↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current text-to-image (T2I) models often struggle to precisely match image details with text descriptions, leading to inaccuracies in spatial relationships or missing objects. Existing methods to improve fidelity rely on expensive human annotations or high-quality image-text datasets, which are resource-intensive to obtain.
To address these issues, the researchers propose SELMA, a novel method that utilizes LLMs for generating diverse image-text data, and employs a skill-specific expert learning and merging approach for T2I model fine-tuning. The results demonstrate significant improvements in image-text alignment across various benchmarks and human evaluations, with comparable performance to methods using ground-truth data, showcasing SELMA’s efficiency and effectiveness in enhancing T2I model faithfulness.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to improve the faithfulness of text-to-image models. It introduces SELMA, a method that uses LLMs and auto-generated data to fine-tune models, achieving significant improvements in multiple benchmarks and human evaluations. This work addresses a key challenge in the field and opens up new avenues of research in efficient model fine-tuning and improving the semantic alignment of generated images with textual descriptions.
Visual Insights#
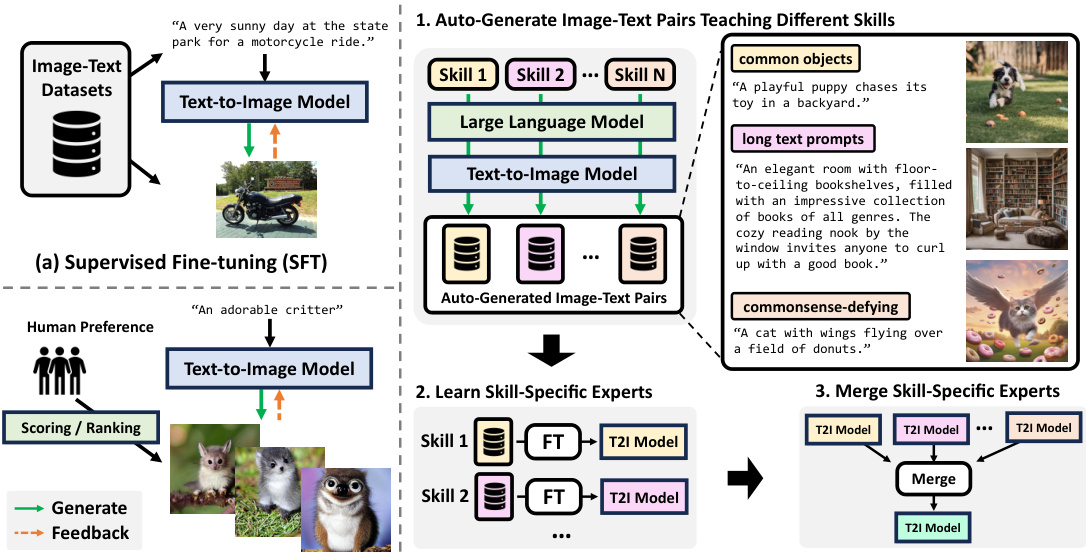
This figure compares three different approaches for fine-tuning text-to-image models: (a) Supervised Fine-tuning (SFT) uses existing image-text datasets, (b) Fine-tuning with Human Preference uses human ranking/scoring of generated images to optimize the model, and (c) SELMA uses an LLM and T2I model to automatically generate image-text pairs for different skills and merges those into a multi-skill model. SELMA is presented as a novel approach.

