↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current data analytics methods struggle with unstructured data (images, text, etc.), requiring complex preprocessing before analysis. Traditional SQL is inflexible for these complex, semantic queries. Large Language Models (LLMs) offer potential but are computationally expensive for large datasets.
This paper introduces a Universal Query Engine (UQE) that addresses these issues. UQE uses LLMs for semantic understanding and integrates sampling and compilation techniques to improve efficiency and accuracy. The engine uses a dialect of SQL (UQL) that allows natural language query flexibility. Experiments demonstrate that UQE significantly outperforms baseline approaches on accuracy and cost across various datasets and query types, making it a significant advancement in unstructured data analytics.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers working on unstructured data analytics. It presents a novel query engine (UQE) that significantly improves efficiency and accuracy compared to existing methods. This opens new avenues for research in natural language processing, database management, and efficient querying of large unstructured datasets. The findings will be especially relevant to researchers working on large language models and their applications to data analysis.
Visual Insights#

This figure illustrates how the Unstructured Query Engine (UQE) handles unstructured data. It shows a table with structured columns (movie, rating) and unstructured columns (review_text). The example demonstrates how a SQL-like query can be used to extract insights from both structured and unstructured data. A simple query selecting movies with a rating above 5 is shown, along with a more complex query using natural language to extract the ‘reason why’ a review is negative from the unstructured ‘review_text’ column. This highlights the engine’s ability to handle both types of data and queries.

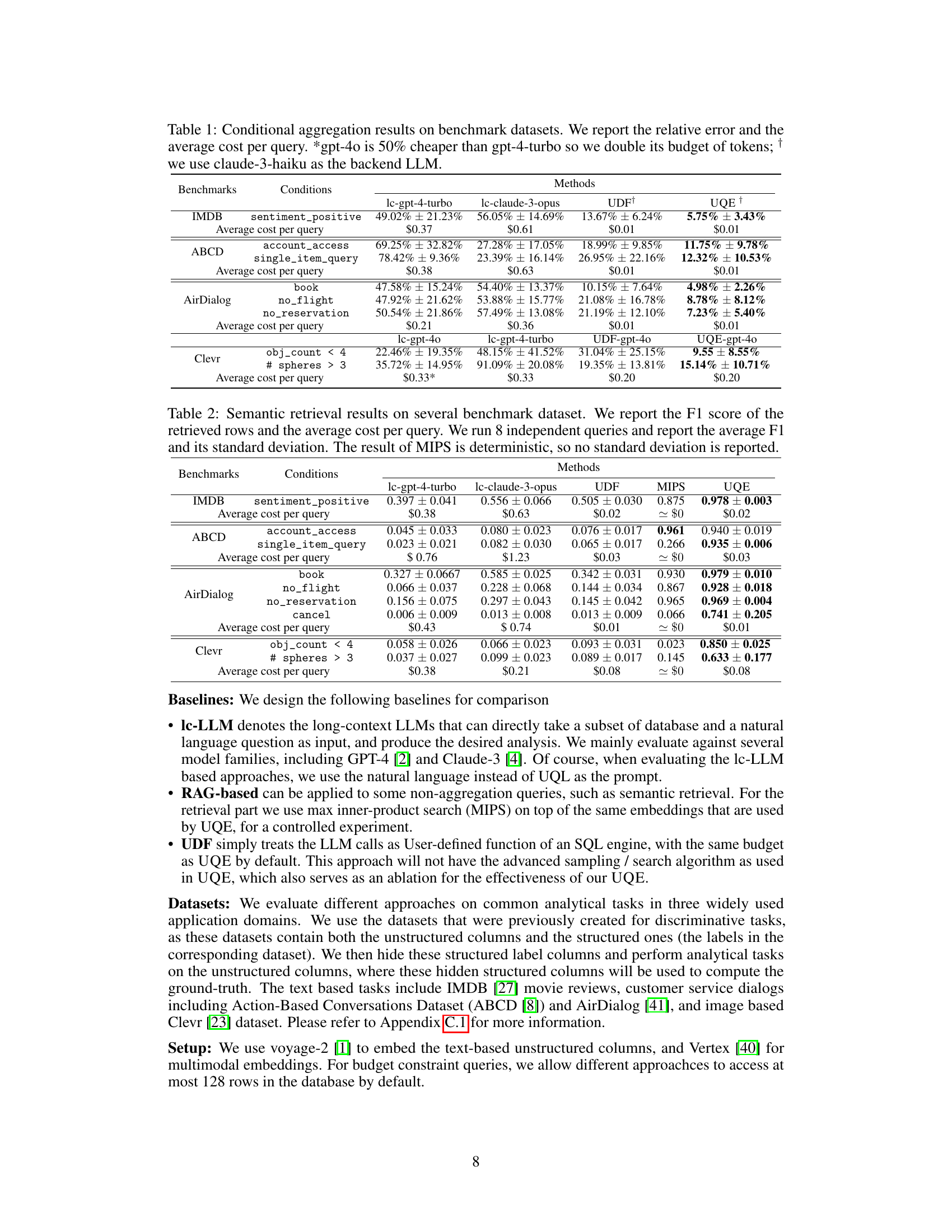
This table presents the results of conditional aggregation experiments performed on four benchmark datasets (IMDB, ABCD, AirDialog, and Clevr). For each dataset, it shows the relative error and average cost per query for several methods: lc-gpt-4-turbo, lc-claude-3-opus, UDF, and UQE. The relative error measures the accuracy of each method in performing conditional aggregations. The average cost per query reflects the computational expense. The table highlights the significant cost reduction and improved accuracy achieved by UQE compared to other methods, especially when using the gpt-4o model.
In-depth insights#
UQL Semantics#
The section on “UQL Semantics” would delve into the intricacies of the Unstructured Query Language proposed in the paper. It would likely begin by establishing the relationship between UQL and SQL, highlighting UQL as an extension designed to handle unstructured data. The core of this section would be dedicated to explaining the semantics of each UQL clause: SELECT, FROM, WHERE, GROUP BY, and potentially others like ORDER BY and LIMIT. For each clause, a detailed explanation of its functionality within the context of unstructured data analysis would be