↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Deep neural networks (DNNs) are powerful but often lack interpretability; post-hoc explanation methods are unreliable. Existing inherently interpretable DNNs require training from scratch, which is expensive for large models. This is a major limitation in the field.
This paper introduces ‘B-cosification,’ a novel method to transform pre-trained DNNs into inherently interpretable models. It leverages architectural similarities between standard and B-cos networks for efficient fine-tuning. The results show that B-cosified models match or exceed the performance of models trained from scratch at a fraction of the cost while showing high interpretability. This is particularly relevant for large-scale models where training from scratch is highly expensive.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers seeking to enhance the interpretability of deep learning models. It presents a novel and cost-effective method for transforming existing pre-trained models into inherently interpretable ones, a significant challenge in the field. The findings open new avenues for research in model explainability and the development of efficient, interpretable AI systems.
Visual Insights#
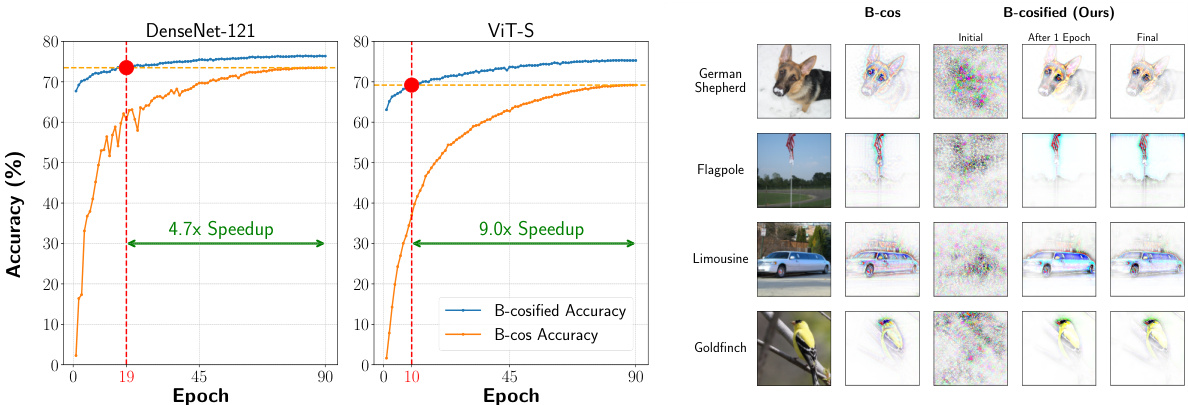
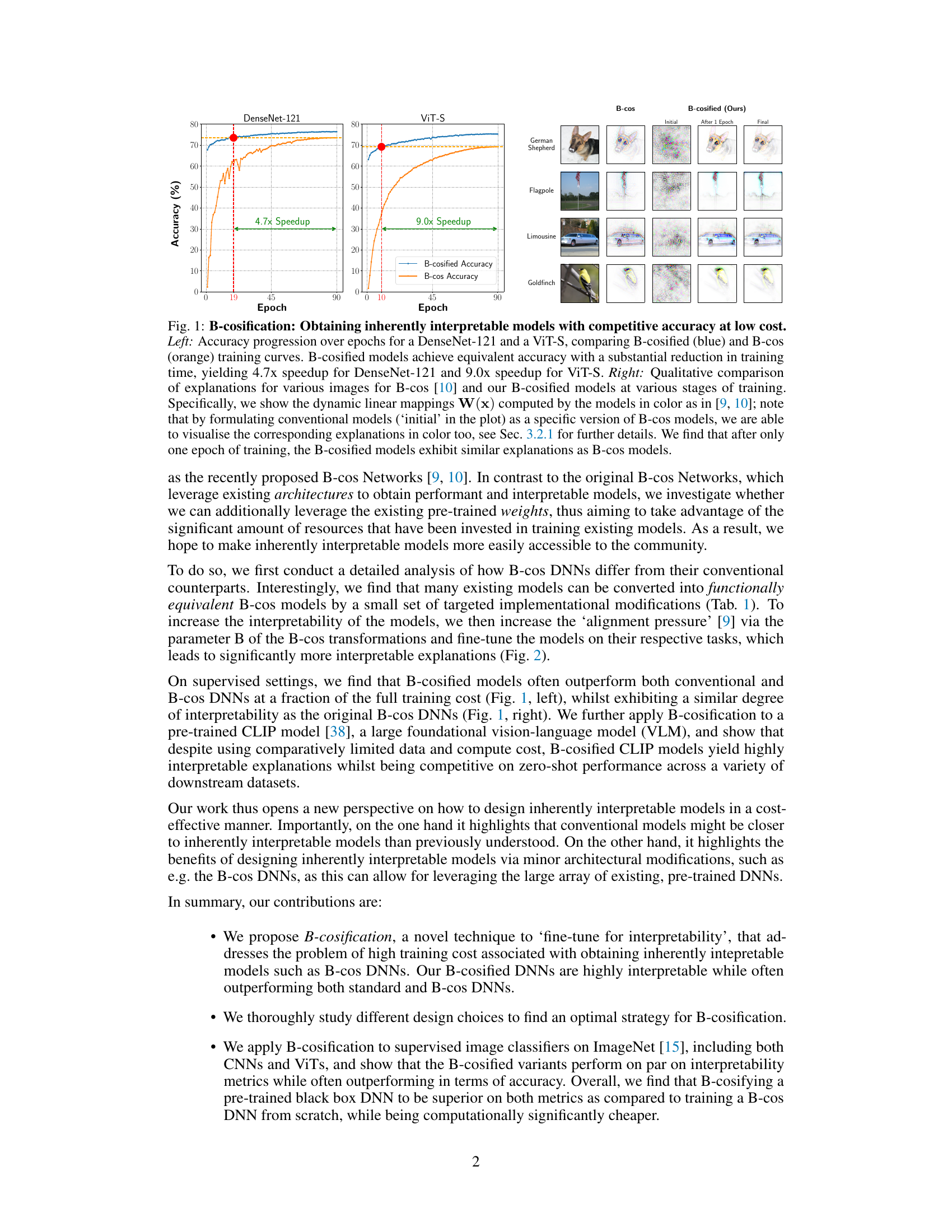
This figure demonstrates the effectiveness of B-cosification in achieving high accuracy and interpretability with significantly reduced training time. The left panel shows training curves for DenseNet-121 and ViT-S, comparing the B-cosified approach (blue) to the standard B-cos approach (orange). The B-cosified method achieves comparable accuracy much faster. The right panel provides a qualitative comparison of the explanations generated by both methods across different stages of training, visually illustrating the similarity of explanations obtained by B-cosification and the standard B-cos method.