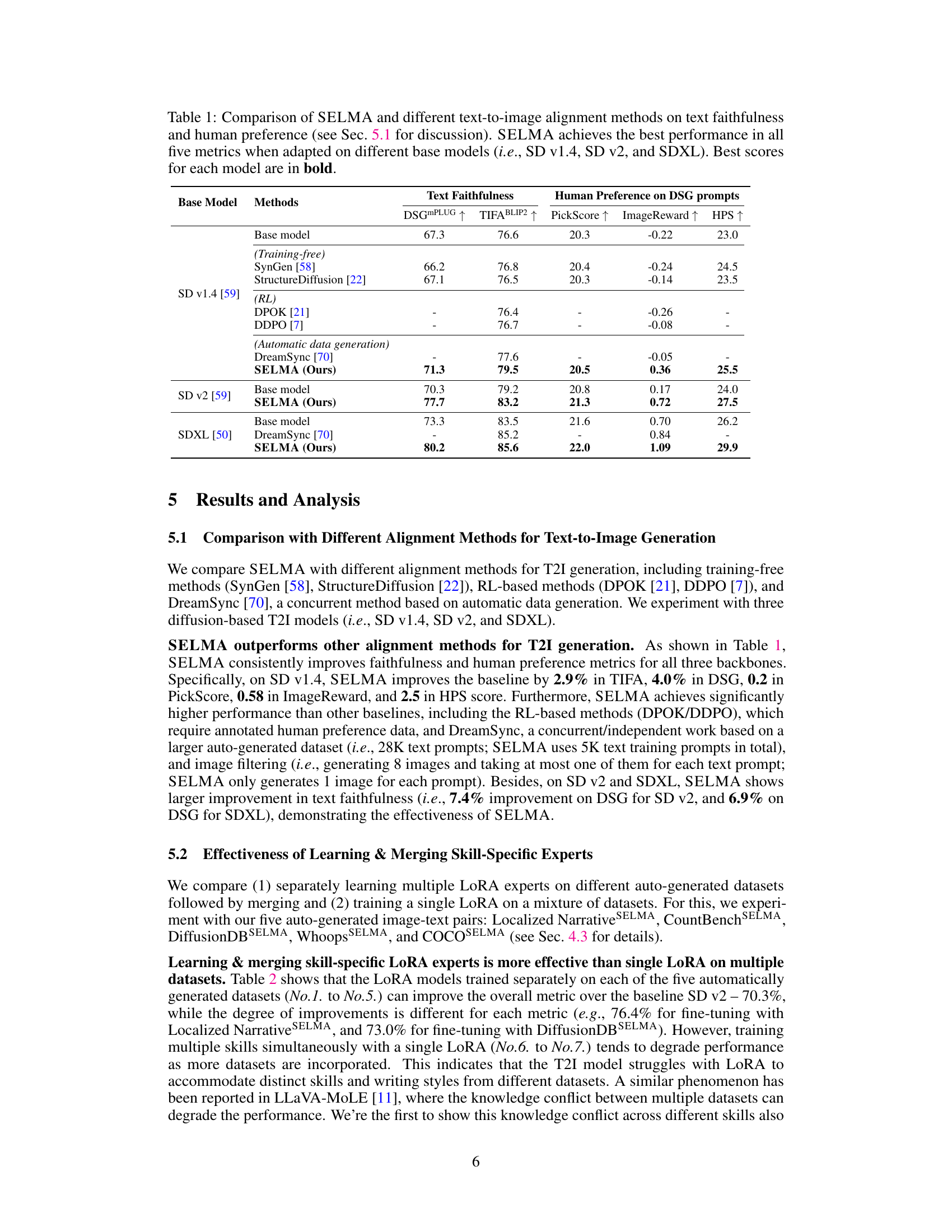
This table compares SELMA’s performance against other text-to-image alignment methods across three different state-of-the-art diffusion models (SD v1.4, SD v2, and SDXL). The comparison includes training-free methods, reinforcement learning (RL) based methods, and another automatic data generation method (DreamSync). The metrics used evaluate both text faithfulness (how well the generated image matches the text description) and human preference (how much humans prefer the generated images). The table highlights that SELMA consistently achieves the best results across all metrics and models, demonstrating its effectiveness in improving the alignment between text descriptions and generated images.
In-depth insights#
SELMA’s Approach#
SELMA presents a novel approach to enhance text-to-image faithfulness by leveraging large language models (LLMs) and diffusion models. Its core innovation lies in auto-generating diverse image-text datasets focused on specific skills (e.g., object composition, long-text comprehension), eliminating the need for manual data annotation. This is achieved by using LLMs to generate skill-specific prompts and a pre-trained T2I model to generate corresponding images. Then, skill-specific LoRA experts are trained, followed by expert merging to create a multi-skill T2I model that excels in generating faithful images for diverse textual inputs. This paradigm is particularly effective in mitigating the knowledge conflict often observed when training with mixed datasets. The results show significant improvement in text faithfulness, semantic alignment and human preference metrics across multiple benchmarks, highlighting the effectiveness of SELMA’s approach for improving the fidelity and robustness of text-to-image generation models.
Multi-skill Experts#
The concept of “Multi-skill Experts” in the context of a text-to-image model suggests a paradigm shift from single-purpose models to a more versatile and robust system. Instead of training a single model to perform all tasks adequately, the approach focuses on developing specialized “expert” models, each adept at a specific skill (e.g., handling long descriptions, generating intricate details, or managing spatial relationships). This modularity offers several advantages: improved efficiency in training and updating specific aspects of image generation, and reduced knowledge conflicts that often arise when a single model tries to master diverse and sometimes contradictory skills. The subsequent merging of these expert models aims to create a unified, multi-skill model that seamlessly integrates the strengths of its components, while potentially mitigating the weaknesses inherent in individual experts. This approach also provides the flexibility to fine-tune specific skills without affecting others, making it easier to adapt the model to evolving demands and new requirements. A key challenge in this approach is effectively merging diverse expert models without performance degradation or unintended interference between skills. Careful design and effective merging strategies are crucial to successfully create a powerful multi-skill model exceeding the capabilities of any individual expert. The ultimate goal is to produce a system that’s both highly effective and easily adaptable to various text-to-image generation tasks.
