↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are increasingly used in various applications, but effectively using tools via APIs remains a challenge due to LLMs’ limited awareness of available APIs and frequent updates. Existing LLMs struggle with accurate API call generation, often producing incorrect or hallucinatory outputs. This paper aims to improve LLMs’ ability to interact with APIs effectively.
The paper introduces Gorilla, a fine-tuned LLaMA model trained with a novel Retriever-Aware Training (RAT) method. RAT improves accuracy and reduces hallucinations by incorporating relevant API documentation into the training process. The effectiveness of Gorilla is demonstrated using APIBench, a new benchmark dataset encompassing various APIs. Gorilla significantly outperforms state-of-the-art LLMs in terms of both accuracy and reduced hallucination. The paper also introduces AST-based evaluation metrics, enabling a more precise measurement of functional correctness and hallucination.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) and APIs. It introduces a novel method for training LLMs to accurately use APIs, overcoming the challenges of dealing with vast, frequently-updated API landscapes. This opens up new avenues for research in LLM tool use, prompt engineering, and API integration, potentially impacting various applications from software development to scientific research.
Visual Insights#

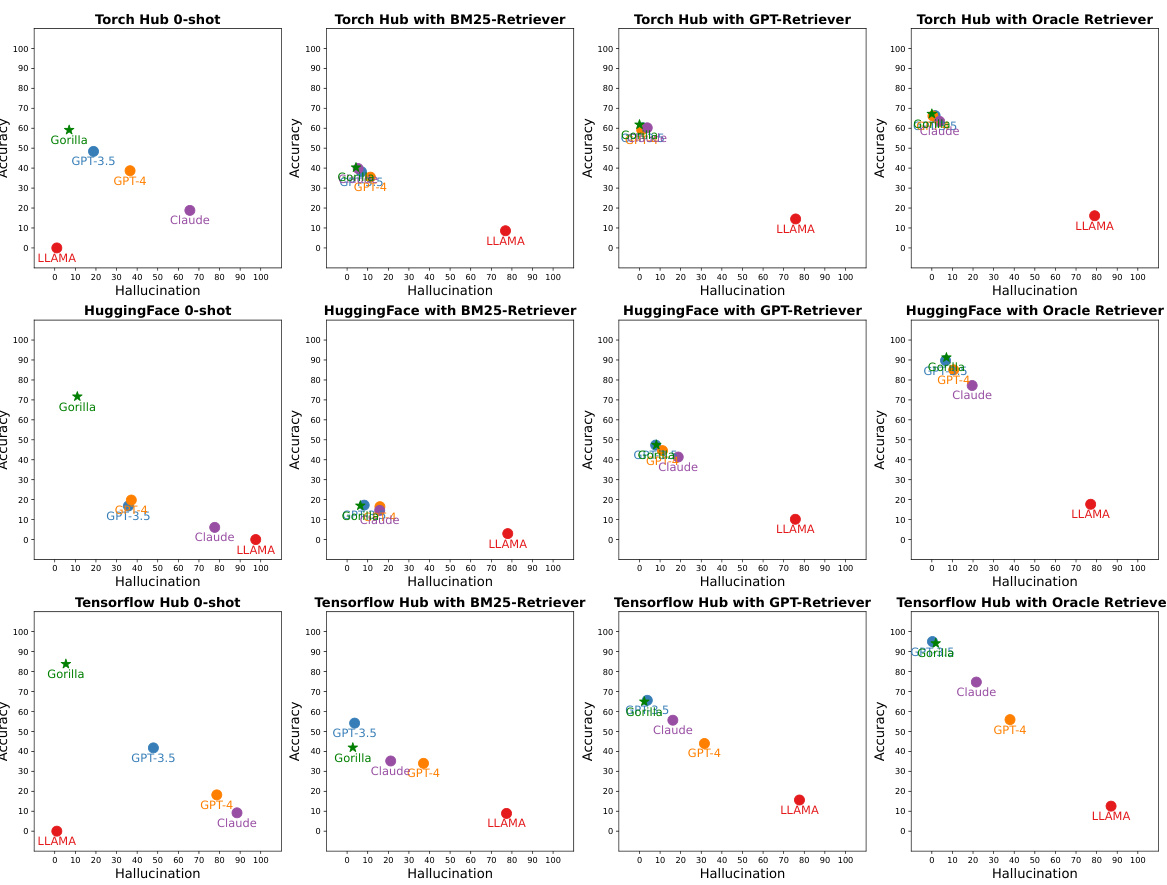
This figure compares the performance of Gorilla and other LLMs (GPT-3.5, GPT-4, LLaMA, Claude) across four different retrieval settings: zero-shot (no retriever), BM25 retriever, GPT retriever, and oracle retriever. The x-axis represents the hallucination rate, and the y-axis represents the accuracy. Gorilla consistently outperforms other models in terms of both accuracy and reduced hallucination, demonstrating its superior ability to utilize tools accurately.

