↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Safe reinforcement learning (RL) is crucial for real-world applications, but current methods often struggle with learning safety constraints from experience. Imitation learning is useful, but limited in extensibility, while traditional RL approaches risk unsafe behavior. Inverse constrained RL (ICRL), aiming to infer constraints from expert data, is promising, but existing methods rely on complex, inefficient algorithms.
This research introduces a simplified approach to constraint inference by demonstrating the equivalence of ICRL and IRL under certain reward conditions. The researchers propose a streamlined IRL-based method for constraint inference that simplifies the training process and improves performance. Furthermore, they introduce practical modifications (reward bounding, separate critics, policy resets) to enhance the stability and applicability of the method. The improved performance and simplicity pave the way for easier implementation, broader use, and further extensions.
Key Takeaways#
Why does it matter?#
This paper is crucial because it simplifies constraint inference in reinforcement learning, a significant challenge in applying RL to real-world scenarios. By showing the equivalence between inverse constrained RL and inverse RL under certain conditions, it offers a simpler, more efficient approach. This opens up new avenues for offline constraint inference and various extensions, making safe RL more practical.
Visual Insights#

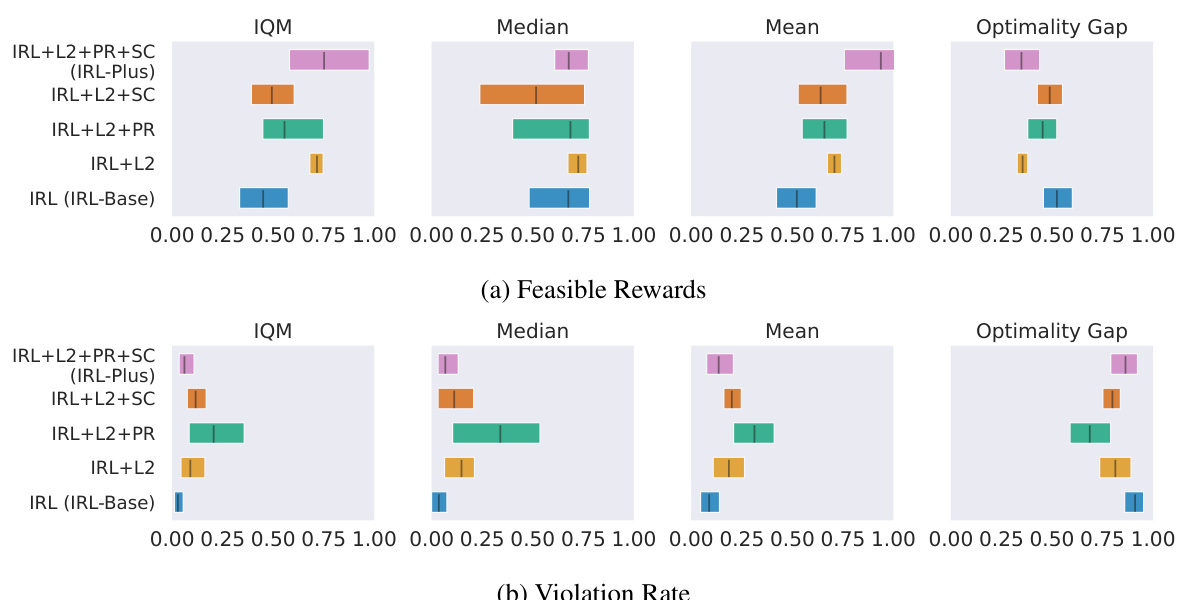
This figure compares the performance of different methods for constraint inference in reinforcement learning across five MuJoCo environments. The x-axis represents different metrics (IQM, Median, Mean, Optimality Gap), and the y-axis shows the normalized performance. The results show that both the proposed IRL-Base and IRL-Plus methods significantly outperform the Maximum Entropy Constrained Reinforcement Learning (MECL) baseline method, with IRL-Plus exhibiting the best overall performance across metrics for both feasible rewards and violation rates.

