↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Machine learning models often suffer from calibration errors, particularly when facing dataset shift, which means the training data differs from the real-world data the model is used on. Existing methods for calibration error estimation typically assume either labeled data from the target domain (real-world data) or rely on covariate shift assumptions. This limits their applicability in many practical scenarios where obtaining labeled target data is expensive or impossible.
This research introduces LaSCal, a novel calibration method designed to address these limitations. LaSCal overcomes the need for labeled target data by using a consistent label-free estimator for calibration error. The method is tested extensively, showing consistent improvement in calibration quality across various models and datasets with varying intensities of label shift. The results highlight the potential of LaSCal for building more reliable AI systems that work effectively in real-world settings where access to labeled target data is limited.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on reliable uncertainty estimation and model calibration, especially in safety-critical applications. It addresses the critical challenge of dataset shift, particularly label shift, offering a novel solution for unsupervised calibration that is both effective and robust. The proposed approach opens new avenues for improving model reliability, and has the potential to significantly impact various fields.
Visual Insights#

This figure compares the performance of the proposed LaSCal method with temperature scaling on source and target data for models facing label shift. The left panel shows that LaSCal, without target labels, performs comparably to temperature scaling on the target data (which uses labels). The right panel demonstrates the robustness of LaSCal in a more challenging scenario where both the label and input distributions shift between source and target datasets.