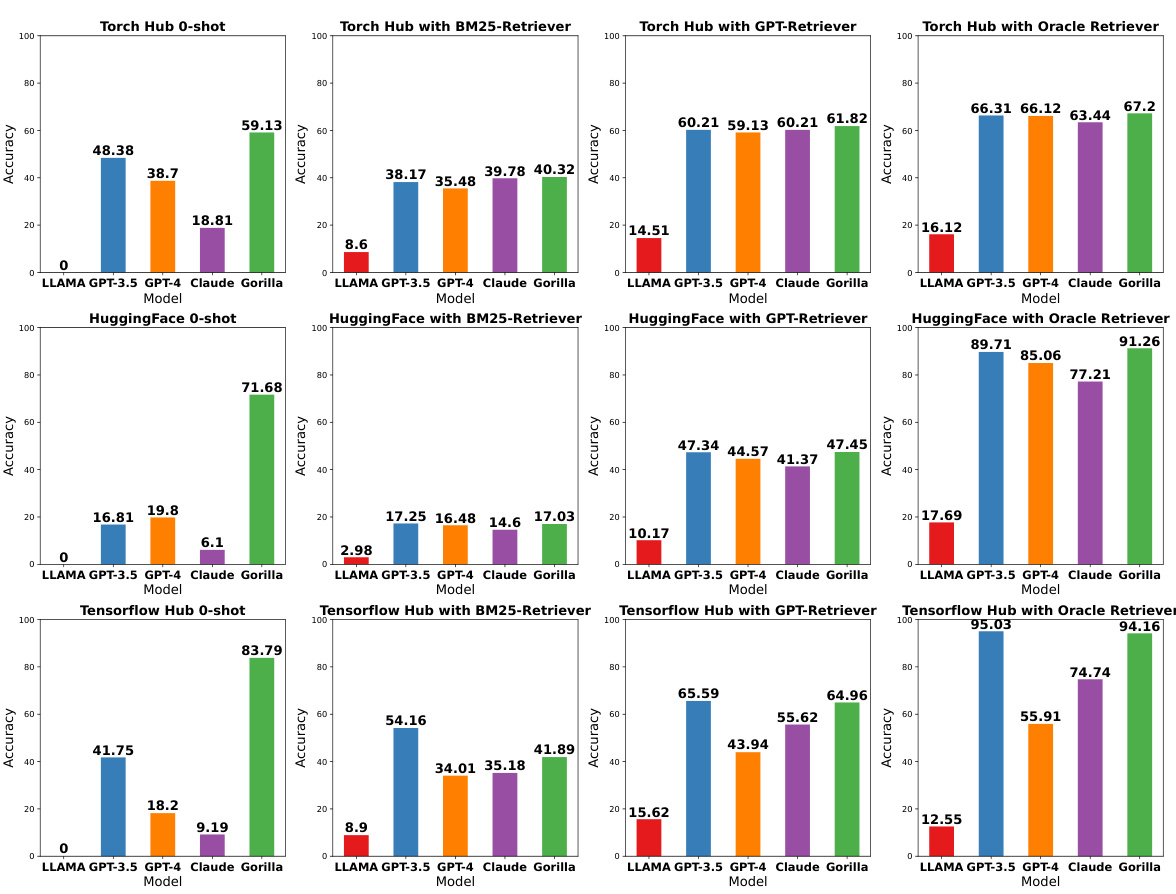
This table presents a comparison of various Large Language Models (LLMs) on three different API datasets: Torch Hub, HuggingFace, and TensorFlow Hub. The results are categorized by LLM, retrieval method (0-shot, BM25, GPT-Index, Oracle), and API dataset. For each combination, the overall accuracy, hallucination rate, and error rate are shown, providing a comprehensive performance comparison across different LLMs and retrieval strategies.
In-depth insights#
API-LLM Integration#
API-LLM integration is a rapidly evolving field aiming to leverage the strengths of both Large Language Models (LLMs) and Application Programming Interfaces (APIs). LLMs excel at understanding and generating human language, while APIs offer access to diverse external resources and functionalities. Effective integration unlocks significant potential, allowing LLMs to perform complex tasks beyond their inherent capabilities. However, challenges remain. LLMs often lack awareness of available APIs and their proper usage, leading to inaccurate or hallucinated outputs. Furthermore, the dynamic nature of APIs, with frequent updates and changes, necessitates robust methods for handling API versioning and documentation. Therefore, research in this area focuses on developing novel techniques to enhance LLM awareness of APIs, such as retrieval-augmented training and prompt engineering. Evaluation metrics also require careful consideration, ensuring they accurately assess both functional correctness and the propensity for hallucination. Successfully addressing these challenges will greatly expand the capabilities of LLMs, empowering them to become powerful and versatile tools across various domains.