Auto-data Creation#
Auto-data creation is a crucial aspect of this research, leveraging LLMs for prompt generation and a pre-trained T2I model for image synthesis. This avoids the need for expensive human annotation, a significant advantage. The process iteratively refines the quality of the generated data by using a text diversity filter based on ROUGE-L scores. This iterative process ensures the generated image-text pairs are diverse and relevant, effectively teaching the T2I model a variety of skills. While this approach is efficient and effective, it is important to consider potential biases introduced by the LLM or the pre-trained T2I model. Further investigation into bias mitigation and potential overreliance on the pre-trained model’s existing knowledge base is warranted. The self-generated data strategy demonstrates a promising path to training models cost-effectively, making advancements in T2I more accessible.
Faithfulness Gains#
The concept of “Faithfulness Gains” in the context of text-to-image models refers to improvements in how accurately generated images reflect the details and semantics of the input text prompts. Higher faithfulness suggests better alignment between textual descriptions and visual representations. This is a critical area of research because early text-to-image models often struggled with inaccuracies, such as incorrect spatial relationships, missing objects, or misinterpretations of textual instructions. Achieving substantial faithfulness gains often requires addressing several challenges: the ambiguity inherent in natural language, the limitations of current generative models, and the difficulty of evaluating faithfulness objectively. Methods to improve faithfulness may involve fine-tuning models on high-quality datasets, utilizing reinforcement learning with human feedback, or incorporating additional contextual information to guide the generation process. Measuring these gains requires robust evaluation metrics that capture both objective and subjective aspects of image-text correspondence, such as semantic similarity, visual fidelity, and human perceptual preference. The ultimate goal is to create models capable of generating highly accurate and nuanced images, perfectly reflecting the user’s creative intent.
Future Work#
Future research directions stemming from this work could involve exploring more sophisticated LLM prompting techniques to generate even more diverse and nuanced datasets for training. Investigating alternative expert merging strategies, beyond LoRA, could potentially unlock further performance gains and address potential knowledge conflicts more effectively. Another promising avenue would be to systematically evaluate the impact of different LLM models on the quality and diversity of generated prompts, allowing for a more robust and adaptable system. Finally, extending SELMA’s methodology to other vision-language tasks, such as image captioning and visual question answering, could reveal further insights into the generalizability and power of this approach. A key focus should be placed on carefully evaluating and mitigating potential biases that may arise during both the data generation and model training phases, ensuring responsible and ethical development of this technology.
More visual insights#
More on figures

This figure illustrates the four stages of the SELMA pipeline. Stage 1 involves using an LLM for prompt generation with text diversity filtering. Stage 2 uses a text-to-image model to automatically generate images from the prompts. Stage 3 uses LoRA modules to fine-tune multiple single-skill experts of the T2I model on the image-text datasets generated in stage 2. Lastly, stage 4 merges the single-skill experts using LoRA merging to create a final multi-skill T2I model.
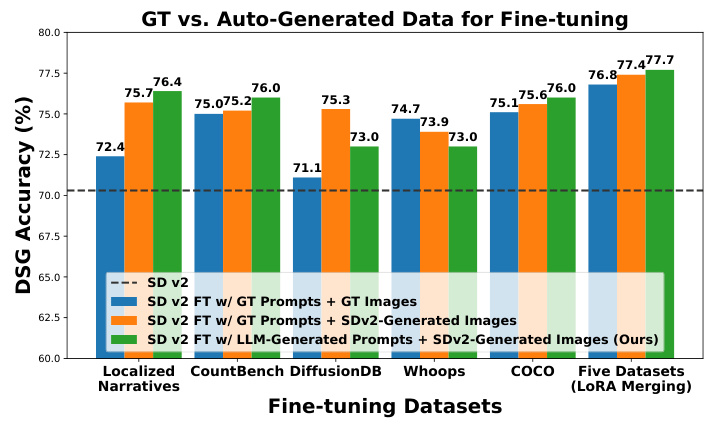
This figure compares the performance of fine-tuning a Stable Diffusion v2 model using different types of image-text pairs. The x-axis shows the datasets used for fine-tuning (Localized Narratives, CountBench, DiffusionDB, Whoops, COCO, and a combined dataset using LoRA merging). The y-axis represents the DSG accuracy achieved after fine-tuning. Four bars are presented for each dataset: a dashed line representing the baseline accuracy of the un-finetuned SD v2 model, and three bars showing the accuracy after fine-tuning with ground truth prompts and images, ground truth prompts and automatically generated images from SDv2, and LLM-generated prompts and automatically generated images from SDv2 (the SELMA approach). The results show that SELMA achieves comparable or even slightly better performance than using ground truth data for fine-tuning.