provided. This would involve illustrating how the clauses allow querying not just on structured columns but also on virtual columns derived from unstructured data via LLMs. The treatment of virtual columns is key, showing how natural language specifications within clauses like SELECT and WHERE enable complex semantic queries impossible with traditional SQL. The discussion would highlight the handling of heterogeneous data modalities (text, images, audio) and the importance of the mapping function of SELECT in transforming unstructured data into structured results. Finally, it might address assumptions about the underlying LLM’s capabilities necessary for the semantic understanding required by UQL and possibly the strategies employed for handling ambiguities or inconsistencies in natural language input.
UQE Indexing#
The UQE indexing strategy is a novel approach to efficiently query unstructured databases. Traditional indexing methods struggle with unstructured data’s lack of predefined schemas, making efficient searching difficult. UQE addresses this by framing the problem as learning to search or sample, rather than relying on pre-computed indexes. For aggregation queries, UQE employs stratified sampling based on multi-modal embeddings of data rows, creating statistically sound estimates without a full database scan. This technique leverages the inherent semantic information within the unstructured data to improve sampling efficiency. For non-aggregation queries, UQE utilizes online active learning, iteratively refining a proxy model to identify relevant data rows while managing token budgets. This dynamic approach balances exploration and exploitation, reducing the need to scan the entire database. The overall approach replaces traditional indexing with statistically-driven sampling and learning methods, making UQE highly efficient in handling queries over large unstructured datasets.
UQE Compilation#
UQE compilation represents a crucial optimization strategy in the proposed Universal Query Engine for handling unstructured data. It aims to efficiently translate high-level unstructured query language (UQL) into sequences of low-level operations, primarily LLM calls. The goal is to minimize LLM usage, a major cost factor. The process involves planning, determining the optimal order and fusion of UQL clauses, and kernel implementation, defining how each clause (SELECT, WHERE, GROUP BY, etc.) is executed using LLMs or other methods for structured data. Cost estimation plays a key role in planning, predicting the LLM token count for each operation, allowing for selection of the most efficient execution path. The system might utilize stratified sampling for aggregation queries and online learning for search queries to reduce LLM calls while preserving accuracy. The compiler’s analogy to a traditional C++ compiler underscores the systematic approach, moving from high-level query representation to optimized LLM interaction. Further optimization involves kernel fusion, combining multiple operations to reduce the overall LLM cost. The success of UQE hinges heavily on the effectiveness of this compilation stage in balancing computational cost with semantic accuracy.
