↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current methods for aligning Large Language Models (LLMs) to human preferences rely heavily on human feedback for labeling, which is expensive and time-consuming. Naive approaches to active learning, selecting data points based solely on model uncertainty, often result in redundant data acquisition. This inefficiency hinders the development and deployment of large-scale LLMs.
The proposed Bayesian Active Learner for Preference Modeling (BAL-PM) tackles this challenge by using a novel stochastic acquisition policy. BAL-PM combines task-dependent epistemic uncertainty (from the preference model) with a task-agnostic uncertainty measure based on the entropy of the acquired prompt distribution in the feature space spanned by the LLM. This dual approach efficiently selects diverse and informative data points, minimizing redundant data and significantly reducing human feedback requirements. Empirical results demonstrate BAL-PM’s superiority over existing methods in reducing human feedback.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in LLM alignment and active learning. It directly addresses the high cost of human feedback in preference-based LLM training by proposing a novel method to significantly reduce labeling needs. The introduction of a task-agnostic uncertainty measure opens new avenues for efficient data acquisition, relevant to researchers working on large language models, AI alignment, and active learning strategies.
Visual Insights#
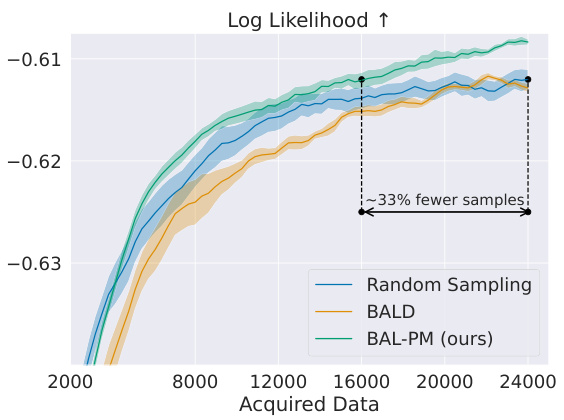
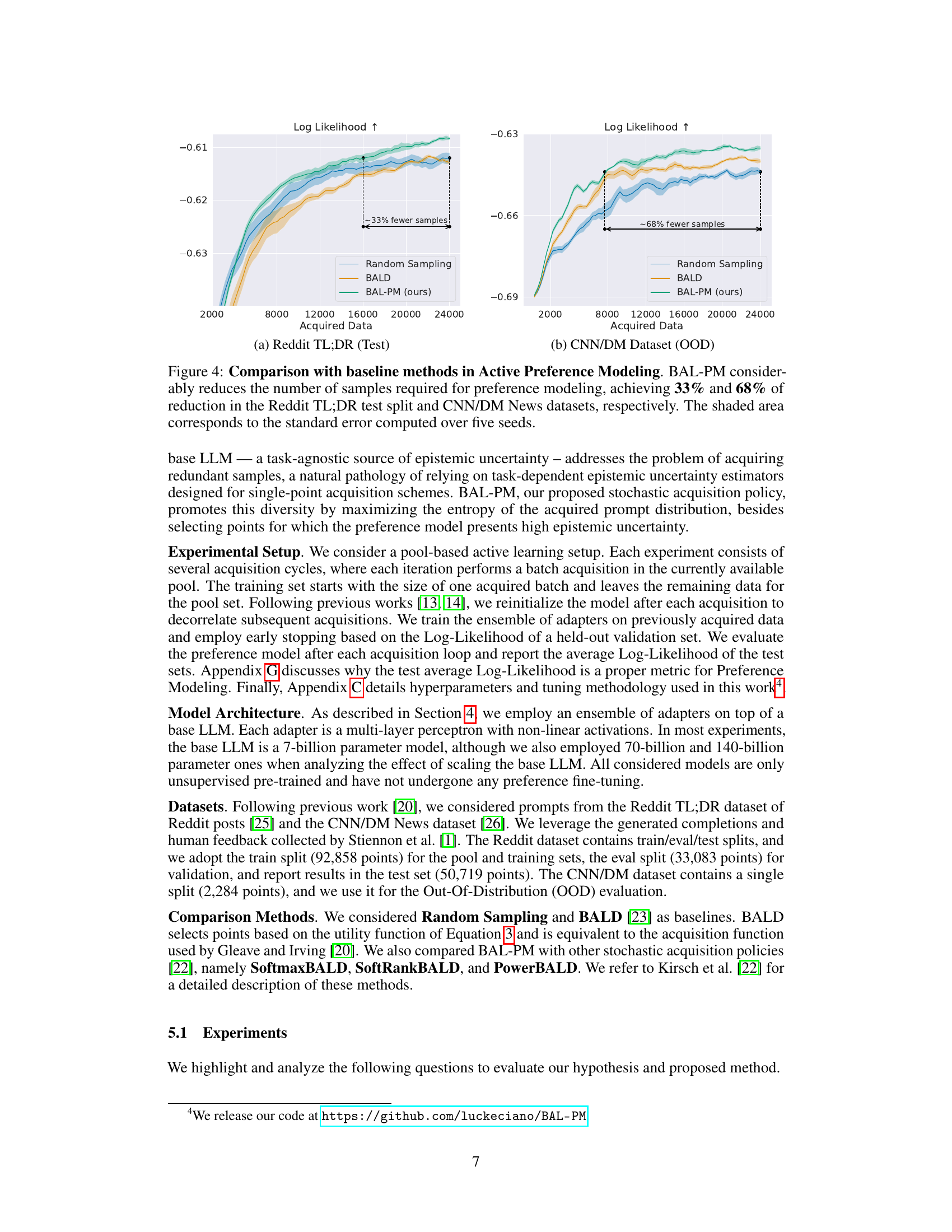
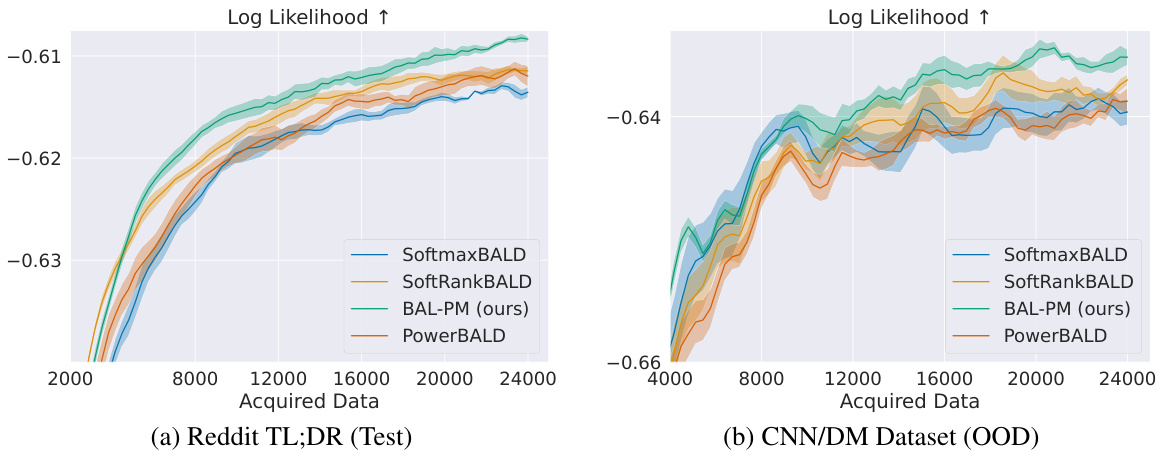