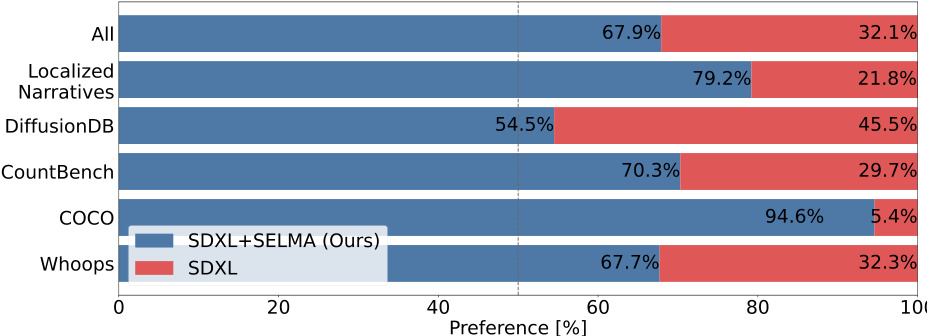
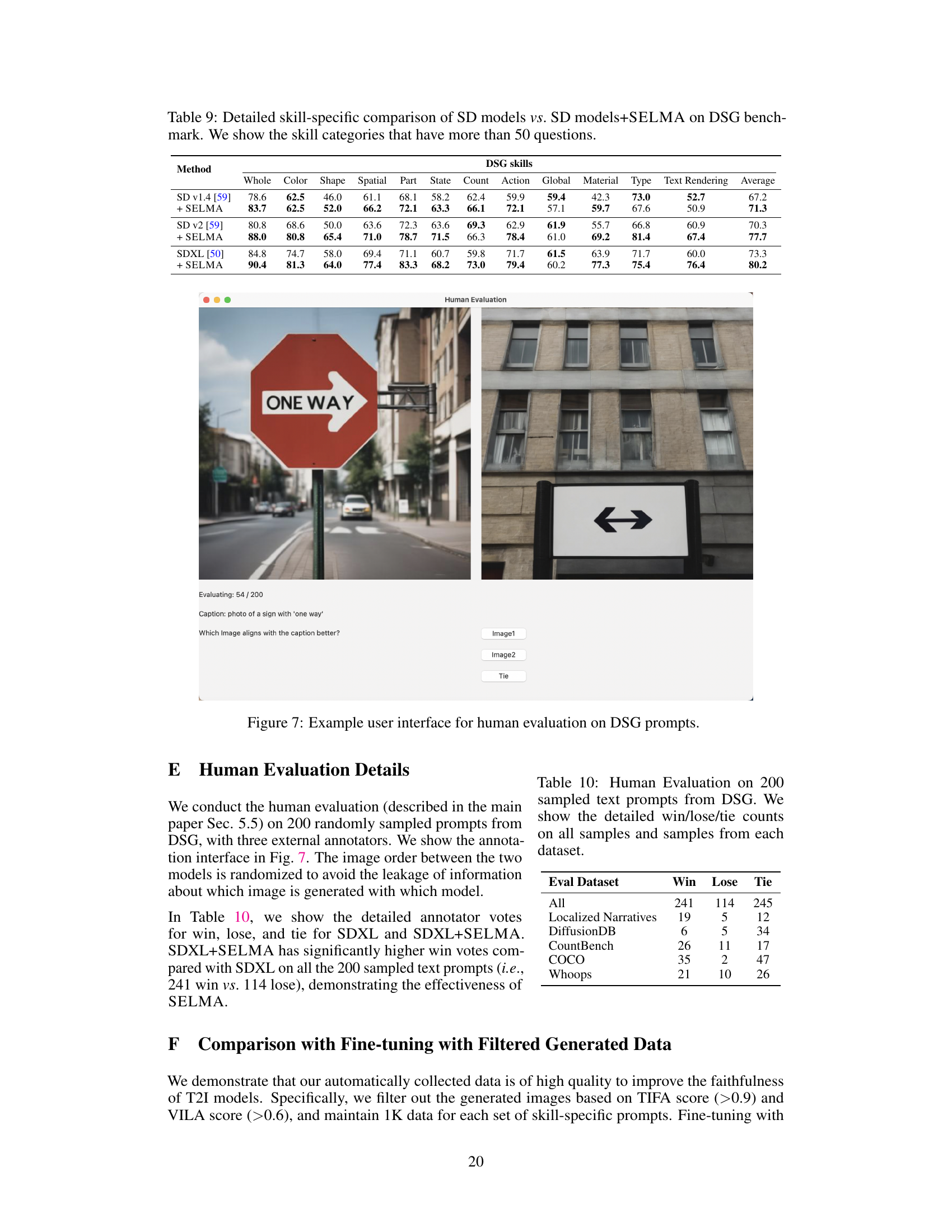
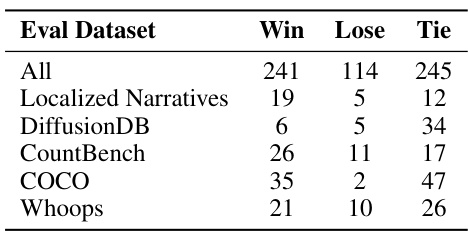
This figure displays the results of a human evaluation comparing the image generation performance of SDXL and SDXL+SELMA (the proposed method). The evaluation involved 200 text prompts from the diverse and challenging DSG benchmark, with three human annotators rating each image pair. For each prompt, annotators chose which image (generated by SDXL or SDXL+SELMA) better matched the prompt description. The bar chart shows the percentage of times SDXL+SELMA was preferred over SDXL for each subset of prompts in the DSG dataset, as well as overall. The results clearly illustrate that SDXL+SELMA significantly outperforms SDXL across different prompt types.

This figure compares three different approaches to fine-tuning text-to-image models. (a) shows supervised fine-tuning, where the model is trained on existing image-text datasets. (b) illustrates fine-tuning based on human preferences, where humans rate image quality and the model learns to match those preferences. (c) introduces the SELMA approach, which uses a large language model (LLM) and a text-to-image model to automatically generate image-text pairs for various skills, then trains and merges skill-specific expert models for improved faithfulness.