Experimental Results#
A thorough analysis of the ‘Experimental Results’ section requires understanding the research question, methodology, and the type of data analyzed. The clarity and organization of the results presentation are critical; well-structured tables and figures are essential for easy comprehension. Statistical significance should be explicitly stated, including error bars or p-values, to support the claims made. A comparison with baselines or previous work is crucial to demonstrate the advancements made. The discussion should connect the results back to the research question, highlighting both successes and limitations, and suggesting possible future work based on the findings. A detailed explanation of the experimental setup, including dataset characteristics and parameter choices, is vital for reproducibility. Any unexpected or outlier results warrant a separate analysis and discussion. Finally, the overall conclusion should be clear and concisely summarize the key findings and their implications.
Future Work#
The paper’s “Future Work” section would greatly benefit from expanding on several key areas. Addressing the limitations of the current LLM reliance is crucial; exploring alternative methods or augmenting LLMs with techniques like knowledge graphs or symbolic reasoning could enhance accuracy and robustness. Extending UQL to incorporate more complex SQL features (joins, subqueries, window functions) is essential for wider applicability. Investigating different LLM architectures and prompting strategies to optimize cost and performance is also key. A focus on improving the sampling strategies for handling large datasets efficiently and incorporating techniques like active learning would enhance scalability. Finally, a thorough evaluation on diverse datasets representing various data modalities and complexities is important for establishing UQE’s generalizability and effectiveness. These expansions would demonstrate a broader impact and solidify the study’s contributions.
More visual insights#
More on tables
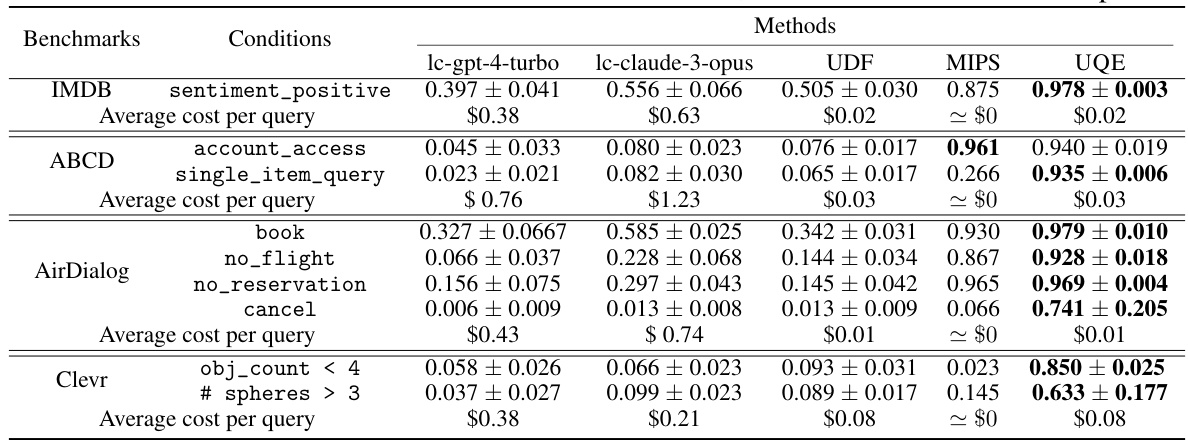
This table presents the results of semantic retrieval experiments on several benchmark datasets. The F1 score, a metric evaluating the accuracy of retrieved data, is reported for each dataset, along with the average cost per query. Eight independent queries were run for each dataset, and the average F1 score and its standard deviation are given. Note that the MIPS (Max Inner Product Search) method produced deterministic results, so no standard deviation is shown.
This table presents the results of conditional aggregation experiments performed on four different benchmark datasets (IMDB, ABCD, AirDialog, and Clevr). For each dataset, the relative error and average cost per query are reported for different methods: lc-gpt-4-turbo, lc-claude-3-opus, UDF+ (with gpt-4-turbo), UDF-gpt-4o, and UQE+ (with gpt-4-turbo) and UQE-gpt-4o. The table highlights the superior performance of UQE in terms of both accuracy and cost.