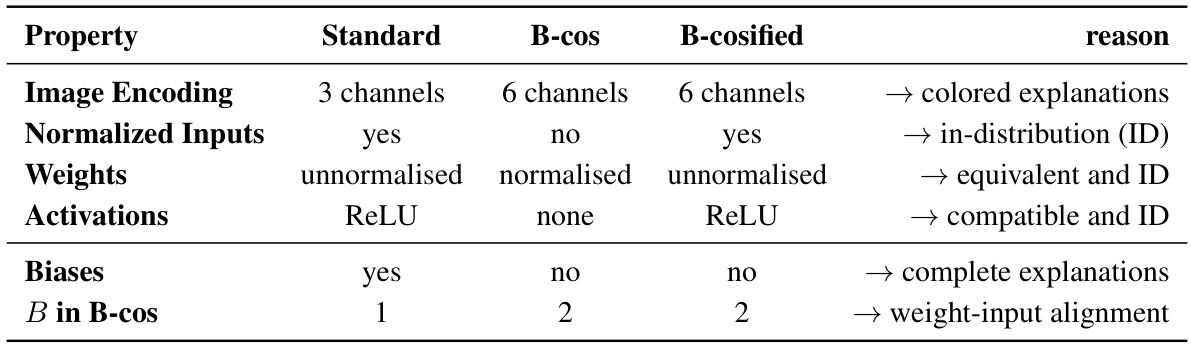
This table summarizes the key differences between standard deep neural networks (DNNs), B-cos networks, and the proposed B-cosified networks. It highlights aspects such as image encoding, input normalization, weight normalization, activation functions, biases, and the hyperparameter B in the B-cos transformation. The ‘reason’ column briefly explains the motivation behind each design choice in B-cosified networks to achieve inherent interpretability. The table facilitates a clear understanding of the transformations involved in converting standard DNNs into B-cos networks and how the B-cosification technique bridges these differences.
In-depth insights#
B-cos Network Intro#
A hypothetical section titled ‘B-cos Network Intro’ would likely introduce the core concepts behind B-cos networks. It would emphasize inherent interpretability as a primary design goal, contrasting with the post-hoc explanation methods common in traditional deep learning. The introduction would likely highlight how B-cos networks achieve interpretability through architectural modifications, primarily replacing standard linear layers with B-cos transformations. This replacement introduces a stronger alignment between inputs and weights, resulting in explanations that are more model-faithful and easier for humans to understand. A key aspect of the introduction would be to emphasize the dynamic linear nature of B-cos networks and how this property facilitates the generation of insightful model explanations. The introduction would set the stage for subsequent sections detailing the network’s architecture, training procedures, and empirical evaluations of its performance and interpretability.
B-cosification Method#
The core idea behind “B-cosification” is an innovative method to transform pre-trained deep neural networks (DNNs) into inherently interpretable models. It leverages the architectural similarities between standard DNNs and B-cos networks, modifying the pre-trained models with minimal effort. Key modifications include replacing linear layers with B-cos transformations and removing biases. This process significantly reduces the training cost compared to training interpretable models from scratch. The method’s effectiveness stems from the architectural similarities between standard and B-cos DNNs, allowing for efficient fine-tuning. The resulting models exhibit comparable accuracy and significantly improved interpretability, as evidenced by qualitative and quantitative evaluations. A crucial aspect is fine-tuning for interpretability by adjusting the hyperparameter ‘B’ in the B-cos transformation, which enhances weight-input alignment. The approach demonstrates its practicality through applications to various architectures and a large-scale vision-language model (CLIP), exhibiting competitive zero-shot performance and improved interpretability. The significance lies in its potential to democratize access to inherently interpretable models, especially with large pre-trained models where training from scratch is expensive and computationally demanding.
CLIP Model Tuning#
CLIP Model Tuning presents a fascinating area of research, focusing on adapting the pre-trained CLIP model for specific downstream tasks while retaining its inherent multi-modal capabilities. Effective tuning strategies are crucial, as they determine the model’s performance and efficiency. Approaches may involve fine-tuning the entire model or specific components, such as the image or text encoders, with varying degrees of data and computational resources required. A key consideration is balancing performance gains with preserving CLIP’s original strengths. Overly aggressive tuning might compromise zero-shot capabilities, so a nuanced approach is essential. Investigating different optimization techniques, learning rates, and regularization methods could significantly improve tuning outcomes. Furthermore, exploring innovative loss functions tailored to specific downstream tasks could also enhance the effectiveness of CLIP model tuning. The potential benefits include improved accuracy, efficiency, and interpretability depending on the application and tuning strategy. Careful evaluation metrics are critical to assess the success of these tuning efforts.
Interpretability Gains#
The concept of “Interpretability Gains” in the context of a deep learning research paper refers to the improvements achieved in understanding and explaining the model’s decision-making process. This is a crucial aspect of machine learning, as opaque models can hinder trust and adoption. Quantitative metrics, such as accuracy improvements and reduced training time, might demonstrate these gains. Qualitative evaluations are also essential, using visualizations of model internals or feature attribution methods to showcase how easily interpretable the resulting models are. The paper likely analyzes these gains across various model architectures (e.g., CNNs, ViTs) and datasets, highlighting the effectiveness of the proposed method in enhancing human understanding of model behavior and revealing the relationships between input data and model predictions. Significant gains indicate a successful approach in transforming complex deep networks into more transparent and explainable systems.
Future of B-cosification#
The “Future of B-cosification” holds exciting potential. Expanding beyond image classification, B-cosification could enhance the interpretability of various deep learning models, including those used in natural language processing, time series analysis, and other domains. Further research should explore optimal B-parameter selection strategies, potentially using adaptive or learned methods, to further improve interpretability without sacrificing accuracy. Investigating the impact of different network architectures and training paradigms on B-cosification’s effectiveness is crucial. The integration with other interpretability techniques like concept-based explanations could lead to more comprehensive model understanding. Finally, applying B-cosification to increasingly larger models and datasets, including foundation models, will be a key challenge and area of significant future development. The overall goal is to make inherent interpretability an accessible and standard feature in future deep learning models.
More visual insights#
More on figures

This figure shows a comparison of the inherent interpretability of a B-cosified CLIP model and a standard CLIP model. The B-cosified model, fine-tuned using the authors’ method, produces more detailed and interpretable linear summaries (visualized in color in the bottom row) compared to GradCAM explanations (middle row) for the same images (top row). The B-cosified CLIP retains zero-shot capabilities.