This figure compares three different approaches for fine-tuning text-to-image models: supervised fine-tuning using existing datasets, fine-tuning based on human preference annotations, and the proposed SELMA method. SELMA leverages LLMs and a T2I model to automatically generate image-text pairs, then fine-tunes skill-specific experts before merging them into a single multi-skill model, avoiding the need for human annotation or preference ranking.
This figure compares three different approaches for fine-tuning text-to-image models: (a) Supervised Fine-tuning (SFT) uses existing image-text datasets for training, (b) Fine-tuning with Human Preference uses human annotations to train models to maximize human preference, and (c) SELMA, the proposed method, automatically generates image-text pairs with an LLM and a T2I model, then fine-tunes the model on those generated pairs.
This figure compares three different approaches for fine-tuning text-to-image models. (a) shows supervised fine-tuning, where a pre-trained model is further trained on a labeled image-text dataset. (b) illustrates fine-tuning with human preferences, where human feedback (rankings or scores) guides model training. (c) introduces SELMA, which generates its own image-text pairs using an LLM (large language model) and a T2I model, then trains skill-specific models that are finally merged into one.
More on tables
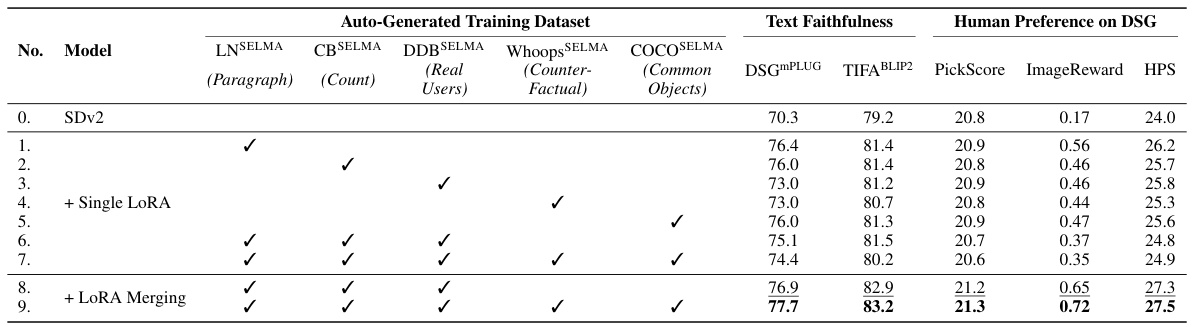
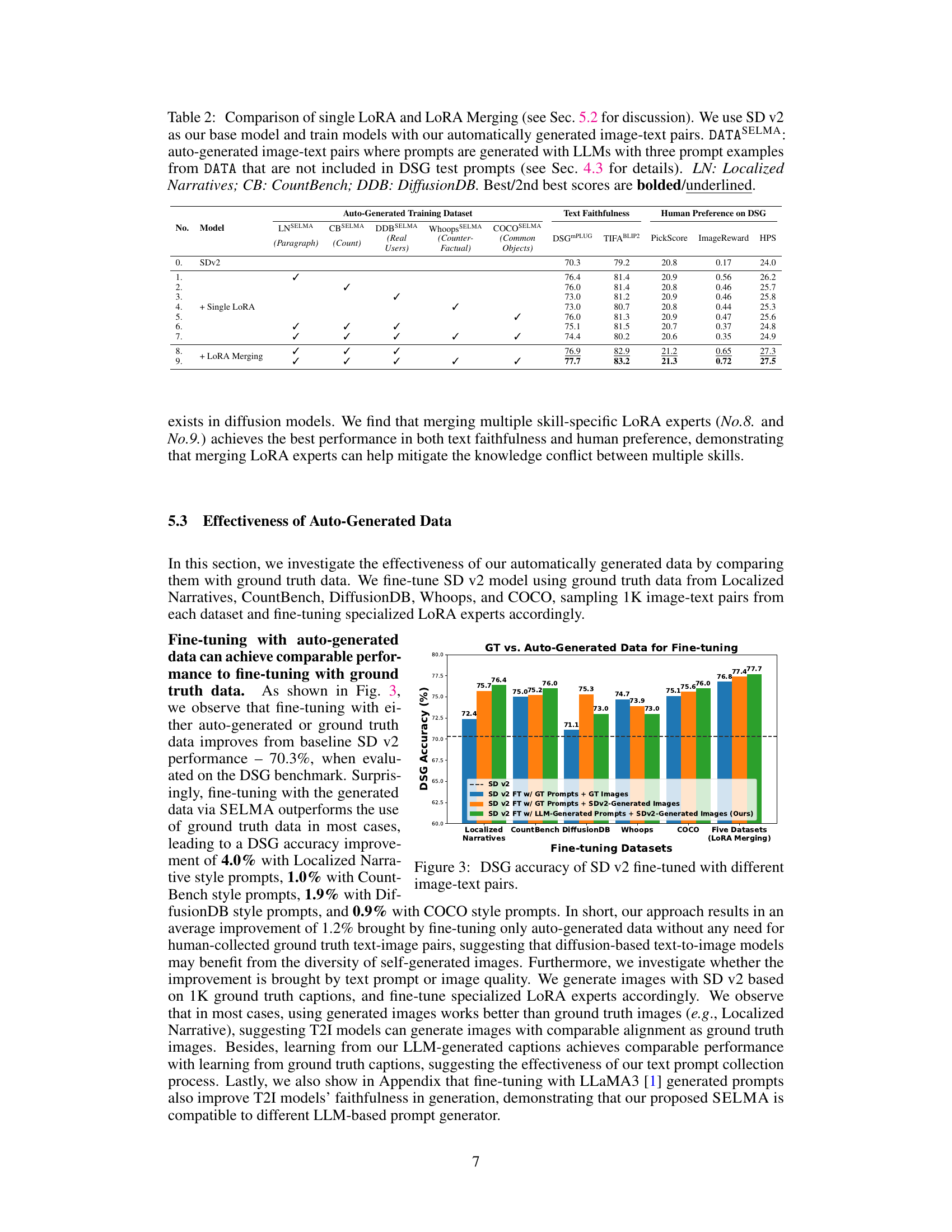
This table compares different training methods for the text-to-image model using automatically generated image-text pairs. It contrasts the performance of training a single LoRA (Low-Rank Adaptation) model across all datasets versus training multiple skill-specific LoRA experts and then merging them. The results are evaluated using several metrics including text faithfulness and human preference scores on the DSG benchmark. The table shows that merging multiple skill-specific LoRA models generally outperforms training a single LoRA model across all datasets, indicating the effectiveness of the proposed SELMA method in mitigating knowledge conflict during multi-skill learning.