This figure compares the performance of BAL-PM against random sampling and BALD in active preference learning on two datasets: Reddit TL;DR and CNN/DM. The x-axis represents the number of data points acquired, and the y-axis represents the log-likelihood of the learned preference models. The results show that BAL-PM significantly outperforms both baselines, requiring fewer data points to achieve the same level of log-likelihood. The shaded areas represent the standard error across multiple runs, indicating the statistical significance of the results. The figure highlights the efficiency gain of BAL-PM, particularly a 33% reduction on Reddit TL;DR’s test set and a 68% improvement on the CNN/DM dataset.

This table lists all the hyperparameters used in the training process of the BAL-PM model and other baselines. It includes values for batch sizes, network architecture parameters (layers, activation function), learning rate and scheduler, optimizer, and parameters for the entropy term in the BAL-PM objective function, as well as hyperparameters for other baseline methods (SoftmaxBALD, SoftRankBALD, PowerBALD).
In-depth insights#
Active Preference Modeling#
Active preference modeling (APM) addresses the challenge of efficiently aligning large language models (LLMs) with human preferences. Traditional methods for preference modeling often rely on substantial labeled data, which is expensive and time-consuming to obtain. APM improves this by strategically selecting the most informative data points for human annotation, significantly reducing the labeling effort. This strategic selection is often guided by uncertainty estimates, calculated either from the model’s parameters or from the data’s distribution within a feature space. Effective APM techniques balance exploration (sampling diverse data points to improve model generalization) and exploitation (focusing on uncertain regions where the model needs more information). Key challenges in APM include handling noise and inconsistency in human preferences, efficiently updating model parameters upon receiving new labels, and adapting to the large scale and high dimensionality of LLM feature spaces. Ultimately, successful APM methods can enable the development of more aligned, efficient, and effective LLMs by minimizing the need for extensive human feedback.