This table compares the properties of several existing calibration methods. It highlights whether each method accounts for label shift, requires target labels, preserves accuracy, and utilizes a consistent calibration error (CE) estimator under the label-shift assumption. LaSCal is shown as the only method meeting all four criteria.
In-depth insights#
Label Shift Calibration#
Label shift calibration addresses the challenge of reliable uncertainty estimation when the distribution of labels changes between training and testing data, while the relationship between features and labels remains consistent. This is a critical problem in real-world applications where data shifts are common. Existing methods often assume access to target labels, which are frequently unavailable. A key innovation is the development of label-free calibration methods, which estimate calibration error without requiring target labels. These methods often leverage techniques from unsupervised domain adaptation, using importance weighting to account for the label shift. The effectiveness of these techniques is demonstrated through rigorous empirical evaluations, showing improved calibration accuracy compared to traditional methods in various scenarios. The key challenge lies in accurately estimating the shift in the target label distribution to properly re-weight the source data for calibration. Future research may focus on handling more complex shifts or combining label shift with other types of dataset shifts for even more robust calibration.
LaSCal: Method Details#
LaSCal’s methodology centers around addressing the challenge of calibrating models under label shift without relying on target labels. This is achieved through a novel, consistent calibration error (CE) estimator specifically designed for label-shift scenarios. The key innovation lies in the estimator’s ability to handle changes in the marginal label distribution while maintaining a constant conditional distribution. This label-free approach uses importance weighting techniques (e.g., ELSA, RLLS) to account for the difference between source and target label distributions. The estimated CE then guides a post-hoc calibration strategy, making LaSCal an unsupervised calibration method. The method’s robustness is a major strength, validated through extensive experiments involving diverse modalities, model architectures, and label shift intensities. While effective, LaSCal’s performance is inherently tied to the quality of the importance weight estimates, and its accuracy may degrade under extreme data scarcity or when the weight estimation process itself is unstable.
Robustness Analysis#
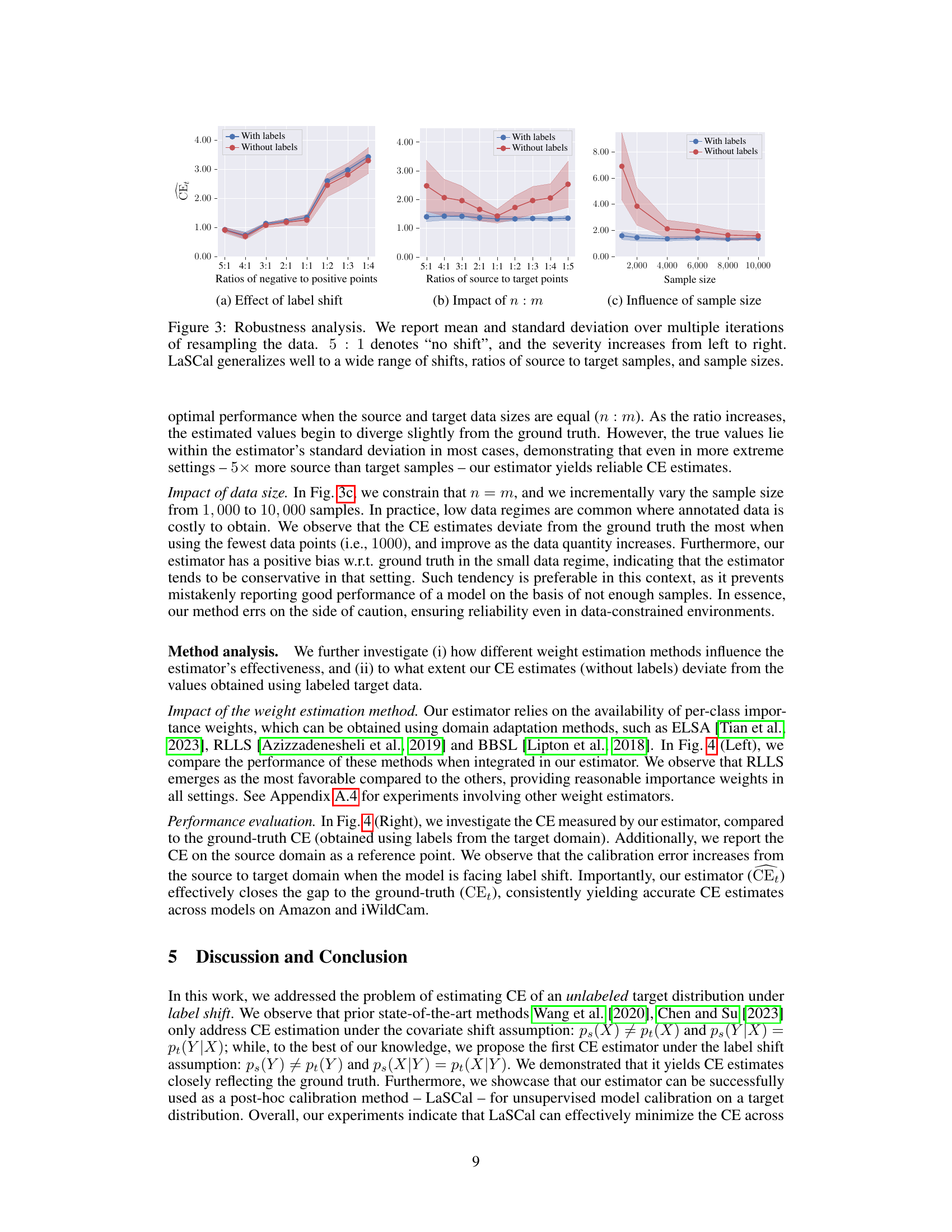
A robustness analysis section in a research paper would typically investigate the sensitivity of the proposed method’s performance to various factors. For a label-shift calibration method, this could involve examining its behavior under different levels of label shift intensity, varying the ratio of source to target data samples, or assessing the impact of differing numbers of data samples. The key is to demonstrate the reliability and stability of the approach under conditions that deviate from the ideal or controlled experimental setting. The use of multiple datasets and models would strengthen the evaluation, showing how results generalize across different modalities. Ideally, the analysis would include both quantitative (e.g., calibration error) and qualitative metrics (e.g., reliability diagrams) to present a comprehensive evaluation. Showing consistent performance in the presence of noise or real-world complexities would be crucial for demonstrating robustness. The robustness analysis should not only show what factors affect the model, but also provide insight into the magnitude of these effects, allowing researchers to understand the practical limitations and applicability of the method.
Limitations & Future#
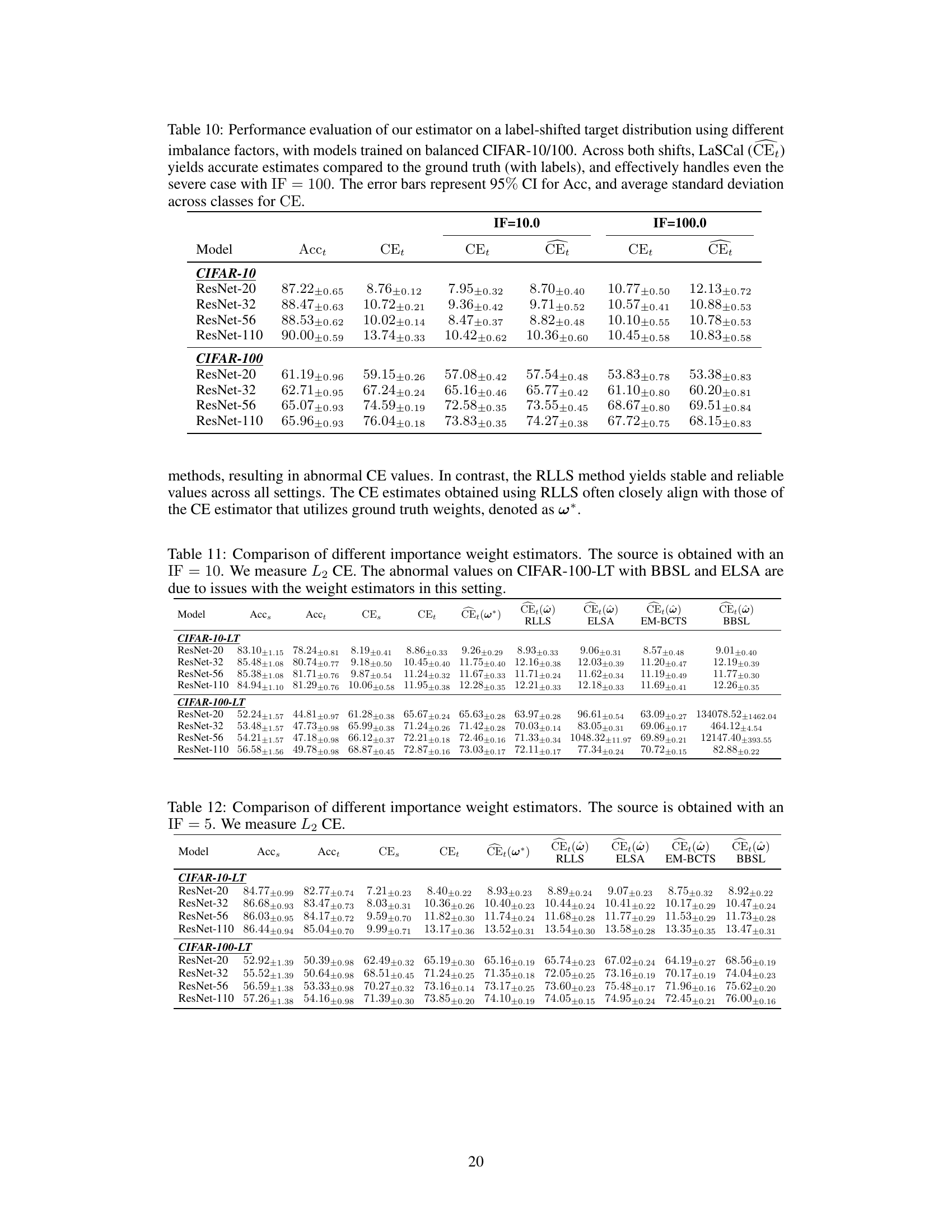
This research makes valuable contributions to label-shift calibration, but acknowledges key limitations. LaSCal’s reliance on accurate importance weights is a significant concern, as the performance of the method directly depends on the quality of these weights. Inconsistent or inaccurate weights, as sometimes seen with ELSA, EM-BCTS, and BBSL, can undermine the estimator’s reliability. The impact of low data regimes is another limitation; while LaSCal demonstrates robustness across various settings, its effectiveness in severely data-scarce scenarios remains to be fully explored. Future work should focus on improving the robustness of importance weight estimation methods and investigating alternative approaches to address data scarcity. Expanding LaSCal’s applicability to other types of dataset shift, such as covariate shift, is essential to broaden its impact. Additionally, exploring the theoretical properties of the proposed CE estimator more rigorously, and potentially investigating its asymptotic convergence rates, would strengthen its theoretical foundations. Finally, a comprehensive comparison with more sophisticated or recent calibration techniques, and detailed exploration of its performance in real-world high-stakes applications, would provide further validation of LaSCal’s utility.
Unsupervised Cal.#
Unsupervised calibration techniques are crucial for reliable machine learning models, especially in situations where labeled data from the target domain is scarce or unavailable. The core challenge lies in accurately estimating the calibration error (CE) without access to labeled target data. This necessitates innovative approaches that leverage the available unlabeled target data and possibly information from a related source domain with labeled data. Effective unsupervised calibration methods typically involve robust CE estimation techniques under label shift, potentially incorporating importance weighting or other domain adaptation strategies to bridge the gap between source and target distributions. A successful unsupervised calibration method will demonstrate improvements in model reliability by aligning predicted confidence scores with actual accuracy on the target domain, and this improvement should be demonstrable without relying on any labeled target data. A key advantage is the ability to build robust and dependable models in scenarios where obtaining labeled target data is expensive, time-consuming, or practically impossible. The success of such methods hinges on the robustness of the CE estimator and its ability to generalize well to the target domain, even under substantial distribution shifts.
More visual insights#
More on figures