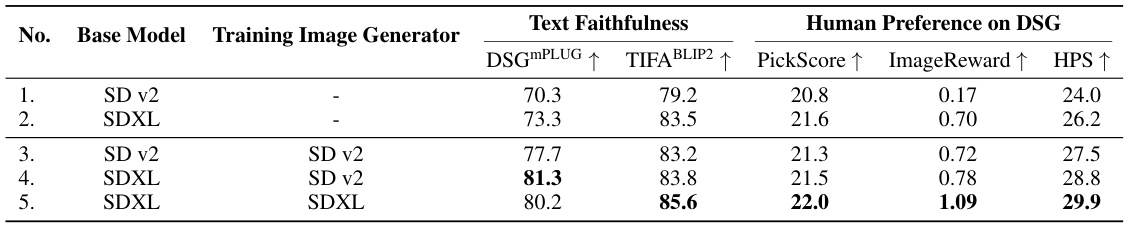
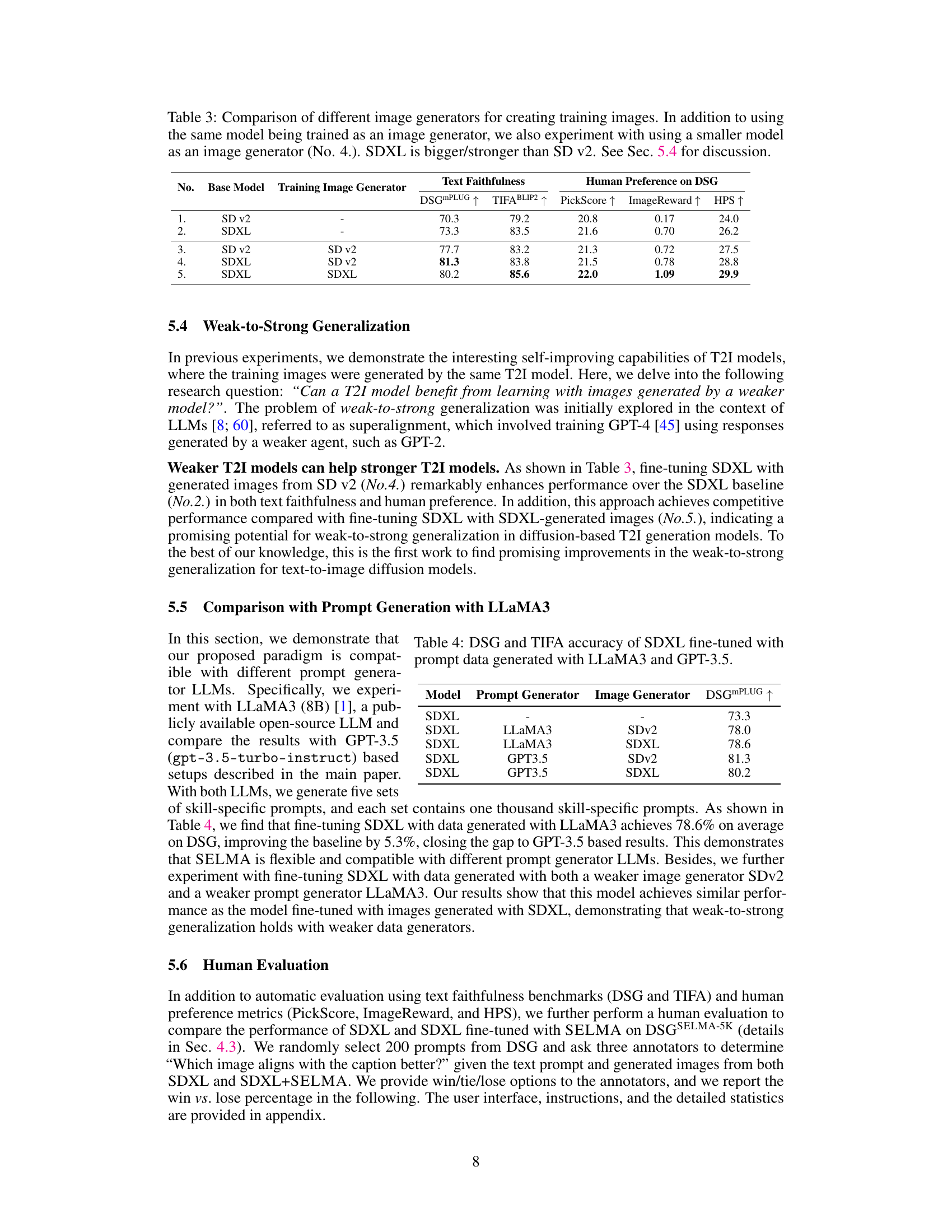
This table compares the performance of different text-to-image models when fine-tuned using images generated by themselves or by a weaker model. It shows that fine-tuning a stronger model (SDXL) with images from a weaker model (SD v2) can achieve comparable or even better results in terms of text faithfulness and human preference compared to fine-tuning with images generated by the same stronger model. This suggests a promising ‘weak-to-strong’ generalization capability in text-to-image models.

This table compares the performance of SDXL models fine-tuned using prompts generated by two different large language models (LLMs): LLaMA3 and GPT-3.5. It shows the impact of different prompt generation methods on the model’s performance as measured by the DSG and TIFA metrics. Two image generators (SDv2 and SDXL) were also used to generate the image data for training. The results highlight how prompt generation and the image source for fine-tuning training data impact the final performance.

