↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing Transformer-based methods for single-image super-resolution (SISR) face challenges in lightweight settings due to coupled optimization of feature extraction and similarity modeling. This coupling limits performance and introduces co-adaptation issues. The computational cost of similarity modeling in these methods also increases quadratically with image size, hindering efficiency.
The paper introduces Unified Projection Sharing (UPS), a novel algorithm that addresses these issues by decoupling feature extraction and similarity modeling. UPS establishes a unified projection space, enabling layer-specific feature extraction optimization while calculating similarity in the shared space. This approach significantly improves efficiency and robustness. Extensive experiments demonstrate UPS achieves state-of-the-art results on various benchmarks and shows promising results on unseen data and different image restoration tasks.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents a novel approach to lightweight single-image super-resolution (SISR), a crucial task in computer vision with broad applications. The UPS method enhances efficiency and robustness, particularly important for resource-constrained environments. It also opens new research directions for decoupled optimization and exploring UPS’s potential in other image restoration tasks.
Visual Insights#
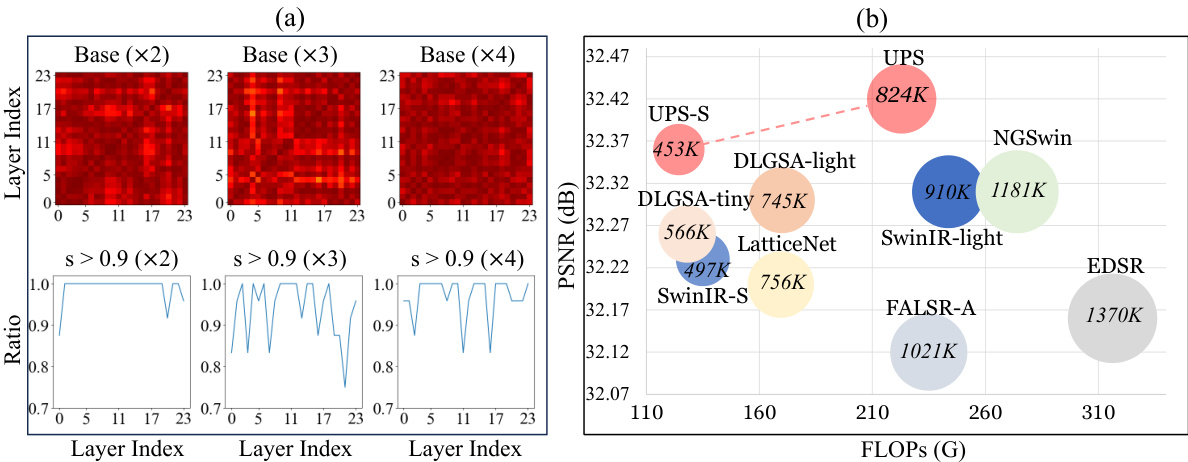
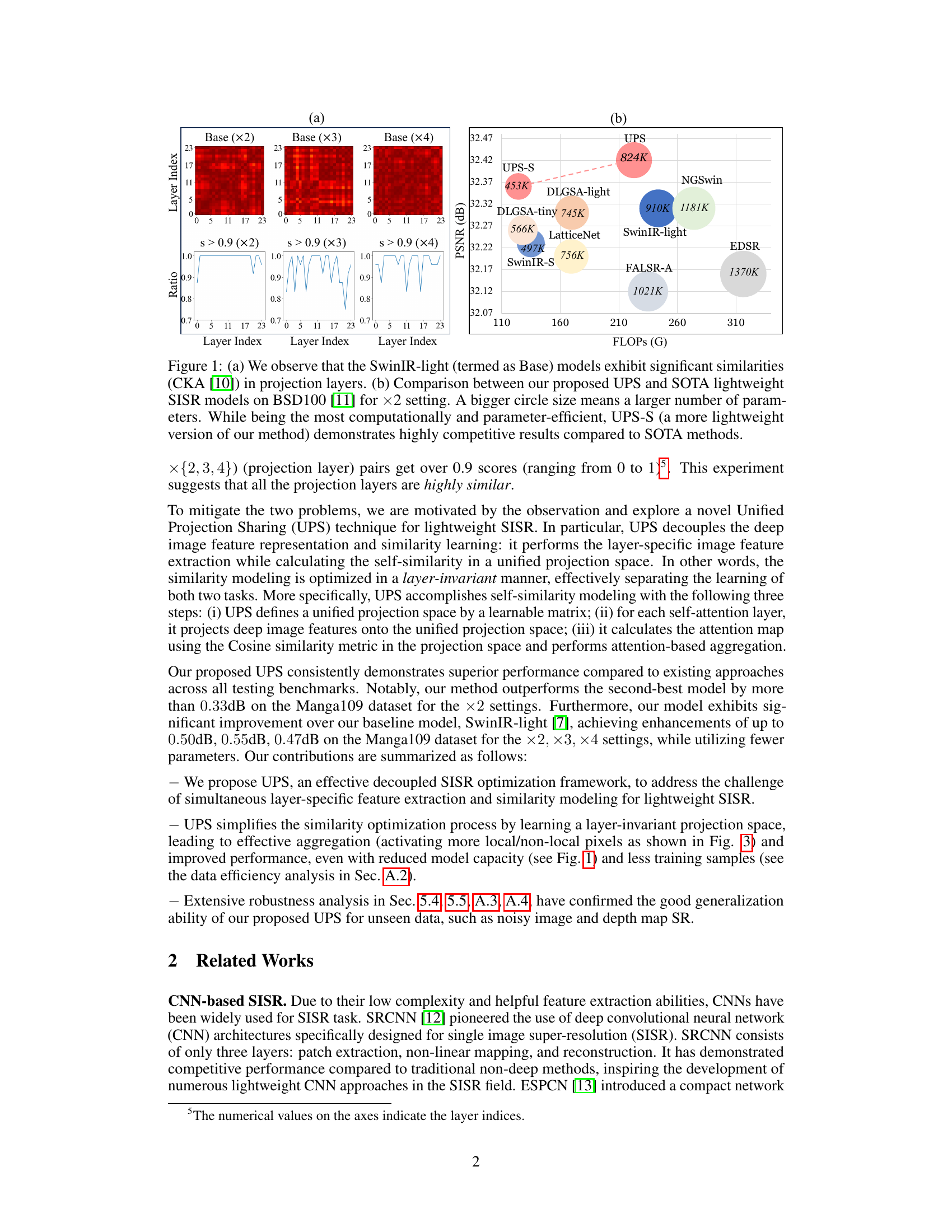
This figure shows two subfigures. The first one (a) displays the similarities of projection layers across different scales in the SwinIR-light model. These similarities are computed using the Centered Kernel Alignment (CKA) metric. The second one (b) compares the proposed UPS method with other state-of-the-art (SOTA) lightweight single image super-resolution (SISR) models. The models are compared in terms of PSNR on the BSD100 dataset and the number of parameters and FLOPs. The results show that the UPS method achieves state-of-the-art performance while having the least number of parameters and FLOPs.
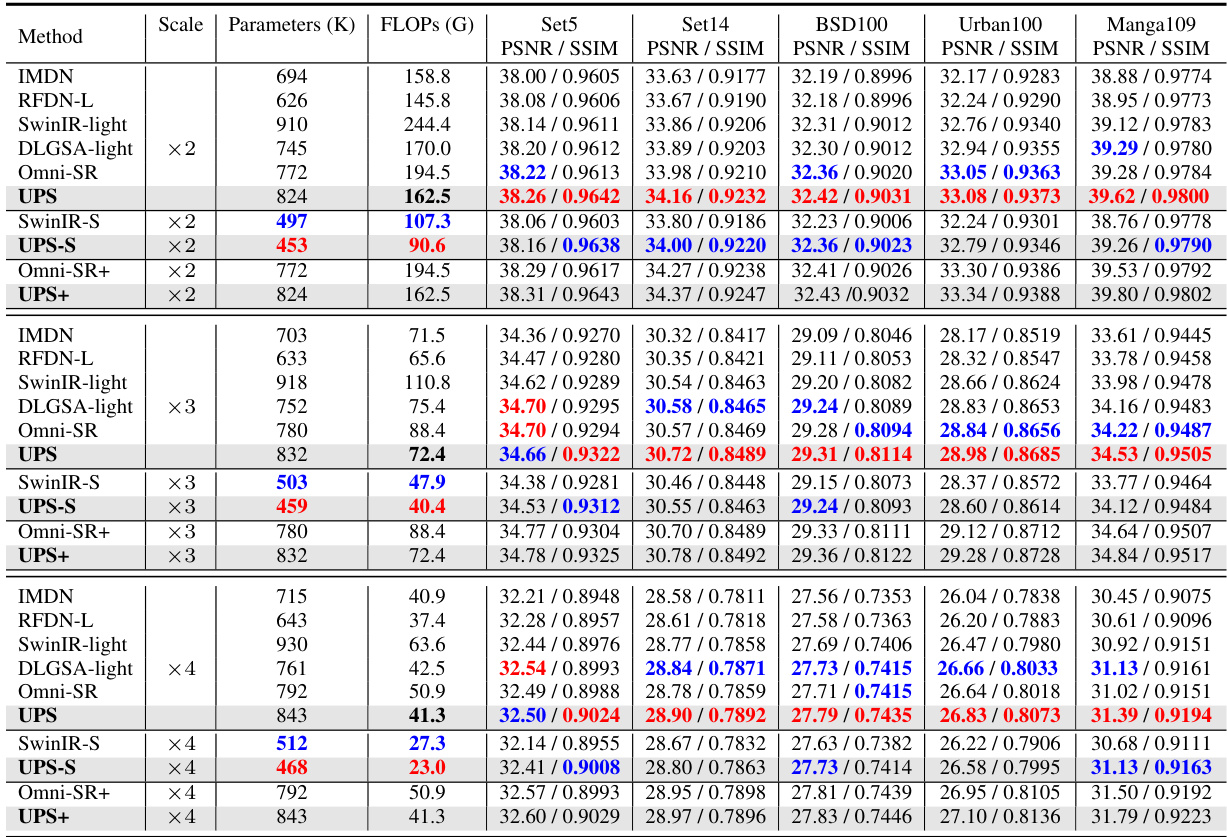
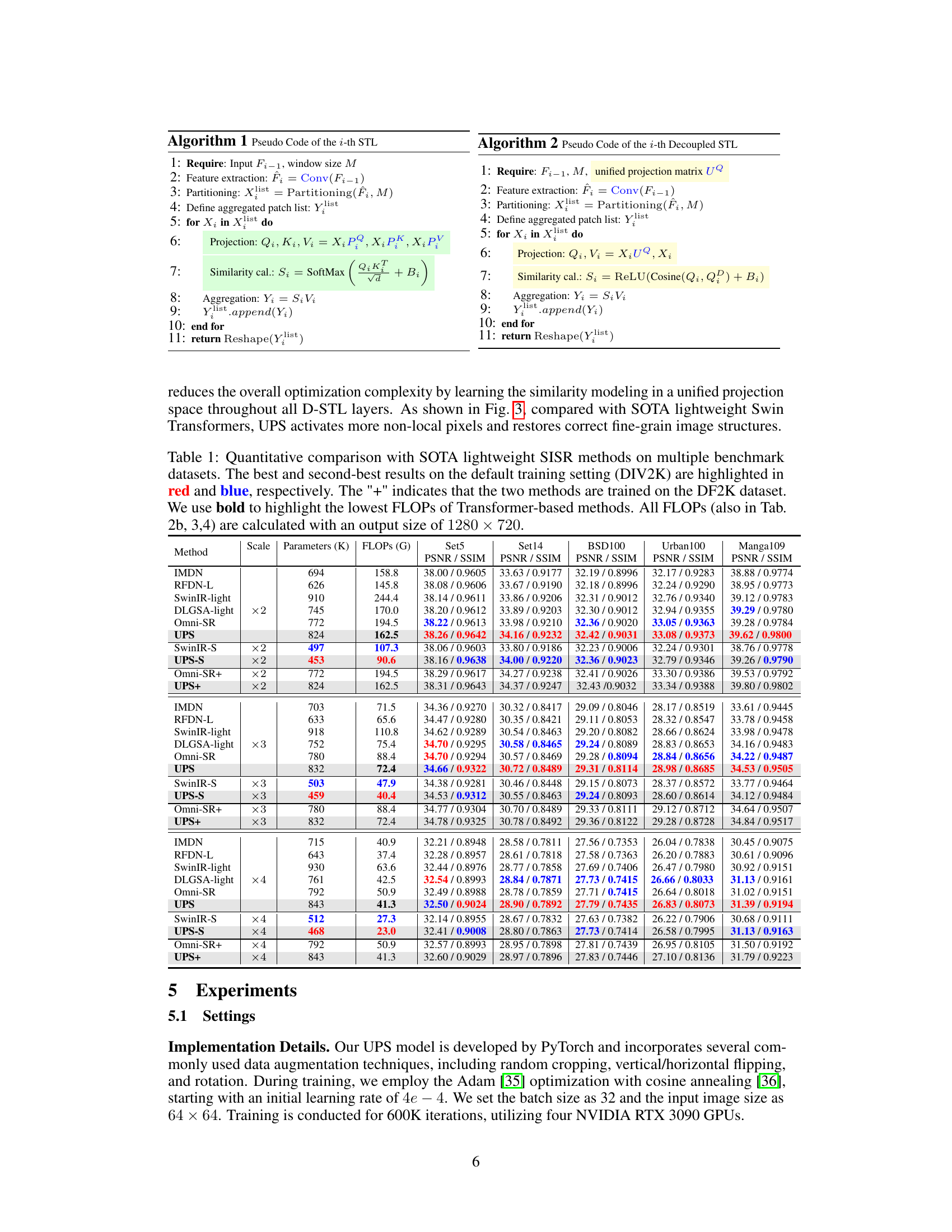