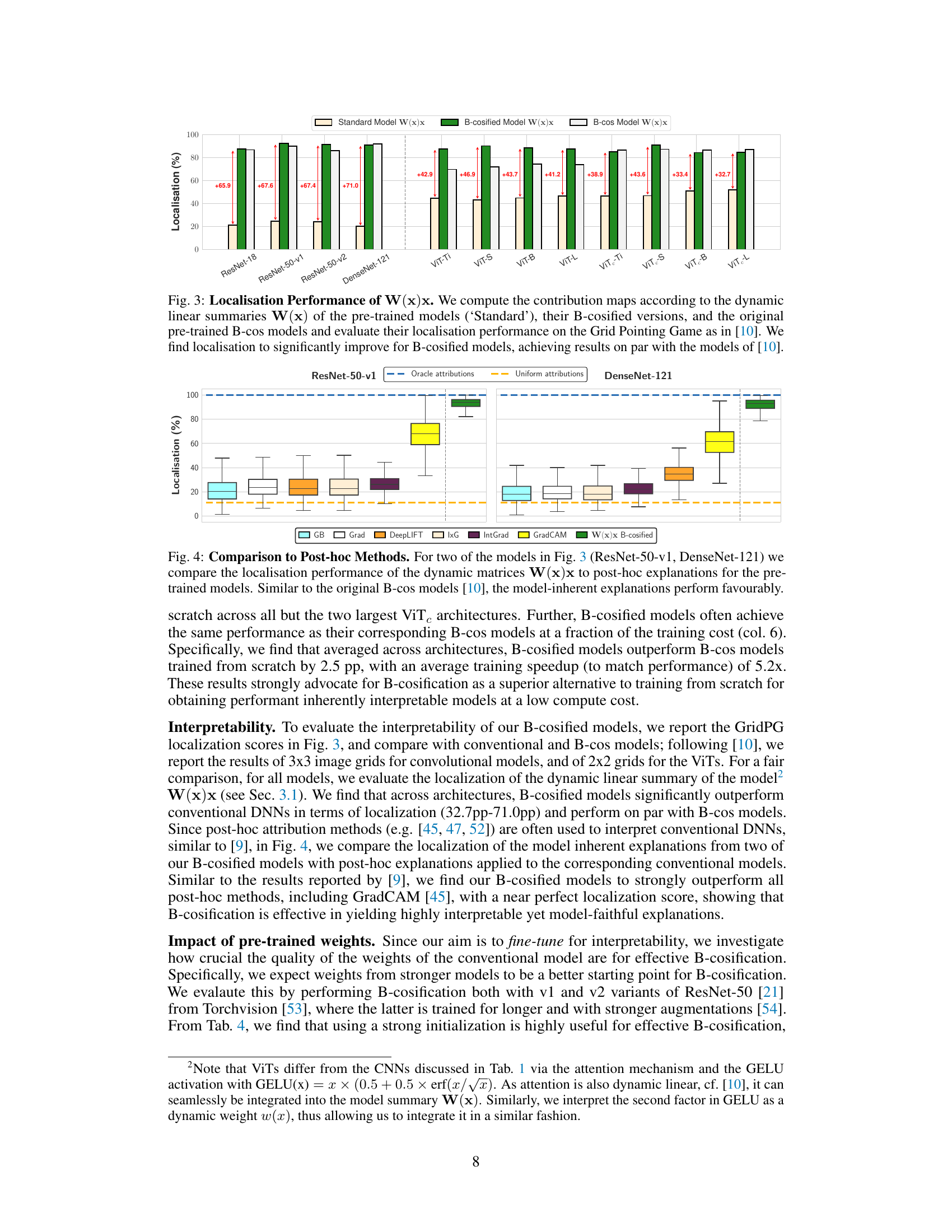
This figure compares the localization performance of the dynamic linear summaries W(x) of pre-trained models, their B-cosified versions, and the original B-cos models. The localization performance is evaluated using the Grid Pointing Game metric from reference [10]. The results show that B-cosified models significantly improve localization compared to standard pre-trained models, achieving similar results to the B-cos models trained from scratch. The figure uses bar graphs to represent the localization scores for each model on different architectures (ResNet-18, ResNet-50-v1, ResNet-50-v2, DenseNet-121, ViT-Ti, ViT-S, ViT-B, ViT-L, and their convolutional counterparts). Numerical values showing improvement are also displayed.

This figure compares the localization performance of model-inherent explanations (W(x)x) with several post-hoc explanation methods for ResNet-50-v1 and DenseNet-121 models. It shows that model-inherent explanations significantly outperform post-hoc methods in terms of localization accuracy, achieving results comparable to the original B-cos models.
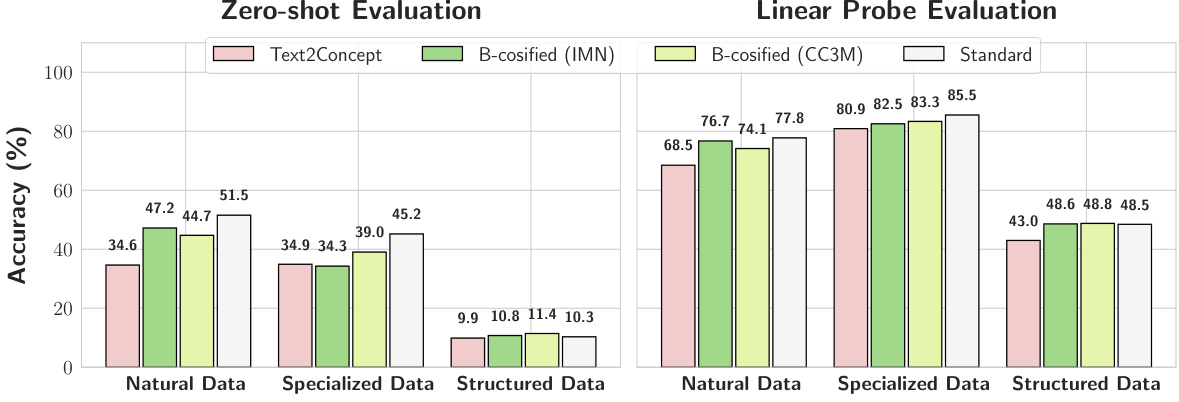
This figure compares the zero-shot and linear probe classification accuracy of different CLIP models on the CLIP Benchmark dataset. The models include the standard pre-trained CLIP, the Text2Concept model, and two B-cosified CLIP models trained on ImageNet and CC3M respectively. The results show that the B-cosified CLIP models generally outperform the Text2Concept model, particularly on natural and specialized data, indicating the effectiveness of the B-cosification technique in improving CLIP’s performance.