BAL-PM Algorithm#
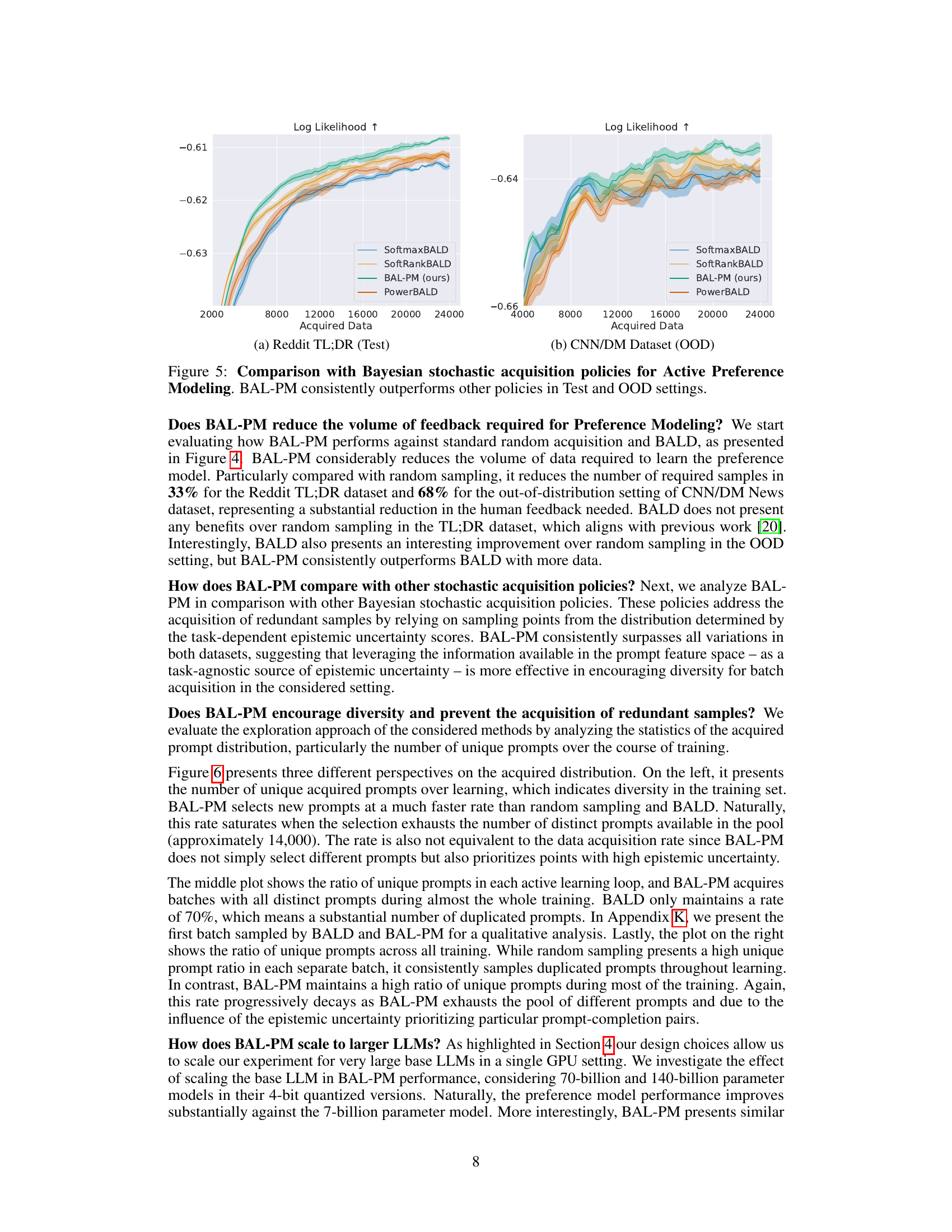
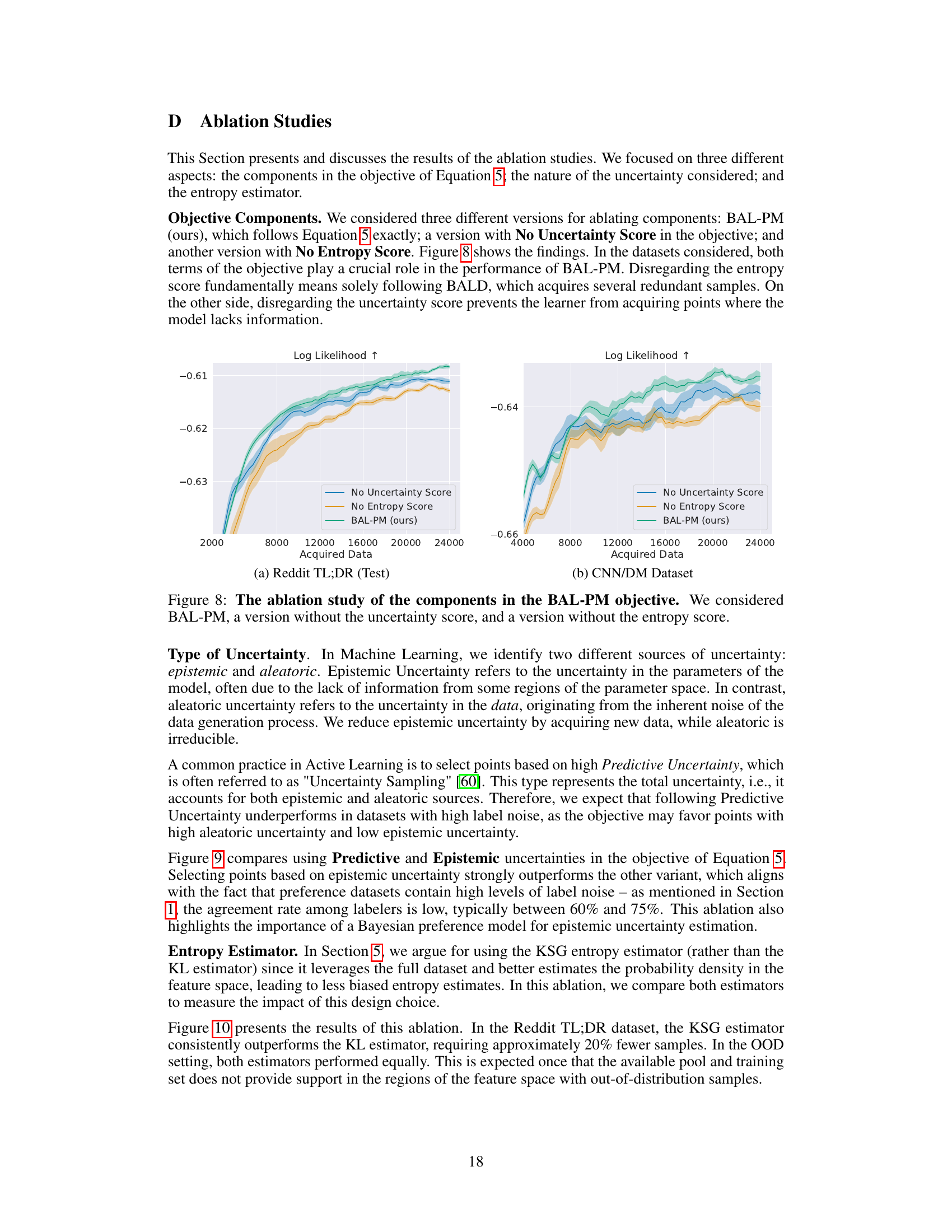
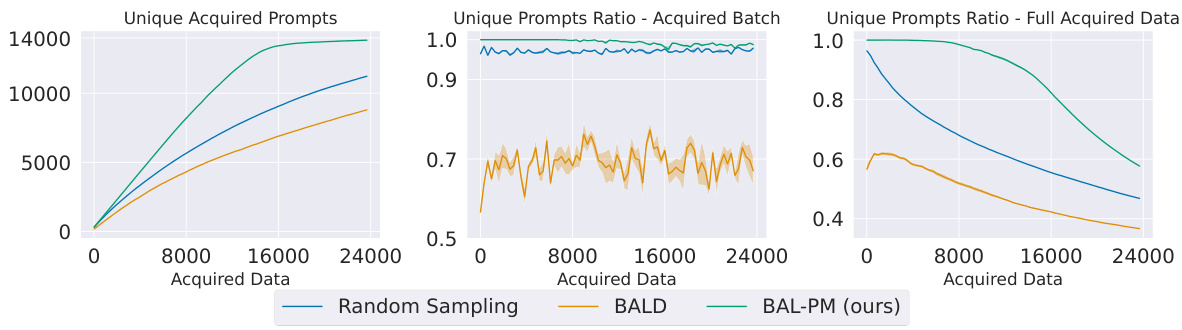
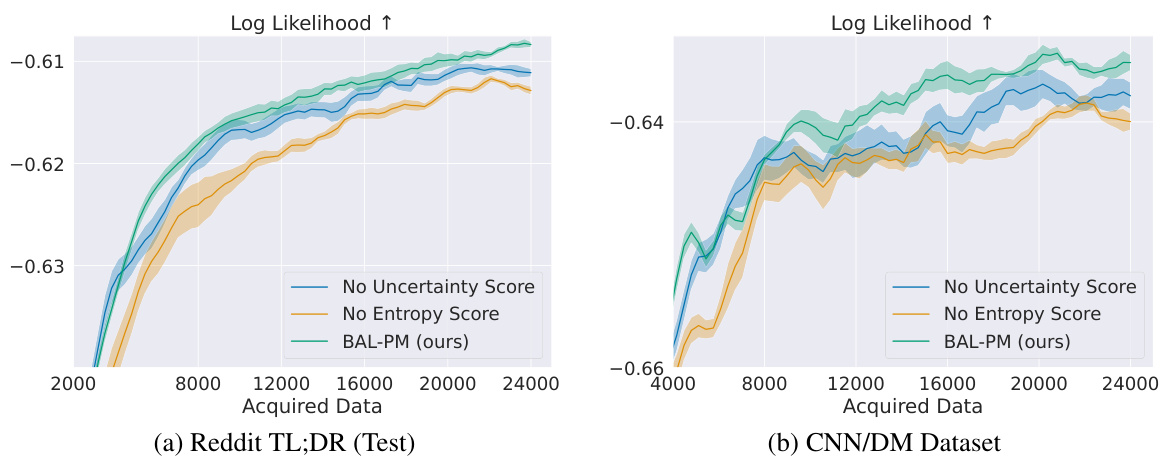
The BAL-PM algorithm is a novel stochastic acquisition policy designed for active preference modeling in large language models (LLMs). It cleverly addresses limitations of previous Bayesian active learning methods by incorporating both task-dependent epistemic uncertainty (from the preference model) and task-agnostic epistemic uncertainty (from the feature space spanned by the LLM). This dual approach prevents the selection of redundant samples by promoting diversity in the acquired prompts. The algorithm’s objective function balances these two uncertainties, dynamically adjusting their contributions as the training progresses. BAL-PM’s efficacy stems from its ability to maximize the entropy of the acquired prompt distribution, thereby encouraging exploration of less-sampled regions of the feature space, leading to more robust and efficient learning of human preferences. Computational efficiency is a key advantage, making it highly scalable to very large LLMs.
LLM Feature Space#
The concept of “LLM Feature Space” refers to the multi-dimensional representation of text learned by a large language model (LLM). LLMs internally transform text into vectors, each dimension capturing a nuanced aspect of semantic meaning. This space is not explicitly defined but is implicitly learned during pre-training. Analyzing this space offers valuable insights into the LLM’s understanding of language, revealing relationships