Retriever-Aware Training#
Retriever-Aware Training (RAT) is a novel training technique that significantly enhances the performance and adaptability of Large Language Models (LLMs) when interacting with APIs. Instead of treating the retrieved information as perfectly accurate, RAT exposes the LLM to potentially flawed retrieved API documentation during training. This forces the model to develop a critical evaluation skill, learning to judge the relevance and accuracy of the retrieved context. This approach results in improved robustness as the LLM learns to rely less on potentially outdated or incorrect retrieved information. The technique is particularly beneficial for handling frequent API updates and resolving the challenge of hallucination, a common problem where LLMs fabricate information. By incorporating RAT, the resulting LLMs exhibit a strong capability to adapt to test-time document changes, making them more resilient to the ever-evolving nature of API documentation and improving both the accuracy and reliability of API calls.
APIBench: A New Dataset#
A hypothetical ‘APIBench: A New Dataset’ section in a research paper would likely detail a novel dataset designed for evaluating large language models’ (LLMs) ability to interact with APIs. Its creation would address the lack of comprehensive benchmarks specifically tailored to this task. The dataset’s design would be crucial, likely involving a structured format to represent diverse APIs, including their parameters, return types, and associated documentation. Diversity in API types and complexity would be paramount, ensuring that the benchmark can effectively evaluate the robustness and generalization capabilities of LLMs across different domains. Furthermore, the section would need to describe the dataset’s size and the process used to collect and curate the data, emphasizing the procedures taken to ensure data quality, consistency, and the elimination of biases. Detailed metrics for evaluating LLM performance on APIBench would also be presented, probably including accuracy, precision, recall, and potentially novel metrics focusing on aspects like the handling of API errors, or the ability to adapt to evolving API documentation. A thorough description of APIBench would be essential for other researchers to replicate experiments and further advance the research in LLM-API interaction.
Hallucination Mitigation#
Hallucination, a significant problem in large language models (LLMs), refers to the generation of plausible-sounding but factually incorrect information. This is particularly detrimental when LLMs interact with APIs, as inaccurate API calls can lead to errors or unexpected behavior. The paper addresses this challenge by introducing a novel training method called Retriever-Aware Training (RAT). RAT exposes the model to potentially inaccurate or incomplete API documentation during training, thereby teaching it to critically evaluate the information it receives from a retriever. This helps mitigate hallucinations by encouraging the model to rely more on its own learned knowledge and less on potentially flawed retrieved data. Furthermore, the use of an Abstract Syntax Tree (AST) based evaluation metric provides a more precise measurement of functional correctness and hallucination, going beyond simple keyword matching. By combining RAT with an AST-based evaluation, the system demonstrates significant improvements in accuracy and a reduction in hallucination compared to other LLMs when making API calls. The results highlight the importance of training methodologies that promote critical evaluation of information sources and the need for more nuanced evaluation metrics to accurately assess LLM performance in real-world applications.
Future of API-LLMs#
The future of API-LLMs is bright, promising a seamless integration between large language models and the vast landscape of APIs. We can anticipate more sophisticated tool use, moving beyond simple API calls to complex workflows and multi-step processes managed by LLMs. Improved accuracy and reliability will be achieved through enhanced training methods and advanced retrieval techniques. This will lead to more robust and trustworthy applications, reducing hallucinations and errors. We will also see broader API support, encompassing diverse data formats and communication protocols. The development of specialized LLMs tailored for specific API domains is another key trend, optimizing performance and enhancing adaptability. Ethical considerations will play a crucial role, emphasizing responsible development and deployment to prevent misuse and ensure fairness. Ultimately, the synergy between LLMs and APIs is poised to unlock unprecedented capabilities, transforming software development, automating tasks, and creating innovative solutions across various sectors.
More visual insights#
More on figures
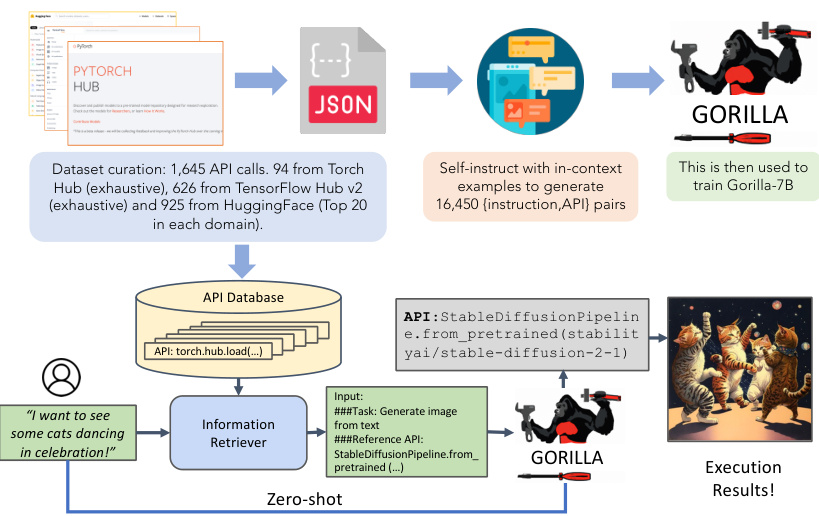
This figure illustrates the Gorilla system architecture. The upper half shows the training process, highlighting the creation of a comprehensive dataset of API calls from various sources (Torch Hub, TensorFlow Hub, HuggingFace), the self-instruct method used to generate training examples, and the training of the Gorilla-7B LLaMA model. The lower half shows the inference process, illustrating how Gorilla takes a user’s natural language query, uses an optional information retriever to find relevant APIs, and then generates an appropriate API call. The example showcases how a request to generate an image of dancing cats is correctly translated into an API call using the StableDiffusion pipeline.