This table presents a quantitative comparison of the proposed UPS method against other state-of-the-art (SOTA) lightweight single image super-resolution (SISR) methods on several benchmark datasets. It shows the performance in terms of Peak Signal-to-Noise Ratio (PSNR) and Structural SIMilarity index (SSIM), highlighting the best and second-best results for each dataset and scale factor. The table also indicates the number of parameters (in thousands), the number of floating point operations (FLOPs) in Giga-operations, and whether the model was trained on the DIV2K or DF2K dataset. It emphasizes the efficiency of the UPS method in terms of parameter count and FLOPs.
In-depth insights#
UPS: Unified Projection#
The proposed “UPS: Unified Projection Sharing” method presents a novel approach to lightweight single-image super-resolution (SISR). The core idea is to decouple the feature extraction and similarity modeling processes, which are often tightly coupled in traditional transformer-based methods. This decoupling is achieved by establishing a unified projection space using a learnable matrix. All self-attention layers project their image features into this shared space, allowing for layer-specific optimization of feature extraction while performing similarity calculations within a consistent, unified context. This design addresses two key challenges in lightweight SISR: the difficulty of performing layer-specific optimization for both feature extraction and similarity modeling with limited parameters, and the co-adaptation issue that can arise from tightly coupled optimization. The use of a shared projection space improves efficiency and robustness. Extensive experiments demonstrate that UPS achieves state-of-the-art results on various benchmarks, particularly excelling in its ability to generalize to unseen data, including degraded and depth images.
Lightweight SISR#