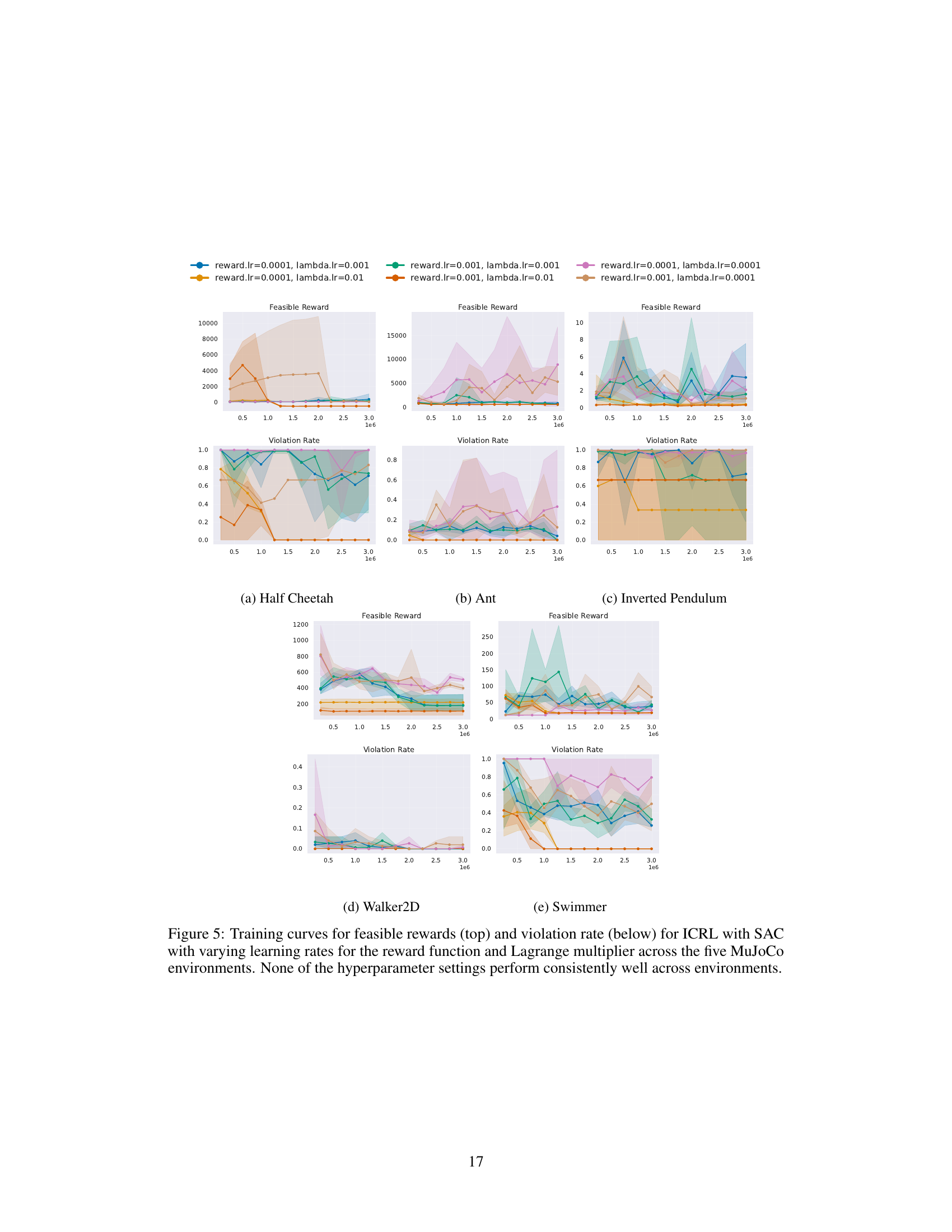
This table lists the hyperparameter settings used for the SAC (Soft Actor-Critic) algorithm and the constraint learning process in the experiments described in the paper. It details parameters for both the SAC algorithm itself (learning rates, optimizers, network architecture, etc.) and for the constraint learning, including the choices for output clipping, activation functions, optimizers, and regularization methods used for different variations of the IRL (Inverse Reinforcement Learning) approach.
In-depth insights#
Inverse RL for ICRL#
The section ‘Inverse RL for ICRL’ would explore the equivalence between inverse reinforcement learning (IRL) and inverse constrained reinforcement learning (ICRL). It would likely demonstrate that, under certain conditions (specific classes of constraint functions), the complex tri-level optimization of ICRL can be simplified to a more manageable bi-level optimization or even reduced to a standard IRL problem. This simplification is a major contribution, potentially making ICRL methods significantly easier to implement, tune, and extend. The authors probably support this equivalence through theoretical analysis and empirical validation, showcasing how a standard IRL approach, with suitable modifications, can achieve performance comparable to or exceeding traditional ICRL methods on benchmark continuous control tasks. This finding suggests that advances in IRL directly translate to ICRL, broadening its applicability and potentially unlocking further improvements through the leveraging of existing IRL research and techniques. The discussion would also likely address the practical implications of this equivalence, including the simplification of training dynamics and complexity of ICRL. Finally, the authors might discuss extending the simplified framework to handle offline constraint inference, furthering its impact on real-world applications of safe reinforcement learning.