between words and concepts. By examining the proximity of vectors in this space, we can uncover semantic similarities and differences that reflect the model’s internal knowledge representation. Furthermore, the distribution of vectors within this space can reveal biases or limitations present in the LLM’s training data. Understanding the LLM feature space is crucial for tasks like active learning, where the goal is to efficiently acquire information to improve the model. This space’s characteristics influence the selection of optimal data points for further model training, impacting performance and cost-effectiveness.
Uncertainty Estimation#
Uncertainty estimation is crucial for robust machine learning, especially in complex domains like natural language processing. Accurate uncertainty quantification allows models to express their confidence in predictions, which is vital for decision-making. In the context of large language models (LLMs), uncertainty estimation is particularly challenging due to their high dimensionality and the inherent ambiguity of language. Methods for estimating uncertainty in LLMs often involve Bayesian approaches, such as using deep ensembles or variational inference, to approximate the posterior distribution over model parameters. However, naive epistemic uncertainty estimations can lead to redundant data acquisition, as highlighted in the paper’s discussion of BAL-PM. Therefore, the paper proposes innovative strategies, such as incorporating task-agnostic uncertainty from the feature space spanned by the LLM, to address these limitations and improve the efficiency of active learning for preference modeling. This demonstrates that exploring alternative sources of epistemic uncertainty, especially ones that capture model behavior in an unsupervised way, is crucial for successful active learning in LLMs.