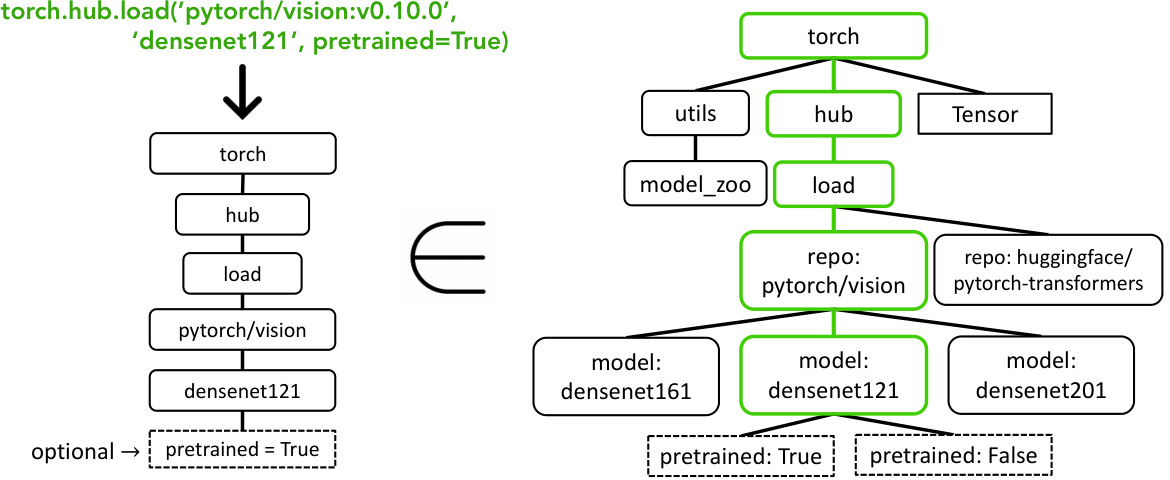
This figure illustrates the Abstract Syntax Tree (AST) based sub-tree matching technique used to evaluate the accuracy of API calls generated by the Gorilla model. The left side shows a sample API call and its corresponding tree representation. The right side shows how this tree is compared against the API calls in the dataset. A match (highlighted in green) indicates a correct API call; a mismatch implies an error or hallucination. The example highlights how optional arguments are handled in the matching process.
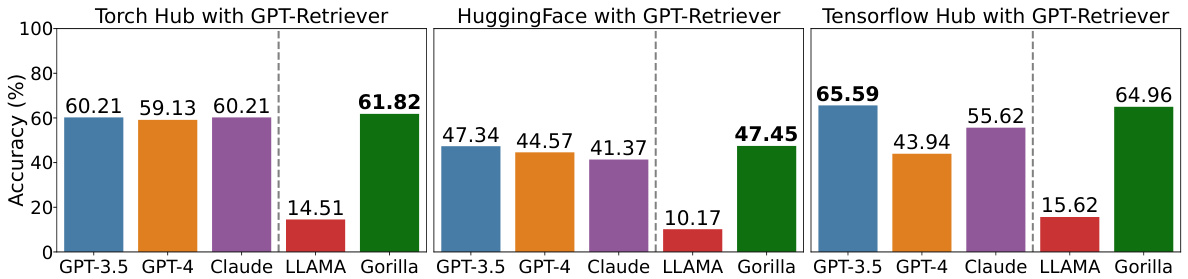
This figure shows the accuracy of different LLMs (GPT-3.5, GPT-4, Claude, LLaMA, and Gorilla) on three different API hubs (Torch Hub, HuggingFace, and TensorFlow Hub) when using a GPT retriever. The results demonstrate that Gorilla significantly outperforms other LLMs on Torch Hub and HuggingFace, achieving comparable performance to the best models on TensorFlow Hub. The dotted line in the chart separates closed-source models (to the left) from open-source models (to the right).
The figure compares the accuracy of different LLMs (including Gorilla) on three different API hubs (Torch Hub, HuggingFace, and TensorFlow Hub) when using a GPT retriever. The left side shows closed-source LLMs, and the right open-source LLMs. Gorilla demonstrates superior or comparable performance across all three hubs compared to other LLMs.
The figure compares the accuracy of several LLMs (including Gorilla) when using a GPT retriever across three different API hubs (Torch Hub, HuggingFace, and TensorFlow Hub). It shows Gorilla achieving either comparable or superior performance to other models, particularly surpassing closed-source models on Torch Hub and HuggingFace.