Lightweight Single Image Super-Resolution (SISR) addresses the challenge of enhancing low-resolution images while minimizing computational cost and model parameters. Existing Transformer-based methods, while effective, often involve complex interactions between feature extraction and similarity modeling, hindering their performance in lightweight scenarios. The core issue lies in the simultaneous, layer-specific optimization of these two tasks. A key focus in lightweight SISR research is to decouple these processes for efficiency. This often involves exploring alternative attention mechanisms, optimized network architectures, or knowledge distillation techniques to reduce model size and computational complexity without significant performance degradation. Strategies for achieving this include using fewer layers, employing less computationally intensive operations (like depthwise convolutions), and exploring novel architectures that inherently favor efficiency, such as those based on efficient transformers. The ultimate goal is to create models that can achieve high-quality super-resolution on resource-constrained devices, such as mobile phones or embedded systems. Success in lightweight SISR is measured not just by the PSNR/SSIM metrics, but also by the trade-off between model size (number of parameters), computational cost (FLOPs), and the quality of the super-resolved images.
Decoupled Optimization#
Decoupled optimization, in the context of deep learning models for image processing, addresses the challenge of simultaneously optimizing multiple, interdependent tasks within a single network. Traditional approaches often couple these tasks, leading to complex interactions and hindering performance, especially in lightweight settings with limited parameters. Decoupling these tasks allows for independent optimization of individual components, such as feature extraction and similarity modeling, leading to a more efficient and effective training process. This approach often involves creating separate modules or pathways for each task, thereby streamlining the optimization process and improving model performance. The key benefit lies in breaking down the complex interplay between different network components, enabling easier tuning and improved overall results. By separating the learning process, decoupled optimization yields simpler, more robust models better suited for resource-constrained environments while achieving state-of-the-art performance. Furthermore, this strategy enhances generalization, making the model more adaptable to variations in input data and more resistant to overfitting.
