLM and task. Future research could focus on refining LaPael for even greater efficiency and to address knowledge retention issues.
LaPael Method#
The LaPael method proposes a novel approach to knowledge injection in LLMs by introducing latent-level paraphrasing. Instead of relying on computationally expensive external paraphrasing models, LaPael directly injects input-dependent noise into early layers of the LLM. This approach enhances the model’s ability to internalize knowledge from new documents by generating diverse and semantically consistent augmentations within the model itself. The key advantage lies in its efficiency: LaPael eliminates the need for repetitive external model usage, reducing computational costs and making knowledge updates more timely. Moreover, by learning optimal noise distributions, it addresses the limitation of previous noise-based methods that used randomly generated perturbations. Experimental results demonstrate that LaPael improves knowledge injection over standard fine-tuning and other noise-based techniques, and combining it with data-level paraphrasing further enhances performance. This latent-level manipulation of LLM features offers a unique and efficient pathway for dynamic knowledge updates, making it particularly suitable for domains with constantly evolving information.
Experimental Results#
The ‘Experimental Results’ section of a research paper is crucial for validating the claims and hypotheses presented earlier. A strong results section will meticulously detail the experimental setup, including datasets used, evaluation metrics, and any preprocessing steps. It should clearly present the findings using tables, figures, and statistical analyses to demonstrate the effectiveness of proposed methods. Significant results should be highlighted and compared to baselines or state-of-the-art approaches to establish novelty and impact. The discussion should go beyond simply stating the results; it should interpret the findings in the context of the research questions, addressing any unexpected results or limitations observed. Statistical significance testing is essential to ensure that observed effects are not due to chance. Furthermore, a well-written results section will acknowledge any limitations of the study and propose directions for future research, thus promoting transparency and providing a comprehensive evaluation of the work.
Future Works#