This table compares the performance of different fine-tuning methods on the Stable Diffusion v2 model using the automatically generated image-text data. It specifically contrasts the performance of the baseline SD v2 model against three variations: 1) SELMA with LoRA Merging, 2) SELMA with LoRA Merging and Direct Preference Optimization (DPO), and 3) SELMA with Mixture of Lora Experts (MoE-LoRA). The comparison uses text faithfulness metrics (DSGmPLUG, TIFA BLIP2) and human preference metrics (PickScore, ImageReward, HPS) on the Diffusion Scene Graph (DSG) dataset. It shows that simple LoRA Merging, as implemented in SELMA, achieves the best overall performance.
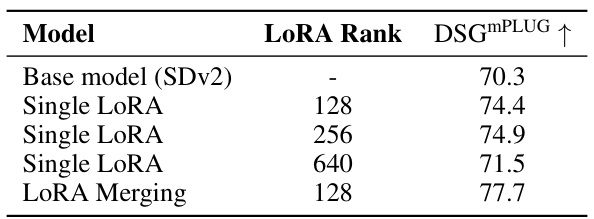
This table compares different training methods for the SELMA model, specifically focusing on the impact of using a single LoRA (Low-Rank Adaptation) versus merging multiple LoRAs. It shows the performance on various metrics (DSG, TIFA, BLIP, PickScore, ImageReward, HPS) using different combinations of automatically generated datasets (LN, CB, DDB, Whoops, COCO). The results highlight the effectiveness of merging multiple skill-specific LoRAs to mitigate knowledge conflict and improve overall performance.

This table compares SELMA’s performance against other text-to-image alignment methods across multiple metrics. It evaluates both text faithfulness (how accurately the generated image matches the text description) and human preference (how aesthetically pleasing and relevant the generated images are to humans). The comparison is done using three different state-of-the-art text-to-image models (Stable Diffusion v1.4, v2, and XL) as baselines. The table highlights that SELMA consistently achieves the best results across all metrics and base models.

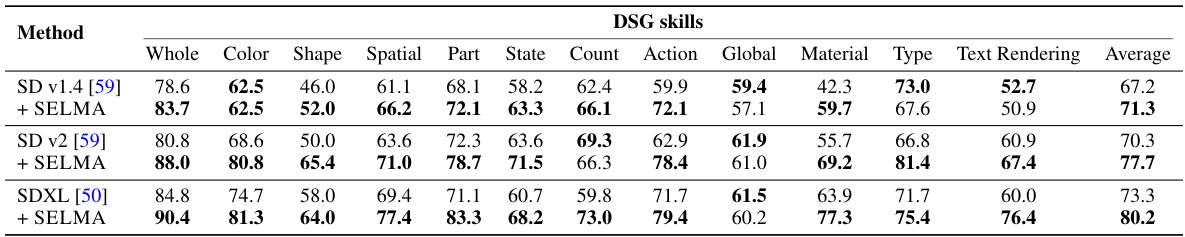
This table presents a detailed comparison of the performance of Stable Diffusion (SD) models (versions 1.4, v2, and XL) and their corresponding SELMA-enhanced versions across various image generation skills evaluated by the TIFA benchmark. It breaks down the accuracy scores for each model on specific skills like recognizing animals/humans, objects, locations, activities, colors, spatial relationships, attributes, food items, counts, materials, other elements, shapes, and provides an overall average score for each model.
This table compares different training methods for the text-to-image model using automatically generated data. It shows the results of training with single LoRA models on individual skill-specific datasets, training with a single LoRA model on a mix of datasets and using LoRA merging with multiple skill-specific LoRA experts. The metrics used are text faithfulness (DSGMPLUG, TIFA, BLIP2) and human preference (PickScore, ImageReward, HPS) on the DSG benchmark. The best performing methods are highlighted.
This table compares different training methods for the Stable Diffusion v2 model using automatically generated image-text datasets. It contrasts single LoRA (Low-Rank Adaptation) training on different skill-specific datasets with the approach of training multiple skill-specific LoRAs separately and then merging them. The table shows the results across several metrics, evaluating text faithfulness and human preference using various datasets (LN, CB, DDB, Whoops, COCO). The results demonstrate the effectiveness of the LoRA merging technique.

This table compares SELMA against several other text-to-image alignment methods across various metrics. These metrics measure how well the generated images match the input text descriptions (text faithfulness) and how well they align with human preferences. The comparison is done using three different state-of-the-art text-to-image models (Stable Diffusion v1.4, v2, and XL) as baselines. The table highlights that SELMA consistently outperforms other methods across all metrics and base models.
Full paper#