Robustness and Limits#
A Robustness and Limits section for this research paper would explore the model’s resilience against various forms of noisy or incomplete input data. Key aspects would include evaluating performance under different levels of Gaussian noise, JPEG compression artifacts, and blurring. The analysis should compare the model’s performance on these degraded inputs against its performance on clean data, quantifying the impact of these degradations. Further exploration should encompass the limits of the model’s capabilities. What types of degradations cause significant performance drops? At what point do these degradations render the model unusable? The investigation should ideally involve analyzing the model’s internal mechanisms to understand why certain types of noise affect it more than others, potentially revealing areas for future improvement. Ultimately, this section aims to establish a clear understanding of the model’s strengths and weaknesses, providing valuable insights into its practical applicability and limitations.
Future Research#
Future research directions stemming from this paper could explore several promising avenues. Extending UPS to other image restoration tasks beyond the ones examined (denoising, deblocking) would be valuable, potentially including inpainting or compression. Investigating the scalability of UPS to handle higher-resolution images and exploring more efficient architectures, possibly by leveraging techniques like pruning or quantization, is crucial for real-world applications. A further area of study is adapting UPS to different Transformer architectures, examining how its principles can be effectively integrated with other advanced designs. Finally, a deeper investigation into the theoretical underpinnings of UPS is needed to fully understand its strengths and limitations, laying the groundwork for even more robust and effective methods. This could involve exploring the relationships between the unified projection space, feature extraction, and network architecture.
More visual insights#
More on figures