This figure presents a comparison of the LaSCal method with temperature scaling applied to both source and target data (using labels for the target). The left panel shows the effectiveness of LaSCal under label shift without target labels, demonstrating its ability to close the performance gap with a fully supervised method (TempScal Target). The right panel demonstrates LaSCal’s robustness against a more challenging scenario involving both label and covariate shift (changes in both the input data distribution and the label distribution). LaSCal is shown to perform comparably to, or better than, other methods in this complex setting.

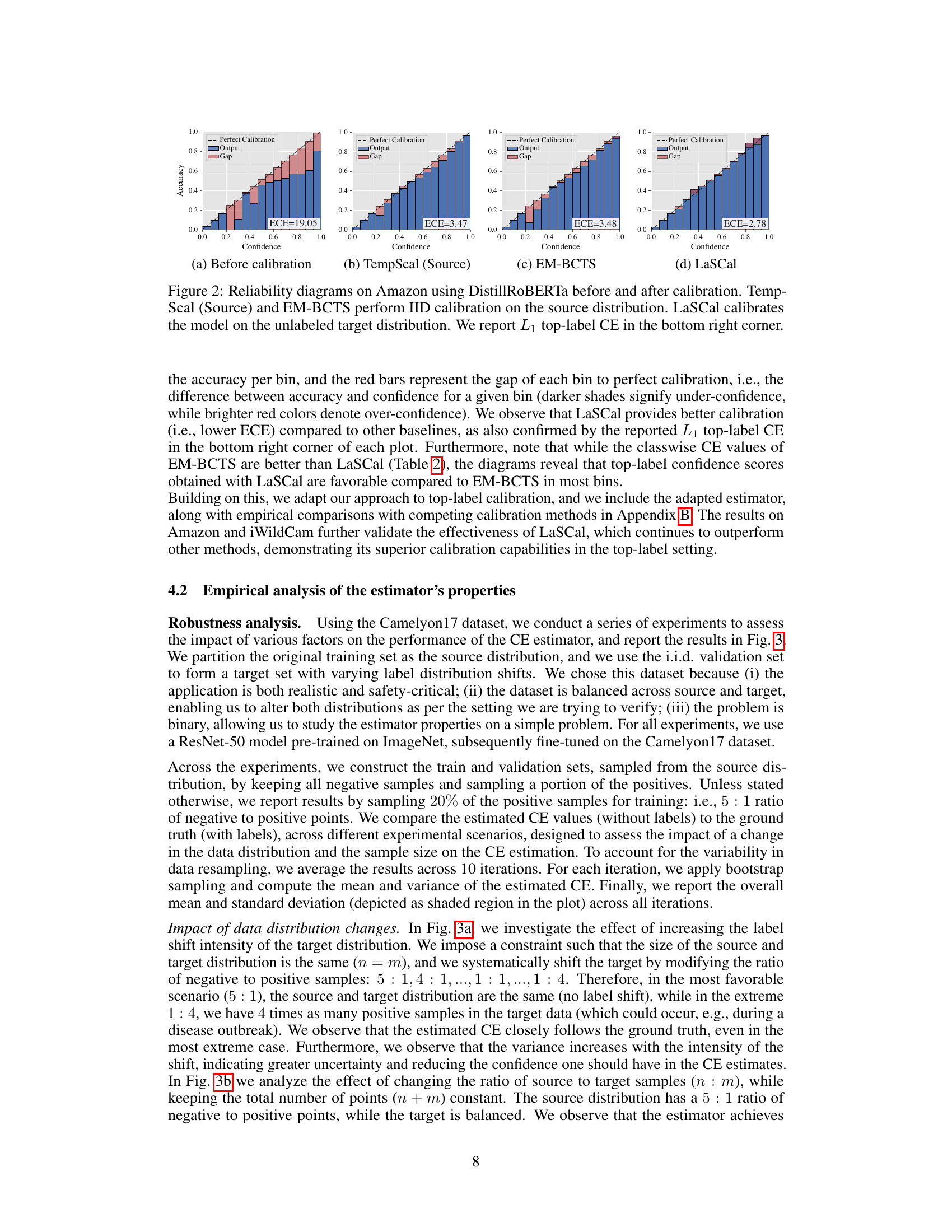
This figure displays reliability diagrams, illustrating the calibration performance of different methods on the Amazon dataset using the DistillRoBERTa model. The diagrams compare the model’s predicted confidence levels against its actual accuracy. The four plots represent different calibration scenarios: (a) Before calibration: Shows the model’s initial calibration state, with significant miscalibration evident in lower confidence bins. (b) TempScal (Source): Represents post-hoc calibration applied using the temperature scaling method trained on the source data. (c) EM-BCTS: Shows the calibration after applying the EM-BCTS method, a technique designed for label shift adaptation but calibrated on source data. (d) LaSCal: Demonstrates the calibration results when using the proposed LaSCal method, which performs calibration directly on the unlabeled target data. The L₁ top-label calibration error (ECE) is provided for each scenario. LaSCal is expected to achieve better calibration (lower ECE) than methods calibrated on the source domain.

This figure demonstrates the robustness of the proposed CE estimator under various conditions. The three subfigures show how the estimator performs under different levels of label shift, different ratios of source to target sample sizes, and different overall sample sizes. The shaded regions represent standard deviation, indicating the uncertainty of the estimate under each scenario. The results suggest the estimator is reliable across a range of conditions.

The left plot shows the impact of different weight estimation methods (ELSA, RLLS, EM-BCTS) on the proposed CE estimator. The right plot compares the estimated CE using the RLLS importance weights with the ground truth CE, demonstrating that the estimator accurately captures the calibration error even in the absence of labeled target data.