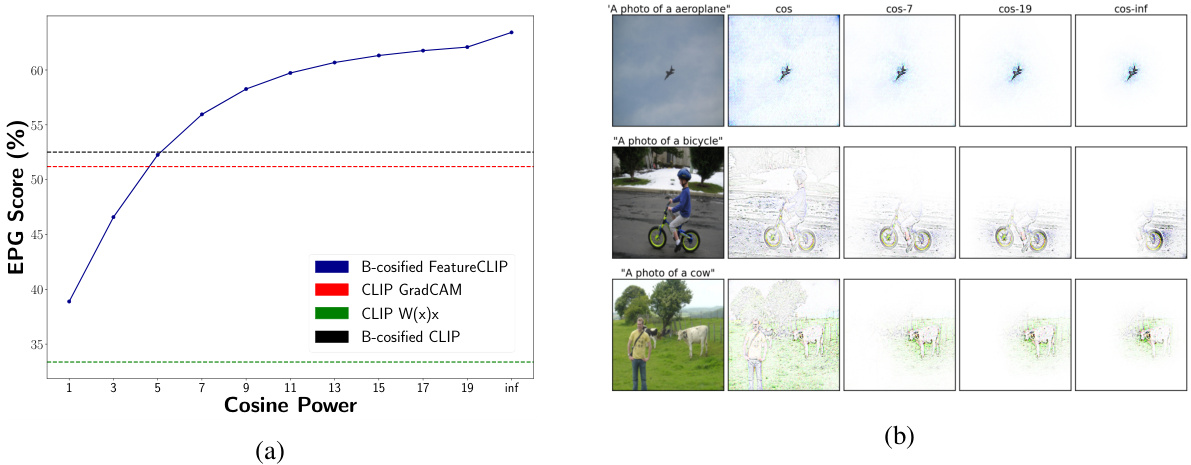
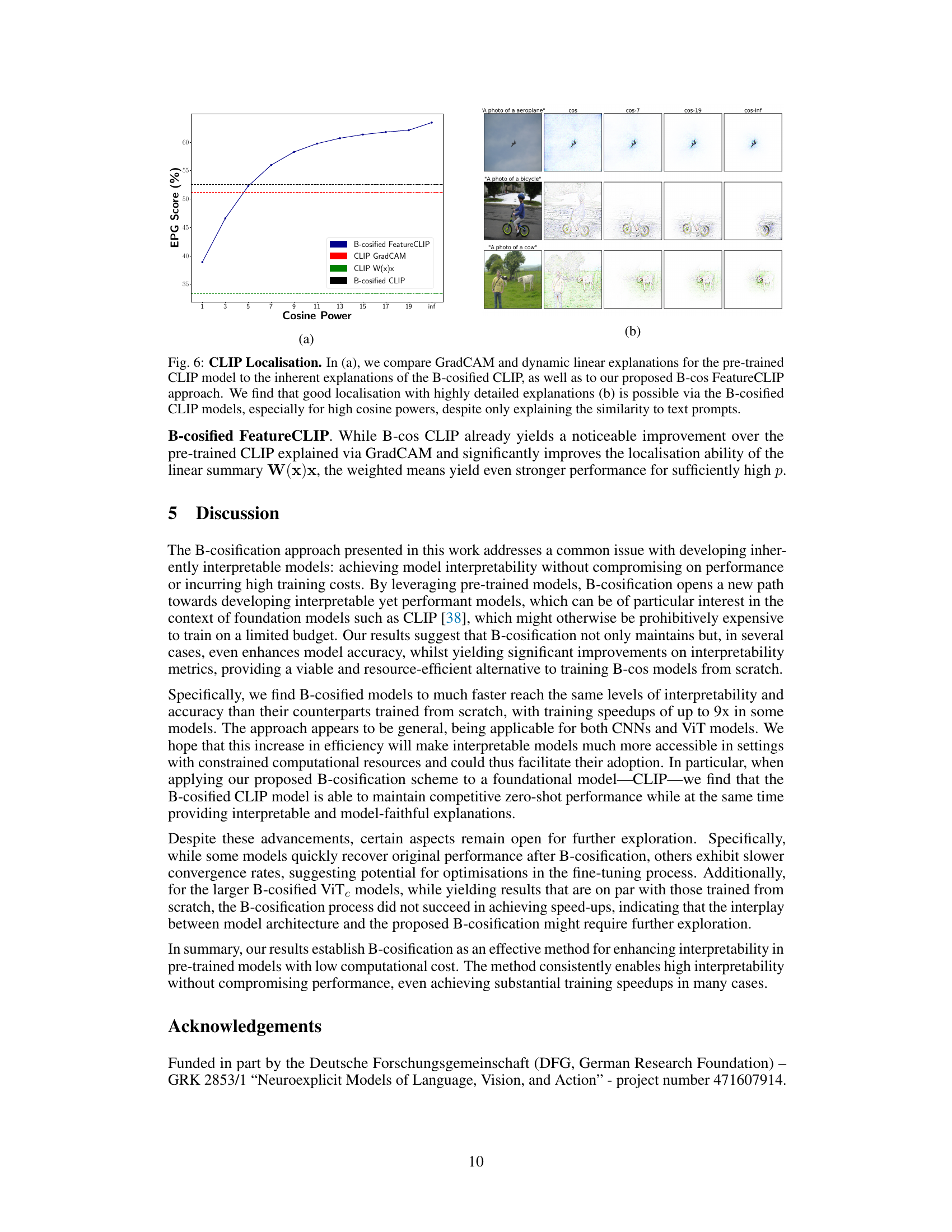
This figure shows a comparison of different methods for localizing objects in images using the CLIP model. Panel (a) presents a graph comparing the EPG (Explanations by Pixel-wise Gradient) score, a measure of localization accuracy, for four methods: B-cosified FeatureCLIP, CLIP GradCAM, CLIP W(x)x (dynamic linear summaries of CLIP), and B-cosified CLIP. The graph shows the EPG score as a function of cosine power (a hyperparameter that controls the strength of alignment between image and text embeddings). Panel (b) shows qualitative examples of localization using the B-cosified CLIP model, illustrating the ability of the method to accurately and precisely locate objects within images by using text prompts.

This figure compares the performance of B-cosified models versus standard and B-cos models. It shows accuracy progression over epochs for a DenseNet-121 and a ViT-S, demonstrating that B-cosified models achieve similar accuracy to B-cos models with significantly reduced training time. Qualitative comparison of explanations from various image examples for B-cos and B-cosified models are also included, highlighting the similarity in explanations obtained after just one epoch of training.

This figure displays additional qualitative examples to demonstrate the effect of increasing the cosine power (p) in the B-cosified CLIP model. The images show that with higher cosine power, the explanations become more focused and interpretable. Fine details, often missed in the original CLIP explanations, are now highlighted, leading to a better understanding of the model’s decision-making process.

This figure demonstrates the effectiveness of B-cosification in achieving both high accuracy and interpretability with significantly reduced training time compared to traditional B-cos models. The left panel shows training curves, highlighting the faster convergence of B-cosified models. The right panel provides a qualitative comparison of explanations generated by B-cos and B-cosified models, illustrating the similarity of explanations achieved by B-cosified models after just one epoch of training.
More on tables

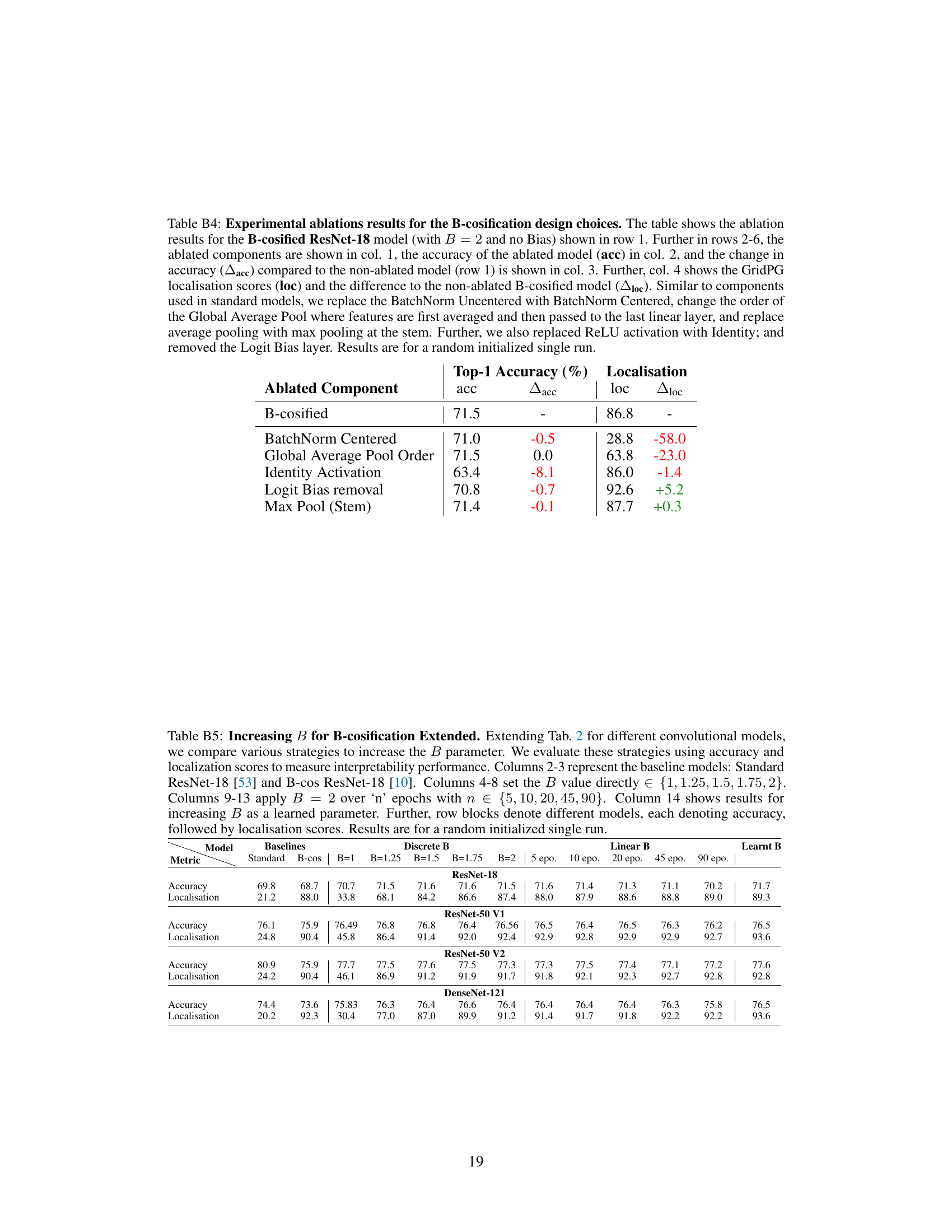
This table presents ablation results on how to increase the B hyperparameter in the B-cosification process. It compares different strategies for increasing B, including setting B to a discrete value, linearly interpolating B over a set number of epochs, or learning B as a trainable parameter. The results are evaluated in terms of accuracy and localization performance, using ResNet-18 as the model. The table shows that setting B=2 immediately yields good results and outperforms linear approaches.