This figure illustrates the architecture of Transformer-based lightweight single image super-resolution (SISR) methods. It compares the traditional approach (layer-specific feature extraction and projection space optimization) with the proposed UPS method (decoupled layer-specific feature extraction and a unified projection space). The UPS method aims to improve efficiency and performance by decoupling these two optimization steps. The figure clearly shows the difference in the optimization strategy between traditional and UPS methods.

This figure compares the super-resolution (SR) results of different state-of-the-art (SOTA) lightweight single image super-resolution (SISR) models with the proposed UPS model. It highlights two example patches from different images. For each patch, it displays the ground truth, results from SwinIR-light, NGSwin, and UPS. Below each set of results is a quantitative comparison showing the distortion index (DI) and peak signal-to-noise ratio (PSNR). The local attribution maps (LAMs) visually represent which pixels were most heavily used in the SR process by each model.

This figure compares the architectures of general transformer-based SISR methods, previous Swin Transformer-based methods, and the proposed UPS method. It highlights the key difference: previous methods perform layer-specific optimization for both feature extraction and projection space, while UPS decouples these, using a unified projection space for all layers. This decoupling is intended to improve efficiency and performance in lightweight settings.

This figure compares the visual results of four different super-resolution models (LAPAR-A, SwinIR-light, NGSwin, and UPS) on four benchmark datasets (BSD100, Urban100, Manga109, and DIV2K) at a scaling factor of 4. It highlights that the proposed UPS model produces images with more detailed textures and fewer artifacts compared to other models.

This figure shows an ablation study on the impact of different similarity calculation methods in the UPS model. The left table presents quantitative results comparing four different methods: A (Matrix dot product + Softmax), B (Cosine + Softmax), C (Matrix dot product + ReLU), and D (Cosine + ReLU). The results are measured by PSNR and SSIM on the Urban100 dataset. The right side of the figure shows a visual comparison of the four methods on a sample image, displaying the super-resolution results overlaid with local attribution maps (LAM). Method D (Cosine + ReLU) achieves the best performance, indicating the effectiveness of using the cosine similarity and ReLU activation for similarity calculation in the UPS model.

This figure compares the layer-specific projection optimization method used in traditional Swin Transformers with the unified projection sharing (UPS) method proposed in the paper. The top row shows the low-resolution (LR) input image and its ground truth (GT) high-resolution counterpart. The two middle sections visually represent the intermediate feature maps (X), similarity maps (S), and aggregated feature maps (Y) at two different layers (Layer 12 and Layer 23) of both the SwinIR-light baseline model and the UPS model. The comparison highlights how the UPS method, by employing a unified projection space, achieves better similarity calculation and, consequently, better reconstruction of the high-resolution image, particularly in terms of structural details.

This figure compares the performance of several lightweight Single Image Super-Resolution (SISR) models, namely SwinIR-S, LAPAR-A, LatticeNet, and UPS-S, under two different experimental conditions. Subfigure (a) shows how the PSNR (Peak Signal-to-Noise Ratio) varies as the percentage of training images used changes. Subfigure (b) plots the PSNR against training iterations (in steps of 5000), again demonstrating performance differences. The results show UPS-S outperforms other models in both data efficiency and training speed.