Simplified Constraint Inference#
The concept of “Simplified Constraint Inference” in the context of reinforcement learning (RL) centers on reducing the complexity of learning safe policies by inferring constraints from expert demonstrations. Traditional methods often involve complex optimization problems, which are computationally expensive and prone to suboptimal solutions. This simplified approach focuses on making constraint inference more efficient and accessible by leveraging existing IRL (Inverse Reinforcement Learning) techniques, potentially avoiding the need for intricate multi-level optimization procedures found in Inverse Constrained RL (ICRL). The core idea is that by reformulating the problem, the constraint learning process can be simplified to a single-level optimization thus improving performance and ease of implementation. Key innovations might include algorithmic modifications such as using separate critics, bounding rewards, and L2 regularization to enhance stability, thereby achieving comparable or better performance compared to more complex methods while maintaining simplicity. This simplification is a significant step toward making safe RL more applicable to real-world scenarios where learning constraints through experience alone is problematic.
IRL Algorithm Enhancements#
The enhancements to the Inverse Reinforcement Learning (IRL) algorithm focus on simplifying the optimization process and improving performance. The core idea is that the complex tri-level optimization in existing Inverse Constrained Reinforcement Learning (ICRL) methods is unnecessary. The authors demonstrate that standard IRL techniques can achieve comparable or better results, significantly reducing complexity. Key enhancements include bounding rewards to promote stability and interpretability, using L2 regularization to prevent constraint function overfitting, and employing separate critics and last-layer policy resetting to enhance training stability. The combination of these enhancements leads to improved results across various continuous-control benchmarks, demonstrating the effectiveness of the simplified approach. This simplification makes the framework easier to implement and adapt to offline scenarios, opening avenues for broader real-world applications. The work highlights a potentially crucial equivalence between simpler IRL and complex ICRL, which may have far-reaching implications for the field.
Suboptimal Expert Data#
The concept of ‘Suboptimal Expert Data’ in the context of reinforcement learning is crucial because real-world scenarios rarely provide perfect expert demonstrations. Standard imitation learning struggles when presented with imperfect data, leading to the learning of suboptimal or unsafe policies. The core challenge lies in discerning true safety constraints from the noise and imperfections inherent in suboptimal data. This necessitates methods robust to inaccuracies, enabling the system to extract essential safety information while filtering out irrelevant details. Inverse reinforcement learning (IRL) techniques offer a promising pathway by focusing on inferring the underlying reward function and implicit constraints from the expert’s behavior rather than directly imitating actions. A key advantage of this approach is its ability to handle inconsistencies and noise, leading to a more adaptable and reliable system. However, traditional IRL methods often involve complex optimization problems, potentially leading to unstable and suboptimal solutions. The research paper likely explores streamlined versions of IRL, specifically tailored to handle suboptimal expert data efficiently and effectively, leading to improved performance and stability in safety-critical applications.
Future Work: Offline ICRL#
Offline Inverse Constrained Reinforcement Learning (ICRL) presents a significant opportunity to enhance the practicality and scalability of safe reinforcement learning. Current ICRL methods heavily rely on online interactions with the environment, limiting their applicability to real-world scenarios where extensive online data collection is costly or unsafe. An offline ICRL approach would leverage existing datasets of expert behavior to infer constraints and learn safe policies without further online interaction. This would require developing robust offline IRL algorithms capable of handling noisy and incomplete data, and addressing the challenges of learning constraints from limited observations. Addressing issues of constraint identifiability and optimization complexity in the offline setting would be crucial, potentially involving techniques like offline policy optimization or improved representation learning. Successfully developing offline ICRL would open up new avenues for deploying safe RL in high-stakes domains such as robotics, healthcare, and autonomous driving, where online learning is impractical or carries unacceptable risks. Further research could explore efficient techniques for handling large-scale offline datasets and the development of methods for automatically verifying the safety of the learned policies.