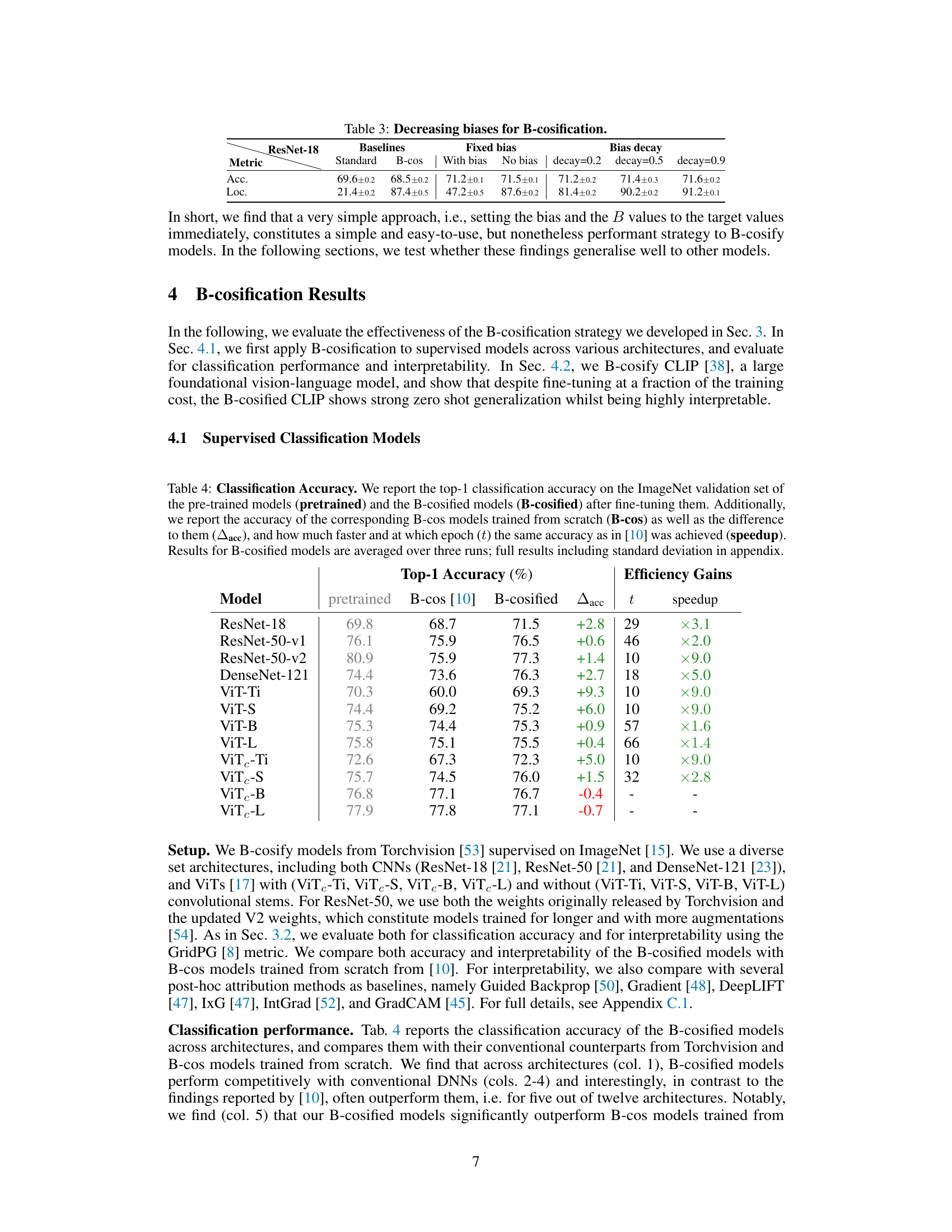
This table presents ablation study results on the impact of removing biases for B-cosification. It compares different strategies for decreasing the bias parameter across various convolutional models and evaluates their performance using accuracy and localization scores. The baselines include the standard model and the B-cos model. The strategies include removing all biases, using bias decay with different values (0.2, 0.5, 0.9), and maintaining the bias as in the original model. The table shows the results separately for accuracy and localization performance metrics for each strategy and model.