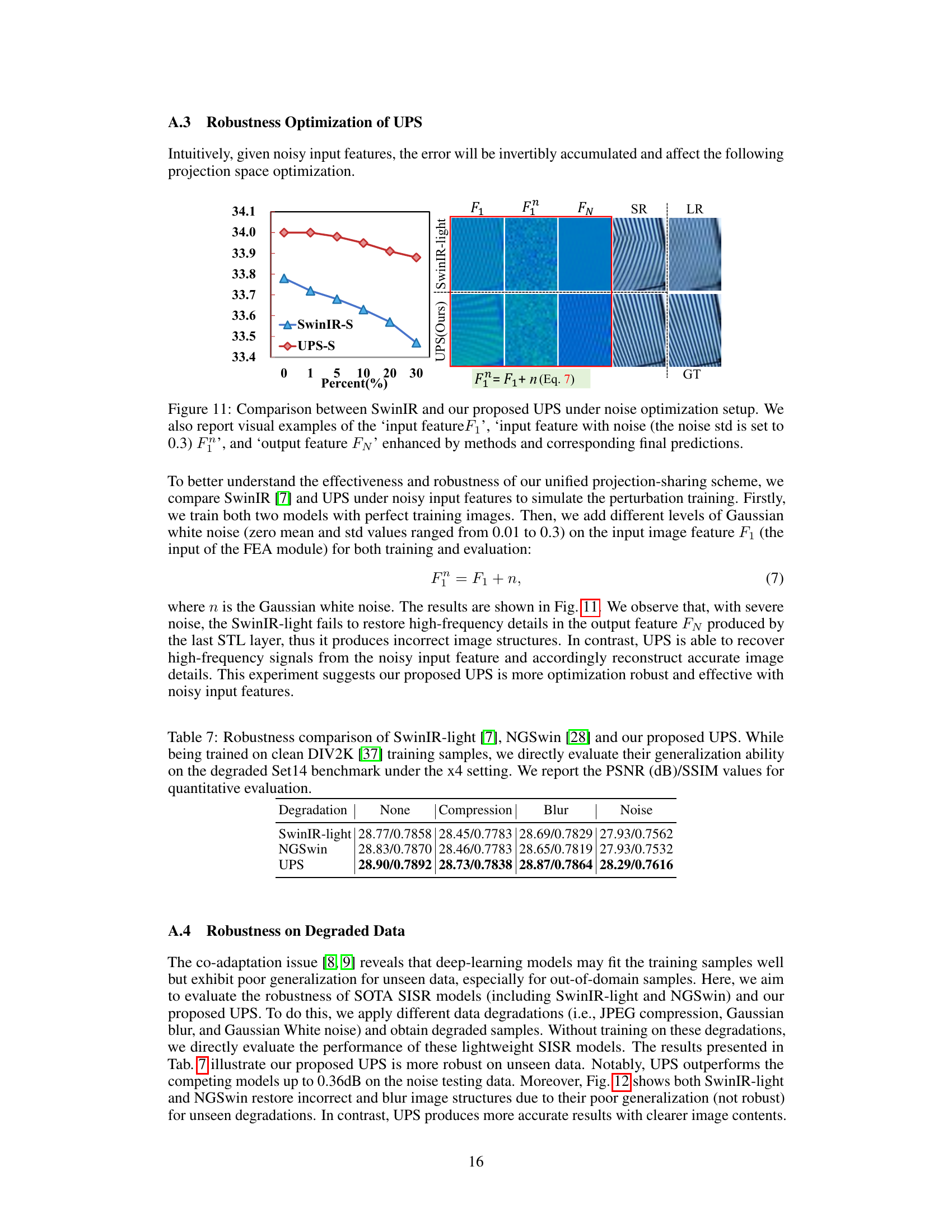
This figure compares the performance of SwinIR and UPS under noisy input conditions. Gaussian noise with a standard deviation of 0.3 is added to the input features. The left panel shows a graph comparing the PSNR values achieved by both models at different noise levels. The right panel displays visual examples showcasing the input features (with and without noise), the output features processed by each model, and the final super-resolution results. It demonstrates that UPS is more robust to noisy inputs, maintaining better image quality compared to SwinIR.