Future work could explore several avenues to enhance the latent paraphrasing approach. Extending LaPael to larger LLMs is crucial for real-world applicability, requiring investigation into efficient training and inference strategies for models with billions of parameters. Addressing the reversal curse remains a key challenge, potentially solvable through architectural modifications or incorporating techniques explicitly designed to handle reversed knowledge relationships. Investigating alternative noise generation methods beyond Gaussian distributions might yield further improvements. The exploration of other noise types and the inclusion of semantic constraints during noise generation are promising directions. Finally, a thorough investigation into the optimal placement of latent paraphrasers within the LLM architecture is warranted, as layer placement greatly influences performance. Comprehensive evaluations across a wider array of downstream tasks and datasets are necessary to fully establish the robustness and generalizability of the method.
More visual insights#
More on figures
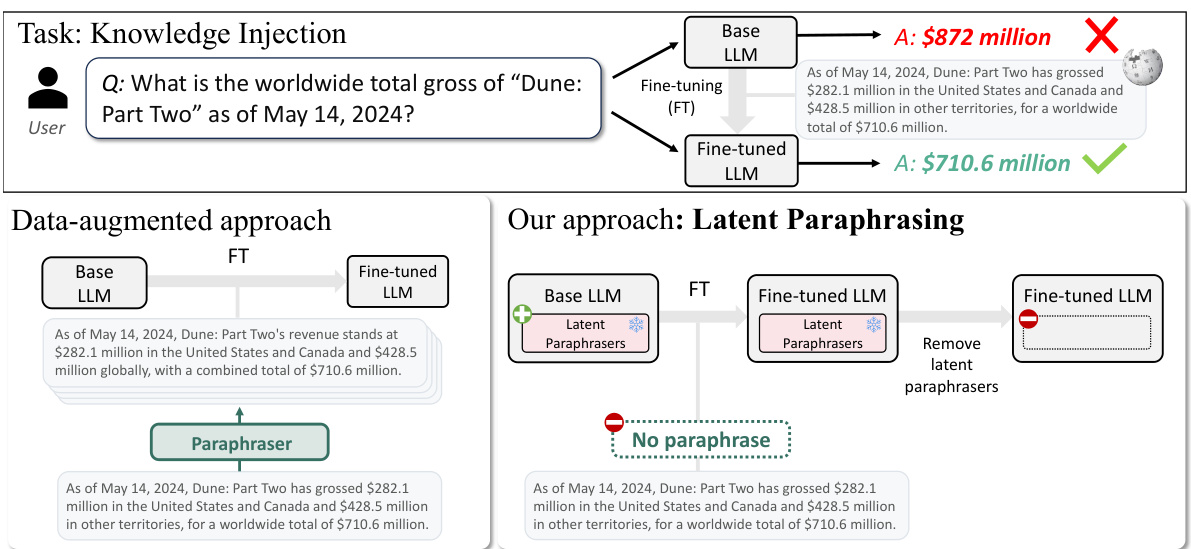
This figure illustrates the difference between the traditional data augmentation approach for knowledge injection and the proposed LaPael method. The left side shows the existing method where each document is paraphrased repeatedly using LLMs for data augmentation, leading to high computational costs. The right side presents LaPael, which uses trained latent paraphrasers to augment the LLM directly at the latent level. This eliminates the need for repetitive external LLM usage for paraphrasing, significantly reducing computational costs.
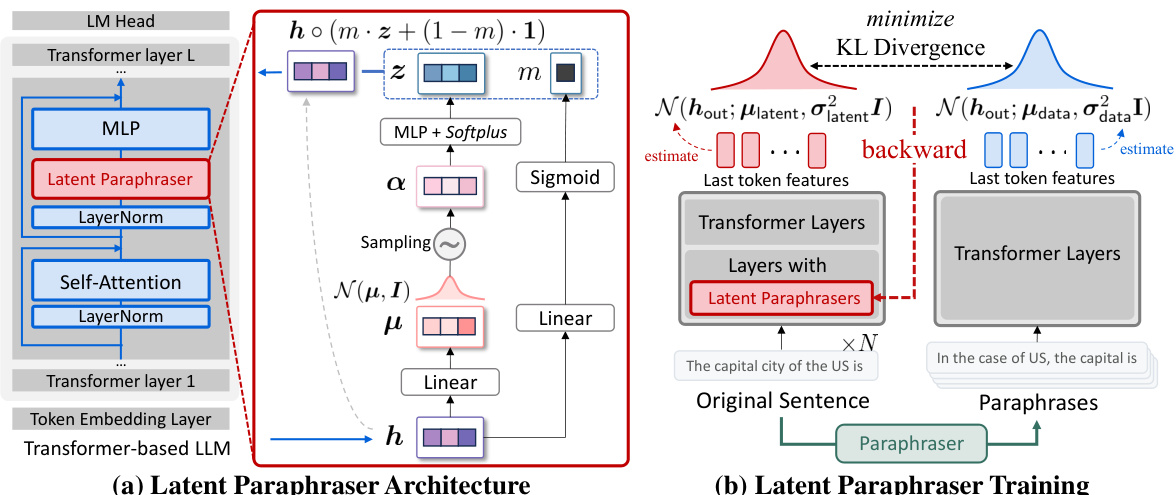
This figure illustrates the architecture and training process of the Latent Paraphraser (LaPael). (a) shows how the latent paraphraser, a neural network module, takes a token’s latent feature (h) as input, generates a noise vector (z) sampled from a Gaussian distribution N(μ, I), and applies a learned mask (m) to control the scale of the noise added to the original latent feature, producing a modified latent feature. (b) depicts the training procedure. Two Gaussian distributions are estimated: one for the latent features processed by the latent paraphraser, and one for the original latent features. The parameters of the latent paraphraser are trained to minimize the Kullback-Leibler (KL) divergence between these distributions, ensuring that the paraphrased and original sentences have similar latent representations.