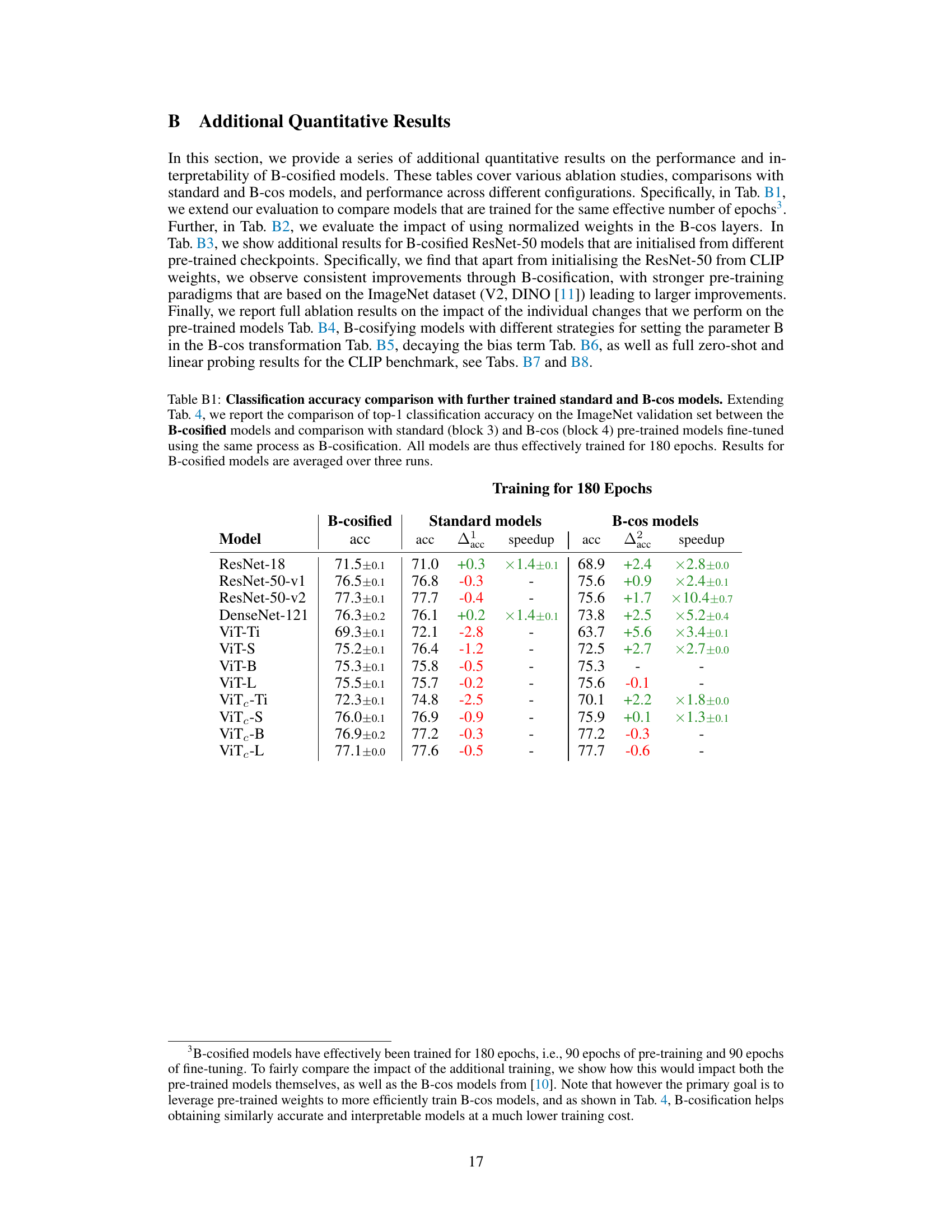
This table presents a comparison of the top-1 accuracy achieved on the ImageNet validation set by three different model types: pre-trained models, B-cos models (trained from scratch), and B-cosified models (fine-tuned from pre-trained models). For each model type, the accuracy is reported, along with the difference in accuracy compared to the B-cos models. Additionally, the table shows how much faster the B-cosified models reached a comparable accuracy to the B-cos models and at which epoch this was achieved, showcasing the efficiency gains of the B-cosification method.

This table compares the classification accuracy on ImageNet for three types of models: pre-trained models, B-cosified models (the models from the paper), and B-cos models trained from scratch. It highlights that B-cosified models achieve comparable or even superior accuracy to both pre-trained and B-cos models, often at a fraction of the training cost (indicated by the speedup). The ‘acc’ column shows the difference in accuracy compared to the B-cos models, providing insight into the performance improvement gained through B-cosification.

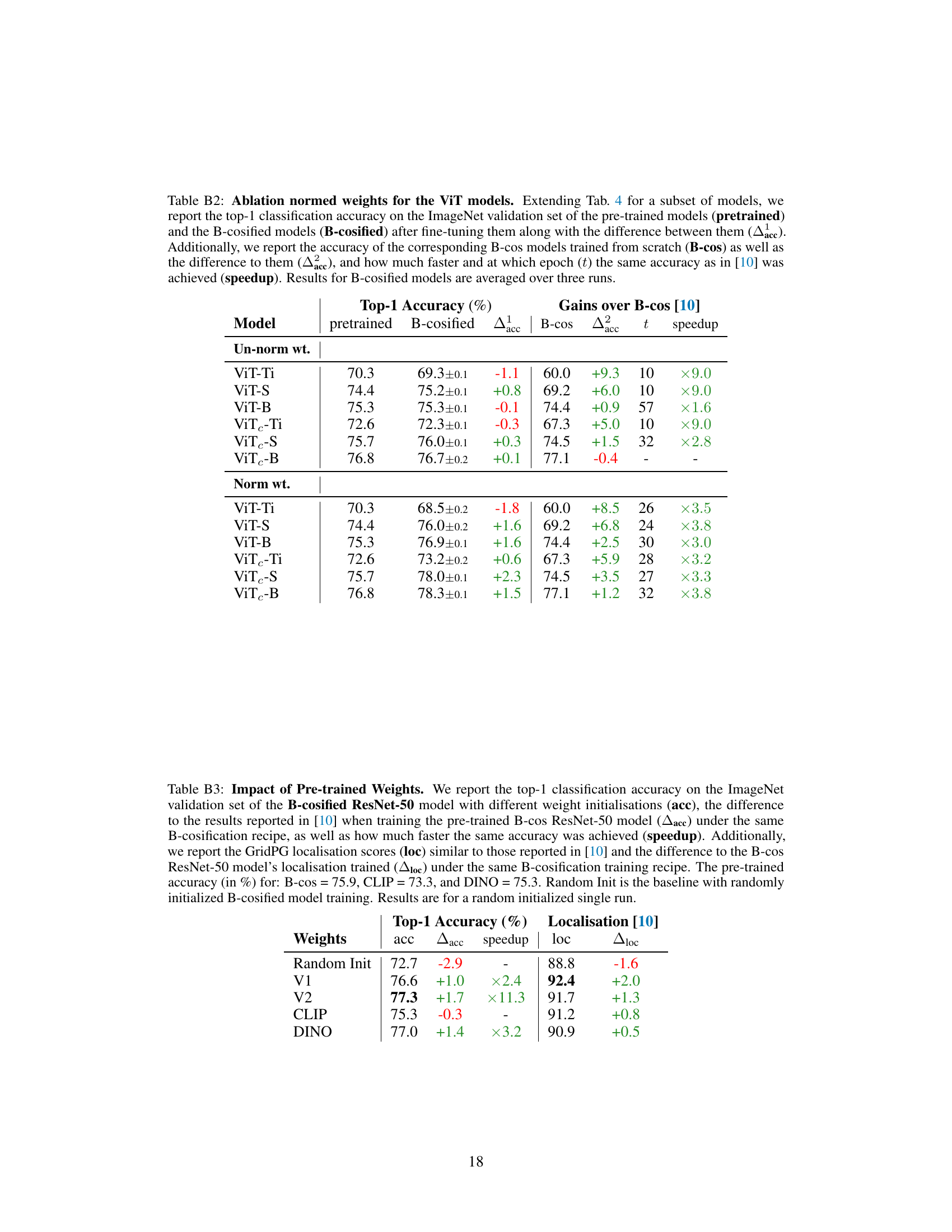
This table presents an ablation study on the impact of using normalized weights in the B-cos layers. It compares the performance of B-cosified ViT models with and without weight normalization against their corresponding B-cos counterparts trained from scratch. The metrics reported are top-1 accuracy on ImageNet validation set, accuracy difference compared to B-cos models (Δacc), accuracy gain over B-cos models (Δ2acc), the epoch at which the B-cosified model matches the accuracy of the B-cos model (t), and the speedup achieved.