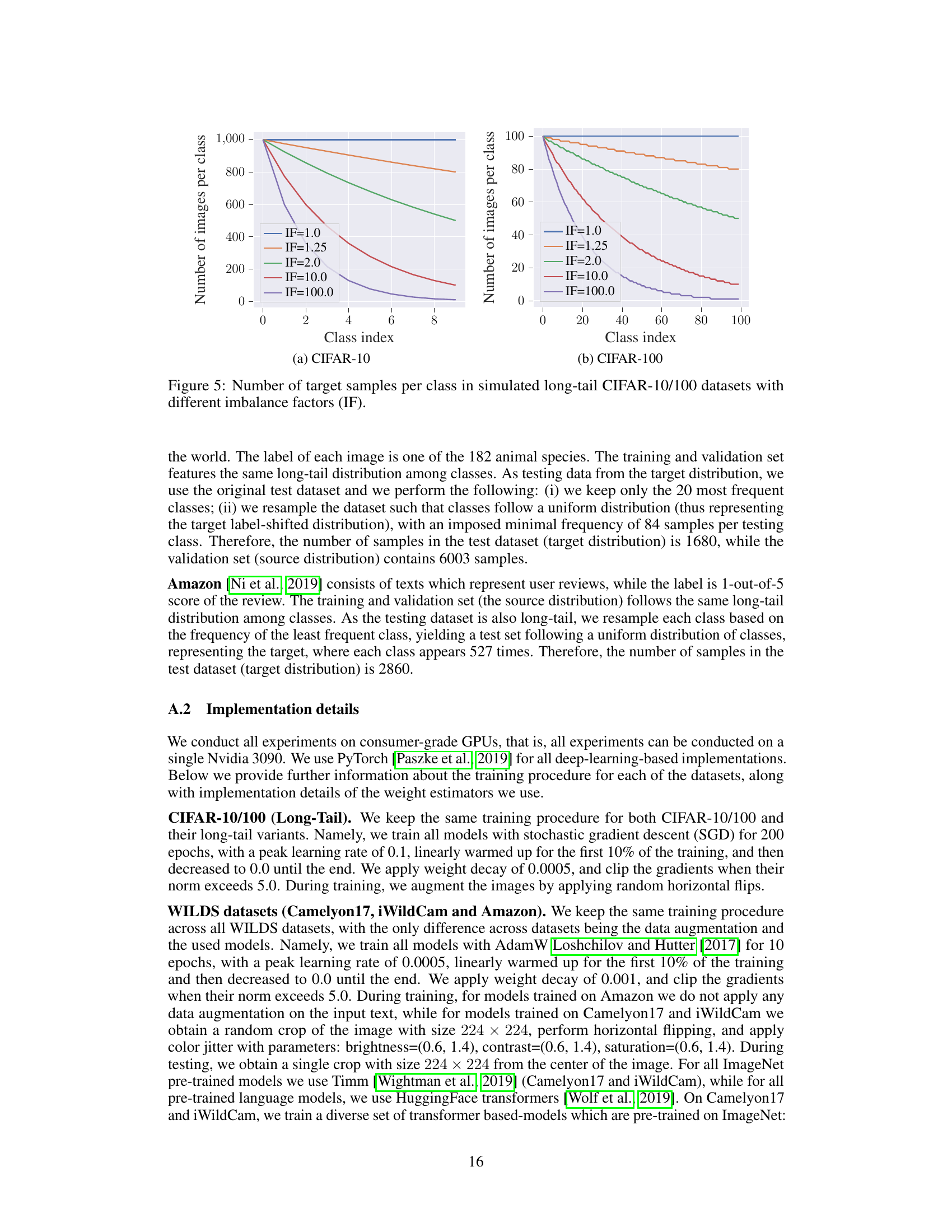
This figure shows the distribution of target samples across classes in simulated long-tail CIFAR-10 and CIFAR-100 datasets. Different lines represent different imbalance factors (IF), which control the ratio between the most and least frequent classes. An IF of 1.0 indicates a balanced dataset, while higher IF values represent increasingly imbalanced datasets. The x-axis represents the class index, and the y-axis shows the number of samples per class. The plot illustrates how the number of samples per class decreases as the imbalance factor increases, showing the effect of the long-tail distribution on the data.

This figure displays reliability diagrams which are used to visualize the calibration of a model’s predicted probabilities. The x-axis represents the model’s predicted confidence, and the y-axis represents the accuracy of the model’s predictions at that confidence level. The four subfigures show the reliability diagrams for a DistillRoBERTa model trained on the Amazon dataset, comparing four different scenarios: (a) Before calibration: shows the model’s calibration before applying any post-hoc calibration method. (b) TempScal (Source): shows the calibration of the model after applying temperature scaling using only labeled source data. (c) EM-BCTS: displays the model’s calibration after applying EM-Bias Corrected Temperature Scaling (EM-BCTS), which accounts for label shift and performs calibration using both source and target data. Note that, unlike LaSCal, EM-BCTS requires labeled target data. (d) LaSCal: shows the calibration performance of the model after applying LaSCal. LaSCal is the proposed calibration method which does not require labeled target data. The dotted line represents perfect calibration. The red bars illustrate the gap between the predicted confidence and the actual accuracy, indicating miscalibration. The lower the L₁ top-label CE value (shown in the lower right corner of each subplot), the better the calibration of the model. The figure indicates that LaSCal achieves the best calibration results among all the methods compared.