This figure displays three graphs, one for each of the SQUAD-syn, StreamingQA-syn, and ArchivalQA-syn datasets. Each graph shows the F1 score (a measure of accuracy) on the question-answering task plotted against the number of paraphrases used for data augmentation. Both the standard fine-tuning approach and the proposed LaPael method show improved performance as the number of paraphrases increases, indicating that data augmentation with paraphrases is beneficial for knowledge injection in language models. LaPael consistently outperforms standard fine-tuning across all three datasets.
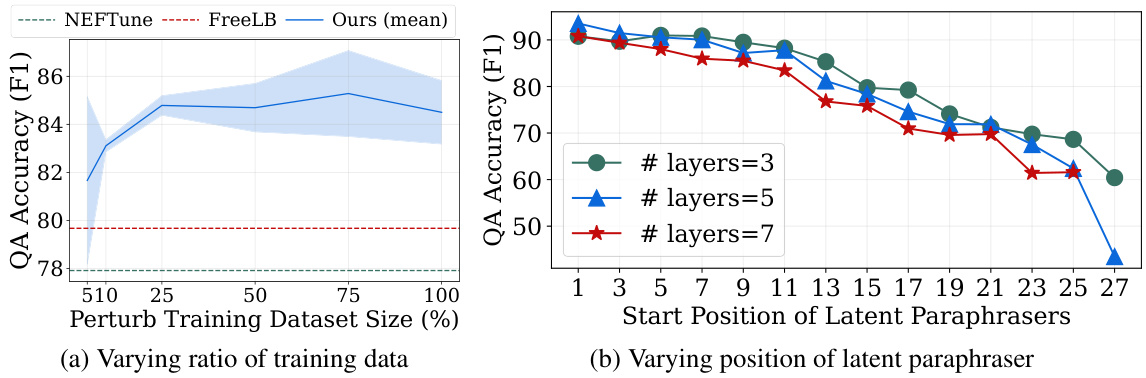
This figure shows two subfigures. Subfigure (a) shows the impact of varying the size of the training dataset (Dtrain) on the F1 score of the SQUAD-syn benchmark. The x-axis represents the percentage of the training dataset used, and the y-axis represents the F1 score. The results show that LaPael’s performance improves steadily with increasing training data size. Subfigure (b) shows the effect of varying the starting layer position for applying the latent paraphrasers within the language model. The x-axis represents the starting layer, and the y-axis represents the F1 score. Three lines represent the results for using 3, 5, and 7 layers with latent paraphrasers. The results indicate that applying the latent paraphrasers to earlier layers produces the best results.

The figure shows a bar chart comparing the F1 scores of question answering tasks for three different methods: Fine-tuning, Fine-tuning with paraphrases, and the proposed method. The proposed method shows a significant improvement in F1 score compared to the other two methods across multiple QA datasets (StreamingQA, SQUAD, and ArchivalQA). This demonstrates the effectiveness of paraphrasing data in improving knowledge injection in language models.

This figure visualizes the latent features extracted from the final layers of LLMs using t-SNE dimensionality reduction. It compares the latent feature distributions of original sentences, their paraphrases, and questions from the ArchivalQA dataset. The use of latent paraphrasing is shown to generate more diverse samples compared to the original data.