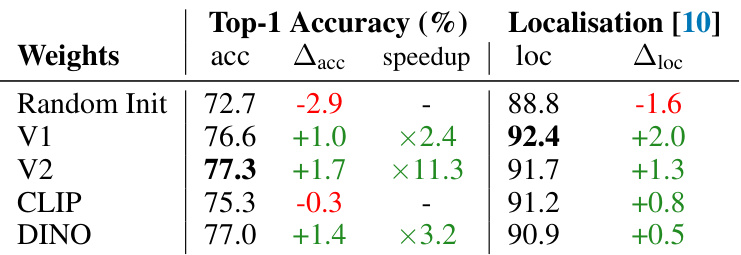
This table shows the impact of using different pre-trained weights (Random Init, V1, V2, CLIP, DINO) on the performance of B-cosified ResNet-50 models. It compares top-1 accuracy, accuracy gain relative to the original B-cos model, training speedup, localization score, and the improvement in localization score compared to the original B-cos model.

This table presents ablation study results for the B-cosification process on a ResNet-18 model. It systematically removes or modifies components of the B-cosified model to analyze their impact on both classification accuracy and localization performance (interpretability). The table shows the accuracy and localization score for the baseline B-cosified model and for models with various components removed or modified. The changes in accuracy and localization are also shown, allowing for a detailed understanding of each component’s contribution to the overall performance.
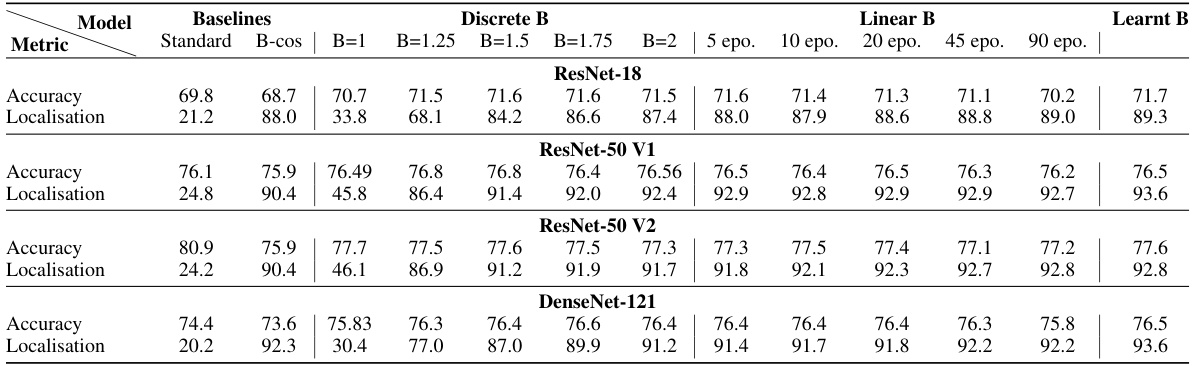
This table presents an ablation study on how to increase the B parameter in the B-cosification method. It compares different strategies for increasing B (discrete values, linear increase, and learning B) across several convolutional neural network models (ResNet-18, ResNet-50 v1, ResNet-50 v2, and DenseNet-121). For each model, it reports accuracy and localization scores (a measure of interpretability) to evaluate the effectiveness of each strategy. The results show the effect of different B values and training epochs on both accuracy and localization.
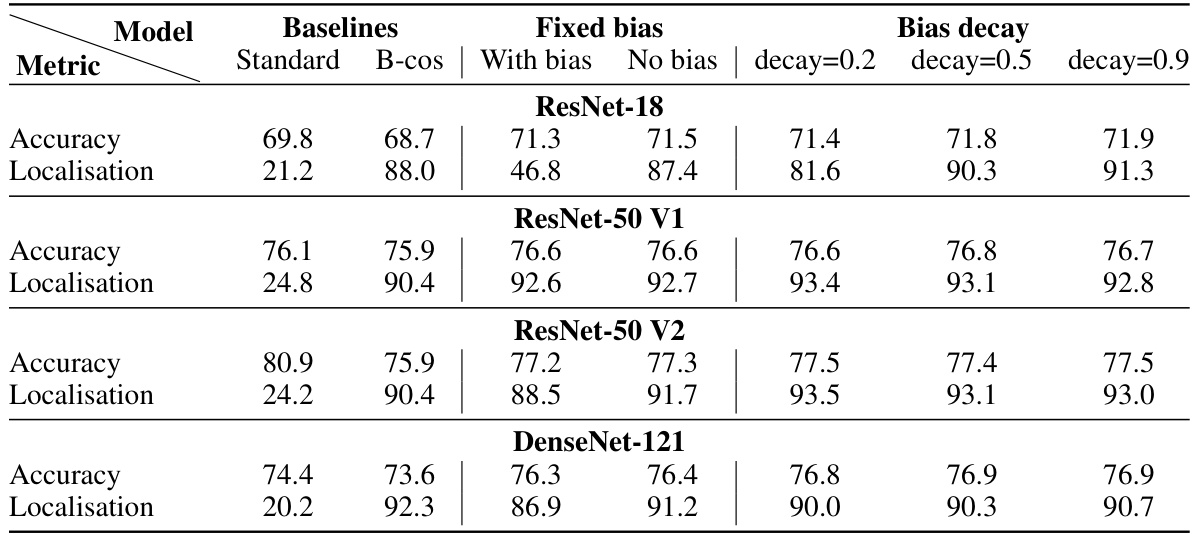
This table presents an ablation study on strategies for decreasing biases during B-cosification of various convolutional neural networks. It compares different methods, including removing biases completely and applying weight decay with varying coefficients (λ). The results are evaluated in terms of classification accuracy and localization performance (GridPG metric), offering a detailed comparison across different bias handling approaches. The goal is to find the best strategy for reducing bias while maintaining or improving model performance and interpretability.