This figure shows examples of API calls generated by three different large language models (LLMs): GPT-4, Claude, and the authors’ proposed model, Gorilla. The prompt asks each model to provide an API call to convert spoken language in a recorded audio file to text using Torch Hub. The figure highlights that while GPT-4 hallucinates a non-existent model and Claude selects an incorrect library, Gorilla correctly identifies the task and generates a fully qualified API call. This demonstrates Gorilla’s superior ability to accurately and effectively use tools via API calls.
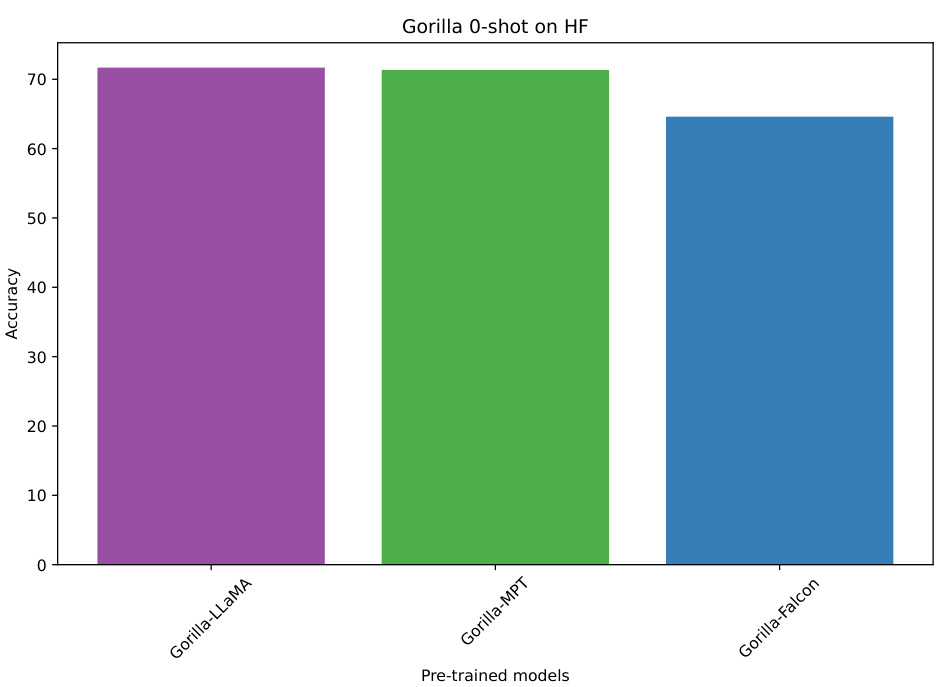
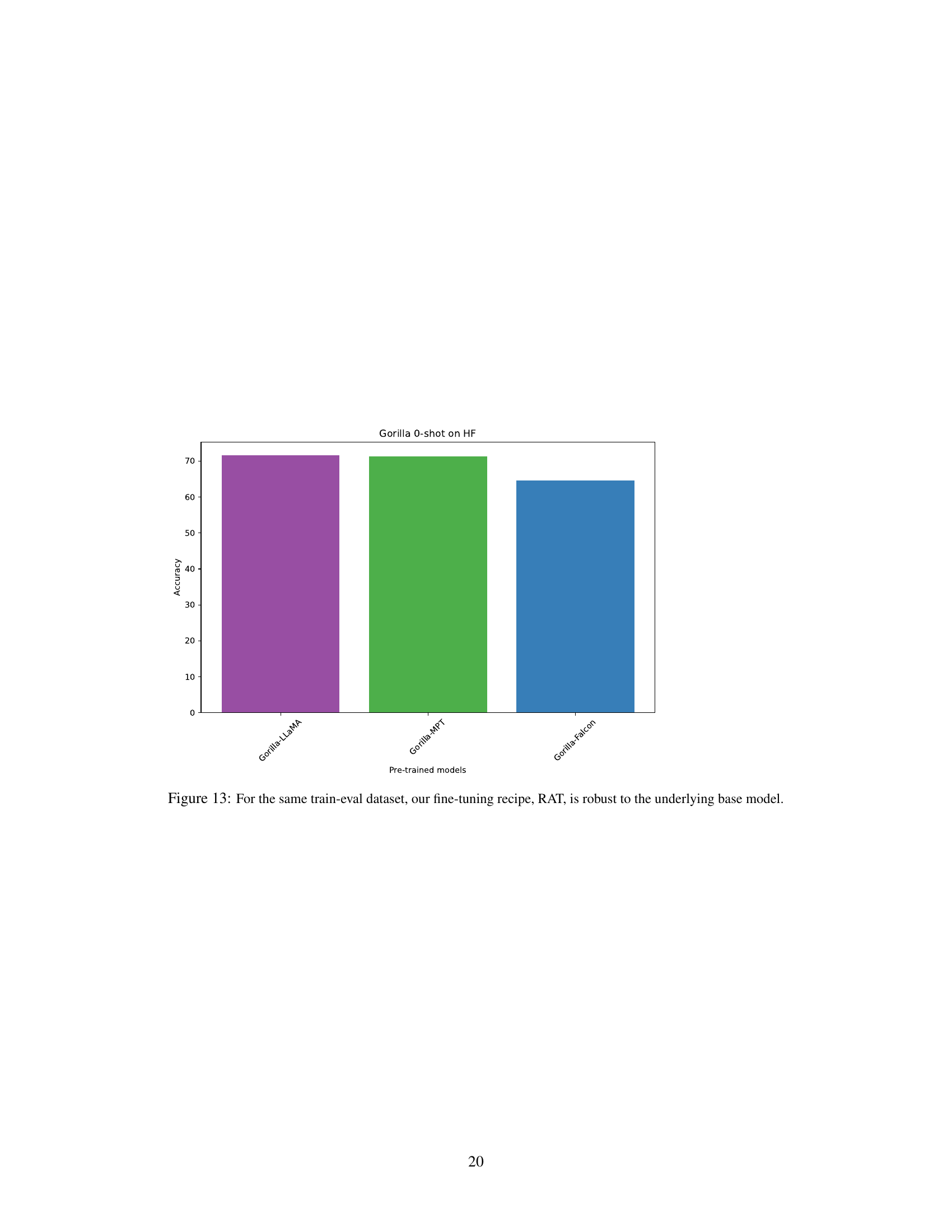
The bar chart displays the accuracy of Gorilla models (Gorilla-LLaMA, Gorilla-MPT, Gorilla-Falcon) trained on the HuggingFace dataset, showcasing the robustness of the RAT fine-tuning method across different base models. Despite