This table presents the results of conditional aggregation experiments conducted on four benchmark datasets (IMDB, ABCD, AirDialog, and Clevr). The table compares the performance of UQE (Unstructured Query Engine) against several baseline methods, including different LLM (Large Language Model) configurations and a UDF (User-Defined Function) approach. For each dataset and method, the relative error (the percentage difference between the estimated and true counts) and the average cost per query (in USD) are reported. The table highlights that UQE achieves significantly lower relative errors and costs than baseline methods across all datasets.

This table presents the results of conditional aggregation queries on four benchmark datasets (IMDB, ABCD, AirDialog, and Clevr). It compares the performance of UQE against several baselines (lc-gpt-4-turbo, lc-claude-3-opus, UDF+, and UDF-gpt-4o). The table shows the relative error (percentage difference between predicted and actual counts) and the average cost (in USD) per query for each method and dataset. The results highlight UQE’s superior accuracy and cost efficiency, especially when using gpt-4o as the LLM.
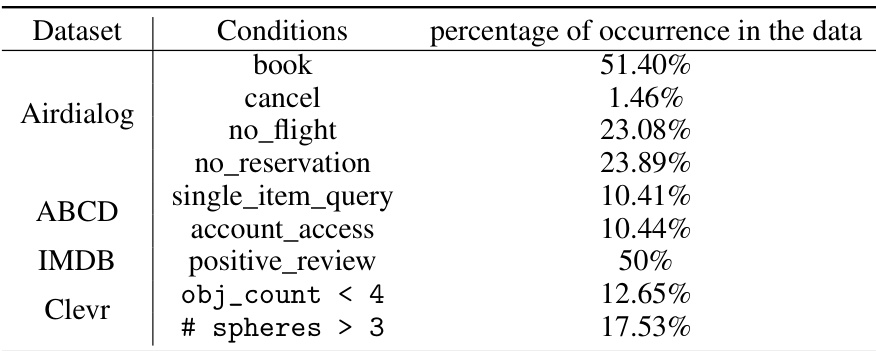
This table presents the statistics of four benchmark datasets used in the paper’s experiments. For each dataset (Airdialog, ABCD, IMDB, Clevr), it shows the different conditions or queries used and the percentage of the data that satisfies each condition. This helps to understand the distribution of data within each dataset and the relative difficulty or rarity of different query types.

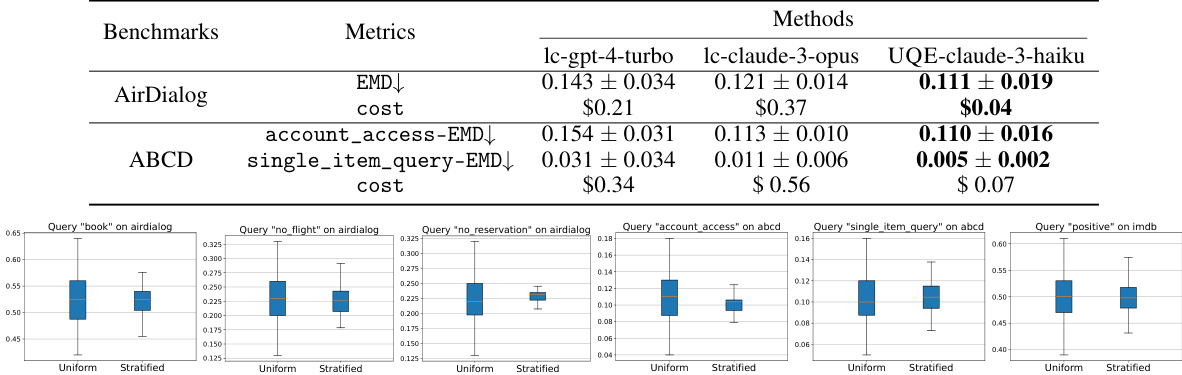
This table presents the performance comparison of UQE (Unstructured Query Engine) using different Large Language Models (LLMs) for both retrieval and aggregation tasks. It compares the F1 scores for retrieval and the relative errors for aggregation, showing how UQE performs with different LLMs as its backend. The results demonstrate the impact of the LLM choice on UQE’s accuracy and efficiency.

This table compares the runtime of UQE and lc-gpt-4-turbo in seconds for different types of queries (Conditional Aggregation and Semantic Retrieval) across different benchmark datasets (Clevr, ABCD, IMDB, AirDialog). It shows that UQE generally has much lower runtime than lc-gpt-4-turbo, highlighting its efficiency in executing unstructured queries.
Full paper#