Future Work#
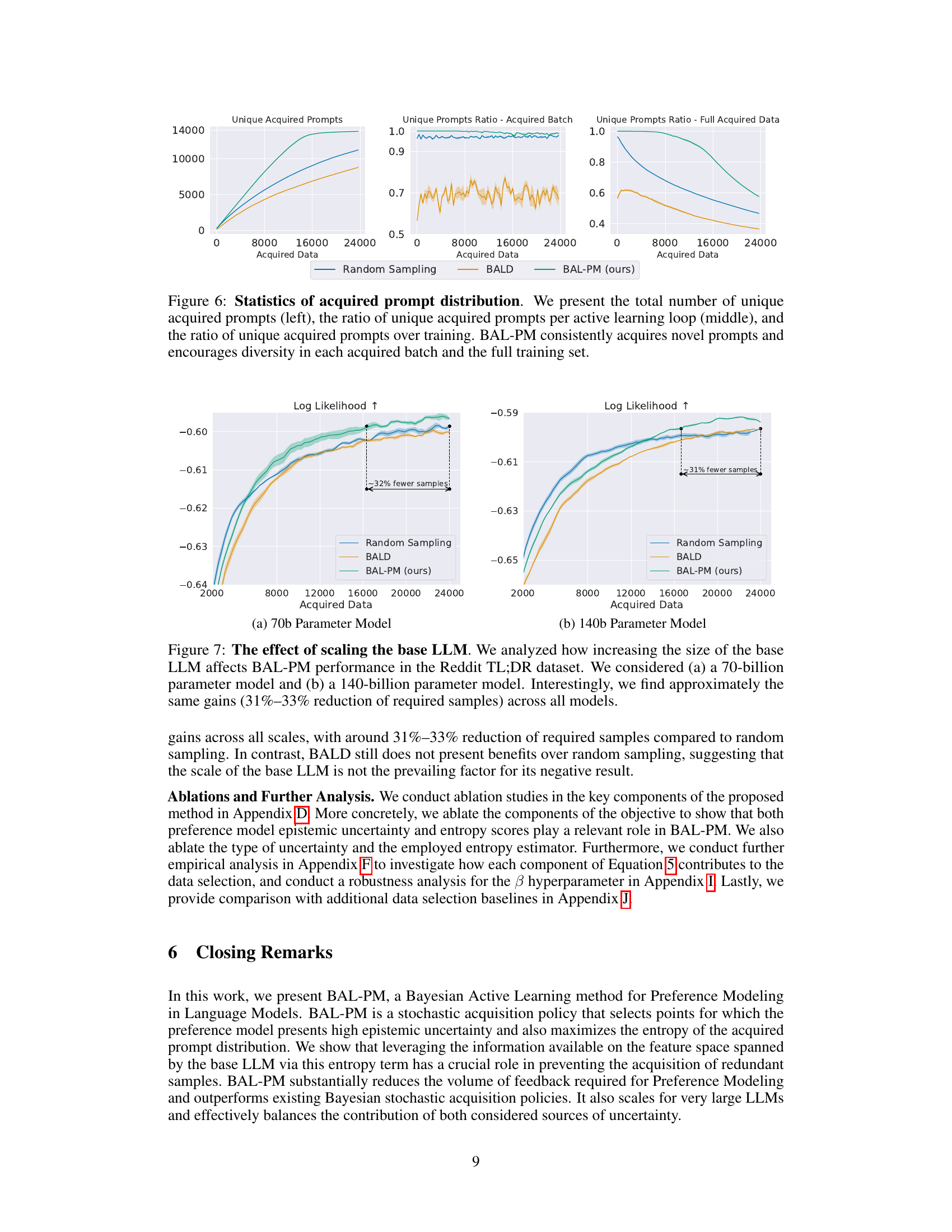
The ‘Future Work’ section of this research paper on deep Bayesian active learning for preference modeling in LLMs presents exciting avenues for improvement and expansion. Scaling to even larger LLMs is crucial, given the rapid advancements in model size and capabilities. Investigating the impact of different model architectures and the effect of quantization on BAL-PM’s performance is key. Addressing the noisy-TV problem inherent in LLMs, where nonsensical prompts are given high entropy scores, is essential for robustness. Furthermore, exploring alternative epistemic uncertainty estimation methods beyond BALD, particularly prediction-oriented approaches, could yield more accurate and efficient active learning. Extending the work to other types of preference datasets and evaluating performance on larger-scale, diverse human evaluations will solidify the generalizability of BAL-PM. Finally, investigating its application in preference optimization settings would demonstrate BAL-PM’s real-world effectiveness in steering LLM behavior towards desired outcomes.
More visual insights#
More on figures
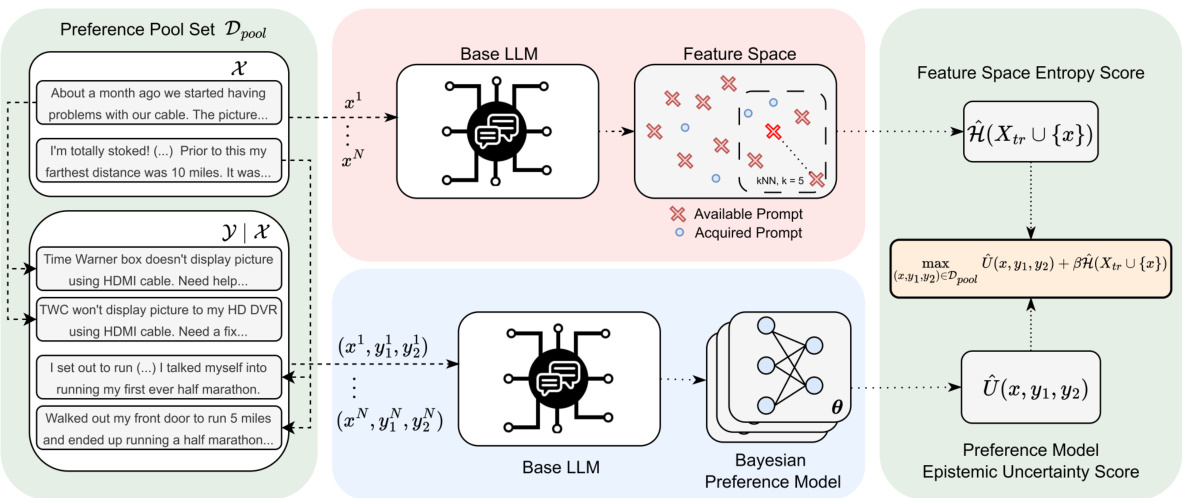
This figure illustrates the BAL-PM algorithm’s workflow. For each prompt-completion pair in the pool, the last layer embeddings from a base LLM are used to represent the prompt and completion in a feature space. The algorithm then estimates two scores: (1) the entropy of the prompt distribution in the feature space, which promotes diversity, and (2) the epistemic uncertainty of the prompt-completion pair according to the Bayesian preference model. BAL-PM selects the pair that maximizes the sum of these two scores, weighted by a hyperparameter β.