More on tables
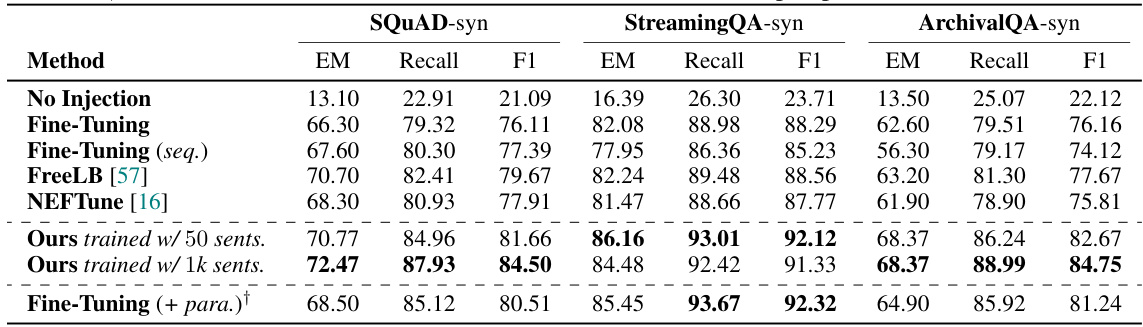
This table presents the experimental results obtained using synthetic datasets for evaluating the knowledge injection performance of different methods. The table compares the performance of several methods, including standard fine-tuning, noise-based methods like FreeLB and NEFTune, and the proposed LaPael method. Results are shown for Exact Match (EM), Recall, and F1 scores on three different question-answering datasets (SQUAD-syn, StreamingQA-syn, and ArchivalQA-syn). The impact of training the latent paraphrasers with different numbers of sentences is also investigated. A comparison is made with a fine-tuning approach that also incorporates data-level paraphrasing.
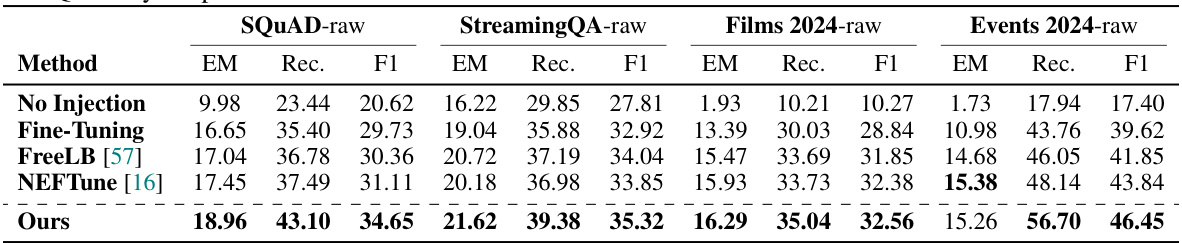
This table presents the experimental results obtained from using raw documents instead of synthetic documents. The results are shown for different question answering datasets (SQUAD-raw, StreamingQA-raw, Films 2024-raw, and Events 2024-raw). The performance of various methods is compared: No Injection (no knowledge injection), Fine-Tuning (standard fine-tuning), FreeLB [57], NEFTune [16], and the proposed method (Ours). The metrics used to evaluate performance are Exact Match (EM), Recall (Rec.), and F1 score. The ‘Ours’ method uses the latent paraphraser trained on the SQUAD-syn dataset (synthetic).
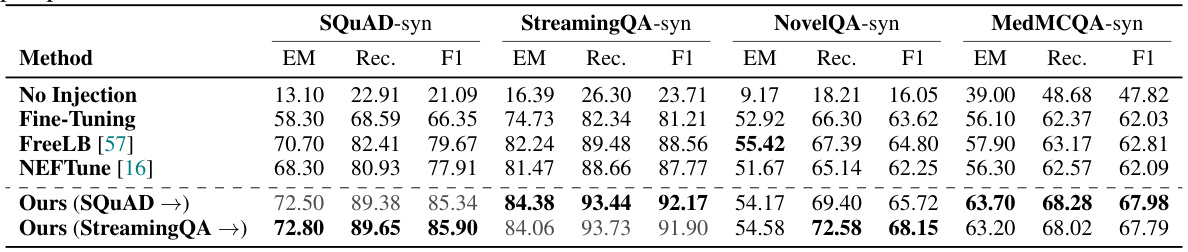
This table presents the results of cross-domain transfer experiments, showing how well the model generalizes across different datasets. The model trains latent paraphrasers on one dataset (source domain, indicated by X) and then fine-tunes the LLM on another dataset (target domain). The table compares the performance of LaPael against several baseline methods in terms of Exact Match (EM), Recall (Rec.), and F1 scores for four different datasets: SQUAD-syn, StreamingQA-syn, MedMCQA-syn, and NovelQA-syn. The results demonstrate the ability of LaPael to successfully transfer knowledge learned from one domain to another, even for datasets with quite different characteristics.