More visual insights#
More on figures
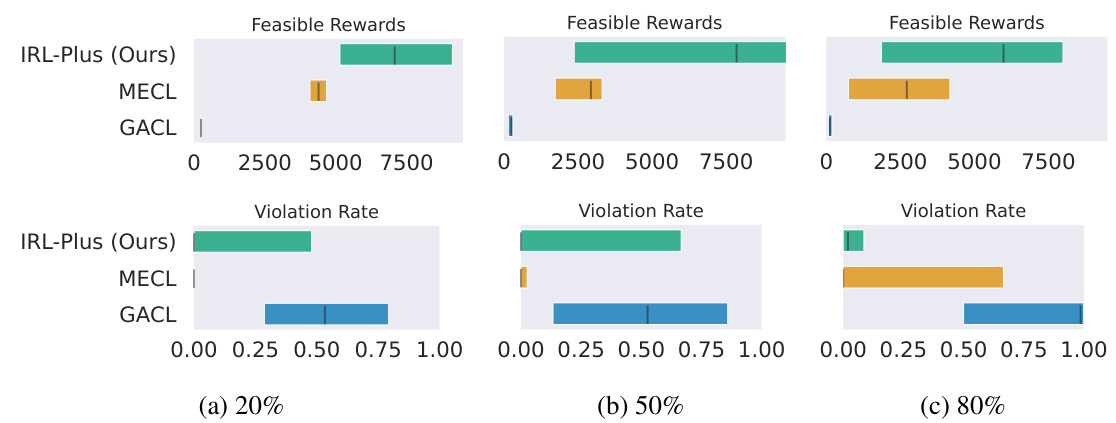
This figure shows the results of applying different methods for constraint inference to the Half-Cheetah environment using suboptimal expert trajectories. The trajectories contain varying percentages of constraint violations (20%, 50%, and 80%). The results show that the proposed IRL-Plus method generally outperforms the baseline ICRL method (MECL) in terms of feasible rewards, which indicates the agent was able to achieve good performance while respecting the constraints. The differences are statistically significant only at 20%. Both methods achieve similar near-zero violation rates, indicating that both methods successfully avoid unsafe actions.
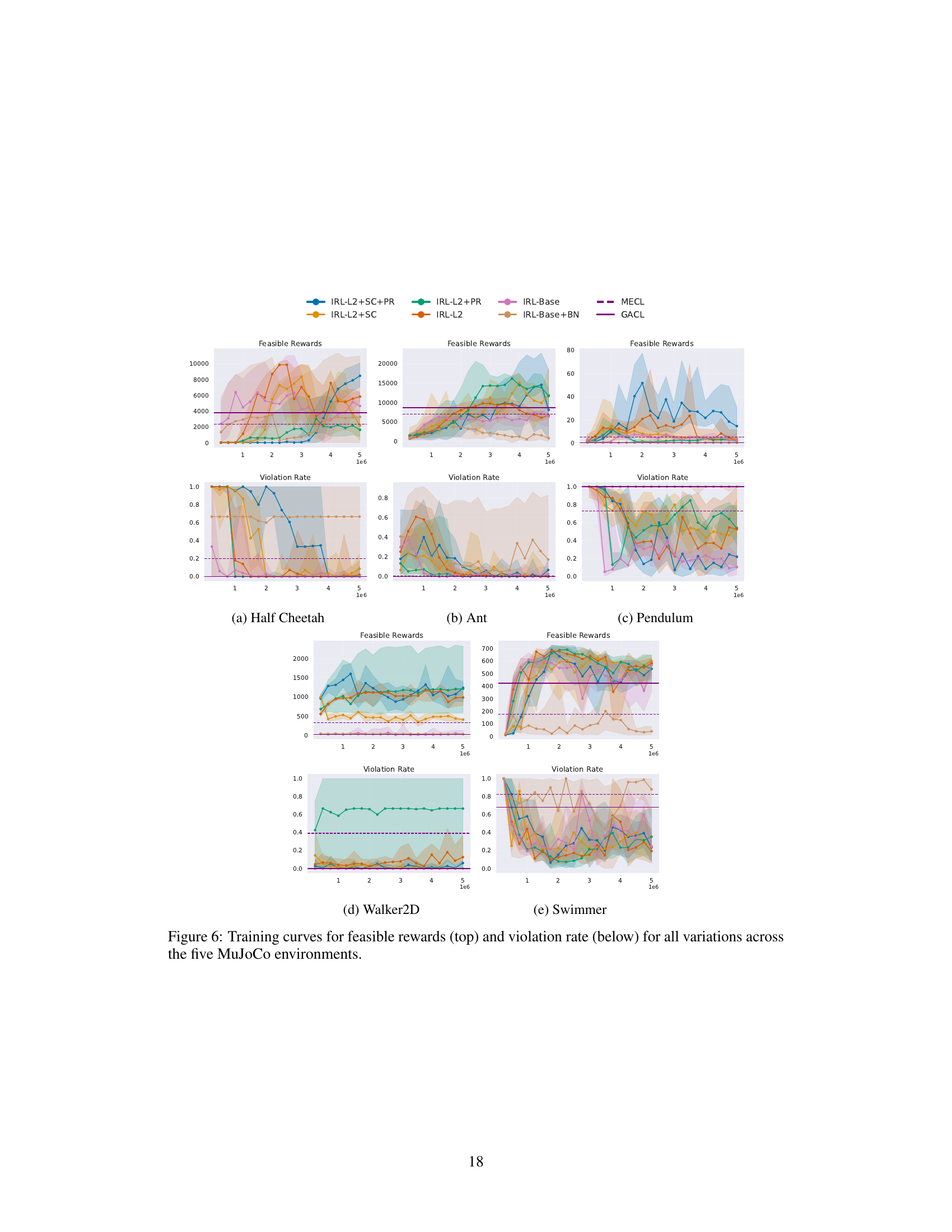
This figure compares the performance of different Inverse Reinforcement Learning (IRL) algorithm variations on five MuJoCo continuous control tasks. The x-axis shows the different modifications to the basic IRL algorithm (IRL-Base). The y-axis shows the performance statistics (interquartile mean (IQM), median, mean, and optimality gap) for feasible rewards and violation rates. The results indicate that adding L2 regularization, separate critics, and policy resets (IRL-Plus) significantly improves feasible rewards while slightly increasing the violation rate compared to the basic IRL method.