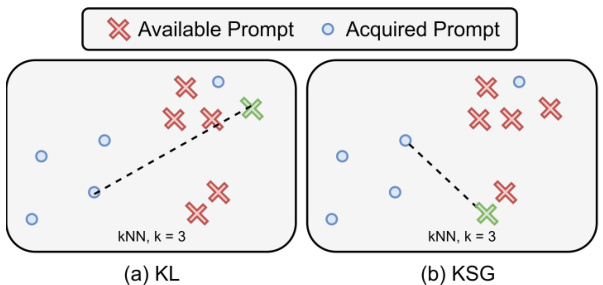
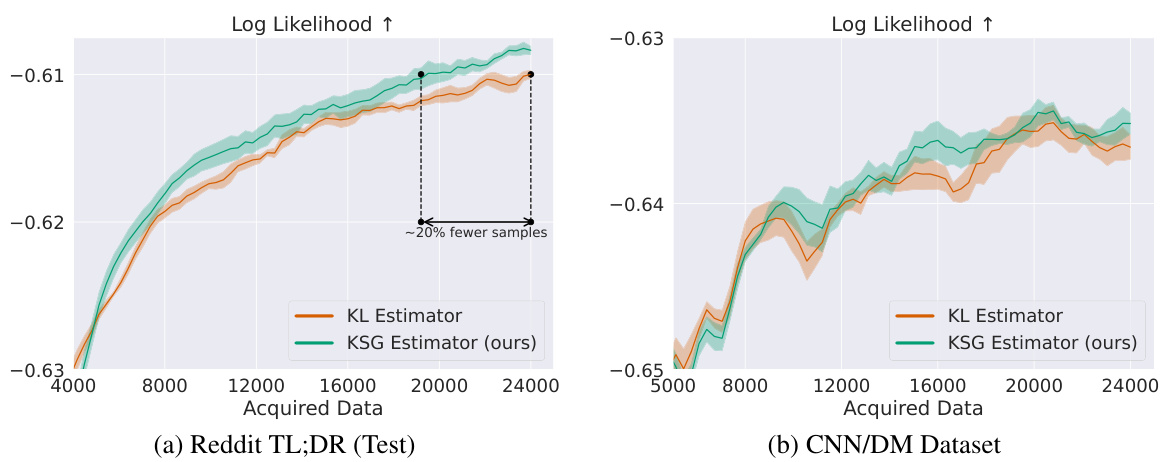
This figure illustrates the difference between two entropy estimation methods: KL and KSG. KL estimator underestimates density in low-density regions because it only considers acquired points, while KSG utilizes all data points (acquired and available) for more accurate entropy estimation and better diversity in selected samples.
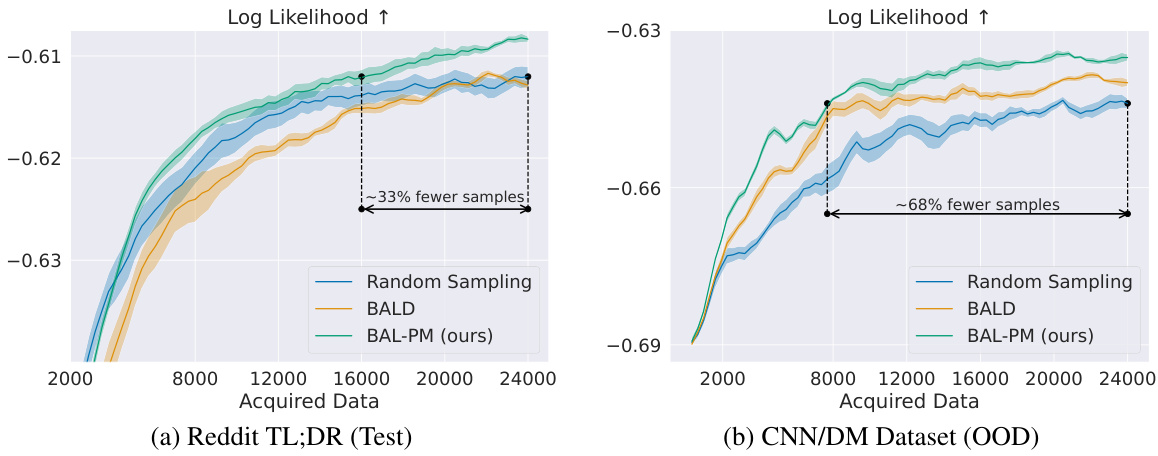
This figure compares the performance of BAL-PM against random sampling and BALD baselines on two datasets: Reddit TL;DR and CNN/DM. The y-axis represents the log-likelihood of the learned preference model, indicating its accuracy. The x-axis represents the number of acquired data points (human feedback). The results show that BAL-PM consistently outperforms the other methods, requiring significantly fewer data points to achieve comparable performance. The shaded regions represent the standard error across multiple experimental runs, illustrating the reliability of the results.