This figure compares the performance of SwinIR-light, NGswin, and UPS on three different types of degraded images (compression, blur, and noise) at a scaling factor of x4. The results show that UPS consistently outperforms the other two models in terms of PSNR and SSIM, indicating its superior robustness to out-of-domain data.
More on tables
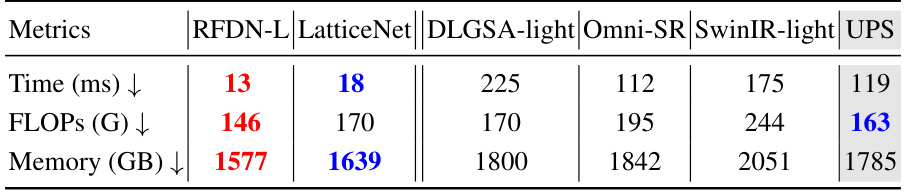
This table compares the inference time, FLOPs (floating point operations), and GPU memory usage of different lightweight single image super-resolution (SISR) models. The models are evaluated using a NVIDIA GeForce RTX 2080Ti GPU and input images of size 256x256, upscaling them by a factor of 2. FLOPs is calculated for an output resolution of 1280x720, providing a standardized measure of computational complexity. The table helps to assess the efficiency of different SISR methods.
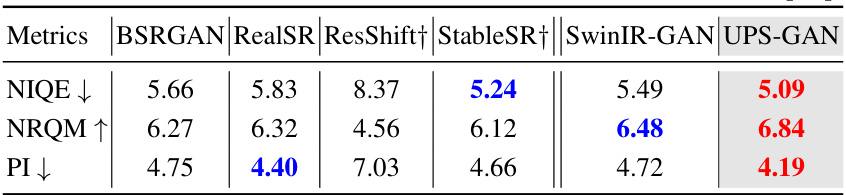
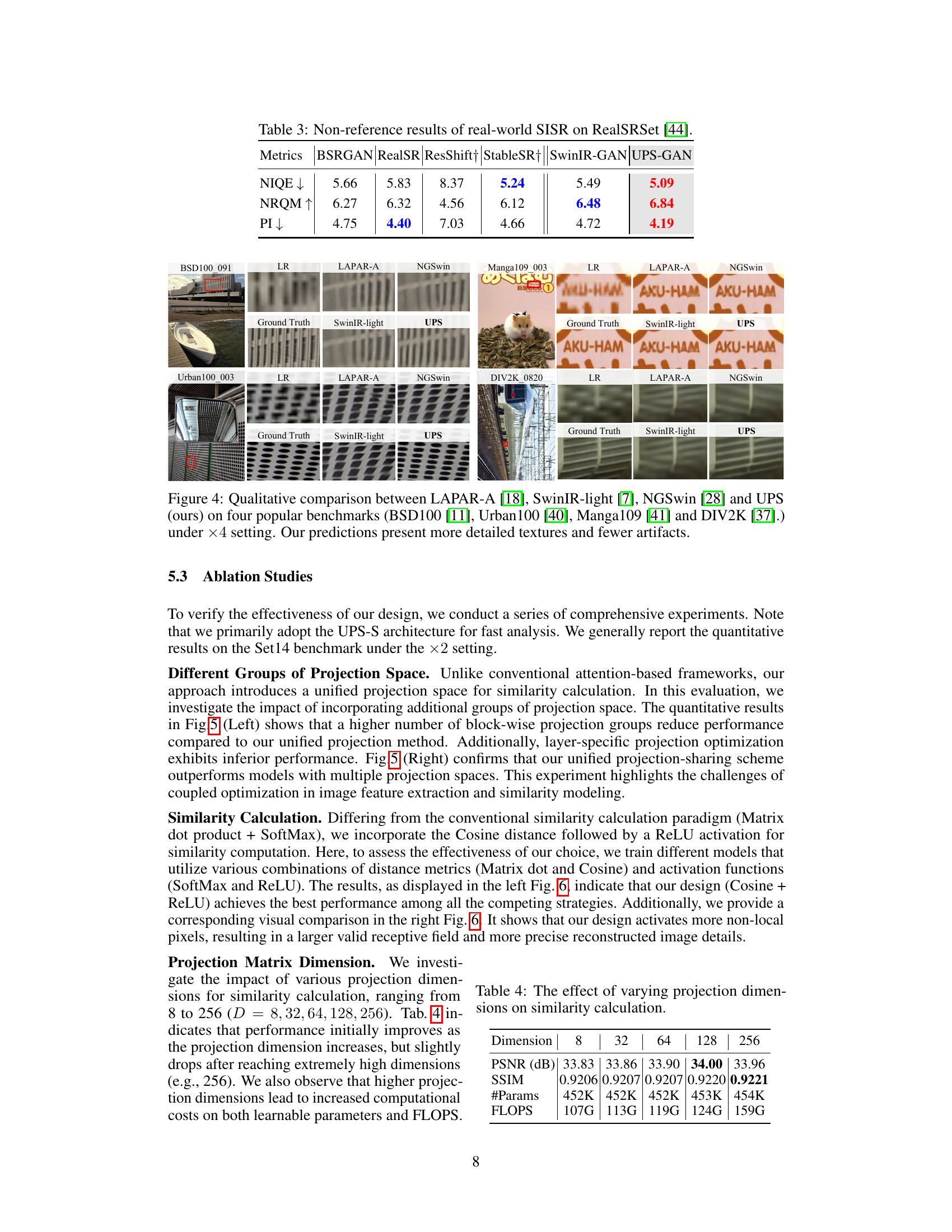
This table presents a comparison of non-reference image quality metrics for real-world single image super-resolution (SISR) on the RealSRSet dataset. The metrics used are NIQE (Natural Image Quality Evaluator), NRQM (No-Reference Quality Metric), and PI (Perceptual Index). Lower NIQE and PI values indicate better image quality, while higher NRQM values represent improved quality. The table compares the performance of several state-of-the-art GAN-based and diffusion-based methods against the proposed UPS-GAN approach.
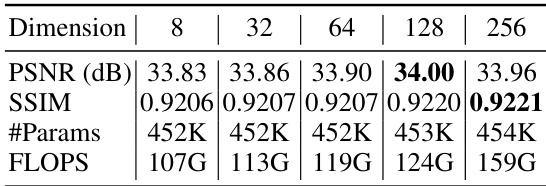
This table presents the results of an ablation study on the impact of different projection dimensions (8, 32, 64, 128, 256) on the performance of the UPS model for similarity calculation. The results show that increasing the dimension improves the performance initially but eventually leads to diminishing returns. The table shows that the best performance was achieved with a projection dimension of 128, achieving a PSNR of 34.00 dB and SSIM of 0.9220. This experiment highlights the importance of finding the optimal balance between the model’s capacity and its computational cost.