The left plot compares LaSCal’s performance against temperature scaling with and without target labels. The right plot shows the calibration error (CE) after applying different calibration methods when both label and input distributions change between the source and target domains. LaSCal is shown to perform competitively, especially considering it does not require target labels.
More on tables
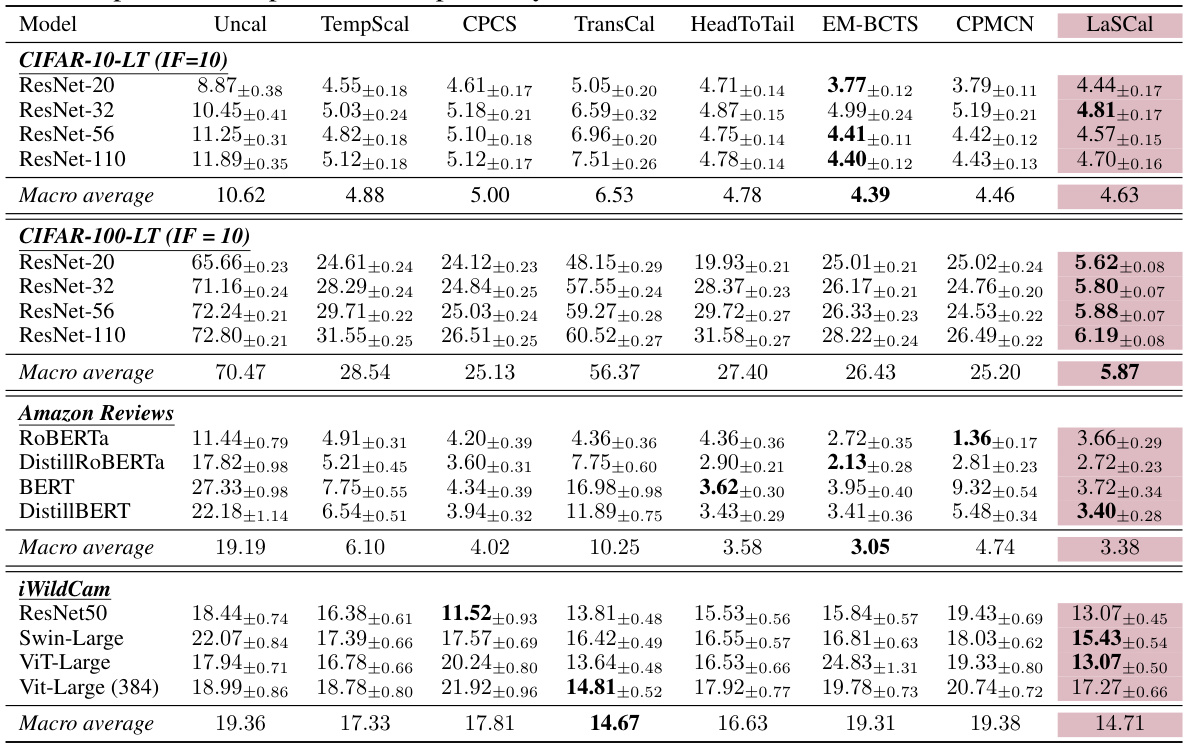
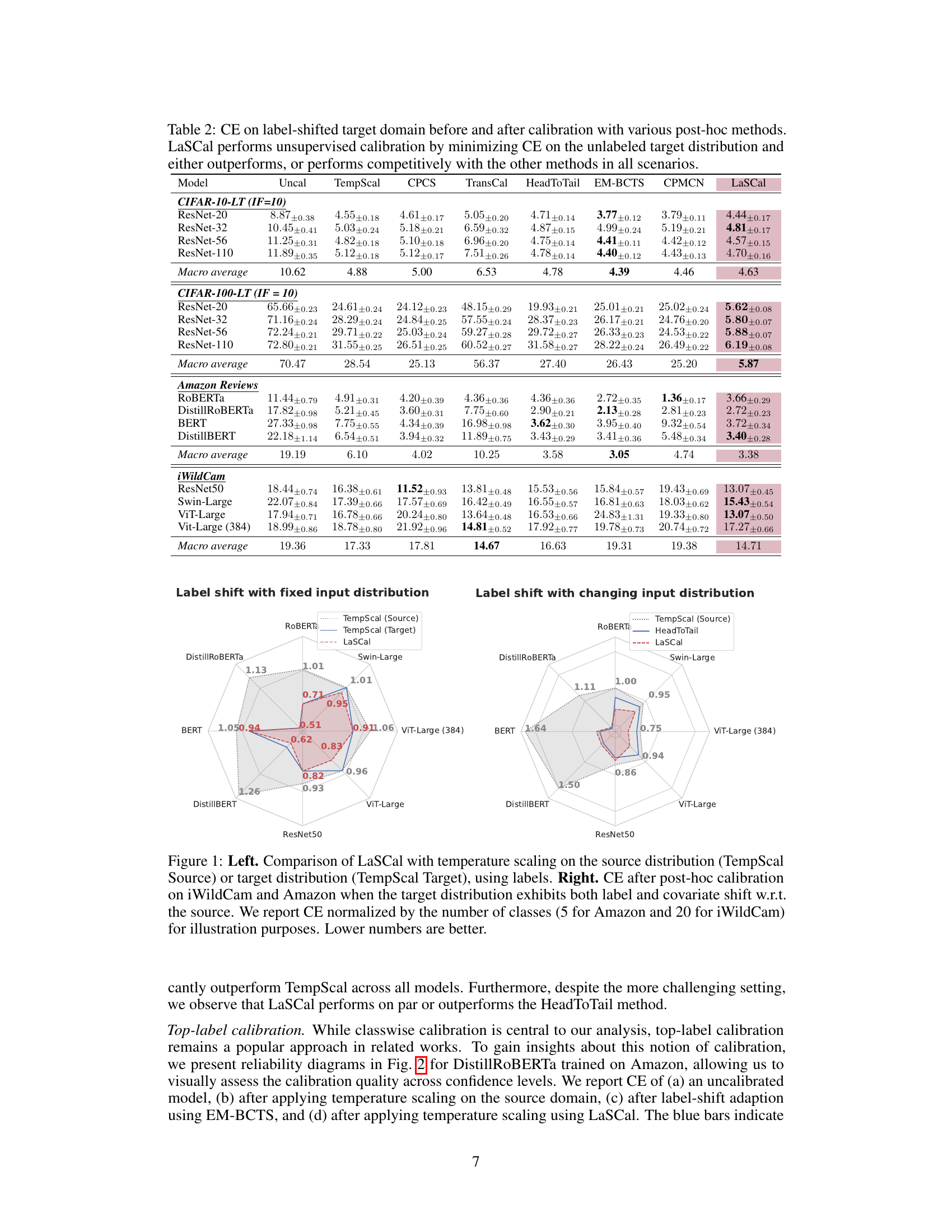
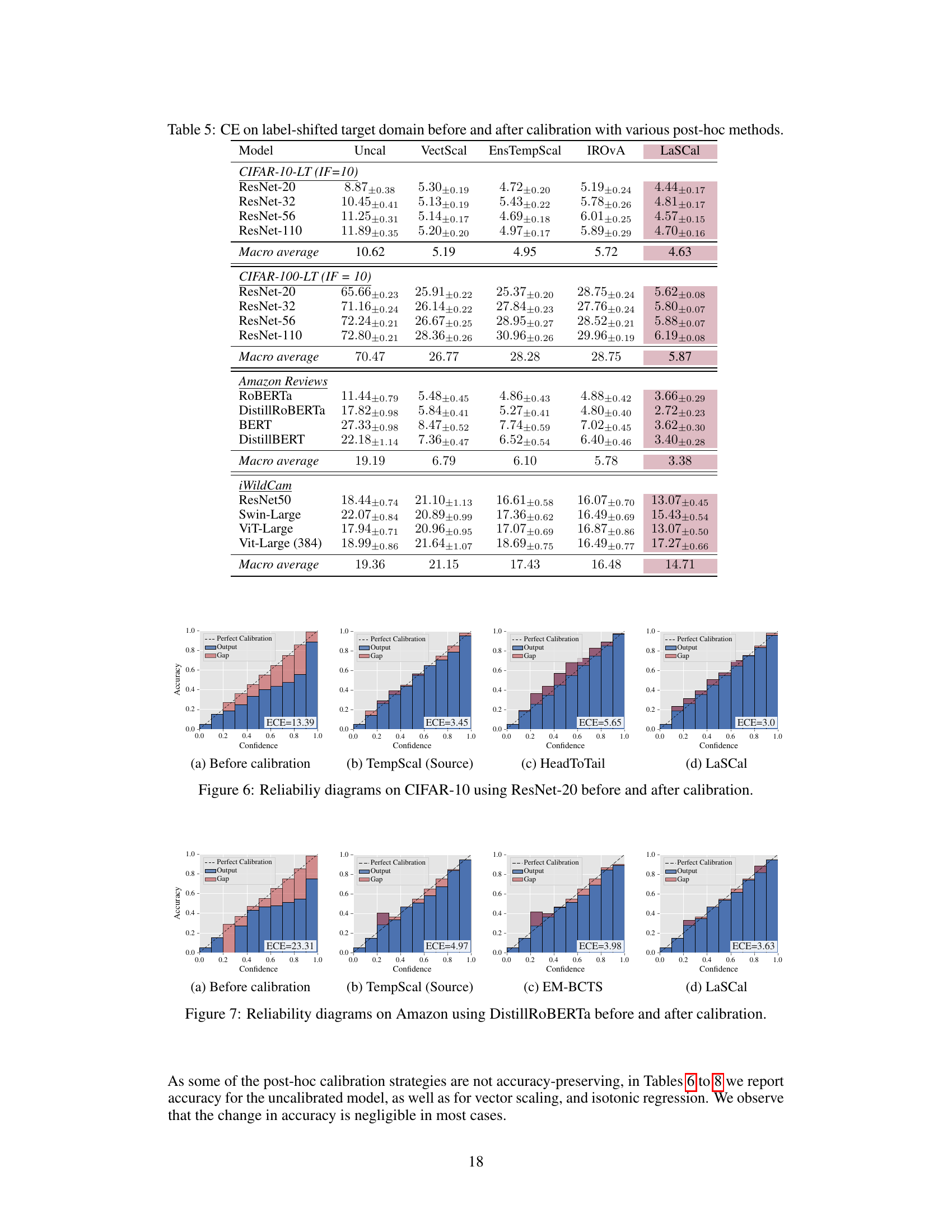
This table compares the calibration error (CE) of several post-hoc calibration methods on label-shifted target datasets. The methods are evaluated across different model architectures (ResNet, ViT, BERT, etc.) and datasets (CIFAR, iWildCam, Amazon reviews). The table shows the CE before calibration (Uncal), after calibration using temperature scaling on the source data (TempScal), and after calibration using other methods designed for covariate or label shift (CPCS, TransCal, HeadToTail, EM-BCTS, CPMCN) and the proposed method (LaSCal). LaSCal consistently performs well compared to other methods.