This figure compares the performance of BAL-PM against baseline methods (random sampling and BALD) in two datasets: Reddit TL;DR (test split) and CNN/DM. The y-axis represents the log-likelihood of the learned preference models, indicating model performance. The x-axis represents the number of data points (acquired data) used for training. BAL-PM consistently outperforms the baselines, achieving a significant reduction in the number of samples needed to reach comparable model performance. The shaded regions illustrate the standard error across five different trials, showing the consistency of the results.
This figure compares the performance of BAL-PM against random sampling and BALD in active preference modeling on two datasets: Reddit TL;DR and CNN/DM. The plots show the log-likelihood of the learned preference models as a function of the number of acquired data points. BAL-PM significantly outperforms the baselines, requiring fewer data points to achieve similar performance, indicating its efficiency in data acquisition for preference learning.
This figure compares the performance of BAL-PM against random sampling and BALD in active preference learning using two datasets: Reddit TL;DR and CNN/DM. The x-axis represents the number of data points acquired, and the y-axis shows the log-likelihood of the learned preference models. The plots demonstrate that BAL-PM achieves significantly higher log-likelihoods with considerably fewer samples compared to the baseline methods, showcasing its efficiency in reducing the amount of human feedback needed for preference modeling. The shaded regions represent the standard errors across multiple runs, indicating the reliability of the results.
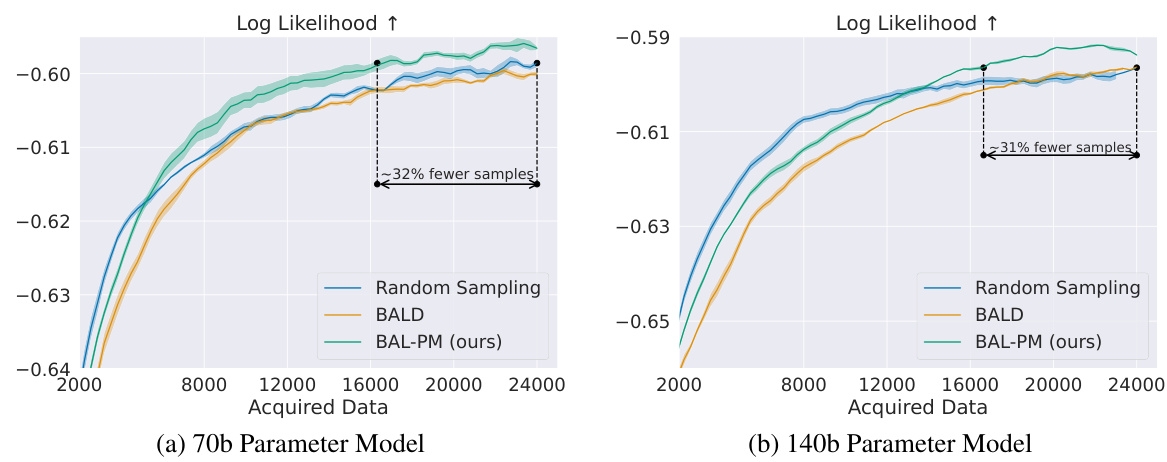
This figure compares the performance of BAL-PM against random sampling and BALD baselines in two active preference modeling tasks: Reddit TL;DR and CNN/DM. The x-axis represents the number of acquired data points, and the y-axis shows the log-likelihood of the learned preference models. The results demonstrate that BAL-PM requires significantly fewer data points (33% fewer for Reddit TL;DR test set and 68% for CNN/DM) to achieve similar or better performance compared to the baselines. The shaded regions represent the standard error computed across multiple runs, showcasing the consistency of the results.
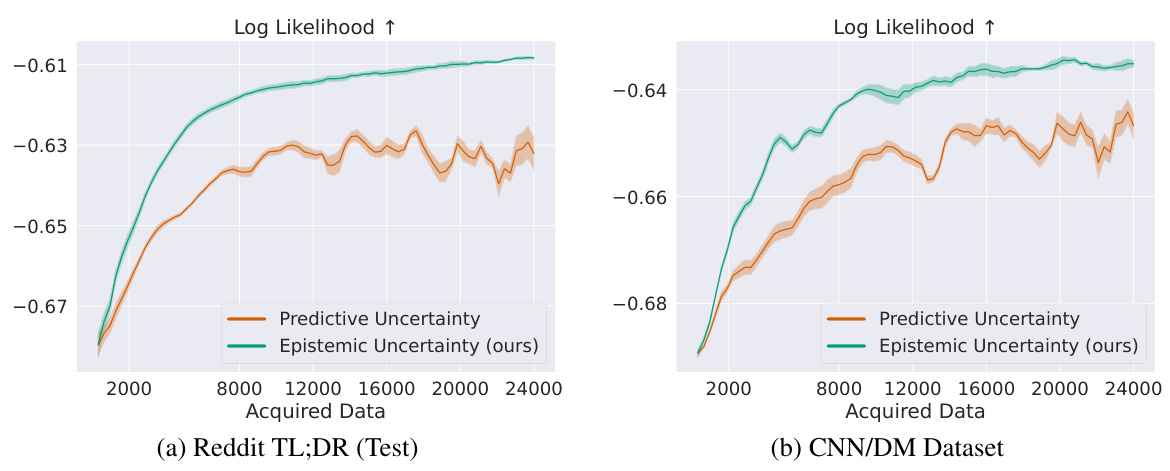
This figure compares the performance of BAL-PM against two baseline methods (random sampling and BALD) in two different datasets (Reddit TL;DR and CNN/DM). The x-axis represents the number of data points acquired, and the y-axis shows the log-likelihood of the learned preference model. The results demonstrate that BAL-PM significantly outperforms the baselines, requiring substantially fewer samples to achieve comparable performance. The shaded areas indicate the standard error across multiple runs, highlighting the consistency of the results. The figure showcases the efficiency of the BAL-PM model in reducing the need for human feedback during preference labeling.