using different pre-trained models as the foundation, the accuracy remains relatively consistent, highlighting the effectiveness and generalizability of RAT. The figure supports the paper’s claim that RAT is not highly sensitive to the choice of pre-trained model.
More on tables
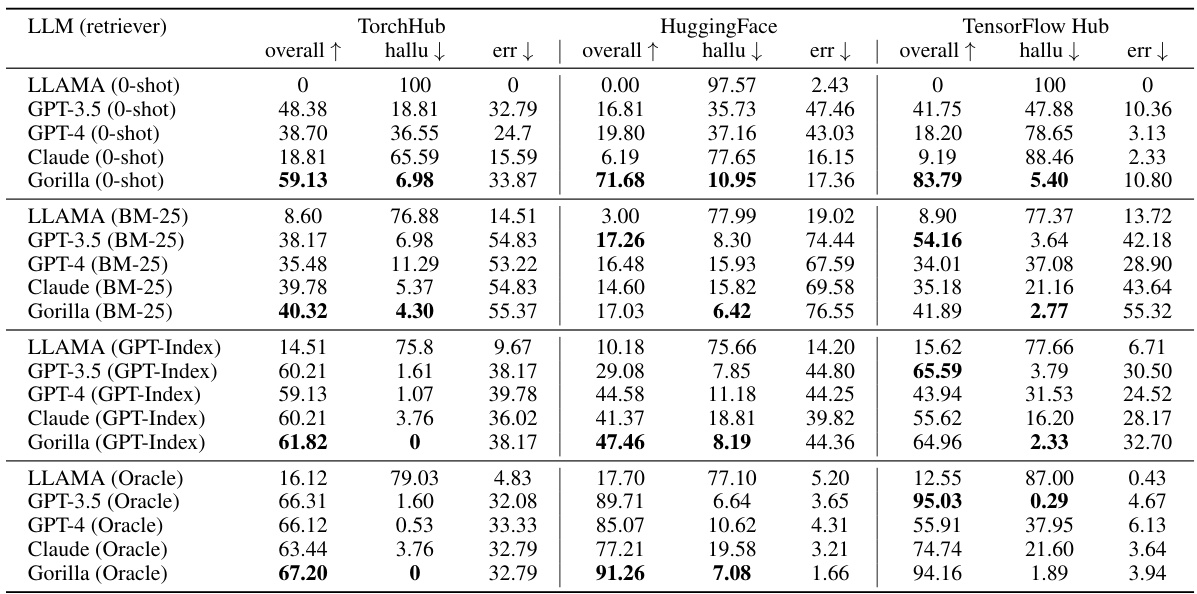
This table presents a comprehensive evaluation of various Large Language Models (LLMs) on three different API hubs: Torch Hub, HuggingFace, and TensorFlow Hub. The evaluation considers zero-shot performance and performance when using BM25 and GPT-Index retrievers. Metrics include overall accuracy, hallucination rate (incorrect API calls due to model generating non-existent APIs), and error rate (incorrect API calls despite using a real API). The table allows for a comparison of different LLMs and retrieval strategies across various API collections.