This table presents a comparison of the calibration error (CE) on a label-shifted target domain before and after applying various post-hoc calibration methods. The methods compared include several state-of-the-art techniques designed for covariate shift, label shift adaptation, and the proposed LaSCal method. The results are shown across different model architectures and datasets, demonstrating the effectiveness of LaSCal in unsupervised calibration under label shift.
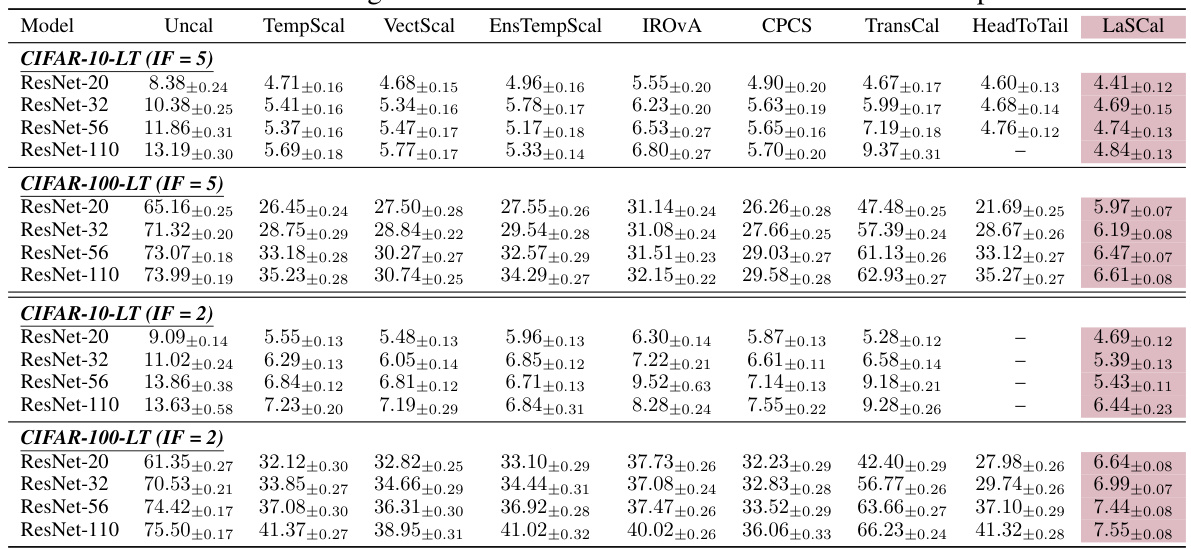
This table presents a comparison of the calibration error (CE) on a label-shifted target domain for various models and post-hoc calibration methods. It shows the CE before calibration (Uncal), after calibration using temperature scaling on the source data (TempScal), using several methods designed for covariate shift (CPCS, TransCal, HeadToTail), and using methods designed for label-shift (EM-BCTS, CPMCN). Finally, it presents results for the proposed LaSCal method. The table is organized by dataset (CIFAR-10-LT, CIFAR-100-LT, Amazon Reviews, iWildCam), model architecture (ResNet, ROBERTa, BERT, ViT etc.), and shows mean CE with standard deviation. The results demonstrate the effectiveness of LaSCal in achieving unsupervised calibration on label-shifted data.