The figure shows the comparison of the proposed BAL-PM method against two baseline methods (random sampling and BALD) for two datasets, Reddit TL;DR and CNN/DM, in active preference learning. The x-axis represents the number of acquired data points, and the y-axis represents the log-likelihood of the learned preference model, a measure of model performance. BAL-PM consistently outperforms the baseline methods across both datasets, demonstrating a significant reduction in the number of samples required to achieve comparable performance. The shaded region indicates standard error across multiple runs, highlighting the statistical significance of the results.

This figure shows how BAL-PM balances the contributions of task-dependent and task-agnostic epistemic uncertainty during active learning. The ratio of entropy and preference model uncertainty scores is plotted against the number of acquired data points. Initially, the entropy score (task-agnostic) dominates, promoting diversity in the acquired prompt distribution. As more data is acquired, the relevance of the preference model uncertainty (task-dependent) increases, leading to a shift towards exploiting the model’s knowledge.
This figure compares the performance of BAL-PM with random sampling and BALD in two datasets: Reddit TL;DR and CNN/DM. The y-axis represents the log-likelihood of the learned preference models, indicating the quality of the model. The x-axis shows the number of acquired data points. BAL-PM consistently outperforms the baselines, demonstrating a significant reduction in the amount of data needed to achieve a high-quality preference model. The shaded regions represent standard error across multiple trials.

This figure compares the performance of BAL-PM with random sampling and BALD across two datasets: Reddit TL;DR and CNN/DM. The x-axis represents the number of acquired data points. The y-axis represents the log-likelihood of the learned preference model. BAL-PM significantly outperforms the baseline methods by requiring considerably fewer samples to achieve comparable or better log-likelihood scores. The shaded regions represent the standard error, indicating the consistency of the results across multiple trials.
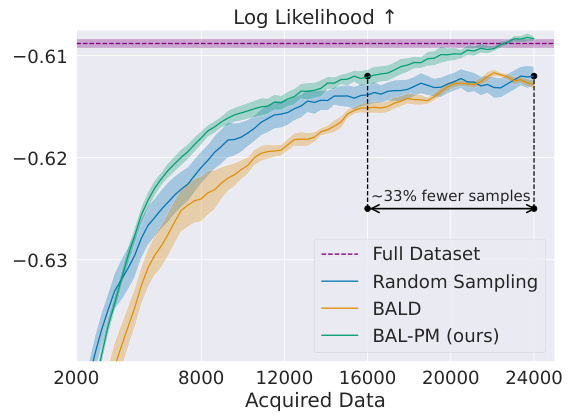
This figure compares the performance of BAL-PM with random sampling and BALD in two datasets: Reddit TL;DR and CNN/DM. The x-axis represents the number of data points acquired, and the y-axis shows the log-likelihood of the learned preference model. The results demonstrate that BAL-PM requires significantly fewer data points (33% fewer for Reddit TL;DR test set and 68% for CNN/DM) to achieve similar or better log-likelihood compared to the baselines, indicating its higher efficiency in preference modeling. Shaded regions represent standard errors across multiple runs.
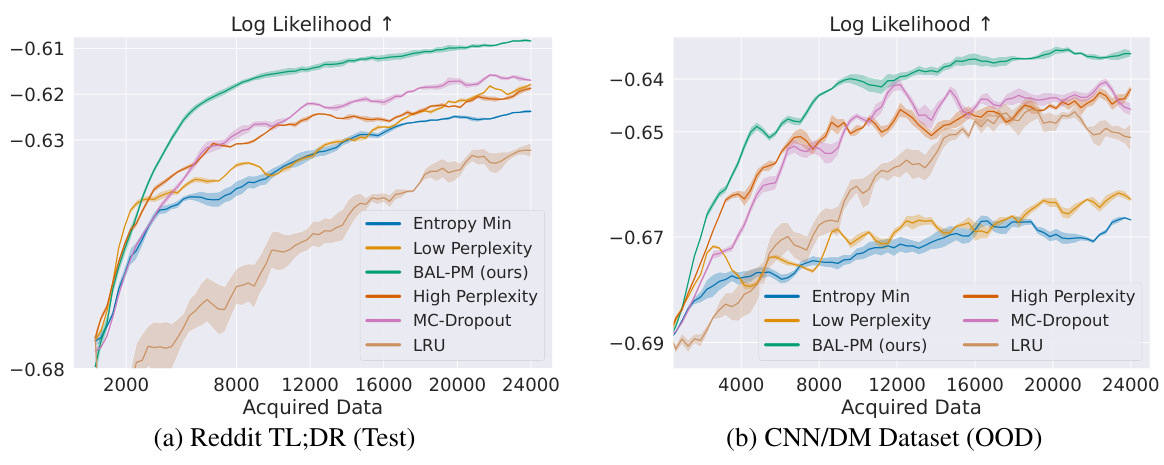
This figure compares the performance of BAL-PM against random sampling and BALD in active preference modeling using two datasets: Reddit TL;DR and CNN/DM. The results show that BAL-PM significantly reduces the number of samples needed to achieve comparable performance, indicating its efficiency. The shaded regions represent standard errors across multiple runs.

This figure compares the performance of BAL-PM against two baseline methods (random sampling and BALD) in active preference learning on two datasets: Reddit TL;DR and CNN/DM. The x-axis represents the number of acquired data points, and the y-axis represents the log-likelihood of the learned preference model. The results demonstrate that BAL-PM significantly outperforms the baselines, requiring substantially fewer data points to achieve similar log-likelihood values, showcasing its efficiency in active preference modeling.
Full paper#