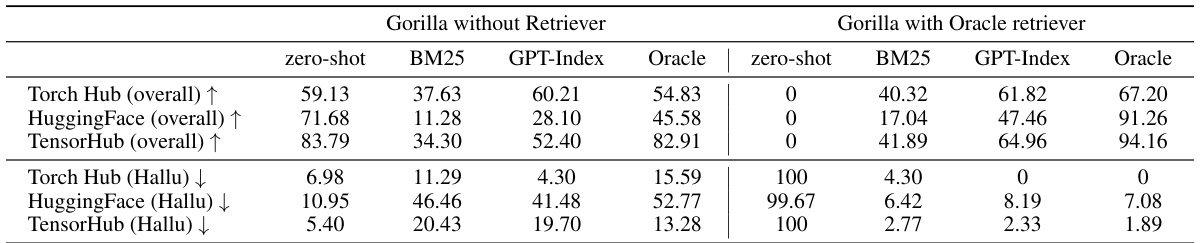
This table presents the performance of various LLMs (LLaMA, GPT-3.5, GPT-4, Claude, and Gorilla) on three different API hubs (Torch Hub, HuggingFace, and TensorFlow Hub). It compares their performance across various retrieval settings (zero-shot, BM25, GPT-Index, and Oracle). The metrics used are overall accuracy, hallucination error rate, and the error rate due to selecting the wrong API call. The table highlights the differences in performance between various models and retrieval strategies. Gorilla’s superior performance compared to other models, especially in zero-shot scenarios, is a key finding.

This table presents the performance of various LLMs (Large Language Models) on three different API hubs: Torch Hub, HuggingFace, and TensorFlow Hub. The models are evaluated under various conditions (zero-shot, with BM25 retriever, with GPT retriever, and with an oracle retriever). The results are presented as overall accuracy, hallucination rate (incorrect APIs generated), and error rate (correct API but with incorrect arguments). The table allows for comparison of the accuracy and reliability of different LLMs in generating API calls across various hubs and retrieval scenarios.
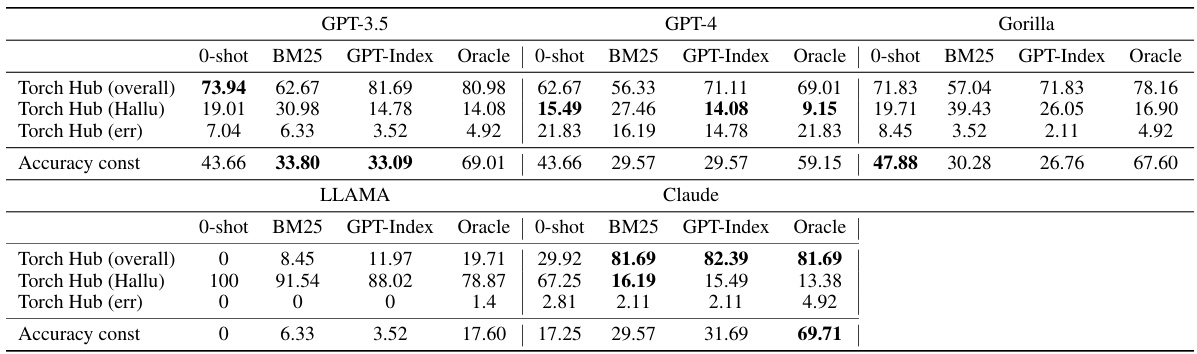
This table presents the performance comparison of various Large Language Models (LLMs) on three different API hubs: Torch Hub, HuggingFace, and TensorFlow Hub. The LLMs are evaluated under different conditions, including zero-shot (no retriever), and using BM25 and GPT-Index retrievers. The metrics used are overall accuracy, hallucination rate (hallu), and error rate (err), which represent the proportion of correctly generated API calls, hallucinated API calls, and API calls with errors, respectively. Additionally, the table shows the accuracy on API calls with constraints (Accuracy const). The results demonstrate the effectiveness of Gorilla, a newly developed LLM, in comparison to existing LLMs.

This table presents the results of evaluating various Large Language Models (LLMs) on three different API hubs: Torch Hub, HuggingFace, and TensorFlow Hub. The evaluation metrics include overall accuracy, hallucination rate (incorrect API calls due to model generation errors), and error rate (incorrect API calls due to selecting the wrong API). The table shows the performance of each LLM in a zero-shot setting and with three different retriever settings: BM25, GPT-Index, and Oracle. The results are useful to compare the performance of different LLMs in generating accurate API calls across various settings and hubs.