This table presents a comparison of different post-hoc calibration methods on label-shifted datasets. It shows the calibration error (CE) before and after applying various calibration techniques, including LaSCal, a novel method proposed by the authors. The results demonstrate LaSCal’s effectiveness in unsupervised calibration under label shift, either outperforming or achieving comparable results to state-of-the-art methods across different datasets and model architectures.

This table presents the results of calibration error (CE) experiments performed on label-shifted target domains across multiple datasets and model architectures. It compares the performance of LaSCal against several baseline methods, including uncalibrated models, temperature scaling on source data, and other methods designed for covariate shift or label shift adaptation. The table highlights that LaSCal, which performs unsupervised calibration on the target domain, either achieves lower CE or performs on par with the best-performing method, showcasing its effectiveness in various settings.

This table presents the calibration error (CE) results on label-shifted target data for various models and calibration methods. It compares the performance of LaSCal against several baselines, including uncalibrated models, temperature scaling on source data, methods adapted for covariate shift, and methods incorporating label shift adaptation with source calibration. The results show LaSCal’s superior or competitive performance across different scenarios.
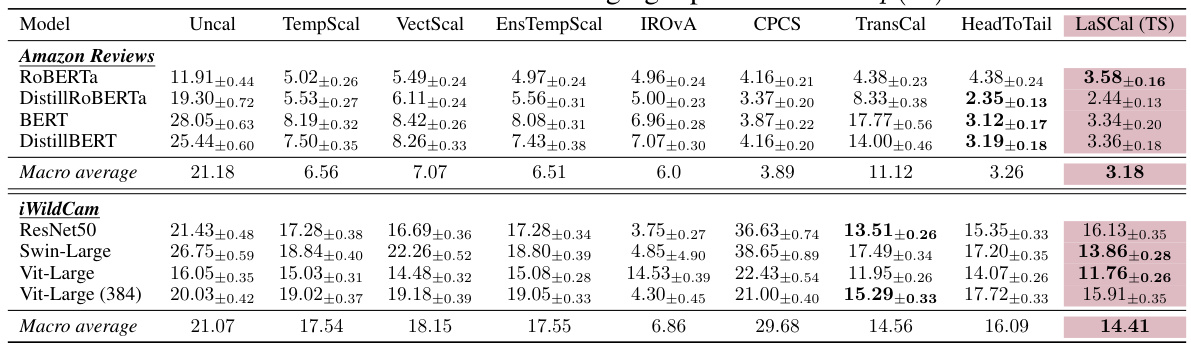
This table presents the calibration error (CE) on a label-shifted target domain for various models and calibration methods. It compares the performance of LaSCal (the proposed method) against several baseline methods, including uncalibrated models, temperature scaling on source data, and methods designed for covariate shift. The results are presented as macro-averaged CE values, showing the effectiveness of LaSCal in unsupervised calibration scenarios.

This table presents the calibration error (CE) on a label-shifted target domain for various models and datasets. It compares the performance of LaSCal (a novel label-free calibration method) against several baseline calibration methods, including uncalibrated models, temperature scaling on source data, and methods designed for covariate shift. The results demonstrate that LaSCal either outperforms or achieves comparable performance to other methods across different modalities, models and datasets.

This table presents a comparison of the calibration error (CE) on a label-shifted target domain before and after applying various post-hoc calibration methods. The methods compared include the uncalibrated model, temperature scaling calibrated on the source data, several state-of-the-art methods designed for covariate shift, and methods for label shift adaptation that perform calibration on source data before obtaining the importance weights. LaSCal, the proposed unsupervised calibration method, is shown to either outperform or perform comparably to the best-performing methods, demonstrating its effectiveness across various datasets and model architectures.
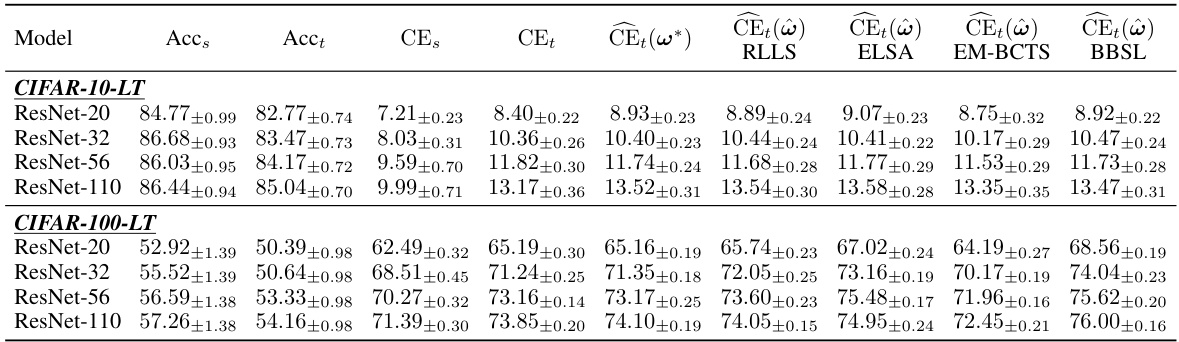
This table presents a comparison of the calibration error (CE) on a label-shifted target domain before and after applying various post-hoc calibration methods. The methods include: uncalibrated models (Uncal), temperature scaling calibrated on source data (TempScal), methods designed for covariate shift (CPCS, TransCal, HeadToTail), and methods for label shift adaptation (EM-BCTS, CPMCN). LaSCal, the proposed method, is shown to either outperform or perform competitively with existing state-of-the-art methods across various model architectures and dataset.
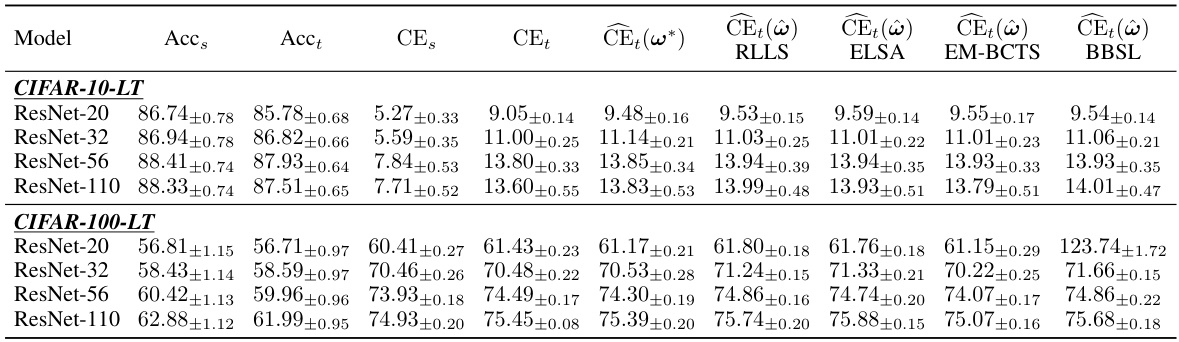
This table presents a comparison of different post-hoc calibration methods on label-shifted target data. It shows the calibration error (CE) before and after applying various calibration methods, including LaSCal. The results are reported across multiple model architectures (ResNet, ViT, etc.) and datasets (CIFAR-10/100-LT, Amazon, iWildCam). LaSCal demonstrates its effectiveness by achieving lower or comparable CE values to the other state-of-the-art methods, especially in unsupervised settings.
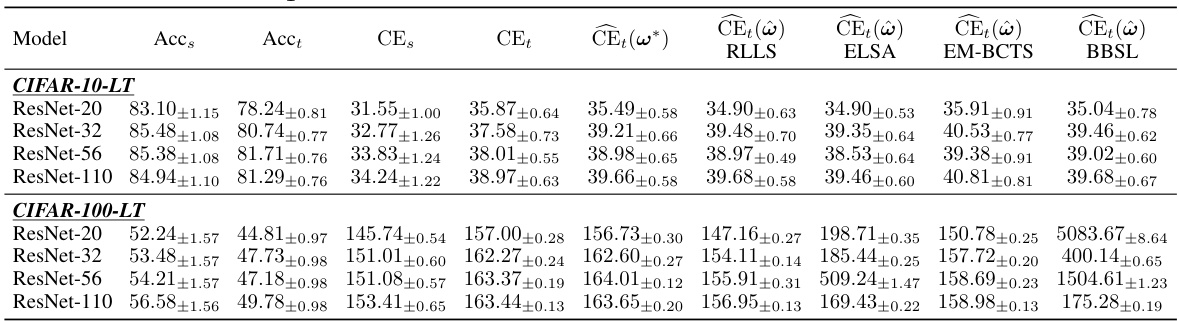
This table presents a comparison of the calibration error (CE) on a label-shifted target domain before and after applying different post-hoc calibration methods. The methods compared include various state-of-the-art techniques, and the proposed LaSCal method. The table shows CE values for several different model architectures (ResNet, ViT, etc.) across multiple datasets (CIFAR, Amazon reviews, iWildCam). The results demonstrate LaSCal’s effectiveness in unsupervised calibration by achieving either superior or comparable performance across all scenarios.