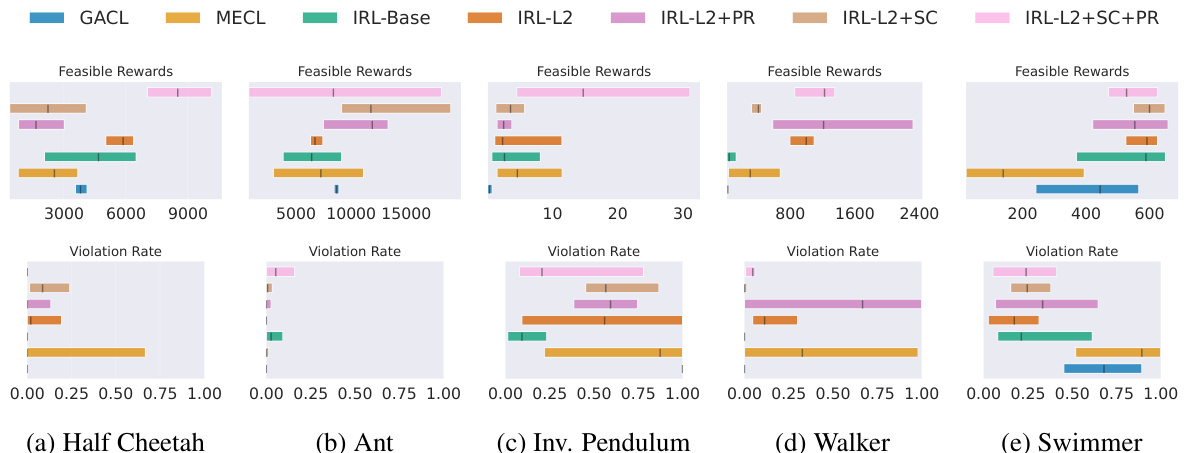
This figure displays the final performance results of the proposed IRL methods (IRL-Base and IRL-Plus) in comparison to two baselines (MECL and GACL) across five MuJoCo environments. Feasible rewards, normalized by expert returns, and violation rates are shown. The results demonstrate that both IRL methods outperform the ICRL baseline (MECL), with IRL-Plus achieving statistically significant improvements across most metrics for both feasible rewards and violation rates.

This figure summarizes the results of comparing the proposed IRL methods (IRL-Base and IRL-Plus) to the existing ICRL method (MECL) across five MuJoCo environments. The results are presented as normalized final performance, with feasible rewards normalized by expert returns. The key finding is that both IRL methods outperform MECL, and IRL-Plus shows a statistically significant improvement over MECL in most metrics for both feasible rewards and violation rate. This suggests that simpler IRL approaches can be just as effective, or even more so, than complex ICRL methods for constraint inference tasks.

This figure presents a summary of the final performance of different methods across five MuJoCo environments. Feasible rewards are normalized by expert returns. The results show that both the basic IRL method (IRL-Base) and the improved IRL method (IRL-Plus) outperform the Maximum Entropy Inverse Constrained Reinforcement Learning method (MECL) in terms of average performance across most metrics (IQM, Median, Mean) . IRL-Plus shows a statistically significant improvement over MECL for both feasible rewards and violation rate.
Full paper#