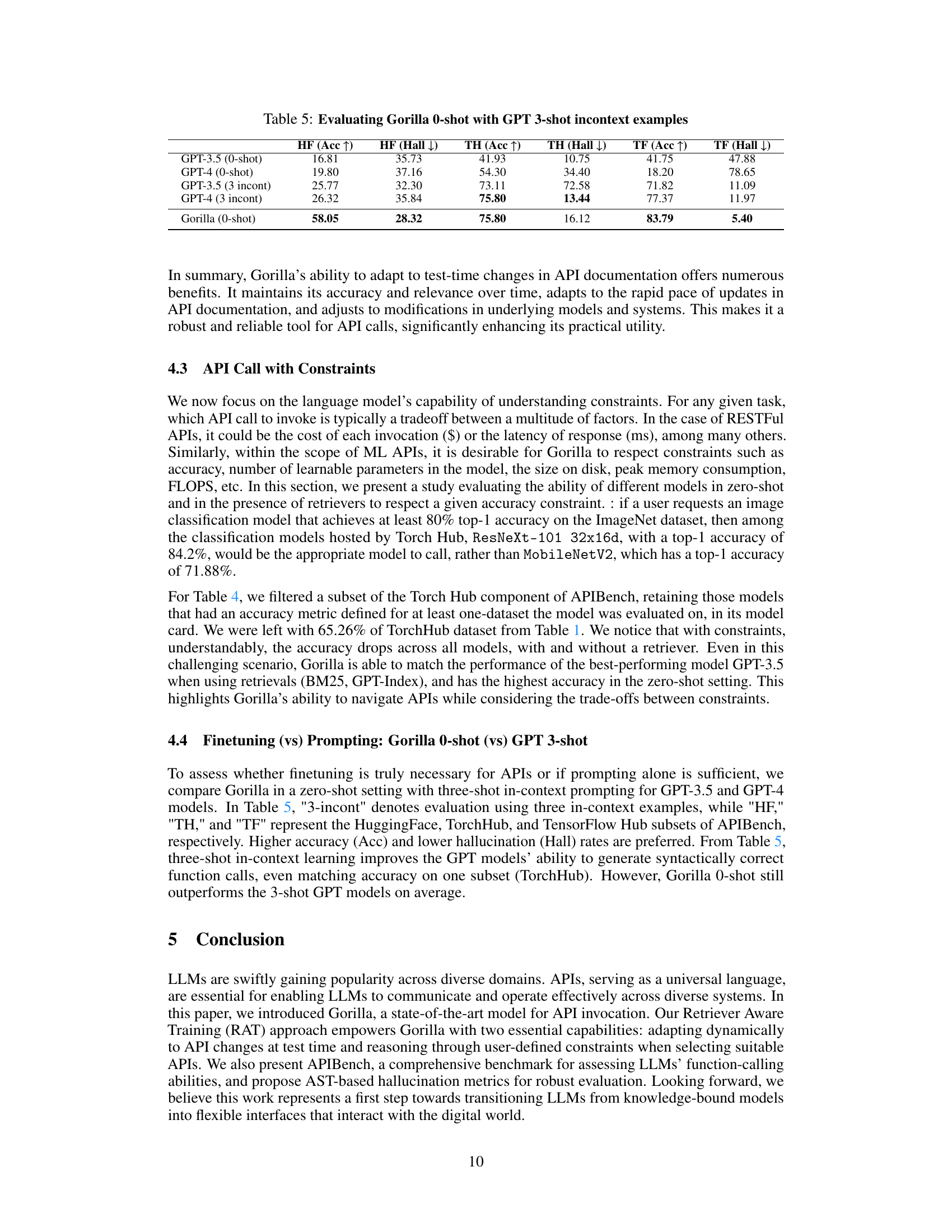
This table compares the performance of Gorilla (zero-shot) against GPT-3.5 and GPT-4 (with three in-context examples) across three API benchmark subsets (HuggingFace, TorchHub, and TensorFlow Hub). The metrics used are accuracy (Acc↑) and hallucination rate (Hall↓). Higher accuracy and lower hallucination are better. The results demonstrate Gorilla’s superior performance even without in-context examples.
This table presents the performance comparison of various LLMs (LLaMA, GPT-3.5, GPT-4, Claude, and Gorilla) across three different API hubs (Torch Hub, HuggingFace, and TensorFlow Hub). The evaluation metrics include overall accuracy, hallucination rate, and error rate. The results are shown for different retriever settings (zero-shot, BM25 retriever, GPT-Index retriever, and Oracle retriever). The table allows for a comprehensive comparison of different models and strategies in using LLMs with APIs.
This table presents the evaluation results of various Large Language Models (LLMs) on three different API hubs: Torch Hub, HuggingFace, and TensorFlow Hub. It compares the performance of these LLMs in several settings: zero-shot (no retriever), and with BM25 and GPT retrievers, as well as an oracle retriever. The metrics used are overall accuracy, hallucination rate (percentage of incorrect API calls due to hallucinations), and error rate (percentage of incorrect API calls due to other reasons). The table allows for a comparison of LLMs across different API datasets and retrieval strategies, highlighting the impact of retrieval methods on performance.

This table compares the performance of Gorilla and DocPrompting on a specific task. It shows that Gorilla achieves higher accuracy while significantly reducing hallucination compared to DocPrompting. The metrics presented are Accuracy (higher is better) and Hallucination (lower is better). The improvements demonstrate the effectiveness of Gorilla’s approach.
Full paper#