This table presents a quantitative comparison of the proposed UPS model against other state-of-the-art lightweight single image super-resolution (SISR) models for a 2x upscaling factor. The models were trained on the DIV2K dataset, and performance is evaluated using PSNR and SSIM metrics on various benchmark datasets (Set5, Set14, BSD100, Urban100, and Manga109). Inference time is also reported, measured on an NVIDIA GeForce RTX 2080Ti GPU with a 256x256 input image.

This table presents ablation study results comparing different activation functions (ReLU and Softmax) within the UPS framework and the effect of two advanced optimization techniques, dropout and progressive training, on the model’s performance. Part A shows the impact of changing activation functions and Part B compares UPS against other methods that utilize dropout or progressive training.

This table presents a quantitative comparison of the proposed UPS model against several state-of-the-art (SOTA) lightweight single image super-resolution (SISR) methods. The comparison is performed across multiple benchmark datasets (Set5, Set14, BSD100, Urban100, and Manga109), using Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) as evaluation metrics. The table highlights the best and second-best results for each dataset and scaling factor (x2, x3, x4). It also includes the model’s parameter count and floating-point operations per second (FLOPs). The use of DF2K dataset for training certain models is noted.

This table compares the performance of the proposed UPS method against other state-of-the-art lightweight single image super-resolution (SISR) models. The comparison is performed on the ×2 setting using the DIV2K dataset for training. The metrics used are PSNR and SSIM, evaluated on the Set5, Set14, BSD100, Urban100, and Manga109 benchmark datasets. The table also includes the model parameters, FLOPs and inference time for each model.

This table presents a quantitative comparison of the proposed UPS model with state-of-the-art (SOTA) lightweight single image super-resolution (SISR) methods across multiple benchmark datasets (Set5, Set14, BSD100, Urban100, and Manga109). The results are shown in terms of PSNR and SSIM values for different upscaling factors (×2, ×3, ×4). The table highlights the best and second-best performing methods for each dataset and upscaling factor, and indicates whether additional training data (DF2K) was used. FLOPs (floating point operations per second) are also listed, providing a measure of computational efficiency.

This table presents a quantitative comparison of the robustness of three different single image super-resolution (SISR) models: SwinIR-light, NGSwin, and the proposed UPS model. All models were trained on clean DIV2K images, but their performance is evaluated on degraded Set14 images with four types of degradations: no degradation (None), JPEG compression, Gaussian blur, and Gaussian noise. The results show PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index) values for each model and degradation type, demonstrating the relative robustness of each model to these common image degradations.

This table presents a quantitative comparison of the proposed UPS model with state-of-the-art (SOTA) lightweight single image super-resolution (SISR) methods. It shows the performance of various models on several benchmark datasets (Set5, Set14, BSD100, Urban100, and Manga109) in terms of PSNR and SSIM. The best and second-best results for each dataset and scaling factor (x2, x3, x4) are highlighted. The table also includes the number of parameters (in thousands) and FLOPs (in Giga-operations) for each model, providing a measure of computational efficiency. The ‘+’ symbol indicates models trained on an extended dataset (DF2K).

This table presents the results of an ablation study comparing two versions of the model: one with a linear projection (w/ V proj.) and one without (w/o V proj.). The results are shown for two datasets: Urban100 (x4) and Set14 (x4), and the number of parameters (in thousands) for each version is also included. The results indicate that the presence or absence of the linear projection does not significantly impact the model’s performance in terms of PSNR/SSIM.
Full paper#