This table presents a comparison of the calibration error (CE) on a label-shifted target domain before and after applying various post-hoc calibration methods. The methods compared include uncalibrated models, temperature scaling on source data, methods designed for covariate shift, methods for label shift adaptation, and the proposed LaSCal method. The results show LaSCal’s performance across different model architectures on CIFAR-10/100, Amazon Reviews, and iWildCam datasets, highlighting its effectiveness in unsupervised calibration under label shift.
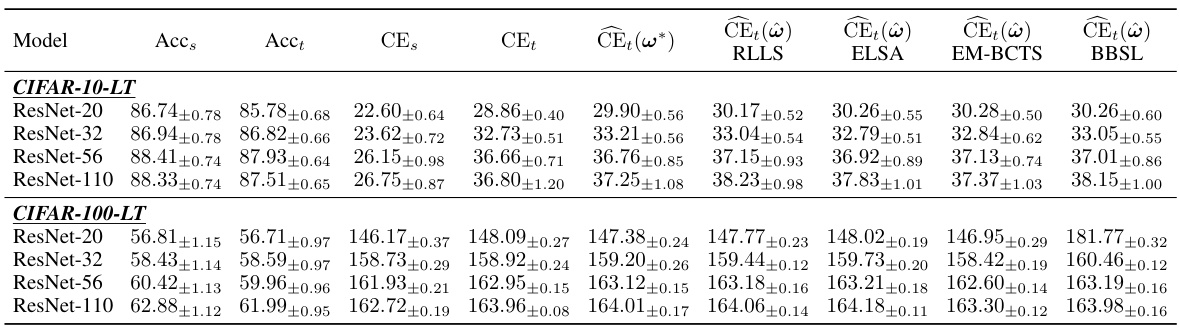
This table presents a comparison of calibration error (CE) on a label-shifted target domain. Several methods are compared: uncalibrated models, temperature scaling on source data, and other methods designed for covariate shift. The proposed method, LaSCal, is shown to perform either better than or comparably to the state-of-the-art in all scenarios. The results are broken down by model architecture and dataset to illustrate performance across different modalities.

This table presents a comparison of the calibration error (CE) on a label-shifted target domain before and after applying various post-hoc calibration methods. The methods compared include an uncalibrated model, temperature scaling on the source data, methods adapted for covariate shift (CPCS, TransCal, HeadToTail), and methods designed for label shift adaptation (EM-BCTS, CPMCN). The table shows that LaSCal, the proposed unsupervised calibration method, either achieves the lowest macro-averaged CE or performs comparably to the top-performing method across various models and datasets, demonstrating its effectiveness in unsupervised calibration under label shift.
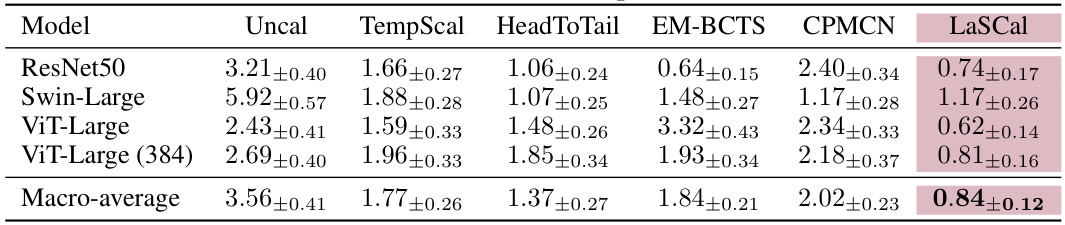
This table presents the Calibration Error (CE) results on a label-shifted target domain for various models using different post-hoc calibration methods. It compares the performance of LaSCal (the proposed method) against several baselines, including uncalibrated models, temperature scaling on source data, methods designed for covariate shift, and methods for label shift adaptation. The results show LaSCal’s effectiveness in unsupervised calibration on the target domain, often outperforming or matching the top-performing baseline across different settings.
Full paper#