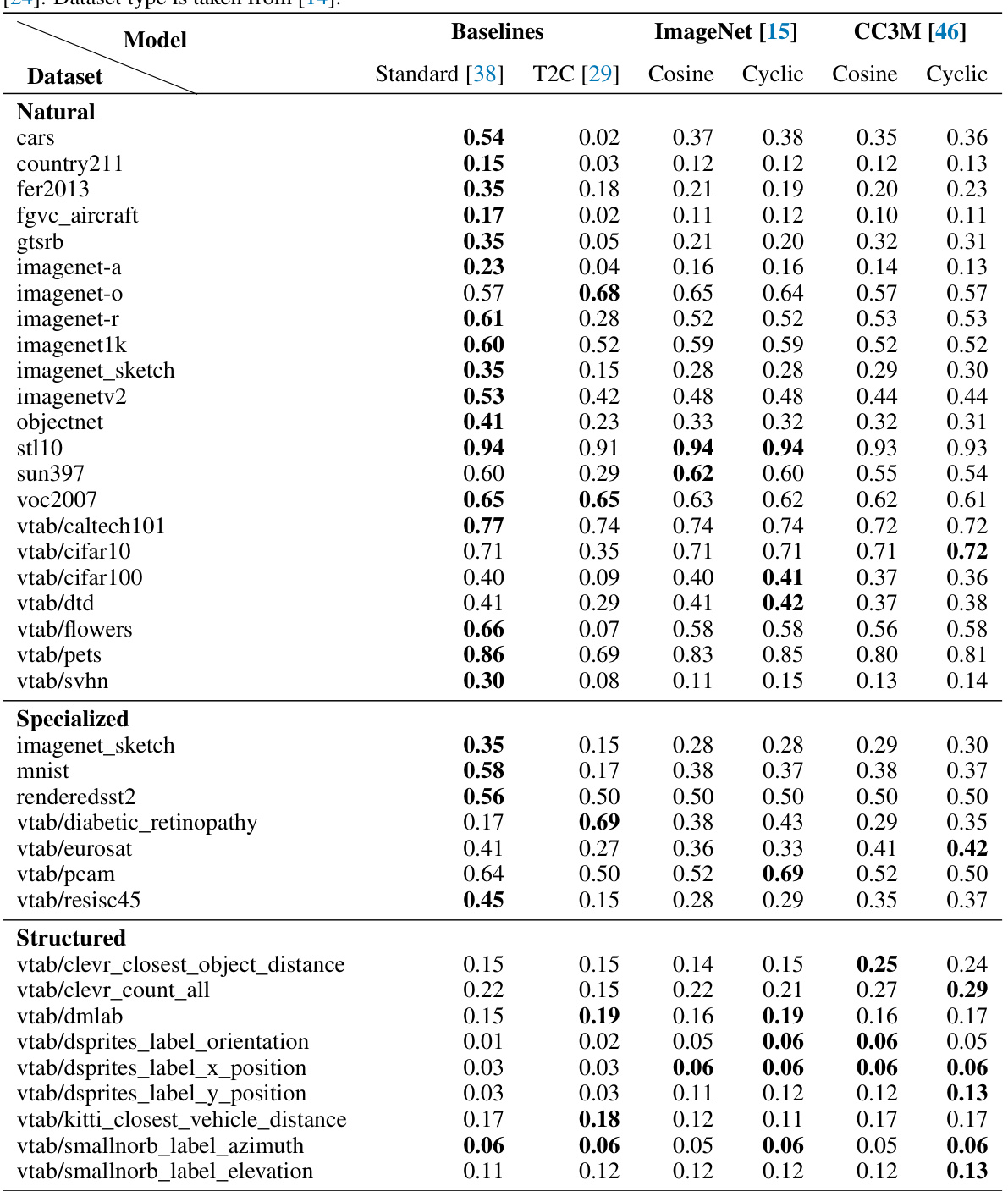
This table presents the zero-shot performance of different CLIP-based models on 38 datasets using the CLIP benchmark. It compares the standard CLIP, the Text2Concept approach, and two B-cosified CLIP models (trained on ImageNet and CC3M datasets respectively) using cosine and cyclic learning schedulers. Scores are presented as the accuracy, with bold values indicating those within the 99.5% Clopper-Pearson confidence interval of the dataset’s top score. The table is organized by dataset type (Natural, Specialized, Structured).
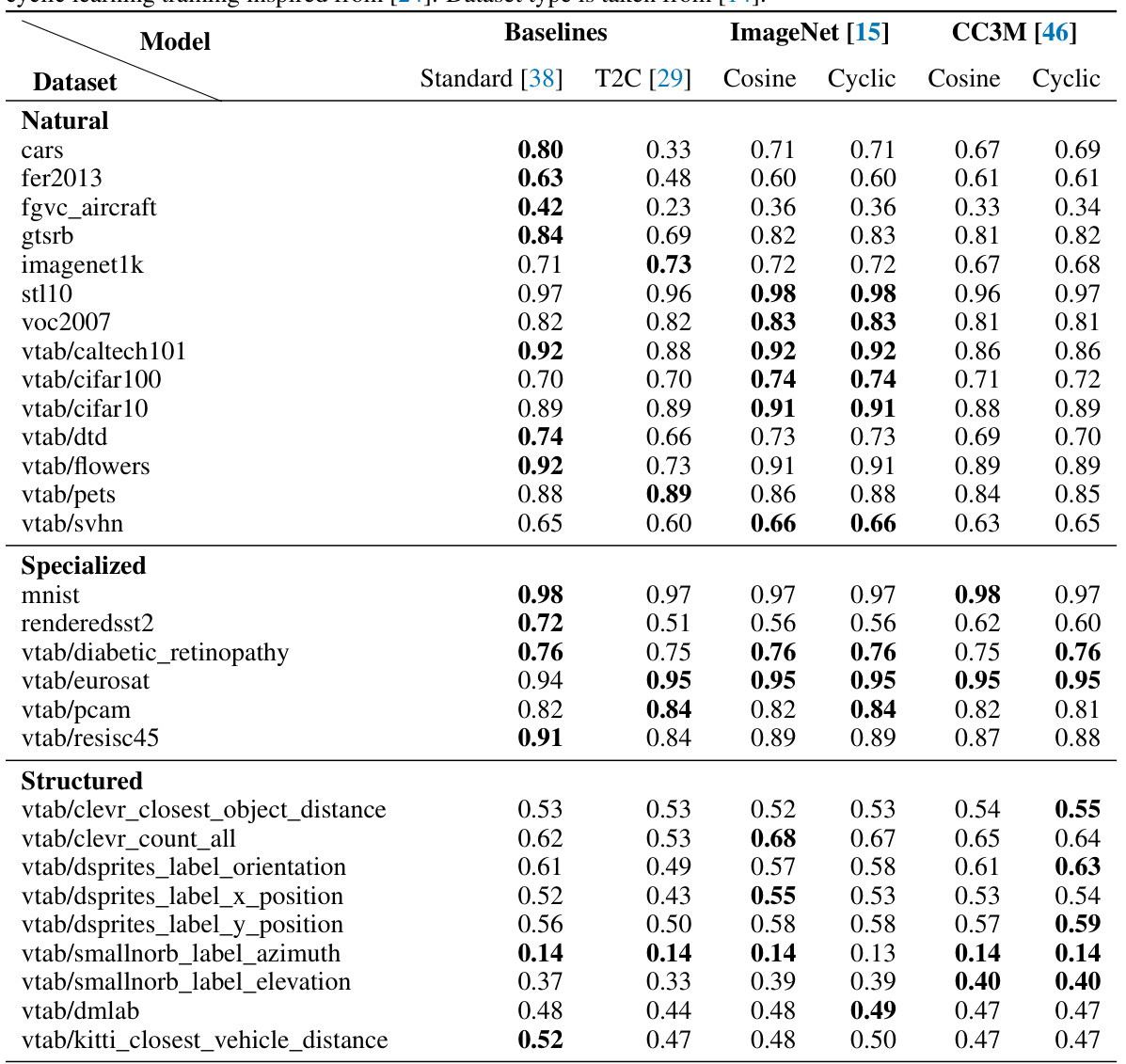
This table presents the zero-shot classification performance of different CLIP models on 38 diverse datasets. It compares the standard CLIP model and a Text2Concept approach with B-cosified CLIP models trained using different training strategies (cosine and cyclic learning schedules) and datasets (ImageNet and CC3M). The results highlight the performance improvements achieved through B-cosification.
Full paper#