This table presents the experimental results obtained using synthetic datasets for evaluating the performance of different knowledge injection methods. The table compares the performance of several methods: No Injection (baseline), Fine-Tuning (standard fine-tuning), Fine-Tuning (seq.) (fine-tuning with paraphrased sequences), FreeLB, NEFTune, and the proposed method (Ours). Results are shown for three datasets (SQUAD-syn, StreamingQA-syn, ArchivalQA-syn) using different evaluation metrics (EM, Recall, F1). The ‘Ours’ results indicate the average performance over three runs, while the ‘†’ symbol indicates methods using significantly more paraphrased data. The number of sentences used to train the latent paraphrasers is also specified for the ‘Ours’ method.

This table compares the performance of the proposed LaPael method against a Retrieval Augmented Generation (RAG) method and baseline fine-tuning methods on the Events 2024-raw dataset. It shows the Exact Match (EM), Recall (Rec.), and F1 scores for each method, highlighting the relative strengths and weaknesses of different knowledge injection techniques.

This table presents the sizes of three different datasets used in the experiments. Dtrain is the training dataset for the latent paraphrasers. Dk contains the knowledge to be injected into the language model. DQA is the question-answering dataset used for evaluating the knowledge injection performance. The table shows the number of documents or question-answer pairs in each dataset for both synthetic and raw document settings across different question answering benchmarks (SQUAD, StreamingQA, ArchivalQA, NovelQA, and MedMCQA).

This table presents the experimental results of different knowledge injection methods on three question answering datasets (SQUAD-syn, StreamingQA-syn, ArchivalQA-syn) with synthetic documents. The results compare standard fine-tuning, several noise-based baselines (FreeLB and NEFTune), and the proposed Latent Paraphrasing (LaPael) method. The table shows the Exact Match (EM), Recall, and F1 scores for each method. The effect of training the latent paraphrasers on different numbers of sentences (50 or 1000) is also evaluated.
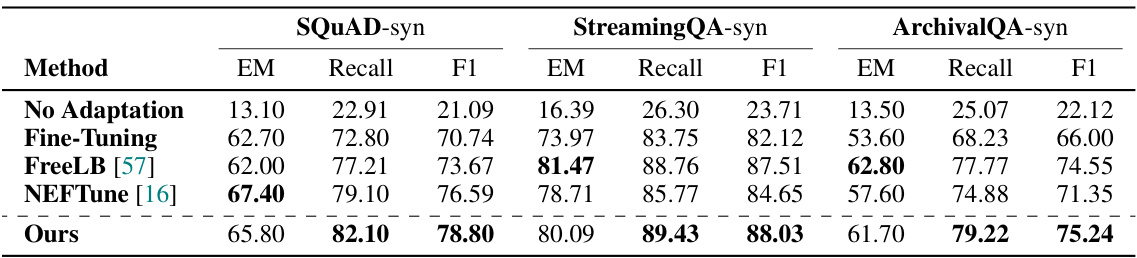
This table presents the experimental results obtained using synthetic datasets for evaluating the performance of different knowledge injection methods. The results are broken down by dataset (SQUAD-syn, StreamingQA-syn, ArchivalQA-syn), metric (EM, Recall, F1), and method (No Injection, Fine-Tuning, FreeLB, NEFTune, Ours). The ‘Ours’ method refers to the proposed approach of latent paraphrasing, which is tested with different numbers of training sentences to show its sensitivity to training data size. The table aims to compare the effectiveness of the proposed approach with existing state-of-the-art methods and standard fine-tuning techniques in scenarios where the training data is augmented.
Full paper#



















